Home / Guides / Citation Guides / How to Cite Sources

How to Cite Sources
Here is a complete list for how to cite sources. Most of these guides present citation guidance and examples in MLA, APA, and Chicago.
If you’re looking for general information on MLA or APA citations , the EasyBib Writing Center was designed for you! It has articles on what’s needed in an MLA in-text citation , how to format an APA paper, what an MLA annotated bibliography is, making an MLA works cited page, and much more!
MLA Format Citation Examples
The Modern Language Association created the MLA Style, currently in its 9th edition, to provide researchers with guidelines for writing and documenting scholarly borrowings. Most often used in the humanities, MLA style (or MLA format ) has been adopted and used by numerous other disciplines, in multiple parts of the world.
MLA provides standard rules to follow so that most research papers are formatted in a similar manner. This makes it easier for readers to comprehend the information. The MLA in-text citation guidelines, MLA works cited standards, and MLA annotated bibliography instructions provide scholars with the information they need to properly cite sources in their research papers, articles, and assignments.
- Book Chapter
- Conference Paper
- Documentary
- Encyclopedia
- Google Images
- Kindle Book
- Memorial Inscription
- Museum Exhibit
- Painting or Artwork
- PowerPoint Presentation
- Sheet Music
- Thesis or Dissertation
- YouTube Video
APA Format Citation Examples
The American Psychological Association created the APA citation style in 1929 as a way to help psychologists, anthropologists, and even business managers establish one common way to cite sources and present content.
APA is used when citing sources for academic articles such as journals, and is intended to help readers better comprehend content, and to avoid language bias wherever possible. The APA style (or APA format ) is now in its 7th edition, and provides citation style guides for virtually any type of resource.
Chicago Style Citation Examples
The Chicago/Turabian style of citing sources is generally used when citing sources for humanities papers, and is best known for its requirement that writers place bibliographic citations at the bottom of a page (in Chicago-format footnotes ) or at the end of a paper (endnotes).
The Turabian and Chicago citation styles are almost identical, but the Turabian style is geared towards student published papers such as theses and dissertations, while the Chicago style provides guidelines for all types of publications. This is why you’ll commonly see Chicago style and Turabian style presented together. The Chicago Manual of Style is currently in its 17th edition, and Turabian’s A Manual for Writers of Research Papers, Theses, and Dissertations is in its 8th edition.
Citing Specific Sources or Events
- Declaration of Independence
- Gettysburg Address
- Martin Luther King Jr. Speech
- President Obama’s Farewell Address
- President Trump’s Inauguration Speech
- White House Press Briefing
Additional FAQs
- Citing Archived Contributors
- Citing a Blog
- Citing a Book Chapter
- Citing a Source in a Foreign Language
- Citing an Image
- Citing a Song
- Citing Special Contributors
- Citing a Translated Article
- Citing a Tweet
6 Interesting Citation Facts
The world of citations may seem cut and dry, but there’s more to them than just specific capitalization rules, MLA in-text citations , and other formatting specifications. Citations have been helping researches document their sources for hundreds of years, and are a great way to learn more about a particular subject area.
Ever wonder what sets all the different styles apart, or how they came to be in the first place? Read on for some interesting facts about citations!
1. There are Over 7,000 Different Citation Styles
You may be familiar with MLA and APA citation styles, but there are actually thousands of citation styles used for all different academic disciplines all across the world. Deciding which one to use can be difficult, so be sure to ask you instructor which one you should be using for your next paper.
2. Some Citation Styles are Named After People
While a majority of citation styles are named for the specific organizations that publish them (i.e. APA is published by the American Psychological Association, and MLA format is named for the Modern Language Association), some are actually named after individuals. The most well-known example of this is perhaps Turabian style, named for Kate L. Turabian, an American educator and writer. She developed this style as a condensed version of the Chicago Manual of Style in order to present a more concise set of rules to students.
3. There are Some Really Specific and Uniquely Named Citation Styles
How specific can citation styles get? The answer is very. For example, the “Flavour and Fragrance Journal” style is based on a bimonthly, peer-reviewed scientific journal published since 1985 by John Wiley & Sons. It publishes original research articles, reviews and special reports on all aspects of flavor and fragrance. Another example is “Nordic Pulp and Paper Research,” a style used by an international scientific magazine covering science and technology for the areas of wood or bio-mass constituents.
4. More citations were created on EasyBib.com in the first quarter of 2018 than there are people in California.
The US Census Bureau estimates that approximately 39.5 million people live in the state of California. Meanwhile, about 43 million citations were made on EasyBib from January to March of 2018. That’s a lot of citations.
5. “Citations” is a Word With a Long History
The word “citations” can be traced back literally thousands of years to the Latin word “citare” meaning “to summon, urge, call; put in sudden motion, call forward; rouse, excite.” The word then took on its more modern meaning and relevance to writing papers in the 1600s, where it became known as the “act of citing or quoting a passage from a book, etc.”
6. Citation Styles are Always Changing
The concept of citations always stays the same. It is a means of preventing plagiarism and demonstrating where you relied on outside sources. The specific style rules, however, can and do change regularly. For example, in 2018 alone, 46 new citation styles were introduced , and 106 updates were made to exiting styles. At EasyBib, we are always on the lookout for ways to improve our styles and opportunities to add new ones to our list.
Why Citations Matter
Here are the ways accurate citations can help your students achieve academic success, and how you can answer the dreaded question, “why should I cite my sources?”
They Give Credit to the Right People
Citing their sources makes sure that the reader can differentiate the student’s original thoughts from those of other researchers. Not only does this make sure that the sources they use receive proper credit for their work, it ensures that the student receives deserved recognition for their unique contributions to the topic. Whether the student is citing in MLA format , APA format , or any other style, citations serve as a natural way to place a student’s work in the broader context of the subject area, and serve as an easy way to gauge their commitment to the project.
They Provide Hard Evidence of Ideas
Having many citations from a wide variety of sources related to their idea means that the student is working on a well-researched and respected subject. Citing sources that back up their claim creates room for fact-checking and further research . And, if they can cite a few sources that have the converse opinion or idea, and then demonstrate to the reader why they believe that that viewpoint is wrong by again citing credible sources, the student is well on their way to winning over the reader and cementing their point of view.
They Promote Originality and Prevent Plagiarism
The point of research projects is not to regurgitate information that can already be found elsewhere. We have Google for that! What the student’s project should aim to do is promote an original idea or a spin on an existing idea, and use reliable sources to promote that idea. Copying or directly referencing a source without proper citation can lead to not only a poor grade, but accusations of academic dishonesty. By citing their sources regularly and accurately, students can easily avoid the trap of plagiarism , and promote further research on their topic.
They Create Better Researchers
By researching sources to back up and promote their ideas, students are becoming better researchers without even knowing it! Each time a new source is read or researched, the student is becoming more engaged with the project and is developing a deeper understanding of the subject area. Proper citations demonstrate a breadth of the student’s reading and dedication to the project itself. By creating citations, students are compelled to make connections between their sources and discern research patterns. Each time they complete this process, they are helping themselves become better researchers and writers overall.
When is the Right Time to Start Making Citations?
Make in-text/parenthetical citations as you need them.
As you are writing your paper, be sure to include references within the text that correspond with references in a works cited or bibliography. These are usually called in-text citations or parenthetical citations in MLA and APA formats. The most effective time to complete these is directly after you have made your reference to another source. For instance, after writing the line from Charles Dickens’ A Tale of Two Cities : “It was the best of times, it was the worst of times…,” you would include a citation like this (depending on your chosen citation style):
(Dickens 11).
This signals to the reader that you have referenced an outside source. What’s great about this system is that the in-text citations serve as a natural list for all of the citations you have made in your paper, which will make completing the works cited page a whole lot easier. After you are done writing, all that will be left for you to do is scan your paper for these references, and then build a works cited page that includes a citation for each one.
Need help creating an MLA works cited page ? Try the MLA format generator on EasyBib.com! We also have a guide on how to format an APA reference page .
2. Understand the General Formatting Rules of Your Citation Style Before You Start Writing
While reading up on paper formatting may not sound exciting, being aware of how your paper should look early on in the paper writing process is super important. Citation styles can dictate more than just the appearance of the citations themselves, but rather can impact the layout of your paper as a whole, with specific guidelines concerning margin width, title treatment, and even font size and spacing. Knowing how to organize your paper before you start writing will ensure that you do not receive a low grade for something as trivial as forgetting a hanging indent.
Don’t know where to start? Here’s a formatting guide on APA format .
3. Double-check All of Your Outside Sources for Relevance and Trustworthiness First
Collecting outside sources that support your research and specific topic is a critical step in writing an effective paper. But before you run to the library and grab the first 20 books you can lay your hands on, keep in mind that selecting a source to include in your paper should not be taken lightly. Before you proceed with using it to backup your ideas, run a quick Internet search for it and see if other scholars in your field have written about it as well. Check to see if there are book reviews about it or peer accolades. If you spot something that seems off to you, you may want to consider leaving it out of your work. Doing this before your start making citations can save you a ton of time in the long run.
Finished with your paper? It may be time to run it through a grammar and plagiarism checker , like the one offered by EasyBib Plus. If you’re just looking to brush up on the basics, our grammar guides are ready anytime you are.
How useful was this post?
Click on a star to rate it!
We are sorry that this post was not useful for you!
Let us improve this post!
Tell us how we can improve this post?
Citation Basics
Harvard Referencing
Plagiarism Basics
Plagiarism Checker
Upload a paper to check for plagiarism against billions of sources and get advanced writing suggestions for clarity and style.
Get Started
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Referencing
- Harvard In-Text Citation | A Complete Guide & Examples
Harvard In-Text Citation | A Complete Guide & Examples
Published on 30 April 2020 by Jack Caulfield . Revised on 5 May 2022.
An in-text citation should appear wherever you quote or paraphrase a source in your writing, pointing your reader to the full reference .
In Harvard style , citations appear in brackets in the text. An in-text citation consists of the last name of the author, the year of publication, and a page number if relevant.
Up to three authors are included in Harvard in-text citations. If there are four or more authors, the citation is shortened with et al .
| 1 author | (Smith, 2014) |
|---|---|
| 2 authors | (Smith and Jones, 2014) |
| 3 authors | (Smith, Jones and Davies, 2014) |
| 4+ authors | (Smith , 2014) |
Instantly correct all language mistakes in your text
Be assured that you'll submit flawless writing. Upload your document to correct all your mistakes.

Table of contents
Including page numbers in citations, where to place harvard in-text citations, citing sources with missing information, frequently asked questions about harvard in-text citations.
When you quote directly from a source or paraphrase a specific passage, your in-text citation must include a page number to specify where the relevant passage is located.
Use ‘p.’ for a single page and ‘pp.’ for a page range:
- Meanwhile, another commentator asserts that the economy is ‘on the downturn’ (Singh, 2015, p. 13 ).
- Wilson (2015, pp. 12–14 ) makes an argument for the efficacy of the technique.
If you are summarising the general argument of a source or paraphrasing ideas that recur throughout the text, no page number is needed.
The only proofreading tool specialized in correcting academic writing
The academic proofreading tool has been trained on 1000s of academic texts and by native English editors. Making it the most accurate and reliable proofreading tool for students.

Correct my document today
When incorporating citations into your text, you can either name the author directly in the text or only include the author’s name in brackets.
Naming the author in the text
When you name the author in the sentence itself, the year and (if relevant) page number are typically given in brackets straight after the name:
Naming the author directly in your sentence is the best approach when you want to critique or comment on the source.
Naming the author in brackets
When you you haven’t mentioned the author’s name in your sentence, include it inside the brackets. The citation is generally placed after the relevant quote or paraphrase, or at the end of the sentence, before the full stop:
Multiple citations can be included in one place, listed in order of publication year and separated by semicolons:
This type of citation is useful when you want to support a claim or summarise the overall findings of sources.
Common mistakes with in-text citations
In-text citations in brackets should not appear as the subject of your sentences. Anything that’s essential to the meaning of a sentence should be written outside the brackets:
- (Smith, 2019) argues that…
- Smith (2019) argues that…
Similarly, don’t repeat the author’s name in the bracketed citation and in the sentence itself:
- As Caulfield (Caulfield, 2020) writes…
- As Caulfield (2020) writes…
Sometimes you won’t have access to all the source information you need for an in-text citation. Here’s what to do if you’re missing the publication date, author’s name, or page numbers for a source.
If a source doesn’t list a clear publication date, as is sometimes the case with online sources or historical documents, replace the date with the words ‘no date’:
When it’s not clear who the author of a source is, you’ll sometimes be able to substitute a corporate author – the group or organisation responsible for the publication:
When there’s no corporate author to cite, you can use the title of the source in place of the author’s name:
No page numbers
If you quote from a source without page numbers, such as a website, you can just omit this information if it’s a short text – it should be easy enough to find the quote without it.
If you quote from a longer source without page numbers, it’s best to find an alternate location marker, such as a paragraph number or subheading, and include that:
A Harvard in-text citation should appear in brackets every time you quote, paraphrase, or refer to information from a source.
The citation can appear immediately after the quotation or paraphrase, or at the end of the sentence. If you’re quoting, place the citation outside of the quotation marks but before any other punctuation like a comma or full stop.
In Harvard referencing, up to three author names are included in an in-text citation or reference list entry. When there are four or more authors, include only the first, followed by ‘ et al. ’
| In-text citation | Reference list | |
|---|---|---|
| 1 author | (Smith, 2014) | Smith, T. (2014) … |
| 2 authors | (Smith and Jones, 2014) | Smith, T. and Jones, F. (2014) … |
| 3 authors | (Smith, Jones and Davies, 2014) | Smith, T., Jones, F. and Davies, S. (2014) … |
| 4+ authors | (Smith , 2014) | Smith, T. (2014) … |
In Harvard style , when you quote directly from a source that includes page numbers, your in-text citation must include a page number. For example: (Smith, 2014, p. 33).
You can also include page numbers to point the reader towards a passage that you paraphrased . If you refer to the general ideas or findings of the source as a whole, you don’t need to include a page number.
When you want to use a quote but can’t access the original source, you can cite it indirectly. In the in-text citation , first mention the source you want to refer to, and then the source in which you found it. For example:
It’s advisable to avoid indirect citations wherever possible, because they suggest you don’t have full knowledge of the sources you’re citing. Only use an indirect citation if you can’t reasonably gain access to the original source.
In Harvard style referencing , to distinguish between two sources by the same author that were published in the same year, you add a different letter after the year for each source:
- (Smith, 2019a)
- (Smith, 2019b)
Add ‘a’ to the first one you cite, ‘b’ to the second, and so on. Do the same in your bibliography or reference list .
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Caulfield, J. (2022, May 05). Harvard In-Text Citation | A Complete Guide & Examples. Scribbr. Retrieved 9 June 2024, from https://www.scribbr.co.uk/referencing/harvard-in-text-citation/
Is this article helpful?

Jack Caulfield
Other students also liked, a quick guide to harvard referencing | citation examples, harvard style bibliography | format & examples, referencing books in harvard style | templates & examples, scribbr apa citation checker.
An innovative new tool that checks your APA citations with AI software. Say goodbye to inaccurate citations!

APA (7th Edition) Referencing Guide
- Information for EndNote Users
- Authors - Numbers, Rules and Formatting
Everything must match!
Types of citations, in-text citations, quoting, summarising and paraphrasing, example text with in-text referencing, slightly tricky in-text citations, organisation as an author, secondary citation (works referred to in other works), what do i do if there are no page numbers.
- Reference List
- Books & eBooks
- Book chapters
- Journal Articles
- Conference Papers
- Newspaper Articles
- Web Pages & Documents
- Specialised Health Databases
- Using Visual Works in Assignments & Class Presentations
- Using Visual Works in Theses and Publications
- Using Tables in Assignments & Class Presentations
- Custom Textbooks & Books of Readings
- ABS AND AIHW
- Videos (YouTube), Podcasts & Webinars
- Blog Posts and Social Media
- First Nations Works
- Dictionary and Encyclopedia Entries
- Personal Communication
- Theses and Dissertations
- Film / TV / DVD
- Miscellaneous (Generic Reference)
- AI software
- APA Format for Assignments
- What If...?
- Other Guides

There are two basic ways to cite someone's work in text.
In narrative citations , the authors are part of the sentence - you are referring to them by name. For example:
Becker (2013) defined gamification as giving the mechanics of principles of a game to other activities.
Cho and Castañeda (2019) noted that game-like activities are frequently used in language classes that adopt mobile and computer technologies.
In parenthetical citations , the authors are not mentioned in the sentence, just the content of their work. Place the citation at the end of the sentence or clause where you have used their information. The author's names are placed in the brackets (parentheses) with the rest of the citation details:
Gamification involves giving the mechanics or principles of a game to another activity (Becker, 2013).
Increasingly, game-like activities are frequently used in language classes that adopt mobile and computer technologies (Cho & Castañeda, 2019).
Using references in text
For APA, you use the authors' surnames only and the year in text. If you are using a direct quote, you will also need to use a page number.
Narrative citations:
If an in-text citation has the authors' names as part of the sentence (that is, outside of brackets) place the year and page numbers in brackets immediately after the name, and use 'and' between the authors' names: Jones and Smith (2020, p. 29)
Parenthetical citations:
If an in-text citation has the authors' names in brackets use "&" between the authors' names : (Jones & Smith, 2020, p. 29).
Note: Some lecturers want page numbers for all citations, while some only want page numbers with direct quotes. Check with your lecturer to see what you need to do for your assignment. If the direct quote starts on one page and finishes on another, include the page range (Jones & Smith, 2020, pp. 29-30).
1 author
Smith (2020) found that "the mice disappeared within minutes" (p. 29).
The author stated "the mice disappeared within minutes" (Smith, 2020, p. 29).
Jones and Smith (2020) found that "the mice disappeared within minutes" (p. 29).
The authors stated "the mice disappeared within minutes" (Jones & Smith, 2020, p. 29).
For 3 or more authors , use the first author and "et al." for all in-text citations
Green et al.'s (2019) findings indicated that the intervention was not based on evidence from clinical trials.
It appears the intervention was not based on evidence from clinical trials (Green et al., 2019).
If you cite more than one work in the same set of brackets in text , your citations will go in the same order in which they will appear in your reference list (i.e. alphabetical order, then oldest to newest for works by the same author) and be separated by a semi-colon. E.g.:
- (Corbin, 2015; James & Waterson, 2017; Smith et al., 2016).
- (Corbin, 2015; 2018)
- (Queensland Health, 2017a; 2017b)
- Use only the surnames of your authors in text (e.g., Smith & Brown, 2014) - however, if you have two authors with the same surname who have published in the same year, then you will need to use their initials to distinguish between the two of them (e.g., K. Smith, 2014; N. Smith, 2014). Otherwise, do not use initials in text .
If your author isn't an "author".
Whoever is in the "author" position of the refence in the references list is treated like an author in text. So, for example, if you had an edited book and the editors of the book were in the "author" position at the beginning of the reference, you would treat them exactly the same way as you would an author - do not include any other information. The same applies for works where the "author" is an illustrator, producer, composer, etc.
- Summarising
- Paraphrasing

It is always a good idea to keep direct quotes to a minimum. Quoting doesn't showcase your writing ability - all it shows is that you can read (plus, lecturers hate reading assignments with a lot of quotes).
You should only use direct quotes if the exact wording is important , otherwise it is better to paraphrase.
If you feel a direct quote is appropriate, try to keep only the most important part of the quote and avoid letting it take up the entire sentence - always start or end the sentence with your own words to tie the quote back into your assignment. Long quotes (more than 40 words) are called "block quotes" and are rarely used in most subject areas (they mostly belong in Literature, History or similar subjects). Each referencing style has rules for setting out a block quote. Check with your style guide .
It has been observed that "pink fairy armadillos seem to be extremely susceptible to stress" (Superina, 2011, p. 6).
NB! Most referencing styles will require a page number to tell readers where to find the original quote.

It is a type of paraphrasing, and you will be using this frequently in your assignments, but note that summarising another person's work or argument isn't showing how you make connections or understand implications. This is preferred to quoting, but where possible try to go beyond simply summarising another person's information without "adding value".
And, remember, the words must be your own words . If you use the exact wording from the original at any time, those words must be treated as a direct quote.
All information must be cited, even if it is in your own words.
Superina (2011) observed a captive pink fairy armadillo, and noticed any variation in its environment could cause great stress.
NB! Some lecturers and citation styles want page numbers for everything you cite, others only want page numbers for direct quotes. Check with your lecturer.
Paraphrasing often involves commenting about the information at the same time, and this is where you can really show your understanding of the topic. You should try to do this within every paragraph in the body of your assignment.
When paraphrasing, it is important to remember that using a thesaurus to change every other word isn't really paraphrasing. It's patchwriting , and it's a kind of plagiarism (as you are not creating original work).
Use your own voice! You sound like you when you write - you have a distinctive style that is all your own, and when your "tone" suddenly changes for a section of your assignment, it looks highly suspicious. Your lecturer starts to wonder if you really wrote that part yourself. Make sure you have genuinely thought about how *you* would write this information, and that the paraphrasing really is in your own words.
Always cite your sources! Even if you have drawn from three different papers to write this one sentence, which is completely in your own words, you still have to cite your sources for that sentence (oh, and excellent work, by the way).
Captive pink fairy armadillos do not respond well to changes in their environment and can be easily stressed (Superina, 2011).
NB! Some lecturers and citation styles want page numbers for all citations, others only want them for direct quotes. Check with your lecturer.
This example paragraph contains mouse-over text. Run your mouse over the paragraph to see notes on formatting.
Excerpt from "The Big Fake Essay"
You can read the entire Big Fake Essay on the Writing Guide. It includes more details about academic writing and the formatting of essays.
- The Big Fake Essay
- Academic Writing Workshop
When you have multiple authors with the same surname who published in the same year:
If your authors have different initials, then include the initials:
As A. Smith (2016) noted...
...which was confirmed by J.G. Smith's (2016) study.
(A. Smith, 2016; J. G. Smith, 2016).
If your authors have the same initials, then include the name:
As Adam Smith noted...
...which was confirmed by Amy Smith's (2016) study.
(Adam Smith, 2016; Amy Smith, 2016).
Note: In your reference list, you would include the author's first name in [square brackets] after their initials:
Smith, A. [Adam]. (2016)...
Smith, A. [Amy]. (2016)...
When you have multiple works by the same author in the same year:
In your reference list, you will have arranged the works alphabetically by title (see the page on Reference Lists for more information). This decides which reference is "a", "b", "c", and so on. You cite them in text accordingly:
Asthma is the most common disease affecting the Queensland population (Queensland Health, 2017b). However, many people do not know how to manage their asthma symptoms (Queensland Health, 2017a).
When you have multiple works by the same author in different years:
Asthma is the most common disease affecting the Queensland population (Queensland Health, 2017, 2018).
When you do not have an author, and your reference list entry begins with the title:
Use the title in place of the author's name, and place it in "quotation marks" if it is the title of an article or book chapter, or in italics if the title would go in italics in your reference list:
During the 2017 presidential inauguration, there were some moments of awkwardness ("Mrs. Obama Says ‘Lovely Frame’", 2018).
Note: You do not need to use the entire title, but a reasonable portion so that it does not end too abruptly - "Mrs. Obama Says" would be too abrupt, but the full title "Mrs. Obama Says 'Lovely Frame' in Box During Awkward Handoff" is unecessarily long. You should also use title case for titles when referring to them in the text of your work.
If there are no page numbers, you can include any of the following in the in-text citation:
- "On Australia Day 1938 William Cooper ... joined forces with Jack Patten and William Ferguson ... to hold a Day of Mourning to draw attention to the losses suffered by Aboriginal people at the hands of the whiteman" (National Museum of Australia, n.d., para. 4).
- "in 1957 news of a report by the Western Australian government provided the catalyst for a reform movement" (National Museum of Australia, n.d., The catalyst for change section, para. 1)
- "By the end of this year of intense activity over 100,000 signatures had been collected" (National Museum of Australia, n.d., "petition gathering", para. 1).
When you are citing a classical work, like the Bible or the Quran:
References to works of scripture or other classical works are treated differently to regular citations. See the APA Blog's entry for more details:
Happy Holiday Citing: Citation of Classical Works . (Please note, this document is from the 6th edition of APA).
In text citation:
If the name of the organisation first appears in a narrative citation, include the abbreviation before the year in brackets, separated with a comma. Use the official acronym/abreviation if you can find it. Otherwise check with your lecturer for permission to create your own acronyms.
Australian Bureau of Statistics (ABS, 2013) shows that...
The Queensland Department of Education (DoE, 2020) encourages students to... (please note, Queensland isn't part of the department's name, it is used in the sentence to provide clarity)
If the name of the organisation first appears in a citation in brackets, include the abbreviation in square brackets.
(Australian Bureau of Statistics [ABS], 2013)
(Department of Education [DoE], 2020)
In the second and subsequent citations, only include the abbreviation or acronym
ABS (2013) found that ...
DoE (2020) instructs teachers to...
This is disputed ( ABS , 2013).
Resources are designed to support "emotional learning pedagogy" (DoE, 2020)
In the reference list:
Use the full name of the organisation in the reference list.
Australian Institute of Health and Welfare. (2017). Australia's welfare 2017 . https://www.aihw.gov.au/reports/australias-welfare/australias-welfare-2017/contents/table-of-contents
Department of Education. (2020, April 22). Respectful relationships education program . Queensland Government. https://education.qld.gov.au/curriculum/stages-of-schooling/respectful-relationships
Academically, it is better to find the original source and reference that.
If you do have to quote a secondary source:
- In the text you must cite the original author of the quote and the year the original quote was written as well as the source you read it in. If you do not know the year the original citation was written, omit the year.
- In the reference list you only list the source that you actually read.
Wembley (1997, as cited in Olsen, 1999) argues that impending fuel shortages ...
Wembley claimed that "fuel shortages are likely" (1997, as cited in Olsen, 1999, pp. 10-12).
Some have noted that fuel shortages are probable in the future (Wembley, 1997, as cited in Olsen, 1999).
Olsen, M. (1999). My career. Gallimard.
- << Previous: Dates
- Next: Reference List >>
- Last Updated: May 22, 2024 11:40 AM
- URL: https://libguides.jcu.edu.au/apa

Essay Writing: In-Text Citations
- Essay Writing Basics
- Purdue OWL Page on Writing Your Thesis This link opens in a new window
- Paragraphs and Transitions
- How to Tell if a Website is Legitimate This link opens in a new window
- Formatting Your References Page
- Cite a Website
- Common Grammatical and Mechanical Errors
- Additional Resources
- Proofread Before You Submit Your Paper
- Structuring the 5-Paragraph Essay
In-text Citations
What are In-Text Citations?
You must cite (give credit) all information sources used in your essay or research paper whenever and wherever you use them.
When citing sources in the text of your paper, you must list:
● The author’s last name
● The year the information was published.
Types of In-Text Citations: Narrative vs Parenthetical
A narrative citation gives the author's name as part of the sentence .
- Example of a Narrative Citation: According to Edwards (2017) , a lthough Smith and Carlos's protest at the 1968 Olympics initially drew widespread criticism, it also led to fundamental reforms in the organizational structure of American amateur athletics.
A parenthetical citation puts the source information in parentheses—first or last—but does not include it in the narrative flow.
- Example of a Parenthetical Citation: Although Tommie Smith and John Carlos paid a heavy price in the immediate aftermath of the protests, they were later vindicated by society at large (Edwards, 2017) .
Full citation for this source (this belongs on the Reference Page of your research paper or essay):
Edwards, H. (2017). The Revolt of the Black Athlete: 50th Anniversary Edition. University of Illinois Press.
Sample In-text Citations
| Studies have shown music and art therapies to be effective in aiding those dealing with mental disorders as well as managing, exploring, and gaining insight into traumatic experiences their patients may have faced. (Stuckey & Nobel, 2010). |
| - FIRST INITIAL, ARTICLE TITLE -- |
| Hint: (Use an when they appear in parenthetical citations.) e.g.: (Jones & Smith, 2022) |
| Stuckey and Nobel (2010) noted, "it has been shown that music can calm neural activity in the brain, which may lead to reductions in anxiety, and that it may help to restore effective functioning in the immune system." |
|
|
Note: This example is a direct quote. It is an exact quotation directly from the text of the article. All direct quotes should appear in quotation marks: "...."
Try keeping direct quotes to a minimum in your writing. You need to show your understanding of the source material by being able to paraphrase or summarize it.
List the author’s last name only (no initials) and the year the information was published, like this:
(Dodge, 2008 ). ( Author , Date).
IF you use a direct quote, add the page number to your citation, like this:
( Dodge , 2008 , p. 125 ).
( Author , Date , page number )
What information should I cite in my paper/essay?
Credit these sources when you mention their information in any way: direct quotation, paraphrase, or summarize.
What should you credit?
Any information that you learned from another source, including:
● statistics
EXCEPTION: Information that is common knowledge: e.g., The Bronx is a borough of New York City.
Quick Sheet: APA 7 Citations
Quick help with apa 7 citations.
- Quick Sheet - Citing Journal Articles, Websites & Videos, and Creating In-Text Citations A quick guide to the most frequently-used types of APA 7 citations.
In-text Citation Tutorial
- Formatting In-text Citations, Full Citations, and Block Quotes In APA 7 Style This presentation will help you understand when, why, and how to use in-text citations in your APA style paper.
Download the In-text Citations presentation (above) for an in-depth look at how to correctly cite your sources in the text of your paper.
SIgnal Phrase Activity
Paraphrasing activity from the excelsior owl, in-text citation quiz.
- << Previous: Formatting Your References Page
- Next: Cite a Website >>
- Last Updated: May 23, 2024 11:09 AM
- URL: https://monroecollege.libguides.com/essaywriting
- Research Guides |
- Databases |
- PRO Courses Guides New Tech Help Pro Expert Videos About wikiHow Pro Upgrade Sign In
- EDIT Edit this Article
- EXPLORE Tech Help Pro About Us Random Article Quizzes Request a New Article Community Dashboard This Or That Game Popular Categories Arts and Entertainment Artwork Books Movies Computers and Electronics Computers Phone Skills Technology Hacks Health Men's Health Mental Health Women's Health Relationships Dating Love Relationship Issues Hobbies and Crafts Crafts Drawing Games Education & Communication Communication Skills Personal Development Studying Personal Care and Style Fashion Hair Care Personal Hygiene Youth Personal Care School Stuff Dating All Categories Arts and Entertainment Finance and Business Home and Garden Relationship Quizzes Cars & Other Vehicles Food and Entertaining Personal Care and Style Sports and Fitness Computers and Electronics Health Pets and Animals Travel Education & Communication Hobbies and Crafts Philosophy and Religion Work World Family Life Holidays and Traditions Relationships Youth
- Browse Articles
- Learn Something New
- Quizzes Hot
- This Or That Game
- Train Your Brain
- Explore More
- Support wikiHow
- About wikiHow
- Log in / Sign up
- Education and Communications
- College University and Postgraduate
- Academic Writing
How to Cite an Essay
Last Updated: February 4, 2023 Fact Checked
This article was co-authored by Diya Chaudhuri, PhD and by wikiHow staff writer, Jennifer Mueller, JD . Diya Chaudhuri holds a PhD in Creative Writing (specializing in Poetry) from Georgia State University. She has over 5 years of experience as a writing tutor and instructor for both the University of Florida and Georgia State University. There are 10 references cited in this article, which can be found at the bottom of the page. This article has been fact-checked, ensuring the accuracy of any cited facts and confirming the authority of its sources. This article has been viewed 558,576 times.
If you're writing a research paper, whether as a student or a professional researcher, you might want to use an essay as a source. You'll typically find essays published in another source, such as an edited book or collection. When you discuss or quote from the essay in your paper, use an in-text citation to relate back to the full entry listed in your list of references at the end of your paper. While the information in the full reference entry is basically the same, the format differs depending on whether you're using the Modern Language Association (MLA), American Psychological Association (APA), or Chicago citation method.
Template and Examples

- Example: Potter, Harry.

- Example: Potter, Harry. "My Life with Voldemort."

- Example: Potter, Harry. "My Life with Voldemort." Great Thoughts from Hogwarts Alumni , by Bathilda Backshot,

- Example: Potter, Harry. "My Life with Voldemort." Great Thoughts from Hogwarts Alumni , by Bathilda Backshot, Hogwarts Press, 2019,

- Example: Potter, Harry. "My Life with Voldemort." Great Thoughts from Hogwarts Alumni , by Bathilda Backshot, Hogwarts Press, 2019, pp. 22-42.
MLA Works Cited Entry Format:
LastName, FirstName. "Title of Essay." Title of Collection , by FirstName Last Name, Publisher, Year, pp. ##-##.

- For example, you might write: While the stories may seem like great adventures, the students themselves were terribly frightened to confront Voldemort (Potter 28).
- If you include the author's name in the text of your paper, you only need the page number where the referenced material can be found in the parenthetical at the end of your sentence.
- If you have several authors with the same last name, include each author's first initial in your in-text citation to differentiate them.
- For several titles by the same author, include a shortened version of the title after the author's name (if the title isn't mentioned in your text).

- Example: Granger, H.

- Example: Granger, H. (2018).

- Example: Granger, H. (2018). Adventures in time turning.

- Example: Granger, H. (2018). Adventures in time turning. In M. McGonagall (Ed.), Reflections on my time at Hogwarts

- Example: Granger, H. (2018). Adventures in time turning. In M. McGonagall (Ed.), Reflections on my time at Hogwarts (pp. 92-130). Hogwarts Press.
APA Reference List Entry Format:
LastName, I. (Year). Title of essay. In I. LastName (Ed.), Title of larger work (pp. ##-##). Publisher.

- For example, you might write: By using a time turner, a witch or wizard can appear to others as though they are actually in two places at once (Granger, 2018).
- If you use the author's name in the text of your paper, include the parenthetical with the year immediately after the author's name. For example, you might write: Although technically against the rules, Granger (2018) maintains that her use of a time turner was sanctioned by the head of her house.
- Add page numbers if you quote directly from the source. Simply add a comma after the year, then type the page number or page range where the quoted material can be found, using the abbreviation "p." for a single page or "pp." for a range of pages.

- Example: Weasley, Ron.

- Example: Weasley, Ron. "Best Friend to a Hero."

- Example: Weasley, Ron. "Best Friend to a Hero." In Harry Potter: Wizard, Myth, Legend , edited by Xenophilius Lovegood, 80-92.

- Example: Weasley, Ron. "Best Friend to a Hero." In Harry Potter: Wizard, Myth, Legend , edited by Xenophilius Lovegood, 80-92. Ottery St. Catchpole: Quibbler Books, 2018.
' Chicago Bibliography Format:
LastName, FirstName. "Title of Essay." In Title of Book or Essay Collection , edited by FirstName LastName, ##-##. Location: Publisher, Year.

- Example: Ron Weasley, "Best Friend to a Hero," in Harry Potter: Wizard, Myth, Legend , edited by Xenophilius Lovegood, 80-92 (Ottery St. Catchpole: Quibbler Books, 2018).
- After the first footnote, use a shortened footnote format that includes only the author's last name, the title of the essay, and the page number or page range where the referenced material appears.
Tip: If you use the Chicago author-date system for in-text citation, use the same in-text citation method as APA style.
Community Q&A

You Might Also Like

- ↑ https://style.mla.org/essay-in-authored-textbook/
- ↑ https://owl.purdue.edu/owl/research_and_citation/mla_style/mla_formatting_and_style_guide/mla_works_cited_page_books.html
- ↑ https://utica.libguides.com/c.php?g=703243&p=4991646
- ↑ https://owl.purdue.edu/owl/research_and_citation/mla_style/mla_formatting_and_style_guide/mla_in_text_citations_the_basics.html
- ↑ https://guides.libraries.psu.edu/apaquickguide/intext
- ↑ https://guides.himmelfarb.gwu.edu/c.php?g=27779&p=170363
- ↑ https://owl.purdue.edu/owl/research_and_citation/apa_style/apa_formatting_and_style_guide/in_text_citations_the_basics.html
- ↑ http://libguides.heidelberg.edu/chicago/book/chapter
- ↑ https://librarybestbets.fairfield.edu/citationguides/chicagonotes-bibliography#CollectionofEssays
- ↑ https://libguides.heidelberg.edu/chicago/book/chapter
About This Article

To cite an essay using MLA format, include the name of the author and the page number of the source you’re citing in the in-text citation. For example, if you’re referencing page 123 from a book by John Smith, you would include “(Smith 123)” at the end of the sentence. Alternatively, include the information as part of the sentence, such as “Rathore and Chauhan determined that Himalayan brown bears eat both plants and animals (6652).” Then, make sure that all your in-text citations match the sources in your Works Cited list. For more advice from our Creative Writing reviewer, including how to cite an essay in APA or Chicago Style, keep reading. Did this summary help you? Yes No
- Send fan mail to authors
Reader Success Stories
Mbarek Oukhouya
Mar 7, 2017
Did this article help you?
Sarah Sandy
May 25, 2017
Skyy DeRouge
Nov 14, 2021
Diana Ordaz
Sep 25, 2016

Featured Articles

Trending Articles

Watch Articles

- Terms of Use
- Privacy Policy
- Do Not Sell or Share My Info
- Not Selling Info
wikiHow Tech Help Pro:
Develop the tech skills you need for work and life
APA Citation Style 7th Edition: Welcome
- Advertisements
- Books & eBooks
- Book Reviews
- Class Handouts, Presentations, and Readings
- Encyclopedias & Dictionaries
- Government Documents
- Images, Charts, Graphs, Maps & Tables
- Journal Articles
- Magazine Articles
- Newspaper Articles
- Personal Communication (Interviews, Emails)
- Social Media
- Videos & DVDs
- Paraphrasing
- No Author, No Date etc.
- Sample Papers
- Annotated Bibliography
What is APA?
APA style was created by the American Psychological Association. It is a set of rules for publications, including research papers.
In APA, you must "cite" sources that you have paraphrased, quoted or otherwise used to write your research paper. Cite your sources in two places:
- In the body of your paper where you add a brief in-text citation.
- In the Reference list at the end of your paper where you give more complete information for the source.
Acknowledgement
What's new in the 7th edition of apa.
Below is a summary of the major changes in the 7th edition of the APA Publication Manual.
Essay Format:
- Font - While you still can use Times New Roman 12, you are free to use other fonts. Calibri 11, Arial 11, Lucida Sans 10, and Georgia 11 are all acceptable.
- Headers - No running headers are required for student papers.
- Tables and Figures - There is a standardized format for both tables and figures.
Style, Grammar, Usage:
- Singular "they" required in two situations: when used by a known person as their personal pronoun or when the gender of a singular person is not known.
- Use only one space after a sentence-ending period.
Citation Style:
- Developed the 'Four Elements of a Reference" (Author, Date, Title, Source) to help writers to create references for source types not explicitly examined in the APA Manual.
- Three or more authors can be abbreviated to First author, et al. on the first citation.
- Up to 20 authors are spelled out in the References List.
- Publisher location is not required for books
- Ebook platform, format, or device is not required for eBooks.
- Library database names are generally not required
- No "doi:" prefix, simply include the doi.
- All hyperlinks retain the https://
- Links can be "live" in blue with underline or black without underlining
Commonly Used Terms
Citing : The process of acknowledging the sources of your information and ideas.
DOI (doi) : Some electronic content, such as online journal articles, is assigned a unique number called a Digital Object Identifier (DOI or doi). Items can be tracked down online using their doi.
In-Text Citation : A brief note at the point where information is used from a source to indicate where the information came from. An in-text citation should always match more detailed information that is available in the Reference List.
Paraphrasing : Taking information that you have read and putting it into your own words.
Plagiarism : Taking, using, and passing off as your own, the ideas or words of another.
Quoting : The copying of words of text originally published elsewhere. Direct quotations generally appear in quotation marks and end with a citation.
Reference : Details about one cited source.
Reference List : Contains details on ALL the sources cited in a text or essay, and supports your research and/or premise.
Retrieval Date : Used for websites where content is likely to change over time (e.g. Wikis), the retrieval date refers to the date you last visited the website.
- Next: How Do I Cite? >>
- Last Updated: Apr 8, 2024 4:30 PM
- URL: https://libguides.msubillings.edu/apa7
MLA In-text Citations and Sample Essay 9th Edition
Listing your sources at the end of your essay in the Works Cited is only the first step in complete and effective documentation. Proper citation of sources is a two-part process . You must also cite, in the body of your essay, the source your paraphrased information or where directly quoted material came from. These citations within the essay are called in-text citations . You must cite all quoted, paraphrased, or summarized words, ideas, and facts from sources. Without in-text citations, you are in danger of plagiarism , even if you have listed your sources at the end of the essay. In-text citations point the reader to the sources’ information in the works cited page, so the in-text citation should be the first item listed in the source’s citation on the works cited page, which is usually the author’s last name (or the title if there is no author) and the page number, if provided.
Two Ways to Cite Your Sources In-text
Parenthetical citation.
Cite your source in parentheses at the end of quoted or paraphrased material.
Example with a page number: In regards to paraphrasing, "It is important to remember to use in-text citations for your paraphrased information, as well as your directly quoted material" (Habib 7).
Example without a page number : Paraphrasing is "often the best choice because direct quotes should be reserved for source material that is especially well-written in style and/or clarity" (Ruiz).
Signal Phrase
Within the sentence, through the use of a "signal phrase" which signals to the reader the specific source the idea or quote came from. Include the page number(s) in parentheses at the end of the sentence, if provided.
Example with a page number: According to Habib, "It is important to remember to use in-text citations for your paraphrased information, as well as your directly quoted material" (7).
Example without a page number: According to Ruiz, paraphrasing is "often the best choice because direct quotes should be reserved for source material that is especially well-written in style and/or clarity."
*See our handout "Signal Phrases" for more examples and information on effective ways to use signal phrases for in-text citations.
Do you need to include a page number in your in-text citation?
Printed materials such as books, magazines, journals, or internet and digital sources with PDF files that show an actual printed page number need to have a page number in the citation.
Internet and digital sources with a continuously scrolling page without a page number do not need a page number in the citation.
Commonly used in-text citations in parentheses
| Type of Source | Parenthetical In-text Citation |
|---|---|
| One author with page number | (Blake 70) |
| One author with multiple works | (Harris, 13-14) |
| Two authors, no page number | (McGrath and Dowd) |
| Three or more authors with page number | (Gooden et al. 445) |
| No author, no page number | ("Cheating")[First word(s) of the title of the article] |
| Two sources each with one author and page number | (Jones 42; Haller 57) |
| A person quoted in another work | (qtd. in Lathrop and Foss 163) |
| Video or audio sources | ("Across the Divide" 00:06:25) |
| Government source | (Center for Disease Control and Prevention) |
Notes on Quotes
Block quotation format.
When using long quotations that are over four lines of prose or over three lines of poetry in length, you will need to use block quotation format. Block format is indented one inch from the margin (you can hit the "tab" button twice to move it one inch). Additionally, block quotes do not use quotation marks, and the parenthetical citation comes after the period of the last sentence. Please see the following sample essay for an example block quote.
Signal Phrase Examples and Ideas
Please see the following sample essay for different kinds of signal phrases and parenthetical in-text citations, which correspond with the sample Works Cited page at the end. The Writing Center also has a handout on signal phrases with many different verb options.
Learn more about the MLA Works Cited page by reviewing this handout .
For information on STLCC's academic integrity policy, check out this website .
- Free Tools for Students
- APA Citation Generator
Free APA Citation Generator
Generate citations in APA format quickly and automatically, with MyBib!

🤔 What is an APA Citation Generator?
An APA citation generator is a software tool that will automatically format academic citations in the American Psychological Association (APA) style.
It will usually request vital details about a source -- like the authors, title, and publish date -- and will output these details with the correct punctuation and layout required by the official APA style guide.
Formatted citations created by a generator can be copied into the bibliography of an academic paper as a way to give credit to the sources referenced in the main body of the paper.
👩🎓 Who uses an APA Citation Generator?
College-level and post-graduate students are most likely to use an APA citation generator, because APA style is the most favored style at these learning levels. Before college, in middle and high school, MLA style is more likely to be used. In other parts of the world styles such as Harvard (UK and Australia) and DIN 1505 (Europe) are used more often.
🙌 Why should I use a Citation Generator?
Like almost every other citation style, APA style can be cryptic and hard to understand when formatting citations. Citations can take an unreasonable amount of time to format manually, and it is easy to accidentally include errors. By using a citation generator to do this work you will:
- Save a considerable amount of time
- Ensure that your citations are consistent and formatted correctly
- Be rewarded with a higher grade
In academia, bibliographies are graded on their accuracy against the official APA rulebook, so it is important for students to ensure their citations are formatted correctly. Special attention should also be given to ensure the entire document (including main body) is structured according to the APA guidelines. Our complete APA format guide has everything you need know to make sure you get it right (including examples and diagrams).
⚙️ How do I use MyBib's APA Citation Generator?
Our APA generator was built with a focus on simplicity and speed. To generate a formatted reference list or bibliography just follow these steps:
- Start by searching for the source you want to cite in the search box at the top of the page.
- MyBib will automatically locate all the required information. If any is missing you can add it yourself.
- Your citation will be generated correctly with the information provided and added to your bibliography.
- Repeat for each citation, then download the formatted list and append it to the end of your paper.
MyBib supports the following for APA style:
| ⚙️ Styles | APA 6 & APA 7 |
|---|---|
| 📚 Sources | Websites, books, journals, newspapers |
| 🔎 Autocite | Yes |
| 📥 Download to | Microsoft Word, Google Docs |

Daniel is a qualified librarian, former teacher, and citation expert. He has been contributing to MyBib since 2018.
- Plagiarism and grammar
- Citation guides
Cite a Website
Don't let plagiarism errors spoil your paper, citing a website in apa.
Once you’ve identified a credible website to use, create a citation and begin building your reference list. Citation Machine citing tools can help you create references for online news articles, government websites, blogs, and many other website! Keeping track of sources as you research and write can help you stay organized and ethical. If you end up not using a source, you can easily delete it from your bibliography. Ready to create a citation? Enter the website’s URL into the search box above. You’ll get a list of results, so you can identify and choose the correct source you want to cite. It’s that easy to begin!
If you’re wondering how to cite a website in APA, use the structure below.
Author Last Name, First initial. (Year, Month Date Published). Title of web page . Name of Website. URL
Example of an APA format website:
Austerlitz, S. (2015, March 3). How long can a spinoff like ‘Better Call Saul’ last? FiveThirtyEight. http://fivethirtyeight.com/features/how-long-can-a-spinoff-like-better-call-saul-last/
Keep in mind that not all information found on a website follows the structure above. Only use the Website format above if your online source does not fit another source category. For example, if you’re looking at a video on YouTube, refer to the ‘YouTube Video’ section. If you’re citing a newspaper article found online, refer to ‘Newspapers Found Online’ section. Again, an APA website citation is strictly for web pages that do not fit better with one of the other categories on this page.
Social media:
When adding the text of a post, keep the original capitalization, spelling, hashtags, emojis (if possible), and links within the text.
Facebook posts:
Structure: Facebook user’s Last name, F. M. (Year, Monday Day of Post). Up to the first 20 words of Facebook post [Source type if attached] [Post type]. Facebook. URL
Source type examples: [Video attached], [Image attached]
Post type examples: [Status update], [Video], [Image], [Infographic]
Gomez, S. (2020, February 4). Guys, I’ve been working on this special project for two years and can officially say Rare Beauty is launching in [Video]. Facebook. https://www.facebook.com/Selena/videos/1340031502835436/
Life at Chegg. (2020, February 7) It breaks our heart that 50% of college students right here in Silicon Valley are hungry. That’s why Chegg has [Images attached] [Status update]. Facebook. https://www.facebook.com/LifeAtChegg/posts/1076718522691591
Twitter posts:
Structure: Account holder’s Last name, F. M. [Twitter Handle]. (Year, Month Day of Post). Up to the first 20 words of tweet [source type if attached] [Tweet]. Twitter. URL
Source type examples: [Video attached], [Image attached], [Poll attached]
Example: Edelman, J. [Edelman11]. (2018, April 26). Nine years ago today my life changed forever. New England took a chance on a long shot and I’ve worked [Video attached] [Tweet]. Twitter. https://twitter.com/Edelman11/status/989652345922473985
Instagram posts:
APA citation format: Account holder’s Last name, F. M. [@Instagram handle]. (Year, Month Day). Up to the first 20 words of caption [Photograph(s) and/or Video(s)]. Instagram. URL
Example: Portman, N. [@natalieportman]. (2019, January 5). Many of my best experiences last year were getting to listen to and learn from so many incredible people through [Videos]. Instagram. https://www.instagram.com/p/BsRD-FBB8HI/?utm_source=ig_web_copy_link
If this guide hasn’t helped solve all of your referencing questions, or if you’re still feeling the need to type “how to cite a website APA” into Google, then check out our APA citation generator on CitationMachine.com, which can build your references for you!
Featured links:
APA Citation Generator | Website | Books | Journal Articles | YouTube | Images | Movies | Interview | PDF
- Citation Machine® Plus
- Citation Guides
- Chicago Style
- Harvard Referencing
- Terms of Use
- Global Privacy Policy
- Cookie Notice
- DO NOT SELL MY INFO
Clip Art or Stock Image References
There are special requirements for using clip art and stock images in APA Style papers.
Common sources for stock images and clip art are iStock, Getty Images, Adobe Stock, Shutterstock, Pixabay, and Flickr. Common sources for clip art are Microsoft Word and Microsoft PowerPoint.
The license associated with the clip art or stock image determines how it should be credited.
- Sometimes the license indicates no reference or attribution is needed, in which case writers can reproduce the image without any reference, citation, or attribution in an APA Style paper.
- Other times, the license indicates that credit is required to reproduce the image, in which case writers should write an APA Style copyright attribution and reference list entry.
Follow the terms of the license associated with the image you want to reproduce. The guidelines apply regardless of whether the image costs money to purchase or is available for free. The guidelines also apply to both students and professionals and to both papers and PowerPoint presentations.
Although for most images you must look at the license on a case-by-case basis, images and clip art from programs such as Microsoft Word and Microsoft PowerPoint can be used without attribution. By purchasing the program, you have purchased a license to use the clip art and images that come with the program without attribution.
This page contains examples for clip art or stock images, including the following:
- Image with no attribution required
- Image that requires an attribution
1. Image with no attribution required
If the license associated with clip art or a stock image states “no attribution required,” then do not provide an APA Style reference, in-text citation, or copyright attribution.
For example, this image of a cat comes from Pixabay and has a license that says the image is free to reproduce with no attribution required. To use the image as a figure in an APA Style paper, provide a figure number and title and then the image. If desired, describe the image in a figure note. In a presentation (such as a PowerPoint presentation), the figure number, title, and note are optional.
Figure 1 A Striped Cat Sits With Paws Crossed

Note. Participants assigned to the cute pets condition saw this image of a cat.
2. Image that requires an attribution
If the license associated with clip art or a stock image says that attribution is required, then provide a copyright attribution in the figure note and a reference list entry for the image in the reference list. Many (but not all) images with Creative Commons licenses require attribution.
For example, this image of a sled dog comes from Flickr and has a Creative Commons license (specifically, CC BY 2.0). The license states that the image is free to use but attribution is required.
To use the image as a figure in an APA Style paper, provide a figure number and title and then the image. Below the image, provide a copyright attribution in the figure note. In a presentation, the figure number and title are optional but the note containing the copyright attribution is required.
The copyright attribution is used instead of an in-text citation. The copyright attribution consists of the same elements as the reference list entry, but in a different order (title, author, date, site name, URL), followed by the name of the Creative Commons License.
Figure 1 Lava the Sled Dog

Note . From Lava [Photograph], by Denali National Park and Preserve, 2013, Flickr
( https://www.flickr.com/photos/denalinps/8639280606/ ). CC BY 2.0.
Also provide a reference list entry for the image. The reference list entry for the image consists of its author, year of publication, title, description in brackets, and source (usually the name of the website and the URL).
Denali National Park and Preserve. (2013). Lava [Photograph]. Flickr. https://www.flickr.com/photos/denalinps/8639280606/
To cite clip art or a stock image without reproducing it, provide an in-text citation for the image instead of a copyright attribution. Also provide a reference list entry.
- Parenthetical citation : (Denali National Park and Preserve, 2013)
- Narrative citation : Denali National Park and Preserve (2013)
Clip art or stock images are covered in the seventh edition APA Style manuals in the Publication Manual Sections 12.14 to 12.18 and the Concise Guide Section 10.12
Top of page
Book/Printed Material The edge of objectivity; an essay in the history of scientific ideas.
Back to Search Results
About this Item
- The edge of objectivity; an essay in the history of scientific ideas.
- Gillispie, Charles Coulston.
Created / Published
- Princeton, N.J., Princeton University Press, 1960.
- - Science--History
- - Science--Philosophy
- - Includes bibliography.
- 562 p. illus. 23 cm.
Call Number/Physical Location
Library of congress control number, lccn permalink.
- https://lccn.loc.gov/60005748
Additional Metadata Formats
- MARCXML Record
- MODS Record
- Dublin Core Record
- Library of Congress Online Catalog (1,603,362)
- Book/Printed Material
Contributor
- Gillispie, Charles Coulston
Rights & Access
More about Copyright and other Restrictions
For guidance about compiling full citations consult Citing Primary Sources .
Cite This Item
Citations are generated automatically from bibliographic data as a convenience, and may not be complete or accurate.
Chicago citation style:
Gillispie, Charles Coulston. The Edge of Objectivity; an Essay in the History of Scientific Ideas . Princeton, N.J., Princeton University Press, 1960.
APA citation style:
Gillispie, C. C. (1960) The Edge of Objectivity; an Essay in the History of Scientific Ideas . Princeton, N.J., Princeton University Press.
MLA citation style:
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 03 June 2024
Applying large language models for automated essay scoring for non-native Japanese
- Wenchao Li 1 &
- Haitao Liu 2
Humanities and Social Sciences Communications volume 11 , Article number: 723 ( 2024 ) Cite this article
254 Accesses
2 Altmetric
Metrics details
- Language and linguistics
Recent advancements in artificial intelligence (AI) have led to an increased use of large language models (LLMs) for language assessment tasks such as automated essay scoring (AES), automated listening tests, and automated oral proficiency assessments. The application of LLMs for AES in the context of non-native Japanese, however, remains limited. This study explores the potential of LLM-based AES by comparing the efficiency of different models, i.e. two conventional machine training technology-based methods (Jess and JWriter), two LLMs (GPT and BERT), and one Japanese local LLM (Open-Calm large model). To conduct the evaluation, a dataset consisting of 1400 story-writing scripts authored by learners with 12 different first languages was used. Statistical analysis revealed that GPT-4 outperforms Jess and JWriter, BERT, and the Japanese language-specific trained Open-Calm large model in terms of annotation accuracy and predicting learning levels. Furthermore, by comparing 18 different models that utilize various prompts, the study emphasized the significance of prompts in achieving accurate and reliable evaluations using LLMs.
Similar content being viewed by others

Accurate structure prediction of biomolecular interactions with AlphaFold 3

Testing theory of mind in large language models and humans

Scaling neural machine translation to 200 languages
Conventional machine learning technology in aes.
AES has experienced significant growth with the advancement of machine learning technologies in recent decades. In the earlier stages of AES development, conventional machine learning-based approaches were commonly used. These approaches involved the following procedures: a) feeding the machine with a dataset. In this step, a dataset of essays is provided to the machine learning system. The dataset serves as the basis for training the model and establishing patterns and correlations between linguistic features and human ratings. b) the machine learning model is trained using linguistic features that best represent human ratings and can effectively discriminate learners’ writing proficiency. These features include lexical richness (Lu, 2012 ; Kyle and Crossley, 2015 ; Kyle et al. 2021 ), syntactic complexity (Lu, 2010 ; Liu, 2008 ), text cohesion (Crossley and McNamara, 2016 ), and among others. Conventional machine learning approaches in AES require human intervention, such as manual correction and annotation of essays. This human involvement was necessary to create a labeled dataset for training the model. Several AES systems have been developed using conventional machine learning technologies. These include the Intelligent Essay Assessor (Landauer et al. 2003 ), the e-rater engine by Educational Testing Service (Attali and Burstein, 2006 ; Burstein, 2003 ), MyAccess with the InterlliMetric scoring engine by Vantage Learning (Elliot, 2003 ), and the Bayesian Essay Test Scoring system (Rudner and Liang, 2002 ). These systems have played a significant role in automating the essay scoring process and providing quick and consistent feedback to learners. However, as touched upon earlier, conventional machine learning approaches rely on predetermined linguistic features and often require manual intervention, making them less flexible and potentially limiting their generalizability to different contexts.
In the context of the Japanese language, conventional machine learning-incorporated AES tools include Jess (Ishioka and Kameda, 2006 ) and JWriter (Lee and Hasebe, 2017 ). Jess assesses essays by deducting points from the perfect score, utilizing the Mainichi Daily News newspaper as a database. The evaluation criteria employed by Jess encompass various aspects, such as rhetorical elements (e.g., reading comprehension, vocabulary diversity, percentage of complex words, and percentage of passive sentences), organizational structures (e.g., forward and reverse connection structures), and content analysis (e.g., latent semantic indexing). JWriter employs linear regression analysis to assign weights to various measurement indices, such as average sentence length and total number of characters. These weights are then combined to derive the overall score. A pilot study involving the Jess model was conducted on 1320 essays at different proficiency levels, including primary, intermediate, and advanced. However, the results indicated that the Jess model failed to significantly distinguish between these essay levels. Out of the 16 measures used, four measures, namely median sentence length, median clause length, median number of phrases, and maximum number of phrases, did not show statistically significant differences between the levels. Additionally, two measures exhibited between-level differences but lacked linear progression: the number of attributives declined words and the Kanji/kana ratio. On the other hand, the remaining measures, including maximum sentence length, maximum clause length, number of attributive conjugated words, maximum number of consecutive infinitive forms, maximum number of conjunctive-particle clauses, k characteristic value, percentage of big words, and percentage of passive sentences, demonstrated statistically significant between-level differences and displayed linear progression.
Both Jess and JWriter exhibit notable limitations, including the manual selection of feature parameters and weights, which can introduce biases into the scoring process. The reliance on human annotators to label non-native language essays also introduces potential noise and variability in the scoring. Furthermore, an important concern is the possibility of system manipulation and cheating by learners who are aware of the regression equation utilized by the models (Hirao et al. 2020 ). These limitations emphasize the need for further advancements in AES systems to address these challenges.
Deep learning technology in AES
Deep learning has emerged as one of the approaches for improving the accuracy and effectiveness of AES. Deep learning-based AES methods utilize artificial neural networks that mimic the human brain’s functioning through layered algorithms and computational units. Unlike conventional machine learning, deep learning autonomously learns from the environment and past errors without human intervention. This enables deep learning models to establish nonlinear correlations, resulting in higher accuracy. Recent advancements in deep learning have led to the development of transformers, which are particularly effective in learning text representations. Noteworthy examples include bidirectional encoder representations from transformers (BERT) (Devlin et al. 2019 ) and the generative pretrained transformer (GPT) (OpenAI).
BERT is a linguistic representation model that utilizes a transformer architecture and is trained on two tasks: masked linguistic modeling and next-sentence prediction (Hirao et al. 2020 ; Vaswani et al. 2017 ). In the context of AES, BERT follows specific procedures, as illustrated in Fig. 1 : (a) the tokenized prompts and essays are taken as input; (b) special tokens, such as [CLS] and [SEP], are added to mark the beginning and separation of prompts and essays; (c) the transformer encoder processes the prompt and essay sequences, resulting in hidden layer sequences; (d) the hidden layers corresponding to the [CLS] tokens (T[CLS]) represent distributed representations of the prompts and essays; and (e) a multilayer perceptron uses these distributed representations as input to obtain the final score (Hirao et al. 2020 ).

AES system with BERT (Hirao et al. 2020 ).
The training of BERT using a substantial amount of sentence data through the Masked Language Model (MLM) allows it to capture contextual information within the hidden layers. Consequently, BERT is expected to be capable of identifying artificial essays as invalid and assigning them lower scores (Mizumoto and Eguchi, 2023 ). In the context of AES for nonnative Japanese learners, Hirao et al. ( 2020 ) combined the long short-term memory (LSTM) model proposed by Hochreiter and Schmidhuber ( 1997 ) with BERT to develop a tailored automated Essay Scoring System. The findings of their study revealed that the BERT model outperformed both the conventional machine learning approach utilizing character-type features such as “kanji” and “hiragana”, as well as the standalone LSTM model. Takeuchi et al. ( 2021 ) presented an approach to Japanese AES that eliminates the requirement for pre-scored essays by relying solely on reference texts or a model answer for the essay task. They investigated multiple similarity evaluation methods, including frequency of morphemes, idf values calculated on Wikipedia, LSI, LDA, word-embedding vectors, and document vectors produced by BERT. The experimental findings revealed that the method utilizing the frequency of morphemes with idf values exhibited the strongest correlation with human-annotated scores across different essay tasks. The utilization of BERT in AES encounters several limitations. Firstly, essays often exceed the model’s maximum length limit. Second, only score labels are available for training, which restricts access to additional information.
Mizumoto and Eguchi ( 2023 ) were pioneers in employing the GPT model for AES in non-native English writing. Their study focused on evaluating the accuracy and reliability of AES using the GPT-3 text-davinci-003 model, analyzing a dataset of 12,100 essays from the corpus of nonnative written English (TOEFL11). The findings indicated that AES utilizing the GPT-3 model exhibited a certain degree of accuracy and reliability. They suggest that GPT-3-based AES systems hold the potential to provide support for human ratings. However, applying GPT model to AES presents a unique natural language processing (NLP) task that involves considerations such as nonnative language proficiency, the influence of the learner’s first language on the output in the target language, and identifying linguistic features that best indicate writing quality in a specific language. These linguistic features may differ morphologically or syntactically from those present in the learners’ first language, as observed in (1)–(3).
我-送了-他-一本-书
Wǒ-sòngle-tā-yī běn-shū
1 sg .-give. past- him-one .cl- book
“I gave him a book.”
Agglutinative
彼-に-本-を-あげ-まし-た
Kare-ni-hon-o-age-mashi-ta
3 sg .- dat -hon- acc- give.honorification. past
Inflectional
give, give-s, gave, given, giving
Additionally, the morphological agglutination and subject-object-verb (SOV) order in Japanese, along with its idiomatic expressions, pose additional challenges for applying language models in AES tasks (4).
足-が 棒-に なり-ました
Ashi-ga bo-ni nar-mashita
leg- nom stick- dat become- past
“My leg became like a stick (I am extremely tired).”
The example sentence provided demonstrates the morpho-syntactic structure of Japanese and the presence of an idiomatic expression. In this sentence, the verb “なる” (naru), meaning “to become”, appears at the end of the sentence. The verb stem “なり” (nari) is attached with morphemes indicating honorification (“ます” - mashu) and tense (“た” - ta), showcasing agglutination. While the sentence can be literally translated as “my leg became like a stick”, it carries an idiomatic interpretation that implies “I am extremely tired”.
To overcome this issue, CyberAgent Inc. ( 2023 ) has developed the Open-Calm series of language models specifically designed for Japanese. Open-Calm consists of pre-trained models available in various sizes, such as Small, Medium, Large, and 7b. Figure 2 depicts the fundamental structure of the Open-Calm model. A key feature of this architecture is the incorporation of the Lora Adapter and GPT-NeoX frameworks, which can enhance its language processing capabilities.

GPT-NeoX Model Architecture (Okgetheng and Takeuchi 2024 ).
In a recent study conducted by Okgetheng and Takeuchi ( 2024 ), they assessed the efficacy of Open-Calm language models in grading Japanese essays. The research utilized a dataset of approximately 300 essays, which were annotated by native Japanese educators. The findings of the study demonstrate the considerable potential of Open-Calm language models in automated Japanese essay scoring. Specifically, among the Open-Calm family, the Open-Calm Large model (referred to as OCLL) exhibited the highest performance. However, it is important to note that, as of the current date, the Open-Calm Large model does not offer public access to its server. Consequently, users are required to independently deploy and operate the environment for OCLL. In order to utilize OCLL, users must have a PC equipped with an NVIDIA GeForce RTX 3060 (8 or 12 GB VRAM).
In summary, while the potential of LLMs in automated scoring of nonnative Japanese essays has been demonstrated in two studies—BERT-driven AES (Hirao et al. 2020 ) and OCLL-based AES (Okgetheng and Takeuchi, 2024 )—the number of research efforts in this area remains limited.
Another significant challenge in applying LLMs to AES lies in prompt engineering and ensuring its reliability and effectiveness (Brown et al. 2020 ; Rae et al. 2021 ; Zhang et al. 2021 ). Various prompting strategies have been proposed, such as the zero-shot chain of thought (CoT) approach (Kojima et al. 2022 ), which involves manually crafting diverse and effective examples. However, manual efforts can lead to mistakes. To address this, Zhang et al. ( 2021 ) introduced an automatic CoT prompting method called Auto-CoT, which demonstrates matching or superior performance compared to the CoT paradigm. Another prompt framework is trees of thoughts, enabling a model to self-evaluate its progress at intermediate stages of problem-solving through deliberate reasoning (Yao et al. 2023 ).
Beyond linguistic studies, there has been a noticeable increase in the number of foreign workers in Japan and Japanese learners worldwide (Ministry of Health, Labor, and Welfare of Japan, 2022 ; Japan Foundation, 2021 ). However, existing assessment methods, such as the Japanese Language Proficiency Test (JLPT), J-CAT, and TTBJ Footnote 1 , primarily focus on reading, listening, vocabulary, and grammar skills, neglecting the evaluation of writing proficiency. As the number of workers and language learners continues to grow, there is a rising demand for an efficient AES system that can reduce costs and time for raters and be utilized for employment, examinations, and self-study purposes.
This study aims to explore the potential of LLM-based AES by comparing the effectiveness of five models: two LLMs (GPT Footnote 2 and BERT), one Japanese local LLM (OCLL), and two conventional machine learning-based methods (linguistic feature-based scoring tools - Jess and JWriter).
The research questions addressed in this study are as follows:
To what extent do the LLM-driven AES and linguistic feature-based AES, when used as automated tools to support human rating, accurately reflect test takers’ actual performance?
What influence does the prompt have on the accuracy and performance of LLM-based AES methods?
The subsequent sections of the manuscript cover the methodology, including the assessment measures for nonnative Japanese writing proficiency, criteria for prompts, and the dataset. The evaluation section focuses on the analysis of annotations and rating scores generated by LLM-driven and linguistic feature-based AES methods.
Methodology
The dataset utilized in this study was obtained from the International Corpus of Japanese as a Second Language (I-JAS) Footnote 3 . This corpus consisted of 1000 participants who represented 12 different first languages. For the study, the participants were given a story-writing task on a personal computer. They were required to write two stories based on the 4-panel illustrations titled “Picnic” and “The key” (see Appendix A). Background information for the participants was provided by the corpus, including their Japanese language proficiency levels assessed through two online tests: J-CAT and SPOT. These tests evaluated their reading, listening, vocabulary, and grammar abilities. The learners’ proficiency levels were categorized into six levels aligned with the Common European Framework of Reference for Languages (CEFR) and the Reference Framework for Japanese Language Education (RFJLE): A1, A2, B1, B2, C1, and C2. According to Lee et al. ( 2015 ), there is a high level of agreement (r = 0.86) between the J-CAT and SPOT assessments, indicating that the proficiency certifications provided by J-CAT are consistent with those of SPOT. However, it is important to note that the scores of J-CAT and SPOT do not have a one-to-one correspondence. In this study, the J-CAT scores were used as a benchmark to differentiate learners of different proficiency levels. A total of 1400 essays were utilized, representing the beginner (aligned with A1), A2, B1, B2, C1, and C2 levels based on the J-CAT scores. Table 1 provides information about the learners’ proficiency levels and their corresponding J-CAT and SPOT scores.
A dataset comprising a total of 1400 essays from the story writing tasks was collected. Among these, 714 essays were utilized to evaluate the reliability of the LLM-based AES method, while the remaining 686 essays were designated as development data to assess the LLM-based AES’s capability to distinguish participants with varying proficiency levels. The GPT 4 API was used in this study. A detailed explanation of the prompt-assessment criteria is provided in Section Prompt . All essays were sent to the model for measurement and scoring.
Measures of writing proficiency for nonnative Japanese
Japanese exhibits a morphologically agglutinative structure where morphemes are attached to the word stem to convey grammatical functions such as tense, aspect, voice, and honorifics, e.g. (5).
食べ-させ-られ-まし-た-か
tabe-sase-rare-mashi-ta-ka
[eat (stem)-causative-passive voice-honorification-tense. past-question marker]
Japanese employs nine case particles to indicate grammatical functions: the nominative case particle が (ga), the accusative case particle を (o), the genitive case particle の (no), the dative case particle に (ni), the locative/instrumental case particle で (de), the ablative case particle から (kara), the directional case particle へ (e), and the comitative case particle と (to). The agglutinative nature of the language, combined with the case particle system, provides an efficient means of distinguishing between active and passive voice, either through morphemes or case particles, e.g. 食べる taberu “eat concusive . ” (active voice); 食べられる taberareru “eat concusive . ” (passive voice). In the active voice, “パン を 食べる” (pan o taberu) translates to “to eat bread”. On the other hand, in the passive voice, it becomes “パン が 食べられた” (pan ga taberareta), which means “(the) bread was eaten”. Additionally, it is important to note that different conjugations of the same lemma are considered as one type in order to ensure a comprehensive assessment of the language features. For example, e.g., 食べる taberu “eat concusive . ”; 食べている tabeteiru “eat progress .”; 食べた tabeta “eat past . ” as one type.
To incorporate these features, previous research (Suzuki, 1999 ; Watanabe et al. 1988 ; Ishioka, 2001 ; Ishioka and Kameda, 2006 ; Hirao et al. 2020 ) has identified complexity, fluency, and accuracy as crucial factors for evaluating writing quality. These criteria are assessed through various aspects, including lexical richness (lexical density, diversity, and sophistication), syntactic complexity, and cohesion (Kyle et al. 2021 ; Mizumoto and Eguchi, 2023 ; Ure, 1971 ; Halliday, 1985 ; Barkaoui and Hadidi, 2020 ; Zenker and Kyle, 2021 ; Kim et al. 2018 ; Lu, 2017 ; Ortega, 2015 ). Therefore, this study proposes five scoring categories: lexical richness, syntactic complexity, cohesion, content elaboration, and grammatical accuracy. A total of 16 measures were employed to capture these categories. The calculation process and specific details of these measures can be found in Table 2 .
T-unit, first introduced by Hunt ( 1966 ), is a measure used for evaluating speech and composition. It serves as an indicator of syntactic development and represents the shortest units into which a piece of discourse can be divided without leaving any sentence fragments. In the context of Japanese language assessment, Sakoda and Hosoi ( 2020 ) utilized T-unit as the basic unit to assess the accuracy and complexity of Japanese learners’ speaking and storytelling. The calculation of T-units in Japanese follows the following principles:
A single main clause constitutes 1 T-unit, regardless of the presence or absence of dependent clauses, e.g. (6).
ケンとマリはピクニックに行きました (main clause): 1 T-unit.
If a sentence contains a main clause along with subclauses, each subclause is considered part of the same T-unit, e.g. (7).
天気が良かった の で (subclause)、ケンとマリはピクニックに行きました (main clause): 1 T-unit.
In the case of coordinate clauses, where multiple clauses are connected, each coordinated clause is counted separately. Thus, a sentence with coordinate clauses may have 2 T-units or more, e.g. (8).
ケンは地図で場所を探して (coordinate clause)、マリはサンドイッチを作りました (coordinate clause): 2 T-units.
Lexical diversity refers to the range of words used within a text (Engber, 1995 ; Kyle et al. 2021 ) and is considered a useful measure of the breadth of vocabulary in L n production (Jarvis, 2013a , 2013b ).
The type/token ratio (TTR) is widely recognized as a straightforward measure for calculating lexical diversity and has been employed in numerous studies. These studies have demonstrated a strong correlation between TTR and other methods of measuring lexical diversity (e.g., Bentz et al. 2016 ; Čech and Miroslav, 2018 ; Çöltekin and Taraka, 2018 ). TTR is computed by considering both the number of unique words (types) and the total number of words (tokens) in a given text. Given that the length of learners’ writing texts can vary, this study employs the moving average type-token ratio (MATTR) to mitigate the influence of text length. MATTR is calculated using a 50-word moving window. Initially, a TTR is determined for words 1–50 in an essay, followed by words 2–51, 3–52, and so on until the end of the essay is reached (Díez-Ortega and Kyle, 2023 ). The final MATTR scores were obtained by averaging the TTR scores for all 50-word windows. The following formula was employed to derive MATTR:
\({\rm{MATTR}}({\rm{W}})=\frac{{\sum }_{{\rm{i}}=1}^{{\rm{N}}-{\rm{W}}+1}{{\rm{F}}}_{{\rm{i}}}}{{\rm{W}}({\rm{N}}-{\rm{W}}+1)}\)
Here, N refers to the number of tokens in the corpus. W is the randomly selected token size (W < N). \({F}_{i}\) is the number of types in each window. The \({\rm{MATTR}}({\rm{W}})\) is the mean of a series of type-token ratios (TTRs) based on the word form for all windows. It is expected that individuals with higher language proficiency will produce texts with greater lexical diversity, as indicated by higher MATTR scores.
Lexical density was captured by the ratio of the number of lexical words to the total number of words (Lu, 2012 ). Lexical sophistication refers to the utilization of advanced vocabulary, often evaluated through word frequency indices (Crossley et al. 2013 ; Haberman, 2008 ; Kyle and Crossley, 2015 ; Laufer and Nation, 1995 ; Lu, 2012 ; Read, 2000 ). In line of writing, lexical sophistication can be interpreted as vocabulary breadth, which entails the appropriate usage of vocabulary items across various lexicon-grammatical contexts and registers (Garner et al. 2019 ; Kim et al. 2018 ; Kyle et al. 2018 ). In Japanese specifically, words are considered lexically sophisticated if they are not included in the “Japanese Education Vocabulary List Ver 1.0”. Footnote 4 Consequently, lexical sophistication was calculated by determining the number of sophisticated word types relative to the total number of words per essay. Furthermore, it has been suggested that, in Japanese writing, sentences should ideally have a length of no more than 40 to 50 characters, as this promotes readability. Therefore, the median and maximum sentence length can be considered as useful indices for assessment (Ishioka and Kameda, 2006 ).
Syntactic complexity was assessed based on several measures, including the mean length of clauses, verb phrases per T-unit, clauses per T-unit, dependent clauses per T-unit, complex nominals per clause, adverbial clauses per clause, coordinate phrases per clause, and mean dependency distance (MDD). The MDD reflects the distance between the governor and dependent positions in a sentence. A larger dependency distance indicates a higher cognitive load and greater complexity in syntactic processing (Liu, 2008 ; Liu et al. 2017 ). The MDD has been established as an efficient metric for measuring syntactic complexity (Jiang, Quyang, and Liu, 2019 ; Li and Yan, 2021 ). To calculate the MDD, the position numbers of the governor and dependent are subtracted, assuming that words in a sentence are assigned in a linear order, such as W1 … Wi … Wn. In any dependency relationship between words Wa and Wb, Wa is the governor and Wb is the dependent. The MDD of the entire sentence was obtained by taking the absolute value of governor – dependent:
MDD = \(\frac{1}{n}{\sum }_{i=1}^{n}|{\rm{D}}{{\rm{D}}}_{i}|\)
In this formula, \(n\) represents the number of words in the sentence, and \({DD}i\) is the dependency distance of the \({i}^{{th}}\) dependency relationship of a sentence. Building on this, the annotation of sentence ‘Mary-ga-John-ni-keshigomu-o-watashita was [Mary- top -John- dat -eraser- acc -give- past] ’. The sentence’s MDD would be 2. Table 3 provides the CSV file as a prompt for GPT 4.
Cohesion (semantic similarity) and content elaboration aim to capture the ideas presented in test taker’s essays. Cohesion was assessed using three measures: Synonym overlap/paragraph (topic), Synonym overlap/paragraph (keywords), and word2vec cosine similarity. Content elaboration and development were measured as the number of metadiscourse markers (type)/number of words. To capture content closely, this study proposed a novel-distance based representation, by encoding the cosine distance between the essay (by learner) and essay task’s (topic and keyword) i -vectors. The learner’s essay is decoded into a word sequence, and aligned to the essay task’ topic and keyword for log-likelihood measurement. The cosine distance reveals the content elaboration score in the leaners’ essay. The mathematical equation of cosine similarity between target-reference vectors is shown in (11), assuming there are i essays and ( L i , …. L n ) and ( N i , …. N n ) are the vectors representing the learner and task’s topic and keyword respectively. The content elaboration distance between L i and N i was calculated as follows:
\(\cos \left(\theta \right)=\frac{{\rm{L}}\,\cdot\, {\rm{N}}}{\left|{\rm{L}}\right|{\rm{|N|}}}=\frac{\mathop{\sum }\nolimits_{i=1}^{n}{L}_{i}{N}_{i}}{\sqrt{\mathop{\sum }\nolimits_{i=1}^{n}{L}_{i}^{2}}\sqrt{\mathop{\sum }\nolimits_{i=1}^{n}{N}_{i}^{2}}}\)
A high similarity value indicates a low difference between the two recognition outcomes, which in turn suggests a high level of proficiency in content elaboration.
To evaluate the effectiveness of the proposed measures in distinguishing different proficiency levels among nonnative Japanese speakers’ writing, we conducted a multi-faceted Rasch measurement analysis (Linacre, 1994 ). This approach applies measurement models to thoroughly analyze various factors that can influence test outcomes, including test takers’ proficiency, item difficulty, and rater severity, among others. The underlying principles and functionality of multi-faceted Rasch measurement are illustrated in (12).
\(\log \left(\frac{{P}_{{nijk}}}{{P}_{{nij}(k-1)}}\right)={B}_{n}-{D}_{i}-{C}_{j}-{F}_{k}\)
(12) defines the logarithmic transformation of the probability ratio ( P nijk /P nij(k-1) )) as a function of multiple parameters. Here, n represents the test taker, i denotes a writing proficiency measure, j corresponds to the human rater, and k represents the proficiency score. The parameter B n signifies the proficiency level of test taker n (where n ranges from 1 to N). D j represents the difficulty parameter of test item i (where i ranges from 1 to L), while C j represents the severity of rater j (where j ranges from 1 to J). Additionally, F k represents the step difficulty for a test taker to move from score ‘k-1’ to k . P nijk refers to the probability of rater j assigning score k to test taker n for test item i . P nij(k-1) represents the likelihood of test taker n being assigned score ‘k-1’ by rater j for test item i . Each facet within the test is treated as an independent parameter and estimated within the same reference framework. To evaluate the consistency of scores obtained through both human and computer analysis, we utilized the Infit mean-square statistic. This statistic is a chi-square measure divided by the degrees of freedom and is weighted with information. It demonstrates higher sensitivity to unexpected patterns in responses to items near a person’s proficiency level (Linacre, 2002 ). Fit statistics are assessed based on predefined thresholds for acceptable fit. For the Infit MNSQ, which has a mean of 1.00, different thresholds have been suggested. Some propose stricter thresholds ranging from 0.7 to 1.3 (Bond et al. 2021 ), while others suggest more lenient thresholds ranging from 0.5 to 1.5 (Eckes, 2009 ). In this study, we adopted the criterion of 0.70–1.30 for the Infit MNSQ.
Moving forward, we can now proceed to assess the effectiveness of the 16 proposed measures based on five criteria for accurately distinguishing various levels of writing proficiency among non-native Japanese speakers. To conduct this evaluation, we utilized the development dataset from the I-JAS corpus, as described in Section Dataset . Table 4 provides a measurement report that presents the performance details of the 14 metrics under consideration. The measure separation was found to be 4.02, indicating a clear differentiation among the measures. The reliability index for the measure separation was 0.891, suggesting consistency in the measurement. Similarly, the person separation reliability index was 0.802, indicating the accuracy of the assessment in distinguishing between individuals. All 16 measures demonstrated Infit mean squares within a reasonable range, ranging from 0.76 to 1.28. The Synonym overlap/paragraph (topic) measure exhibited a relatively high outfit mean square of 1.46, although the Infit mean square falls within an acceptable range. The standard error for the measures ranged from 0.13 to 0.28, indicating the precision of the estimates.
Table 5 further illustrated the weights assigned to different linguistic measures for score prediction, with higher weights indicating stronger correlations between those measures and higher scores. Specifically, the following measures exhibited higher weights compared to others: moving average type token ratio per essay has a weight of 0.0391. Mean dependency distance had a weight of 0.0388. Mean length of clause, calculated by dividing the number of words by the number of clauses, had a weight of 0.0374. Complex nominals per T-unit, calculated by dividing the number of complex nominals by the number of T-units, had a weight of 0.0379. Coordinate phrases rate, calculated by dividing the number of coordinate phrases by the number of clauses, had a weight of 0.0325. Grammatical error rate, representing the number of errors per essay, had a weight of 0.0322.
Criteria (output indicator)
The criteria used to evaluate the writing ability in this study were based on CEFR, which follows a six-point scale ranging from A1 to C2. To assess the quality of Japanese writing, the scoring criteria from Table 6 were utilized. These criteria were derived from the IELTS writing standards and served as assessment guidelines and prompts for the written output.
A prompt is a question or detailed instruction that is provided to the model to obtain a proper response. After several pilot experiments, we decided to provide the measures (Section Measures of writing proficiency for nonnative Japanese ) as the input prompt and use the criteria (Section Criteria (output indicator) ) as the output indicator. Regarding the prompt language, considering that the LLM was tasked with rating Japanese essays, would prompt in Japanese works better Footnote 5 ? We conducted experiments comparing the performance of GPT-4 using both English and Japanese prompts. Additionally, we utilized the Japanese local model OCLL with Japanese prompts. Multiple trials were conducted using the same sample. Regardless of the prompt language used, we consistently obtained the same grading results with GPT-4, which assigned a grade of B1 to the writing sample. This suggested that GPT-4 is reliable and capable of producing consistent ratings regardless of the prompt language. On the other hand, when we used Japanese prompts with the Japanese local model “OCLL”, we encountered inconsistent grading results. Out of 10 attempts with OCLL, only 6 yielded consistent grading results (B1), while the remaining 4 showed different outcomes, including A1 and B2 grades. These findings indicated that the language of the prompt was not the determining factor for reliable AES. Instead, the size of the training data and the model parameters played crucial roles in achieving consistent and reliable AES results for the language model.
The following is the utilized prompt, which details all measures and requires the LLM to score the essays using holistic and trait scores.
Please evaluate Japanese essays written by Japanese learners and assign a score to each essay on a six-point scale, ranging from A1, A2, B1, B2, C1 to C2. Additionally, please provide trait scores and display the calculation process for each trait score. The scoring should be based on the following criteria:
Moving average type-token ratio.
Number of lexical words (token) divided by the total number of words per essay.
Number of sophisticated word types divided by the total number of words per essay.
Mean length of clause.
Verb phrases per T-unit.
Clauses per T-unit.
Dependent clauses per T-unit.
Complex nominals per clause.
Adverbial clauses per clause.
Coordinate phrases per clause.
Mean dependency distance.
Synonym overlap paragraph (topic and keywords).
Word2vec cosine similarity.
Connectives per essay.
Conjunctions per essay.
Number of metadiscourse markers (types) divided by the total number of words.
Number of errors per essay.
Japanese essay text
出かける前に二人が地図を見ている間に、サンドイッチを入れたバスケットに犬が入ってしまいました。それに気づかずに二人は楽しそうに出かけて行きました。やがて突然犬がバスケットから飛び出し、二人は驚きました。バスケット の 中を見ると、食べ物はすべて犬に食べられていて、二人は困ってしまいました。(ID_JJJ01_SW1)
The score of the example above was B1. Figure 3 provides an example of holistic and trait scores provided by GPT-4 (with a prompt indicating all measures) via Bing Footnote 6 .

Example of GPT-4 AES and feedback (with a prompt indicating all measures).
Statistical analysis
The aim of this study is to investigate the potential use of LLM for nonnative Japanese AES. It seeks to compare the scoring outcomes obtained from feature-based AES tools, which rely on conventional machine learning technology (i.e. Jess, JWriter), with those generated by AI-driven AES tools utilizing deep learning technology (BERT, GPT, OCLL). To assess the reliability of a computer-assisted annotation tool, the study initially established human-human agreement as the benchmark measure. Subsequently, the performance of the LLM-based method was evaluated by comparing it to human-human agreement.
To assess annotation agreement, the study employed standard measures such as precision, recall, and F-score (Brants 2000 ; Lu 2010 ), along with the quadratically weighted kappa (QWK) to evaluate the consistency and agreement in the annotation process. Assume A and B represent human annotators. When comparing the annotations of the two annotators, the following results are obtained. The evaluation of precision, recall, and F-score metrics was illustrated in equations (13) to (15).
\({\rm{Recall}}(A,B)=\frac{{\rm{Number}}\,{\rm{of}}\,{\rm{identical}}\,{\rm{nodes}}\,{\rm{in}}\,A\,{\rm{and}}\,B}{{\rm{Number}}\,{\rm{of}}\,{\rm{nodes}}\,{\rm{in}}\,A}\)
\({\rm{Precision}}(A,\,B)=\frac{{\rm{Number}}\,{\rm{of}}\,{\rm{identical}}\,{\rm{nodes}}\,{\rm{in}}\,A\,{\rm{and}}\,B}{{\rm{Number}}\,{\rm{of}}\,{\rm{nodes}}\,{\rm{in}}\,B}\)
The F-score is the harmonic mean of recall and precision:
\({\rm{F}}-{\rm{score}}=\frac{2* ({\rm{Precision}}* {\rm{Recall}})}{{\rm{Precision}}+{\rm{Recall}}}\)
The highest possible value of an F-score is 1.0, indicating perfect precision and recall, and the lowest possible value is 0, if either precision or recall are zero.
In accordance with Taghipour and Ng ( 2016 ), the calculation of QWK involves two steps:
Step 1: Construct a weight matrix W as follows:
\({W}_{{ij}}=\frac{{(i-j)}^{2}}{{(N-1)}^{2}}\)
i represents the annotation made by the tool, while j represents the annotation made by a human rater. N denotes the total number of possible annotations. Matrix O is subsequently computed, where O_( i, j ) represents the count of data annotated by the tool ( i ) and the human annotator ( j ). On the other hand, E refers to the expected count matrix, which undergoes normalization to ensure that the sum of elements in E matches the sum of elements in O.
Step 2: With matrices O and E, the QWK is obtained as follows:
K = 1- \(\frac{\sum i,j{W}_{i,j}\,{O}_{i,j}}{\sum i,j{W}_{i,j}\,{E}_{i,j}}\)
The value of the quadratic weighted kappa increases as the level of agreement improves. Further, to assess the accuracy of LLM scoring, the proportional reductive mean square error (PRMSE) was employed. The PRMSE approach takes into account the variability observed in human ratings to estimate the rater error, which is then subtracted from the variance of the human labels. This calculation provides an overall measure of agreement between the automated scores and true scores (Haberman et al. 2015 ; Loukina et al. 2020 ; Taghipour and Ng, 2016 ). The computation of PRMSE involves the following steps:
Step 1: Calculate the mean squared errors (MSEs) for the scoring outcomes of the computer-assisted tool (MSE tool) and the human scoring outcomes (MSE human).
Step 2: Determine the PRMSE by comparing the MSE of the computer-assisted tool (MSE tool) with the MSE from human raters (MSE human), using the following formula:
\({\rm{PRMSE}}=1-\frac{({\rm{MSE}}\,{\rm{tool}})\,}{({\rm{MSE}}\,{\rm{human}})\,}=1-\,\frac{{\sum }_{i}^{n}=1{({{\rm{y}}}_{i}-{\hat{{\rm{y}}}}_{{\rm{i}}})}^{2}}{{\sum }_{i}^{n}=1{({{\rm{y}}}_{i}-\hat{{\rm{y}}})}^{2}}\)
In the numerator, ŷi represents the scoring outcome predicted by a specific LLM-driven AES system for a given sample. The term y i − ŷ i represents the difference between this predicted outcome and the mean value of all LLM-driven AES systems’ scoring outcomes. It quantifies the deviation of the specific LLM-driven AES system’s prediction from the average prediction of all LLM-driven AES systems. In the denominator, y i − ŷ represents the difference between the scoring outcome provided by a specific human rater for a given sample and the mean value of all human raters’ scoring outcomes. It measures the discrepancy between the specific human rater’s score and the average score given by all human raters. The PRMSE is then calculated by subtracting the ratio of the MSE tool to the MSE human from 1. PRMSE falls within the range of 0 to 1, with larger values indicating reduced errors in LLM’s scoring compared to those of human raters. In other words, a higher PRMSE implies that LLM’s scoring demonstrates greater accuracy in predicting the true scores (Loukina et al. 2020 ). The interpretation of kappa values, ranging from 0 to 1, is based on the work of Landis and Koch ( 1977 ). Specifically, the following categories are assigned to different ranges of kappa values: −1 indicates complete inconsistency, 0 indicates random agreement, 0.0 ~ 0.20 indicates extremely low level of agreement (slight), 0.21 ~ 0.40 indicates moderate level of agreement (fair), 0.41 ~ 0.60 indicates medium level of agreement (moderate), 0.61 ~ 0.80 indicates high level of agreement (substantial), 0.81 ~ 1 indicates almost perfect level of agreement. All statistical analyses were executed using Python script.
Results and discussion
Annotation reliability of the llm.
This section focuses on assessing the reliability of the LLM’s annotation and scoring capabilities. To evaluate the reliability, several tests were conducted simultaneously, aiming to achieve the following objectives:
Assess the LLM’s ability to differentiate between test takers with varying levels of oral proficiency.
Determine the level of agreement between the annotations and scoring performed by the LLM and those done by human raters.
The evaluation of the results encompassed several metrics, including: precision, recall, F-Score, quadratically-weighted kappa, proportional reduction of mean squared error, Pearson correlation, and multi-faceted Rasch measurement.
Inter-annotator agreement (human–human annotator agreement)
We started with an agreement test of the two human annotators. Two trained annotators were recruited to determine the writing task data measures. A total of 714 scripts, as the test data, was utilized. Each analysis lasted 300–360 min. Inter-annotator agreement was evaluated using the standard measures of precision, recall, and F-score and QWK. Table 7 presents the inter-annotator agreement for the various indicators. As shown, the inter-annotator agreement was fairly high, with F-scores ranging from 1.0 for sentence and word number to 0.666 for grammatical errors.
The findings from the QWK analysis provided further confirmation of the inter-annotator agreement. The QWK values covered a range from 0.950 ( p = 0.000) for sentence and word number to 0.695 for synonym overlap number (keyword) and grammatical errors ( p = 0.001).
Agreement of annotation outcomes between human and LLM
To evaluate the consistency between human annotators and LLM annotators (BERT, GPT, OCLL) across the indices, the same test was conducted. The results of the inter-annotator agreement (F-score) between LLM and human annotation are provided in Appendix B-D. The F-scores ranged from 0.706 for Grammatical error # for OCLL-human to a perfect 1.000 for GPT-human, for sentences, clauses, T-units, and words. These findings were further supported by the QWK analysis, which showed agreement levels ranging from 0.807 ( p = 0.001) for metadiscourse markers for OCLL-human to 0.962 for words ( p = 0.000) for GPT-human. The findings demonstrated that the LLM annotation achieved a significant level of accuracy in identifying measurement units and counts.
Reliability of LLM-driven AES’s scoring and discriminating proficiency levels
This section examines the reliability of the LLM-driven AES scoring through a comparison of the scoring outcomes produced by human raters and the LLM ( Reliability of LLM-driven AES scoring ). It also assesses the effectiveness of the LLM-based AES system in differentiating participants with varying proficiency levels ( Reliability of LLM-driven AES discriminating proficiency levels ).
Reliability of LLM-driven AES scoring
Table 8 summarizes the QWK coefficient analysis between the scores computed by the human raters and the GPT-4 for the individual essays from I-JAS Footnote 7 . As shown, the QWK of all measures ranged from k = 0.819 for lexical density (number of lexical words (tokens)/number of words per essay) to k = 0.644 for word2vec cosine similarity. Table 9 further presents the Pearson correlations between the 16 writing proficiency measures scored by human raters and GPT 4 for the individual essays. The correlations ranged from 0.672 for syntactic complexity to 0.734 for grammatical accuracy. The correlations between the writing proficiency scores assigned by human raters and the BERT-based AES system were found to range from 0.661 for syntactic complexity to 0.713 for grammatical accuracy. The correlations between the writing proficiency scores given by human raters and the OCLL-based AES system ranged from 0.654 for cohesion to 0.721 for grammatical accuracy. These findings indicated an alignment between the assessments made by human raters and both the BERT-based and OCLL-based AES systems in terms of various aspects of writing proficiency.
Reliability of LLM-driven AES discriminating proficiency levels
After validating the reliability of the LLM’s annotation and scoring, the subsequent objective was to evaluate its ability to distinguish between various proficiency levels. For this analysis, a dataset of 686 individual essays was utilized. Table 10 presents a sample of the results, summarizing the means, standard deviations, and the outcomes of the one-way ANOVAs based on the measures assessed by the GPT-4 model. A post hoc multiple comparison test, specifically the Bonferroni test, was conducted to identify any potential differences between pairs of levels.
As the results reveal, seven measures presented linear upward or downward progress across the three proficiency levels. These were marked in bold in Table 10 and comprise one measure of lexical richness, i.e. MATTR (lexical diversity); four measures of syntactic complexity, i.e. MDD (mean dependency distance), MLC (mean length of clause), CNT (complex nominals per T-unit), CPC (coordinate phrases rate); one cohesion measure, i.e. word2vec cosine similarity and GER (grammatical error rate). Regarding the ability of the sixteen measures to distinguish adjacent proficiency levels, the Bonferroni tests indicated that statistically significant differences exist between the primary level and the intermediate level for MLC and GER. One measure of lexical richness, namely LD, along with three measures of syntactic complexity (VPT, CT, DCT, ACC), two measures of cohesion (SOPT, SOPK), and one measure of content elaboration (IMM), exhibited statistically significant differences between proficiency levels. However, these differences did not demonstrate a linear progression between adjacent proficiency levels. No significant difference was observed in lexical sophistication between proficiency levels.
To summarize, our study aimed to evaluate the reliability and differentiation capabilities of the LLM-driven AES method. For the first objective, we assessed the LLM’s ability to differentiate between test takers with varying levels of oral proficiency using precision, recall, F-Score, and quadratically-weighted kappa. Regarding the second objective, we compared the scoring outcomes generated by human raters and the LLM to determine the level of agreement. We employed quadratically-weighted kappa and Pearson correlations to compare the 16 writing proficiency measures for the individual essays. The results confirmed the feasibility of using the LLM for annotation and scoring in AES for nonnative Japanese. As a result, Research Question 1 has been addressed.
Comparison of BERT-, GPT-, OCLL-based AES, and linguistic-feature-based computation methods
This section aims to compare the effectiveness of five AES methods for nonnative Japanese writing, i.e. LLM-driven approaches utilizing BERT, GPT, and OCLL, linguistic feature-based approaches using Jess and JWriter. The comparison was conducted by comparing the ratings obtained from each approach with human ratings. All ratings were derived from the dataset introduced in Dataset . To facilitate the comparison, the agreement between the automated methods and human ratings was assessed using QWK and PRMSE. The performance of each approach was summarized in Table 11 .
The QWK coefficient values indicate that LLMs (GPT, BERT, OCLL) and human rating outcomes demonstrated higher agreement compared to feature-based AES methods (Jess and JWriter) in assessing writing proficiency criteria, including lexical richness, syntactic complexity, content, and grammatical accuracy. Among the LLMs, the GPT-4 driven AES and human rating outcomes showed the highest agreement in all criteria, except for syntactic complexity. The PRMSE values suggest that the GPT-based method outperformed linguistic feature-based methods and other LLM-based approaches. Moreover, an interesting finding emerged during the study: the agreement coefficient between GPT-4 and human scoring was even higher than the agreement between different human raters themselves. This discovery highlights the advantage of GPT-based AES over human rating. Ratings involve a series of processes, including reading the learners’ writing, evaluating the content and language, and assigning scores. Within this chain of processes, various biases can be introduced, stemming from factors such as rater biases, test design, and rating scales. These biases can impact the consistency and objectivity of human ratings. GPT-based AES may benefit from its ability to apply consistent and objective evaluation criteria. By prompting the GPT model with detailed writing scoring rubrics and linguistic features, potential biases in human ratings can be mitigated. The model follows a predefined set of guidelines and does not possess the same subjective biases that human raters may exhibit. This standardization in the evaluation process contributes to the higher agreement observed between GPT-4 and human scoring. Section Prompt strategy of the study delves further into the role of prompts in the application of LLMs to AES. It explores how the choice and implementation of prompts can impact the performance and reliability of LLM-based AES methods. Furthermore, it is important to acknowledge the strengths of the local model, i.e. the Japanese local model OCLL, which excels in processing certain idiomatic expressions. Nevertheless, our analysis indicated that GPT-4 surpasses local models in AES. This superior performance can be attributed to the larger parameter size of GPT-4, estimated to be between 500 billion and 1 trillion, which exceeds the sizes of both BERT and the local model OCLL.
Prompt strategy
In the context of prompt strategy, Mizumoto and Eguchi ( 2023 ) conducted a study where they applied the GPT-3 model to automatically score English essays in the TOEFL test. They found that the accuracy of the GPT model alone was moderate to fair. However, when they incorporated linguistic measures such as cohesion, syntactic complexity, and lexical features alongside the GPT model, the accuracy significantly improved. This highlights the importance of prompt engineering and providing the model with specific instructions to enhance its performance. In this study, a similar approach was taken to optimize the performance of LLMs. GPT-4, which outperformed BERT and OCLL, was selected as the candidate model. Model 1 was used as the baseline, representing GPT-4 without any additional prompting. Model 2, on the other hand, involved GPT-4 prompted with 16 measures that included scoring criteria, efficient linguistic features for writing assessment, and detailed measurement units and calculation formulas. The remaining models (Models 3 to 18) utilized GPT-4 prompted with individual measures. The performance of these 18 different models was assessed using the output indicators described in Section Criteria (output indicator) . By comparing the performances of these models, the study aimed to understand the impact of prompt engineering on the accuracy and effectiveness of GPT-4 in AES tasks.
| ||
Model 1: GPT-4 | ||
| ||
Model 2: GPT-4 + 17 measures | ||
| ||
Model 3: GPT-4 + MATTR | Model 4: GPT-4 + LD | Model 5: GPT-4 + LS |
Model 6: GPT-4 + MLC | Model 7: GPT-4 + VPT | Model 8: GPT-4 + CT |
Model 9: GPT-4 + DCT | Model 10: GPT-4 + CNT | Model 11: GPT-4 + ACC |
Model 12: GPT-4 + CPC | Model 13: GPT-4 + MDD | Model 14: GPT-4 + SOPT |
Model 15: GPT-4 + SOPK | Model 16: GPT-4 + word2vec | |
Model 17: GPT-4 + IMM | Model 18: GPT-4 + GER |
Based on the PRMSE scores presented in Fig. 4 , it was observed that Model 1, representing GPT-4 without any additional prompting, achieved a fair level of performance. However, Model 2, which utilized GPT-4 prompted with all measures, outperformed all other models in terms of PRMSE score, achieving a score of 0.681. These results indicate that the inclusion of specific measures and prompts significantly enhanced the performance of GPT-4 in AES. Among the measures, syntactic complexity was found to play a particularly significant role in improving the accuracy of GPT-4 in assessing writing quality. Following that, lexical diversity emerged as another important factor contributing to the model’s effectiveness. The study suggests that a well-prompted GPT-4 can serve as a valuable tool to support human assessors in evaluating writing quality. By utilizing GPT-4 as an automated scoring tool, the evaluation biases associated with human raters can be minimized. This has the potential to empower teachers by allowing them to focus on designing writing tasks and guiding writing strategies, while leveraging the capabilities of GPT-4 for efficient and reliable scoring.

PRMSE scores of the 18 AES models.
This study aimed to investigate two main research questions: the feasibility of utilizing LLMs for AES and the impact of prompt engineering on the application of LLMs in AES.
To address the first objective, the study compared the effectiveness of five different models: GPT, BERT, the Japanese local LLM (OCLL), and two conventional machine learning-based AES tools (Jess and JWriter). The PRMSE values indicated that the GPT-4-based method outperformed other LLMs (BERT, OCLL) and linguistic feature-based computational methods (Jess and JWriter) across various writing proficiency criteria. Furthermore, the agreement coefficient between GPT-4 and human scoring surpassed the agreement among human raters themselves, highlighting the potential of using the GPT-4 tool to enhance AES by reducing biases and subjectivity, saving time, labor, and cost, and providing valuable feedback for self-study. Regarding the second goal, the role of prompt design was investigated by comparing 18 models, including a baseline model, a model prompted with all measures, and 16 models prompted with one measure at a time. GPT-4, which outperformed BERT and OCLL, was selected as the candidate model. The PRMSE scores of the models showed that GPT-4 prompted with all measures achieved the best performance, surpassing the baseline and other models.
In conclusion, this study has demonstrated the potential of LLMs in supporting human rating in assessments. By incorporating automation, we can save time and resources while reducing biases and subjectivity inherent in human rating processes. Automated language assessments offer the advantage of accessibility, providing equal opportunities and economic feasibility for individuals who lack access to traditional assessment centers or necessary resources. LLM-based language assessments provide valuable feedback and support to learners, aiding in the enhancement of their language proficiency and the achievement of their goals. This personalized feedback can cater to individual learner needs, facilitating a more tailored and effective language-learning experience.
There are three important areas that merit further exploration. First, prompt engineering requires attention to ensure optimal performance of LLM-based AES across different language types. This study revealed that GPT-4, when prompted with all measures, outperformed models prompted with fewer measures. Therefore, investigating and refining prompt strategies can enhance the effectiveness of LLMs in automated language assessments. Second, it is crucial to explore the application of LLMs in second-language assessment and learning for oral proficiency, as well as their potential in under-resourced languages. Recent advancements in self-supervised machine learning techniques have significantly improved automatic speech recognition (ASR) systems, opening up new possibilities for creating reliable ASR systems, particularly for under-resourced languages with limited data. However, challenges persist in the field of ASR. First, ASR assumes correct word pronunciation for automatic pronunciation evaluation, which proves challenging for learners in the early stages of language acquisition due to diverse accents influenced by their native languages. Accurately segmenting short words becomes problematic in such cases. Second, developing precise audio-text transcriptions for languages with non-native accented speech poses a formidable task. Last, assessing oral proficiency levels involves capturing various linguistic features, including fluency, pronunciation, accuracy, and complexity, which are not easily captured by current NLP technology.
Data availability
The dataset utilized was obtained from the International Corpus of Japanese as a Second Language (I-JAS). The data URLs: [ https://www2.ninjal.ac.jp/jll/lsaj/ihome2.html ].
J-CAT and TTBJ are two computerized adaptive tests used to assess Japanese language proficiency.
SPOT is a specific component of the TTBJ test.
J-CAT: https://www.j-cat2.org/html/ja/pages/interpret.html
SPOT: https://ttbj.cegloc.tsukuba.ac.jp/p1.html#SPOT .
The study utilized a prompt-based GPT-4 model, developed by OpenAI, which has an impressive architecture with 1.8 trillion parameters across 120 layers. GPT-4 was trained on a vast dataset of 13 trillion tokens, using two stages: initial training on internet text datasets to predict the next token, and subsequent fine-tuning through reinforcement learning from human feedback.
https://www2.ninjal.ac.jp/jll/lsaj/ihome2-en.html .
http://jhlee.sakura.ne.jp/JEV/ by Japanese Learning Dictionary Support Group 2015.
We express our sincere gratitude to the reviewer for bringing this matter to our attention.
On February 7, 2023, Microsoft began rolling out a major overhaul to Bing that included a new chatbot feature based on OpenAI’s GPT-4 (Bing.com).
Appendix E-F present the analysis results of the QWK coefficient between the scores computed by the human raters and the BERT, OCLL models.
Attali Y, Burstein J (2006) Automated essay scoring with e-rater® V.2. J. Technol., Learn. Assess., 4
Barkaoui K, Hadidi A (2020) Assessing Change in English Second Language Writing Performance (1st ed.). Routledge, New York. https://doi.org/10.4324/9781003092346
Bentz C, Tatyana R, Koplenig A, Tanja S (2016) A comparison between morphological complexity. measures: Typological data vs. language corpora. In Proceedings of the workshop on computational linguistics for linguistic complexity (CL4LC), 142–153. Osaka, Japan: The COLING 2016 Organizing Committee
Bond TG, Yan Z, Heene M (2021) Applying the Rasch model: Fundamental measurement in the human sciences (4th ed). Routledge
Brants T (2000) Inter-annotator agreement for a German newspaper corpus. Proceedings of the Second International Conference on Language Resources and Evaluation (LREC’00), Athens, Greece, 31 May-2 June, European Language Resources Association
Brown TB, Mann B, Ryder N, et al. (2020) Language models are few-shot learners. Advances in Neural Information Processing Systems, Online, 6–12 December, Curran Associates, Inc., Red Hook, NY
Burstein J (2003) The E-rater scoring engine: Automated essay scoring with natural language processing. In Shermis MD and Burstein JC (ed) Automated Essay Scoring: A Cross-Disciplinary Perspective. Lawrence Erlbaum Associates, Mahwah, NJ
Čech R, Miroslav K (2018) Morphological richness of text. In Masako F, Václav C (ed) Taming the corpus: From inflection and lexis to interpretation, 63–77. Cham, Switzerland: Springer Nature
Çöltekin Ç, Taraka, R (2018) Exploiting Universal Dependencies treebanks for measuring morphosyntactic complexity. In Aleksandrs B, Christian B (ed), Proceedings of first workshop on measuring language complexity, 1–7. Torun, Poland
Crossley SA, Cobb T, McNamara DS (2013) Comparing count-based and band-based indices of word frequency: Implications for active vocabulary research and pedagogical applications. System 41:965–981. https://doi.org/10.1016/j.system.2013.08.002
Article Google Scholar
Crossley SA, McNamara DS (2016) Say more and be more coherent: How text elaboration and cohesion can increase writing quality. J. Writ. Res. 7:351–370
CyberAgent Inc (2023) Open-Calm series of Japanese language models. Retrieved from: https://www.cyberagent.co.jp/news/detail/id=28817
Devlin J, Chang MW, Lee K, Toutanova K (2019) BERT: Pre-training of deep bidirectional transformers for language understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, Minnesota, 2–7 June, pp. 4171–4186. Association for Computational Linguistics
Diez-Ortega M, Kyle K (2023) Measuring the development of lexical richness of L2 Spanish: a longitudinal learner corpus study. Studies in Second Language Acquisition 1-31
Eckes T (2009) On common ground? How raters perceive scoring criteria in oral proficiency testing. In Brown A, Hill K (ed) Language testing and evaluation 13: Tasks and criteria in performance assessment (pp. 43–73). Peter Lang Publishing
Elliot S (2003) IntelliMetric: from here to validity. In: Shermis MD, Burstein JC (ed) Automated Essay Scoring: A Cross-Disciplinary Perspective. Lawrence Erlbaum Associates, Mahwah, NJ
Google Scholar
Engber CA (1995) The relationship of lexical proficiency to the quality of ESL compositions. J. Second Lang. Writ. 4:139–155
Garner J, Crossley SA, Kyle K (2019) N-gram measures and L2 writing proficiency. System 80:176–187. https://doi.org/10.1016/j.system.2018.12.001
Haberman SJ (2008) When can subscores have value? J. Educat. Behav. Stat., 33:204–229
Haberman SJ, Yao L, Sinharay S (2015) Prediction of true test scores from observed item scores and ancillary data. Brit. J. Math. Stat. Psychol. 68:363–385
Halliday MAK (1985) Spoken and Written Language. Deakin University Press, Melbourne, Australia
Hirao R, Arai M, Shimanaka H et al. (2020) Automated essay scoring system for nonnative Japanese learners. Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), pp. 1250–1257. European Language Resources Association
Hunt KW (1966) Recent Measures in Syntactic Development. Elementary English, 43(7), 732–739. http://www.jstor.org/stable/41386067
Ishioka T (2001) About e-rater, a computer-based automatic scoring system for essays [Konpyūta ni yoru essei no jidō saiten shisutemu e − rater ni tsuite]. University Entrance Examination. Forum [Daigaku nyūshi fōramu] 24:71–76
Hochreiter S, Schmidhuber J (1997) Long short- term memory. Neural Comput. 9(8):1735–1780
Article CAS PubMed Google Scholar
Ishioka T, Kameda M (2006) Automated Japanese essay scoring system based on articles written by experts. Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 17–18 July 2006, pp. 233-240. Association for Computational Linguistics, USA
Japan Foundation (2021) Retrieved from: https://www.jpf.gp.jp/j/project/japanese/survey/result/dl/survey2021/all.pdf
Jarvis S (2013a) Defining and measuring lexical diversity. In Jarvis S, Daller M (ed) Vocabulary knowledge: Human ratings and automated measures (Vol. 47, pp. 13–44). John Benjamins. https://doi.org/10.1075/sibil.47.03ch1
Jarvis S (2013b) Capturing the diversity in lexical diversity. Lang. Learn. 63:87–106. https://doi.org/10.1111/j.1467-9922.2012.00739.x
Jiang J, Quyang J, Liu H (2019) Interlanguage: A perspective of quantitative linguistic typology. Lang. Sci. 74:85–97
Kim M, Crossley SA, Kyle K (2018) Lexical sophistication as a multidimensional phenomenon: Relations to second language lexical proficiency, development, and writing quality. Mod. Lang. J. 102(1):120–141. https://doi.org/10.1111/modl.12447
Kojima T, Gu S, Reid M et al. (2022) Large language models are zero-shot reasoners. Advances in Neural Information Processing Systems, New Orleans, LA, 29 November-1 December, Curran Associates, Inc., Red Hook, NY
Kyle K, Crossley SA (2015) Automatically assessing lexical sophistication: Indices, tools, findings, and application. TESOL Q 49:757–786
Kyle K, Crossley SA, Berger CM (2018) The tool for the automatic analysis of lexical sophistication (TAALES): Version 2.0. Behav. Res. Methods 50:1030–1046. https://doi.org/10.3758/s13428-017-0924-4
Article PubMed Google Scholar
Kyle K, Crossley SA, Jarvis S (2021) Assessing the validity of lexical diversity using direct judgements. Lang. Assess. Q. 18:154–170. https://doi.org/10.1080/15434303.2020.1844205
Landauer TK, Laham D, Foltz PW (2003) Automated essay scoring and annotation of essays with the Intelligent Essay Assessor. In Shermis MD, Burstein JC (ed), Automated Essay Scoring: A Cross-Disciplinary Perspective. Lawrence Erlbaum Associates, Mahwah, NJ
Landis JR, Koch GG (1977) The measurement of observer agreement for categorical data. Biometrics 159–174
Laufer B, Nation P (1995) Vocabulary size and use: Lexical richness in L2 written production. Appl. Linguist. 16:307–322. https://doi.org/10.1093/applin/16.3.307
Lee J, Hasebe Y (2017) jWriter Learner Text Evaluator, URL: https://jreadability.net/jwriter/
Lee J, Kobayashi N, Sakai T, Sakota K (2015) A Comparison of SPOT and J-CAT Based on Test Analysis [Tesuto bunseki ni motozuku ‘SPOT’ to ‘J-CAT’ no hikaku]. Research on the Acquisition of Second Language Japanese [Dainigengo to shite no nihongo no shūtoku kenkyū] (18) 53–69
Li W, Yan J (2021) Probability distribution of dependency distance based on a Treebank of. Japanese EFL Learners’ Interlanguage. J. Quant. Linguist. 28(2):172–186. https://doi.org/10.1080/09296174.2020.1754611
Article MathSciNet Google Scholar
Linacre JM (2002) Optimizing rating scale category effectiveness. J. Appl. Meas. 3(1):85–106
PubMed Google Scholar
Linacre JM (1994) Constructing measurement with a Many-Facet Rasch Model. In Wilson M (ed) Objective measurement: Theory into practice, Volume 2 (pp. 129–144). Norwood, NJ: Ablex
Liu H (2008) Dependency distance as a metric of language comprehension difficulty. J. Cognitive Sci. 9:159–191
Liu H, Xu C, Liang J (2017) Dependency distance: A new perspective on syntactic patterns in natural languages. Phys. Life Rev. 21. https://doi.org/10.1016/j.plrev.2017.03.002
Loukina A, Madnani N, Cahill A, et al. (2020) Using PRMSE to evaluate automated scoring systems in the presence of label noise. Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications, Seattle, WA, USA → Online, 10 July, pp. 18–29. Association for Computational Linguistics
Lu X (2010) Automatic analysis of syntactic complexity in second language writing. Int. J. Corpus Linguist. 15:474–496
Lu X (2012) The relationship of lexical richness to the quality of ESL learners’ oral narratives. Mod. Lang. J. 96:190–208
Lu X (2017) Automated measurement of syntactic complexity in corpus-based L2 writing research and implications for writing assessment. Lang. Test. 34:493–511
Lu X, Hu R (2022) Sense-aware lexical sophistication indices and their relationship to second language writing quality. Behav. Res. Method. 54:1444–1460. https://doi.org/10.3758/s13428-021-01675-6
Ministry of Health, Labor, and Welfare of Japan (2022) Retrieved from: https://www.mhlw.go.jp/stf/newpage_30367.html
Mizumoto A, Eguchi M (2023) Exploring the potential of using an AI language model for automated essay scoring. Res. Methods Appl. Linguist. 3:100050
Okgetheng B, Takeuchi K (2024) Estimating Japanese Essay Grading Scores with Large Language Models. Proceedings of 30th Annual Conference of the Language Processing Society in Japan, March 2024
Ortega L (2015) Second language learning explained? SLA across 10 contemporary theories. In VanPatten B, Williams J (ed) Theories in Second Language Acquisition: An Introduction
Rae JW, Borgeaud S, Cai T, et al. (2021) Scaling Language Models: Methods, Analysis & Insights from Training Gopher. ArXiv, abs/2112.11446
Read J (2000) Assessing vocabulary. Cambridge University Press. https://doi.org/10.1017/CBO9780511732942
Rudner LM, Liang T (2002) Automated Essay Scoring Using Bayes’ Theorem. J. Technol., Learning and Assessment, 1 (2)
Sakoda K, Hosoi Y (2020) Accuracy and complexity of Japanese Language usage by SLA learners in different learning environments based on the analysis of I-JAS, a learners’ corpus of Japanese as L2. Math. Linguist. 32(7):403–418. https://doi.org/10.24701/mathling.32.7_403
Suzuki N (1999) Summary of survey results regarding comprehensive essay questions. Final report of “Joint Research on Comprehensive Examinations for the Aim of Evaluating Applicability to Each Specialized Field of Universities” for 1996-2000 [shōronbun sōgō mondai ni kansuru chōsa kekka no gaiyō. Heisei 8 - Heisei 12-nendo daigaku no kaku senmon bun’ya e no tekisei no hyōka o mokuteki to suru sōgō shiken no arikata ni kansuru kyōdō kenkyū’ saishū hōkoku-sho]. University Entrance Examination Section Center Research and Development Department [Daigaku nyūshi sentā kenkyū kaihatsubu], 21–32
Taghipour K, Ng HT (2016) A neural approach to automated essay scoring. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, Texas, 1–5 November, pp. 1882–1891. Association for Computational Linguistics
Takeuchi K, Ohno M, Motojin K, Taguchi M, Inada Y, Iizuka M, Abo T, Ueda H (2021) Development of essay scoring methods based on reference texts with construction of research-available Japanese essay data. In IPSJ J 62(9):1586–1604
Ure J (1971) Lexical density: A computational technique and some findings. In Coultard M (ed) Talking about Text. English Language Research, University of Birmingham, Birmingham, England
Vaswani A, Shazeer N, Parmar N, et al. (2017) Attention is all you need. In Advances in Neural Information Processing Systems, Long Beach, CA, 4–7 December, pp. 5998–6008, Curran Associates, Inc., Red Hook, NY
Watanabe H, Taira Y, Inoue Y (1988) Analysis of essay evaluation data [Shōronbun hyōka dēta no kaiseki]. Bulletin of the Faculty of Education, University of Tokyo [Tōkyōdaigaku kyōiku gakubu kiyō], Vol. 28, 143–164
Yao S, Yu D, Zhao J, et al. (2023) Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36
Zenker F, Kyle K (2021) Investigating minimum text lengths for lexical diversity indices. Assess. Writ. 47:100505. https://doi.org/10.1016/j.asw.2020.100505
Zhang Y, Warstadt A, Li X, et al. (2021) When do you need billions of words of pretraining data? Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, pp. 1112-1125. Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.acl-long.90
Download references
This research was funded by National Foundation of Social Sciences (22BYY186) to Wenchao Li.
Author information
Authors and affiliations.
Department of Japanese Studies, Zhejiang University, Hangzhou, China
Department of Linguistics and Applied Linguistics, Zhejiang University, Hangzhou, China
You can also search for this author in PubMed Google Scholar
Contributions
Wenchao Li is in charge of conceptualization, validation, formal analysis, investigation, data curation, visualization and writing the draft. Haitao Liu is in charge of supervision.
Corresponding author
Correspondence to Wenchao Li .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Ethical approval
Ethical approval was not required as the study did not involve human participants.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplemental material file #1, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Li, W., Liu, H. Applying large language models for automated essay scoring for non-native Japanese. Humanit Soc Sci Commun 11 , 723 (2024). https://doi.org/10.1057/s41599-024-03209-9
Download citation
Received : 02 February 2024
Accepted : 16 May 2024
Published : 03 June 2024
DOI : https://doi.org/10.1057/s41599-024-03209-9
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies

Why some Believe being Gay is Considered a Sin in Certain Religions
This essay is about the belief that being gay is considered a sin in certain religions, exploring the reasons behind this view. It discusses how religious texts, such as those in Christianity, Islam, and Judaism, have been interpreted to condemn homosexuality. The essay also highlights the historical and cultural contexts that influenced these interpretations and how societal norms have reinforced these beliefs. Additionally, it addresses the growing movement within various faith communities advocating for acceptance and inclusivity of LGBTQ+ individuals. By understanding the diverse perspectives on this issue, the essay emphasizes the importance of empathy, respect, and informed dialogue.
How it works
The inquiry into the moral standing of homosexuality is deeply entwined with religious doctrines, cultural mores, and historical milieus. Numerous religious traditions have maintained conventional perspectives on human sexuality, often deeming homosexuality as morally reprehensible. However, delving into the rationale and contexts underlying these convictions is imperative for fostering informed and considerate discourse.
The principal impetus behind the conviction that homosexuality constitutes a sin emanates from sacred scriptures. Notably, within Christianity, passages from the Bible, such as those found in Leviticus and Romans, have been construed to censure same-sex relations.
Leviticus 18:22 articulates, “You shall not lie with a male as with a woman; it is an abomination.” Similarly, Romans 1:26-27 delineates men forsaking natural relations with women in favor of indulging in acts with other men, deemed “shameful.” Throughout history, these scriptures have served as the theological bedrock for numerous Christian denominations, buttressing the notion that homosexuality contravenes divine edicts.
Nevertheless, contextualizing these scriptures within their historical and cultural milieu is imperative. Ancient societies espoused disparate conceptions of sexuality and gender roles compared to contemporary norms. The proscriptions against same-sex relations in these religious texts may have been shaped by imperatives to establish societal order, propagate progeny, and delineate religious communities from neighboring cultures. In light of this backdrop, interpretations of these passages can diverge markedly, with contemporary theologians and scholars positing that they do not necessarily pertain to loving, consensual same-sex relationships as understood in modern times.
Beyond Christianity, other religious traditions likewise proffer teachings addressing homosexuality. In Islam, for instance, the Quran recounts the saga of the people of Lot, who faced retribution for engaging in homosexual acts. Many Islamic scholars have construed this narrative as corroborative evidence of the sinful nature of homosexuality. Likewise, traditional Jewish teachings, rooted in the Torah, mirror the sentiments articulated in the Old Testament of the Bible, censuring homosexual conduct.
Notwithstanding these enduring religious interpretations, a burgeoning movement within various faith communities advocates for a more inclusive and affirming stance towards LGBTQ+ individuals. Advocates contend that the cardinal tenets of their faith—such as love, compassion, and equity—warrant the embrace of all individuals, irrespective of their sexual orientation. This viewpoint is gaining traction, particularly among younger cohorts and progressive religious factions, prompting a reassessment of conventional interpretations of religious scriptures.
In tandem with religious arguments, cultural and societal norms have exerted a profound influence on attitudes towards homosexuality. In numerous cultures, heteronormativity—the presumption that heterosexuality constitutes the default or preferred sexual orientation—has been deeply entrenched. This cultural bias frequently intersects with religious convictions, reinforcing the perception that homosexuality is aberrant or sinful. Over time, these attitudes have been contested by movements championing LGBTQ+ rights, underscoring the imperative of recognizing sexuality as a natural and multifaceted facet of human existence.
Moreover, acknowledging the sway of personal and familial convictions on individuals’ perceptions of homosexuality is crucial. For many individuals, their upbringing and communal teachings wield considerable sway over their conception of moral rectitude. When these convictions become intertwined with one’s identity and sense of belonging, interrogating or revising them can prove to be a multifaceted and emotionally charged endeavor.
In summation, the conviction that homosexuality constitutes a sin is entrenched in a confluence of religious interpretations, historical contexts, and cultural norms. While traditional religious scriptures have been marshaled to validate this stance, there exists an evolving comprehension within numerous faith communities that underscores inclusivity and acceptance. As society advances towards greater recognition of LGBTQ+ rights, it is incumbent upon us to approach this topic with empathy, deference, and a disposition towards substantive dialogue. Appreciating the diverse perspectives on this issue can engender a more inclusive and compassionate world for all.
Cite this page
Why Some Believe Being Gay Is Considered a Sin in Certain Religions. (2024, Jun 01). Retrieved from https://papersowl.com/examples/why-some-believe-being-gay-is-considered-a-sin-in-certain-religions/
"Why Some Believe Being Gay Is Considered a Sin in Certain Religions." PapersOwl.com , 1 Jun 2024, https://papersowl.com/examples/why-some-believe-being-gay-is-considered-a-sin-in-certain-religions/
PapersOwl.com. (2024). Why Some Believe Being Gay Is Considered a Sin in Certain Religions . [Online]. Available at: https://papersowl.com/examples/why-some-believe-being-gay-is-considered-a-sin-in-certain-religions/ [Accessed: 9 Jun. 2024]
"Why Some Believe Being Gay Is Considered a Sin in Certain Religions." PapersOwl.com, Jun 01, 2024. Accessed June 9, 2024. https://papersowl.com/examples/why-some-believe-being-gay-is-considered-a-sin-in-certain-religions/
"Why Some Believe Being Gay Is Considered a Sin in Certain Religions," PapersOwl.com , 01-Jun-2024. [Online]. Available: https://papersowl.com/examples/why-some-believe-being-gay-is-considered-a-sin-in-certain-religions/. [Accessed: 9-Jun-2024]
PapersOwl.com. (2024). Why Some Believe Being Gay Is Considered a Sin in Certain Religions . [Online]. Available at: https://papersowl.com/examples/why-some-believe-being-gay-is-considered-a-sin-in-certain-religions/ [Accessed: 9-Jun-2024]
Don't let plagiarism ruin your grade
Hire a writer to get a unique paper crafted to your needs.

Our writers will help you fix any mistakes and get an A+!
Please check your inbox.
You can order an original essay written according to your instructions.
Trusted by over 1 million students worldwide
1. Tell Us Your Requirements
2. Pick your perfect writer
3. Get Your Paper and Pay
Hi! I'm Amy, your personal assistant!
Don't know where to start? Give me your paper requirements and I connect you to an academic expert.
short deadlines
100% Plagiarism-Free
Certified writers
Purdue Online Writing Lab Purdue OWL® College of Liberal Arts
Welcome to the Purdue Online Writing Lab

Welcome to the Purdue OWL
This page is brought to you by the OWL at Purdue University. When printing this page, you must include the entire legal notice.
Copyright ©1995-2018 by The Writing Lab & The OWL at Purdue and Purdue University. All rights reserved. This material may not be published, reproduced, broadcast, rewritten, or redistributed without permission. Use of this site constitutes acceptance of our terms and conditions of fair use.
The Online Writing Lab at Purdue University houses writing resources and instructional material, and we provide these as a free service of the Writing Lab at Purdue. Students, members of the community, and users worldwide will find information to assist with many writing projects. Teachers and trainers may use this material for in-class and out-of-class instruction.
The Purdue On-Campus Writing Lab and Purdue Online Writing Lab assist clients in their development as writers—no matter what their skill level—with on-campus consultations, online participation, and community engagement. The Purdue Writing Lab serves the Purdue, West Lafayette, campus and coordinates with local literacy initiatives. The Purdue OWL offers global support through online reference materials and services.
A Message From the Assistant Director of Content Development
The Purdue OWL® is committed to supporting students, instructors, and writers by offering a wide range of resources that are developed and revised with them in mind. To do this, the OWL team is always exploring possibilties for a better design, allowing accessibility and user experience to guide our process. As the OWL undergoes some changes, we welcome your feedback and suggestions by email at any time.
Please don't hesitate to contact us via our contact page if you have any questions or comments.
All the best,
Social Media
Facebook twitter.
Scribbr Citation Generator
Accurate APA, MLA, Chicago, and Harvard citations, verified by experts, trusted by millions
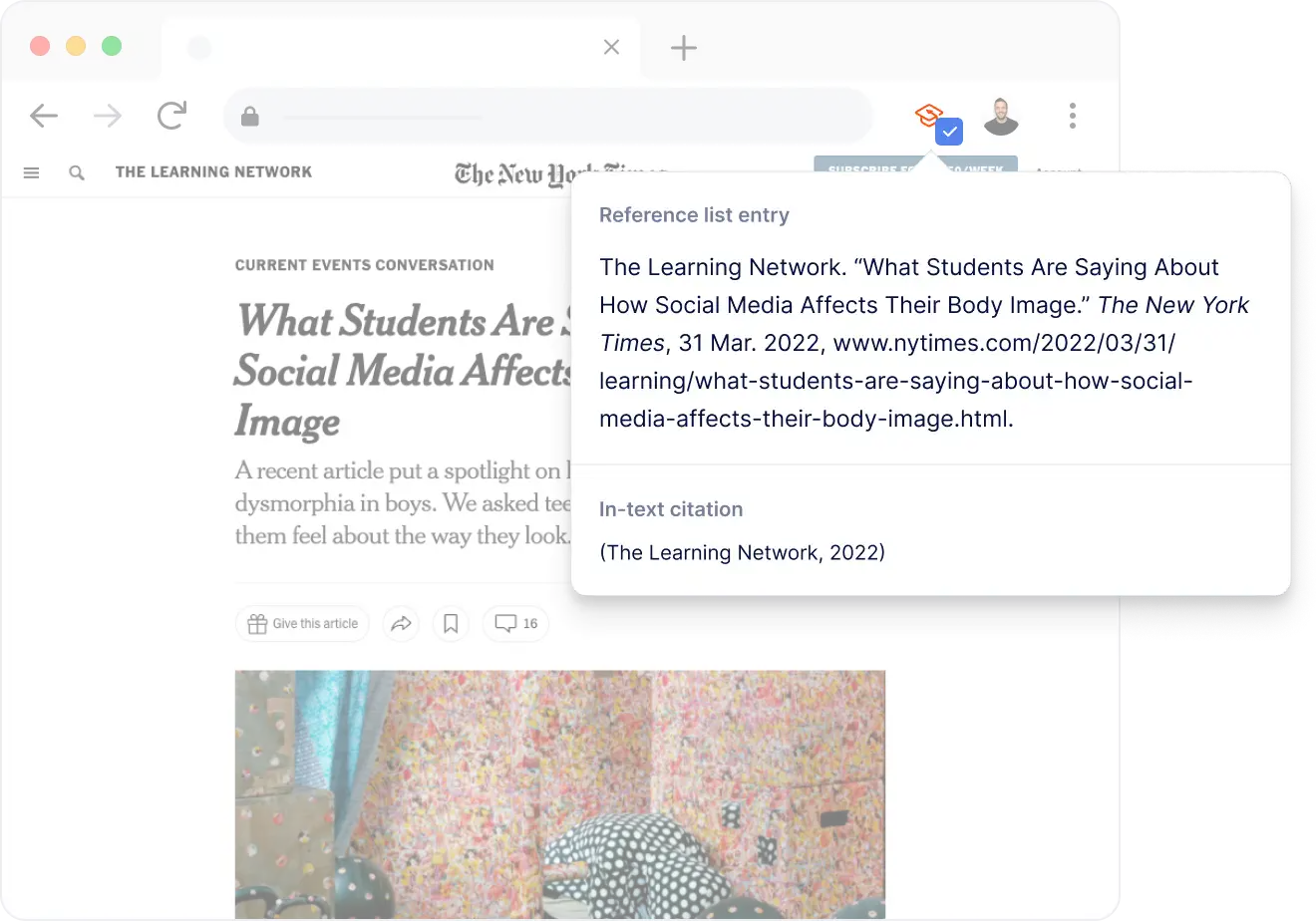
Scribbr for Chrome: Your shortcut to citations
Cite any page or article with a single click right from your browser. The extension does the hard work for you by automatically grabbing the title, author(s), publication date, and everything else needed to whip up the perfect citation.
| ⚙️ Styles | APA, MLA, Chicago, Harvard |
|---|---|
| 📚 Source types | Websites, books, articles |
| 🔎 Autocite | Search by title, URL, DOI, or ISBN |

Perfectly formatted references every time
Inaccurate citations can cost you points on your assignments, so our seasoned citation experts have invested countless hours in perfecting Scribbr’s citation generator algorithms. We’re proud to be recommended by teachers and universities worldwide.
Enjoy a citation generator without flashy ads
Staying focused is already difficult enough, so unlike other citation generators, Scribbr won’t slow you down with flashing banner ads and video pop-ups. That’s a promise!
Citation Generator features you'll love
Look up your source by its title, URL, ISBN, or DOI, and let Scribbr find and fill in all the relevant information automatically.
APA, MLA, Chicago, and Harvard
Generate flawless citations according to the official APA, MLA, Chicago, Harvard style, or many other rules.
Export to Word
When your reference list is complete, export it to Word. We’ll apply the official formatting guidelines automatically.
Lists and folders
Create separate reference lists for each of your assignments to stay organized. You can also group related lists into folders.
Export to Bib(La)TeX
Are you using a LaTex editor like Overleaf? If so, you can easily export your references in Bib(La)TeX format with a single click.
Custom fonts
Change the typeface used for your reference list to match the rest of your document. Options include Times New Roman, Arial, and Calibri.
Industry-standard technology
Scribbr’s Citation Generator is built using the same citation software (CSL) as Mendeley and Zotero, but with an added layer for improved accuracy.
Annotations
Describe or evaluate your sources in annotations, and Scribbr will generate a perfectly formatted annotated bibliography .
Citation guides
Scribbr’s popular guides and videos will help you understand everything related to finding, evaluating, and citing sources.
Secure backup
Your work is saved automatically after every change and stored securely in your Scribbr account.
- Introduction
- Finding sources
Evaluating sources
- Integrating sources
Citing sources
Tools and resources, a quick guide to working with sources.
Working with sources is an important skill that you’ll need throughout your academic career.
It includes knowing how to find relevant sources, assessing their authority and credibility, and understanding how to integrate sources into your work with proper referencing.
This quick guide will help you get started!
Finding relevant sources
Sources commonly used in academic writing include academic journals, scholarly books, websites, newspapers, and encyclopedias. There are three main places to look for such sources:
- Research databases: Databases can be general or subject-specific. To get started, check out this list of databases by academic discipline . Another good starting point is Google Scholar .
- Your institution’s library: Use your library’s database to narrow down your search using keywords to find relevant articles, books, and newspapers matching your topic.
- Other online resources: Consult popular online sources like websites, blogs, or Wikipedia to find background information. Be sure to carefully evaluate the credibility of those online sources.
When using academic databases or search engines, you can use Boolean operators to refine your results.
Generate APA, MLA, Chicago, and Harvard citations in seconds
Get started
In academic writing, your sources should be credible, up to date, and relevant to your research topic. Useful approaches to evaluating sources include the CRAAP test and lateral reading.
CRAAP is an abbreviation that reminds you of a set of questions to ask yourself when evaluating information.
- Currency: Does the source reflect recent research?
- Relevance: Is the source related to your research topic?
- Authority: Is it a respected publication? Is the author an expert in their field?
- Accuracy: Does the source support its arguments and conclusions with evidence?
- Purpose: What is the author’s intention?
Lateral reading
Lateral reading means comparing your source to other sources. This allows you to:
- Verify evidence
- Contextualize information
- Find potential weaknesses
If a source is using methods or drawing conclusions that are incompatible with other research in its field, it may not be reliable.
Integrating sources into your work
Once you have found information that you want to include in your paper, signal phrases can help you to introduce it. Here are a few examples:
| Function | Example sentence | Signal words and phrases |
|---|---|---|
| You present the author’s position neutrally, without any special emphasis. | recent research, food services are responsible for one-third of anthropogenic greenhouse gas emissions. | According to, analyzes, asks, describes, discusses, explains, in the words of, notes, observes, points out, reports, writes |
| A position is taken in agreement with what came before. | Recent research Einstein’s theory of general relativity by observing light from behind a black hole. | Agrees, confirms, endorses, reinforces, promotes, supports |
| A position is taken for or against something, with the implication that the debate is ongoing. | Allen Ginsberg artistic revision … | Argues, contends, denies, insists, maintains |
Following the signal phrase, you can choose to quote, paraphrase or summarize the source.
- Quoting : This means including the exact words of another source in your paper. The quoted text must be enclosed in quotation marks or (for longer quotes) presented as a block quote . Quote a source when the meaning is difficult to convey in different words or when you want to analyze the language itself.
- Paraphrasing : This means putting another person’s ideas into your own words. It allows you to integrate sources more smoothly into your text, maintaining a consistent voice. It also shows that you have understood the meaning of the source.
- Summarizing : This means giving an overview of the essential points of a source. Summaries should be much shorter than the original text. You should describe the key points in your own words and not quote from the original text.
Whenever you quote, paraphrase, or summarize a source, you must include a citation crediting the original author.
Citing your sources is important because it:
- Allows you to avoid plagiarism
- Establishes the credentials of your sources
- Backs up your arguments with evidence
- Allows your reader to verify the legitimacy of your conclusions
The most common citation styles are APA, MLA, and Chicago style. Each citation style has specific rules for formatting citations.
Generate APA, MLA, Chicago, and Harvard citations in seconds
Scribbr offers tons of tools and resources to make working with sources easier and faster. Take a look at our top picks:
- Citation Generator: Automatically generate accurate references and in-text citations using Scribbr’s APA Citation Generator, MLA Citation Generator , Harvard Referencing Generator , and Chicago Citation Generator .
- Plagiarism Checker : Detect plagiarism in your paper using the most accurate Turnitin-powered plagiarism software available to students.
- AI Proofreader: Upload and improve unlimited documents and earn higher grades on your assignments. Try it for free!
- Paraphrasing tool: Avoid accidental plagiarism and make your text sound better.
- Grammar checker : Eliminate pesky spelling and grammar mistakes.
- Summarizer: Read more in less time. Distill lengthy and complex texts down to their key points.
- AI detector: Find out if your text was written with ChatGPT or any other AI writing tool. ChatGPT 2 & ChatGPT 3 supported.
- Proofreading services : Have a human editor improve your writing.
- Citation checker: Check your work for citation errors and missing citations.
- Knowledge Base : Explore hundreds of articles, bite-sized videos, time-saving templates, and handy checklists that guide you through the process of research, writing, and citation.
- Real estate
- Growth and development
- Jobs and careers
- Key Bridge add
- Politics and power add
- Education add
- Community issues add
- Business add
- Culture add
- Opinion add
- Regions add
- Collections add
- Group & enterprise sales
- Customer care
- Contact The Newsroom
- Submit a Tip
- Advertise with us
- Culture & careers
- Newsroom policies & code of ethics
- Creatives in residence
- Sponsored Content
- Impact Maryland
- Subscribe for $1
© 2024 The Baltimore Banner. All Rights Reserved.
Use of this site constitutes acceptance of our Terms of Service and Privacy Policies .
The Baltimore Banner may receive compensation for some links to products and services on this website. Offers may be subject to change without notice. See our Cookie Policy , RSS Terms of Service , Submissions Policy , Ad Choices , Do Not Sell My Personal Information , and CA Notice at Collection at Privacy Notice .
Click here to view our Terms of Sale.
The Baltimore Banner is a trademark registered in the U.S. for The Venetoulis Institute for Local Journalism, a 501(c)(3) nonprofit organization.
Click here to learn more about supporting local journalism.
As Baltimore ends deal with Poppleton developer, the community wants a say on what’s next
:quality(70)/cloudfront-us-east-1.images.arcpublishing.com/baltimorebanner/K7OEQDGURNGAPPYIKOZXUT3VC4.JPG "cite in essay")
West Baltimore residents want houses not high-rises, a long-promised grocery store and garden — and more than anything, a seat at the table with any future developer
This week, Baltimore City said it was unwilling to wait any longer on the redevelopment that New York developer La Cité has been promising for almost 20 years in West Baltimore’s Poppleton neighborhood.
In all that time, La Cité has completed only one project, a 252-unit apartment complex, on the up to 14 acres of land it was supposed to redevelop. A long-promised grocery store hasn’t materialized, nor has the pledge to reinstall a sense of community to a majority-Black neighborhood in distress.
The Baltimore Banner reported that La Cité had missed a deadline last month to show it had the financing to move forward on a residential building for seniors. The developer said it cannot secure financing until the city arranges for a tax incentive funding package. The firm has not responded to a request for an interview.
:format(jpg)/cloudfront-us-east-1.images.arcpublishing.com/baltimorebanner/P2X6APX2FVA3NNUYF7WAA34MQE.JPG "cite in essay")
Housing Commissioner Alice Kennedy on Monday notified the company that it is terminating their agreement for projects beyond the senior building. The move comes after hundreds of Poppleton residents were displaced, blocks of buildings were razed and millions of dollars in government money were spent.
The Baltimore Banner thanks its sponsors. Become one.
Now, the neighbors and community leaders who remain want a say in what happens next.
‘There’s a lack of trust’
“People have been fighting for 20 years, and it feels like they have been fighting against their own government,” said Pastor Brenda White, who has led the Allen African Methodist Episcopal Church in Poppleton in recent years. “I know the work that people have put in to preserve their legacy, their heritage.”
She said she is glad to see Mayor Brandon Scott’s administration begin to disentangle from La Cité. The deal was struck under then-Mayor Martin O’Malley and spanned the administrations of six mayors.
“So many families have had to move away, and they haven’t seen progress,” she said. “People have been told, ‘This is coming and this is coming.’ They haven’t seen it. And so there’s a lack of trust.”
:format(jpg)/cloudfront-us-east-1.images.arcpublishing.com/baltimorebanner/HF3YHLQVKBANVL5LMEZHW3AC2I.JPG "cite in essay")
Going forward, she said she hopes the city will involve the community more deeply. And she said the church’s neighbors weren’t keen on the style La Cité had chosen.
“It’s not that the community is against development. It’s how it’s done. They want houses. They want families to live here,” she said. “They don’t want high-rise. They want houses that blend into the history of the community.”
Still, White pointed to a positive: A few years ago, with help from several local organizations, Poppleton got a pollinator garden on some of its empty land.
When it blooms, White said, “the residents say, the people say, ‘It looks like somebody cares.’”
:format(jpg)/cloudfront-us-east-1.images.arcpublishing.com/baltimorebanner/JF57GNSRDFFATJ6Q33HBWWSMPU.JPG "cite in essay")
‘Forced to be in a state of stagnation’
“This community has been traumatized,” said Tisha Guthrie, the secretary for the Poppleton Now Community Association, pointing out the “Highway to Nowhere” is nearby and Poppleton is one of many parts of West Baltimore where long, systemic disadvantages have not been redressed.
Guthrie said she is a lifelong Baltimore resident and moved to Poppleton in 2021.
“From the very beginning, the process seemed to be lacking community involvement,” she said. “And the very fact that a developer who had never done any project at this scale ... and him being offered this project, it speaks volumes about how the city values communities like Poppleton and West Baltimore.”
La Cité's president, Dan Bythewood, approached the city in the early 2000s with a plan to transform the neighborhood, which is just a few minutes west of downtown.
After being targeted for redevelopment with little community input, Guthrie said, Poppleton is “being forced to be in a state of stagnation.”
“The neighbors talk about how embarrassing it is to have family and friends come into their community — and their homes, and see the plots of land that are in disrepair,” she said.
:format(jpg)/cloudfront-us-east-1.images.arcpublishing.com/baltimorebanner/QXVJU4UVSBEKDKUBDEIB34U6EU.JPG "cite in essay")
She wants to see the city partner with developers who “have the heart and have the vision to be a part of community, and not say you’re creating a community, which is what we are coming out of, hopefully.”
And she said she wants her young neighbors to have a bigger say.
Her dream for Poppleton: an urban farm that would partner with a local grocer. Poppleton residents have been hearing since 2021 that a grocery store is coming “soon.”
She noted she still carries the reusable grocery bag from the first grocer that committed to the Poppleton project.
“He was excited,” she said. “I don’t know what happened with that.”
:format(jpg)/cloudfront-us-east-1.images.arcpublishing.com/baltimorebanner/VJZVM6V24ZDNPHXSZBBVUHD5BM.JPG "cite in essay")
For West Baltimore native Sonia Eaddy, the city’s termination of its contract with La Cité brought an immediate sense of relief.
“I’ve been on a high,” she said. “I’m like, ‘Whew.’”
She parlayed her years of fighting what she sees as the developer’s empty promises into a long-shot bid to unseat the district’s incumbent city councilman, John Bullock. She hoped the organizing skills she had mastered during her successful fight to save her home from the developer’s grasp would propel her to an unlikely victory.
She placed second in a four-way race for the seat in the primary election last month.
Although she said she in encouraged by the city’s action this week, she also said it’s too soon for a victory lap. The community has been down this road before, she noted. About a decade ago the city lost a lawsuit when it attempted to end its contract with La Cité.
“I’m wanting to get a little more understanding of what this means,” Eaddy said, “so that we don’t get all excited and then find out, no, it doesn’t mean ‘this.’”
More From The Banner
:format(jpg)/cloudfront-us-east-1.images.arcpublishing.com/baltimorebanner/6BZGYSVHCNBY7PAEXNXWGDGHSY.jpg "cite in essay")
Baltimore County is waging a war against tiny flies in the Back River area— and winning
:format(jpg)/cloudfront-us-east-1.images.arcpublishing.com/baltimorebanner/W4OUNM36ABEDZN4ZPTVIAE3JKE.JPG "cite in essay")
Beloved restaurateur Qayum Karzai, owner of The Helmand, dies at 77
:format(jpg)/cloudfront-us-east-1.images.arcpublishing.com/baltimorebanner/CV5GWVQWCZCCJA3BMNEP2ZCO2E.jpg "cite in essay")
Almost 6,000 dead in 6 years: How Baltimore became the U.S. overdose capital
:format(jpg)/cloudfront-us-east-1.images.arcpublishing.com/baltimorebanner/Z4QNLB5325DN7BR44WUDYXPENM.jpg "cite in essay")
Marilyn Mosby spared prison time in fraud and perjury case, must forfeit vacation home
COMMENTS
APA Citation Basics. When using APA format, follow the author-date method of in-text citation. This means that the author's last name and the year of publication for the source should appear in the text, like, for example, (Jones, 1998). One complete reference for each source should appear in the reference list at the end of the paper.
When you cite a work that appears inside a larger source (for instance, an article in a periodical or an essay in a collection), cite the author of the internal source (i.e., the article or essay). For example, to cite Albert Einstein's article "A Brief Outline of the Theory of Relativity," which was published in Nature in 1921, you might write ...
At college level, you must properly cite your sources in all essays, research papers, and other academic texts (except exams and in-class exercises). Add a citation whenever you quote, paraphrase, or summarize information or ideas from a source. You should also give full source details in a bibliography or reference list at the end of your text.
Create manual citation. The guidelines for citing an essay in MLA format are similar to those for citing a chapter in a book. Include the author of the essay, the title of the essay, the name of the collection if the essay belongs to one, the editor of the collection or other contributors, the publication information, and the page number (s).
You must first cite each source in the body of your essay; these citations within the essay are called in-text citations. You MUST cite all quoted, paraphrased, or summarized words, ideas, and facts from sources. Without in-text citations, you are technically in danger of plagiarism, even if you have listed your sources at the end of the essay ...
The Chicago/Turabian style of citing sources is generally used when citing sources for humanities papers, and is best known for its requirement that writers place bibliographic citations at the bottom of a page (in Chicago-format footnotes) or at the end of a paper (endnotes). The Turabian and Chicago citation styles are almost identical, but ...
General guidelines for referring to the works of others in your essay Author/Authors How to refer to authors in-text, including single and multiple authors, unknown authors, organizations, etc. Reference List. Resources on writing an APA style reference list, including citation formats
An MLA in-text citation provides the author's last name and a page number in parentheses. If a source has two authors, name both. If a source has more than two authors, name only the first author, followed by " et al. ". If the part you're citing spans multiple pages, include the full page range. If you want to cite multiple non ...
Throughout your paper, you need to apply the following APA format guidelines: Set page margins to 1 inch on all sides. Double-space all text, including headings. Indent the first line of every paragraph 0.5 inches. Use an accessible font (e.g., Times New Roman 12pt., Arial 11pt., or Georgia 11pt.).
In-text citations are covered in the seventh edition APA Style manuals in the Publication Manual Chapter 8 and the Concise Guide Chapter 8. Date created: September 2019. APA Style provides guidelines to help writers determine the appropriate level of citation and how to avoid plagiarism and self-plagiarism. We also provide specific guidance for ...
In Harvard style, citations appear in brackets in the text. An in-text citation consists of the last name of the author, the year of publication, and a page number if relevant. Up to three authors are included in Harvard in-text citations. If there are four or more authors, the citation is shortened with et al. Harvard in-text citation examples.
The following are guidelines to follow when writing in-text citations: Ensure that the spelling of author names and the publication dates in reference list entries match those in the corresponding in-text citations. Cite only works that you have read and ideas that you have incorporated into your writing. The works you cite may provide key ...
In-text citations. Using references in text. For APA, you use the authors' surnames only and the year in text. If you are using a direct quote, you will also need to use a page number. Narrative citations: If an in-text citation has the authors' names as part of the sentence (that is, outside of brackets) place the year and page numbers in ...
When citing sources in the text of your paper, you must list: The author's last name. The year the information was published. Types of In-Text Citations: Narrative vs Parenthetical. A narrative citation gives the author's name as part of the sentence. Example of a Narrative Citation: According to Edwards (2017), although Smith and Carlos's ...
2. List the title of the essay in quotation marks. After the author's name, type the title of the essay in title case, capitalizing the first word and all nouns, pronouns, adjectives, adverbs, and verbs in the title. Place a period at the end of the title, inside the closing quotation marks. [2] Example: Potter, Harry.
In APA, you must "cite" sources that you have paraphrased, quoted or otherwise used to write your research paper. Cite your sources in two places: ... Essay Format: Font - While you still can use Times New Roman 12, you are free to use other fonts. Calibri 11, Arial 11, Lucida Sans 10, and Georgia 11 are all acceptable.
These citations within the essay are called in-text citations. You must cite all quoted, paraphrased, or summarized words, ideas, and facts from sources. Without in-text citations, you are in danger of plagiarism, even if you have listed your sources at the end of the essay. In-text citations point the reader to the sources' information in ...
On the first line of the page, write the section label "References" (in bold and centered). On the second line, start listing your references in alphabetical order. Apply these formatting guidelines to the APA reference page: Double spacing (within and between references) Hanging indent of ½ inch.
Our APA generator was built with a focus on simplicity and speed. To generate a formatted reference list or bibliography just follow these steps: Start by searching for the source you want to cite in the search box at the top of the page. MyBib will automatically locate all the required information. If any is missing you can add it yourself.
Enter the website's URL into the search box above. You'll get a list of results, so you can identify and choose the correct source you want to cite. It's that easy to begin! If you're wondering how to cite a website in APA, use the structure below. Structure: Author Last Name, First initial.
Common sources for stock images and clip art are iStock, Getty Images, Adobe Stock, Shutterstock, Pixabay, and Flickr. Common sources for clip art are Microsoft Word and Microsoft PowerPoint. The license associated with the clip art or stock image determines how it should be credited. Sometimes the license indicates no reference or attribution ...
In the case of a group project, list all names of the contributors, giving each name its own line in the header, followed by the remaining MLA header requirements as described below. Format the remainder of the page as requested by the instructor. In the upper left-hand corner of the first page, list your name, your instructor's name, the ...
Book/Printed Material. The edge of objectivity : an essay in the history of scientific ideas Reprint. Originally published: 1960. Includes bibliographical references and index. Contributor: Gillispie, Charles Coulston - Porter, Theodore M. Date: 2016. Book/Printed Material. A master of science history : essays in honor of Charles Coulston ...
How to Cite Sources | Citation Generator & Quick Guide. Citing your sources is essential in academic writing.Whenever you quote or paraphrase a source (such as a book, article, or webpage), you have to include a citation crediting the original author.. Failing to properly cite your sources counts as plagiarism, since you're presenting someone else's ideas as if they were your own.
Initially, a TTR is determined for words 1-50 in an essay, followed by words 2-51, 3-52, and so on until the end of the essay is reached (Díez-Ortega and Kyle, 2023). The final MATTR scores ...
Essay Example: The inquiry into the moral standing of homosexuality is deeply entwined with religious doctrines, cultural mores, and historical milieus. Numerous religious traditions have maintained conventional perspectives on human sexuality, often deeming homosexuality as morally reprehensible ... Cite this. Summary. This essay is about the ...
Mission. The Purdue On-Campus Writing Lab and Purdue Online Writing Lab assist clients in their development as writers—no matter what their skill level—with on-campus consultations, online participation, and community engagement. The Purdue Writing Lab serves the Purdue, West Lafayette, campus and coordinates with local literacy initiatives.
Citation Generator: Automatically generate accurate references and in-text citations using Scribbr's APA Citation Generator, MLA Citation Generator, Harvard Referencing Generator, and Chicago Citation Generator. Plagiarism Checker: Detect plagiarism in your paper using the most accurate Turnitin-powered plagiarism software available to students.
Now, the neighbors and community leaders who remain want a say in what happens next. 'There's a lack of trust' "People have been fighting for 20 years, and it feels like they have been fighting against their own government," said Pastor Brenda White, who has led the Allen African Methodist Episcopal Church in Poppleton in recent years.
Jump to essay-10 United States v. Nixon, 418 U.S. 683, 710 (1974). Jump to essay-11 Id. at 711. Jump to essay-12 In re Sealed Case, 121 F.3d 729, 746 (D.C. Cir. 1997). Given its broad scope, the Deliberative Process Privilege is the most frequent form of executive privilege raised. Id. at 737.