Stop doing your research essay wrong way!
Writing a research paper: devil in details..
Another task from a professor made you devastated and lost? Of course, because it's something that no one likes to do. Especially a young student who obviously have dozens of other important things to do. What task we are talking about? The monotonous and long, time consuming and confusing one. Yes, it's all about writing a research paper! Why students don't like it? Well, let's see.
First, the job requires a lot of time necessary for searching, reading, comparing, analyzing and then put together. Finding a topic and the data to do a research is just 30% of the task. The major part is to put everything in a proper format. For example, create a suitable and captivating research paper introduction to arouse your professor interest.
Second, it's the efforts to make everything correct and according to requirements. You don't write make a composition with your thoughts and conclusions in chaotic way. You need to make APA research paper to show your knowledge and proficiency. It takes time as well.
Third, it's the amount of workload. Looking for data, then finding the necessary parts, trying to put everything in a proper order and format. Isn't it easier just to have someone doing it for you?

Research essay: 5 steps to success!
Everyone wants to be a great student. Taking major part in college life, getting straight As, being helpful and easy-going. But what if you need help yourself? For instance, with your research essay. How to get it done and not to be exhausted? Here are some tips to help you!
- Calculate you time right. You'll never be able to finish a task overnight, so don't attempt to make a worthy writing when the deadline is tomorrow. Usually the task to write a paper is given long before the actual deadline.
- Choose the topic correctly. You won't be enjoying your work if you don't like the subject. In every task, even the most boring one, there might be something interesting for you. Be creative. Think outside the box. It might be the key to tremendous success!
- Acknowledge that it's time to give in. If you tried and then you failed, there might be other solutions. Like typing in Google "write my paper for me" and be relieved of the burden of the task.
- Divide the whole work into small tasks and steps. Let's face the truth, no one is able to compose the whole essay at one try. Little by little you'll get to the end of the task, but doing it gradually. And keep in mind the advise number 1!
- Rest! Don't stay in front of your PC until your eyes are red, brain not working, coffee not helping. Have a little walk outside, distract yourself from constant work. After that you'll be able to come back to the task with a new wave of energy.
Always check your paper.
No matter what you decide - to make the writing yourself or use professional service to do the task - keep in mind one general rule! Always check the essay to make sure there are no mistakes. There would be a possibility to make edits after you hand the paper to your professor. Look for spelling mistakes, compare the topic and content, check the format.
A free, AI-powered research tool for scientific literature
- Jean Louise Cohen
- Deep Learning
- Game Theory
New & Improved API for Developers
Introducing semantic reader in beta.
Stay Connected With Semantic Scholar Sign Up What Is Semantic Scholar? Semantic Scholar is a free, AI-powered research tool for scientific literature, based at Ai2.
Unfortunately we don't fully support your browser. If you have the option to, please upgrade to a newer version or use Mozilla Firefox , Microsoft Edge , Google Chrome , or Safari 14 or newer. If you are unable to, and need support, please send us your feedback .
We'd appreciate your feedback. Tell us what you think! opens in new tab/window
Scopus Search
Scopus quickly delivers the information you're looking for from over 92m records. Updated daily, Scopus features state-of-the-art search tools and filters to empower research efficiency.

Increase research efficiency
Having access to comprehensive content and high-quality data is only effective if you can easily find the information you need. Uncovering trends, discovering sources and potential collaborators, and building deeper insights require effective search tools that can identify the right results.
Identify trends for key topics
Scopus’ literature search is built to distill massive amounts of information down to the most relevant documents and information in less time.
With Scopus you can search and filter results in the following ways:
Document search : Search directly from the homepage and use detailed search options to ensure you find the document(s) you want
Author search : Search for a specific author by name or by Open Research and Contributor Identifier ID (ORCID)
Affiliation search : Identify and assess an affiliation’s scholarly output, collaborating institutions and top authors
Advanced search : Narrow the scope of your search using field codes, proximity operators and/or Boolean operators
Refine results : Scopus makes it easy to refine your results list to specific categories of documents
Language interface : The Scopus interface is available in Chinese and Japanese; content is not localized, but you can switch the interface to one of these language options (and switch back to English, the default language) at the bottom of any Scopus page
Quick reference guide
Learn how to easily start your search from the homepage and use all the features in Scopus with this handy Quick Reference Guide.
Download the guide opens in new tab/window .

Learn how Scopus can help your organization achieve its goals.

Related links
- Corrections
Search Help
Get the most out of Google Scholar with some helpful tips on searches, email alerts, citation export, and more.
Finding recent papers
Your search results are normally sorted by relevance, not by date. To find newer articles, try the following options in the left sidebar:
- click "Since Year" to show only recently published papers, sorted by relevance;
- click "Sort by date" to show just the new additions, sorted by date;
- click the envelope icon to have new results periodically delivered by email.
Locating the full text of an article
Abstracts are freely available for most of the articles. Alas, reading the entire article may require a subscription. Here're a few things to try:
- click a library link, e.g., "FindIt@Harvard", to the right of the search result;
- click a link labeled [PDF] to the right of the search result;
- click "All versions" under the search result and check out the alternative sources;
- click "Related articles" or "Cited by" under the search result to explore similar articles.
If you're affiliated with a university, but don't see links such as "FindIt@Harvard", please check with your local library about the best way to access their online subscriptions. You may need to do search from a computer on campus, or to configure your browser to use a library proxy.
Getting better answers
If you're new to the subject, it may be helpful to pick up the terminology from secondary sources. E.g., a Wikipedia article for "overweight" might suggest a Scholar search for "pediatric hyperalimentation".
If the search results are too specific for your needs, check out what they're citing in their "References" sections. Referenced works are often more general in nature.
Similarly, if the search results are too basic for you, click "Cited by" to see newer papers that referenced them. These newer papers will often be more specific.
Explore! There's rarely a single answer to a research question. Click "Related articles" or "Cited by" to see closely related work, or search for author's name and see what else they have written.
Searching Google Scholar
Use the "author:" operator, e.g., author:"d knuth" or author:"donald e knuth".
Put the paper's title in quotations: "A History of the China Sea".
You'll often get better results if you search only recent articles, but still sort them by relevance, not by date. E.g., click "Since 2018" in the left sidebar of the search results page.
To see the absolutely newest articles first, click "Sort by date" in the sidebar. If you use this feature a lot, you may also find it useful to setup email alerts to have new results automatically sent to you.
Note: On smaller screens that don't show the sidebar, these options are available in the dropdown menu labelled "Year" right below the search button.
Select the "Case law" option on the homepage or in the side drawer on the search results page.
It finds documents similar to the given search result.
It's in the side drawer. The advanced search window lets you search in the author, title, and publication fields, as well as limit your search results by date.
Select the "Case law" option and do a keyword search over all jurisdictions. Then, click the "Select courts" link in the left sidebar on the search results page.
Tip: To quickly search a frequently used selection of courts, bookmark a search results page with the desired selection.
Access to articles
For each Scholar search result, we try to find a version of the article that you can read. These access links are labelled [PDF] or [HTML] and appear to the right of the search result. For example:
A paper that you need to read
Access links cover a wide variety of ways in which articles may be available to you - articles that your library subscribes to, open access articles, free-to-read articles from publishers, preprints, articles in repositories, etc.
When you are on a campus network, access links automatically include your library subscriptions and direct you to subscribed versions of articles. On-campus access links cover subscriptions from primary publishers as well as aggregators.
Off-campus access
Off-campus access links let you take your library subscriptions with you when you are at home or traveling. You can read subscribed articles when you are off-campus just as easily as when you are on-campus. Off-campus access links work by recording your subscriptions when you visit Scholar while on-campus, and looking up the recorded subscriptions later when you are off-campus.
We use the recorded subscriptions to provide you with the same subscribed access links as you see on campus. We also indicate your subscription access to participating publishers so that they can allow you to read the full-text of these articles without logging in or using a proxy. The recorded subscription information expires after 30 days and is automatically deleted.
In addition to Google Scholar search results, off-campus access links can also appear on articles from publishers participating in the off-campus subscription access program. Look for links labeled [PDF] or [HTML] on the right hand side of article pages.
Anne Author , John Doe , Jane Smith , Someone Else
In this fascinating paper, we investigate various topics that would be of interest to you. We also describe new methods relevant to your project, and attempt to address several questions which you would also like to know the answer to. Lastly, we analyze …
You can disable off-campus access links on the Scholar settings page . Disabling off-campus access links will turn off recording of your library subscriptions. It will also turn off indicating subscription access to participating publishers. Once off-campus access links are disabled, you may need to identify and configure an alternate mechanism (e.g., an institutional proxy or VPN) to access your library subscriptions while off-campus.
Email Alerts
Do a search for the topic of interest, e.g., "M Theory"; click the envelope icon in the sidebar of the search results page; enter your email address, and click "Create alert". We'll then periodically email you newly published papers that match your search criteria.
No, you can enter any email address of your choice. If the email address isn't a Google account or doesn't match your Google account, then we'll email you a verification link, which you'll need to click to start receiving alerts.
This works best if you create a public profile , which is free and quick to do. Once you get to the homepage with your photo, click "Follow" next to your name, select "New citations to my articles", and click "Done". We will then email you when we find new articles that cite yours.
Search for the title of your paper, e.g., "Anti de Sitter space and holography"; click on the "Cited by" link at the bottom of the search result; and then click on the envelope icon in the left sidebar of the search results page.
First, do a search for your colleague's name, and see if they have a Scholar profile. If they do, click on it, click the "Follow" button next to their name, select "New articles by this author", and click "Done".
If they don't have a profile, do a search by author, e.g., [author:s-hawking], and click on the mighty envelope in the left sidebar of the search results page. If you find that several different people share the same name, you may need to add co-author names or topical keywords to limit results to the author you wish to follow.
We send the alerts right after we add new papers to Google Scholar. This usually happens several times a week, except that our search robots meticulously observe holidays.
There's a link to cancel the alert at the bottom of every notification email.
If you created alerts using a Google account, you can manage them all here . If you're not using a Google account, you'll need to unsubscribe from the individual alerts and subscribe to the new ones.
Google Scholar library
Google Scholar library is your personal collection of articles. You can save articles right off the search page, organize them by adding labels, and use the power of Scholar search to quickly find just the one you want - at any time and from anywhere. You decide what goes into your library, and we’ll keep the links up to date.
You get all the goodies that come with Scholar search results - links to PDF and to your university's subscriptions, formatted citations, citing articles, and more!
Library help
Find the article you want to add in Google Scholar and click the “Save” button under the search result.
Click “My library” at the top of the page or in the side drawer to view all articles in your library. To search the full text of these articles, enter your query as usual in the search box.
Find the article you want to remove, and then click the “Delete” button under it.
- To add a label to an article, find the article in your library, click the “Label” button under it, select the label you want to apply, and click “Done”.
- To view all the articles with a specific label, click the label name in the left sidebar of your library page.
- To remove a label from an article, click the “Label” button under it, deselect the label you want to remove, and click “Done”.
- To add, edit, or delete labels, click “Manage labels” in the left column of your library page.
Only you can see the articles in your library. If you create a Scholar profile and make it public, then the articles in your public profile (and only those articles) will be visible to everyone.
Your profile contains all the articles you have written yourself. It’s a way to present your work to others, as well as to keep track of citations to it. Your library is a way to organize the articles that you’d like to read or cite, not necessarily the ones you’ve written.
Citation Export
Click the "Cite" button under the search result and then select your bibliography manager at the bottom of the popup. We currently support BibTeX, EndNote, RefMan, and RefWorks.
Err, no, please respect our robots.txt when you access Google Scholar using automated software. As the wearers of crawler's shoes and webmaster's hat, we cannot recommend adherence to web standards highly enough.
Sorry, we're unable to provide bulk access. You'll need to make an arrangement directly with the source of the data you're interested in. Keep in mind that a lot of the records in Google Scholar come from commercial subscription services.
Sorry, we can only show up to 1,000 results for any particular search query. Try a different query to get more results.
Content Coverage
Google Scholar includes journal and conference papers, theses and dissertations, academic books, pre-prints, abstracts, technical reports and other scholarly literature from all broad areas of research. You'll find works from a wide variety of academic publishers, professional societies and university repositories, as well as scholarly articles available anywhere across the web. Google Scholar also includes court opinions and patents.
We index research articles and abstracts from most major academic publishers and repositories worldwide, including both free and subscription sources. To check current coverage of a specific source in Google Scholar, search for a sample of their article titles in quotes.
While we try to be comprehensive, it isn't possible to guarantee uninterrupted coverage of any particular source. We index articles from sources all over the web and link to these websites in our search results. If one of these websites becomes unavailable to our search robots or to a large number of web users, we have to remove it from Google Scholar until it becomes available again.
Our meticulous search robots generally try to index every paper from every website they visit, including most major sources and also many lesser known ones.
That said, Google Scholar is primarily a search of academic papers. Shorter articles, such as book reviews, news sections, editorials, announcements and letters, may or may not be included. Untitled documents and documents without authors are usually not included. Website URLs that aren't available to our search robots or to the majority of web users are, obviously, not included either. Nor do we include websites that require you to sign up for an account, install a browser plugin, watch four colorful ads, and turn around three times and say coo-coo before you can read the listing of titles scanned at 10 DPI... You get the idea, we cover academic papers from sensible websites.
That's usually because we index many of these papers from other websites, such as the websites of their primary publishers. The "site:" operator currently only searches the primary version of each paper.
It could also be that the papers are located on examplejournals.gov, not on example.gov. Please make sure you're searching for the "right" website.
That said, the best way to check coverage of a specific source is to search for a sample of their papers using the title of the paper.
Ahem, we index papers, not journals. You should also ask about our coverage of universities, research groups, proteins, seminal breakthroughs, and other dimensions that are of interest to users. All such questions are best answered by searching for a statistical sample of papers that has the property of interest - journal, author, protein, etc. Many coverage comparisons are available if you search for [allintitle:"google scholar"], but some of them are more statistically valid than others.
Currently, Google Scholar allows you to search and read published opinions of US state appellate and supreme court cases since 1950, US federal district, appellate, tax and bankruptcy courts since 1923 and US Supreme Court cases since 1791. In addition, it includes citations for cases cited by indexed opinions or journal articles which allows you to find influential cases (usually older or international) which are not yet online or publicly available.
Legal opinions in Google Scholar are provided for informational purposes only and should not be relied on as a substitute for legal advice from a licensed lawyer. Google does not warrant that the information is complete or accurate.
We normally add new papers several times a week. However, updates to existing records take 6-9 months to a year or longer, because in order to update our records, we need to first recrawl them from the source website. For many larger websites, the speed at which we can update their records is limited by the crawl rate that they allow.
Inclusion and Corrections
We apologize, and we assure you the error was unintentional. Automated extraction of information from articles in diverse fields can be tricky, so an error sometimes sneaks through.
Please write to the owner of the website where the erroneous search result is coming from, and encourage them to provide correct bibliographic data to us, as described in the technical guidelines . Once the data is corrected on their website, it usually takes 6-9 months to a year or longer for it to be updated in Google Scholar. We appreciate your help and your patience.
If you can't find your papers when you search for them by title and by author, please refer your publisher to our technical guidelines .
You can also deposit your papers into your institutional repository or put their PDF versions on your personal website, but please follow your publisher's requirements when you do so. See our technical guidelines for more details on the inclusion process.
We normally add new papers several times a week; however, it might take us some time to crawl larger websites, and corrections to already included papers can take 6-9 months to a year or longer.
Google Scholar generally reflects the state of the web as it is currently visible to our search robots and to the majority of users. When you're searching for relevant papers to read, you wouldn't want it any other way!
If your citation counts have gone down, chances are that either your paper or papers that cite it have either disappeared from the web entirely, or have become unavailable to our search robots, or, perhaps, have been reformatted in a way that made it difficult for our automated software to identify their bibliographic data and references. If you wish to correct this, you'll need to identify the specific documents with indexing problems and ask your publisher to fix them. Please refer to the technical guidelines .
Please do let us know . Please include the URL for the opinion, the corrected information and a source where we can verify the correction.
We're only able to make corrections to court opinions that are hosted on our own website. For corrections to academic papers, books, dissertations and other third-party material, click on the search result in question and contact the owner of the website where the document came from. For corrections to books from Google Book Search, click on the book's title and locate the link to provide feedback at the bottom of the book's page.
General Questions
These are articles which other scholarly articles have referred to, but which we haven't found online. To exclude them from your search results, uncheck the "include citations" box on the left sidebar.
First, click on links labeled [PDF] or [HTML] to the right of the search result's title. Also, check out the "All versions" link at the bottom of the search result.
Second, if you're affiliated with a university, using a computer on campus will often let you access your library's online subscriptions. Look for links labeled with your library's name to the right of the search result's title. Also, see if there's a link to the full text on the publisher's page with the abstract.
Keep in mind that final published versions are often only available to subscribers, and that some articles are not available online at all. Good luck!
Technically, your web browser remembers your settings in a "cookie" on your computer's disk, and sends this cookie to our website along with every search. Check that your browser isn't configured to discard our cookies. Also, check if disabling various proxies or overly helpful privacy settings does the trick. Either way, your settings are stored on your computer, not on our servers, so a long hard look at your browser's preferences or internet options should help cure the machine's forgetfulness.
Not even close. That phrase is our acknowledgement that much of scholarly research involves building on what others have already discovered. It's taken from Sir Isaac Newton's famous quote, "If I have seen further, it is by standing on the shoulders of giants."
- Privacy & Terms
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
- We're Hiring!
- Help Center
Download 55 million PDFs for free
Explore our top research interests.

Engineering

Anthropology

- Earth Sciences

- Computer Science

- Mathematics

- Health Sciences

Join 270 million academics and researchers
Track your impact.
Share your work with other academics, grow your audience and track your impact on your field with our robust analytics
Discover new research
Get access to millions of research papers and stay informed with the important topics around the world
Publish your work
Publish your research with fast and rigorous service through Academia.edu Journals. Get instant worldwide dissemination of your work
Unlock the most powerful tools with Academia Premium

Work faster and smarter with advanced research discovery tools
Search the full text and citations of our millions of papers. Download groups of related papers to jumpstart your research. Save time with detailed summaries and search alerts.
- Advanced Search
- PDF Packages of 37 papers
- Summaries and Search Alerts

Share your work, track your impact, and grow your audience
Get notified when other academics mention you or cite your papers. Track your impact with in-depth analytics and network with members of your field.
- Mentions and Citations Tracking
- Advanced Analytics
- Publishing Tools
Real stories from real people

Used by academics at over 15,000 universities

Get started and find the best quality research
- Academia.edu Journals
- We're Hiring!
- Help Center
- Find new research papers in:
- Cognitive Science
- Academia ©2024
🇺🇦 make metadata, not war
A comprehensive bibliographic database of the world’s scholarly literature
The world’s largest collection of open access research papers, machine access to our vast unique full text corpus, core features, indexing the world’s repositories.
We serve the global network of repositories and journals
Comprehensive data coverage
We provide both metadata and full text access to our comprehensive collection through our APIs and Datasets
Powerful services
We create powerful services for researchers, universities, and industry
Cutting-edge solutions
We research and develop innovative data-driven and AI solutions
Committed to the POSI
Cost-free PIDs for your repository
OAI identifiers are unique identifiers minted cost-free by repositories. Ensure that your repository is correctly configured, enabling the CORE OAI Resolver to redirect your identifiers to your repository landing pages.
OAI IDs provide a cost-free option for assigning Persistent Identifiers (PIDs) to your repository records. Learn more.
Who we serve?
Enabling others to create new tools and innovate using a global comprehensive collection of research papers.

“ Our partnership with CORE will provide Turnitin with vast amounts of metadata and full texts that we can ... ” Show more
Gareth Malcolm, Content Partner Manager at Turnitin
Academic institutions.
Making research more discoverable, improving metadata quality, helping to meet and monitor open access compliance.

“ CORE’s role in providing a unified search of repository content is a great tool for the researcher and ex... ” Show more
Nicola Dowson, Library Services Manager at Open University
Researchers & general public.
Tools to find, discover and explore the wealth of open access research. Free for everyone, forever.

“ With millions of research papers available across thousands of different systems, CORE provides an invalu... ” Show more
Jon Tennant, Rogue Paleontologist and Founder of the Open Science MOOC
Helping funders to analyse, audit and monitor open research and accelerate towards open science.

“ Aggregation plays an increasingly essential role in maximising the long-term benefits of open access, hel... ” Show more
Ben Johnson, Research Policy Adviser at Research England
Our services, access to raw data.
Create new and innovative solutions.
Content discovery
Find relevant research and make your research more visible.
Managing content
Manage how your research content is exposed to the world.
Companies using CORE

Gareth Malcolm
Content Partner Manager at Turnitin
Our partnership with CORE will provide Turnitin with vast amounts of metadata and full texts that we can utilise in our plagiarism detection software.
Academic institution using CORE
Kathleen Shearer
Executive Director of the Confederation of Open Access Repositories (COAR)
CORE has significantly assisted the academic institutions participating in our global network with their key mission, which is their scientific content exposure. In addition, CORE has helped our content administrators to showcase the real benefits of repositories via its added value services.
Partner projects

Ben Johnson
Research Policy Adviser
Aggregation plays an increasingly essential role in maximising the long-term benefits of open access, helping to turn the promise of a 'research commons' into a reality. The aggregation services that CORE provides therefore make a very valuable contribution to the evolving open access environment in the UK.

Reference management. Clean and simple.
Google Scholar: the ultimate guide

What is Google Scholar?
Why is google scholar better than google for finding research papers, the google scholar search results page, the first two lines: core bibliographic information, quick full text-access options, "cited by" count and other useful links, tips for searching google scholar, 1. google scholar searches are not case sensitive, 2. use keywords instead of full sentences, 3. use quotes to search for an exact match, 3. add the year to the search phrase to get articles published in a particular year, 4. use the side bar controls to adjust your search result, 5. use boolean operator to better control your searches, google scholar advanced search interface, customizing search preferences and options, using the "my library" feature in google scholar, the scope and limitations of google scholar, alternatives to google scholar, country-specific google scholar sites, frequently asked questions about google scholar, related articles.
Google Scholar (GS) is a free academic search engine that can be thought of as the academic version of Google. Rather than searching all of the indexed information on the web, it searches repositories of:
- universities
- scholarly websites
This is generally a smaller subset of the pool that Google searches. It's all done automatically, but most of the search results tend to be reliable scholarly sources.
However, Google is typically less careful about what it includes in search results than more curated, subscription-based academic databases like Scopus and Web of Science . As a result, it is important to take some time to assess the credibility of the resources linked through Google Scholar.
➡️ Take a look at our guide on the best academic databases .

One advantage of using Google Scholar is that the interface is comforting and familiar to anyone who uses Google. This lowers the learning curve of finding scholarly information .
There are a number of useful differences from a regular Google search. Google Scholar allows you to:
- copy a formatted citation in different styles including MLA and APA
- export bibliographic data (BibTeX, RIS) to use with reference management software
- explore other works have cited the listed work
- easily find full text versions of the article
Although it is free to search in Google Scholar, most of the content is not freely available. Google does its best to find copies of restricted articles in public repositories. If you are at an academic or research institution, you can also set up a library connection that allows you to see items that are available through your institution.
The Google Scholar results page differs from the Google results page in a few key ways. The search result page is, however, different and it is worth being familiar with the different pieces of information that are shown. Let's have a look at the results for the search term "machine learning.”

- The first line of each result provides the title of the document (e.g. of an article, book, chapter, or report).
- The second line provides the bibliographic information about the document, in order: the author(s), the journal or book it appears in, the year of publication, and the publisher.
Clicking on the title link will bring you to the publisher’s page where you may be able to access more information about the document. This includes the abstract and options to download the PDF.

To the far right of the entry are more direct options for obtaining the full text of the document. In this example, Google has also located a publicly available PDF of the document hosted at umich.edu . Note, that it's not guaranteed that it is the version of the article that was finally published in the journal.

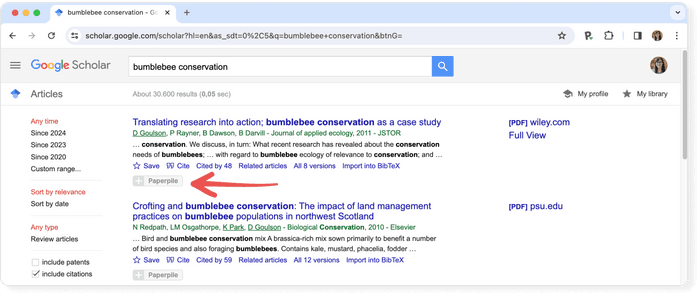
Below the text snippet/abstract you can find a number of useful links.
- Cited by : the cited by link will show other articles that have cited this resource. That is a super useful feature that can help you in many ways. First, it is a good way to track the more recent research that has referenced this article, and second the fact that other researches cited this document lends greater credibility to it. But be aware that there is a lag in publication type. Therefore, an article published in 2017 will not have an extensive number of cited by results. It takes a minimum of 6 months for most articles to get published, so even if an article was using the source, the more recent article has not been published yet.
- Versions : this link will display other versions of the article or other databases where the article may be found, some of which may offer free access to the article.
- Quotation mark icon : this will display a popup with commonly used citation formats such as MLA, APA, Chicago, Harvard, and Vancouver that may be copied and pasted. Note, however, that the Google Scholar citation data is sometimes incomplete and so it is often a good idea to check this data at the source. The "cite" popup also includes links for exporting the citation data as BibTeX or RIS files that any major reference manager can import.

Pro tip: Use a reference manager like Paperpile to keep track of all your sources. Paperpile integrates with Google Scholar and many popular academic research engines and databases, so you can save references and PDFs directly to your library using the Paperpile buttons and later cite them in thousands of citation styles:
Although Google Scholar limits each search to a maximum of 1,000 results , it's still too much to explore, and you need an effective way of locating the relevant articles. Here’s a list of pro tips that will help you save time and search more effectively.
You don’t need to worry about case sensitivity when you’re using Google scholar. In other words, a search for "Machine Learning" will produce the same results as a search for "machine learning.”
Let's say your research topic is about self driving cars. For a regular Google search we might enter something like " what is the current state of the technology used for self driving cars ". In Google Scholar, you will see less than ideal results for this query .
The trick is to build a list of keywords and perform searches for them like self-driving cars, autonomous vehicles, or driverless cars. Google Scholar will assist you on that: if you start typing in the search field you will see related queries suggested by Scholar!
If you put your search phrase into quotes you can search for exact matches of that phrase in the title and the body text of the document. Without quotes, Google Scholar will treat each word separately.
This means that if you search national parks , the words will not necessarily appear together. Grouped words and exact phrases should be enclosed in quotation marks.
A search using “self-driving cars 2015,” for example, will return articles or books published in 2015.
Using the options in the left hand panel you can further restrict the search results by limiting the years covered by the search, the inclusion or exclude of patents, and you can sort the results by relevance or by date.
Searches are not case sensitive, however, there are a number of Boolean operators you can use to control the search and these must be capitalized.
- AND requires both of the words or phrases on either side to be somewhere in the record.
- NOT can be placed in front of a word or phrases to exclude results which include them.
- OR will give equal weight to results which match just one of the words or phrases on either side.
➡️ Read more about how to efficiently search online databases for academic research .
In case you got overwhelmed by the above options, here’s some illustrative examples:
| Example queries | When to use and what will it do? |
|---|---|
"alternative medicine" | Multiword concepts like are best searched as an exact phrase match. Otherwise, Google Scholar will display results that contain and/or . |
"The wisdom of the hive: the social physiology of honey bee colonies" | If you are looking for a particular article and know the title, it is best to put it into quotes to look for an exact match. |
author:"Jane Goodall" | A query for a particular author, e.g., Jane Goodall. "J Goodall" or "Goodall" will also work, but will be less restrictive. |
"self-driving cars" AND "autonomous vehicles" | Only results will be shown that contain both the phrases "self-driving cars" and "autonomous vehicles" |
dinosaur 2014 | Limits search results about dinosaurs to articles that were published in 2014 |
Tip: Use the advanced search features in Google Scholar to narrow down your search results.
You can gain even more fine-grained control over your search by using the advanced search feature. This feature is available by clicking on the hamburger menu in the upper left and selecting the "Advanced search" menu item.

Adjusting the Google Scholar settings is not necessary for getting good results, but offers some additional customization, including the ability to enable the above-mentioned library integrations.
The settings menu is found in the hamburger menu located in the top left of the Google Scholar page. The settings are divided into five sections:
- Collections to search: by default Google scholar searches articles and includes patents, but this default can be changed if you are not interested in patents or if you wish to search case law instead.
- Bibliographic manager: you can export relevant citation data via the “Bibliography manager” subsection.
- Languages: if you wish for results to return only articles written in a specific subset of languages, you can define that here.
- Library links: as noted, Google Scholar allows you to get the Full Text of articles through your institution’s subscriptions, where available. Search for, and add, your institution here to have the relevant link included in your search results.
- Button: the Scholar Button is a Chrome extension which adds a dropdown search box to your toolbar. This allows you to search Google Scholar from any website. Moreover, if you have any text selected on the page and then click the button it will display results from a search on those words when clicked.
When signed in, Google Scholar adds some simple tools for keeping track of and organizing the articles you find. These can be useful if you are not using a full academic reference manager.
All the search results include a “save” button at the end of the bottom row of links, clicking this will add it to your "My Library".
To help you provide some structure, you can create and apply labels to the items in your library. Appended labels will appear at the end of the article titles. For example, the following article has been assigned a “RNA” label:

Within your Google Scholar library, you can also edit the metadata associated with titles. This will often be necessary as Google Scholar citation data is often faulty.
There is no official statement about how big the Scholar search index is, but unofficial estimates are in the range of about 160 million , and it is supposed to continue to grow by several million each year.
Yet, Google Scholar does not return all resources that you may get in search at you local library catalog. For example, a library database could return podcasts, videos, articles, statistics, or special collections. For now, Google Scholar has only the following publication types:
- Journal articles : articles published in journals. It's a mixture of articles from peer reviewed journals, predatory journals and pre-print archives.
- Books : links to the Google limited version of the text, when possible.
- Book chapters : chapters within a book, sometimes they are also electronically available.
- Book reviews : reviews of books, but it is not always apparent that it is a review from the search result.
- Conference proceedings : papers written as part of a conference, typically used as part of presentation at the conference.
- Court opinions .
- Patents : Google Scholar only searches patents if the option is selected in the search settings described above.
The information in Google Scholar is not cataloged by professionals. The quality of the metadata will depend heavily on the source that Google Scholar is pulling the information from. This is a much different process to how information is collected and indexed in scholarly databases such as Scopus or Web of Science .
➡️ Visit our list of the best academic databases .
Google Scholar is by far the most frequently used academic search engine , but it is not the only one. Other academic search engines include:
- Science.gov
- Semantic Scholar
- scholar.google.fr : Sur les épaules d'un géant
- scholar.google.es (Google Académico): A hombros de gigantes
- scholar.google.pt (Google Académico): Sobre os ombros de gigantes
- scholar.google.de : Auf den Schultern von Riesen
➡️ Once you’ve found some research, it’s time to read it. Take a look at our guide on how to read a scientific paper .
No. Google Scholar is a bibliographic search engine rather than a bibliographic database. In order to qualify as a database Google Scholar would need to have stable identifiers for its records.
No. Google Scholar is an academic search engine, but the records found in Google Scholar are scholarly sources.
No. Google Scholar collects research papers from all over the web, including grey literature and non-peer reviewed papers and reports.
Google Scholar does not provide any full text content itself, but links to the full text article on the publisher page, which can either be open access or paywalled content. Google Scholar tries to provide links to free versions, when possible.
The easiest way to access Google scholar is by using The Google Scholar Button. This is a browser extension that allows you easily access Google Scholar from any web page. You can install it from the Chrome Webstore .


An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
PubMed Central (PMC) Home Page
PubMed Central ® (PMC) is a free full-text archive of biomedical and life sciences journal literature at the U.S. National Institutes of Health's National Library of Medicine (NIH/NLM)
Discover a digital archive of scholarly articles, spanning centuries of scientific research.
Learn how to find and read articles of interest to you.
Collections
Browse the PMC Journal List or learn about some of PMC's unique collections.
For Authors
Navigate the PMC submission methods to comply with a funder mandate, expand access, and ensure preservation.
For Publishers
Learn about deposit options for journals and publishers and the PMC selection process.
For Developers
Find tools for bulk download, text mining, and other machine analysis.
10.2 MILLION articles are archived in PMC.
Content provided in part by:, full participation journals.
Journals deposit the complete contents of each issue or volume.
NIH Portfolio Journals
Journals deposit all NIH-funded articles as defined by the NIH Public Access Policy.
Selective Deposit Programs
Publisher deposits a subset of articles from a collection of journals.
March 21, 2024
Preview upcoming improvements to pmc.
We are pleased to announce the availability of a preview of improvements planned for the PMC website. These…
Dec. 15, 2023
Update on pubreader format.
The PubReader format was added to PMC in 2012 to make it easier to read full text articles on tablet, mobile, and oth…

We are pleased to announce the availability of a preview of improvements planned for the PMC website. These improvements will become the default in October 2024.
- Advanced search
- Peer review

Discover relevant research today

Advance your research field in the open

Reach new audiences and maximize your readership
ScienceOpen puts your research in the context of
Publications
For Publishers
ScienceOpen offers content hosting, context building and marketing services for publishers. See our tailored offerings
- For academic publishers to promote journals and interdisciplinary collections
- For open access journals to host journal content in an interactive environment
- For university library publishing to develop new open access paradigms for their scholars
- For scholarly societies to promote content with interactive features
For Institutions
ScienceOpen offers state-of-the-art technology and a range of solutions and services
- For faculties and research groups to promote and share your work
- For research institutes to build up your own branding for OA publications
- For funders to develop new open access publishing paradigms
- For university libraries to create an independent OA publishing environment
For Researchers
Make an impact and build your research profile in the open with ScienceOpen
- Search and discover relevant research in over 95 million Open Access articles and article records
- Share your expertise and get credit by publicly reviewing any article
- Publish your poster or preprint and track usage and impact with article- and author-level metrics
- Create a topical Collection to advance your research field
Create a Journal powered by ScienceOpen
Launching a new open access journal or an open access press? ScienceOpen now provides full end-to-end open access publishing solutions – embedded within our smart interactive discovery environment. A modular approach allows open access publishers to pick and choose among a range of services and design the platform that fits their goals and budget.
Continue reading “Create a Journal powered by ScienceOpen”
What can a Researcher do on ScienceOpen?
ScienceOpen provides researchers with a wide range of tools to support their research – all for free. Here is a short checklist to make sure you are getting the most of the technological infrastructure and content that we have to offer. What can a researcher do on ScienceOpen? Continue reading “What can a Researcher do on ScienceOpen?”
ScienceOpen on the Road
Upcoming events.
- 15 June – Scheduled Server Maintenance, 13:00 – 01:00 CEST
Past Events
- 20 – 22 February – ResearcherToReader Conference
- 09 November – Webinar for the Discoverability of African Research
- 26 – 27 October – Attending the Workshop on Open Citations and Open Scholarly Metadata
- 18 – 22 October – ScienceOpen at Frankfurt Book Fair.
- 27 – 29 September – Attending OA Tage, Berlin .
- 25 – 27 September – ScienceOpen at Open Science Fair
- 19 – 21 September – OASPA 2023 Annual Conference .
- 22 – 24 May – ScienceOpen sponsoring Pint of Science, Berlin.
- 16-17 May – ScienceOpen at 3rd AEUP Conference.
- 20 – 21 April – ScienceOpen attending Scaling Small: Community-Owned Futures for Open Access Books .
What is ScienceOpen?
- Smart search and discovery within an interactive interface
- Researcher promotion and ORCID integration
- Open evaluation with article reviews and Collections
- Business model based on providing services to publishers
Live Twitter stream
Some of our partners:.
This website uses cookies to ensure you get the best experience. Learn more about DOAJ’s privacy policy.
Hide this message
You are using an outdated browser. Please upgrade your browser to improve your experience and security.
The Directory of Open Access Journals
Directory of Open Access Journals
Find open access journals & articles.
Doaj in numbers.
80 languages
135 countries represented
13,745 journals without APCs
20,897 journals
10,450,448 article records
Quick search
About the directory.
DOAJ is a unique and extensive index of diverse open access journals from around the world, driven by a growing community, and is committed to ensuring quality content is freely available online for everyone.
DOAJ is committed to keeping its services free of charge, including being indexed, and its data freely available.
→ About DOAJ
→ How to apply
DOAJ is twenty years old in 2023.
Fund our 20th anniversary campaign
DOAJ is independent. All support is via donations.
82% from academic organisations
18% from contributors
Support DOAJ
Publishers don't need to donate to be part of DOAJ.
News Service
Meet the doaj team: head of editorial and deputy head of editorial (quality), vacancy: operations manager, press release: pubscholar joins the movement to support the directory of open access journals, new major version of the api to be released.
→ All blog posts
We would not be able to work without our volunteers, such as these top-performing editors and associate editors.
→ Meet our volunteers
Librarianship, Scholarly Publishing, Data Management
Brisbane, Australia (Chinese, English)
Adana, Türkiye (Turkish, English)
Humanities, Social Sciences
Natalia Pamuła
Toruń, Poland (Polish, English)
Medical Sciences, Nutrition
Pablo Hernandez
Caracas, Venezuela (Spanish, English)
Research Evaluation
Paola Galimberti
Milan, Italy (Italian, German, English)
Social Sciences, Humanities
Dawam M. Rohmatulloh
Ponorogo, Indonesia (Bahasa Indonesia, English, Dutch)
Systematic Entomology
Kadri Kıran
Edirne, Türkiye (English, Turkish, German)
Library and Information Science
Nataliia Kaliuzhna
Kyiv, Ukraine (Ukrainian, Russian, English, Polish)
WeChat QR code

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
PubMed Advanced Search Builder
- Add with AND
- Add with OR
- Add with NOT
- Add to History
Your saved search
History and search details.
No History items are available for download.
History items expire after 8 hour of inactivity.
Click 'Refresh' to clear items from the table,
or click the 'X' to go back to the table.
The history table currently contains expired items.
Clear expired items and add your new query?
No History items are available for deletion.
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
Adapting to Misspecification
Empirical research typically involves a robustness-efficiency tradeoff. A researcher seeking to estimate a scalar parameter can invoke strong assumptions to motivate a restricted estimator that is precise but may be heavily biased, or they can relax some of these assumptions to motivate a more robust, but variable, unrestricted estimator. When a bound on the bias of the restricted estimator is available, it is optimal to shrink the unrestricted estimator towards the restricted estimator. For settings where a bound on the bias of the restricted estimator is unknown, we propose adaptive estimators that minimize the percentage increase in worst case risk relative to an oracle that knows the bound. We show that adaptive estimators solve a weighted convex minimax problem and provide lookup tables facilitating their rapid computation. Revisiting some well known empirical studies where questions of model specification arise, we examine the advantages of adapting to—rather than testing for—misspecification.
Timothy Armstrong gratefully acknowledges support from National Science Foundation Grant SES-2049765. Liyang Sun gratefully acknowledges support from the Institute of Education Sciences, U.S. Department of Education, through Grant R305D200010, and Ayudas Juan de la Cierva Formacion. The views expressed herein are those of the authors and do not necessarily reflect the views of the National Bureau of Economic Research.
MARC RIS BibTeΧ
Download Citation Data
More from NBER
In addition to working papers , the NBER disseminates affiliates’ latest findings through a range of free periodicals — the NBER Reporter , the NBER Digest , the Bulletin on Retirement and Disability , the Bulletin on Health , and the Bulletin on Entrepreneurship — as well as online conference reports , video lectures , and interviews .

This week: the arXiv Accessibility Forum
Help | Advanced Search
Computer Science > Computation and Language
Title: can llms generate novel research ideas a large-scale human study with 100+ nlp researchers.
Abstract: Recent advancements in large language models (LLMs) have sparked optimism about their potential to accelerate scientific discovery, with a growing number of works proposing research agents that autonomously generate and validate new ideas. Despite this, no evaluations have shown that LLM systems can take the very first step of producing novel, expert-level ideas, let alone perform the entire research process. We address this by establishing an experimental design that evaluates research idea generation while controlling for confounders and performs the first head-to-head comparison between expert NLP researchers and an LLM ideation agent. By recruiting over 100 NLP researchers to write novel ideas and blind reviews of both LLM and human ideas, we obtain the first statistically significant conclusion on current LLM capabilities for research ideation: we find LLM-generated ideas are judged as more novel (p < 0.05) than human expert ideas while being judged slightly weaker on feasibility. Studying our agent baselines closely, we identify open problems in building and evaluating research agents, including failures of LLM self-evaluation and their lack of diversity in generation. Finally, we acknowledge that human judgements of novelty can be difficult, even by experts, and propose an end-to-end study design which recruits researchers to execute these ideas into full projects, enabling us to study whether these novelty and feasibility judgements result in meaningful differences in research outcome.
| Comments: | main paper is 20 pages |
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computers and Society (cs.CY); Human-Computer Interaction (cs.HC); Machine Learning (cs.LG) |
| Cite as: | [cs.CL] |
| (or [cs.CL] for this version) | |
| Focus to learn more arXiv-issued DOI via DataCite (pending registration) |
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
Search Icon
Events See all →
Incantation.

6:00 p.m. - 7:30 p.m.
Penn Museum, 3260 South St.
Movable Books Opening

4:00 p.m. - 8:00 p.m.
Van Pelt-Dietrich Library, 3420 Walnut St.
September 2024 Wellness Walk

LOVE Sculpture on Locust Walk
Health Sciences
Understanding diabetes and oral health
Two undergraduates, supported by purm, worked on research projects this summer with the graves lab to contribute to the knowledge of diabetes’ impact on oral wound healing and periodontal disease..

Despite a robust amount of research about diabetes, much is still unknown about its effects on oral health. Changes in inflammation are understood to contribute to the impact of diabetes, but what is driving the increase is less clear.
Through a study in the Graves Lab, led by Dana Graves , a professor of periodontics in the School of Dental Medicine , the goal has been to identify molecules that are modulated by diabetes to increase pathology.
One project, co-led by research scholar Hamideh Afzali, used single-cell RNA sequencing, which is a sophisticated assay that measures the mRNA level of thousands of genes in each individual cell. The sequencing focused on white blood cells in contrast to many wound healing studies that focus on fibroblasts. That led the research team to identify the gene S100A11 that was found at high levels in diabetic wounds in a specific white blood cell, neutrophils.
“Not as many genes were obviously affected by diabetes as we expected”,” explains Graves. “There’s not a huge number that are different. … And this gene is the one that Hamideh thought was pretty important.”
The process was to examine the healing of a diabetic wounds in mice and conduct bioinformatic analysis during the healing process when connective tissue starts to form. The analysis led to S100A11, but the question remained whether inhibiting this gene would improve healing.
Helpful in this process was Sanan Gueyikian, a third-year neuroscience major with a minor in health care management in the College of Arts and Sciences, who measured histologic tissues to assess, quantitatively, whether healing improved. Gueyikian conducted this work through the Penn Undergraduate Research Mentoring Program (PURM), a 10-week opportunity from the Center for Undergraduate Research and Fellowships . The program provides rising second- and third-year students with a $5,000 award to work alongside Penn faculty.
“There’s a long history of diabetes in my family, and the lack of information regarding its cause or what it can trigger fascinates me,” Gueyikian says. “I am also interested in dental medicine and pursuing it in the future. So, Dr. Graves’ lab was the perfect place for me to explore these interests.”
Through the experience, she says, she learned a lot about signaling pathways and testing for genes. Gueyikian adds that, with the mentorship of Afzali, she learned to read research papers differently and understand them better. She says that this was her first experience with research and further cemented her interest in oral surgery.
“I came out with a much better understanding of the research process,” she says.
A second research project in the Graves Lab, supported with a PURM student researcher, looked at periodontal disease and bone loss among diabetics. Su Ah Kim, a third-year student majoring in finance and healthcare management at the Wharton School with a minor in chemistry, worked with senior research investigator Min Liu to genotype and quantify bone loss in diabetic mice. Liu says Kim is “very smart and works very hard and learns very fast,” and analyzed the bone levels to help determine whether the Akt1 gene played a significant role in the increased periodontal disease caused by diabetes.
Like Gueyikian, Kim says her family has a history of diabetes, which partly spurred her interest in the PURM project. She plans to pursue dentistry after graduating and has spent time shadowing at University Dental Associates. She hopes to combine her business and dentistry knowledge to one day own her own practice.
The research opportunity, Kim says, taught her how to be more self-sufficient, while also giving her a chance to interact with Penn Dental students who were happy to answer questions about dentistry as a career path.
“I learned in the 10 weeks that self-initiation and being proactive are fundamental for success in scientific research,” Kim says.
“It was my first time conducting research in a wet lab, so I experienced learning curves with performing procedures, including genotyping and histological staining,” she adds. “However, through several processes of trial and error and collaboration with other lab members, I developed a strong knowledge of each procedure, which I was able to carry out successfully on my own.” Graves is a big fan of the PURM program and has brought undergraduates into projects for many years, he says—always to great success.
“Both of them contributed a lot to their projects,” says Graves. “This was not a teaching exercise; this was an opportunity to participate as a researcher. They both will be coauthors on a paper and both provided valuable data, bringing a lot of enthusiasm, while learning quickly. They were a pleasure to work with.”
Participating PURM students, Sanan and Kim, he says, learned how important teamwork is in a research lab setting and how it is necessary to obtain successful results. He says both students embraced a spirit of cooperation, which is “a key factor” in lab work.
“They became real researchers toward the end, both understanding their projects well and capable of carrying out the experimental assays,” he says.
At Convocation, a call to ‘come together’

Campus & Community
Move-In coordinators help ease transition to college
Forty-eight second-year, third-year, and fourth-year students will be on the ground during Move-In to assist approximately 6,000 new and returning Quakers.

The power of protons
Penn Medicine has treated more than 10,000 cancer patients at three proton therapy centers across the region, including the largest and busiest center in the world—while also leading the way in research to expand the healing potential of these positive particles.

To Penn’s Class of 2024: ‘The world needs you’
The University celebrated graduating students on Monday during the 268th Commencement.

Class of 2025 relishes time together at Hey Day
An iconic tradition at Penn, third-year students were promoted to senior status.
Peer Reviewed
GPT-fabricated scientific papers on Google Scholar: Key features, spread, and implications for preempting evidence manipulation
Article metrics.
CrossRef Citations
Altmetric Score
PDF Downloads
Academic journals, archives, and repositories are seeing an increasing number of questionable research papers clearly produced using generative AI. They are often created with widely available, general-purpose AI applications, most likely ChatGPT, and mimic scientific writing. Google Scholar easily locates and lists these questionable papers alongside reputable, quality-controlled research. Our analysis of a selection of questionable GPT-fabricated scientific papers found in Google Scholar shows that many are about applied, often controversial topics susceptible to disinformation: the environment, health, and computing. The resulting enhanced potential for malicious manipulation of society’s evidence base, particularly in politically divisive domains, is a growing concern.
Swedish School of Library and Information Science, University of Borås, Sweden
Department of Arts and Cultural Sciences, Lund University, Sweden
Division of Environmental Communication, Swedish University of Agricultural Sciences, Sweden

Research Questions
- Where are questionable publications produced with generative pre-trained transformers (GPTs) that can be found via Google Scholar published or deposited?
- What are the main characteristics of these publications in relation to predominant subject categories?
- How are these publications spread in the research infrastructure for scholarly communication?
- How is the role of the scholarly communication infrastructure challenged in maintaining public trust in science and evidence through inappropriate use of generative AI?
research note Summary
- A sample of scientific papers with signs of GPT-use found on Google Scholar was retrieved, downloaded, and analyzed using a combination of qualitative coding and descriptive statistics. All papers contained at least one of two common phrases returned by conversational agents that use large language models (LLM) like OpenAI’s ChatGPT. Google Search was then used to determine the extent to which copies of questionable, GPT-fabricated papers were available in various repositories, archives, citation databases, and social media platforms.
- Roughly two-thirds of the retrieved papers were found to have been produced, at least in part, through undisclosed, potentially deceptive use of GPT. The majority (57%) of these questionable papers dealt with policy-relevant subjects (i.e., environment, health, computing), susceptible to influence operations. Most were available in several copies on different domains (e.g., social media, archives, and repositories).
- Two main risks arise from the increasingly common use of GPT to (mass-)produce fake, scientific publications. First, the abundance of fabricated “studies” seeping into all areas of the research infrastructure threatens to overwhelm the scholarly communication system and jeopardize the integrity of the scientific record. A second risk lies in the increased possibility that convincingly scientific-looking content was in fact deceitfully created with AI tools and is also optimized to be retrieved by publicly available academic search engines, particularly Google Scholar. However small, this possibility and awareness of it risks undermining the basis for trust in scientific knowledge and poses serious societal risks.
Implications
The use of ChatGPT to generate text for academic papers has raised concerns about research integrity. Discussion of this phenomenon is ongoing in editorials, commentaries, opinion pieces, and on social media (Bom, 2023; Stokel-Walker, 2024; Thorp, 2023). There are now several lists of papers suspected of GPT misuse, and new papers are constantly being added. 1 See for example Academ-AI, https://www.academ-ai.info/ , and Retraction Watch, https://retractionwatch.com/papers-and-peer-reviews-with-evidence-of-chatgpt-writing/ . While many legitimate uses of GPT for research and academic writing exist (Huang & Tan, 2023; Kitamura, 2023; Lund et al., 2023), its undeclared use—beyond proofreading—has potentially far-reaching implications for both science and society, but especially for their relationship. It, therefore, seems important to extend the discussion to one of the most accessible and well-known intermediaries between science, but also certain types of misinformation, and the public, namely Google Scholar, also in response to the legitimate concerns that the discussion of generative AI and misinformation needs to be more nuanced and empirically substantiated (Simon et al., 2023).
Google Scholar, https://scholar.google.com , is an easy-to-use academic search engine. It is available for free, and its index is extensive (Gusenbauer & Haddaway, 2020). It is also often touted as a credible source for academic literature and even recommended in library guides, by media and information literacy initiatives, and fact checkers (Tripodi et al., 2023). However, Google Scholar lacks the transparency and adherence to standards that usually characterize citation databases. Instead, Google Scholar uses automated crawlers, like Google’s web search engine (Martín-Martín et al., 2021), and the inclusion criteria are based on primarily technical standards, allowing any individual author—with or without scientific affiliation—to upload papers to be indexed (Google Scholar Help, n.d.). It has been shown that Google Scholar is susceptible to manipulation through citation exploits (Antkare, 2020) and by providing access to fake scientific papers (Dadkhah et al., 2017). A large part of Google Scholar’s index consists of publications from established scientific journals or other forms of quality-controlled, scholarly literature. However, the index also contains a large amount of gray literature, including student papers, working papers, reports, preprint servers, and academic networking sites, as well as material from so-called “questionable” academic journals, including paper mills. The search interface does not offer the possibility to filter the results meaningfully by material type, publication status, or form of quality control, such as limiting the search to peer-reviewed material.
To understand the occurrence of ChatGPT (co-)authored work in Google Scholar’s index, we scraped it for publications, including one of two common ChatGPT responses (see Appendix A) that we encountered on social media and in media reports (DeGeurin, 2024). The results of our descriptive statistical analyses showed that around 62% did not declare the use of GPTs. Most of these GPT-fabricated papers were found in non-indexed journals and working papers, but some cases included research published in mainstream scientific journals and conference proceedings. 2 Indexed journals mean scholarly journals indexed by abstract and citation databases such as Scopus and Web of Science, where the indexation implies journals with high scientific quality. Non-indexed journals are journals that fall outside of this indexation. More than half (57%) of these GPT-fabricated papers concerned policy-relevant subject areas susceptible to influence operations. To avoid increasing the visibility of these publications, we abstained from referencing them in this research note. However, we have made the data available in the Harvard Dataverse repository.
The publications were related to three issue areas—health (14.5%), environment (19.5%) and computing (23%)—with key terms such “healthcare,” “COVID-19,” or “infection”for health-related papers, and “analysis,” “sustainable,” and “global” for environment-related papers. In several cases, the papers had titles that strung together general keywords and buzzwords, thus alluding to very broad and current research. These terms included “biology,” “telehealth,” “climate policy,” “diversity,” and “disrupting,” to name just a few. While the study’s scope and design did not include a detailed analysis of which parts of the articles included fabricated text, our dataset did contain the surrounding sentences for each occurrence of the suspicious phrases that formed the basis for our search and subsequent selection. Based on that, we can say that the phrases occurred in most sections typically found in scientific publications, including the literature review, methods, conceptual and theoretical frameworks, background, motivation or societal relevance, and even discussion. This was confirmed during the joint coding, where we read and discussed all articles. It became clear that not just the text related to the telltale phrases was created by GPT, but that almost all articles in our sample of questionable articles likely contained traces of GPT-fabricated text everywhere.
Evidence hacking and backfiring effects
Generative pre-trained transformers (GPTs) can be used to produce texts that mimic scientific writing. These texts, when made available online—as we demonstrate—leak into the databases of academic search engines and other parts of the research infrastructure for scholarly communication. This development exacerbates problems that were already present with less sophisticated text generators (Antkare, 2020; Cabanac & Labbé, 2021). Yet, the public release of ChatGPT in 2022, together with the way Google Scholar works, has increased the likelihood of lay people (e.g., media, politicians, patients, students) coming across questionable (or even entirely GPT-fabricated) papers and other problematic research findings. Previous research has emphasized that the ability to determine the value and status of scientific publications for lay people is at stake when misleading articles are passed off as reputable (Haider & Åström, 2017) and that systematic literature reviews risk being compromised (Dadkhah et al., 2017). It has also been highlighted that Google Scholar, in particular, can be and has been exploited for manipulating the evidence base for politically charged issues and to fuel conspiracy narratives (Tripodi et al., 2023). Both concerns are likely to be magnified in the future, increasing the risk of what we suggest calling evidence hacking —the strategic and coordinated malicious manipulation of society’s evidence base.
The authority of quality-controlled research as evidence to support legislation, policy, politics, and other forms of decision-making is undermined by the presence of undeclared GPT-fabricated content in publications professing to be scientific. Due to the large number of archives, repositories, mirror sites, and shadow libraries to which they spread, there is a clear risk that GPT-fabricated, questionable papers will reach audiences even after a possible retraction. There are considerable technical difficulties involved in identifying and tracing computer-fabricated papers (Cabanac & Labbé, 2021; Dadkhah et al., 2023; Jones, 2024), not to mention preventing and curbing their spread and uptake.
However, as the rise of the so-called anti-vaxx movement during the COVID-19 pandemic and the ongoing obstruction and denial of climate change show, retracting erroneous publications often fuels conspiracies and increases the following of these movements rather than stopping them. To illustrate this mechanism, climate deniers frequently question established scientific consensus by pointing to other, supposedly scientific, studies that support their claims. Usually, these are poorly executed, not peer-reviewed, based on obsolete data, or even fraudulent (Dunlap & Brulle, 2020). A similar strategy is successful in the alternative epistemic world of the global anti-vaccination movement (Carrion, 2018) and the persistence of flawed and questionable publications in the scientific record already poses significant problems for health research, policy, and lawmakers, and thus for society as a whole (Littell et al., 2024). Considering that a person’s support for “doing your own research” is associated with increased mistrust in scientific institutions (Chinn & Hasell, 2023), it will be of utmost importance to anticipate and consider such backfiring effects already when designing a technical solution, when suggesting industry or legal regulation, and in the planning of educational measures.
Recommendations
Solutions should be based on simultaneous considerations of technical, educational, and regulatory approaches, as well as incentives, including social ones, across the entire research infrastructure. Paying attention to how these approaches and incentives relate to each other can help identify points and mechanisms for disruption. Recognizing fraudulent academic papers must happen alongside understanding how they reach their audiences and what reasons there might be for some of these papers successfully “sticking around.” A possible way to mitigate some of the risks associated with GPT-fabricated scholarly texts finding their way into academic search engine results would be to provide filtering options for facets such as indexed journals, gray literature, peer-review, and similar on the interface of publicly available academic search engines. Furthermore, evaluation tools for indexed journals 3 Such as LiU Journal CheckUp, https://ep.liu.se/JournalCheckup/default.aspx?lang=eng . could be integrated into the graphical user interfaces and the crawlers of these academic search engines. To enable accountability, it is important that the index (database) of such a search engine is populated according to criteria that are transparent, open to scrutiny, and appropriate to the workings of science and other forms of academic research. Moreover, considering that Google Scholar has no real competitor, there is a strong case for establishing a freely accessible, non-specialized academic search engine that is not run for commercial reasons but for reasons of public interest. Such measures, together with educational initiatives aimed particularly at policymakers, science communicators, journalists, and other media workers, will be crucial to reducing the possibilities for and effects of malicious manipulation or evidence hacking. It is important not to present this as a technical problem that exists only because of AI text generators but to relate it to the wider concerns in which it is embedded. These range from a largely dysfunctional scholarly publishing system (Haider & Åström, 2017) and academia’s “publish or perish” paradigm to Google’s near-monopoly and ideological battles over the control of information and ultimately knowledge. Any intervention is likely to have systemic effects; these effects need to be considered and assessed in advance and, ideally, followed up on.
Our study focused on a selection of papers that were easily recognizable as fraudulent. We used this relatively small sample as a magnifying glass to examine, delineate, and understand a problem that goes beyond the scope of the sample itself, which however points towards larger concerns that require further investigation. The work of ongoing whistleblowing initiatives 4 Such as Academ-AI, https://www.academ-ai.info/ , and Retraction Watch, https://retractionwatch.com/papers-and-peer-reviews-with-evidence-of-chatgpt-writing/ . , recent media reports of journal closures (Subbaraman, 2024), or GPT-related changes in word use and writing style (Cabanac et al., 2021; Stokel-Walker, 2024) suggest that we only see the tip of the iceberg. There are already more sophisticated cases (Dadkhah et al., 2023) as well as cases involving fabricated images (Gu et al., 2022). Our analysis shows that questionable and potentially manipulative GPT-fabricated papers permeate the research infrastructure and are likely to become a widespread phenomenon. Our findings underline that the risk of fake scientific papers being used to maliciously manipulate evidence (see Dadkhah et al., 2017) must be taken seriously. Manipulation may involve undeclared automatic summaries of texts, inclusion in literature reviews, explicit scientific claims, or the concealment of errors in studies so that they are difficult to detect in peer review. However, the mere possibility of these things happening is a significant risk in its own right that can be strategically exploited and will have ramifications for trust in and perception of science. Society’s methods of evaluating sources and the foundations of media and information literacy are under threat and public trust in science is at risk of further erosion, with far-reaching consequences for society in dealing with information disorders. To address this multifaceted problem, we first need to understand why it exists and proliferates.
Finding 1: 139 GPT-fabricated, questionable papers were found and listed as regular results on the Google Scholar results page. Non-indexed journals dominate.
Most questionable papers we found were in non-indexed journals or were working papers, but we did also find some in established journals, publications, conferences, and repositories. We found a total of 139 papers with a suspected deceptive use of ChatGPT or similar LLM applications (see Table 1). Out of these, 19 were in indexed journals, 89 were in non-indexed journals, 19 were student papers found in university databases, and 12 were working papers (mostly in preprint databases). Table 1 divides these papers into categories. Health and environment papers made up around 34% (47) of the sample. Of these, 66% were present in non-indexed journals.
| Indexed journals* | 5 | 3 | 4 | 7 | 19 |
| Non-indexed journals | 18 | 18 | 13 | 40 | 89 |
| Student papers | 4 | 3 | 1 | 11 | 19 |
| Working papers | 5 | 3 | 2 | 2 | 12 |
| Total | 32 | 27 | 20 | 60 | 139 |
Finding 2: GPT-fabricated, questionable papers are disseminated online, permeating the research infrastructure for scholarly communication, often in multiple copies. Applied topics with practical implications dominate.
The 20 papers concerning health-related issues are distributed across 20 unique domains, accounting for 46 URLs. The 27 papers dealing with environmental issues can be found across 26 unique domains, accounting for 56 URLs. Most of the identified papers exist in multiple copies and have already spread to several archives, repositories, and social media. It would be difficult, or impossible, to remove them from the scientific record.
As apparent from Table 2, GPT-fabricated, questionable papers are seeping into most parts of the online research infrastructure for scholarly communication. Platforms on which identified papers have appeared include ResearchGate, ORCiD, Journal of Population Therapeutics and Clinical Pharmacology (JPTCP), Easychair, Frontiers, the Institute of Electrical and Electronics Engineer (IEEE), and X/Twitter. Thus, even if they are retracted from their original source, it will prove very difficult to track, remove, or even just mark them up on other platforms. Moreover, unless regulated, Google Scholar will enable their continued and most likely unlabeled discoverability.
| Environment | researchgate.net (13) | orcid.org (4) | easychair.org (3) | ijope.com* (3) | publikasiindonesia.id (3) |
| Health | researchgate.net (15) | ieee.org (4) | twitter.com (3) | jptcp.com** (2) | frontiersin.org (2) |
A word rain visualization (Centre for Digital Humanities Uppsala, 2023), which combines word prominences through TF-IDF 5 Term frequency–inverse document frequency , a method for measuring the significance of a word in a document compared to its frequency across all documents in a collection. scores with semantic similarity of the full texts of our sample of GPT-generated articles that fall into the “Environment” and “Health” categories, reflects the two categories in question. However, as can be seen in Figure 1, it also reveals overlap and sub-areas. The y-axis shows word prominences through word positions and font sizes, while the x-axis indicates semantic similarity. In addition to a certain amount of overlap, this reveals sub-areas, which are best described as two distinct events within the word rain. The event on the left bundles terms related to the development and management of health and healthcare with “challenges,” “impact,” and “potential of artificial intelligence”emerging as semantically related terms. Terms related to research infrastructures, environmental, epistemic, and technological concepts are arranged further down in the same event (e.g., “system,” “climate,” “understanding,” “knowledge,” “learning,” “education,” “sustainable”). A second distinct event further to the right bundles terms associated with fish farming and aquatic medicinal plants, highlighting the presence of an aquaculture cluster. Here, the prominence of groups of terms such as “used,” “model,” “-based,” and “traditional” suggests the presence of applied research on these topics. The two events making up the word rain visualization, are linked by a less dominant but overlapping cluster of terms related to “energy” and “water.”
The bar chart of the terms in the paper subset (see Figure 2) complements the word rain visualization by depicting the most prominent terms in the full texts along the y-axis. Here, word prominences across health and environment papers are arranged descendingly, where values outside parentheses are TF-IDF values (relative frequencies) and values inside parentheses are raw term frequencies (absolute frequencies).
Finding 3: Google Scholar presents results from quality-controlled and non-controlled citation databases on the same interface, providing unfiltered access to GPT-fabricated questionable papers.
Google Scholar’s central position in the publicly accessible scholarly communication infrastructure, as well as its lack of standards, transparency, and accountability in terms of inclusion criteria, has potentially serious implications for public trust in science. This is likely to exacerbate the already-known potential to exploit Google Scholar for evidence hacking (Tripodi et al., 2023) and will have implications for any attempts to retract or remove fraudulent papers from their original publication venues. Any solution must consider the entirety of the research infrastructure for scholarly communication and the interplay of different actors, interests, and incentives.
We searched and scraped Google Scholar using the Python library Scholarly (Cholewiak et al., 2023) for papers that included specific phrases known to be common responses from ChatGPT and similar applications with the same underlying model (GPT3.5 or GPT4): “as of my last knowledge update” and/or “I don’t have access to real-time data” (see Appendix A). This facilitated the identification of papers that likely used generative AI to produce text, resulting in 227 retrieved papers. The papers’ bibliographic information was automatically added to a spreadsheet and downloaded into Zotero. 6 An open-source reference manager, https://zotero.org .
We employed multiple coding (Barbour, 2001) to classify the papers based on their content. First, we jointly assessed whether the paper was suspected of fraudulent use of ChatGPT (or similar) based on how the text was integrated into the papers and whether the paper was presented as original research output or the AI tool’s role was acknowledged. Second, in analyzing the content of the papers, we continued the multiple coding by classifying the fraudulent papers into four categories identified during an initial round of analysis—health, environment, computing, and others—and then determining which subjects were most affected by this issue (see Table 1). Out of the 227 retrieved papers, 88 papers were written with legitimate and/or declared use of GPTs (i.e., false positives, which were excluded from further analysis), and 139 papers were written with undeclared and/or fraudulent use (i.e., true positives, which were included in further analysis). The multiple coding was conducted jointly by all authors of the present article, who collaboratively coded and cross-checked each other’s interpretation of the data simultaneously in a shared spreadsheet file. This was done to single out coding discrepancies and settle coding disagreements, which in turn ensured methodological thoroughness and analytical consensus (see Barbour, 2001). Redoing the category coding later based on our established coding schedule, we achieved an intercoder reliability (Cohen’s kappa) of 0.806 after eradicating obvious differences.
The ranking algorithm of Google Scholar prioritizes highly cited and older publications (Martín-Martín et al., 2016). Therefore, the position of the articles on the search engine results pages was not particularly informative, considering the relatively small number of results in combination with the recency of the publications. Only the query “as of my last knowledge update” had more than two search engine result pages. On those, questionable articles with undeclared use of GPTs were evenly distributed across all result pages (min: 4, max: 9, mode: 8), with the proportion of undeclared use being slightly higher on average on later search result pages.
To understand how the papers making fraudulent use of generative AI were disseminated online, we programmatically searched for the paper titles (with exact string matching) in Google Search from our local IP address (see Appendix B) using the googlesearch – python library(Vikramaditya, 2020). We manually verified each search result to filter out false positives—results that were not related to the paper—and then compiled the most prominent URLs by field. This enabled the identification of other platforms through which the papers had been spread. We did not, however, investigate whether copies had spread into SciHub or other shadow libraries, or if they were referenced in Wikipedia.
We used descriptive statistics to count the prevalence of the number of GPT-fabricated papers across topics and venues and top domains by subject. The pandas software library for the Python programming language (The pandas development team, 2024) was used for this part of the analysis. Based on the multiple coding, paper occurrences were counted in relation to their categories, divided into indexed journals, non-indexed journals, student papers, and working papers. The schemes, subdomains, and subdirectories of the URL strings were filtered out while top-level domains and second-level domains were kept, which led to normalizing domain names. This, in turn, allowed the counting of domain frequencies in the environment and health categories. To distinguish word prominences and meanings in the environment and health-related GPT-fabricated questionable papers, a semantically-aware word cloud visualization was produced through the use of a word rain (Centre for Digital Humanities Uppsala, 2023) for full-text versions of the papers. Font size and y-axis positions indicate word prominences through TF-IDF scores for the environment and health papers (also visualized in a separate bar chart with raw term frequencies in parentheses), and words are positioned along the x-axis to reflect semantic similarity (Skeppstedt et al., 2024), with an English Word2vec skip gram model space (Fares et al., 2017). An English stop word list was used, along with a manually produced list including terms such as “https,” “volume,” or “years.”
- Artificial Intelligence
- / Search engines
Cite this Essay
Haider, J., Söderström, K. R., Ekström, B., & Rödl, M. (2024). GPT-fabricated scientific papers on Google Scholar: Key features, spread, and implications for preempting evidence manipulation. Harvard Kennedy School (HKS) Misinformation Review . https://doi.org/10.37016/mr-2020-156
- / Appendix B
Bibliography
Antkare, I. (2020). Ike Antkare, his publications, and those of his disciples. In M. Biagioli & A. Lippman (Eds.), Gaming the metrics (pp. 177–200). The MIT Press. https://doi.org/10.7551/mitpress/11087.003.0018
Barbour, R. S. (2001). Checklists for improving rigour in qualitative research: A case of the tail wagging the dog? BMJ , 322 (7294), 1115–1117. https://doi.org/10.1136/bmj.322.7294.1115
Bom, H.-S. H. (2023). Exploring the opportunities and challenges of ChatGPT in academic writing: A roundtable discussion. Nuclear Medicine and Molecular Imaging , 57 (4), 165–167. https://doi.org/10.1007/s13139-023-00809-2
Cabanac, G., & Labbé, C. (2021). Prevalence of nonsensical algorithmically generated papers in the scientific literature. Journal of the Association for Information Science and Technology , 72 (12), 1461–1476. https://doi.org/10.1002/asi.24495
Cabanac, G., Labbé, C., & Magazinov, A. (2021). Tortured phrases: A dubious writing style emerging in science. Evidence of critical issues affecting established journals . arXiv. https://doi.org/10.48550/arXiv.2107.06751
Carrion, M. L. (2018). “You need to do your research”: Vaccines, contestable science, and maternal epistemology. Public Understanding of Science , 27 (3), 310–324. https://doi.org/10.1177/0963662517728024
Centre for Digital Humanities Uppsala (2023). CDHUppsala/word-rain [Computer software]. https://github.com/CDHUppsala/word-rain
Chinn, S., & Hasell, A. (2023). Support for “doing your own research” is associated with COVID-19 misperceptions and scientific mistrust. Harvard Kennedy School (HSK) Misinformation Review, 4 (3). https://doi.org/10.37016/mr-2020-117
Cholewiak, S. A., Ipeirotis, P., Silva, V., & Kannawadi, A. (2023). SCHOLARLY: Simple access to Google Scholar authors and citation using Python (1.5.0) [Computer software]. https://doi.org/10.5281/zenodo.5764801
Dadkhah, M., Lagzian, M., & Borchardt, G. (2017). Questionable papers in citation databases as an issue for literature review. Journal of Cell Communication and Signaling , 11 (2), 181–185. https://doi.org/10.1007/s12079-016-0370-6
Dadkhah, M., Oermann, M. H., Hegedüs, M., Raman, R., & Dávid, L. D. (2023). Detection of fake papers in the era of artificial intelligence. Diagnosis , 10 (4), 390–397. https://doi.org/10.1515/dx-2023-0090
DeGeurin, M. (2024, March 19). AI-generated nonsense is leaking into scientific journals. Popular Science. https://www.popsci.com/technology/ai-generated-text-scientific-journals/
Dunlap, R. E., & Brulle, R. J. (2020). Sources and amplifiers of climate change denial. In D.C. Holmes & L. M. Richardson (Eds.), Research handbook on communicating climate change (pp. 49–61). Edward Elgar Publishing. https://doi.org/10.4337/9781789900408.00013
Fares, M., Kutuzov, A., Oepen, S., & Velldal, E. (2017). Word vectors, reuse, and replicability: Towards a community repository of large-text resources. In J. Tiedemann & N. Tahmasebi (Eds.), Proceedings of the 21st Nordic Conference on Computational Linguistics (pp. 271–276). Association for Computational Linguistics. https://aclanthology.org/W17-0237
Google Scholar Help. (n.d.). Inclusion guidelines for webmasters . https://scholar.google.com/intl/en/scholar/inclusion.html
Gu, J., Wang, X., Li, C., Zhao, J., Fu, W., Liang, G., & Qiu, J. (2022). AI-enabled image fraud in scientific publications. Patterns , 3 (7), 100511. https://doi.org/10.1016/j.patter.2022.100511
Gusenbauer, M., & Haddaway, N. R. (2020). Which academic search systems are suitable for systematic reviews or meta-analyses? Evaluating retrieval qualities of Google Scholar, PubMed, and 26 other resources. Research Synthesis Methods , 11 (2), 181–217. https://doi.org/10.1002/jrsm.1378
Haider, J., & Åström, F. (2017). Dimensions of trust in scholarly communication: Problematizing peer review in the aftermath of John Bohannon’s “Sting” in science. Journal of the Association for Information Science and Technology , 68 (2), 450–467. https://doi.org/10.1002/asi.23669
Huang, J., & Tan, M. (2023). The role of ChatGPT in scientific communication: Writing better scientific review articles. American Journal of Cancer Research , 13 (4), 1148–1154. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10164801/
Jones, N. (2024). How journals are fighting back against a wave of questionable images. Nature , 626 (8000), 697–698. https://doi.org/10.1038/d41586-024-00372-6
Kitamura, F. C. (2023). ChatGPT is shaping the future of medical writing but still requires human judgment. Radiology , 307 (2), e230171. https://doi.org/10.1148/radiol.230171
Littell, J. H., Abel, K. M., Biggs, M. A., Blum, R. W., Foster, D. G., Haddad, L. B., Major, B., Munk-Olsen, T., Polis, C. B., Robinson, G. E., Rocca, C. H., Russo, N. F., Steinberg, J. R., Stewart, D. E., Stotland, N. L., Upadhyay, U. D., & Ditzhuijzen, J. van. (2024). Correcting the scientific record on abortion and mental health outcomes. BMJ , 384 , e076518. https://doi.org/10.1136/bmj-2023-076518
Lund, B. D., Wang, T., Mannuru, N. R., Nie, B., Shimray, S., & Wang, Z. (2023). ChatGPT and a new academic reality: Artificial Intelligence-written research papers and the ethics of the large language models in scholarly publishing. Journal of the Association for Information Science and Technology, 74 (5), 570–581. https://doi.org/10.1002/asi.24750
Martín-Martín, A., Orduna-Malea, E., Ayllón, J. M., & Delgado López-Cózar, E. (2016). Back to the past: On the shoulders of an academic search engine giant. Scientometrics , 107 , 1477–1487. https://doi.org/10.1007/s11192-016-1917-2
Martín-Martín, A., Thelwall, M., Orduna-Malea, E., & Delgado López-Cózar, E. (2021). Google Scholar, Microsoft Academic, Scopus, Dimensions, Web of Science, and OpenCitations’ COCI: A multidisciplinary comparison of coverage via citations. Scientometrics , 126 (1), 871–906. https://doi.org/10.1007/s11192-020-03690-4
Simon, F. M., Altay, S., & Mercier, H. (2023). Misinformation reloaded? Fears about the impact of generative AI on misinformation are overblown. Harvard Kennedy School (HKS) Misinformation Review, 4 (5). https://doi.org/10.37016/mr-2020-127
Skeppstedt, M., Ahltorp, M., Kucher, K., & Lindström, M. (2024). From word clouds to Word Rain: Revisiting the classic word cloud to visualize climate change texts. Information Visualization , 23 (3), 217–238. https://doi.org/10.1177/14738716241236188
Swedish Research Council. (2017). Good research practice. Vetenskapsrådet.
Stokel-Walker, C. (2024, May 1.). AI Chatbots Have Thoroughly Infiltrated Scientific Publishing . Scientific American. https://www.scientificamerican.com/article/chatbots-have-thoroughly-infiltrated-scientific-publishing/
Subbaraman, N. (2024, May 14). Flood of fake science forces multiple journal closures: Wiley to shutter 19 more journals, some tainted by fraud. The Wall Street Journal . https://www.wsj.com/science/academic-studies-research-paper-mills-journals-publishing-f5a3d4bc
The pandas development team. (2024). pandas-dev/pandas: Pandas (v2.2.2) [Computer software]. Zenodo. https://doi.org/10.5281/zenodo.10957263
Thorp, H. H. (2023). ChatGPT is fun, but not an author. Science , 379 (6630), 313–313. https://doi.org/10.1126/science.adg7879
Tripodi, F. B., Garcia, L. C., & Marwick, A. E. (2023). ‘Do your own research’: Affordance activation and disinformation spread. Information, Communication & Society , 27 (6), 1212–1228. https://doi.org/10.1080/1369118X.2023.2245869
Vikramaditya, N. (2020). Nv7-GitHub/googlesearch [Computer software]. https://github.com/Nv7-GitHub/googlesearch
This research has been supported by Mistra, the Swedish Foundation for Strategic Environmental Research, through the research program Mistra Environmental Communication (Haider, Ekström, Rödl) and the Marcus and Amalia Wallenberg Foundation [2020.0004] (Söderström).
Competing Interests
The authors declare no competing interests.
The research described in this article was carried out under Swedish legislation. According to the relevant EU and Swedish legislation (2003:460) on the ethical review of research involving humans (“Ethical Review Act”), the research reported on here is not subject to authorization by the Swedish Ethical Review Authority (“etikprövningsmyndigheten”) (SRC, 2017).
This is an open access article distributed under the terms of the Creative Commons Attribution License , which permits unrestricted use, distribution, and reproduction in any medium, provided that the original author and source are properly credited.
Data Availability
All data needed to replicate this study are available at the Harvard Dataverse: https://doi.org/10.7910/DVN/WUVD8X
Acknowledgements
The authors wish to thank two anonymous reviewers for their valuable comments on the article manuscript as well as the editorial group of Harvard Kennedy School (HKS) Misinformation Review for their thoughtful feedback and input.
Study finds AI-generated research papers on Google Scholar - why it matters

By this point, most chatbot users have accepted the possibility that artificial intelligence (AI) tools will hallucinate in almost every scenario. Despite the efforts of AI content detectors , fact-checkers, and increasingly sophisticated large language models (LLMs), no developers have found a solution for this yet.
Also: Implementing AI? Check MIT's free database for the risks
Meanwhile, the consequences of misinformation are only getting higher: People are using generative AI (gen AI) tools like ChatGPT to create fake research.
A recent study published in the Harvard Kennedy School's Misinformation Review found 139 papers on Google Scholar , a search engine for scholarly literature, that appear to be AI-generated. The researchers found most of the "questionable" papers in non-indexed (unverified) journals, though 19 of them were found in indexed journals and established publications. Another 19 appeared in university databases, apparently written by students.
Even more concerning is the content of the papers. 57% of the fake studies covered topics like health, computational tech, and the environment -- areas the researchers note are relevant to and could influence policy development .
Also: The best AI image generators of 2024: Tested and reviewed
After analyzing the papers, the researchers identified them as likely AI-generated due to their inclusion of "at least one of two common phrases returned by conversational agents that use large language models (LLM) like OpenAI's ChatGPT ." The team then used Google Search to find where the papers could be accessed, locating multiple copies of them across databases, archives, and repositories and on social media.
"The public release of ChatGPT in 2022, together with the way Google Scholar works, has increased the likelihood of lay people (e.g., media, politicians, patients, students) coming across questionable (or even entirely GPT-fabricated) papers and other problematic research findings," the study explains.
Also: The data suggests gen AI boosts software productivity - for these developers
The researchers behind the study noted that theirs is not the first list of academic papers suspected to be AI-generated and that papers are "constantly being added" to these.
So what risks do these fake studies pose being on the internet?
Also: How do AI checkers actually work?
While propaganda and slapdash or falsified studies aren't new, gen AI makes this content exponentially easier to create. "The abundance of fabricated 'studies' seeping into all areas of the research infrastructure threatens to overwhelm the scholarly communication system and jeopardize the integrity of the scientific record," the researchers explain in their findings. They went on to note that it's worrisome that someone could "deceitfully" create "convincingly scientific-looking content" using AI and optimize it to rank on popular search engines like Google Scholar.
Back in April, 404 Media found similar evidence of entirely AI-fabricated books and other material on Google Books and Google Scholar by searching for the phrase "As of my last knowledge update," which is commonly found in ChatGPT responses due to its previously limited dataset. Now that the free version of ChatGPT has web browsing and can access live information, markers like this may be less frequent or disappear altogether, making AI-generated texts harder to spot.
While Google Scholar does have a majority of quality literature, it "lacks the transparency and adherence to standards that usually characterize citation databases," the study explains. The researchers note that, like Google Search, Scholar uses automated crawlers, meaning "the inclusion criteria are based on primarily technical standards, allowing any individual author -- with or without scientific affiliation -- to upload papers." Users also can't filter results for parameters like material type, publication status, or whether they've been peer-reviewed.
Also: I tested 7 AI content detectors - they're getting dramatically better at identifying plagiarism
Google Scholar is easily accessible -- and very popular. According to SimilarWeb , the search engine had over 111 million visits last month, putting it just over academic databases like ResearchGate.net. With so many users flocking to Scholar, likely based on brand trust from all the other Google products they use daily, the odds of them citing false studies are only getting higher.
The most potent difference between AI chatbot hallucinations and entirely falsified studies is context. If users querying ChatGPT know to expect some untrue information, they can take ChatGPT's responses with a grain of salt and double-check its claims. But if AI-generated text is presented as vetted academic research conducted by humans and platformed by a popular source database, users have little reason or means to verify what they're reading is real.
Artificial Intelligence
What is duckduckgo if you're into online privacy, try this popular google alternative, the best soundproof curtains you can buy, google's notebooklm can discuss your notes with you now. how to access it (and why you should).
Research: How to Delegate Decision-Making Strategically
by Hayley Blunden and Mary Steffel

Summary .
Delegating work can help free up managers’ time and energy while empowering their employees to take on meaningful tasks. Yet, previous research has shown that delegating decision-making can cause employees to feel overly burdened. In a new paper, researchers examine the negative impact that handing over choice responsibility can have on delegator-delegate relationships. They offer research-backed solutions for delegating decisions more fairly in order to offset some of delegation’s negative interpersonal consequences.
Effective delegation is critical to managerial success : delegating properly can help empower employees , and those who delegate can increase their earnings . Delegation can also be a way for managers to give employees experience and control, especially when they delegate decision-making responsibilities, which allow employees to exhibit agency over important stakes. Yet, some of our recent research has shown that employees can view delegated decision-making as a burden that they would prefer to avoid.
Partner Center
IMAGES
VIDEO
COMMENTS
Google Scholar lets you broadly search for articles, theses, books, abstracts and court opinions across various disciplines and sources. You can also access your profile, library and settings to customize your search experience.
Learn how to write a research paper with tips and examples. Find out how to choose a topic, format, and check your paper.
Find the research you need | With 160+ million publication pages, 1+ million questions, and 25+ million researchers, this is where everyone can access science
Harness the power of visual materials—explore more than 3 million images now on JSTOR. Enhance your scholarly research with underground newspapers, magazines, and journals. Take your research further with Artstor's 3+ million images. Explore collections in the arts, sciences, and literature from the world's leading museums, archives, and ...
Semantic Scholar is a free, AI-powered research tool for scientific literature, based at Ai2. Semantic Scholar uses groundbreaking AI and engineering to understand the semantics of scientific literature to help Scholars discover relevant research.
Find research papers and scholarly sources for free with these seven academic search engines. Compare their features, coverage, and export formats, and learn how to use them with Paperpile.
Elsevier journals offer the latest peer-reviewed research papers on climate change, biodiversity, renewable energy and other topics addressing our planet's climate emergency. ... Keep up to date with health and medical developments to stimulate research and improve patient care. Search our books and journals covering education, reference ...
Access 160+ million publications and connect with 25+ million researchers. Join for free and gain visibility by uploading your research.
Scopus Search lets you find and filter over 92 million records from various fields and sources. You can also identify trends, discover authors and affiliations, and use advanced search options and filters.
Learn how to use Google Scholar to find recent papers, access full text, sort by date, and more. Explore related articles, citation links, and email alerts for your research topics.
Academia.edu is a platform for researchers to upload and access millions of papers in various topics and disciplines. You can browse by research interests, follow authors, and download 55 million PDFs for free.
Connected Papers is a tool that helps you discover and visualize related papers in any scientific field. You can use it to build a graph of similar papers, find prior and derivative works, and create your bibliography for your thesis.
CORE is a comprehensive bibliographic database of the world's scholarly literature, with 259M papers from around the world. It provides both metadata and full text access, as well as powerful services and data solutions for researchers, universities, and industry.
Web of Science is a leading platform for advanced scientific research and citation data analysis across all disciplines.
Learn how to use Google Scholar, a free academic search engine, to find research papers, books, and articles. Discover tips, tricks, and alternatives to Google Scholar for your academic research.
Academic search engine for students and researchers. Locates relevant academic search results from web pages, books, encyclopedias, and journals.
Advanced. Journal List. PubMed Central ® (PMC) is a free full-text archive of biomedical and life sciences journal literature at the U.S. National Institutes of Health's National Library of Medicine (NIH/NLM)
Make an impact and build your research profile in the open with ScienceOpen. Search and discover relevant research in over 95 million Open Access articles and article records; Share your expertise and get credit by publicly reviewing any article; Publish your poster or preprint and track usage and impact with article- and author-level metrics; Create a topical Collection to advance your ...
One of the largest and most authoritative collections of online journals, books, and research resources, covering life, health, social, and physical sciences.
About the directory. DOAJ is a unique and extensive index of diverse open access journals from around the world, driven by a growing community, and is committed to ensuring quality content is freely available online for everyone. DOAJ is committed to keeping its services free of charge, including being indexed, and its data freely available.
As you use PubMed your recent searches will appear here. Download. Delete. [x] No History items are available for download. History items expire after 8 hour of inactivity. Click 'Refresh' to clear items from the table, or click the 'X' to go back to the table. Refresh.
Browse by Subject. Area Studies. African American Studies African Studies American Indian Studies
arXiv is a free distribution service and an open-access archive for nearly 2.4 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.
Empirical research typically involves a robustness-efficiency tradeoff. A researcher seeking to estimate a scalar parameter can invoke strong assumptions to motivate a restricted estimator that is precise but may be heavily biased, or they can relax some of these assumptions to motivate a more robust, but variable, unrestricted estimator.
The purpose of the white paper is to convince an agency, organization, or governmental body to support a proposed idea based on well-research evidence. The white paper should be as long or short as it needs to be to successfully lay out convincing data and argumentation.
Recent advancements in large language models (LLMs) have sparked optimism about their potential to accelerate scientific discovery, with a growing number of works proposing research agents that autonomously generate and validate new ideas. Despite this, no evaluations have shown that LLM systems can take the very first step of producing novel, expert-level ideas, let alone perform the entire ...
They both will be coauthors on a paper and both provided valuable data, bringing a lot of enthusiasm, while learning quickly. They were a pleasure to work with." Participating PURM students, Sanan and Kim, he says, learned how important teamwork is in a research lab setting and how it is necessary to obtain successful results.
Academic journals, archives, and repositories are seeing an increasing number of questionable research papers clearly produced using generative AI. They are often created with widely available, general-purpose AI applications, most likely ChatGPT, and mimic scientific writing. Google Scholar easily locates and lists these questionable papers alongside reputable, quality-controlled research.
A recent study published in the Harvard Kennedy School's Misinformation Review found 139 papers on Google Scholar, a search engine for scholarly literature, that appear to be AI-generated. The ...
Summary.. Delegating work can help free up managers' time and energy while empowering their employees to take on meaningful tasks. Yet, previous research has shown that delegating decision ...