Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base

Hypothesis Testing | A Step-by-Step Guide with Easy Examples
Published on November 8, 2019 by Rebecca Bevans . Revised on June 22, 2023.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics . It is most often used by scientists to test specific predictions, called hypotheses, that arise from theories.
There are 5 main steps in hypothesis testing:
- State your research hypothesis as a null hypothesis and alternate hypothesis (H o ) and (H a or H 1 ).
- Collect data in a way designed to test the hypothesis.
- Perform an appropriate statistical test .
- Decide whether to reject or fail to reject your null hypothesis.
- Present the findings in your results and discussion section.
Though the specific details might vary, the procedure you will use when testing a hypothesis will always follow some version of these steps.
Table of contents
Step 1: state your null and alternate hypothesis, step 2: collect data, step 3: perform a statistical test, step 4: decide whether to reject or fail to reject your null hypothesis, step 5: present your findings, other interesting articles, frequently asked questions about hypothesis testing.
After developing your initial research hypothesis (the prediction that you want to investigate), it is important to restate it as a null (H o ) and alternate (H a ) hypothesis so that you can test it mathematically.
The alternate hypothesis is usually your initial hypothesis that predicts a relationship between variables. The null hypothesis is a prediction of no relationship between the variables you are interested in.
- H 0 : Men are, on average, not taller than women. H a : Men are, on average, taller than women.
Prevent plagiarism. Run a free check.
For a statistical test to be valid , it is important to perform sampling and collect data in a way that is designed to test your hypothesis. If your data are not representative, then you cannot make statistical inferences about the population you are interested in.
There are a variety of statistical tests available, but they are all based on the comparison of within-group variance (how spread out the data is within a category) versus between-group variance (how different the categories are from one another).
If the between-group variance is large enough that there is little or no overlap between groups, then your statistical test will reflect that by showing a low p -value . This means it is unlikely that the differences between these groups came about by chance.
Alternatively, if there is high within-group variance and low between-group variance, then your statistical test will reflect that with a high p -value. This means it is likely that any difference you measure between groups is due to chance.
Your choice of statistical test will be based on the type of variables and the level of measurement of your collected data .
- an estimate of the difference in average height between the two groups.
- a p -value showing how likely you are to see this difference if the null hypothesis of no difference is true.
Based on the outcome of your statistical test, you will have to decide whether to reject or fail to reject your null hypothesis.
In most cases you will use the p -value generated by your statistical test to guide your decision. And in most cases, your predetermined level of significance for rejecting the null hypothesis will be 0.05 – that is, when there is a less than 5% chance that you would see these results if the null hypothesis were true.
In some cases, researchers choose a more conservative level of significance, such as 0.01 (1%). This minimizes the risk of incorrectly rejecting the null hypothesis ( Type I error ).
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
The results of hypothesis testing will be presented in the results and discussion sections of your research paper , dissertation or thesis .
In the results section you should give a brief summary of the data and a summary of the results of your statistical test (for example, the estimated difference between group means and associated p -value). In the discussion , you can discuss whether your initial hypothesis was supported by your results or not.
In the formal language of hypothesis testing, we talk about rejecting or failing to reject the null hypothesis. You will probably be asked to do this in your statistics assignments.
However, when presenting research results in academic papers we rarely talk this way. Instead, we go back to our alternate hypothesis (in this case, the hypothesis that men are on average taller than women) and state whether the result of our test did or did not support the alternate hypothesis.
If your null hypothesis was rejected, this result is interpreted as “supported the alternate hypothesis.”
These are superficial differences; you can see that they mean the same thing.
You might notice that we don’t say that we reject or fail to reject the alternate hypothesis . This is because hypothesis testing is not designed to prove or disprove anything. It is only designed to test whether a pattern we measure could have arisen spuriously, or by chance.
If we reject the null hypothesis based on our research (i.e., we find that it is unlikely that the pattern arose by chance), then we can say our test lends support to our hypothesis . But if the pattern does not pass our decision rule, meaning that it could have arisen by chance, then we say the test is inconsistent with our hypothesis .
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Descriptive statistics
- Measures of central tendency
- Correlation coefficient
Methodology
- Cluster sampling
- Stratified sampling
- Types of interviews
- Cohort study
- Thematic analysis
Research bias
- Implicit bias
- Cognitive bias
- Survivorship bias
- Availability heuristic
- Nonresponse bias
- Regression to the mean
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 22). Hypothesis Testing | A Step-by-Step Guide with Easy Examples. Scribbr. Retrieved September 18, 2024, from https://www.scribbr.com/statistics/hypothesis-testing/
Is this article helpful?

Rebecca Bevans
Other students also liked, choosing the right statistical test | types & examples, understanding p values | definition and examples, what is your plagiarism score.
Society Homepage About Public Health Policy Contact
Data-driven hypothesis generation in clinical research: what we learned from a human subject study, article sidebar.

Submit your own article
Register as an author to reserve your spot in the next issue of the Medical Research Archives.
Join the Society
The European Society of Medicine is more than a professional association. We are a community. Our members work in countries across the globe, yet are united by a common goal: to promote health and health equity, around the world.
Join Europe’s leading medical society and discover the many advantages of membership, including free article publication.
Main Article Content
Hypothesis generation is an early and critical step in any hypothesis-driven clinical research project. Because it is not yet a well-understood cognitive process, the need to improve the process goes unrecognized. Without an impactful hypothesis, the significance of any research project can be questionable, regardless of the rigor or diligence applied in other steps of the study, e.g., study design, data collection, and result analysis. In this perspective article, the authors provide a literature review on the following topics first: scientific thinking, reasoning, medical reasoning, literature-based discovery, and a field study to explore scientific thinking and discovery. Over the years, scientific thinking has shown excellent progress in cognitive science and its applied areas: education, medicine, and biomedical research. However, a review of the literature reveals the lack of original studies on hypothesis generation in clinical research. The authors then summarize their first human participant study exploring data-driven hypothesis generation by clinical researchers in a simulated setting. The results indicate that a secondary data analytical tool, VIADS—a visual interactive analytic tool for filtering, summarizing, and visualizing large health data sets coded with hierarchical terminologies, can shorten the time participants need, on average, to generate a hypothesis and also requires fewer cognitive events to generate each hypothesis. As a counterpoint, this exploration also indicates that the quality ratings of the hypotheses thus generated carry significantly lower ratings for feasibility when applying VIADS. Despite its small scale, the study confirmed the feasibility of conducting a human participant study directly to explore the hypothesis generation process in clinical research. This study provides supporting evidence to conduct a larger-scale study with a specifically designed tool to facilitate the hypothesis-generation process among inexperienced clinical researchers. A larger study could provide generalizable evidence, which in turn can potentially improve clinical research productivity and overall clinical research enterprise.
Article Details
The Medical Research Archives grants authors the right to publish and reproduce the unrevised contribution in whole or in part at any time and in any form for any scholarly non-commercial purpose with the condition that all publications of the contribution include a full citation to the journal as published by the Medical Research Archives .

Hypothesis Generation and Interpretation
Design Principles and Patterns for Big Data Applications
- © 2024
- Hiroshi Ishikawa 0
Department of Systems Design, Tokyo Metropolitan University, Hino, Japan
You can also search for this author in PubMed Google Scholar
- Provides an integrated perspective on why decisions are made and how the process is modeled
- Presentation of design patterns enables use in a wide variety of big-data applications
- Multiple practical use cases indicate the broad real-world significance of the methods presented
Part of the book series: Studies in Big Data (SBD, volume 139)
2537 Accesses
This is a preview of subscription content, log in via an institution to check access.
Access this book
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as EPUB and PDF
- Read on any device
- Instant download
- Own it forever
- Durable hardcover edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Other ways to access
Licence this eBook for your library
Institutional subscriptions
About this book
The novel methods and technologies proposed in Hypothesis Generation and Interpretation are supported by the incorporation of historical perspectives on science and an emphasis on the origin and development of the ideas behind their design principles and patterns.
Similar content being viewed by others

A New Kind of Science: Big Data und Algorithmen verändern die Wissenschaft

Analysis, Visualization and Exploration Scenarios: Formal Methods for Systematic Meta Studies of Big Data Applications

The Nexus Between Big Data and Decision-Making: A Study of Big Data Techniques and Technologies
- Hypothesis Generation
- Hypothesis Interpretation
- Data Engineering
- Data Science
- Data Management
- Machine Learning
- Data Mining
- Design Patterns
- Design Principles
Table of contents (8 chapters)
Front matter, basic concept.
Hiroshi Ishikawa
Science and Hypothesis
Machine learning and integrated approach, hypothesis generation by difference, methods for integrated hypothesis generation, interpretation, back matter, authors and affiliations, about the author.
He has published actively in international, refereed journals and conferences, such as ACM Transactions on Database Systems , IEEE Transactions on Knowledge and Data Engineering , The VLDB Journal , IEEE International Conference on Data Engineering, and ACM SIGSPATIAL and Management of Emergent Digital EcoSystems (MEDES). He has authored and co-authored a dozen books, including Social Big Data Mining (CRC, 2015) and Object-Oriented Database System (Springer-Verlag, 1993).
Bibliographic Information
Book Title : Hypothesis Generation and Interpretation
Book Subtitle : Design Principles and Patterns for Big Data Applications
Authors : Hiroshi Ishikawa
Series Title : Studies in Big Data
DOI : https://doi.org/10.1007/978-3-031-43540-9
Publisher : Springer Cham
eBook Packages : Computer Science , Computer Science (R0)
Copyright Information : The Editor(s) (if applicable) and The Author(s), under exclusive license to Springer Nature Switzerland AG 2024
Hardcover ISBN : 978-3-031-43539-3 Published: 02 February 2024
Softcover ISBN : 978-3-031-43542-3 Due: 15 February 2025
eBook ISBN : 978-3-031-43540-9 Published: 01 January 2024
Series ISSN : 2197-6503
Series E-ISSN : 2197-6511
Edition Number : 1
Number of Pages : XII, 372
Number of Illustrations : 52 b/w illustrations, 125 illustrations in colour
Topics : Theory of Computation , Database Management , Data Mining and Knowledge Discovery , Machine Learning , Big Data , Complex Systems
- Publish with us
Policies and ethics
- Find a journal
- Track your research
- History & Society
- Science & Tech
- Biographies
- Animals & Nature
- Geography & Travel
- Arts & Culture
- Games & Quizzes
- On This Day
- One Good Fact
- New Articles
- Lifestyles & Social Issues
- Philosophy & Religion
- Politics, Law & Government
- World History
- Health & Medicine
- Browse Biographies
- Birds, Reptiles & Other Vertebrates
- Bugs, Mollusks & Other Invertebrates
- Environment
- Fossils & Geologic Time
- Entertainment & Pop Culture
- Sports & Recreation
- Visual Arts
- Demystified
- Image Galleries
- Infographics
- Top Questions
- Britannica Kids
- Saving Earth
- Space Next 50
- Student Center

- When did science begin?
- Where was science invented?

scientific hypothesis
Our editors will review what you’ve submitted and determine whether to revise the article.
- National Center for Biotechnology Information - PubMed Central - On the scope of scientific hypotheses
- LiveScience - What is a scientific hypothesis?
- The Royal Society - Open Science - On the scope of scientific hypotheses

scientific hypothesis , an idea that proposes a tentative explanation about a phenomenon or a narrow set of phenomena observed in the natural world. The two primary features of a scientific hypothesis are falsifiability and testability, which are reflected in an “If…then” statement summarizing the idea and in the ability to be supported or refuted through observation and experimentation. The notion of the scientific hypothesis as both falsifiable and testable was advanced in the mid-20th century by Austrian-born British philosopher Karl Popper .
The formulation and testing of a hypothesis is part of the scientific method , the approach scientists use when attempting to understand and test ideas about natural phenomena. The generation of a hypothesis frequently is described as a creative process and is based on existing scientific knowledge, intuition , or experience. Therefore, although scientific hypotheses commonly are described as educated guesses, they actually are more informed than a guess. In addition, scientists generally strive to develop simple hypotheses, since these are easier to test relative to hypotheses that involve many different variables and potential outcomes. Such complex hypotheses may be developed as scientific models ( see scientific modeling ).
Depending on the results of scientific evaluation, a hypothesis typically is either rejected as false or accepted as true. However, because a hypothesis inherently is falsifiable, even hypotheses supported by scientific evidence and accepted as true are susceptible to rejection later, when new evidence has become available. In some instances, rather than rejecting a hypothesis because it has been falsified by new evidence, scientists simply adapt the existing idea to accommodate the new information. In this sense a hypothesis is never incorrect but only incomplete.
The investigation of scientific hypotheses is an important component in the development of scientific theory . Hence, hypotheses differ fundamentally from theories; whereas the former is a specific tentative explanation and serves as the main tool by which scientists gather data, the latter is a broad general explanation that incorporates data from many different scientific investigations undertaken to explore hypotheses.
Countless hypotheses have been developed and tested throughout the history of science . Several examples include the idea that living organisms develop from nonliving matter, which formed the basis of spontaneous generation , a hypothesis that ultimately was disproved (first in 1668, with the experiments of Italian physician Francesco Redi , and later in 1859, with the experiments of French chemist and microbiologist Louis Pasteur ); the concept proposed in the late 19th century that microorganisms cause certain diseases (now known as germ theory ); and the notion that oceanic crust forms along submarine mountain zones and spreads laterally away from them ( seafloor spreading hypothesis ).

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Overview of the Scientific Method
10 Developing a Hypothesis
Learning objectives.
- Distinguish between a theory and a hypothesis.
- Discover how theories are used to generate hypotheses and how the results of studies can be used to further inform theories.
- Understand the characteristics of a good hypothesis.
Theories and Hypotheses
Before describing how to develop a hypothesis, it is important to distinguish between a theory and a hypothesis. A theory is a coherent explanation or interpretation of one or more phenomena. Although theories can take a variety of forms, one thing they have in common is that they go beyond the phenomena they explain by including variables, structures, processes, functions, or organizing principles that have not been observed directly. Consider, for example, Zajonc’s theory of social facilitation and social inhibition (1965) [1] . He proposed that being watched by others while performing a task creates a general state of physiological arousal, which increases the likelihood of the dominant (most likely) response. So for highly practiced tasks, being watched increases the tendency to make correct responses, but for relatively unpracticed tasks, being watched increases the tendency to make incorrect responses. Notice that this theory—which has come to be called drive theory—provides an explanation of both social facilitation and social inhibition that goes beyond the phenomena themselves by including concepts such as “arousal” and “dominant response,” along with processes such as the effect of arousal on the dominant response.
Outside of science, referring to an idea as a theory often implies that it is untested—perhaps no more than a wild guess. In science, however, the term theory has no such implication. A theory is simply an explanation or interpretation of a set of phenomena. It can be untested, but it can also be extensively tested, well supported, and accepted as an accurate description of the world by the scientific community. The theory of evolution by natural selection, for example, is a theory because it is an explanation of the diversity of life on earth—not because it is untested or unsupported by scientific research. On the contrary, the evidence for this theory is overwhelmingly positive and nearly all scientists accept its basic assumptions as accurate. Similarly, the “germ theory” of disease is a theory because it is an explanation of the origin of various diseases, not because there is any doubt that many diseases are caused by microorganisms that infect the body.
A hypothesis , on the other hand, is a specific prediction about a new phenomenon that should be observed if a particular theory is accurate. It is an explanation that relies on just a few key concepts. Hypotheses are often specific predictions about what will happen in a particular study. They are developed by considering existing evidence and using reasoning to infer what will happen in the specific context of interest. Hypotheses are often but not always derived from theories. So a hypothesis is often a prediction based on a theory but some hypotheses are a-theoretical and only after a set of observations have been made, is a theory developed. This is because theories are broad in nature and they explain larger bodies of data. So if our research question is really original then we may need to collect some data and make some observations before we can develop a broader theory.
Theories and hypotheses always have this if-then relationship. “ If drive theory is correct, then cockroaches should run through a straight runway faster, and a branching runway more slowly, when other cockroaches are present.” Although hypotheses are usually expressed as statements, they can always be rephrased as questions. “Do cockroaches run through a straight runway faster when other cockroaches are present?” Thus deriving hypotheses from theories is an excellent way of generating interesting research questions.
But how do researchers derive hypotheses from theories? One way is to generate a research question using the techniques discussed in this chapter and then ask whether any theory implies an answer to that question. For example, you might wonder whether expressive writing about positive experiences improves health as much as expressive writing about traumatic experiences. Although this question is an interesting one on its own, you might then ask whether the habituation theory—the idea that expressive writing causes people to habituate to negative thoughts and feelings—implies an answer. In this case, it seems clear that if the habituation theory is correct, then expressive writing about positive experiences should not be effective because it would not cause people to habituate to negative thoughts and feelings. A second way to derive hypotheses from theories is to focus on some component of the theory that has not yet been directly observed. For example, a researcher could focus on the process of habituation—perhaps hypothesizing that people should show fewer signs of emotional distress with each new writing session.
Among the very best hypotheses are those that distinguish between competing theories. For example, Norbert Schwarz and his colleagues considered two theories of how people make judgments about themselves, such as how assertive they are (Schwarz et al., 1991) [2] . Both theories held that such judgments are based on relevant examples that people bring to mind. However, one theory was that people base their judgments on the number of examples they bring to mind and the other was that people base their judgments on how easily they bring those examples to mind. To test these theories, the researchers asked people to recall either six times when they were assertive (which is easy for most people) or 12 times (which is difficult for most people). Then they asked them to judge their own assertiveness. Note that the number-of-examples theory implies that people who recalled 12 examples should judge themselves to be more assertive because they recalled more examples, but the ease-of-examples theory implies that participants who recalled six examples should judge themselves as more assertive because recalling the examples was easier. Thus the two theories made opposite predictions so that only one of the predictions could be confirmed. The surprising result was that participants who recalled fewer examples judged themselves to be more assertive—providing particularly convincing evidence in favor of the ease-of-retrieval theory over the number-of-examples theory.
Theory Testing
The primary way that scientific researchers use theories is sometimes called the hypothetico-deductive method (although this term is much more likely to be used by philosophers of science than by scientists themselves). Researchers begin with a set of phenomena and either construct a theory to explain or interpret them or choose an existing theory to work with. They then make a prediction about some new phenomenon that should be observed if the theory is correct. Again, this prediction is called a hypothesis. The researchers then conduct an empirical study to test the hypothesis. Finally, they reevaluate the theory in light of the new results and revise it if necessary. This process is usually conceptualized as a cycle because the researchers can then derive a new hypothesis from the revised theory, conduct a new empirical study to test the hypothesis, and so on. As Figure 2.3 shows, this approach meshes nicely with the model of scientific research in psychology presented earlier in the textbook—creating a more detailed model of “theoretically motivated” or “theory-driven” research.
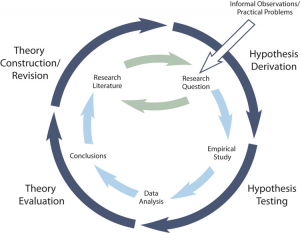
As an example, let us consider Zajonc’s research on social facilitation and inhibition. He started with a somewhat contradictory pattern of results from the research literature. He then constructed his drive theory, according to which being watched by others while performing a task causes physiological arousal, which increases an organism’s tendency to make the dominant response. This theory predicts social facilitation for well-learned tasks and social inhibition for poorly learned tasks. He now had a theory that organized previous results in a meaningful way—but he still needed to test it. He hypothesized that if his theory was correct, he should observe that the presence of others improves performance in a simple laboratory task but inhibits performance in a difficult version of the very same laboratory task. To test this hypothesis, one of the studies he conducted used cockroaches as subjects (Zajonc, Heingartner, & Herman, 1969) [3] . The cockroaches ran either down a straight runway (an easy task for a cockroach) or through a cross-shaped maze (a difficult task for a cockroach) to escape into a dark chamber when a light was shined on them. They did this either while alone or in the presence of other cockroaches in clear plastic “audience boxes.” Zajonc found that cockroaches in the straight runway reached their goal more quickly in the presence of other cockroaches, but cockroaches in the cross-shaped maze reached their goal more slowly when they were in the presence of other cockroaches. Thus he confirmed his hypothesis and provided support for his drive theory. (Zajonc also showed that drive theory existed in humans [Zajonc & Sales, 1966] [4] in many other studies afterward).
Incorporating Theory into Your Research
When you write your research report or plan your presentation, be aware that there are two basic ways that researchers usually include theory. The first is to raise a research question, answer that question by conducting a new study, and then offer one or more theories (usually more) to explain or interpret the results. This format works well for applied research questions and for research questions that existing theories do not address. The second way is to describe one or more existing theories, derive a hypothesis from one of those theories, test the hypothesis in a new study, and finally reevaluate the theory. This format works well when there is an existing theory that addresses the research question—especially if the resulting hypothesis is surprising or conflicts with a hypothesis derived from a different theory.
To use theories in your research will not only give you guidance in coming up with experiment ideas and possible projects, but it lends legitimacy to your work. Psychologists have been interested in a variety of human behaviors and have developed many theories along the way. Using established theories will help you break new ground as a researcher, not limit you from developing your own ideas.
Characteristics of a Good Hypothesis
There are three general characteristics of a good hypothesis. First, a good hypothesis must be testable and falsifiable . We must be able to test the hypothesis using the methods of science and if you’ll recall Popper’s falsifiability criterion, it must be possible to gather evidence that will disconfirm the hypothesis if it is indeed false. Second, a good hypothesis must be logical. As described above, hypotheses are more than just a random guess. Hypotheses should be informed by previous theories or observations and logical reasoning. Typically, we begin with a broad and general theory and use deductive reasoning to generate a more specific hypothesis to test based on that theory. Occasionally, however, when there is no theory to inform our hypothesis, we use inductive reasoning which involves using specific observations or research findings to form a more general hypothesis. Finally, the hypothesis should be positive. That is, the hypothesis should make a positive statement about the existence of a relationship or effect, rather than a statement that a relationship or effect does not exist. As scientists, we don’t set out to show that relationships do not exist or that effects do not occur so our hypotheses should not be worded in a way to suggest that an effect or relationship does not exist. The nature of science is to assume that something does not exist and then seek to find evidence to prove this wrong, to show that it really does exist. That may seem backward to you but that is the nature of the scientific method. The underlying reason for this is beyond the scope of this chapter but it has to do with statistical theory.
- Zajonc, R. B. (1965). Social facilitation. Science, 149 , 269–274 ↵
- Schwarz, N., Bless, H., Strack, F., Klumpp, G., Rittenauer-Schatka, H., & Simons, A. (1991). Ease of retrieval as information: Another look at the availability heuristic. Journal of Personality and Social Psychology, 61 , 195–202. ↵
- Zajonc, R. B., Heingartner, A., & Herman, E. M. (1969). Social enhancement and impairment of performance in the cockroach. Journal of Personality and Social Psychology, 13 , 83–92. ↵
- Zajonc, R.B. & Sales, S.M. (1966). Social facilitation of dominant and subordinate responses. Journal of Experimental Social Psychology, 2 , 160-168. ↵
A coherent explanation or interpretation of one or more phenomena.
A specific prediction about a new phenomenon that should be observed if a particular theory is accurate.
A cyclical process of theory development, starting with an observed phenomenon, then developing or using a theory to make a specific prediction of what should happen if that theory is correct, testing that prediction, refining the theory in light of the findings, and using that refined theory to develop new hypotheses, and so on.
The ability to test the hypothesis using the methods of science and the possibility to gather evidence that will disconfirm the hypothesis if it is indeed false.
Research Methods in Psychology Copyright © 2019 by Rajiv S. Jhangiani, I-Chant A. Chiang, Carrie Cuttler, & Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
- Data Science
- Data Analysis
- Data Visualization
- Machine Learning
- Deep Learning
- Computer Vision
- Artificial Intelligence
- AI ML DS Interview Series
- AI ML DS Projects series
- Data Engineering
- Web Scrapping
Understanding Hypothesis Testing
Hypothesis testing involves formulating assumptions about population parameters based on sample statistics and rigorously evaluating these assumptions against empirical evidence. This article sheds light on the significance of hypothesis testing and the critical steps involved in the process.
What is Hypothesis Testing?
A hypothesis is an assumption or idea, specifically a statistical claim about an unknown population parameter. For example, a judge assumes a person is innocent and verifies this by reviewing evidence and hearing testimony before reaching a verdict.
Hypothesis testing is a statistical method that is used to make a statistical decision using experimental data. Hypothesis testing is basically an assumption that we make about a population parameter. It evaluates two mutually exclusive statements about a population to determine which statement is best supported by the sample data.
To test the validity of the claim or assumption about the population parameter:
- A sample is drawn from the population and analyzed.
- The results of the analysis are used to decide whether the claim is true or not.
Example: You say an average height in the class is 30 or a boy is taller than a girl. All of these is an assumption that we are assuming, and we need some statistical way to prove these. We need some mathematical conclusion whatever we are assuming is true.
Defining Hypotheses
- Null hypothesis (H 0 ): In statistics, the null hypothesis is a general statement or default position that there is no relationship between two measured cases or no relationship among groups. In other words, it is a basic assumption or made based on the problem knowledge. Example : A company’s mean production is 50 units/per da H 0 : [Tex]\mu [/Tex] = 50.
- Alternative hypothesis (H 1 ): The alternative hypothesis is the hypothesis used in hypothesis testing that is contrary to the null hypothesis. Example: A company’s production is not equal to 50 units/per day i.e. H 1 : [Tex]\mu [/Tex] [Tex]\ne [/Tex] 50.
Key Terms of Hypothesis Testing
- Level of significance : It refers to the degree of significance in which we accept or reject the null hypothesis. 100% accuracy is not possible for accepting a hypothesis, so we, therefore, select a level of significance that is usually 5%. This is normally denoted with [Tex]\alpha[/Tex] and generally, it is 0.05 or 5%, which means your output should be 95% confident to give a similar kind of result in each sample.
- P-value: The P value , or calculated probability, is the probability of finding the observed/extreme results when the null hypothesis(H0) of a study-given problem is true. If your P-value is less than the chosen significance level then you reject the null hypothesis i.e. accept that your sample claims to support the alternative hypothesis.
- Test Statistic: The test statistic is a numerical value calculated from sample data during a hypothesis test, used to determine whether to reject the null hypothesis. It is compared to a critical value or p-value to make decisions about the statistical significance of the observed results.
- Critical value : The critical value in statistics is a threshold or cutoff point used to determine whether to reject the null hypothesis in a hypothesis test.
- Degrees of freedom: Degrees of freedom are associated with the variability or freedom one has in estimating a parameter. The degrees of freedom are related to the sample size and determine the shape.
Why do we use Hypothesis Testing?
Hypothesis testing is an important procedure in statistics. Hypothesis testing evaluates two mutually exclusive population statements to determine which statement is most supported by sample data. When we say that the findings are statistically significant, thanks to hypothesis testing.
One-Tailed and Two-Tailed Test
One tailed test focuses on one direction, either greater than or less than a specified value. We use a one-tailed test when there is a clear directional expectation based on prior knowledge or theory. The critical region is located on only one side of the distribution curve. If the sample falls into this critical region, the null hypothesis is rejected in favor of the alternative hypothesis.
One-Tailed Test
There are two types of one-tailed test:
- Left-Tailed (Left-Sided) Test: The alternative hypothesis asserts that the true parameter value is less than the null hypothesis. Example: H 0 : [Tex]\mu \geq 50 [/Tex] and H 1 : [Tex]\mu < 50 [/Tex]
- Right-Tailed (Right-Sided) Test : The alternative hypothesis asserts that the true parameter value is greater than the null hypothesis. Example: H 0 : [Tex]\mu \leq50 [/Tex] and H 1 : [Tex]\mu > 50 [/Tex]
Two-Tailed Test
A two-tailed test considers both directions, greater than and less than a specified value.We use a two-tailed test when there is no specific directional expectation, and want to detect any significant difference.
Example: H 0 : [Tex]\mu = [/Tex] 50 and H 1 : [Tex]\mu \neq 50 [/Tex]
To delve deeper into differences into both types of test: Refer to link
What are Type 1 and Type 2 errors in Hypothesis Testing?
In hypothesis testing, Type I and Type II errors are two possible errors that researchers can make when drawing conclusions about a population based on a sample of data. These errors are associated with the decisions made regarding the null hypothesis and the alternative hypothesis.
- Type I error: When we reject the null hypothesis, although that hypothesis was true. Type I error is denoted by alpha( [Tex]\alpha [/Tex] ).
- Type II errors : When we accept the null hypothesis, but it is false. Type II errors are denoted by beta( [Tex]\beta [/Tex] ).
Null Hypothesis is True | Null Hypothesis is False | |
|---|---|---|
Null Hypothesis is True (Accept) | Correct Decision | Type II Error (False Negative) |
Alternative Hypothesis is True (Reject) | Type I Error (False Positive) | Correct Decision |
How does Hypothesis Testing work?
Step 1: define null and alternative hypothesis.
State the null hypothesis ( [Tex]H_0 [/Tex] ), representing no effect, and the alternative hypothesis ( [Tex]H_1 [/Tex] ), suggesting an effect or difference.
We first identify the problem about which we want to make an assumption keeping in mind that our assumption should be contradictory to one another, assuming Normally distributed data.
Step 2 – Choose significance level
Select a significance level ( [Tex]\alpha [/Tex] ), typically 0.05, to determine the threshold for rejecting the null hypothesis. It provides validity to our hypothesis test, ensuring that we have sufficient data to back up our claims. Usually, we determine our significance level beforehand of the test. The p-value is the criterion used to calculate our significance value.
Step 3 – Collect and Analyze data.
Gather relevant data through observation or experimentation. Analyze the data using appropriate statistical methods to obtain a test statistic.
Step 4-Calculate Test Statistic
The data for the tests are evaluated in this step we look for various scores based on the characteristics of data. The choice of the test statistic depends on the type of hypothesis test being conducted.
There are various hypothesis tests, each appropriate for various goal to calculate our test. This could be a Z-test , Chi-square , T-test , and so on.
- Z-test : If population means and standard deviations are known. Z-statistic is commonly used.
- t-test : If population standard deviations are unknown. and sample size is small than t-test statistic is more appropriate.
- Chi-square test : Chi-square test is used for categorical data or for testing independence in contingency tables
- F-test : F-test is often used in analysis of variance (ANOVA) to compare variances or test the equality of means across multiple groups.
We have a smaller dataset, So, T-test is more appropriate to test our hypothesis.
T-statistic is a measure of the difference between the means of two groups relative to the variability within each group. It is calculated as the difference between the sample means divided by the standard error of the difference. It is also known as the t-value or t-score.
Step 5 – Comparing Test Statistic:
In this stage, we decide where we should accept the null hypothesis or reject the null hypothesis. There are two ways to decide where we should accept or reject the null hypothesis.
Method A: Using Crtical values
Comparing the test statistic and tabulated critical value we have,
- If Test Statistic>Critical Value: Reject the null hypothesis.
- If Test Statistic≤Critical Value: Fail to reject the null hypothesis.
Note: Critical values are predetermined threshold values that are used to make a decision in hypothesis testing. To determine critical values for hypothesis testing, we typically refer to a statistical distribution table , such as the normal distribution or t-distribution tables based on.
Method B: Using P-values
We can also come to an conclusion using the p-value,
- If the p-value is less than or equal to the significance level i.e. ( [Tex]p\leq\alpha [/Tex] ), you reject the null hypothesis. This indicates that the observed results are unlikely to have occurred by chance alone, providing evidence in favor of the alternative hypothesis.
- If the p-value is greater than the significance level i.e. ( [Tex]p\geq \alpha[/Tex] ), you fail to reject the null hypothesis. This suggests that the observed results are consistent with what would be expected under the null hypothesis.
Note : The p-value is the probability of obtaining a test statistic as extreme as, or more extreme than, the one observed in the sample, assuming the null hypothesis is true. To determine p-value for hypothesis testing, we typically refer to a statistical distribution table , such as the normal distribution or t-distribution tables based on.
Step 7- Interpret the Results
At last, we can conclude our experiment using method A or B.
Calculating test statistic
To validate our hypothesis about a population parameter we use statistical functions . We use the z-score, p-value, and level of significance(alpha) to make evidence for our hypothesis for normally distributed data .
1. Z-statistics:
When population means and standard deviations are known.
[Tex]z = \frac{\bar{x} – \mu}{\frac{\sigma}{\sqrt{n}}}[/Tex]
- [Tex]\bar{x} [/Tex] is the sample mean,
- μ represents the population mean,
- σ is the standard deviation
- and n is the size of the sample.
2. T-Statistics
T test is used when n<30,
t-statistic calculation is given by:
[Tex]t=\frac{x̄-μ}{s/\sqrt{n}} [/Tex]
- t = t-score,
- x̄ = sample mean
- μ = population mean,
- s = standard deviation of the sample,
- n = sample size
3. Chi-Square Test
Chi-Square Test for Independence categorical Data (Non-normally distributed) using:
[Tex]\chi^2 = \sum \frac{(O_{ij} – E_{ij})^2}{E_{ij}}[/Tex]
- [Tex]O_{ij}[/Tex] is the observed frequency in cell [Tex]{ij} [/Tex]
- i,j are the rows and columns index respectively.
- [Tex]E_{ij}[/Tex] is the expected frequency in cell [Tex]{ij}[/Tex] , calculated as : [Tex]\frac{{\text{{Row total}} \times \text{{Column total}}}}{{\text{{Total observations}}}}[/Tex]
Real life Examples of Hypothesis Testing
Let’s examine hypothesis testing using two real life situations,
Case A: D oes a New Drug Affect Blood Pressure?
Imagine a pharmaceutical company has developed a new drug that they believe can effectively lower blood pressure in patients with hypertension. Before bringing the drug to market, they need to conduct a study to assess its impact on blood pressure.
- Before Treatment: 120, 122, 118, 130, 125, 128, 115, 121, 123, 119
- After Treatment: 115, 120, 112, 128, 122, 125, 110, 117, 119, 114
Step 1 : Define the Hypothesis
- Null Hypothesis : (H 0 )The new drug has no effect on blood pressure.
- Alternate Hypothesis : (H 1 )The new drug has an effect on blood pressure.
Step 2: Define the Significance level
Let’s consider the Significance level at 0.05, indicating rejection of the null hypothesis.
If the evidence suggests less than a 5% chance of observing the results due to random variation.
Step 3 : Compute the test statistic
Using paired T-test analyze the data to obtain a test statistic and a p-value.
The test statistic (e.g., T-statistic) is calculated based on the differences between blood pressure measurements before and after treatment.
t = m/(s/√n)
- m = mean of the difference i.e X after, X before
- s = standard deviation of the difference (d) i.e d i = X after, i − X before,
- n = sample size,
then, m= -3.9, s= 1.8 and n= 10
we, calculate the , T-statistic = -9 based on the formula for paired t test
Step 4: Find the p-value
The calculated t-statistic is -9 and degrees of freedom df = 9, you can find the p-value using statistical software or a t-distribution table.
thus, p-value = 8.538051223166285e-06
Step 5: Result
- If the p-value is less than or equal to 0.05, the researchers reject the null hypothesis.
- If the p-value is greater than 0.05, they fail to reject the null hypothesis.
Conclusion: Since the p-value (8.538051223166285e-06) is less than the significance level (0.05), the researchers reject the null hypothesis. There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different.
Python Implementation of Case A
Let’s create hypothesis testing with python, where we are testing whether a new drug affects blood pressure. For this example, we will use a paired T-test. We’ll use the scipy.stats library for the T-test.
Scipy is a mathematical library in Python that is mostly used for mathematical equations and computations.
We will implement our first real life problem via python,
import numpy as np from scipy import stats # Data before_treatment = np . array ([ 120 , 122 , 118 , 130 , 125 , 128 , 115 , 121 , 123 , 119 ]) after_treatment = np . array ([ 115 , 120 , 112 , 128 , 122 , 125 , 110 , 117 , 119 , 114 ]) # Step 1: Null and Alternate Hypotheses # Null Hypothesis: The new drug has no effect on blood pressure. # Alternate Hypothesis: The new drug has an effect on blood pressure. null_hypothesis = "The new drug has no effect on blood pressure." alternate_hypothesis = "The new drug has an effect on blood pressure." # Step 2: Significance Level alpha = 0.05 # Step 3: Paired T-test t_statistic , p_value = stats . ttest_rel ( after_treatment , before_treatment ) # Step 4: Calculate T-statistic manually m = np . mean ( after_treatment - before_treatment ) s = np . std ( after_treatment - before_treatment , ddof = 1 ) # using ddof=1 for sample standard deviation n = len ( before_treatment ) t_statistic_manual = m / ( s / np . sqrt ( n )) # Step 5: Decision if p_value <= alpha : decision = "Reject" else : decision = "Fail to reject" # Conclusion if decision == "Reject" : conclusion = "There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different." else : conclusion = "There is insufficient evidence to claim a significant difference in average blood pressure before and after treatment with the new drug." # Display results print ( "T-statistic (from scipy):" , t_statistic ) print ( "P-value (from scipy):" , p_value ) print ( "T-statistic (calculated manually):" , t_statistic_manual ) print ( f "Decision: { decision } the null hypothesis at alpha= { alpha } ." ) print ( "Conclusion:" , conclusion )
T-statistic (from scipy): -9.0 P-value (from scipy): 8.538051223166285e-06 T-statistic (calculated manually): -9.0 Decision: Reject the null hypothesis at alpha=0.05. Conclusion: There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different.
In the above example, given the T-statistic of approximately -9 and an extremely small p-value, the results indicate a strong case to reject the null hypothesis at a significance level of 0.05.
- The results suggest that the new drug, treatment, or intervention has a significant effect on lowering blood pressure.
- The negative T-statistic indicates that the mean blood pressure after treatment is significantly lower than the assumed population mean before treatment.
Case B : Cholesterol level in a population
Data: A sample of 25 individuals is taken, and their cholesterol levels are measured.
Cholesterol Levels (mg/dL): 205, 198, 210, 190, 215, 205, 200, 192, 198, 205, 198, 202, 208, 200, 205, 198, 205, 210, 192, 205, 198, 205, 210, 192, 205.
Populations Mean = 200
Population Standard Deviation (σ): 5 mg/dL(given for this problem)
Step 1: Define the Hypothesis
- Null Hypothesis (H 0 ): The average cholesterol level in a population is 200 mg/dL.
- Alternate Hypothesis (H 1 ): The average cholesterol level in a population is different from 200 mg/dL.
As the direction of deviation is not given , we assume a two-tailed test, and based on a normal distribution table, the critical values for a significance level of 0.05 (two-tailed) can be calculated through the z-table and are approximately -1.96 and 1.96.
The test statistic is calculated by using the z formula Z = [Tex](203.8 – 200) / (5 \div \sqrt{25}) [/Tex] and we get accordingly , Z =2.039999999999992.
Step 4: Result
Since the absolute value of the test statistic (2.04) is greater than the critical value (1.96), we reject the null hypothesis. And conclude that, there is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL
Python Implementation of Case B
import scipy.stats as stats import math import numpy as np # Given data sample_data = np . array ( [ 205 , 198 , 210 , 190 , 215 , 205 , 200 , 192 , 198 , 205 , 198 , 202 , 208 , 200 , 205 , 198 , 205 , 210 , 192 , 205 , 198 , 205 , 210 , 192 , 205 ]) population_std_dev = 5 population_mean = 200 sample_size = len ( sample_data ) # Step 1: Define the Hypotheses # Null Hypothesis (H0): The average cholesterol level in a population is 200 mg/dL. # Alternate Hypothesis (H1): The average cholesterol level in a population is different from 200 mg/dL. # Step 2: Define the Significance Level alpha = 0.05 # Two-tailed test # Critical values for a significance level of 0.05 (two-tailed) critical_value_left = stats . norm . ppf ( alpha / 2 ) critical_value_right = - critical_value_left # Step 3: Compute the test statistic sample_mean = sample_data . mean () z_score = ( sample_mean - population_mean ) / \ ( population_std_dev / math . sqrt ( sample_size )) # Step 4: Result # Check if the absolute value of the test statistic is greater than the critical values if abs ( z_score ) > max ( abs ( critical_value_left ), abs ( critical_value_right )): print ( "Reject the null hypothesis." ) print ( "There is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL." ) else : print ( "Fail to reject the null hypothesis." ) print ( "There is not enough evidence to conclude that the average cholesterol level in the population is different from 200 mg/dL." )
Reject the null hypothesis. There is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL.
Limitations of Hypothesis Testing
- Although a useful technique, hypothesis testing does not offer a comprehensive grasp of the topic being studied. Without fully reflecting the intricacy or whole context of the phenomena, it concentrates on certain hypotheses and statistical significance.
- The accuracy of hypothesis testing results is contingent on the quality of available data and the appropriateness of statistical methods used. Inaccurate data or poorly formulated hypotheses can lead to incorrect conclusions.
- Relying solely on hypothesis testing may cause analysts to overlook significant patterns or relationships in the data that are not captured by the specific hypotheses being tested. This limitation underscores the importance of complimenting hypothesis testing with other analytical approaches.
Hypothesis testing stands as a cornerstone in statistical analysis, enabling data scientists to navigate uncertainties and draw credible inferences from sample data. By systematically defining null and alternative hypotheses, choosing significance levels, and leveraging statistical tests, researchers can assess the validity of their assumptions. The article also elucidates the critical distinction between Type I and Type II errors, providing a comprehensive understanding of the nuanced decision-making process inherent in hypothesis testing. The real-life example of testing a new drug’s effect on blood pressure using a paired T-test showcases the practical application of these principles, underscoring the importance of statistical rigor in data-driven decision-making.
Frequently Asked Questions (FAQs)
1. what are the 3 types of hypothesis test.
There are three types of hypothesis tests: right-tailed, left-tailed, and two-tailed. Right-tailed tests assess if a parameter is greater, left-tailed if lesser. Two-tailed tests check for non-directional differences, greater or lesser.
2.What are the 4 components of hypothesis testing?
Null Hypothesis ( [Tex]H_o [/Tex] ): No effect or difference exists. Alternative Hypothesis ( [Tex]H_1 [/Tex] ): An effect or difference exists. Significance Level ( [Tex]\alpha [/Tex] ): Risk of rejecting null hypothesis when it’s true (Type I error). Test Statistic: Numerical value representing observed evidence against null hypothesis.
3.What is hypothesis testing in ML?
Statistical method to evaluate the performance and validity of machine learning models. Tests specific hypotheses about model behavior, like whether features influence predictions or if a model generalizes well to unseen data.
4.What is the difference between Pytest and hypothesis in Python?
Pytest purposes general testing framework for Python code while Hypothesis is a Property-based testing framework for Python, focusing on generating test cases based on specified properties of the code.
Please Login to comment...
Similar reads.
- data-science
- Best External Hard Drives for Mac in 2024: Top Picks for MacBook Pro, MacBook Air & More
- How to Watch NFL Games Live Streams Free
- OpenAI o1 AI Model Launched: Explore o1-Preview, o1-Mini, Pricing & Comparison
- How to Merge Cells in Google Sheets: Step by Step Guide
- #geekstreak2024 – 21 Days POTD Challenge Powered By Deutsche Bank
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Developing a Hypothesis
Rajiv S. Jhangiani; I-Chant A. Chiang; Carrie Cuttler; and Dana C. Leighton
Learning Objectives
- Distinguish between a theory and a hypothesis.
- Discover how theories are used to generate hypotheses and how the results of studies can be used to further inform theories.
- Understand the characteristics of a good hypothesis.
Theories and Hypotheses
Before describing how to develop a hypothesis, it is important to distinguish between a theory and a hypothesis. A theory is a coherent explanation or interpretation of one or more phenomena. Although theories can take a variety of forms, one thing they have in common is that they go beyond the phenomena they explain by including variables, structures, processes, functions, or organizing principles that have not been observed directly. Consider, for example, Zajonc’s theory of social facilitation and social inhibition (1965) [1] . He proposed that being watched by others while performing a task creates a general state of physiological arousal, which increases the likelihood of the dominant (most likely) response. So for highly practiced tasks, being watched increases the tendency to make correct responses, but for relatively unpracticed tasks, being watched increases the tendency to make incorrect responses. Notice that this theory—which has come to be called drive theory—provides an explanation of both social facilitation and social inhibition that goes beyond the phenomena themselves by including concepts such as “arousal” and “dominant response,” along with processes such as the effect of arousal on the dominant response.
Outside of science, referring to an idea as a theory often implies that it is untested—perhaps no more than a wild guess. In science, however, the term theory has no such implication. A theory is simply an explanation or interpretation of a set of phenomena. It can be untested, but it can also be extensively tested, well supported, and accepted as an accurate description of the world by the scientific community. The theory of evolution by natural selection, for example, is a theory because it is an explanation of the diversity of life on earth—not because it is untested or unsupported by scientific research. On the contrary, the evidence for this theory is overwhelmingly positive and nearly all scientists accept its basic assumptions as accurate. Similarly, the “germ theory” of disease is a theory because it is an explanation of the origin of various diseases, not because there is any doubt that many diseases are caused by microorganisms that infect the body.
A hypothesis , on the other hand, is a specific prediction about a new phenomenon that should be observed if a particular theory is accurate. It is an explanation that relies on just a few key concepts. Hypotheses are often specific predictions about what will happen in a particular study. They are developed by considering existing evidence and using reasoning to infer what will happen in the specific context of interest. Hypotheses are often but not always derived from theories. So a hypothesis is often a prediction based on a theory but some hypotheses are a-theoretical and only after a set of observations have been made, is a theory developed. This is because theories are broad in nature and they explain larger bodies of data. So if our research question is really original then we may need to collect some data and make some observations before we can develop a broader theory.
Theories and hypotheses always have this if-then relationship. “ If drive theory is correct, then cockroaches should run through a straight runway faster, and a branching runway more slowly, when other cockroaches are present.” Although hypotheses are usually expressed as statements, they can always be rephrased as questions. “Do cockroaches run through a straight runway faster when other cockroaches are present?” Thus deriving hypotheses from theories is an excellent way of generating interesting research questions.
But how do researchers derive hypotheses from theories? One way is to generate a research question using the techniques discussed in this chapter and then ask whether any theory implies an answer to that question. For example, you might wonder whether expressive writing about positive experiences improves health as much as expressive writing about traumatic experiences. Although this question is an interesting one on its own, you might then ask whether the habituation theory—the idea that expressive writing causes people to habituate to negative thoughts and feelings—implies an answer. In this case, it seems clear that if the habituation theory is correct, then expressive writing about positive experiences should not be effective because it would not cause people to habituate to negative thoughts and feelings. A second way to derive hypotheses from theories is to focus on some component of the theory that has not yet been directly observed. For example, a researcher could focus on the process of habituation—perhaps hypothesizing that people should show fewer signs of emotional distress with each new writing session.
Among the very best hypotheses are those that distinguish between competing theories. For example, Norbert Schwarz and his colleagues considered two theories of how people make judgments about themselves, such as how assertive they are (Schwarz et al., 1991) [2] . Both theories held that such judgments are based on relevant examples that people bring to mind. However, one theory was that people base their judgments on the number of examples they bring to mind and the other was that people base their judgments on how easily they bring those examples to mind. To test these theories, the researchers asked people to recall either six times when they were assertive (which is easy for most people) or 12 times (which is difficult for most people). Then they asked them to judge their own assertiveness. Note that the number-of-examples theory implies that people who recalled 12 examples should judge themselves to be more assertive because they recalled more examples, but the ease-of-examples theory implies that participants who recalled six examples should judge themselves as more assertive because recalling the examples was easier. Thus the two theories made opposite predictions so that only one of the predictions could be confirmed. The surprising result was that participants who recalled fewer examples judged themselves to be more assertive—providing particularly convincing evidence in favor of the ease-of-retrieval theory over the number-of-examples theory.
Theory Testing
The primary way that scientific researchers use theories is sometimes called the hypothetico-deductive method (although this term is much more likely to be used by philosophers of science than by scientists themselves). Researchers begin with a set of phenomena and either construct a theory to explain or interpret them or choose an existing theory to work with. They then make a prediction about some new phenomenon that should be observed if the theory is correct. Again, this prediction is called a hypothesis. The researchers then conduct an empirical study to test the hypothesis. Finally, they reevaluate the theory in light of the new results and revise it if necessary. This process is usually conceptualized as a cycle because the researchers can then derive a new hypothesis from the revised theory, conduct a new empirical study to test the hypothesis, and so on. As Figure 2.3 shows, this approach meshes nicely with the model of scientific research in psychology presented earlier in the textbook—creating a more detailed model of “theoretically motivated” or “theory-driven” research.
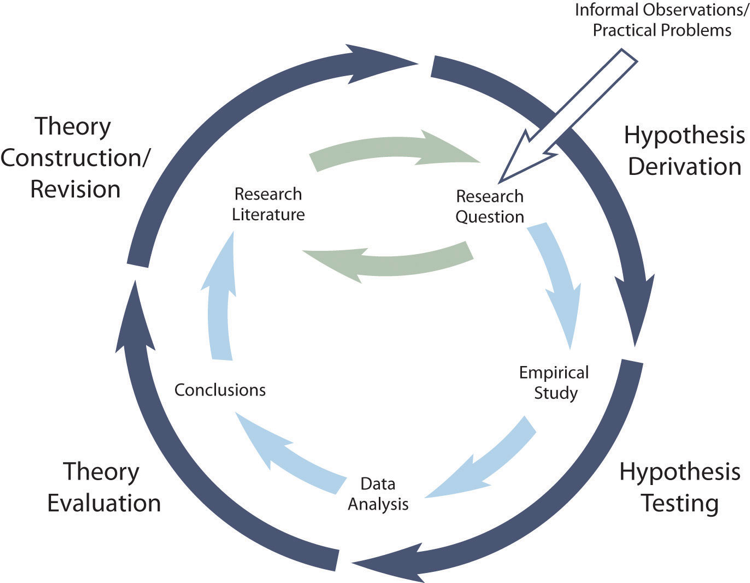
As an example, let us consider Zajonc’s research on social facilitation and inhibition. He started with a somewhat contradictory pattern of results from the research literature. He then constructed his drive theory, according to which being watched by others while performing a task causes physiological arousal, which increases an organism’s tendency to make the dominant response. This theory predicts social facilitation for well-learned tasks and social inhibition for poorly learned tasks. He now had a theory that organized previous results in a meaningful way—but he still needed to test it. He hypothesized that if his theory was correct, he should observe that the presence of others improves performance in a simple laboratory task but inhibits performance in a difficult version of the very same laboratory task. To test this hypothesis, one of the studies he conducted used cockroaches as subjects (Zajonc, Heingartner, & Herman, 1969) [3] . The cockroaches ran either down a straight runway (an easy task for a cockroach) or through a cross-shaped maze (a difficult task for a cockroach) to escape into a dark chamber when a light was shined on them. They did this either while alone or in the presence of other cockroaches in clear plastic “audience boxes.” Zajonc found that cockroaches in the straight runway reached their goal more quickly in the presence of other cockroaches, but cockroaches in the cross-shaped maze reached their goal more slowly when they were in the presence of other cockroaches. Thus he confirmed his hypothesis and provided support for his drive theory. (Zajonc also showed that drive theory existed in humans [Zajonc & Sales, 1966] [4] in many other studies afterward).
Incorporating Theory into Your Research
When you write your research report or plan your presentation, be aware that there are two basic ways that researchers usually include theory. The first is to raise a research question, answer that question by conducting a new study, and then offer one or more theories (usually more) to explain or interpret the results. This format works well for applied research questions and for research questions that existing theories do not address. The second way is to describe one or more existing theories, derive a hypothesis from one of those theories, test the hypothesis in a new study, and finally reevaluate the theory. This format works well when there is an existing theory that addresses the research question—especially if the resulting hypothesis is surprising or conflicts with a hypothesis derived from a different theory.
To use theories in your research will not only give you guidance in coming up with experiment ideas and possible projects, but it lends legitimacy to your work. Psychologists have been interested in a variety of human behaviors and have developed many theories along the way. Using established theories will help you break new ground as a researcher, not limit you from developing your own ideas.
Characteristics of a Good Hypothesis
There are three general characteristics of a good hypothesis. First, a good hypothesis must be testable and falsifiable . We must be able to test the hypothesis using the methods of science and if you’ll recall Popper’s falsifiability criterion, it must be possible to gather evidence that will disconfirm the hypothesis if it is indeed false. Second, a good hypothesis must be logical. As described above, hypotheses are more than just a random guess. Hypotheses should be informed by previous theories or observations and logical reasoning. Typically, we begin with a broad and general theory and use deductive reasoning to generate a more specific hypothesis to test based on that theory. Occasionally, however, when there is no theory to inform our hypothesis, we use inductive reasoning which involves using specific observations or research findings to form a more general hypothesis. Finally, the hypothesis should be positive. That is, the hypothesis should make a positive statement about the existence of a relationship or effect, rather than a statement that a relationship or effect does not exist. As scientists, we don’t set out to show that relationships do not exist or that effects do not occur so our hypotheses should not be worded in a way to suggest that an effect or relationship does not exist. The nature of science is to assume that something does not exist and then seek to find evidence to prove this wrong, to show that it really does exist. That may seem backward to you but that is the nature of the scientific method. The underlying reason for this is beyond the scope of this chapter but it has to do with statistical theory.
- Zajonc, R. B. (1965). Social facilitation. Science, 149 , 269–274 ↵
- Schwarz, N., Bless, H., Strack, F., Klumpp, G., Rittenauer-Schatka, H., & Simons, A. (1991). Ease of retrieval as information: Another look at the availability heuristic. Journal of Personality and Social Psychology, 61 , 195–202. ↵
- Zajonc, R. B., Heingartner, A., & Herman, E. M. (1969). Social enhancement and impairment of performance in the cockroach. Journal of Personality and Social Psychology, 13 , 83–92. ↵
- Zajonc, R.B. & Sales, S.M. (1966). Social facilitation of dominant and subordinate responses. Journal of Experimental Social Psychology, 2 , 160-168. ↵
A coherent explanation or interpretation of one or more phenomena.
A specific prediction about a new phenomenon that should be observed if a particular theory is accurate.
A cyclical process of theory development, starting with an observed phenomenon, then developing or using a theory to make a specific prediction of what should happen if that theory is correct, testing that prediction, refining the theory in light of the findings, and using that refined theory to develop new hypotheses, and so on.
The ability to test the hypothesis using the methods of science and the possibility to gather evidence that will disconfirm the hypothesis if it is indeed false.
Developing a Hypothesis Copyright © by Rajiv S. Jhangiani; I-Chant A. Chiang; Carrie Cuttler; and Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
- About the LSE Impact Blog
- Comments Policy
- Popular Posts
- Recent Posts
- Subscribe to the Impact Blog
- Write for us
- LSE comment
February 3rd, 2016
Putting hypotheses to the test: we must hold ourselves accountable to decisions made before we see the data..
5 comments | 2 shares
Estimated reading time: 5 minutes

We are giving $1,000 prizes to 1,000 scholars simply for making clear when data were used to generate or test a hypothesis. Science is the best tool we have for understanding the way the natural world works. Unfortunately, it is in our imperfect hands . Though scientists are curious and can be quite clever , we also fall victim to biases that can cloud our vision. We seek rewards from our community, we ignore information that contradicts what we believe, and we are capable of elaborate rationalizations for our decisions. We are masters of self-deception .
Yet we don’t want to be. Many scientists choose their career because they are curious and want to find real answers to meaningful questions. In its idealized form, science is a process of proposing explanations and then using data to expose their weaknesses and improve them. This process is both elegant and brutal. It is elegant when we find a new way to explain the world, a way that no one has thought of before. It is brutal in a way that is familiar to any graduate student who has proposed an experiment to a committee or to any researcher who has submitted a paper for peer-review. Logical errors, alternative explanations, and falsification are not just common – they are baked into the process.
Image credit: Winnowing Grain Eastman Johnson Museum of Fine Arts, Boston
Using data to generate potential discoveries and using data to subject those discoveries to tests are distinct processes. This distinction is known as exploratory (or hypothesis-generating) research and confirmatory (or hypothesis-testing) research. In the daily practice of doing research, it is easy to confuse which one is being done. But there is a way – preregistration. Preregistration defines how a hypothesis or research question will be tested – the methodology and analysis plan. It is written down in advance of looking at the data, and it maximizes the diagnosticity of the statistical inferences used to test the hypothesis. After the confirmatory test, the data can then be subjected to any exploratory analyses to identify new hypotheses that can be the focus of a new study. In this way, preregistration provides an unambiguous distinction between exploratory and confirmatory research.The two actions, building and tearing down, are both crucial to advancing our knowledge. Building pushes our potential knowledge a bit further than it was before. Tearing down separates the wheat from the chaff. It exposes that new potential explanation to every conceivable test to see if it survives.
To illustrate how confirmatory and exploratory approaches can be easily confused, picture a path through a garden, forking at regular intervals, as it spreads out into a wide tree. Each split in this garden of forking paths is a decision that can be made when analysing a data set. Do you exclude these samples because they are too extreme? Do you control for income/age/height/wealth? Do you use the mean or median of the measurements? Each decision can be perfectly justifiable and seem insignificant in the moment. After a few of these decisions there exists a surprisingly large number of reasonable analyses. One quickly reaches the point where there are so many of these reasonable analyses, that the traditional threshold of statistical significance, p < .05, or 1 in 20, can be obtained by chance alone .

If we don’t have strong reasons to make these decisions ahead of time, we are simply exploring the dataset for the path that tells the most interesting story. Once we find that interesting story, bolstered by the weight of statistical significance, every decision on that path becomes even more justified, and all of the reasonable, alternative paths are forgotten. Without us realizing what we have done, the diagnosticity of our statistical inferences is gone. We have no idea if our significant result is a product of accumulated luck with random error in the data, or if it is revealing a truly unusual result worthy of interpretation.
This is why we must hold ourselves accountable to decisions made before seeing the data. Without putting those reasons into a time-stamped, uneditable plan, it becomes nearly impossible to avoid making decisions that lead to the most interesting story. This is what preregistration does. Without preregistration, we effectively change our hypothesis as we make those decisions along the forking path. The work that we thought was confirmatory becomes exploratory without us even realizing it.
I am advocating for a way to make sure the data we use to create our explanations is separated from the data that we use to test those explanations. Preregistration does not put science in chains . Scientists should be free to explore the garden and to advance knowledge. Novelty, happenstance, and unexpected findings are core elements of discovery. However, when it comes time to put our new explanations to the test, we will make progress more efficiently and effectively by being as rigorous and as free from bias as possible.
Preregistration is effective. After the United States required that all clinical trials of new treatments on human subjects be preregistered, the rate of finding a significant effect on the primary outcome variable fell from 57% to just 8% within a group of 55 cardiovascular studies. This suggests that flexibility in analytical decisions had an enormous effect on the analysis and publication of these large studies. Preregistration is supported by journals and research funders . Taking this step will show that you are taking every reasonable precaution to reach the most robust conclusions possible, and will improve the weight of your assertions.
Most scientists, when testing a hypothesis, do not specify key analytical decisions prior to looking through a dataset. It’s not what we’re trained to do. We at the Center for Open Science want to change that. We will be giving 1,000 researchers $1,000 prizes for publishing the results of preregistered work. You can be one of them. Begin your preregistration by going to https://cos.io/prereg .

Note: This article gives the views of the author(s), and not the position of the LSE Impact blog, nor of the London School of Economics. Please review our Comments Policy if you have any concerns on posting a comment below.
About the Author:
David Mellor is a Project Manager at the Center for Open Science and works to encourage preregistration. He received his PhD from Rutgers University in Ecology and Evolution has been an active researcher in the behavioral ecology and citizen science communities.

About the author

I strongly agree with almost all of this. One question, though. I sometimes take part in studies that use path models. It can happen that a referee suggests an additional pathway that makes sense to us. But this would not have been in the original specification of the model. Come to think of it this kind of thing must happen pretty often. How would you view that?
That is a great point and is a very frequent occurrence. I think that the vast majority of papers come out of peer review with one or more changes in how the data are analyzed. The best way to handle that is with transparency: “The following, additional paths (or tests, interactions, correlations, etc..) were conducted after data collection was complete…” The important distinction is to not present those new pathways as simply part of the a-priori tests or to lump them with the same analyses presented initially and planned ahead of time. This way, the reader will be able to properly situate those new tests in the complete body of evidence presented in the paper. After data collection and initial analysis, any new tests were created by being influenced by the data and are, in essence, a new hypothesis that is now being tested with the same data that was used to create it. That new test can be confirmed with later follow up study using newly collected data.
Doesn’t this just say – we can only be honest by being rigid? It carries hypothetico-deductive ‘logic’ to a silly extreme, ignoring the inherently iterative process of theorization, recognition of interesting phenomena, and data analysis. But, creative research is not like this. How can you formulate meaningful hypotheses without thinking about and recognizing patterning in the data – the two go hand in hand, and are not the same as simply ‘milking’ data for significant results.
- Pingback: Testing a Hypothesis? Be Upfront About It and Win $1,000
Hi Patrick, Thank you for commenting. I very much agree that meaningful hypotheses cannot be made without recognizing patterns in the date. That may the best way to make a reasonable hypothesis. However, the same data that are used to create the hypothesis cannot be used to test that same hypothesis, and this is what preregistration does. It makes it clear to ourselves exactly what the hypothesis is before seeing the data, so that the data aren’t then used to subtly change/create a new hypothesis. If it does, fine, great! But that is hypothesis building, not hypothesis testing. That is exploratory work, not confirmatory work.
Leave a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Notify me of follow-up comments by email.
Related Posts

Qualitative and quantitative research are fundamentally distinct and differences are paramount to the social sciences
December 12th, 2014.

Could Blockchain provide the technical fix to solve science’s reproducibility crisis?
July 21st, 2016.

Your grant application is about to die: Research teams that recognise gender dimension offer a competitive advantage.
June 16th, 2015.

Was the REF a waste of time? Strong relationship between grant income and quality-related funding allocation.
August 25th, 2015.

Visit our sister blog LSE Review of Books
- A-Z Publications
Annual Review of Psychology
Volume 48, 1997, review article, creative hypothesis generating in psychology: some useful heuristics.
- William J. McGuire 1
- View Affiliations Hide Affiliations Affiliations: Department of Psychology, Yale University, 2 Hillhouse Avenue, New Haven, Connecticut P.O. Box 208205, 06520-8205
- Vol. 48:1-30 (Volume publication date February 1997) https://doi.org/10.1146/annurev.psych.48.1.1
- © Annual Reviews
To correct a common imbalance in methodology courses, focusing almost entirely on hypothesis-testing issues to the neglect of hypothesis-generating issues which are at least as important, 49 creative heuristics are described, divided into 5 categories and 14 subcategories. Each of these heuristics has often been used to generate hypotheses in psychological research, and each is teachable to students. The 49 heuristics range from common sense perceptiveness of the oddity of natural occurrences to use of sophisticated quantitative data analyses in ways that provoke new insights.
Article metrics loading...
Full text loading...
Literature Cited
- Abelson RP , Aronson E , McGuire WJ , Newcomb TM , Rosenberg MJ , Tannenbaum PH . eds 1968 . Theories of Cognitive Consistency . Chicago: Rand-McNally [Google Scholar]
- Anderson NH . 1982 . Methods of Information Integration Theory . New York: Academic [Google Scholar]
- Anzieu D . 1986 . Freud's Self-Analysis . Madison, CT: Int. Univ. Press [Google Scholar]
- Argylle M , Cook M . 1976 . Gaze and Mutual Gaze . Cambridge: Cambridge Univ. Press [Google Scholar]
- Breckler SJ . 1984 . Empirical validation of affect, behavior, and cognition as distinct components of attitude.. J. Pers. Soc. Psychol. 47 : 1191– 205 [Google Scholar]
- Brock TC . 1965 . Communicator-recipient similarity and decision change.. J. Pers. Soc. Psychol. 1 : 650– 54 [Google Scholar]
- Bush RR , Mosteller F . 1955 . Stochastic Models for Learning . New York: Wiley [Google Scholar]
- Byrne D . 1971 . The Attraction Paradigm . New York: Academic [Google Scholar]
- Campbell DT . 1963 . Social attitudes and other acquired behavioral dispositions. In Psychology: A Study of a Science , ed. S Koch 6 94– 172 New York: McGraw-Hill [Google Scholar]
- Cialdini RB . 1993 . Influence: Science and Practice . New York: Harper Collins. 3rd ed [Google Scholar]
- Collins BE , Hoyt MF . 1972 . Personal responsibility-for-consequences: an integration and extension of the “forced compliance” literature.. J. Exp. Soc. Psychol. 8 : 558– 93 [Google Scholar]
- Deaux K . 1972 . To err is humanizing: but sex makes a difference.. Represent. Res. Soc. Psychol. 3 : 20– 28 [Google Scholar]
- Eagly AH . 1974 . Comprehensibility of persuasive arguments as a determinant of opinion change.. J. Pers. Soc. Psychol. 29 : 758– 73 [Google Scholar]
- Eagly AH , Carli LL . 1981 . Sex of researchers and sex-typed communications as determinants of sex differences in influenceability: a meta-analysis of social influence studies.. Psychol. Bull. 90 : 1– 20 [Google Scholar]
- Estes WK . 1950 . Toward a statistical theory of learning.. Psychol. Rev. 57 : 94– 107 [Google Scholar]
- Festinger L . 1957 . A Theory of Cognitive Dissonance . Stanford, CA: Stanford Univ. Press [Google Scholar]
- Festinger L . 1964 . Conflict, Decision, and Dissonance . Stanford, CA: Stanford Univ. Press [Google Scholar]
- Greenwald AG , Pratkanis AR , Leippe MR , Baumgardner MH . 1986 . Under what conditions does theory obstruct research progress?. Psychol. Rev. 93 : 216– 29 [Google Scholar]
- Heilbron JL . 1986 . The Dilemmas of an Up-right Man: Max Planck as Spokesman for German Science . Berkeley, CA: Univ. Calif. Press [Google Scholar]
- Hornstein HA , LaKind E , Frankel G , Manne S . 1975 . Effects of knowledge about remote social events on prosocial behavior, social conception, and mood.. J. Pers. Soc. Psychol. 32 : 1038– 46 [Google Scholar]
- Hovland CI . 1952 . A “communication analysis” of concept learning.. Psychol. Rev. 59 : 461– 72 [Google Scholar]
- Hovland CI . 1959 . Reconciling conflicting results derived from experimental and field studies of attitude change.. Am. Psychol. 14 : 8– 17 [Google Scholar]
- Hovland CI , Lumsdaine AA , Sheffield FD . 1949 . Studies in Social Psychology in World War II , Vol. 3, Experiments on Mass Communication . Princeton, NJ: Princeton Univ. Press [Google Scholar]
- Hull CL . 1933 . Hypnosis and Suggestibility . New York: Appleton-Century [Google Scholar]
- Hull CL . 1952 . A Behavior System . New Haven, CT: Yale Univ. Press [Google Scholar]
- Hull CL , Hovland CI , Ross RT , Hall M , Perkins DT , Fitch FB . 1940 . Mathematico-deductive Theory of Rote Learning . New Haven, CT: Yale Univ. Press [Google Scholar]
- Johnson BT , Eagly AH . 1990 . Involvement and persuasion: types, traditions, and the evidence.. Psychol. Bull. 107 : 375– 84 [Google Scholar]
- McClelland DC . 1961 . The Achieving Society . Princeton, NJ: Van Nostrand [Google Scholar]
- McGuire AM . 1994 . Helping behaviors in the natural environment: dimensions and correlates of helping.. Pers. Soc. Psychol. Bull. 20 : 45– 56 [Google Scholar]
- McGuire WJ . 1964 . Inducing resistance to persuasion. In Advances in Experimental Social Psychology , ed. L Berkowitz 1 191– 229 New York: Academic [Google Scholar]
- McGuire WJ . 1968 . Personality and susceptibility to social influence. In Handbook of Personality Theory and Research , ed. EF Borgatta, WW Lambert 1130– 87 Chicago: Rand-McNally [Google Scholar]
- McGuire WJ . 1973 . The yin and yang of progress in social psychology: seven koan.. J. Pers. Soc. Psychol. 26 : 446– 56 [Google Scholar]
- McGuire WJ . 1983 . A contextualist theory of knowledge: its implications for innovation and reform in psychological research. In Advances in Experimental Social Psychology , ed. L Berkowitz 16 1– 47 New York: Academic [Google Scholar]
- McGuire WJ . 1984 . Search for the self: going beyond self-esteem and the reactive self. In Personality and the Prediction of Behavior , ed. RA Zucker, J Aronoff, AI Rabin 73– 120 New York: Academic [Google Scholar]
- McGuire WJ . 1985 . Attitudes and attitude change. In Handbook of Social Psychology , ed. G Lindsey, E Aronson pp. 3 233– 346 New York: Random House. 3rd ed [Google Scholar]
- McGuire WJ . 1986 . The vicissitudes of attitudes and similar representational constructs in twentieth century psychology.. Eur. J. Soc. Psychol. 16 : 89– 130 [Google Scholar]
- McGuire WJ . 1989 . A perspectivist approach to the strategic planning of programmatic scientific research. In The Psychology of Science: Contributions to Metascience , ed. B Gholson, A Houts, R Neimeyer, WR Shadish 214– 45 New York: Cambridge Univ. Press [Google Scholar]
- Milgram S . 1976 . Interview. In The Making of Psychology , ed. RI Evans 187– 97 New York: Knopf [Google Scholar]
- Neustadt RE , May ER . 1986 . Thinking in Time: the Uses of History for Decision Makers . New York: Free Press [Google Scholar]
- Nisbett RE , Wilson TD . 1977 . Telling more than we can know: verbal report on mental processes.. Psychol. Rev. 84 : 231– 59 [Google Scholar]
- Ostrom TM . 1988 . Computer simulation: the third symbol system.. J. Exp. Soc. Psychol. 24 : 381– 92 [Google Scholar]
- Petty RE , Cacioppo J . 1986 . Communication and Persuasion: Central and Peripheral Routes to Attitude Change . New York: Springer-Verlag [Google Scholar]
- Pratkanis AR , Greenwald AG , Leippe MR , Baumgardner MH . 1988 . In search of reliable persuasion effects. III. The sleeper effect is dead. Long live the sleeper effect J. Pers. Soc. Psychol. 54 : 203– 18 [Google Scholar]
- Rokeach M . 1973 . The Nature of Human Values . New York: Free Press [Google Scholar]
- Rumelhart DE , McClelland JL . 1986 . On learning the past tenses of English verbs. In Parallel Distributed Processing , ed. DE Rumelhart, JL McClelland 2 216– 71 Cambridge, MA: MIT Press [Google Scholar]
Data & Media loading...
- Article Type: Review Article
Most Read This Month
Most cited most cited rss feed, job burnout, executive functions, social cognitive theory: an agentic perspective, on happiness and human potentials: a review of research on hedonic and eudaimonic well-being, sources of method bias in social science research and recommendations on how to control it, mediation analysis, missing data analysis: making it work in the real world, grounded cognition, personality structure: emergence of the five-factor model, motivational beliefs, values, and goals.

- Books, Journals, Papers
- Guides & How To’s
- Life Around The World
- Research Methods
- Functionalism
- Postmodernism
- Social Constructionism
- Structuralism
- Symbolic Interactionism
- Sociology Theorists
- General Sociology
- Social Policy
- Social Work
- Sociology of Childhood
- Sociology of Crime & Deviance
- Sociology of Art
- Sociology of Dance
- Sociology of Food
- Sociology of Sport
- Sociology of Disability
- Sociology of Economics
- Sociology of Education
- Sociology of Emotion
- Sociology of Family & Relationships
- Sociology of Gender
- Sociology of Health
- Sociology of Identity
- Sociology of Ideology
- Sociology of Inequalities
- Sociology of Knowledge
- Sociology of Language
- Sociology of Law
- Sociology of Anime
- Sociology of Film
- Sociology of Gaming
- Sociology of Literature
- Sociology of Music
- Sociology of TV
- Sociology of Migration
- Sociology of Nature & Environment
- Sociology of Politics
- Sociology of Power
- Sociology of Race & Ethnicity
- Sociology of Religion
- Sociology of Sexuality
- Sociology of Social Movements
- Sociology of Technology
- Sociology of the Life Course
- Sociology of Travel & Tourism
- Sociology of Violence & Conflict
- Sociology of Work
- Urban Sociology
- Changing Relationships Within Families
- Conjugal Role Relationships
- Criticisms of Families
- Family Forms
- Functions of the Family
- Featured Articles
- Privacy Policy
- Terms & Conditions
What is a Hypothesis?

Table of Contents
Defining the hypothesis, the role of a hypothesis in the scientific method, types of hypotheses, hypothesis formulation, hypotheses and variables.
- The Importance of Testing Hypotheses
- The Hypothesis and Sociological Theory
In sociology, as in other scientific disciplines, the hypothesis serves as a crucial building block for research. It is a central element that directs the inquiry and provides a framework for testing the relationships between social phenomena. This article will explore what a hypothesis is, how it is formulated, and its role within the broader scientific method. By understanding the hypothesis, students of sociology can grasp how sociologists construct and test theories about the social world.
A hypothesis is a specific, testable statement about the relationship between two or more variables. It acts as a proposed explanation or prediction based on limited evidence, which researchers then test through empirical investigation. In essence, it is a statement that can be supported or refuted by data gathered from observation, experimentation, or other forms of systematic inquiry. The hypothesis typically takes the form of an “if-then” statement: if one variable changes, then another will change in response.
In sociological research, a hypothesis helps to focus the investigation by offering a clear proposition that can be tested. For instance, a sociologist might hypothesize that an increase in education levels leads to a decrease in crime rates. This hypothesis gives the researcher a direction, guiding them to collect data on education and crime, and analyze the relationship between the two variables. By doing so, the hypothesis serves as a tool for making sense of complex social phenomena.
The hypothesis is a key component of the scientific method, which is the systematic process by which sociologists and other scientists investigate the world. The scientific method begins with an observation of the world, followed by the formulation of a question or problem. Based on prior knowledge, theory, or preliminary observations, researchers then develop a hypothesis, which predicts an outcome or proposes a relationship between variables.
Once a hypothesis is established, researchers gather data to test it. If the data supports the hypothesis, it may be used to build a broader theory or to further refine the understanding of the social phenomenon in question. If the data contradicts the hypothesis, researchers may revise their hypothesis or abandon it altogether, depending on the strength of the evidence. In either case, the hypothesis helps to organize the research process, ensuring that it remains focused and methodologically sound.
In sociology, this method is particularly important because the social world is highly complex. Researchers must navigate a vast range of variables—age, gender, class, race, education, and countless others—that interact in unpredictable ways. A well-constructed hypothesis allows sociologists to narrow their focus to a manageable set of variables, making the investigation more precise and efficient.
Sociologists use different types of hypotheses, depending on the nature of their research question and the methods they plan to use. Broadly speaking, hypotheses can be classified into two main types: null hypotheses and alternative (or research) hypotheses.
Null Hypothesis
The null hypothesis, denoted as H0, states that there is no relationship between the variables being studied. It is a default assumption that any observed differences or relationships are due to random chance rather than a real underlying cause. In research, the null hypothesis serves as a point of comparison. Researchers collect data to see if the results allow them to reject the null hypothesis in favor of an alternative explanation.
For example, a sociologist studying the relationship between income and political participation might propose a null hypothesis that income has no effect on political participation. The goal of the research would then be to determine whether this null hypothesis can be rejected based on the data. If the data shows a significant correlation between income and political participation, the null hypothesis would be rejected.
Alternative Hypothesis
The alternative hypothesis, denoted as H1 or Ha, proposes that there is a significant relationship between the variables. This is the hypothesis that researchers aim to support with their data. In contrast to the null hypothesis, the alternative hypothesis predicts a specific direction or effect. For example, a researcher might hypothesize that higher levels of education lead to greater political engagement. In this case, the alternative hypothesis is proposing a positive correlation between the two variables.
The alternative hypothesis is the one that guides the research design, as it directs the researcher toward gathering evidence that will either support or refute the predicted relationship. The research process is structured around testing this hypothesis and determining whether the evidence is strong enough to reject the null hypothesis.
The process of formulating a hypothesis is both an art and a science. It requires a deep understanding of the social phenomena under investigation, as well as a clear sense of what is possible to observe and measure. Hypothesis formulation is closely linked to the theoretical framework that guides the research. Sociologists draw on existing theories to generate hypotheses, ensuring that their predictions are grounded in established knowledge.
To formulate a good hypothesis, a researcher must identify the key variables and determine how they are expected to relate to one another. Variables are the factors or characteristics that are being measured in a study. In sociology, these variables often include social attributes such as class, race, gender, age, education, and income, as well as behavioral variables like voting, criminal activity, or social participation.
For example, a sociologist studying the effects of social media on self-esteem might propose the following hypothesis: “Increased time spent on social media leads to lower levels of self-esteem among adolescents.” Here, the independent variable is the time spent on social media, and the dependent variable is the level of self-esteem. The hypothesis predicts a negative relationship between the two variables: as time spent on social media increases, self-esteem decreases.
A strong hypothesis has several key characteristics. It should be clear and specific, meaning that it unambiguously states the relationship between the variables. It should also be testable, meaning that it can be supported or refuted through empirical investigation. Finally, it should be grounded in theory, meaning that it is based on existing knowledge about the social phenomenon in question.
Membership Required
You must be a member to access this content.
View Membership Levels
Mr Edwards has a PhD in sociology and 10 years of experience in sociological knowledge
Related Articles

Field Experiment in Sociology: Concept, Methodology, and Applications
Field experiments are a critical methodological approach in sociology that allows researchers to study social phenomena in natural settings while...

Coding in Research: An Overview and Explanation in Sociology
Learn about the concept of coding in research, its importance, and various methods used in sociological studies. Coding allows researchers...

Social Constructionism: An Introduction
Get the latest sociology.
How would you rate the content on Easy Sociology?
Recommended

Understanding AIDS in Sociology

Expressive and Instrumental Ties in Sociology
24 hour trending.

Robert Merton’s Strain Theory Explained
Symbolic interactionism: understanding symbols, functionalism: an introduction, understanding the concept of ‘community’ in sociology, pierre bourdieu’s symbolic violence: an outline and explanation.
Easy Sociology makes sociology as easy as possible. Our aim is to make sociology accessible for everybody. © 2023 Easy Sociology
© 2023 Easy Sociology
January 13, 2024

Demystifying Hypothesis Generation: A Guide to AI-Driven Insights
Hypothesis generation involves making informed guesses about various aspects of a business, market, or problem that need further exploration and testing. This article discusses the process you need to follow while generating hypothesis and how an AI tool, like Akaike's BYOB can help you achieve the process quicker and better.

What is Hypothesis Generation?
Hypothesis generation involves making informed guesses about various aspects of a business, market, or problem that need further exploration and testing. It's a crucial step while applying the scientific method to business analysis and decision-making.
Here is an example from a popular B-school marketing case study:
A bicycle manufacturer noticed that their sales had dropped significantly in 2002 compared to the previous year. The team investigating the reasons for this had many hypotheses. One of them was: “many cycling enthusiasts have switched to walking with their iPods plugged in.” The Apple iPod was launched in late 2001 and was an immediate hit among young consumers. Data collected manually by the team seemed to show that the geographies around Apple stores had indeed shown a sales decline.
Traditionally, hypothesis generation is time-consuming and labour-intensive. However, the advent of Large Language Models (LLMs) and Generative AI (GenAI) tools has transformed the practice altogether. These AI tools can rapidly process extensive datasets, quickly identifying patterns, correlations, and insights that might have even slipped human eyes, thus streamlining the stages of hypothesis generation.
These tools have also revolutionised experimentation by optimising test designs, reducing resource-intensive processes, and delivering faster results. LLMs' role in hypothesis generation goes beyond mere assistance, bringing innovation and easy, data-driven decision-making to businesses.
Hypotheses come in various types, such as simple, complex, null, alternative, logical, statistical, or empirical. These categories are defined based on the relationships between the variables involved and the type of evidence required for testing them. In this article, we aim to demystify hypothesis generation. We will explore the role of LLMs in this process and outline the general steps involved, highlighting why it is a valuable tool in your arsenal.
Understanding Hypothesis Generation
A hypothesis is born from a set of underlying assumptions and a prediction of how those assumptions are anticipated to unfold in a given context. Essentially, it's an educated, articulated guess that forms the basis for action and outcome assessment.
A hypothesis is a declarative statement that has not yet been proven true. Based on past scholarship , we could sum it up as the following:
- A definite statement, not a question
- Based on observations and knowledge
- Testable and can be proven wrong
- Predicts the anticipated results clearly
- Contains a dependent and an independent variable where the dependent variable is the phenomenon being explained and the independent variable does the explaining
In a business setting, hypothesis generation becomes essential when people are made to explain their assumptions. This clarity from hypothesis to expected outcome is crucial, as it allows people to acknowledge a failed hypothesis if it does not provide the intended result. Promoting such a culture of effective hypothesising can lead to more thoughtful actions and a deeper understanding of outcomes. Failures become just another step on the way to success, and success brings more success.
Hypothesis generation is a continuous process where you start with an educated guess and refine it as you gather more information. You form a hypothesis based on what you know or observe.
Say you're a pen maker whose sales are down. You look at what you know:
- I can see that pen sales for my brand are down in May and June.
- I also know that schools are closed in May and June and that schoolchildren use a lot of pens.
- I hypothesise that my sales are down because school children are not using pens in May and June, and thus not buying newer ones.
The next step is to collect and analyse data to test this hypothesis, like tracking sales before and after school vacations. As you gather more data and insights, your hypothesis may evolve. You might discover that your hypothesis only holds in certain markets but not others, leading to a more refined hypothesis.
Once your hypothesis is proven correct, there are many actions you may take - (a) reduce supply in these months (b) reduce the price so that sales pick up (c) release a limited supply of novelty pens, and so on.
Once you decide on your action, you will further monitor the data to see if your actions are working. This iterative cycle of formulating, testing, and refining hypotheses - and using insights in decision-making - is vital in making impactful decisions and solving complex problems in various fields, from business to scientific research.
How do Analysts generate Hypotheses? Why is it iterative?
A typical human working towards a hypothesis would start with:
1. Picking the Default Action
2. Determining the Alternative Action
3. Figuring out the Null Hypothesis (H0)
4. Inverting the Null Hypothesis to get the Alternate Hypothesis (H1)
5. Hypothesis Testing
The default action is what you would naturally do, regardless of any hypothesis or in a case where you get no further information. The alternative action is the opposite of your default action.
The null hypothesis, or H0, is what brings about your default action. The alternative hypothesis (H1) is essentially the negation of H0.
For example, suppose you are tasked with analysing a highway tollgate data (timestamp, vehicle number, toll amount) to see if a raise in tollgate rates will increase revenue or cause a volume drop. Following the above steps, we can determine:
| Default Action | “I want to increase toll rates by 10%.” |
| Alternative Action | “I will keep my rates constant.” |
| H | “A 10% increase in the toll rate will not cause a significant dip in traffic (say 3%).” |
| H | “A 10% increase in the toll rate will cause a dip in traffic of greater than 3%.” |
Now, we can start looking at past data of tollgate traffic in and around rate increases for different tollgates. Some data might be irrelevant. For example, some tollgates might be much cheaper so customers might not have cared about an increase. Or, some tollgates are next to a large city, and customers have no choice but to pay.
Ultimately, you are looking for the level of significance between traffic and rates for comparable tollgates. Significance is often noted as its P-value or probability value . P-value is a way to measure how surprising your test results are, assuming that your H0 holds true.
The lower the p-value, the more convincing your data is to change your default action.
Usually, a p-value that is less than 0.05 is considered to be statistically significant, meaning there is a need to change your null hypothesis and reject your default action. In our example, a low p-value would suggest that a 10% increase in the toll rate causes a significant dip in traffic (>3%). Thus, it is better if we keep our rates as is if we want to maintain revenue.
In other examples, where one has to explore the significance of different variables, we might find that some variables are not correlated at all. In general, hypothesis generation is an iterative process - you keep looking for data and keep considering whether that data convinces you to change your default action.
Internal and External Data
Hypothesis generation feeds on data. Data can be internal or external. In businesses, internal data is produced by company owned systems (areas such as operations, maintenance, personnel, finance, etc). External data comes from outside the company (customer data, competitor data, and so on).
Let’s consider a real-life hypothesis generated from internal data:
Multinational company Johnson & Johnson was looking to enhance employee performance and retention. Initially, they favoured experienced industry candidates for recruitment, assuming they'd stay longer and contribute faster. However, HR and the people analytics team at J&J hypothesised that recent college graduates outlast experienced hires and perform equally well. They compiled data on 47,000 employees to test the hypothesis and, based on it, Johnson & Johnson increased hires of new graduates by 20% , leading to reduced turnover with consistent performance.
For an analyst (or an AI assistant), external data is often hard to source - it may not be available as organised datasets (or reports), or it may be expensive to acquire. Teams might have to collect new data from surveys, questionnaires, customer feedback and more.
Further, there is the problem of context. Suppose an analyst is looking at the dynamic pricing of hotels offered on his company’s platform in a particular geography. Suppose further that the analyst has no context of the geography, the reasons people visit the locality, or of local alternatives; then the analyst will have to learn additional context to start making hypotheses to test.
Internal data, of course, is internal, meaning access is already guaranteed. However, this probably adds up to staggering volumes of data.
Looking Back, and Looking Forward
Data analysts often have to generate hypotheses retrospectively, where they formulate and evaluate H0 and H1 based on past data. For the sake of this article, let's call it retrospective hypothesis generation.
Alternatively, a prospective approach to hypothesis generation could be one where hypotheses are formulated before data collection or before a particular event or change is implemented.
For example:
A pen seller has a hypothesis that during the lean periods of summer, when schools are closed, a Buy One Get One (BOGO) campaign will lead to a 100% sales recovery because customers will buy pens in advance. He then collects feedback from customers in the form of a survey and also implements a BOGO campaign in a single territory to see whether his hypothesis is correct, or not.
The HR head of a multi-office employer realises that some of the company’s offices have been providing snacks at 4:30 PM in the common area, and the rest have not. He has a hunch that these offices have higher productivity. The leader asks the company’s data science team to look at employee productivity data and the employee location data. “Am I correct, and to what extent?”, he asks.
These examples also reflect another nuance, in which the data is collected differently:
- Observational: Observational testing happens when researchers observe a sample population and collect data as it occurs without intervention. The data for the snacks vs productivity hypothesis was observational.
- Experimental: In experimental testing, the sample is divided into multiple groups, with one control group. The test for the non-control groups will be varied to determine how the data collected differs from that of the control group. The data collected by the pen seller in the single territory experiment was experimental.
Such data-backed insights are a valuable resource for businesses because they allow for more informed decision-making, leading to the company's overall growth. Taking a data-driven decision, from forming a hypothesis to updating and validating it across iterations, to taking action based on your insights reduces guesswork, minimises risks, and guides businesses towards strategies that are more likely to succeed.
How can GenAI help in Hypothesis Generation?
Of course, hypothesis generation is not always straightforward. Understanding the earlier examples is easy for us because we're already inundated with context. But, in a situation where an analyst has no domain knowledge, suddenly, hypothesis generation becomes a tedious and challenging process.
AI, particularly high-capacity, robust tools such as LLMs, have radically changed how we process and analyse large volumes of data. With its help, we can sift through massive datasets with precision and speed, regardless of context, whether it's customer behaviour, financial trends, medical records, or more. Generative AI, including LLMs, are trained on diverse text data, enabling them to comprehend and process various topics.
Now, imagine an AI assistant helping you with hypothesis generation. LLMs are not born with context. Instead, they are trained upon vast amounts of data, enabling them to develop context in a completely unfamiliar environment. This skill is instrumental when adopting a more exploratory approach to hypothesis generation. For example, the HR leader from earlier could simply ask an LLM tool: “Can you look at this employee productivity data and find cohorts of high-productivity and see if they correlate to any other employee data like location, pedigree, years of service, marital status, etc?”
For an LLM-based tool to be useful, it requires a few things:
- Domain Knowledge: A human could take months to years to acclimatise to a particular field fully, but LLMs, when fed extensive information and utilising Natural Language Processing (NLP), can familiarise themselves in a very short time.
- Explainability: Explainability is its ability to explain its thought process and output to cease being a "black box".
- Customisation: For consistent improvement, contextual AI must allow tweaks, allowing users to change its behaviour to meet their expectations. Human intervention and validation is a necessary step in adoptingAI tools. NLP allows these tools to discern context within textual data, meaning it can read, categorise, and analyse data with unimaginable speed. LLMs, thus, can quickly develop contextual understanding and generate human-like text while processing vast amounts of unstructured data, making it easier for businesses and researchers to organise and utilise data effectively.LLMs have the potential to become indispensable tools for businesses. The future rests on AI tools that harness the powers of LLMs and NLP to deliver actionable insights, mitigate risks, inform decision-making, predict future trends, and drive business transformation across various sectors.
Together, these technologies empower data analysts to unravel hidden insights within their data. For our pen maker, for example, an AI tool could aid data analytics. It can look through historical data to track when sales peaked or go through sales data to identify the pens that sold the most. It can refine a hypothesis across iterations, just as a human analyst would. It can even be used to brainstorm other hypotheses. Consider the situation where you ask the LLM, " Where do I sell the most pens? ". It will go through all of the data you have made available - places where you sell pens, the number of pens you sold - to return the answer. Now, if we were to do this on our own, even if we were particularly meticulous about keeping records, it would take us at least five to ten minutes, that too, IF we know how to query a database and extract the needed information. If we don't, there's the added effort required to find and train such a person. An AI assistant, on the other hand, could share the answer with us in mere seconds. Its finely-honed talents in sorting through data, identifying patterns, refining hypotheses iteratively, and generating data-backed insights enhance problem-solving and decision-making, supercharging our business model.
Top-Down and Bottom-Up Hypothesis Generation
As we discussed earlier, every hypothesis begins with a default action that determines your initial hypotheses and all your subsequent data collection. You look at data and a LOT of data. The significance of your data is dependent on the effect and the relevance it has to your default action. This would be a top-down approach to hypothesis generation.
There is also the bottom-up method , where you start by going through your data and figuring out if there are any interesting correlations that you could leverage better. This method is usually not as focused as the earlier approach and, as a result, involves even more data collection, processing, and analysis. AI is a stellar tool for Exploratory Data Analysis (EDA). Wading through swathes of data to highlight trends, patterns, gaps, opportunities, errors, and concerns is hardly a challenge for an AI tool equipped with NLP and powered by LLMs.
EDA can help with:
- Cleaning your data
- Understanding your variables
- Analysing relationships between variables
An AI assistant performing EDA can help you review your data, remove redundant data points, identify errors, note relationships, and more. All of this ensures ease, efficiency, and, best of all, speed for your data analysts.
Good hypotheses are extremely difficult to generate. They are nuanced and, without necessary context, almost impossible to ascertain in a top-down approach. On the other hand, an AI tool adopting an exploratory approach is swift, easily running through available data - internal and external.
If you want to rearrange how your LLM looks at your data, you can also do that. Changing the weight you assign to the various events and categories in your data is a simple process. That’s why LLMs are a great tool in hypothesis generation - analysts can tailor them to their specific use cases.
Ethical Considerations and Challenges
There are numerous reasons why you should adopt AI tools into your hypothesis generation process. But why are they still not as popular as they should be?
Some worry that AI tools can inadvertently pick up human biases through the data it is fed. Others fear AI and raise privacy and trust concerns. Data quality and ability are also often questioned. Since LLMs and Generative AI are developing technologies, such issues are bound to be, but these are all obstacles researchers are earnestly tackling.
One oft-raised complaint against LLM tools (like OpenAI's ChatGPT) is that they 'fill in' gaps in knowledge, providing information where there is none, thus giving inaccurate, embellished, or outright wrong answers; this tendency to "hallucinate" was a major cause for concern. But, to combat this phenomenon, newer AI tools have started providing citations with the insights they offer so that their answers become verifiable. Human validation is an essential step in interpreting AI-generated hypotheses and queries in general. This is why we need a collaboration between the intelligent and artificially intelligent mind to ensure optimised performance.
Clearly, hypothesis generation is an immensely time-consuming activity. But AI can take care of all these steps for you. From helping you figure out your default action, determining all the major research questions, initial hypotheses and alternative actions, and exhaustively weeding through your data to collect all relevant points, AI can help make your analysts' jobs easier. It can take any approach - prospective, retrospective, exploratory, top-down, bottom-up, etc. Furthermore, with LLMs, your structured and unstructured data are taken care of, meaning no more worries about messy data! With the wonders of human intuition and the ease and reliability of Generative AI and Large Language Models, you can speed up and refine your process of hypothesis generation based on feedback and new data to provide the best assistance to your business.
Related Posts
The latest industry news, interviews, technologies, and resources.

What is Open Source AI, Exactly?
.jpg)
Analyst 2.0: How is AI Changing the Role of Data Analysts
The future belongs to those who forge a symbiotic relationship between Human Ingenuity and Machine Intelligence

From Development to Deployment: Exploring the LLMOps Life Cycle
Discover how Large Language Models (LLMs) are revolutionizing enterprise AI with capabilities like text generation, sentiment analysis, and language translation. Learn about LLMOps, the specialized practices for deploying, monitoring, and maintaining LLMs in production, ensuring reliability, performance, and security in business operations.

8 Ways By Which AI Fraud Detection Helps Financial Firms
In the era of the Digital revolution, financial systems and AI fraud detection go hand-in-hand as they share a common characteristic.
Knowledge Center
Case Studies

© 2023 Akaike Technologies Pvt. Ltd. and/or its associates and partners
Terms of Use
Privacy Policy
Terms of Service
© Akaike Technologies Pvt. Ltd. and/or its associates and partners

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- My Bibliography
- Collections
- Citation manager
Save citation to file
Email citation, add to collections.
- Create a new collection
- Add to an existing collection
Add to My Bibliography
Your saved search, create a file for external citation management software, your rss feed.
- Search in PubMed
- Search in NLM Catalog
- Add to Search
Hypothesis-generating research and predictive medicine
Affiliation.
- 1 National Human Genome Research Institute, National Institutes of Health, Bethesda, Maryland 20892, USA. [email protected]
- PMID: 23817045
- PMCID: PMC3698497
- DOI: 10.1101/gr.157826.113
Genomics has profoundly changed biology by scaling data acquisition, which has provided researchers with the opportunity to interrogate biology in novel and creative ways. No longer constrained by low-throughput assays, researchers have developed hypothesis-generating approaches to understand the molecular basis of nature-both normal and pathological. The paradigm of hypothesis-generating research does not replace or undermine hypothesis-testing modes of research; instead, it complements them and has facilitated discoveries that may not have been possible with hypothesis-testing research. The hypothesis-generating mode of research has been primarily practiced in basic science but has recently been extended to clinical-translational work as well. Just as in basic science, this approach to research can facilitate insights into human health and disease mechanisms and provide the crucially needed data set of the full spectrum of genotype-phenotype correlations. Finally, the paradigm of hypothesis-generating research is conceptually similar to the underpinning of predictive genomic medicine, which has the potential to shift medicine from a primarily population- or cohort-based activity to one that instead uses individual susceptibility, prognostic, and pharmacogenetic profiles to maximize the efficacy and minimize the iatrogenic effects of medical interventions.
PubMed Disclaimer
Similar articles
- Translational Genomics in Low- and Middle-Income Countries: Opportunities and Challenges. Tekola-Ayele F, Rotimi CN. Tekola-Ayele F, et al. Public Health Genomics. 2015;18(4):242-7. doi: 10.1159/000433518. Epub 2015 Jun 26. Public Health Genomics. 2015. PMID: 26138992 Free PMC article.
- Genomics and medicine: distraction, incremental progress, or the dawn of a new age? Cooper RS, Psaty BM. Cooper RS, et al. Ann Intern Med. 2003 Apr 1;138(7):576-80. doi: 10.7326/0003-4819-138-7-200304010-00014. Ann Intern Med. 2003. PMID: 12667028
- The future of Cochrane Neonatal. Soll RF, Ovelman C, McGuire W. Soll RF, et al. Early Hum Dev. 2020 Nov;150:105191. doi: 10.1016/j.earlhumdev.2020.105191. Epub 2020 Sep 12. Early Hum Dev. 2020. PMID: 33036834
- Insulin-like growth factor binding protein 2: gene expression microarrays and the hypothesis-generation paradigm. Zhang W, Wang H, Song SW, Fuller GN. Zhang W, et al. Brain Pathol. 2002 Jan;12(1):87-94. doi: 10.1111/j.1750-3639.2002.tb00425.x. Brain Pathol. 2002. PMID: 11770904 Free PMC article. Review.
- Systems Medicine: The Future of Medical Genomics, Healthcare, and Wellness. Saqi M, Pellet J, Roznovat I, Mazein A, Ballereau S, De Meulder B, Auffray C. Saqi M, et al. Methods Mol Biol. 2016;1386:43-60. doi: 10.1007/978-1-4939-3283-2_3. Methods Mol Biol. 2016. PMID: 26677178 Review.
- Data-Driven Hypothesis Generation in Clinical Research: What We Learned from a Human Subject Study? Jing X, Cimino JJ, Patel VL, Zhou Y, Shubrook JH, Liu C, De Lacalle S. Jing X, et al. Med Res Arch. 2024 Feb;12(2):10.18103/mra.v12i2.5132. doi: 10.18103/mra.v12i2.5132. Epub 2024 Feb 28. Med Res Arch. 2024. PMID: 39211055 Free PMC article.
- Rethinking the utility of the Five Domains model. Hampton JO, Hemsworth LM, Hemsworth PH, Hyndman TH, Sandøe P. Hampton JO, et al. Anim Welf. 2023 Sep 27;32:e62. doi: 10.1017/awf.2023.84. eCollection 2023. Anim Welf. 2023. PMID: 38487458 Free PMC article. Review.
- Data-driven hypothesis generation among inexperienced clinical researchers: A comparison of secondary data analyses with visualization (VIADS) and other tools. Jing X, Cimino JJ, Patel VL, Zhou Y, Shubrook JH, De Lacalle S, Draghi BN, Ernst MA, Weaver A, Sekar S, Liu C. Jing X, et al. J Clin Transl Sci. 2024 Jan 4;8(1):e13. doi: 10.1017/cts.2023.708. eCollection 2024. J Clin Transl Sci. 2024. PMID: 38384898 Free PMC article.
- How do clinical researchers generate data-driven scientific hypotheses? Cognitive events using think-aloud protocol. Jing X, Draghi BN, Ernst MA, Patel VL, Cimino JJ, Shubrook JH, Zhou Y, Liu C, De Lacalle S. Jing X, et al. medRxiv [Preprint]. 2023 Oct 31:2023.10.31.23297860. doi: 10.1101/2023.10.31.23297860. medRxiv. 2023. PMID: 37961555 Free PMC article. Preprint.
- Data-driven hypothesis generation among inexperienced clinical researchers: A comparison of secondary data analyses with visualization (VIADS) and other tools. Jing X, Cimino JJ, Patel VL, Zhou Y, Shubrook JH, De Lacalle S, Draghi BN, Ernst MA, Weaver A, Sekar S, Liu C. Jing X, et al. medRxiv [Preprint]. 2023 Oct 31:2023.05.30.23290719. doi: 10.1101/2023.05.30.23290719. medRxiv. 2023. Update in: J Clin Transl Sci. 2024 Jan 04;8(1):e13. doi: 10.1017/cts.2023.708. PMID: 37333271 Free PMC article. Updated. Preprint.
- Bell CJ, Dinwiddie DL, Miller NA, Hateley SL, Ganusova EE, Mudge J, Langley RJ, Zhang L, Lee CC, Schilkey FD, et al. 2011. Carrier testing for severe childhood recessive diseases by next-generation sequencing. Sci Transl Med 3: 65ra64 - PMC - PubMed
- Biesecker LG 2013. Incidental findings are critical for genomics. Am J Hum Genet 92: 648–651 - PMC - PubMed
- Biesecker LG, Mullikin JC, Facio FM, Turner C, Cherukuri PF, Blakesley RW, Bouffard GG, Chines PS, Cruz P, Hansen NF, et al. 2009. The ClinSeq Project: Piloting large-scale genome sequencing for research in genomic medicine. Genome Res 19: 1665–1674 - PMC - PubMed
- Hennekam RC, Biesecker LG 2012. Next-generation sequencing demands next-generation phenotyping. Hum Mutat 33: 884–886 - PMC - PubMed
- International Human Genome Sequencing Consortium 2004. Finishing the euchromatic sequence of the human genome. Nature 431: 931–945 - PubMed
Publication types
- Search in MeSH
LinkOut - more resources
Full text sources.
- Europe PubMed Central
- PubMed Central
Other Literature Sources
- scite Smart Citations
- Citation Manager
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
- Data, AI, & Machine Learning
- Managing Technology
- Social Responsibility
- Workplace, Teams, & Culture
- AI & Machine Learning
- Hybrid Work
- Big ideas Research Projects
- Artificial Intelligence and Business Strategy
- Responsible AI
- Future of the Workforce
- Future of Leadership
- All Research Projects
- AI in Action
- Most Popular
- Coaching for the Future-Forward Leader
- Measuring Culture

MIT SMR ’s fall 2024 issue highlights the need for personal and organizational resilience amid global uncertainty.
- Past Issues
- Upcoming Events
- Video Archive
- Me, Myself, and AI
- Three Big Points
Why Hypotheses Beat Goals

- Developing Strategy
- Skills & Learning

Not long ago, it became fashionable to embrace failure as a sign of a company’s willingness to take risks. This trend lost favor as executives recognized that what they wanted was learning, not necessarily failure. Every failure can be attributed to a raft of missteps, and many failures do not automatically contribute to future success.
Certainly, if companies want to aggressively pursue learning, they must accept that failures will happen. But the practice of simply setting goals and then being nonchalant if they fail is inadequate.
Instead, companies should focus organizational energy on hypothesis generation and testing. Hypotheses force individuals to articulate in advance why they believe a given course of action will succeed. A failure then exposes an incorrect hypothesis — which can more reliably convert into organizational learning.
What Exactly Is a Hypothesis?
When my son was in second grade, his teacher regularly introduced topics by asking students to state some initial assumptions. For example, she introduced a unit on whales by asking: How big is a blue whale? The students all knew blue whales were big, but how big? Guesses ranged from the size of the classroom to the size of two elephants to the length of all the students in class lined up in a row. Students then set out to measure the classroom and the length of the row they formed, and they looked up the size of an elephant. They compared their results with the measurements of the whale and learned how close their estimates were.
Note that in this example, there is much more going on than just learning the size of a whale. Students were learning to recognize assumptions, make intelligent guesses based on those assumptions, determine how to test the accuracy of their guesses, and then assess the results.
This is the essence of hypothesis generation. A hypothesis emerges from a set of underlying assumptions. It is an articulation of how those assumptions are expected to play out in a given context. In short, a hypothesis is an intelligent, articulated guess that is the basis for taking action and assessing outcomes.
Get Updates on Transformative Leadership
Evidence-based resources that can help you lead your team more effectively, delivered to your inbox monthly.
Please enter a valid email address
Thank you for signing up
Privacy Policy
Hypothesis generation in companies becomes powerful if people are forced to articulate and justify their assumptions. It makes the path from hypothesis to expected outcomes clear enough that, should the anticipated outcomes fail to materialize, people will agree that the hypothesis was faulty.
Building a culture of effective hypothesizing can lead to more thoughtful actions and a better understanding of outcomes. Not only will failures be more likely to lead to future successes, but successes will foster future successes.
Why Is Hypothesis Generation Important?
Digital technologies are creating new business opportunities, but as I’ve noted in earlier columns , companies must experiment to learn both what is possible and what customers want. Most companies are relying on empowered, agile teams to conduct these experiments. That’s because teams can rapidly hypothesize, test, and learn.
Hypothesis generation contrasts starkly with more traditional management approaches designed for process optimization. Process optimization involves telling employees both what to do and how to do it. Process optimization is fine for stable business processes that have been standardized for consistency. (Standardized processes can usually be automated, specifically because they are stable.) Increasingly, however, companies need their people to steer efforts that involve uncertainty and change. That’s when organizational learning and hypothesis generation are particularly important.
Shifting to a culture that encourages empowered teams to hypothesize isn’t easy. Established hierarchies have developed managers accustomed to directing employees on how to accomplish their objectives. Those managers invariably rose to power by being the smartest person in the room. Such managers can struggle with the requirements for leading empowered teams. They may recognize the need to hold teams accountable for outcomes rather than specific tasks, but they may not be clear about how to guide team efforts.
Some newer companies have baked this concept into their organizational structure. Leaders at the Swedish digital music service Spotify note that it is essential to provide clear missions to teams . A clear mission sets up a team to articulate measurable goals. Teams can then hypothesize how they can best accomplish those goals. The role of leaders is to quiz teams about their hypotheses and challenge their logic if those hypotheses appear to lack support.
A leader at another company told me that accountability for outcomes starts with hypotheses. If a team cannot articulate what it intends to do and what outcomes it anticipates, it is unlikely that team will deliver on its mission. In short, the success of empowered teams depends upon management shifting from directing employees to guiding their development of hypotheses. This is how leaders hold their teams accountable for outcomes.
Members of empowered teams are not the only people who need to hone their ability to hypothesize. Leaders in companies that want to seize digital opportunities are learning through their experiments which strategies hold real promise for future success. They must, in effect, hypothesize about what will make the company successful in a digital economy. If they take the next step and articulate those hypotheses and establish metrics for assessing the outcomes of their actions, they will facilitate learning about the company’s long-term success. Hypothesis generation can become a critical competency throughout a company.
How Does a Company Become Proficient at Hypothesizing?
Most business leaders have embraced the importance of evidence-based decision-making. But developing a culture of evidence-based decision-making by promoting hypothesis generation is a new challenge.
For one thing, many hypotheses are sloppy. While many people naturally hypothesize and take actions based on their hypotheses, their underlying assumptions may go unexamined. Often, they don’t clearly articulate the premise itself. The better hypotheses are straightforward and succinctly written. They’re pointed about the suppositions they’re based on. And they’re shared, allowing an audience to examine the assumptions (are they accurate?) and the postulate itself (is it an intelligent, articulated guess that is the basis for taking action and assessing outcomes?).
Related Articles
Seven-Eleven Japan offers a case in how do to hypotheses right.
For over 30 years, Seven-Eleven Japan was the most profitable retailer in Japan. It achieved that stature by relying on each store’s salesclerks to decide what items to stock on that store’s shelves. Many of the salesclerks were part-time, but they were each responsible for maximizing turnover for one part of the store’s inventory, and they received detailed reports so they could monitor their own performance.
The language of hypothesis formulation was part of their process. Each week, Seven-Eleven Japan counselors visited the stores and asked salesclerks three questions:
- What did you hypothesize this week? (That is, what did you order?)
- How did you do? (That is, did you sell what you ordered?)
- How will you do better next week? (That is, how will you incorporate the learning?)
By repeatedly asking these questions and checking the data for results, counselors helped people throughout the company hypothesize, test, and learn. The result was consistently strong inventory turnover and profitability.
How can other companies get started on this path? Evidence-based decision-making requires data — good data, as the Seven-Eleven Japan example shows. But rather than get bogged down with the limits of a company’s data, I would argue that companies can start to change their culture by constantly exposing individual hypotheses. Those hypotheses will highlight what data matters most — and the need of teams to test hypotheses will help generate enthusiasm for cleaning up bad data. A sense of accountability for generating and testing hypotheses then fosters a culture of evidence-based decision-making.
The uncertainties and speed of change in the current business environment render traditional management approaches ineffective. To create the agile, evidence-based, learning culture your business needs to succeed in a digital economy, I suggest that instead of asking What is your goal? you make it a habit to ask What is your hypothesis?
About the Author
Jeanne Ross is principal research scientist for MIT’s Center for Information Systems Research . Follow CISR on Twitter @mit_cisr .
More Like This
Add a comment cancel reply.
You must sign in to post a comment. First time here? Sign up for a free account : Comment on articles and get access to many more articles.
Comment (1)
Richard jones.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 17 September 2024
Intergenerational effects of a casino-funded family transfer program on educational outcomes in an American Indian community
- Tim A. Bruckner ORCID: orcid.org/0000-0002-6927-964X 1 , 2 ,
- Brenda Bustos 2 ,
- Kenneth A. Dodge 3 ,
- Jennifer E. Lansford ORCID: orcid.org/0000-0003-1956-4917 3 ,
- Candice L. Odgers ORCID: orcid.org/0000-0003-4937-6618 4 &
- William E. Copeland ORCID: orcid.org/0000-0002-1348-7781 5
Nature Communications volume 15 , Article number: 8168 ( 2024 ) Cite this article
Metrics details
- Human behaviour
- Social sciences
Cash transfer policies have been widely discussed as mechanisms to curb intergenerational transmission of socioeconomic disadvantage. In this paper, we take advantage of a large casino-funded family transfer program introduced in a Southeastern American Indian Tribe to generate difference-in-difference estimates of the link between children’s cash transfer exposure and third grade math and reading test scores of their offspring. Here we show greater math (0.25 standard deviation [SD], p =.0148, 95% Confidence Interval [CI]: 0.05, 0.45) and reading (0.28 SD, p = .0066, 95% CI: 0.08, 0.49) scores among American Indian students whose mother was exposed ten years longer than other American Indian students to the cash transfer during her childhood (or relative to the non-American Indian student referent group). Exploratory analyses find that a mother’s decision to pursue higher education and delay fertility appears to explain some, but not all, of the relation between cash transfers and children’s test scores. In this rural population, large cash transfers have the potential to reduce intergenerational cycles of poverty-related educational outcomes.
Similar content being viewed by others

The effect of intergenerational mobility on family education investment: evidence from China

Effects of a monthly unconditional cash transfer starting at birth on family investments among US families with low income

Persistent association between family socioeconomic status and primary school performance in Britain over 95 years
Introduction.
Parents’ wealth plays a substantial role in their children’s life chances 1 , 2 . In the United States, 13 million children live in families with incomes below the poverty line 3 . Extensive literature finds that these children show an increased risk of poor physical and cognitive outcomes 4 , 5 , 6 , 7 , 8 , 9 as well as lower socioeconomic status attainment in adulthood 10 , 11 . Increasing recognition of the strong intergenerational transmission of disadvantage, and the relatively high fraction of children living in poverty in the US 12 , has led to a variety of interventions which aim to improve life outcomes for low-income children. Some scholars and policymakers, for instance, have proposed direct cash transfers (e.g., a child tax credit) to boost the financial resources of low-income families with children 12 , 13 , 14 .
Accumulating evidence 15 , including from the Great Smoky Mountains Study (GSMS) in rural North Carolina which began recruitment before a “natural experiment,” supports causal long-term benefits of a large family cash transfer during childhood. In the late 1990s, a Southeastern American Indian Tribe underwent a natural experiment by way of the introduction of a casino on their lands. Under the terms of an agreement with the tribe, the casino allocated a percentage of profits in acute lump sums to all enrolled members. Gaming proved profitable; since 1996, per capita payments to members have averaged approximately $5000 per year. These disbursements raised income levels of an entire community that previously exhibited a high rate of poverty. GSMS findings indicate improved educational attainment 13 , health 16 and financial well-being into adulthood among American Indian participants whose families received cash transfers during their childhood 17 . Importantly, findings appear stronger with increasing duration of time that their American Indian families received the transfers while the child lived at home 17 . This result coheres with work in economics which finds that early childhood investments offer greater long-term gains to human capital than do investments later in life 18 .
Whereas many interventions aim to improve outcomes for low-income children, few examine whether their effects persist into the next generation. In this study, we exploit the quasi-random timing of the cash transfer during childhood among the tribe to test whether the next generation of children show human capital gains. We use the second generation’s math and reading test score data in third grade—a reliable predictor of later-life educational attainment 19 , 20 and the earliest year in which standardized educational outcomes are obtained—as a gauge of intergenerational effects. In addition, unlike earlier work, we focus on the population base of American Indians that had children (rather than a selected cohort) which permits not only increased study power but also external validity to the affected region.
In this work, we use American Indian race/ethnicity as a proxy for tribal membership and find improved third grade math and reading scores among American Indian students whose mother was exposed longer to the cash transfer during her childhood. A mother’s decision to pursue higher education and delay fertility explains some, but not all, of the discovered relation. In this rural population, large cash transfers have the potential to enhance human capital of the next generation.
Exposure and sample characteristics
Consistent with prior work, we used American Indian race/ethnicity in Jackson, Swain, and Graham counties in North Carolina as a proxy for the Eastern Band of Cherokee. These residents received the large family cash transfer beginning in 1996. By contrast, non- American Indian residents in these counties received no cash transfer. Figure 1 provides a timeline of the cash transfers to American Indian families, the timing of births, and the data linkage to third grade test scores.

Casino payments begin in 1996 and are disbursed to adults (G1). The young children of G1 (i.e., G2) grow to childbearing age, and 2000 is the first birth year of their children (G3) for whom we retrieved third grade reading and math test scores from 2008 to 2017. G2 women who were relatively young in 1996 –when G1 received the first Casino payment– are considered more exposed to the cash transfers than are G2 women who were at or above 18 years of age in 1996.
Using state administrative records housed at the North Carolina Education Research Data Center (NCERDC), we accessed the linked North Carolina Birth file to math ( N = 4289) and reading test scores ( N = 4254) for third grade public school students in the three treated counties, from 2008 to 2017. Whereas mean scores for non- American Indian children ( N = 3549) lie slightly above the state mean, those for American Indian children ( N = 740) fall, on average, 0.39 standard deviations ( SD ) below the state mean (Fig. 2 ).

Third grade math ( a ) and reading ( b ) scores among children born to American Indian (orange bar) and non-American Indian mothers (blue bar), Jackson, Swain, and Graham counties, for test years 2008–2017. The orange bars represent the proportion of a z-score to children of American Indian mothers. The blue bars represent the proportion of a z-score to children of non- American Indian mothers.
Table 1 describes maternal and birth characteristics of the children with valid third grade test scores. American Indian mothers tend to report lower completed education, younger age at birth, and lower frequency of being married than do non- American Indian mothers. By contrast, the prevalence of preterm (<37 weeks completed gestational age at delivery) and/or low weight (<2500 g) delivery is lower among births to American Indian mothers (vs. non-American Indian mothers). These patterns appear consistent with the broader literature describing racial/ethnic differences, which indicates minimal bias in the NCERDC algorithm used to link birth records to third grade test scores.
Regression for third grade math and reading scores
We employed a “difference-in-difference” (DiD) regression strategy to isolate potential benefits of the family cash transfer on educational outcomes of children born to American Indian mothers who were relatively young in 1996—the first year of the family cash transfer program. This approach uses two control populations (e.g., non- American Indian children as well as children born to American Indian mothers who were relatively older, around age 17 in 1996) to adjust for unmeasured confounding and other threats to validity. Our DiD specification is a time-varying treatment effect design in which duration of exposure to the cash transfer as a child serves as the “intensity” of exposure for American Indian mothers 21 . We examine the influence of the cash transfer by regressing children’s test scores on time exposed to the cash transfer and American Indian status, and then testing whether the relation between test scores and time exposed to the cash transfer differs by American Indian status. Here, duration of time exposed before age 18 is a continuous variable (range: 0–15 years; see Supplementary Table 1 ). A person over 18 in 1996 receives a “0” duration value and we retain them in the sample. Importantly, our dataset also permits a test of the parallel trends assumption in the pre-treatment period (see Supplementary Tables 2 and 3 ).
Results from the DiD regressions (Model 1 column in Table 2 for Math; Model 1 column in Table 3 for Reading) show a positive relation between test scores and the interaction term of American Indian race/ethnicity and childhood remaining at the start of the family cash transfer. The positive relation reaches conventional levels of statistical detection (i.e., p < 0.05) for both reading ( p = 0.0014, 95% CI: 0.013, 0.055) and math ( p = 0.0055, 95% CI: 0.009, 0.050) scores. The strength of the relation is slightly larger (i.e., ~17%) for reading relative to math. Inclusion of child age at time of test (with a squared and cubed term; see Model 2 column in Tables 2 and 3 ) and infant sex slightly attenuates main results but does not affect statistical inference. Figure 3 (math) and Figure 4 (reading) illustrate the regression results of Model 2 in Tables 2 and 3 by showing fitted third grade test scores by American Indian status and category of duration exposure. Within the context of the declining trend in third grade test scores in this rural population (which mirrors national trends 22 ), the race-based disparity in test scores narrows for American Indian children whose mothers had a relatively greater duration exposure.

Within the context of the declining trend in third grade math test scores in this rural population (which mirrors national trends), the race-based disparity in test scores narrows for American Indian children whose mothers had a relatively greater duration exposure. American Indian scores are represented by the orange line. Non-American Indian scores are represented by the blue line.
Summary of findings
To give the reader a sense of the magnitude of the findings, a child whose American Indian mother with ten years of exposure to the family cash transfer before age 18 years scores 0.25 SD higher in math, and 0.28 SD higher in reading, relative to a child whose American Indian mother had no exposure to the family cash transfer before age 18 years (per coefficients in Model 2 column). This value, while smaller than the observed American Indian/non- American Indian gap in test scores at third grade, is greater than the average score gap between a child whose mother graduated from high school and a child whose mother did not graduate from high school. This value is similar in magnitude to $1000 per pupil per year investments in early childhood education interventions in North Carolina 23 . When scaled to other early childhood educational interventions 23 , the magnitude of the test score increases equates to an additional half school year of learning. Furthermore, these results appear consistent with a continued educational benefit, of moderate magnitude, that affects not only the generation of parents (G2; see Akee et al. 13 ) but also their children.
The discovered support for our hypothesis as well as recent published literature 24 led us to explore whether life course decisions and behaviors of the mother, which precede the child’s birth, may help to explain test score gains among children whose mothers were exposed to the cash transfer for longer periods of time. A mother’s decision to, for instance, pursue higher education, marry, delay fertility, or refrain from smoking during pregnancy all could plausibly lead to improvements in child’s test scores. Results from the exploration (Model 3, Tables 2 and 3 ) indicate that several of these variables predict children’s test scores. Inclusion of these variables, moreover, attenuates the interaction term by ~20%. The interaction term, however, reaches conventional levels of statistical detection for both math and reading, which indicates that these factors may not fully account for American Indian children’s gain in test scores.

Within the context of the declining trend in third grade reading test scores in this rural population (which mirrors national trends), the race-based disparity in test scores narrows for American Indian children whose mothers had a relatively greater duration exposure. American Indian scores are represented by the orange line. Non- American Indian scores are represented by the blue line.
Sensitivity analyses
We conducted several additional checks to assess robustness of results. First, to support the validity of the DiD model, we tested the parallel trends assumption in the pre-treatment period 21 by interacting a time-invariant treatment indicator (American Indian status) with the age of the mother in 1996 minus 18 years of age, and then testing whether the coefficient of the interaction term (i.e., American Indian*pre_treatment) rejects the null for the periods prior to treatment. Results of the American Indian*pre_treatment coefficient in the pre-treatment period do not reject the null for either math or reading test scores (see Supplementary Tables 2 and 3 ), which supports parallel trends in the pre-treatment period.
Second, we restricted the analysis to mothers (G2) who received between 0 and 12 years of duration exposure by 1996 to rule out the possibility that outliers in exposure drive results. Inference for both math and reading did not change (Supplementary Tables 4 and 5 ). Third, we restricted the mother’s (G2) age of delivering children to 16–35 years. We arrived at this range by inspecting the age distribution of mothers at the time of the child’s (G3’s) birth, by American Indian status, and dropping the maternal ages for which fewer than 10 participants fell into that cell. This sensitivity check rules out the possibility that high “outliers” in maternal age drive results. Findings remain similar to those in columns 2 of Tables 2 and 3 , albeit with less precision owing to dropping 8% (math) and 11% (reading) of observations after these restrictions (Supplementary Tables 6 and 7 ). Fourth, to rule out the possibility that trends over time in test scores (such as declines reported nationally 22 and in rural areas 25 ) drive results, we controlled for test year in several ways (including a continuous year variable and, separately, test year indicator variables) and re-ran analyses. This time control also adjusts for any potential response to the 2007-2009 Great Recession. Inference for the American Indian*duration coefficient does not change (Supplementary Tables 8 – 11 ).
We investigated whether childhood investments, in the form of family cash transfers, could improve human capital outcomes in the next generation of children. We focused on a Southeastern American Indian tribe in rural North Carolina who, via a natural experiment by the introduction of a successful casino, received a large cash transfer. Findings indicate statistically significant increases in both reading and math third grade test scores among students born to American Indian mothers with more years of exposure to the cash transfers as children. Results, which control for general changes in the region over time that could have benefited American Indian and non- American Indian students equally, support the hypothesis that large early-life investments show human capital benefits into subsequent generations.
Many American Indian (G2) mothers who were very young in 1996 (i.e., <5 years old) have children that are scheduled to attend third grade after 2017—the last year in which we could link test score information. This circumstance means that our analysis includes very few (G2) mothers who had early-life exposure (i.e., from infancy to age 5) to the cash transfer. Our results may therefore underestimate the potentially larger benefit of cash transfers (especially before age 5 years among G2) that may accrue to the subsequent generation of American Indian children and produce large returns to health and education 26 , 27 .
The magnitude of the statistically significant test score increases in reading and math for children born to American Indian mothers seems reasonable in relation to prior interventions in North Carolina 23 . The slightly larger benefits observed for reading, moreover, cohere with the notion that non-school factors play a substantial role. The education literature generally finds that reading skills develop in much broader (i.e., non-school) settings relative to math skills 28 , 29 , 30 . This work implies that our discovered results likely do not arise from unmeasured factors in which American Indian mothers (but not non- American Indian mothers) chose high-performing schools for their children. We also note, importantly, that non-American Indian children show a steep declining trend over time in test scores, and that American Indian children do not show increases in the absolute level of test scores with increased exposure to the cash transfer. National studies similarly find declining trends in test scores over this time period 22 , as well as persistently lower test scores among white and American Indian children in rural areas 25 , 31 of the US (vs. suburban and urban areas). Explanations for these geographic patterns and time-trends remain elusive. We encourage more careful research in this area to understand the broader national educational landscape within which the cash transfer accrues to American Indian families and children in this rural population.
Since the introduction of the casino in the late 1990s, the Tribe constructed several new facilities including healthcare centers and educational academies. The New Kituwah Academy 32 , for instance, is a private facility (accredited in 2015) which offers, among other programs, dual-immersion elementary school education focused on preserving the Cherokee language, culture, traditions, and history. Whereas American Indian children enrolled in this Academy would not appear in our dataset (i.e., NCERDC linked test scores only for public school-enrolled children), this resource as well as others may benefit human capital especially among American Indian children. Although we have no reason to believe that these benefits covary with the number of childhood years remaining at the start of the family cash transfer, our methods cannot rule out this explanation. We, however, note that much of the infrastructure improvements on Tribal lands remain available to all residents regardless of race/ethnicity. Therefore, our DiD analyses help to control for this rival explanation.
Whereas our findings are among the first to document statistically significant intergenerational test score improvements—25 years after the inception of large family cash transfers—several caveats deserve mention. First, the magnitude of the gains to American Indian children depicts a narrowing of the differences between American Indian and non- American Indian math and reading scores since the onset of the cash transfer in 1996. Despite the higher American Indian math and reading scores, the large American Indian/non- American Indian score gap in math (0.46 SD) and reading (0.54 SD) scores did not close during this time. The latter is as expected considering cash transfers alone are unlikely to rectify the education effects of multi-generational discrimination among American Indian and non- American Indian populations 33 . This discrimination includes past and present unequal treatment as well as structural factors that may lead to a higher prevalence of predictors of low educational attainment among American Indian populations (e.g., poverty, residing near low quality schools, high levels of teen pregnancy; see Demmert and colleagues) 30 , 34
Second, NCERDC could not link the full population of births in this region to their third-grade test score. Non-matches are attributed to moves out of state, private school attendance, name changes, or errors in spelling on records. Third, substantial missing/unknown paternity on the birth file did not permit an examination of whether having an American Indian father who received the cash transfer, or having two American Indian parents (vs. solely an American Indian mother) that received the cash transfer, confers stronger intergenerational associations. Fourth, given the nature of the timing of cash transfers to this population, we cannot determine which factor (child age at initiation of cash transfer or duration of cash transfer exposure before 18 years) seems most relevant in designing new interventions. Fifth, some other work examining this large cash transfer to this population shows adverse outcomes, such as risk of accidental death during months of large casino payments 35 , 36 . This circumstance indicates that any policy discussion about the value of family cash transfers to the next generation should include a careful assessment of their costs and benefits to all generations as well as an assessment of the type (e.g., in-kind vs. cash) and frequency (e.g., lump sum or monthly payment) of the transfer.
Whereas the population-based nature of our linked datasets provides a larger sample size than do cohort studies of this population (i.e., GSMS), the birth and test score data lack contextual variables that may illuminate mechanistic pathways. American Indian mothers with more years of exposure to the family cash transfer as children could, for instance, make a variety of life course decisions that ultimately benefit their children. Previous work on this population finds that fertility 37 , attitudes around fertility timing 38 as well as educational attainment 13 may change after the introduction of the family cash transfer. Recent work also finds that American Indian mothers exposed for a longer duration to the cash transfer show improved maternal/infant health at birth 24 . These pathways, as well as prenatal investments or changes in parenting quality, could account for gains in children’s test scores. We await the availability of additional contextual data, as well as a richer set of school-level variables (e.g., attendance, test scores at later ages) in coming years.
Within the context of the secular decline in third grade test scores in this rural population (Supplementary Figs. 1 and 2 ), the American Indian / non- American Indian disparity in test scores narrows as mothers of American Indian children have a relatively greater duration of exposure. Whereas we infer that this finding arises from the benefit of the cash transfer to American Indian families, we cannot rule out the possibility of unmeasured confounding. Such a confounder would have to correlate positively with our exposure (but not be caused by it), occur only among American Indian families (but not among non- American Indian families), and vary positively with third grade test scores. School-based investments particular to American Indian children that concentrate in recent years, or broader employment gains to American Indian families that concentrate in recent years, could meet these criteria. We, however, know of no such trend in school-based investments unique to American Indian children in public schools. In addition, both American Indian and non- American Indian adults show employment gains following the opening of the casino, which minimizes the plausibility that this factor introduces bias.
The casino opening led to several community improvements besides the cash transfer to tribal members. The tribe designated half of the gaming revenues to community investments, including behavioral health, drug abuse prevention, health care, education, and social services 39 , 40 . In addition, the casino itself is the largest employer in the region and boosts other local businesses 41 . These improvements may lead to gains in health and functioning for all American Indian members (regardless of age) as well as non- American Indian individuals in the study region.
The establishment of the cash transfer payments among this population in the 1990s substantially raised median income in a community that previously exhibited a high poverty rate. Between the years of 1995 and 2000, the percent of American Indian families below the poverty line fell from almost 60% to less than 25% 42 . This circumstance, coupled with accumulating literature documenting improved adult health among recipients who were at earlier childhood ages at the onset of the family cash transfer 17 , compelled us to examine the potential intergenerational benefits among those who were young in 1995 and later decided to have children. An intuitive follow-up question involves whether these intergenerational associations would persist, or even become stronger, among those who were in infancy or under age five at the inception of the family cash transfer in the 1990s and later had children of their own. For American Indian females born in this region in 1995, we can expect their children to have completed third grade and test scores to be available by 2050. In the near term, however, we encourage replication in other settings in the US to determine external validity. A more complete picture of educational outcomes (e.g., subject-matter test scores other than reading and math, school attendance, social and emotional well-being), which we aim to collect in future work, may also better capture academic ability. Other extensions of this work should identify potential pathways in which less impoverished childhood environments affect later-life adult school choice, fertility decisions, and parental investments that in turn enhance human capital of the next generation.
Study population
We examined American Indians in Jackson, Swain, and Graham counties in North Carolina as a proxy for the Eastern Band of Cherokee. According to the 2020 Census, American Indian residents comprise 14.8% of the population in these three counties. No other federally recognized, state recognized, or even unrecognized Tribes claim lands in the western North Carolina area, and the Eastern Band of Cherokee have historically been the only Tribe in this region of western North Carolina. Previous studies have used the census indicator of American Indians as a proxy for Eastern Band of Cherokee in this region 42 . These American Indians residents received the large family cash transfer beginning in 1996. By contrast, non- American Indians residents in these counties received no cash transfer but (as with the American Indian population) experienced the broader economic and infrastructural changes to that region. We therefore use children born to non- American Indians residents of Jackson, Swain, and Graham counties as a comparison group when examining the relation between the family cash transfer and educational outcomes among American Indians residents’ children.
Inclusion and ethics statement
This study was completed using education and birth records from a number of counties in western North Carolina. The data for the current manuscript were obtained from the North Carolina Education Research Data Center (NCERDC), which houses data files from State of North Carolina administrative records 43 . Through data use agreements between Duke University and the State of North Carolina, the NCERDC receives state data files with identified records, merges files as needed, de-identifies the merged files, and then provides access to de-identified files to researchers. None of the NCERDC staff members who worked on the current data set are researchers or authors of the current study. The NCERDC is described here: https://childandfamilypolicy.duke.edu/north-carolina-education-research-data/ . This study is relevant to the educational functioning of families receiving the cash transfer in western North Carolina, but this was not determined in collaboration with local partners. The roles and responsibilities for compiling the data were agreed upon by collaborators ahead of time.
This study was approved by the IRB at Duke University which is located in North Carolina but not specifically in western North Carolina. Also, the research does not result in discrimination as it was focused on a quasi-experiment design resulting from the introduction of a community-wide transfer. The Southeastern American Indian Tribe which co-generated (along with the casino) the cash transfer has promoted this transfer as a public good. We have taken local and regional research relevant to our study into account by citing prior studies of this cash transfer.
Variables and data
Starting in the third grade, North Carolina conducts end-of-grade standards-based achievement tests for math and reading for all students enrolled in public school. The reading and mathematics tests align with the North Carolina Standard Course of Study 44 . We used third grade test scores as our key dependent variable because education scholars view these measures as a stable indicator of student achievement and a reliable predictor of longer-term educational outcomes, not only nationally but also in North Carolina 23 , 45 . Test scores by third grade predict both likelihood of high school graduation and college attendance 19 , 20 . We standardized each raw score to Z-score values using the mean and standard deviation (SD) of all third-grade scores in North Carolina for that test year. This standardization permits direct comparison of student scores across years because it controls for variation over time in difficulty or scaling of the state tests (e.g., if mean test scores show a trend over time, the Z-score values [normed within each test year] are less subject to such trends).
We acquired third grade math and reading test scores among infants born in Jackson, Swain, and Graham counties using linked administrative data files from the Duke University North Carolina Education Research Data Center (NCERDC). The NCERDC receives educational administrative data files from the North Carolina Department of Public Instruction (NC DPI), which collects files submitted annually by each of 115 school districts. To identify the child’s county of birth, NCERDC links individual birth records from the Birth File of the North Carolina Office of Vital Records for all children born in the state with education records from NC DPI. The sample includes only children born in North Carolina and then enrolled (by third grade) in a public elementary school in the state. This process necessarily excludes children who enroll in a private school as well as those whose families moved out of North Carolina by third grade. Over 200 peer-reviewed publications use NCERDC-linked data, which attests to the quality and coverage of the dataset 46 .
Beginning in 2008, in our study region NCERDC reports a match rate of >74% between birth records and third grade test scores. 2017 represents the last year for which we have matched data available at the time of our study. Our test population includes over 4000 American Indian and non- American Indian children who have a valid third grade test score from 2008 to 2017—and who were born from 1998 to 2009 in Jackson, Swain, and Graham counties.
Prior literature finds a positive relation between American Indian later-life health and the number of years during which the individual was exposed to the family cash transfer before reaching age 18 years 17 . This relation coheres with the notion that the duration of the family cash transfer during childhood can exert a positive influence later in life. We, similarly, reasoned that additional benefits could include life-course maternal investments and behaviors which in turn may improve the next generation’s educational outcomes. For this reason, and consistent with prior literature 17 , 42 , we used as the primary exposure the number of years before age 18 that the index individual’s family received the cash transfer.
The Birth File contains several variables that may control for confounding bias but do not plausibly lie on the causal pathway between family cash transfer and the next generation of children’s test scores. These variables, which show associations with test scores, include infant sex and child age (i.e., date of birth). We retrieved these variables from the birth file and used them (as well as other variables in the birth file [maternal education, maternal age], described below in Analysis section) as controls for potential confounding. We determined infant sex based on sex assigned at birth, as recorded on the birth certificate.
All data analyses were conducted using SAS version 9.4. Examination of American Indian and non-American Indian cohorts at varying ages at the inception of the family cash transfer in 1996 confers the methodological benefit of using the family cash transfer as a “natural experiment” which randomly assigns income to American Indian families. We employ a “difference-in-difference” (DiD) regression strategy to isolate potential benefits of the family cash transfer on educational outcomes of children born to American Indian mothers who were relatively young in 1996—the first year of the family cash transfer program. This approach uses a series of control populations to adjust for unmeasured confounding and other threats to validity. It remains plausible, for instance, that the level of social, educational, and economic resources increased over time in Jackson, Swain, and Graham counties in ways that benefited younger-age cohorts in 1996 (relative to older-age cohorts in 1996). This circumstance could result in improved math and reading test scores of children born to younger (relative to older) cohorts. Such a circumstance would confound our test if we falsely attributed this positive relation to the duration of the family cash transfer in childhood.
Our DiD regression approach minimizes the problem of unmeasured confounding. This strategy compares the test scores outcome of children born to American Indian mothers who were young in 1996 to that of children born to American Indian mothers who were relatively older in 1996. Importantly, we also adjust for general cohort differences in access to social, educational, and economic resources in Jackson, Swain, and Graham counties.
The key features of a DiD design involve (i.) comparison of outcomes between two alternative treatment regimes (i.e., treatment and control), (ii.) the availability of pre-treatment and post-treatment time periods in both the treatment and control group, and (iii.) a well-defined study population 21 . We augment this standard DiD with a time-varying treatment effects design, also called DiD with treatment as intensity of exposure. This design assumes that the relation of the treatment to the outcome increases with longer duration of exposure to the treatment. In our case, duration of exposure to the cash transfer as a child serves as the intensity of exposure for American Indian mothers.
The DiD approach (shown below) minimizes the problem of unmeasured confounding. This strategy compares the test scores outcome ( θ , representing third grade math or reading Z-score) of children born to American Indian mothers who were young in 1996 to that of children born to American Indian mothers who were relatively older in 1996. Importantly, we also adjust for general cohort differences in access to social, educational, and economic resources in Jackson, Swain, and Graham counties by subtracting the difference in test scores observed between children born to non-American Indian mothers who were young in 1996 and non-American Indian mothers who were relatively older (i.e., around age 17) in 1996.
Social scientists have employed this approach to examine the effect of large “shocks” on children’s outcomes 28 , 47 , 48 , 49 .
Estimation of the equation above entails pooling data for American Indian and non-American Indian births in Jackson, Swain, and Graham counties, and regressing the third grade test score outcomes from 2008 to 2017 (Z-score for math, and Z-score for reading) on a dichotomous indicator capturing (1) American Indian race/ethnicity (as measured by mother’s race/ethnicity from the Birth file), (2) a continuous indicator of childhood years remaining before age 18 at the start of the family cash transfer and the two-way interaction between American Indian race/ethnicity and childhood years remaining at the start of the family cash transfer. The estimate of interest is the coefficient on the two-way interaction term, which captures the difference in test score outcome between American Indian children born to residents who were relatively young in 1996 and those who were older in 1996, net of that same difference in non-American Indian children. Specifically, we examine the influence of the cash transfer by regressing Y (children’s test scores) on X 1 (time exposed before age 18; continuous) and X 2 (American Indian status), and then testing whether the relation between Y and X 1 differs by American Indian Status (X 2 ). The DiD regression also includes controls for the child’s age in months at third grade test and assigned sex at birth. We applied generalized estimating equation regressions 50 using maximum likelihood estimators to predict the two continuous outcomes (PROC GENMOD in SAS). The test score data (for both math and reading) meet the assumptions for use of these methods. We used two-tailed tests for all statistical analyses.
If we discovered support for a positive relation between the interaction term and Z-score of test (i.e., more childhood years remaining at the start of family cash transfer varies positively with subsequent generation’s third grade test score), we then explored potential pathways of this association. Such an exploration included the addition of maternal education, maternal behavior during pregnancy, and infant health information contained in the Birth File. In addition, as a falsification check we examined the assumption of parallel trends in a DiD framework by testing pre-treatment trends between the treated group and the control group prior to the treatment. To do so, we interacted a time-invariant treatment indicator (American Indian status) with the age of the mother in 1996 minus 18 years of age—but only among mothers 18 years or older in 1996 and therefore never exposed as a child to the cash transfer treatment—and then tested whether the coefficient of this interaction term (American Indian*pre-treatment) rejected the null for both children’s math and reading test scores (see Supplementary Tables 2 and 3 ). Failure to reject the null would satisfy the parallel trends assumption in the pre-treatment period.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The individual-level linked birth records and education outcomes, deriving from existing administrative records, are housed by the NCERDC and derive from existing administrative records. The individual-level raw data are available under restricted access given the usage of personal identifiable information, the state of North Carolina’s restrictions on dissemination without prior consent, and the regulations set by the IRB protocol (Protocol: Pro00090215 with Duke University). The raw data are protected and are not available due to privacy laws. Request for raw data can be made to the NCERDC here: https://childandfamilypolicy.duke.edu/north-carolina-education-research-data/ . Data are only provided to researchers who meet the requirements of the NCERDC Data Use Agreement which stipulates primary affiliation with an institution of higher education, non-profit organization, or government agency within the United States. Additional information can be found at the link provided above. In addition, to comply with open science requirements and that of NCERDC, the processed group-level data used in this study are available within the Figshare database 51 and are available here: https://doi.org/10.6084/m9.figshare.26288080.v1 . These data include the covariance matrix of the data analyzed along with a vector of means, standard deviations, and number of observations, separately by American Indian and non-American Indian participants. This information allows interested readers to re-create the regression analyses. The data file also provides the summary data points used to create all figures.
Code availability
The SAS program code is available upon request to the first Author, who can provide the code via email.
Duncan, G. J., Yeung, W. J., Brooks-Gunn, J. & Smith, J. R. How Much Does Childhood Poverty Affect the Life Chances of Children? Am. Sociological Rev. 63 , 406–423 (1998).
Article Google Scholar
Odgers, C. L. Income Inequality and the Developing Child: Is It All Relative? Am. Psychol. 70 , 722–731 (2015).
Article PubMed PubMed Central Google Scholar
Fontenot, K., Semega, J. & Kollar, M. Income and Poverty in the United States: 2017 (US Government Printing Office 74, 2018).
Adler, N. E. & Rehkopf, D. H. U. S. Disparities in Health: Descriptions, Causes, and Mechanisms. SSRN Scholarly Paper at https://papers.ssrn.com/abstract=1142022 (2008).
Chen, E., Cohen, S. & Miller, G. E. How low socioeconomic status affects 2-year hormonal trajectories in children. Psychol. Sci. 21 , 31–37 (2010).
Article PubMed Google Scholar
Cohen, S., Doyle, W. J. & Baum, A. Socioeconomic Status Is Associated With Stress Hormones. Psychosom. Med. 68 , 414–420 (2006).
Cohen, S., Janicki-Deverts, D., Chen, E. & Matthews, K. A. Childhood socioeconomic status and adult health. Ann. N. Y. Acad. Sci. 1186 , 37–55 (2010).
Article ADS PubMed Google Scholar
Stringhini, S. et al. Association of Lifecourse Socioeconomic Status with Chronic Inflammation and Type 2 Diabetes Risk: The Whitehall II Prospective Cohort Study. PLoS Med. 10 , e1001479 (2013).
Subramanyam, M. A. et al. Socioeconomic status, John Henryism and blood pressure among African-Americans in the Jackson Heart Study. Soc. Sci. Med. 93 , 139–146 (2013).
Bird, K. The Intergenerational Transmission of Poverty. in Chronic Poverty (eds. Shepherd, A. & Brunt, J.) (Palgrave Macmillan, 2013). https://doi.org/10.1057/9781137316707.0009 .
Chetty, R., Hendren, N., Kline, P., Saez, E. & Turner, N. Is the United States Still a Land of Opportunity? Recent Trends in Intergenerational Mobility. Am. Economic Rev. 104 , 141–147 (2014).
Aizer, A., Hoynes, H. & Lleras-Muney, A. Children and the US Social Safety Net: Balancing Disincentives for Adults and Benefits for Children. J. Economic Perspect. 36 , 149–174 (2022).
Akee, R. K. Q., Copeland, W. E., Keeler, G., Angold, A. & Costello, E. J. Parents’ Incomes and Children’s Outcomes: A Quasi-experiment Using Transfer Payments from Casino Profits. Am. Economic J. Appl. Econ. 2 , 86–115 (2010).
Bastagli, F. et al. The Impact of Cash Transfers: A Review of the Evidence from Low- and Middle-income Countries. J. Soc. Policy 48 , 569–594 (2019).
Aizer, A., Eli, S., Ferrie, J. & Lleras-Muney, A. The Long-Run Impact of Cash Transfers to Poor Families. Am. Economic Rev. 106 , 935–971 (2016).
Costello, E. J., Erkanli, A., Copeland, W. & Angold, A. Association of Family Income Supplements in Adolescence With Development of Psychiatric and Substance Use Disorders in Adulthood Among an American Indian Population. JAMA 303 , 1954–1960 (2010).
Article CAS PubMed PubMed Central Google Scholar
Copeland, W. E. et al. Long-term Outcomes of Childhood Family Income Supplements on Adult Functioning. JAMA Pediatrics , https://doi.org/10.1001/jamapediatrics.2022.2946 (2022).
Cunha, F., Heckman, J. J., Lochner, L. & Masterov, D. V. Chapter 12 Interpreting the Evidence on Life Cycle Skill Formation. In Handbook of the Economics of Education (eds. Hanushek, E. & Welch, F.) vol. 1 697–812 (Elsevier, 2006).
National Research Council, Division of Behavioral and Social Sciences and Education, Board on Behavioral, Cognitive, and Sensory Sciences & Committee on the Prevention of Reading Difficulties in Young Children. Preventing Reading Difficulties in Young Children (National Academies Press, 1998).
Lesnick, J., Goerge, R. M., Smithgall, C. & Gwynne, J. Reading on Grade Level in Third Grade: How Is It Related to High School Performance and College Enrollment? A Longitudinal Analysis of Third-Grade Students in Chicago in 1996-97 and Their Educational Outcomes . A Report to the Annie E. Casey Foundation . Chapin Hall at the University of Chicago (Chapin Hall at the University of Chicago, 2010).
Wing, C., Simon, K. & Bello-Gomez, R. A. Designing Difference in Difference Studies: Best Practices for Public Health Policy Research. Annu. Rev. Public Health 39 , 453–469 (2018).
National Center for Education Statistics. Reading and Mathematics Score Trends . https://nces.ed.gov/programs/coe/indicator/cnj (2022).
Ladd, H. F., Muschkin, C. G. & Dodge, K. A. From Birth to School: Early Childhood Initiatives and Third-Grade Outcomes in North Carolina. J. Policy Anal. Manag. 33 , 162–187 (2014).
Bustos, B. et al. Family cash transfers in childhood and birthing persons and birth outcomes later in life. SSM Popul. Health 25 , 101623 (2024).
Drescher, J., Podolsky, A., Reardon, S. F. & Torrance, G. The Geography of Rural Educational Opportunity. RSF Russell Sage Found. J. Soc. Sci. 8 , 123–149 (2022).
Google Scholar
Carneiro, P. M. & Heckman, J. J. Human Capital Policy. SSRN Sch. Pap. https://doi.org/10.2139/ssrn.434544 (2003).
Duncan, G. J., Magnuson, K. & Votruba-Drzal, E. Boosting Family Income to Promote Child Development. Future Child. 24 , 99–120 (2014).
Baker, M., Gruber, J. & Milligan, K. The Long-Run Impacts of a Universal Child Care Program. Am. Econ. J. Economic Policy 11 , 1–26 (2019).
Jeynes, W. H. A Meta-Analysis of the Relation of Parental Involvement to Urban Elementary School Student Academic Achievement. Urban Educ. 40 , 237–269 (2005).
Merlo, L. J., Bowman, M. & Barnett, D. Parental Nurturance Promotes Reading Acquisition in Low Socioeconomic Status Children. Early Educ. Dev. 18 , 51–69 (2007).
Logan, J. R. & Burdick-Will, J. School Segregation and Disparities in Urban, Suburban, and Rural Areas. ANNALS Am. Acad. Political Soc. Sci. 674 , 199–216 (2017).
Kituwah Preservation and Education Program. New Kituwah Academy Elementary - Cherokee, North Carolina. KPEP https://ebcikpep.com/nka-elementary/ (2022).
Martinez, J. P. New Mexico’s Academic Achievement Gaps: A Synthesis of Status, Causes, and Solutions . A White Paper . Online Submission https://eric.ed.gov/?id=ED575669 (2017).
Demmert, W. G., Grissmer, D. & Towner, J. A Review and Analysis of the Research on Native American Students. J. Am. Indian Educ. 45 , 5–23 (2006).
Akee, R., Simeonova, E., Copeland, W., Angold, A. & Costello, E. J. Young Adult Obesity and Household Income: Effects of Unconditional Cash Transfers. Am. Economic J. Appl. Econ. 5 , 1–28 (2013).
Bruckner, T. A., Brown, R. A. & Margerison-Zilko, C. Positive income shocks and accidental deaths among Cherokee Indians: a natural experiment. Int J. Epidemiol. 40 , 1083–1090 (2011).
Singh, P., Gemmill, A. & Bruckner, T.-A. Casino-based cash transfers and fertility among the Eastern Band of Cherokee Indians in North Carolina: A time-series analysis. Econ. Hum. Biol. 51 , 101315 (2023).
Brown, R. A., Hruschka, D. J. & Worthman, C. M. Cultural Models and Fertility Timing among Cherokee and White Youth in Appalachia: Beyond the Mode. Am. Anthropol. 111 , 420–431 (2009).
Johnson, J. H., Kasarda, J. D. & Appold, S. J. Assessing the Economic and Non-Economic Impacts of Harrah’s Cherokee Casino (Frank Hawkins Kenan Institute of Private Enterprise, 2011).
Bullock, A. & Bradley, V. L. Family income supplements and development of psychiatric and substance use disorders among an American Indian population. JAMA 304 , 962–963 (2010).
Article CAS PubMed Google Scholar
Harrah’s Cherokee 2022 Economic, Community Impact Report. Indian Gaming, https://www.indiangaming.com/harrahs-cherokee-2022-economic-community-impact-report/ (2023).
Costello, E. J., Compton, S. N., Keeler, G. & Angold, A. Relationships Between Poverty and Psychopathology: A Natural Experiment. JAMA: J. Am. Med. Assoc. 290 , 2023–2029 (2003).
Article CAS Google Scholar
Muschkin, C., Bonneau, K. & Dodge, K. North Carolina Education Research Data Center Grant # 200300138. (Spencer Foundation, 2011)
North Carolina Department of Public Instruction. EOG Reading Grades 3–8 and Beginning-of-Grade 3 Reading Test Achievement Level Ranges and Descriptors | NC DPI. https://www.dpi.nc.gov/documents/accountability/testing/achievelevels/eog-reading-grades-3-8-and-beginning-grade-3-reading-test-achievement-level-ranges-and-descriptors . (2022)
Goldhaber, D., Wolff, M. & Daly, T. Assessing the accuracy of elementary school test scores as predictors of students’ high school outcomes (National Center for Analysis of Longitudinal Data in Education Research, 2020).
Duke Sanford Center for Child & Family Policy. North Carolina Education Research Data Center. Duke Center for Child & Family Policy https://childandfamilypolicy.duke.edu/north-carolina-education-research-data/ (2022).
Akresh, R., Verwimp, P. & Bundervoet, T. Civil War, Crop Failure, and Child Stunting in Rwanda. Economic Dev. Cultural Change 59 , 777–810 (2011).
Bruckner, T. A. & Nobles, J. Intrauterine stress and male cohort quality: The case of September 11, 2001. Social . Sci. Med. 76 , 107–114 (2013).
Bleakley, H. Disease and Development: Evidence from Hookworm Eradication in the American South. Q J. Econ. 122 , 73–117 (2007).
Liang, K.-Y. & Zeger, S. L. Longitudinal data analysis using generalized linear models. Biometrika 73 , 13–22 (1986).
Article MathSciNet Google Scholar
Bruckner, T. et al. NatureCommunications_source_data_071224.xlsx. figshare, https://doi.org/10.6084/m9.figshare.26288080.v1 (2024).
Download references
Acknowledgements
This work was supported by the Eunice Kennedy Shriver National Institute of Child Health and Human Development (5R01HD093651-05)(K.A.D.).
Author information
Authors and affiliations.
Center for Population, Inequality, and Policy, University of California, Irvine, CA, 92697, USA
Tim A. Bruckner
Joe C. Wen School of Population & Public Health, University of California, Irvine, CA, 92697, USA
Tim A. Bruckner & Brenda Bustos
Sanford School of Public Policy, Duke University, Durham, NC, 27708, USA
Kenneth A. Dodge & Jennifer E. Lansford
Department of Psychological Science, University of California, Irvine, CA, 92697, USA
Candice L. Odgers
Department of Psychiatry, University of Vermont, Burlington, VT, 05405, USA
William E. Copeland
You can also search for this author in PubMed Google Scholar
Contributions
T.A.B. contributed to the conceptualization, methodology and formal analysis. B.B. contributed to the formal analysis and visualization. K.A.D. and J.E.L. contributed to the acquisition of data. C.L.O. and W.E.C. contributed to the interpretation of data. All authors contributed to writing, reviewing, and editing of the manuscript.
Corresponding author
Correspondence to Tim A. Bruckner .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Peer review
Peer review information.
Nature Communications thanks the anonymous reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary information, reporting summary, peer review file, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Bruckner, T.A., Bustos, B., Dodge, K.A. et al. Intergenerational effects of a casino-funded family transfer program on educational outcomes in an American Indian community. Nat Commun 15 , 8168 (2024). https://doi.org/10.1038/s41467-024-52428-w
Download citation
Received : 13 January 2023
Accepted : 06 September 2024
Published : 17 September 2024
DOI : https://doi.org/10.1038/s41467-024-52428-w
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
The PMC website is updating on October 15, 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Acta Orthop
- v.90(4); 2019 Aug
Hypothesis-generating and confirmatory studies, Bonferroni correction, and pre-specification of trial endpoints
A p-value presents the outcome of a statistically tested null hypothesis. It indicates how incompatible observed data are with a statistical model defined by a null hypothesis. This hypothesis can, for example, be that 2 parameters have identical values, or that they differ by a specified amount. A low p-value shows that it is unlikely (a high p-value that it is not unlikely) that the observed data are consistent with the null hypothesis. Many null hypotheses are tested in order to generate study hypotheses for further research, others to confirm an already established study hypothesis. The difference between generating and confirming a hypothesis is crucial for the interpretation of the results. Presenting an outcome from a hypothesis-generating study as if it had been produced in a confirmatory study is misleading and represents methodological ignorance or scientific misconduct.
Hypothesis-generating studies differ methodologically from confirmatory studies. A generated hypothesis must be confirmed in a new study. An experiment is usually required for confirmation as an observational study cannot provide unequivocal results. For example, selection and confounding bias can be prevented by randomization and blinding in a clinical trial, but not in an observational study. Confirmatory studies, but not hypothesis-generating studies, also require control of the inflation in the false-positive error risk that is caused by testing multiple null hypotheses. The phenomenon is known as a multiplicity or mass-significance effect. A method for correcting the significance level for the multiplicity effect has been devised by the Italian mathematician Carlo Emilio Bonferroni. The correction (Bender and Lange 2001 ) is often misused in hypothesis-generating studies, often ignored when designing confirmatory studies (which results in underpowered studies), and often inadequately used in laboratory studies, for example when an investigator corrects the significance level for comparing 3 experimental groups by lowering it to 0.05/3 = 0. 017 and believes that this solves the problem of testing 50 null hypotheses, which would have required a corrected significance level of 0.05/50 = 0.001.
In a confirmatory study, it is mandatory to show that the tested hypothesis has been pre-specified. A study protocol or statistical analysis plan should therefore be enclosed with the study report when submitted to a scientific journal for publication. Since 2005 the ICMJE (International Committee of Medical Journal Editors) and the WHO also require registration of clinical trials and their endpoints in a publicly accessible register before enrollment of the first participant. Changing endpoints in a randomized trial after its initiation can in some cases be acceptable, but this is never a trivial problem (Evans 2007 ) and must always be described to the reader. Many authors do not understand the importance of pre-specification and desist from registering their trial, use vague or ambiguous endpoint definitions, redefine the primary endpoint during the analysis, switch primary and secondary outcomes, or present completely new endpoints without mentioning this to the reader. Such publications are simply not credible, but are nevertheless surprisingly common (Ramagopalan et al. 2014 ) even in high impact factor journals (Goldacre et al. 2019 ). A serious editorial evaluation of manuscripts presenting confirmatory results should always include a verification of the endpoint’s pre-specification.
Hypothesis-generating studies are much more common than confirmatory, because the latter are logistically more complex, more laborious, more time-consuming, more expensive, and require more methodological expertise. However, the result of a hypothesis-generating study is just a hypothesis. A hypothesis cannot be generated and confirmed in the same study, and it cannot be confirmed with a new hypothesis-generating study. Confirmatory studies are essential for scientific progress.
- Bender R, Lange S. Adjusting for multiple testing: when and how? J Clin Epidemiol 2001; 54 : 343–9. [ PubMed ] [ Google Scholar ]
- Evans S. When and how can endpoints be changed after initiation of a randomized clinical trial? PLoS Clin Trials 2007; 2 : e18. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Goldacre B, Drysdale H, Milosevic I, Slade E, Hartley P, Marston C, Powell-Smith A, Heneghan C, Mahtani K R. COMPare: a prospective cohort study correcting and monitoring 58 misreported trials in real time . Trials 2019; 20 : 118. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Ramagopalan S, Skingsley A P, Handunnetthi L, Klingel M, Magnus D, Pakpoor J, Goldacre B. Prevalence of primary outcome changes in clinical trials registered on ClinicalTrials.gov: a cross-sectional study . F1000Research 2014, 3 : 77. [ PMC free article ] [ PubMed ] [ Google Scholar ]
IMAGES
VIDEO
COMMENTS
Formulating Hypotheses for Different Study Designs. Generating a testable working hypothesis is the first step towards conducting original research. Such research may prove or disprove the proposed hypothesis. Case reports, case series, online surveys and other observational studies, clinical trials, and narrative reviews help to generate ...
Present the findings in your results and discussion section. Though the specific details might vary, the procedure you will use when testing a hypothesis will always follow some version of these steps. Table of contents. Step 1: State your null and alternate hypothesis. Step 2: Collect data. Step 3: Perform a statistical test.
generation represent two distinct research objectives. In hypothesis testing research, the researcher specifies one or more a priori hypotheses, based on existing theory and/or data, and then puts these hypotheses to an empirical test with a new set of data. In hypothesis generating research, the researcher explores a set of data searching
1. An Overview. Broadly, preclinical research can be classified into two distinct categories depending on the aim and purpose of the experiment, namely, "hypothesis generating" (exploratory) and "hypothesis testing" (confirmatory) research (Fig. 1).Hypothesis generating studies are often scientifically-informed, curiosity and intuition-driven explorations which may generate testable ...
Hypothesis generation is an early and critical step in any hypothesis-driven clinical research project. Because it is not yet a well-understood cognitive process, the need to improve the process goes unrecognized. Without an impactful hypothesis, the significance of any research project can be questionable, regardless of the rigor or diligence applied in other steps of the study, e.g., study ...
The paradigm of hypothesis-generating research does not replace or undermine hypothesis-testing modes of research; instead, it complements them and has facilitated discoveries that may not have been possible with hypothesis-testing research. The hypothesis-generating mode of research has been primarily practiced in basic science but has ...
Academic investigators and practitioners working on the further development and application of hypothesis generation and interpretation in big data computing, with backgrounds in data science and engineering, or the study of problem solving and scientific methods or who employ those ideas in fields like machine learning will find this book of ...
Background: Scientific hypothesis generation is a critical step in scientific research that determines the direction and impact of any investigation. Despite its vital role, we have limited ... After formulating a scientific hypothesis, researchers design studies to test the scientific hypothesis to determine the answer to research questions 2,4.
The formulation and testing of a hypothesis is part of the scientific method, the approach scientists use when attempting to understand and test ideas about natural phenomena. The generation of a hypothesis frequently is described as a creative process and is based on existing scientific knowledge, intuition, or experience.
First, a good hypothesis must be testable and falsifiable. We must be able to test the hypothesis using the methods of science and if you'll recall Popper's falsifiability criterion, it must be possible to gather evidence that will disconfirm the hypothesis if it is indeed false. Second, a good hypothesis must be logical.
Hypothesis testing is a statistical method that is used to make a statistical decision using experimental data. Hypothesis testing is basically an assumption that we make about a population parameter. ... focusing on generating test cases based on specified properties of the code. D. deepanshu_jain. Follow. Improve. Previous Article. Chi-square ...
The second way is to describe one or more existing theories, derive a hypothesis from one of those theories, test the hypothesis in a new study, and finally reevaluate the theory. This format works well when there is an existing theory that addresses the research question—especially if the resulting hypothesis is surprising or conflicts with ...
The hypothesis is a tentative prediction of the nature and direction of relationships between sets of data, phrased as a declarative statement. ... Studies that seek to answer descriptive research questions do not test hypotheses, but they can be used for hypothesis generation. Those hypotheses would then be tested in subsequent studies.
Using data to generate potential discoveries and using data to subject those discoveries to tests are distinct processes. This distinction is known as exploratory (or hypothesis-generating) research and confirmatory (or hypothesis-testing) research. In the daily practice of doing research, it is easy to confuse which one is being done.
Abstract To correct a common imbalance in methodology courses, focusing almost entirely on hypothesis-testing issues to the neglect of hypothesis-generating issues which are at least as important, 49 creative heuristics are described, divided into 5 categories and 14 subcategories. Each of these heuristics has often been used to generate hypotheses in psychological research, and each is ...
The alternative hypothesis is the one that guides the research design, as it directs the researcher toward gathering evidence that will either support or refute the predicted relationship. The research process is structured around testing this hypothesis and determining whether the evidence is strong enough to reject the null hypothesis.
Decision-making. Hypothesis generation involves making informed guesses about various aspects of a business, market, or problem that need further exploration and testing. This article discusses the process you need to follow while generating hypothesis and how an AI tool, like Akaike's BYOB can help you achieve the process quicker and better.
The paradigm of hypothesis-generating research does not replace or undermine hypothesis-testing modes of research; instead, it complements them and has facilitated discoveries that may not have been possible with hypothesis-testing research. The hypothesis-generating mode of research has been primarily practiced in basic science but has ...
Instead, companies should focus organizational energy on hypothesis generation and testing. Hypotheses force individuals to articulate in advance why they believe a given course of action will succeed. A failure then exposes an incorrect hypothesis — which can more reliably convert into organizational learning. What Exactly Is a Hypothesis?
Generating new ideas and scientific hypotheses is a sophisticated task since not all researchers and authors are skilled to plan, conduct, and interpret various research studies. ... research design to test the hypothesis, and its ethical implications: Sections are chosen by the authors, depending on the topic: Introduction, Methods, Results ...
Social psychology research projects begin with generating a testable idea that relies heavily on a researcher's ability to assimilate, recall, and accurately process available research findings. However, an exponential increase in new research findings is making the task of synthesizing ideas across the multitude of topics challenging, which could result in important overlooked research ...
Hypothesis-generating (Qualitative hypothesis-generating research) - Qualitative research uses inductive reasoning. - This involves data collection from study participants or the literature regarding a phenomenon of interest, using the collected data to develop a formal hypothesis, and using the formal hypothesis as a framework for testing the ...
Involving Hypothesis Generation and Testing . Take Time to Think • Choose one of the two elements in DQ4 and independently record what this might look like in a K-2 classroom - Element 21: Organizing Students for Cognitively Complex Tasks - Element 22: Engaging Students in Cognitively
The discovered support for our hypothesis as well as ... more childhood years remaining at the start of family cash transfer varies positively with subsequent generation's third grade test score ...
Presenting an outcome from a hypothesis-generating study as if it had been produced in a confirmatory study is misleading and represents methodological ignorance or scientific misconduct. Hypothesis-generating studies differ methodologically from confirmatory studies. A generated hypothesis must be confirmed in a new study.