
- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons

Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
8.1: Nucleic Acids - Structure and Function
- Last updated
- Save as PDF
- Page ID 14963

- Henry Jakubowski and Patricia Flatt
- College of St. Benedict/St. John's University and Western Oregon University
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
Search Fundamentals of Biochemistry
Introduction to Nucleic Acids
Alongside proteins, lipids, and complex carbohydrates (polysaccharides), nucleic acids are one of the four major types of macromolecules that are essential for all known forms of life. The nucleic acids consist of two major macromolecules, Deoxyribonucleic acid (DNA) and ribonucleic acid (RNA) that carry the genetic instructions for the development, functioning, growth, and reproduction of all known organisms and viruses. Both consist of polymers of a sugar-phosphate-sugar backbone with organic heterocyclic bases attached to the sugars. The sugar in DNA is deoxyribose while in RNA it is ribose. DNA contains four bases, cytosine and thymine (pyrimidine bases) and guanine and adenine (purine bases). DNA in vivo consists of two antiparallel strands intertwined to form the iconic DNA double-stranded helix. RNA is single-stranded but may adopt many secondary and tertiary conformations not unlike that of a protein. Figure \(\PageIndex{1}\) shows a low-resolution comparison of the structure of DNA and RNA.
The biological function of DNA is quite simple, to carry and protect the genetic code. Its structure serves that purpose well. In the next section, we will study the functions of RNA, which are much more numerous and complicated. The structure of RNA has evolved to serve those added functions.
The core structure of a nucleic acid monomer is the nucleoside , which consists of a sugar residue + a nitrogenous base that is attached to the sugar residue at the 1′ position as shown in Figure \(\PageIndex{2}\). The sugar utilized for RNA monomers is ribose, whereas DNA monomers utilize deoxyribose that has lost the hydroxyl functional group at the 2′ position of ribose. For the DNA molecule, four nitrogenous bases are incorporated into the standard DNA structure. These include the Purines: Adenine (A) and Guanine (G), and the Pyrimidines: Cytosine (C) and Thymine (T). RNA uses the same nitrogenous bases as DNA, except for Thymine. Thymine is replaced with Uracil (U) in the RNA structure.
When one or more phosphate groups are attached to a nucleoside at the 5′ position of the sugar residue, it is called a nucleotide. Nucleotides come in three flavors depending on how many phosphates are included: the incorporation of one phosphate forms a nucleoside monophosphate , the incorporation of two phosphates forms a nucleoside diphosphate , and the incorporation of three phosphates forms a nucleoside triphosphate as shown in Figure \(\PageIndex{2}\).
DNA and RNA Hydrogen-bonded structures
Figure \(\PageIndex{3}\) below shows a "flattened" structure of double-stranded B-DNA that best shows the backbone and hydrogen-bonded base pairs between two antiparallel strands of the DNA. Unlike the protein α-helix, where the R-groups of the amino acids are positioned to the outside of the helix, in the DNA double-stranded helix, the nitrogenous bases are positioned inward and face each other. The backbone of the DNA is made up of repeating sugar-phosphate-sugar-phosphate residues. Bases fit in the double-helical model if pyrimidine on one strand is always paired with purine on the other. From Chargaff’s rules , the two strands will pair A with T and G with C. This pairs a keto base with an amino base, and a purine with a pyrimidine. Two H‑bonds can form between A and T, and three can form between G and C . This third H-bond in the G:C base pair is between the additional exocyclic amino group on G and the C2 keto group on C. The pyrimidine C2 keto group is not involved in hydrogen bonding in the A:T base pair.
Furthermore, the orientation of the sugar molecule within the strand determines the directionality of the strands. The phosphate group that makes up part of the nucleotide monomer is always attached to the 5′ position of the deoxyribose sugar residue. The free end that can accept a new incoming nucleotide is the 3′ hydroxyl position of the deoxyribose sugar. Thus, DNA is directional and is always synthesized in the 5′ to 3′ direction. Interestingly, the two strands of the DNA double helix lie in opposite directions or have a head-to-tail orientation.
By analogy to proteins, DNA and RNA can be loosely thought to have primary and secondary structures. For a single strand, the primary sequence is just the base sequence read from the 5' to 3' end of the strand, with the bases thought of as "side chains" as illustrated in Figure \(\PageIndex{4}\) for an RNA strand which contains U instead of T.

Since it is found partnered with another molecule (strand) of DNA, the double-stranded DNA, which consists of two molecules held together by hydrogen bonds, might be considered to have secondary structure (analogous to alpha and beta structure in proteins). Of course, the hydrogen bonds are not between backbone atoms but between side chain bases in double-stranded DNA.
Figure \(\PageIndex{5}\) shows an interactive iCn3D model of the iconic structure of a short oligomer of double-stranded DNA (1BNA).

The backbones of the antiparallel strands are magenta (chain A) and cyan (chain B). The 5' sugar-phosphate end of each chain is shown in spacefill and colored magenta (chain A) and cyan (chain B). The hydrogen-bonded interstrand base pairs are shown alternatively in spacefill and sticks to illustrate how the bases stack on top of each other.
Figure \(\PageIndex{6}\) shows types of " secondary (flat representations) and their 3D or tertiary representations found in nucleic acids.

Figure \(\PageIndex{7}\) shows an interactive iCn3D model of the tertiary structure of the T4 hairpin loop on a Z-DNA stem (1D16).
.png?revision=1&size=bestfit&width=387&height=272 "nucleic acid assignment pdf")
The hairpin shown is from a synthetic DNA oligomer C-G-C-G-C-G-T-T-T-T-C-G-C-G-C-G which adopts an alternative Z-DNA conformation (which we will explore below) with a loop at one end. The thymine bases 7, 8, and 9 are generally perpendicular to one another and stack together, along with the ribose of T7.
Figure \(\PageIndex{8}\) shows an interactive iCn3D model of pseudoknot in RNA (437D).
.png?revision=1&size=bestfit&width=335&height=259 "nucleic acid assignment pdf")
The pseudoknot has two stems that form a "helix" and two loops. The knot consists of a hairpin in the nucleic acid structure with the loop between the helices paired to another part of the nucleic acid. Pseudoknots can be found in mRNA and ribosomal RNA and affect the translation of the RNA (decoding to instruct the synthesis of a protein sequence). RNA viruses have pseudoknots which likewise affect protein synthesis as well as RNA replication. Pseudoknots also occur in DNA.
Synthesis and structure of DNA
The nucleotide that is required as the monomer for the synthesis of both DNA and RNA is nucleoside triphosphate . During the incorporation of the nucleotide into the polymeric structure, two phosphate groups, (P i -P i , called pyrophosphate ) from each triphosphate are cleaved from the incoming nucleotide and further hydrolyzed during the reaction, leaving a nucleoside monophosphate that is incorporated into the growing RNA or DNA chain as shown in Figure \(\PageIndex{9}\) below. Incorporation of the incoming nucleoside triphosphate is mediated by the nucleophilic attack of the 3′-OH of the growing DNA polymer. Thus, DNA synthesis is directional, only occurring at the 3′-end of the molecule.
The further hydrolysis of the pyrophosphate (P i -P i ) releases a large amount of energy ensuring that the overall reaction has a negative ΔG . Hydrolysis of P i -P i ↔ 2P i has a ΔG = -7 kcal/mol (-29 kJ/mol) and is essential to provide the overall negative ΔG (-6.5 kcal/mol, -27 kJ/mol) of the DNA synthesis reaction. Hydrolysis of the pyrophosphate also ensures that the reverse reaction, pyrophosphorolysis, will not take place removing the newly incorporated nucleotide from the growing DNA chain.
This reaction is mediated in DNA by a family of enzymes known as DNA polymerases. Similarly, RNA polymerases are required for RNA synthesis. A more detailed description of polymerase reaction mechanisms will be covered in Chapters X and Y, covering DNA Replication and Repair, and DNA Transcription.

DNA was first isolated by Friedrich Miescher in 1869. The double-helix model of DNA structure was first published in the journal Nature by James Watson and Francis Crick in 1953 based upon the crucial X-ray diffraction image of DNA from Rosalind Franklin in 1952, followed by her more clarified DNA image with Raymond Gosling, Maurice Wilkins, Alexander Stokes, and Herbert Wilson, and base-pairing chemical and biochemical information by Erwin Chargaff. The prior model was triple-stranded DNA.
The realization that the structure of DNA is that of a double-helix elucidated the mechanism of base pairing by which genetic information is stored and copied in living organisms and is widely considered one of the most important scientific discoveries of the 20th century. Crick, Wilkins, and Watson each received one-third of the 1962 Nobel Prize in Physiology or Medicine for their contributions to the discovery. (Franklin, whose breakthrough X-ray diffraction data was used to formulate the DNA structure, died in 1958, and thus was ineligible to be nominated for a Nobel Prize.)
Watson and Crick proposed two strands of DNA – each in a right-hand helix – wound around the same axis. The two strands are held together by H-bonding between the complementary base pairs (A pairs with T and G pairs with C) as shown in Figure \(\PageIndex{10}\) below. Note that when looking from the top view, down on a DNA base pair, that the position where the base pairs attach to the DNA backbone is not equidistant, but that attachment favors one side over the other. This creates unequal gaps or spaces in the DNA known as the major groove for the larger gap, and the minor groove for the smaller gap (Figure 4.5). Based on the DNA sequence within the region, the hydrogen-bond potential created by the nitrogen and oxygen atoms present in the nitrogenous base pairs causes unique recognition features within the major and minor grooves, allowing for specific protein recognition sites to be created.

Figure \(\PageIndex{1}\) shows a schematic representation of available hydrogen bond donors and acceptors in the major and minor grove for TA and CG base pairs.
Figure \(\PageIndex{12}\) shows an interactive iCn3D model of DNA showing the major and minor grooves.

The two sugar-phosphate backbones are shown in green and yellow. Some of the red (oxygen) and blue (nitrogen) atoms in the major grove (and to a much less extent in the minor groove) are not involved in inter-strand G-C and A-T base pairing and so would be available to hydrogen bond donors with specific binding proteins that would display complementary shape and hydrogen bonds acceptors and donors.
Figure \(\PageIndex{13}\) shows an interactive iCn3D model of the N-terminal fragment of the yeast transcriptional activator GAL4 bound to DNA (1D66).
.png?revision=1&size=bestfit&width=449&height=250 "nucleic acid assignment pdf")
The N-terminal fragment binds to conserved CCG triplets found at both ends of the DNA in the major grove. The protein shown is a dimer held together by a short coiled-coil interaction domain so the site has 2-fold symmetry. A small Zn 2 + -containing secondary structure motif in each member of the dimer interacts with the major grove. An extended chain connects the DNA binding and interaction domains of each protein.
In addition to the major and minor grooves providing variation within the double helix structure, the axis alignment of the helix along with other influencing factors such as the degree of solvation can give rise to three forms of the double helix, the A-form (A-DNA) , the B-form (B-DNA), and the Z-form (Z-DNA) as shown in Figure \(\PageIndex{14}\).

Both the A- and B-forms of the double helix are right-handed spirals, with the B-form being the predominant form found in vivo . The A-form helix arises when conditions of dehydration below 75% of normal occur and have mainly been observed in vitro during X-ray crystallography experiments when the DNA helix has become desiccated. However, the A-form of the double helix can occur in vivo when RNA adopts a double-stranded conformation, or when RNA-DNA complexes form. The 2′-OH group of the ribose sugar backbone in the RNA molecule prevents the RNA-DNA hybrid from adopting the B-conformation due to steric hindrance.
The third type of double helix formed is a left-handed helical structure known as the Z-form or Z-DNA. Within this structural motif, the phosphates within the backbone appear to zigzag, providing the name Z-DNA. In vitro, the Z-form of DNA is adopted in short sequences that alternate pyrimidine and purines when high salinity is present. However, the Z-form has been identified in vivo , within short regions of the DNA, showing that DNA is quite flexible and can adopt a variety of conformations. A comparison of features between A-, B-, and Z-form DNA is shown in Table 4.1.
The double-stranded helix of DNA is not always stable. This is because the stair step links between the strands are noncovalent, reversible interactions. Depending on the DNA sequence, denaturation (melting) can be local or widespread and enables various crucial cellular processes to take place, including DNA replication, transcription, and repair.
Both sequence specificity and interaction (whether covalent or not) with a small compound or a protein can induce tilt, roll, and twist effects that rotate the base pairs in the x, y, or z axis, respectively as seen in Figure \(\PageIndex{15}\) , and can therefore change the helix’s overall organization. Furthermore, slide or flip effects can also modify the geometrical orientation of the helix. Hence the flip effects, and (to a lesser extent) the other above-defined movements modulate the double-strand stability within the helix or at its ends. Indeed, under physiological conditions, local DNA ‘breathing’ has been evidenced at both ends of the DNA helix and B- to Z-DNA structural transitions have been observed in internal DNA regions. These types of locally open DNA structures are good substrates for specific proteins which can also induce the opening of a ‘closed’ helix. The processes of DNA replication and repair will be discussed in more detail in Chapter 28.
Figure \(\PageIndex{16}\) shows interactive iCn3D models of A-DNA (top), B-DNA (center), and Z-DNA (bottom). (Copyright; author via source). Click the image for a popup or use the external links in column 1.
We studied the structure of proteins in-depth, discussing resonance in the peptide backbone, allowed backbone angles φ, ψ, and ω, side chain rotamers, Ramachandran plots, and different structural motifs. We also explored them dynamically using molecular dynamic simulations. We also discussed the thermodynamics of protein stability, and how stability could be altered by changing environmental factors such as solution composition and temperature.
In contrast, our understanding of the structural parameters and the dynamics of nucleic acids is less advanced. This may seem paradoxical, especially given the apparent simplicity of the iconic structure of DNA presented in textbooks. Yet look at the types of secondary structures of nucleic acid presented and then the complicated tertiary and quaternary structures of RNA.
The backbone of nucleic acid has a 5-membered sugar ring, which adds rigidity to the backbone, linked to another sugar ring by CH 2 O(PO 3 )O- connectors, which add some additional conformational freedom. We'll explore the effects of the pentose ring geometry in RNA and DNA in chapter section 8.3. To illustrate a yet unexplored complexity of nucleic acid structure, consider just the orientation of rings in double-stranded DNA and in regions of RNA where double-stranded structures form. The variants in the orientation of the hydrogen-bonded base pairs and the corresponding parameters that define them are shown in Figure \(\PageIndex{17}\).

Figure \(\PageIndex{17}\): Base pair orientation and corresponding parameters in nucleic acids. http ://x3dna.org/highlights/schemati...air-parameters (with permission). 2008 3DNA Nature Protocols paper (NP08), the initial 3DNA Nucleic Acids Research paper .
Consider just two of these, the propellor and twist angles. If you examine the iCn3D models of nucleic acids presented above, you will see that the base pairs are not perfectly flat but are twisted. Larger propeller angles are associated with increased rigidity. The propellor angles for A, B, and Z DNA are +18 o , + 16 +/-7 o , and about 0 o , respectively. The twist angles A, B, and Z DNA are +33 o , +36 o , and -30 o , respectively. The lower the twist angle, the higher the number of base pairs per turn. This of course affects the pitch of the helix (the length of one complete turn). All of these terms should be minimized to computationally determine the lowest energy state for a given double-stranded nucleic acid.
Alternative Base Pairing in DNA and RNA
A first glance at a DNA or RNA structure reveals a myriad of possible hydrogen bond donors and acceptors in the bases of the nucleic acid. Hence it should come as no surprise that a variety of alternative or noncanonical (not in the canon or dogma) intermolecular hydrogen bonds can form between and among bases, leading to alternatives to the classical Watson-Crick base pairing. There are 28 possible base pairs with two hydrogen bonds between them. As structure determines function and activity, these alternative structures also influence DNA/RNA function. We will consider four different types of noncanonical base pairing: reverse Watson Crick, wobble, Hoogsteen, and reverse Hoogsteen base pairs.
In DNA, these types of noncanonical base pairs can occur when bases become mismatched in double-stranded regions. In RNA, which we will explore more fully in Chapter 8.2, double-stranded molecules form by separate RNA molecules aren't common. Instead, the molecule folds on itself in 3D space to form a complex tertiary structure containing regions of helical secondary structure. RNAs also form quaternary structures when bound to other nucleic acids and proteins. Larger RNAs have loops with complex secondary and tertiary structures which often require noncanonical base pairing, stabilizesbilize the alternative structures. The noncanonical structures are also important for RNA-protein interactions in the RNA region which binds proteins. If one considers RNA and protein binding as a coupled equilibrium, it should be clear that protein binding to RNA might also induce conformation changes, specifically noncanonical base pairs, in the RNA. For example, the HIV Rev peptide binds to a target site in the envelop gene of HIV (which has an RNA genome) and leads to the formation of an RNA loop with hydrogen bonding between two purines.
Figure \(\PageIndex{18}\) shows an interactive iCn3D model of the REV Response element RNA complexed with REV peptide (1ETF).
.png?revision=1&size=bestfit&height=430 "nucleic acid assignment pdf")
The peptide is shown in cyan and its arginine side chains are shown as cyan lines. There are an extraordinary number of arginines that form ion-ion interactions with the negatively charged phosphates in the major grove of this double-stranded A-RNA. The noncanonical base pairs are shown in CPK-colored sticks. A wobble base, U43-G77, see below, is shown as well as three homopurine base pairs, G47-A73, G55-A58, and G48-G71. The solitary A68 base is shown projecting away from the RNA.
Figure \(\PageIndex{19}\) shows the Watson Crick and the first set of alternative non-canonical base pairs.
Figure \(\PageIndex{19}\): Some noncanonical base nucleic acid base pairs
Let's look at them in more detail.
Reverse Watson Crick : The reverse Watson-Crick AT (AU) and GC pairs can sometimes be found at the end of DNA strands and also in RNA. In forming the reverse base pairs, the pyrimidine can rotate 180 o along the axis shown and then rotate in the plane to align the hydrogen bond donors and acceptors as shown in the top part of the figure. The glycosidic bond between the N in the base and the sugar (the circled R group) is now in an "antiparallel" arrangement in the reverse base pair.
Wobble Base Pairs
The bases in nucleic acids can undergo tautomerization to produce forms that can base pair noncanonically. They are termed wobble base pairs and include G-T(U) base pairs from keto–enol tautomerism and A-C base pairs from amino–imino tautomerism, as illustrated in Figure 18 above.
Figure \(\PageIndex{20}\) shows an interactive iCn3D model of the GT Wobble Base-Pairing in Z-DNA form of d(CGCGTG) (1VTT). Two such GT pairs are found in the structure.
_(1VTT).png?revision=1&size=bestfit&width=262&height=371 "nucleic acid assignment pdf")
The water around the wobble base pairs can form hydrogen bonds and stabilize the pair if a hydrogen bond is missing.
Figure \(\PageIndex{21}\) shows an interactive iCn3D model of dsRNA with G-U wobble base pairs (6L0Y).
.png?revision=1&size=bestfit&width=513&height=173 "nucleic acid assignment pdf")
The structure contains many GU wobble base pairs as well as two CU base pairs between two pyrimidine bases.
Inosine, a variant of the base adenine, can be found in RNA. It is formed by the deamination of adenosine by the enzyme adenosine deaminase. A nucleotide having inosine is named hypoxanthine. Hypoxanthine can form the wobble base pairs I-U, I-A, and I-C when incorporated into RNA, as illustrated in Figure \(\PageIndex{22}\).
Figure \(\PageIndex{22}\): Wobble bases pairs using hypoxanthine with the base inosine
Wobble base pair interactions are especially important in translation when a protein sequence is made from a messenger RNA template (which will be discussed in Unit III). For that decoding process to occur, two RNA molecules, messenger RNA (mRNA) and a transfer RNA (t-RNA) covalently attached to a specific amino acid like glutamic acid, must bind to each other through a 3 base pair interaction. The 3 bases on the mRNA are called the codon, and the 3 complementary bases on the tRNA are called the anticodon. The triplet base pair are antiparallel to each other. The interaction between mRNA and tRNA are illustrated in Figure \(\PageIndex{23}\).
Figure \(\PageIndex{23}\): The wobble uridine (U34) of tRNA molecules that recognize both AAand AG-ending codons for Lys, Gln, and Glu, is modified by the addition of both a thiol (s2) and a methoxy-carbonyl-methyl (mcm5). This double modification enhances the translational efficiency of AA-ending codons. Goffena, J et al. Nat Commun 9, 889 (2018). https://doi.org/10.1038/s41467-018-03221-z . Creative Commons Attribution 4.0 International License. http://creativecommons.org/licenses/by/4.0/ .
The third 3' base on the mRNA is less restricted and can form noncanonical, specifically, wobble base pairs, with the 5' base in the anti-codon triplet of tRNA. The term wobble arises from the subtle conformational changes used to optimize the pairing of the triplets. Wobble bases occur much more in tRNA than other nucleic acids.
Hoogsteen base pairing
Flexibility in DNA allows rotation around the C1'-N glycosidic bond connecting the deoxyribose and base in DNA, allowing different orientations of AT and GC base pairs with each other. The normal "anti" orientation allows "Watson-Crick" (WC) base pairing between AT and GC base pairs while the altered rotation allows "Hoogsteen" base pairs. The different orientations for an AT base pair are shown in Figure \(\PageIndex{24}\).
Figure \(\PageIndex{24}\): Xu, Y., McSally, J., Andricioaei, I. et al. Modulation of Figure \(\PageIndex{xx}\)Hoogsteen dynamics on DNA recognition. Nat Commun 9, 1473 (2018). https://doi.org/10.1038/s41467-018-03516-1Creative Commons Attribution 4.0 International License. http://creativecommons.org/licenses/by/4.0/ .
Hoogsteen base pairing is usually seen when DNA is distorted through interactions with bound proteins and drugs that intercalate between base pairs. Figure \(\PageIndex{25}\) shows an interactive iCn3D model of a Hoogsteen base pair embedded in undistorted B-DNA - MATAlpha2 homeodomain bound to DNA (1K61).
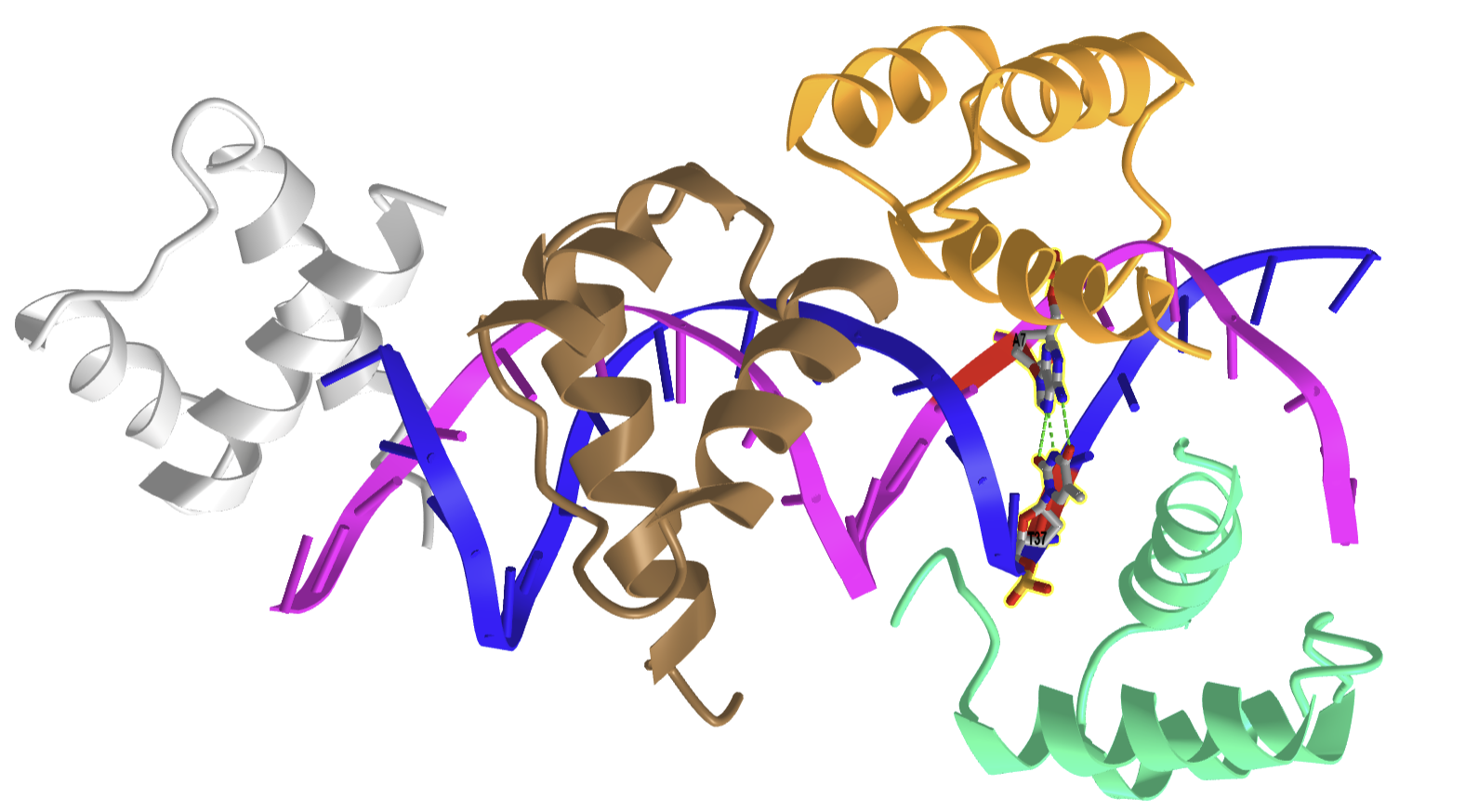.png?revision=1 "nucleic acid assignment pdf")
The same DNA without bound protein has no Hoogsteen base pairs. To form Hoogsteen base pairs, a rotation around the glycosidic-base bond must occur. Hoogsteen base pairs between G and C can also occur on rotation but in addition, the N3 of cytosine is protonated, as shown in Figure 14 above.
Evidence suggests that Hoogsteen base pairing may be important in DNA replication, binding, damage, or repair. They can induce kinking of the DNA near the major grove.
There are also examples of reverse Hoogsteen base pairing, as shown in Figure \(\PageIndex{26}\).
Figure \(\PageIndex{26}\): The reverse Hoogsteen AT base pair
Additional Alternative Structures: Quadruplexes, Triple Helices, and 4-Way Junctions
Quadruplexes
These can be formed in DNA and RNA from G-rich sequences involving tetrads of guanine bases that are hydrogen bonded. They are a bit hard to describe in words so let's first examine one particular structure.
In human cells, telomeres (the ends of chromosomes) contain 300-8000 repeats of a simple TTAGGG sequence. The repetitive TTAGGG sequences in telomeric DNA can form quadruplexes. Figure \(\PageIndex{27}\) shows an interactive iCn3D model of parallel quadruplexes from human telomeric DNA (1KF1). The structure contains a single DNA strand ( 5'- AGGG TTAGGG TTAGGG TTAGGG -3') which contains four TTAGGG repeats.
.png?revision=1&size=bestfit&height=315 "nucleic acid assignment pdf")
Rotate the model to see 3 parallel layers of quadruplexes. In each layer, 4 noncontiguous guanine bases interact with a K + ion. Hover over the guanine bases in one layer and you will find that one layer consists of guanines 4, 10, 16, and 22, which derive from the last G in each of the repeats in the sequence of the oligomer used (5'- AGG G TTAGG G TTAGG G TTAGG G -3'). These quadruplexes certainly serve in recognition and as binding site for telomerase proteins. The guanine-rich telomere sequences which can form quadruplex may also function to stabilize chromosome ends
A Quadruplex can be formed in 1 strand of nucleic acid (as in the above model) or from 2 or 4 separate strands. They also must have at least 2 stacked triads. As in the example above, single-stranded sections can form intramolecular G-quadruplex from a G m X n G m X o G m X p G m sequence, where m is the number of Gs in each short segment (3 in the structure above). If a segment is longer than others, a G might be in a loop.
Triple Helices
These structures can occur in DNA (and also RNA) that contain homopurine and homopyrimidine sequences that have a mirror repeat symmetry. Hence they can occur naturally. A mirror repeat contains a center of symmetry on a single strand. Here is an example: 5'-GCATGGTACG-3'.
They can also occur when a third single-strand DNA (called a triplex-forming oligonucleotide or TFO) binds to a double-stranded DNA. The TFOs bind through Hoogsteen base pairing in the major grove of the ds-DNA. They can bind tightly and specifically in a parallel or antiparallel fashion. Specific and locally higher concentrations of divalent cations or positively charged polyamines like spermine act to stabilize the extra negative charge density from the binding of a third polyanionic DNA strand.
An example of a triple helix system that has been studied in vitro is shown in Figure \(\PageIndex{28}\).
Figure \(\PageIndex{28}\): Intermolecular triplex formation and their oligonucleotide sequences (where “•” and “-” indicates Hoogsteen and Watson–Crick base pairings, respectively). Inset: chemical structure of a parallel T•AT triplet. Guerrini, L. and Alvarez-Puebla, R.A. Nanomaterials 2021, 11, 326. https://doi.org/10.3390/nano11020326 . Creative Commons Attribution (CC BY) license ( https://creativecommons.org/licenses/by/4.0/ )
The double-stranded canonical helix ( D 1 D 2 ) consists of 31 base pairs in which strand D 1 is pyrimidine-rich and D 2 is purine-rich strand ( D 2 ). A 22-nucleotide Triple helix forming oligonucleotide ( TFO ) that is rich in pyrimidines binds the 19 AT and 2 C-GC base triplets. The TFO binds along the major grove of the D 2 strand which is purine rich.
If the binding of the third strand in the major groove occurs at the site where RNA polymerase binds to a gene, then the third strand can inhibit gene transcription. Binding can also lead to a mutation or recombination at the site.
Figure \(\PageIndex{29}\) shows the base pairing of purine and pyrimidines of the third strand to the canonical AT dn GC base pairs of the original double-stranded DNA.
Figure \(\PageIndex{29}\): Base pairing in triple helix motifs. (after Jain et al. Biochimie. 2008. doi: 10.1016/j.biochi.2008.02.011
Figure \(\PageIndex{30}\) shows an interactive iCn3D model of a solution conformation of a parallel DNA triple helix (1BWG).
.png?revision=1&size=bestfit&height=315 "nucleic acid assignment pdf")
Triple helix formation can also occur within a single strand of DNA. The resulting structure is called H-DNA . An example is shown below. Note that the central blue , black, and red sequences are all mirror image repeats (around a central nucleotide). During processes that unravel DNA (replication, transcription, repair), the self-association of individual mirror repeats can form a locally stable triple helix, as shown in Figure \(\PageIndex{31}\).
Figure \(\PageIndex{31}\): Schematic illustrations of (A) the H-DNA or intramolecular triplex structure used in this study; del Mundo et al. (2019) Nucleic acids research. 47. e73. 10.1093/nar/gkz237. Creative Commons Attribution Non-Commercial License ( http://creativecommons.org/licenses/by-nc/4.0/ )
The * between in the G* G and A* A denote Hoogsteen hydrogen bonding (purine motifs) in this intramolecular triple helix. Reverse Hoogsteen hydrogen bonds can also occur.
Triple helices can form when single-stranded DNA formed during replication, transcription or DNA repair with half of the required mirror symmetry folds back into the adjacent major grove and base pairs using Hoogsteen/reverse Hoogsteen bonding, which can be stabilized by Mg 2 + .
Recent Updates: Four-Way Junctions
Nonhelical sections of DNA can, as we will see in the next section on RNA, can bind small target molecules through noncovalent interactions. (RNA examples that we will see in the next chapter section include aptamers, ribozymes and riboswitches.) One example is "lettuce" single-stranded DNA that can bind small fluorophores modeled after the intrinsic fluorophore of the green fluorescent protein. When bound to the lettuce DNA, the fluorescence of the fluorophore is dramatically enhanced. Figure \(\PageIndex{32}\) below shows the structure of extrinsic DNA fluorophores based on GFP that bind to the single-stranded "lettuce" DNA.
Figure \(\PageIndex{32}\): Structure of extrinsic DNA fluorophores based on GFP that bind to DNA. The font color of the names indicates the color of the emitted fluorescence.
Figure \(\PageIndex{33}\) shows an interactive iCn3D model of a solution conformation of a ssDNA:DFAME fluorophore complex (8FI0). The blue dotted lines shown π-π stacking interactions and the green dotted line a hydrogen bond.
.png?revision=1 "nucleic acid assignment pdf")
Figure \(\PageIndex{33}\): Solution conformation of a ss-53 mer DNA:DFAME fluorophore complex (8FI0). (Copyright; author via source). Click the image for a popup or use this external link: https://structure.ncbi.nlm.nih.gov/i...97eLqwNWmaTNC9
The DFAME ligand as shown in sticks.
Figure \(\PageIndex{34}\) shows a closeup of DFAME (colored spacefill) bound to the lettuce DNA.

Figure \(\PageIndex{34}\): Pi stacking interactions (blue dotted lines) between the extrinsic fluorophore DFAME (spacefill) and ssDNA.
The DNA fold is characterized as a four-way junction (also seen in RNA but they are more L or H-shaped). On either end are B-DNA duplexes and the ssDNA between them forms stem-loops with odd base pairing in the stems. The overall structure is like a cloverleaf. Two coaxial stacks of nucleotides form what is called a G-quadruplex where the fluorophore binds. Pi base stacking between diagonally packed bases, along with the binding of Mg 2 + and K + , stabilize the structure.
Stability of nucleic acids
After looking at the myriad of structures showing the nearly parallel hydrogen-bonded base pairs, and from ideas from most textbooks and classes you have taken, you probably think that double-stranded DNA is held together and stabilized by hydrogen bonds between the bases. It is well known that the greater the percentage of GC compared to AT, the greater the stability of the dsDNA, which translates into a higher "melting temperature (T M )", the temperature at which the dsDNA is converted to ssDNA. There is a linear relationship between GC content and T M . The figures above show that GC base pairs have 3 inter-base hydrogen bonds compared to 2 in AT base pairs. These observations support the simple notion that inter-base hydrogen bonds are the source of dsDNA stability.
You would be in general correct in this belief, but you'd be missing the more important contributor to ds-DNA stability, base (π) stacking, and the noncovalent interactions associated with the stacking. The main contributors to stability are hydrophobic interactions in the anhydrous hydrogen-bonded base pairs in the helix. Given that the hydrogen bond donors and acceptors that contribute to base pairing exist in the absence of competing water, the donors and acceptors are free to fully engage in bonding. The hydrogen bond interaction energy is hence more favorable in the stack. The stacking energy is similar for an AT-AT stack and a GC-GC stack ( about -9.8 kcal/mol , 41 kJ/mol). Hence AT and GC base pairs contribute equally to stability. The excess stability of dsDNA enriched in GC base pairs can still be explained by the extra stabilization for an additional hydrogen bond per GC base pair
Proteins are stabilized by a myriad of interactions, but the folded state is marginally more stable than the ensemble of the unfolded state. Marginal stability is important as protein conformation often must be perturbed on binding and ensuing function. The same must be true of double-stranded DNA, which must "unfold' or separate on replication, transcription, and repair. It is well known that dsDNA structure is sensitive to hydration (see the section on A, B, and Z DNA). Small molecules like urea, as we saw with proteins, can also denature DNA into single strands.
DNA must be stable enough to be the carrier of genetic information but dynamic enough to allow events that required partial unfolding. Other water-soluble molecules like ethylene glycol ethers (polyethylene glycol-400) and diglyme (dimethyl ether of diethylene glycol), which are more hydrophobic than water, appear to reduce base stacking interactions while maintaining them, and at the same time allow a longitudinal extension or breathing of the helix. This dynamic extension may be required for transitions of B-DNA to Z-DNA, for example. The extensions also allow transient "hole" to appear between base pairs which might assist in the binding of intercalating agents like some transition metal complexes. The extension caused by these ethers and natural extensions would decrease base stacking but appear at the same time to strengthen the hydrogen bonding between bases.
Longitudinal helical extensions might be important when homologous gene recombine. In that process the homologous DNA strand but exchange with a paired homolog. This processing is associated with strand extension and disruption of base pair at every third base. Recombination also must allow chain extension as it maintains base-pairing fidelity.
DNA structures get obviously more complicated as it packs into the nucleus of a cell and form chromosomes, as shown in Figure \(\PageIndex{35}\). We will study the packing of DNA in other sections.
Börner, R., Kowerko, D., Miserachs, H.G., Shaffer, M., and Sigel, R.K.O. (2016) Metal ion induced heterogeneity in RNA folding studied by smFRET. Coordination Chemistry Reviews 327 DOI: 10.1016/j.ccr.2016.06.002 Available at: https://www.researchgate.net/publication/303846502_Metal_ion_induced_heterogeneity_in_RNA_folding_studied_by_smFRET
Hardison, R. (2019) B-Form, A-Form, and Z-Form of DNA. Chapter in: R. Hardison’s Working with Molecular Genetics. Published by LibreTexts. Available at: https://bio.libretexts.org/Bookshelves/Genetics/Book%3A_Working_with_Molecular_Genetics_(Hardison)/Unit_I%3A_Genes%2C_Nucleic_Acids%2C_Genomes_and_Chromosomes/2%3A_Structures_of_Nucleic_Acids/2.5%3A_B-Form%2C_A-Form%2C_and_Z-Form_of_DNA
Lenglet, G., David-Cordonnier, M-H., (2010) DNA-destabilizing agents as an alternative approach for targeting DNA: Mechanisms of action and cellular consequences. Journal of Nucleic Acids 2010, Article ID: 290935, DOI: 10.4061/2010/290935 Available at: https://www.hindawi.com/journals/jna/2010/290935/
Mechanobiology Institute (2018) What are chromosomes and chromosome territories? Produced by the National University of Singapore. Available at: https://www.mechanobio.info/genome-regulation/what-are-chromosomes-and-chromosome-territories/
National Human Genome Research Institute (2019) The Human Genome Project. National Institutes of Health . Available at: https://www.genome.gov/human-genome-project
Wikipedia contributors. (2019, July 8). DNA. In Wikipedia, The Free Encyclopedia . Retrieved 02:41, July 22, 2019, from https://en.Wikipedia.org/w/index.php?title=DNA&oldid=905364161
Wikipedia contributors. (2019, July 22). Chromosome. In Wikipedia, The Free Encyclopedia . Retrieved 15:18, July 23, 2019, from en.Wikipedia.org/w/index.php?title=Chromosome&oldid=907355235
Wikilectures. Prokaryotic Chromosomes (2017) In MediaWiki, Available at: https://www.wikilectures.eu/w/Prokaryotic_Chromosomes
Wikipedia contributors. (2019, May 15). DNA supercoil. In Wikipedia, The Free Encyclopedia . Retrieved 19:40, July 25, 2019, from en.Wikipedia.org/w/index.php?title=DNA_supercoil&oldid=897160342
Wikipedia contributors. (2019, July 23). Histone. In Wikipedia, The Free Encyclopedia . Retrieved 16:19, July 26, 2019, from en.Wikipedia.org/w/index.php?title=Histone&oldid=907472227
Wikipedia contributors. (2019, July 17). Nucleosome. In Wikipedia, The Free Encyclopedia . Retrieved 17:17, July 26, 2019, from en.Wikipedia.org/w/index.php?title=Nucleosome&oldid=906654745
Wikipedia contributors. (2019, July 26). Human genome. In Wikipedia, The Free Encyclopedia . Retrieved 06:12, July 27, 2019, from en.Wikipedia.org/w/index.php?title=Human_genome&oldid=908031878
Wikipedia contributors. (2019, July 19). Gene structure. In Wikipedia, The Free Encyclopedia . Retrieved 06:16, July 27, 2019, from en.Wikipedia.org/w/index.php?title=Gene_structure&oldid=906938498
Browse Course Material
Course info, instructors.
- Prof. Barbara Imperiali
- Prof. Adam Martin
- Dr. Diviya Ray
Departments
As taught in.
- Functional Genomics
- Biochemistry
- Cell Biology
- Microbiology
- Molecular Biology
Learning Resource Types
Introductory biology, lecture 6: nucleic acids, description.
In this final lecture of the Biochemistry unit, Professor Imperiali covers nucleotides and nucleic acids, discussing their structures and their importance as fundamental units for information storage and information transfer.
Instructor: Barbara Imperiali
- Download video
- Download transcript

You are leaving MIT OpenCourseWare
NMR Study on Nucleic Acids
- Living reference work entry
- First Online: 09 December 2022
- Cite this living reference work entry

- Janez Plavec 2 , 3 , 4
193 Accesses
Nucleic acid structures and their interactions with cellular constituents continue to offer surprises despite decades of structural, biophysical, and biochemical studies. Knowledge of the structure and dynamics of nucleic acids is important not only for understanding biological mechanisms, but also for developing new therapeutics. NMR (Nuclear Magnetic Resonance) spectroscopy has been used for many years to determine the structure of nucleic acids as well as their dynamics and interactions with proteins, other nucleic acids, low molecular weight ligands, cations, and solvent molecules. Recent studies use nucleic acids to create new materials or focus on the interactions of small molecule ligands with large entities such as the ribosome, while novel in vivo methods enable probing of RNA structure and proteins that remodel nucleic acid structures, correct for chemical damage to DNA, modulate gene expression by binding to RNAs, etc. 1 H NMR experiments allow determination of NOE effects and scalar coupling constants between nearby protons of nucleobases and sugar units. The low proton density of nucleic acids allows for rapid detection and identification of hydrogen bonds, which enable assessment of folding and provide constraints for defining base pair arrangements and assessing secondary structure. Sequential resonance assignment is typically followed by collection of structural restraints and structure determination at high resolution. Conventionally, the structure determination process is based on interpretation of magnetization transfer between protons through space mediated by carbon, nitrogen, and phosphorus atoms. Numerous advances including the introduction of ingenious pulse sequences and refined sample preparation strategies have enabled NMR structure determination of RNAs larger than 100-nt. These advances, coupled with improved workflows that incorporate hybrid methods of structure determination, have pushed the boundaries for studying larger, more complex, and biologically relevant systems into new dimensions. With multidimensional NMR experiments, we can measure the dynamics of constituent nuclei along the entire DNA and RNA structure and characterize functionally important motions that range from picoseconds to seconds and longer.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Institutional subscriptions
Adrian M, Heddi B, Phan AT (2012) NMR spectroscopy of G-quadruplexes. Methods 57(1):11–24
Article CAS Google Scholar
Altona C (1982a) Conformational analysis of nucleic acids. Determination of backbone geometry of single-helical RNA and DNA in aqueous solution. Recl Trav Chim Pays-Bas 101(12):413–433
Altona C (1982b) High resolution NMR studies of nucleic acids. NATO Adv Stud Inst 45:161
CAS Google Scholar
Altona C, Haasnoot CAG (1980) Prediction of anti anf gauche vicinal proton-proton coupling constants in carbohydrates: a simple additivity rule for pyranose rings. Org Magn Reson 13(6):417–429
Altona C, Sundaralingam M (1972) Conformational analysis of the sugar ring in nucleosides and nucleotides. A new description using the concept of pseudorotation. J Am Chem Soc 94(23):8205–8212
Altona C, Francke R, de Haan R, Ippel JH, Daalmans GJ, Westra Hoekzema AJA, van Wijk J (1994) Empirical group electronegativities for vicinal NMR proton-proton couplings along a C-C bond: solvent effects and reparametrization of the Haasnoot equation. Magn Reson Chem 32:670–678
Barnwal RP, Yang F, Varani G (2017) Applications of NMR to structure determination of RNAs large and small. Arch Biochem Biophys 628:42–56
Becette OB, Zong G, Chen B, Taiwo KM, Case DA, Dayie TK (2020) Solution NMR readily reveals distinct structural folds and interactions in doubly 13C- and 19F-labeled RNAs. Sci Adv 6(41):eabc6572
Berman HM, Olson WK, Beveridge DL, Westbrook J, Gelbin A, Demeny T, Hsieh SH, Srinivasan AR, Schneider B (1992) The nucleic acid database. A comprehensive relational database of three-dimensional structures of nucleic acids. Biophys J 63(3):751–759
Boelens R, Koning TMG, Vandermarel GA, Vanboom JH, Kaptein R (1989) Iterative procedure for structure determination from proton proton NOEs using a full relaxation matrix approach – application to a DNA octamer. J Magn Reson 82(2):290–308
Boisbouvier J, Brutscher B, Pardi A, Marion D, Simorre JP (2000) NMR determination of sugar puckers in nucleic acids from CSA-dipolar cross-correlated relaxation. J Am Chem Soc 122(28):6779–6780
Božič T, Zalar M, Rogelj B, Plavec J, Šket P (2020) Structural diversity of sense and antisense RNA hexanucleotide repeats associated with ALS and FTLD. Molecules 25(3):525
Article Google Scholar
Chiliveri SC, Robertson AJ, Shen Y, Torchia DA, Bax A (2022) Advances in NMR spectroscopy of weakly aligned biomolecular systems. Chem Rev 122(10):9307–9330
Dayie TK, Olenginski LT, Taiwo KM (2022) Isotope labels combined with solution NMR spectroscopy make visible the invisible conformations of small-to-large RNAs. Chem Rev 122(10):9357–9394
de Leeuw FAAM, Altona C (1982) Conformational analysis of ß-D-Ribo-, ß-D-Deoxyribo-, ß-D-Arabino-, ß-D-Xylo-, and ß-D-Lyxo-nucleosides from proton-proton coupling constants. J Chem Soc Perkin Trans 2:375–384
Dethoff EA, Petzold K, Chugh J, Casiano-Negroni A, Al-Hashimi HM (2012) Visualizing transient low-populated structures of RNA. Nature 491(7426):724–728
Every AE, Russu IM (2007) Probing the role of hydrogen bonds in the stability of base pairs in double-helical DNA. Biopolymers 87(2–3):165–173
Feigon J, Koshlap KM, Smith FW (1995) 1 H NMR spectroscopy of DNA triplexes and quadruplexes. Methods Enzymol 261:225–255
Google Scholar
Flynn PF, Kintanar A, Reid BR, Drobny G (1988) Coherence transfer in deoxyribose sugars produced by isotropic mixing: an improved intraresidue assignment strategy for the two-dimensional NMR spectra of DNA. Biochemistry 27(4):1191–1197
Furtig B, Richter C, Wohnert J, Schwalbe H (2003) NMR spectroscopy of RNA. Chembiochem 4(10):936–962
Gaffney BL, Wang C, Jones RA (1992) Nitrogen-15-labeled oligodeoxynucleotides. 4. Tetraplex formation of d[G(15N-7)GTTTTTGG] and d[T(15N7)GGGT] monitored by 1H detected 15N NMR. J Am Chem Soc 114(11):4047–4050
Glaser SJ, Remerowski ML, Drobny GP (1989) Complete assignment of the deoxyribose 5′/5″ proton resonances of the EcoRI DNA sequence using isotropic mixing. Biochemistry 28(4):1483–1487
Gorenstein DG (1994) Conformation and dynamics of DNA and protein-DNA complexes by 31 P NMR. Chem Rev 94(5):1315–1338
Groves P, Webba da Silva M (2010) Rapid stoichiometric analysis of G-quadruplexes in solution. Chem Eur J 16(22):6451–6453
Haasnoot CAG, de Leeuw FAAM, Altona C (1980) The relationship between proton-proton NMR coupling constants and substituent electronegativities -I. an empirical generalization of the Karplus equation. Tetrahedron 36:2783–2792
Haasnoot CAG, de Leeuw FAAM, de Leeuw HPM, Altona C (1981) Relationship between proton-proton NMR coupling constants and substituent electronegativities. III. Conformational analysis of proline rings in solution using a generalized Karplus equation. Biopolymers 20:1211–1245
Hänsel R, Luh LM, Corbeski I, Trantirek L, Dötsch V (2014) In-cell NMR and EPR spectroscopy of biomacromolecules. Angew Chem Int Ed 53(39):10300–10314
Hoogstraten CG, Pardi A (1998) Measurement of carbon-phosphorus J coupling constants in RNA using spin-echo difference constant-time HCCH-COSY. J Magn Reson 133(1):236–240
Ippel JH, Wijmenga SS, de Jong R, Heus HA, Hilbers CW, de Vroom E, van der Marel GA, van Boom JH (1996) Heteronuclear scalar couplings in the bases and sugar rings of nucleic acids: their determination and application in assignment and conformational analysis. Magn Reson Chem 34:S156–S176
Kaptein R (2013) NMR studies on protein-nucleic acid interaction. J Biomol NMR 56(1):1–2
Karplus M (1959) Contact electron-spin coupling of nuclear magnetic moments. J Chem Phys 30(1):11–15
Kemmink J, Boelens R, Koning T, Vandermarel GA, van Boom JH, Kaptein R (1987) H-1-NMR study of the exchangeable protons of the duplex d(GCGTTGCG).D(CGCAACGC) containing a thymine photodimer. Nucl Acids Res 15(11):4645–4653
Koning TMG, Boelens R, Vandermarel GA, Vanboom JH, Kaptein R (1991) Structure determination of a DNA octamer in solution by NMR spectroscopy – effect of fast local motions. Biochemistry 30(15):3787–3797
Kotar A, Foley HN, Baughman KM, Keane SC (2020) Advanced approaches for elucidating structures of large RNAs using NMR spectroscopy and complementary methods. Methods 183:93–107
Kovačič M, Podbevšek P, Tateishi-Karimata H, Takahashi S, Sugimoto N, Plavec J (2020) Thrombin binding aptamer G-quadruplex stabilized by pyrene-modified nucleotides. Nucleic Acids Res 48(7):3975–3986
Kovanda A, Zalar M, Šket P, Plavec J, Rogelj B (2015) Anti-sense DNA d(GGCCCC)n expansions in C9ORF72 form i-motifs and protonated hairpins. Sci Rep 5:17944
Lankhorst PP, Haasnoot CAG, Erkelens C, Westerink HP, van der Marel GA, van Boom JH, Altona C (1985) Carbon-13 NMR in conformational analysis of nucleic acid fragments 4. The torsion angle distribution about the C3′-O3′ bond in DNA constituents. Nucleic Acids Res 13(3):927–942
Latham MR, Brown DJ, McCallum SA, Pardi A (2005) NMR methods for studying the structure and dynamics of RNA. Chembiochem 6(9):1492–1505
Li Q, Chen J, Trajkovski M, Zhou Y, Fan C, Lu K, Tang P, Su X, Plavec J, Xi Z, Zhou C (2020) 4′-fluorinated RNA: synthesis, structure, and applications as a sensitive 19F NMR probe of RNA structure and function. J Am Chem Soc 142(10):4739–4748
Lipsitz RS, Tjandra N (2004) Residual dipolar couplings in NMR structure analysis. Annu Rev Biophys Biomol Struct 33:387–413
Marino JP, Schwalbe H, Anklin C, Bermel W, Crothers DM, Griesinger C (1994) A three-dimensional triple-resonance 1H, 13C, 31P experiment: sequential through-bond correlation of ribose protons and intervening phosphorus along the RNA oligonucleotide backbone. J Am Chem Soc 116(14):6472–6473
Marino JP, Schwalbe H, Anklin C, Bermel W, Crothers DM, Griesinger C (1995) Sequential correlation of anomeric ribose protons and intervening phosphorus in RNA oligonucleotides by a 1H, 13C, 31P triple-resonance experiment: HCP-CCH-TOCSY. J Biomol NMR 5(1):87–92
Marino JP, Schwalbe H, Glaser SJ, Griesinger C (1996) Determination of gamma and stereospecific assignment of H5′ protons by measurement of 2J and 3J coupling constants in uniformly C-13 labeled RNA. J Am Chem Soc 118(18):4388–4395
Marino JP, Schwalbe H, Griesinger C (1999) J-coupling restraints in RNA structure determination. Acc Chem Res 32(7):614–623
Marušič M, Schlagnitweit J, Petzold K (2019) RNA dynamics by NMR spectroscopy. Chembiochem 20(21):2685–2710
Pardi A, Hare DR, Wang C (1988) Determination of DNA structures by NMR and distance geometry techniques: a computer simulation. Proc Natl Acad Sci U S A 85:8785–8789
Pavc D, Wang B, Spindler L, Drevenšek-Olenik I, Plavec J, Šket P (2020) GC ends control topology of DNA G-quadruplexes and their cation-dependent assembly. Nucleic Acids Res 48(5):2749–2761
Phan AT (2000) Long-range imino proton 13C J-couplings and the through-bond correlation of imino and non-exchangeable protons in unlabeled DNA. J Bomol NMR 16(2):175–178
Phan AT (2001) Through-bond correlation of sugar and base protons in unlabeled nucleic acids. J Magn Reson 153(2):223–226
Phan AT, Patel DJ (2002) A site-specific low-enrichment N-15,C-13 isotope-labeling approach to unambiguous NMR spectral assignments in nucleic acids. J Am Chem Soc 124(7):1160–1161
Phan AT, Luu KN, Patel DJ (2006) Different loop arrangements of intramolecular human telomeric (3+1) G-quadruplexes in K+ solution. Nucleic Acids Res 34(19):5715–5719
Pikkemaat JA, Altona C (1996) Fine structure of the P-H5′ cross-peak in 31P-1H correlated 2D NMR spectroscopy. An efficient probe for the backbone torsion angles β and γ in nucleic acids. Magn Reson Chem 34(Special Issue):S33–S39
Plavec J (2012) DNA. In NMR of biomolecules: towards mechanistic systems biology. In: Bertini I, McGreevy KS, Parigi G (eds). Wiley-VCH Verlag, Singapore, pp 97–116
Plavec J, Tong W, Chattopadhyaya J (1993) How do the gauche and anomeric effects drive the pseudorotational equilibrium of the pentofuranose moiety of nucleosides? J Am Chem Soc 115(21):9734–9746
Plavec J, Thibaudeau C, Chattopadhyaya J (1996) How do the energetics of the stereoelectronic gauche and anomeric effects modulate the conformation of nucleos(t)ides? Pure & Appl Chem 68:2137–2145
Richter C, Reif B, Worner K, Quant S, Marino JP, Engels JW, Griesinger C, Schwalbe H (1998) A new experiment for the measurement of nJ(C,P) coupling constants including 3J(C4i′,P-i) and 3J(C4i′,Pi+1) in oligonucleotides. J Biomol NMR 12(2):223–230
Rinkel LJ, Altona C (1987) Conformational analysis of the deoxyribofuranose ring in DNA by means of proton-proton coupling constants: a graphical method. J Biomol Struct Dyn 4(4):621–649
Schnieders R, Keyhani S, Schwalbe H, Fürtig B (2020) More than proton detection—new avenues for NMR spectroscopy of RNA. Chem Eur J 26(1):102–113
Schwalbe H, Marino JP, King GC, Wechselberger R, Bermel W, Griesinger C (1994) Determination of a complete set of coupling constants in 13C-labeled oligonucleotides. J Biomol NMR 4:631–644
Schwalbe H, Marino JP, Glaser SJ, Griesinger C (1995) Measurement of H,H-coupling constants associated with ν 1 ,ν 2 and ν 3 in uniformly 13C-labeled RNA by HCC-TOCSY-CCH-E.COSY. J Am Chem Soc 117(27):7251–7252
Sket P, Crnugelj M, Kozminski W, Plavec J (2004) 15 NH 4 + ion movement inside d(G 4 T 4 G 4 ) 2 G-quadruplex is accelerated in the presence of smaller Na + ions. Org Biomol Chem 2(14):1970–1973
Sket P, Crnugelj M, Plavec J (2005) Identification of mixed di-cation forms of G-quadruplex in solution. Nucleic Acids Res 33(11):3691–3697
Šket P, Pohleven J, Kovanda A, Štalekar M, Župunski V, Zalar M, Plavec J, Rogelj B (2015) Characterization of DNA G-quadruplex species forming from C9ORF72 G4C2-expanded repeats associated with amyotrophic lateral sclerosis and frontotemporal lobar degeneration. Neurobiol Aging 36(2):1091–1096
Sklenar V, Bax A (1987) Measurement of 1H-31P NMR coupling constants in double-stranded DNA fragments. J Am Chem Soc 109(24):7525–7526
Sklenar V, Miyashiro H, Zon G, Miles HT, Bax A (1986) Assignment of the 31P and 1H resonances in oligonucleotides by two-dimensional NMR spectroscopy. FEBS Lett 208(1):94–98
Szyperski T, Ono A, Fernandez C, Iwai H, Tate S, Wuthrich K, Kainosho M (1997) Measurement of 3JC2′P scalar couplings in a 17 kDa protein complex with 13C,15N-labeled DNA distinguishes the B-I and B-II phosphate conformations of the DNA. J Am Chem Soc 119(41):9901–9902
Takahashi S, Kotar A, Tateishi-Karimata H, Bhowmik S, Wang Z-F, Chang T-C, Sato S, Takenaka S, Plavec J, Sugimoto N (2021) Chemical modulation of DNA replication along G-quadruplex based on topology-dependent ligand binding. J Am Chem Soc 143(40):16458–16469
Tisne C, Simenel C, Hantz E, Schaeffer F, Delepierre M (1996) Backbone conformational study of a non-palindromic 16 base pair DNA duplex exploring 2D 31P-1H heteronuclear inverse spectroscopy: assignment of all NMR phosphorus resonances and measurement of 3J31P-1H3′ coupling constants. Magn Reson Chem 34:S115–S124
van Wijk J, Huckriede BD, Ippel JH, Altona C (1992) Furanose sugar conformations in DNA from NMR coupling constants. Methods Enzymol 211:286–306
Webba da Silva M (2007) NMR methods for studying quadruplex nucleic acids. Methods 43:264–277
Webba da Silva M, Trajkovski M, Sannohe Y, Hessari NM, Sugiyama H, Plavec J (2009) Design of a G-quadruplex topology through glycosidic bond angles. Angew Chem Int Ed 48(48):9167–9170
Weber PL, Drobny G, Reid BR (1985) 1H NMR studies of Lambda-Cro repressor. 1. Selective optimization of two-dimensional relayed coherence transfer spectroscopy. Biochemistry 24(17):4549–4552
Wijmenga SS, van Buuren BNM (1998) The use of NMR methods for conformational studies of nucleic acids. Prog Nucl Magn Reson Spectrosc 32:287–387
Wüthrich K (1986) NMR of proteins and nucleic acids. Wiley, New York
Book Google Scholar
Xue Y, Kellogg D, Kimsey IJ, Sathyamoorthy B, Stein ZW, McBrairty M, Al-Hashimi HM (2015) Characterizing RNA excited states using NMR relaxation dispersion. Methods Enzymol S A Woodson and F H T Allain 558:39–73
Zhu LM, Reid BR, Drobny GP (1995) Errors in measuring and interpreting values of coupling constants J from PE.COSY experiments. J Magn Res A 115(2):206–212
Download references
Acknowledgments
The author is grateful to the colleagues named in the cited papers from his laboratory at Slovenian NMR center, especially Drs. Trajkovski, Šket, Lenarčič Živković, Kocman, Kotar, Marušič, Podbevšek, Pavc, Toplishek, and Cevec. The help of Klemen Pečnik, Dr. Marko Trajkovski, Matic Kovačič, and Dr. Primož Šket in the preparation of the artwork is gratefully acknowledged. This work was supported partly by the Slovenian Research Agency (ARRS, grants P1-0242 and J1-1704).
Author information
Authors and affiliations.
Slovenian NMR Centre, National Institute of Chemistry, Ljubljana, Slovenia
Janez Plavec
Faculty of Chemistry and Chemical Technology, University of Ljubljana, Ljubljana, Slovenia
EN-FIST Center of Excellence, Ljubljana, Slovenia
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Janez Plavec .
Editor information
Editors and affiliations.
Frontier Institute for Biomolecular Engineering Research (FIBER), Konan University, Kobe, Japan
Naoki Sugimoto
Section Editor information
Rights and permissions.
Reprints and permissions
Copyright information
© 2022 Springer Nature Singapore Pte Ltd.
About this entry
Cite this entry.
Plavec, J. (2022). NMR Study on Nucleic Acids. In: Sugimoto, N. (eds) Handbook of Chemical Biology of Nucleic Acids. Springer, Singapore. https://doi.org/10.1007/978-981-16-1313-5_8-1
Download citation
DOI : https://doi.org/10.1007/978-981-16-1313-5_8-1
Received : 10 August 2022
Accepted : 11 August 2022
Published : 09 December 2022
Publisher Name : Springer, Singapore
Print ISBN : 978-981-16-1313-5
Online ISBN : 978-981-16-1313-5
eBook Packages : Springer Reference Chemistry and Mat. Science Reference Module Physical and Materials Science Reference Module Chemistry, Materials and Physics
- Publish with us
Policies and ethics
- Find a journal
- Track your research
- Search Menu
- Sign in through your institution
Chemical Biology and Nucleic Acid Chemistry
Computational biology, critical reviews and perspectives.
- Data Resources and Analyses
Gene Regulation, Chromatin and Epigenetics
Genome integrity, repair and replication.
- Methods Online
Molecular Biology
Nucleic acid enzymes, rna and rna-protein complexes, structural biology, synthetic biology and bioengineering.
- Advance Articles
- Breakthrough Articles
- Special Collections
- Scope and Criteria for Consideration
- Author Guidelines
- Data Deposition Policy
- Database Issue Guidelines
- Web Server Issue Guidelines
- Submission Site
- About Nucleic Acids Research
- Editors & Editorial Board
- Information of Referees
- Self-Archiving Policy
- Dispatch Dates
- Advertising and Corporate Services
- Journals Career Network
- Journals on Oxford Academic
- Books on Oxford Academic
Browse issues
Cover image.

Volume 52, Issue 9, 22 May 2024
Fourteen years of cellular deconvolution: methodology, applications, technical evaluation and outstanding challenges.

- View article
- Supplementary data
A novel transient receptor potential C3/C6 selective activator induces the cellular uptake of antisense oligonucleotides

Quantifying the activity profile of ASO and siRNA conjugates in glioblastoma xenograft tumors in vivo

Definition of the binding specificity of the T7 bacteriophage primase by analysis of a protein binding microarray using a thermodynamic model

m6ACali: machine learning-powered calibration for accurate m6A detection in MeRIP-Seq

High-density generation of spatial transcriptomics with STAGE

Genome-wide screening and functional validation of methylation barriers near promoters

RNA–RNA interactions between respiratory syncytial virus and miR-26 and miR-27 are associated with regulation of cell cycle and antiviral immunity

Processivity and specificity of histone acetylation by the male-specific lethal complex

The jet-like chromatin structure defines active secondary metabolism in fungi

Tracking pairwise genomic loci by the ParB–ParS and Noc-NBS systems in living cells

HBO1 determines SMAD action in pluripotency and mesendoderm specification

ATRX guards against aberrant differentiation in mesenchymal progenitor cells

WSB1/2 target chromatin-bound lysine-methylated RelA for proteasomal degradation and NF-κB termination

Catalytic residues of microRNA Argonautes play a modest role in microRNA star strand destabilization in C. elegans

Defining the contribution of microRNA-specific Argonautes with slicer capability in animals

Viral reprogramming of host transcription initiation

Correction of non-random mutational biases along a linear bacterial chromosome by the mismatch repair endonuclease NucS

DNA-PKcs suppresses illegitimate chromosome rearrangements

CSB and SMARCAL1 compete for RPA32 at stalled forks and differentially control the fate of stalled forks in BRCA2-deficient cells

LC3B drives transcription-associated homologous recombination via direct interaction with R-loops

SIRT2 promotes base excision repair by transcriptionally activating OGG1 in an ATM/ATR-dependent manner

S-phase checkpoint prevents leading strand degradation from strand-associated nicks at stalled replication forks

Defective transfer of parental histone decreases frequency of homologous recombination by increasing free histone pools in budding yeast

The discovery of novel noncoding RNAs in 50 bacterial genomes

Comprehensive profiling of L1 retrotransposons in mouse

Comprehensive genomic features indicative for Notch responsiveness

RecA-dependent or independent recombination of plasmid DNA generates a conflict with the host EcoKI immunity by launching restriction alleviation

Caspase-mediated processing of TRBP regulates apoptosis during viral infection

Activity reconstitution of Kre33 and Tan1 reveals a molecular ruler mechanism in eukaryotic tRNA acetylation

Live-cell imaging reveals the trade-off between target search flexibility and efficiency for Cas9 and Cas12a

SARS-CoV-2 nsp15 preferentially degrades AU-rich dsRNA via its dsRNA nickase activity

A combinatorial approach for achieving CNS-selective RNAi

Cryo-EM structure of SRP68/72 reveals an extended dimerization domain with RNA-binding activity

RNA-binding properties orchestrate TDP-43 homeostasis through condensate formation in vivo

A Fur family protein BosR is a novel RNA-binding protein that controls rpoS RNA stability in the Lyme disease pathogen

Dynamics of miRNA accumulation during C. elegans larval development

Nuclear RNA-related processes modulate the assembly of cytoplasmic RNA granules

UPF1 ATPase autoinhibition and activation modulate RNA binding kinetics and NMD efficiency

Biochemical and structural characterization of Fapy•dG replication by Human DNA polymerase β

CRISPR-Cas tools for simultaneous transcription & translation control in bacteria

Correction to ‘STIM1 translocation to the nucleus protects cells from DNA damage’
Retraction of ‘dissecting the splicing mechanism of the drosophila editing enzyme; dadar ’, netactivity enhances transcriptional signals by combining gene expression into robust gene set activity scores through interpretable autoencoders.

Examining chromatin heterogeneity through PacBio long-read sequencing of M.EcoGII methylated genomes: an m 6 A detection efficiency and calling bias correcting pipeline

SifiNet: a robust and accurate method to identify feature gene sets and annotate cells

Email alerts
- Editorial Board
Affiliations
- Online ISSN 1362-4962
- Print ISSN 0305-1048
- Copyright © 2024 Oxford University Press
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
IMAGES
VIDEO
COMMENTS
Nucleotides are the building blocks of nucleic acids: they are the monomers which, repeated many times, form the polymers DNA and RNA. Nucleotides are composed of a five-carbon sugar covalently attached to a phosphate group and a base containing nitrogen atoms. Figure 1 shows the structure of the nucleotides making up nucleic acids.
of complex cells. Elemental analysis of nucleic acids showed the presence of phosphorus, in addition to the usual C, H, N & O. We now know that nucleic acids are found throughout a cell, not just in the nucleus, the name nucleic acid is still used for such materials. A nucleic acid is a polymer in which the monomer units are nucleotides.
N-Glycosides of a purine or pyrimidine heterocyclic base and a carbohydrate. The C-N bond involves the anomeric carbon of the carbohydrate. The carbohydrates for nucleic acids are D-ribose and 2-deoxy-D-ribose. 342. Nucleosides = carbohydrate + base (Table 28.2, p. 1168) ribonucleosides or 2'-deoxyribonucleosides. NH2 O.
Nucleic acids are the 'building blocks' of DNA and RNA. The structure of DNA . DNA is formed from two polynucleotide chains. Each chain has a helical structure (a helix), in other words the molecule is coiled like a spring. The two helices are then intertwined to give a double helix. The bases are on the inside of the helix
Nucleic acids are macromolecules, like proteins, carbohydrates and lipids. It is essential for all known forms of life. They are found in abundance in all living things, where they function in encoding, transmitting and expressing genetic information. Nucleic acids are divided into: DNA (deoxyribonucleic acid) and.
We will now turn to the chemistry of nucleic acids. Components of nucleic acids Nucleotide bases Nucleic acids are the acidic component of nuclei, first identified by Meischer in the late 19th century. Subsequent work showed that they are polymers, and the monomeric subunit of nucleic acids was termed a nucleotide. Hence nucleic acids are ...
found in some nucleic acid molecules. DNA has two types of pyrimidines, cyto-sine and thymine. In RNA, thymine is normally replaced by a similar base, uracil, which lacks the methyl group found in thymine (Fig. 3.8). P= + -+ + arctan ( )( ) [sin( ) sin( )]. u u uu up p 2 4 13 2 5 25 0 Basics of Nucleic Acid Structure61 FA Chain direction ...
DNA is a polymer made of mo nomeric units called nucleotides (Figure 1A), a n ucleotide comprises a. 5-carbon sugar, deoxyribose, a nitrogenous base and one or mor e phosphate groups. The building ...
The structure of RNA has evolved to serve those added functions. The core structure of a nucleic acid monomer is the nucleoside, which consists of a sugar residue + a nitrogenous base that is attached to the sugar residue at the 1′ position as shown in Figure 8.1.2 8.1. 2.
In this final lecture of the Biochemistry unit, Professor Imperiali covers nucleotides and nucleic acids, discussing their structures and their importance as fundamental units for information storage and information transfer. Instructor: Barbara Imperiali. MIT OpenCourseWare is a web based publication of virtually all MIT course content.
6.2.1 Chemistry of nucleic acid Nucleotides are organic compounds that are monomeric units of nucleic acids,they are of different types and structures and have variety of physiological functions. Nucleic acids are responsible for storage and transmission of genetic information. Nucleic acids are chemically composed of polymers of nucleotides
Figure 4 shows the mechanism for the attachment of an amino acid in tRNA. In the first step, the CO 2 - of amino acid attacks the α-phosphorus of ATP. The carboxylic acid of amino acid is now activated with good leaving group. The 3'-OH group of tRNA attacks the carbonyl carbon via nucleophilic addition to give the amino acid attached tRNA.
Nucleic Acids Web Assignment Name:_____ PART A: Review of DNA structure ... Then, click the link for unit 4, nucleic acids and under "notes" click "nucleic acids." This will take you through a set of notes on DNA. Answer the following questions as you view the site. STOP at slide 11.
Hardcover Book USD 1,199.99. Price excludes VAT (USA) Durable hardcover edition. Dispatched in 3 to 5 business days. Free shipping worldwide - see info. Buy Hardcover Book. Tax calculation will be finalised at checkout. Handbook of Chemical Biology of Nucleic Acids is a comprehensive source of information on the fundamentals and applications of ...
Nucleic acids, macromolecules made out of units called nucleotides, come in two naturally occurring varieties: deoxyribonucleic acid ( DNA) and ribonucleic acid ( RNA ). DNA is the genetic material found in living organisms, all the way from single-celled bacteria to multicellular mammals like you and me. Some viruses use RNA, not DNA, as their ...
Basically, nucleic acids can be subdivided into two types: deoxy-ribonucleic acid (DNA) and ribonucleic acid (RNA). Both DNA and RNA have been shown to consist of three groups of molecules: pentose (5-carbon-atom) sugars; organic bases; and inorganic phosphate. Sugars There are only two types of sugar present in nucleic acids, ribose which
Nucleotides have three characteristic components: (1) a nitrogenous (nitrogen-containing) base, (2) a pentose, and (3) one or more phosphates (Fig. 8-1). The mol-ecule without a phosphate group is called a nucleoside. The nitrogenous bases are derivatives of two parent. Purine or pyrimidine base.
A nucleic acid is an organic compound, such as DNA or RNA, that is built of monomers called nucleotides. Many nucleotides bind together to form a chain called a polynucleotide. The nucleic acid DNA (deoxyribonucleic acid) consists of two polynucleotide chains. The nucleic acid RNA (ribonucleic acid) consists of just one polynucleotide chain.
nucleic acid, naturally occurring chemical compound that is capable of being broken down to yield phosphoric acid, sugars, and a mixture of organic bases (purines and pyrimidines).Nucleic acids are the main information-carrying molecules of the cell, and, by directing the process of protein synthesis, they determine the inherited characteristics of every living thing.
Separation of the nucleic acids from other cellular components • Purification of nucleic acids . 4-1.2. Isolation and Purification of Genomic DNA. Genomic DNA is found in the nucleus of all living cells with the structure of double-stranded DNA remaining unchanged (helical ribbon). The isolation of genomic DNA differs in animals and plant cells.
Nuclear magnetic resonance spectroscopy (NMR) enables the determination of the three-dimensional structure of proteins and nucleic acids in solution. A set of NMR experiments identifies the residues in the molecule and determines the order of residues that comprises the primary structure. Distance and angular relationships are subsequently ...
Problem: No or low nucleic acid yield. Make sure that ample time was allowed for resuspension or rehydration of sample. Repeat isolation from any remaining original sample (adjust procedure for possible low cell number or poorly handled starting material). Concentrate dilute nucleic acid using ethanol precipitation.
NMR (Nuclear Magnetic Resonance) spectroscopy has been used for many years to determine the structure of nucleic acids as well as their dynamics and interactions with proteins, other nucleic acids, low molecular weight ligands, cations, and solvent molecules. Recent studies use nucleic acids to create new.
Publishes the results of leading edge research into physical, chemical, biochemical and biological aspects of nucleic acids and proteins involved in nucleic acid metabolism and/or interactions. Fully open access.