Random Assignment in Psychology: Definition & Examples
Julia Simkus
Editor at Simply Psychology
BA (Hons) Psychology, Princeton University
Julia Simkus is a graduate of Princeton University with a Bachelor of Arts in Psychology. She is currently studying for a Master's Degree in Counseling for Mental Health and Wellness in September 2023. Julia's research has been published in peer reviewed journals.
Learn about our Editorial Process
Saul McLeod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul McLeod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
In psychology, random assignment refers to the practice of allocating participants to different experimental groups in a study in a completely unbiased way, ensuring each participant has an equal chance of being assigned to any group.
In experimental research, random assignment, or random placement, organizes participants from your sample into different groups using randomization.
Random assignment uses chance procedures to ensure that each participant has an equal opportunity of being assigned to either a control or experimental group.
The control group does not receive the treatment in question, whereas the experimental group does receive the treatment.
When using random assignment, neither the researcher nor the participant can choose the group to which the participant is assigned. This ensures that any differences between and within the groups are not systematic at the onset of the study.
In a study to test the success of a weight-loss program, investigators randomly assigned a pool of participants to one of two groups.
Group A participants participated in the weight-loss program for 10 weeks and took a class where they learned about the benefits of healthy eating and exercise.
Group B participants read a 200-page book that explains the benefits of weight loss. The investigator randomly assigned participants to one of the two groups.
The researchers found that those who participated in the program and took the class were more likely to lose weight than those in the other group that received only the book.

Importance
Random assignment ensures that each group in the experiment is identical before applying the independent variable.
In experiments , researchers will manipulate an independent variable to assess its effect on a dependent variable, while controlling for other variables. Random assignment increases the likelihood that the treatment groups are the same at the onset of a study.
Thus, any changes that result from the independent variable can be assumed to be a result of the treatment of interest. This is particularly important for eliminating sources of bias and strengthening the internal validity of an experiment.
Random assignment is the best method for inferring a causal relationship between a treatment and an outcome.
Random Selection vs. Random Assignment
Random selection (also called probability sampling or random sampling) is a way of randomly selecting members of a population to be included in your study.
On the other hand, random assignment is a way of sorting the sample participants into control and treatment groups.
Random selection ensures that everyone in the population has an equal chance of being selected for the study. Once the pool of participants has been chosen, experimenters use random assignment to assign participants into groups.
Random assignment is only used in between-subjects experimental designs, while random selection can be used in a variety of study designs.
Random Assignment vs Random Sampling
Random sampling refers to selecting participants from a population so that each individual has an equal chance of being chosen. This method enhances the representativeness of the sample.
Random assignment, on the other hand, is used in experimental designs once participants are selected. It involves allocating these participants to different experimental groups or conditions randomly.
This helps ensure that any differences in results across groups are due to manipulating the independent variable, not preexisting differences among participants.
When to Use Random Assignment
Random assignment is used in experiments with a between-groups or independent measures design.
In these research designs, researchers will manipulate an independent variable to assess its effect on a dependent variable, while controlling for other variables.
There is usually a control group and one or more experimental groups. Random assignment helps ensure that the groups are comparable at the onset of the study.
How to Use Random Assignment
There are a variety of ways to assign participants into study groups randomly. Here are a handful of popular methods:
- Random Number Generator : Give each member of the sample a unique number; use a computer program to randomly generate a number from the list for each group.
- Lottery : Give each member of the sample a unique number. Place all numbers in a hat or bucket and draw numbers at random for each group.
- Flipping a Coin : Flip a coin for each participant to decide if they will be in the control group or experimental group (this method can only be used when you have just two groups)
- Roll a Die : For each number on the list, roll a dice to decide which of the groups they will be in. For example, assume that rolling 1, 2, or 3 places them in a control group and rolling 3, 4, 5 lands them in an experimental group.
When is Random Assignment not used?
- When it is not ethically permissible: Randomization is only ethical if the researcher has no evidence that one treatment is superior to the other or that one treatment might have harmful side effects.
- When answering non-causal questions : If the researcher is just interested in predicting the probability of an event, the causal relationship between the variables is not important and observational designs would be more suitable than random assignment.
- When studying the effect of variables that cannot be manipulated: Some risk factors cannot be manipulated and so it would not make any sense to study them in a randomized trial. For example, we cannot randomly assign participants into categories based on age, gender, or genetic factors.
Drawbacks of Random Assignment
While randomization assures an unbiased assignment of participants to groups, it does not guarantee the equality of these groups. There could still be extraneous variables that differ between groups or group differences that arise from chance. Additionally, there is still an element of luck with random assignments.
Thus, researchers can not produce perfectly equal groups for each specific study. Differences between the treatment group and control group might still exist, and the results of a randomized trial may sometimes be wrong, but this is absolutely okay.
Scientific evidence is a long and continuous process, and the groups will tend to be equal in the long run when data is aggregated in a meta-analysis.
Additionally, external validity (i.e., the extent to which the researcher can use the results of the study to generalize to the larger population) is compromised with random assignment.
Random assignment is challenging to implement outside of controlled laboratory conditions and might not represent what would happen in the real world at the population level.
Random assignment can also be more costly than simple observational studies, where an investigator is just observing events without intervening with the population.
Randomization also can be time-consuming and challenging, especially when participants refuse to receive the assigned treatment or do not adhere to recommendations.
What is the difference between random sampling and random assignment?
Random sampling refers to randomly selecting a sample of participants from a population. Random assignment refers to randomly assigning participants to treatment groups from the selected sample.
Does random assignment increase internal validity?
Yes, random assignment ensures that there are no systematic differences between the participants in each group, enhancing the study’s internal validity .
Does random assignment reduce sampling error?
Yes, with random assignment, participants have an equal chance of being assigned to either a control group or an experimental group, resulting in a sample that is, in theory, representative of the population.
Random assignment does not completely eliminate sampling error because a sample only approximates the population from which it is drawn. However, random sampling is a way to minimize sampling errors.
When is random assignment not possible?
Random assignment is not possible when the experimenters cannot control the treatment or independent variable.
For example, if you want to compare how men and women perform on a test, you cannot randomly assign subjects to these groups.
Participants are not randomly assigned to different groups in this study, but instead assigned based on their characteristics.
Does random assignment eliminate confounding variables?
Yes, random assignment eliminates the influence of any confounding variables on the treatment because it distributes them at random among the study groups. Randomization invalidates any relationship between a confounding variable and the treatment.
Why is random assignment of participants to treatment conditions in an experiment used?
Random assignment is used to ensure that all groups are comparable at the start of a study. This allows researchers to conclude that the outcomes of the study can be attributed to the intervention at hand and to rule out alternative explanations for study results.
Further Reading
- Bogomolnaia, A., & Moulin, H. (2001). A new solution to the random assignment problem . Journal of Economic theory , 100 (2), 295-328.
- Krause, M. S., & Howard, K. I. (2003). What random assignment does and does not do . Journal of Clinical Psychology , 59 (7), 751-766.
Random Assignment in Psychology (Definition + 40 Examples)
Have you ever wondered how researchers discover new ways to help people learn, make decisions, or overcome challenges? A hidden hero in this adventure of discovery is a method called random assignment, a cornerstone in psychological research that helps scientists uncover the truths about the human mind and behavior.
Random Assignment is a process used in research where each participant has an equal chance of being placed in any group within the study. This technique is essential in experiments as it helps to eliminate biases, ensuring that the different groups being compared are similar in all important aspects.
By doing so, researchers can be confident that any differences observed are likely due to the variable being tested, rather than other factors.
In this article, we’ll explore the intriguing world of random assignment, diving into its history, principles, real-world examples, and the impact it has had on the field of psychology.
History of Random Assignment

Stepping back in time, we delve into the origins of random assignment, which finds its roots in the early 20th century.
The pioneering mind behind this innovative technique was Sir Ronald A. Fisher , a British statistician and biologist. Fisher introduced the concept of random assignment in the 1920s, aiming to improve the quality and reliability of experimental research .
His contributions laid the groundwork for the method's evolution and its widespread adoption in various fields, particularly in psychology.
Fisher’s groundbreaking work on random assignment was motivated by his desire to control for confounding variables – those pesky factors that could muddy the waters of research findings.
By assigning participants to different groups purely by chance, he realized that the influence of these confounding variables could be minimized, paving the way for more accurate and trustworthy results.
Early Studies Utilizing Random Assignment
Following Fisher's initial development, random assignment started to gain traction in the research community. Early studies adopting this methodology focused on a variety of topics, from agriculture (which was Fisher’s primary field of interest) to medicine and psychology.
The approach allowed researchers to draw stronger conclusions from their experiments, bolstering the development of new theories and practices.
One notable early study utilizing random assignment was conducted in the field of educational psychology. Researchers were keen to understand the impact of different teaching methods on student outcomes.
By randomly assigning students to various instructional approaches, they were able to isolate the effects of the teaching methods, leading to valuable insights and recommendations for educators.
Evolution of the Methodology
As the decades rolled on, random assignment continued to evolve and adapt to the changing landscape of research.
Advances in technology introduced new tools and techniques for implementing randomization, such as computerized random number generators, which offered greater precision and ease of use.
The application of random assignment expanded beyond the confines of the laboratory, finding its way into field studies and large-scale surveys.
Researchers across diverse disciplines embraced the methodology, recognizing its potential to enhance the validity of their findings and contribute to the advancement of knowledge.
From its humble beginnings in the early 20th century to its widespread use today, random assignment has proven to be a cornerstone of scientific inquiry.
Its development and evolution have played a pivotal role in shaping the landscape of psychological research, driving discoveries that have improved lives and deepened our understanding of the human experience.
Principles of Random Assignment
Delving into the heart of random assignment, we uncover the theories and principles that form its foundation.
The method is steeped in the basics of probability theory and statistical inference, ensuring that each participant has an equal chance of being placed in any group, thus fostering fair and unbiased results.
Basic Principles of Random Assignment
Understanding the core principles of random assignment is key to grasping its significance in research. There are three principles: equal probability of selection, reduction of bias, and ensuring representativeness.
The first principle, equal probability of selection , ensures that every participant has an identical chance of being assigned to any group in the study. This randomness is crucial as it mitigates the risk of bias and establishes a level playing field.
The second principle focuses on the reduction of bias . Random assignment acts as a safeguard, ensuring that the groups being compared are alike in all essential aspects before the experiment begins.
This similarity between groups allows researchers to attribute any differences observed in the outcomes directly to the independent variable being studied.
Lastly, ensuring representativeness is a vital principle. When participants are assigned randomly, the resulting groups are more likely to be representative of the larger population.
This characteristic is crucial for the generalizability of the study’s findings, allowing researchers to apply their insights broadly.
Theoretical Foundation
The theoretical foundation of random assignment lies in probability theory and statistical inference .
Probability theory deals with the likelihood of different outcomes, providing a mathematical framework for analyzing random phenomena. In the context of random assignment, it helps in ensuring that each participant has an equal chance of being placed in any group.
Statistical inference, on the other hand, allows researchers to draw conclusions about a population based on a sample of data drawn from that population. It is the mechanism through which the results of a study can be generalized to a broader context.
Random assignment enhances the reliability of statistical inferences by reducing biases and ensuring that the sample is representative.
Differentiating Random Assignment from Random Selection
It’s essential to distinguish between random assignment and random selection, as the two terms, while related, have distinct meanings in the realm of research.
Random assignment refers to how participants are placed into different groups in an experiment, aiming to control for confounding variables and help determine causes.
In contrast, random selection pertains to how individuals are chosen to participate in a study. This method is used to ensure that the sample of participants is representative of the larger population, which is vital for the external validity of the research.
While both methods are rooted in randomness and probability, they serve different purposes in the research process.
Understanding the theories, principles, and distinctions of random assignment illuminates its pivotal role in psychological research.
This method, anchored in probability theory and statistical inference, serves as a beacon of reliability, guiding researchers in their quest for knowledge and ensuring that their findings stand the test of validity and applicability.
Methodology of Random Assignment

Implementing random assignment in a study is a meticulous process that involves several crucial steps.
The initial step is participant selection, where individuals are chosen to partake in the study. This stage is critical to ensure that the pool of participants is diverse and representative of the population the study aims to generalize to.
Once the pool of participants has been established, the actual assignment process begins. In this step, each participant is allocated randomly to one of the groups in the study.
Researchers use various tools, such as random number generators or computerized methods, to ensure that this assignment is genuinely random and free from biases.
Monitoring and adjusting form the final step in the implementation of random assignment. Researchers need to continuously observe the groups to ensure that they remain comparable in all essential aspects throughout the study.
If any significant discrepancies arise, adjustments might be necessary to maintain the study’s integrity and validity.
Tools and Techniques Used
The evolution of technology has introduced a variety of tools and techniques to facilitate random assignment.
Random number generators, both manual and computerized, are commonly used to assign participants to different groups. These generators ensure that each individual has an equal chance of being placed in any group, upholding the principle of equal probability of selection.
In addition to random number generators, researchers often use specialized computer software designed for statistical analysis and experimental design.
These software programs offer advanced features that allow for precise and efficient random assignment, minimizing the risk of human error and enhancing the study’s reliability.
Ethical Considerations
The implementation of random assignment is not devoid of ethical considerations. Informed consent is a fundamental ethical principle that researchers must uphold.
Informed consent means that every participant should be fully informed about the nature of the study, the procedures involved, and any potential risks or benefits, ensuring that they voluntarily agree to participate.
Beyond informed consent, researchers must conduct a thorough risk and benefit analysis. The potential benefits of the study should outweigh any risks or harms to the participants.
Safeguarding the well-being of participants is paramount, and any study employing random assignment must adhere to established ethical guidelines and standards.
Conclusion of Methodology
The methodology of random assignment, while seemingly straightforward, is a multifaceted process that demands precision, fairness, and ethical integrity. From participant selection to assignment and monitoring, each step is crucial to ensure the validity of the study’s findings.
The tools and techniques employed, coupled with a steadfast commitment to ethical principles, underscore the significance of random assignment as a cornerstone of robust psychological research.
Benefits of Random Assignment in Psychological Research
The impact and importance of random assignment in psychological research cannot be overstated. It is fundamental for ensuring the study is accurate, allowing the researchers to determine if their study actually caused the results they saw, and making sure the findings can be applied to the real world.
Facilitating Causal Inferences
When participants are randomly assigned to different groups, researchers can be more confident that the observed effects are due to the independent variable being changed, and not other factors.
This ability to determine the cause is called causal inference .
This confidence allows for the drawing of causal relationships, which are foundational for theory development and application in psychology.
Ensuring Internal Validity
One of the foremost impacts of random assignment is its ability to enhance the internal validity of an experiment.
Internal validity refers to the extent to which a researcher can assert that changes in the dependent variable are solely due to manipulations of the independent variable , and not due to confounding variables.
By ensuring that each participant has an equal chance of being in any condition of the experiment, random assignment helps control for participant characteristics that could otherwise complicate the results.
Enhancing Generalizability
Beyond internal validity, random assignment also plays a crucial role in enhancing the generalizability of research findings.
When done correctly, it ensures that the sample groups are representative of the larger population, so can allow researchers to apply their findings more broadly.
This representative nature is essential for the practical application of research, impacting policy, interventions, and psychological therapies.
Limitations of Random Assignment
Potential for implementation issues.
While the principles of random assignment are robust, the method can face implementation issues.
One of the most common problems is logistical constraints. Some studies, due to their nature or the specific population being studied, find it challenging to implement random assignment effectively.
For instance, in educational settings, logistical issues such as class schedules and school policies might stop the random allocation of students to different teaching methods .
Ethical Dilemmas
Random assignment, while methodologically sound, can also present ethical dilemmas.
In some cases, withholding a potentially beneficial treatment from one of the groups of participants can raise serious ethical questions, especially in medical or clinical research where participants' well-being might be directly affected.
Researchers must navigate these ethical waters carefully, balancing the pursuit of knowledge with the well-being of participants.
Generalizability Concerns
Even when implemented correctly, random assignment does not always guarantee generalizable results.
The types of people in the participant pool, the specific context of the study, and the nature of the variables being studied can all influence the extent to which the findings can be applied to the broader population.
Researchers must be cautious in making broad generalizations from studies, even those employing strict random assignment.
Practical and Real-World Limitations
In the real world, many variables cannot be manipulated for ethical or practical reasons, limiting the applicability of random assignment.
For instance, researchers cannot randomly assign individuals to different levels of intelligence, socioeconomic status, or cultural backgrounds.
This limitation necessitates the use of other research designs, such as correlational or observational studies , when exploring relationships involving such variables.
Response to Critiques
In response to these critiques, people in favor of random assignment argue that the method, despite its limitations, remains one of the most reliable ways to establish cause and effect in experimental research.
They acknowledge the challenges and ethical considerations but emphasize the rigorous frameworks in place to address them.
The ongoing discussion around the limitations and critiques of random assignment contributes to the evolution of the method, making sure it is continuously relevant and applicable in psychological research.
While random assignment is a powerful tool in experimental research, it is not without its critiques and limitations. Implementation issues, ethical dilemmas, generalizability concerns, and real-world limitations can pose significant challenges.
However, the continued discourse and refinement around these issues underline the method's enduring significance in the pursuit of knowledge in psychology.
By being careful with how we do things and doing what's right, random assignment stays a really important part of studying how people act and think.
Real-World Applications and Examples

Random assignment has been employed in many studies across various fields of psychology, leading to significant discoveries and advancements.
Here are some real-world applications and examples illustrating the diversity and impact of this method:
- Medicine and Health Psychology: Randomized Controlled Trials (RCTs) are the gold standard in medical research. In these studies, participants are randomly assigned to either the treatment or control group to test the efficacy of new medications or interventions.
- Educational Psychology: Studies in this field have used random assignment to explore the effects of different teaching methods, classroom environments, and educational technologies on student learning and outcomes.
- Cognitive Psychology: Researchers have employed random assignment to investigate various aspects of human cognition, including memory, attention, and problem-solving, leading to a deeper understanding of how the mind works.
- Social Psychology: Random assignment has been instrumental in studying social phenomena, such as conformity, aggression, and prosocial behavior, shedding light on the intricate dynamics of human interaction.
Let's get into some specific examples. You'll need to know one term though, and that is "control group." A control group is a set of participants in a study who do not receive the treatment or intervention being tested , serving as a baseline to compare with the group that does, in order to assess the effectiveness of the treatment.
- Smoking Cessation Study: Researchers used random assignment to put participants into two groups. One group received a new anti-smoking program, while the other did not. This helped determine if the program was effective in helping people quit smoking.
- Math Tutoring Program: A study on students used random assignment to place them into two groups. One group received additional math tutoring, while the other continued with regular classes, to see if the extra help improved their grades.
- Exercise and Mental Health: Adults were randomly assigned to either an exercise group or a control group to study the impact of physical activity on mental health and mood.
- Diet and Weight Loss: A study randomly assigned participants to different diet plans to compare their effectiveness in promoting weight loss and improving health markers.
- Sleep and Learning: Researchers randomly assigned students to either a sleep extension group or a regular sleep group to study the impact of sleep on learning and memory.
- Classroom Seating Arrangement: Teachers used random assignment to place students in different seating arrangements to examine the effect on focus and academic performance.
- Music and Productivity: Employees were randomly assigned to listen to music or work in silence to investigate the effect of music on workplace productivity.
- Medication for ADHD: Children with ADHD were randomly assigned to receive either medication, behavioral therapy, or a placebo to compare treatment effectiveness.
- Mindfulness Meditation for Stress: Adults were randomly assigned to a mindfulness meditation group or a waitlist control group to study the impact on stress levels.
- Video Games and Aggression: A study randomly assigned participants to play either violent or non-violent video games and then measured their aggression levels.
- Online Learning Platforms: Students were randomly assigned to use different online learning platforms to evaluate their effectiveness in enhancing learning outcomes.
- Hand Sanitizers in Schools: Schools were randomly assigned to use hand sanitizers or not to study the impact on student illness and absenteeism.
- Caffeine and Alertness: Participants were randomly assigned to consume caffeinated or decaffeinated beverages to measure the effects on alertness and cognitive performance.
- Green Spaces and Well-being: Neighborhoods were randomly assigned to receive green space interventions to study the impact on residents’ well-being and community connections.
- Pet Therapy for Hospital Patients: Patients were randomly assigned to receive pet therapy or standard care to assess the impact on recovery and mood.
- Yoga for Chronic Pain: Individuals with chronic pain were randomly assigned to a yoga intervention group or a control group to study the effect on pain levels and quality of life.
- Flu Vaccines Effectiveness: Different groups of people were randomly assigned to receive either the flu vaccine or a placebo to determine the vaccine’s effectiveness.
- Reading Strategies for Dyslexia: Children with dyslexia were randomly assigned to different reading intervention strategies to compare their effectiveness.
- Physical Environment and Creativity: Participants were randomly assigned to different room setups to study the impact of physical environment on creative thinking.
- Laughter Therapy for Depression: Individuals with depression were randomly assigned to laughter therapy sessions or control groups to assess the impact on mood.
- Financial Incentives for Exercise: Participants were randomly assigned to receive financial incentives for exercising to study the impact on physical activity levels.
- Art Therapy for Anxiety: Individuals with anxiety were randomly assigned to art therapy sessions or a waitlist control group to measure the effect on anxiety levels.
- Natural Light in Offices: Employees were randomly assigned to workspaces with natural or artificial light to study the impact on productivity and job satisfaction.
- School Start Times and Academic Performance: Schools were randomly assigned different start times to study the effect on student academic performance and well-being.
- Horticulture Therapy for Seniors: Older adults were randomly assigned to participate in horticulture therapy or traditional activities to study the impact on cognitive function and life satisfaction.
- Hydration and Cognitive Function: Participants were randomly assigned to different hydration levels to measure the impact on cognitive function and alertness.
- Intergenerational Programs: Seniors and young people were randomly assigned to intergenerational programs to study the effects on well-being and cross-generational understanding.
- Therapeutic Horseback Riding for Autism: Children with autism were randomly assigned to therapeutic horseback riding or traditional therapy to study the impact on social communication skills.
- Active Commuting and Health: Employees were randomly assigned to active commuting (cycling, walking) or passive commuting to study the effect on physical health.
- Mindful Eating for Weight Management: Individuals were randomly assigned to mindful eating workshops or control groups to study the impact on weight management and eating habits.
- Noise Levels and Learning: Students were randomly assigned to classrooms with different noise levels to study the effect on learning and concentration.
- Bilingual Education Methods: Schools were randomly assigned different bilingual education methods to compare their effectiveness in language acquisition.
- Outdoor Play and Child Development: Children were randomly assigned to different amounts of outdoor playtime to study the impact on physical and cognitive development.
- Social Media Detox: Participants were randomly assigned to a social media detox or regular usage to study the impact on mental health and well-being.
- Therapeutic Writing for Trauma Survivors: Individuals who experienced trauma were randomly assigned to therapeutic writing sessions or control groups to study the impact on psychological well-being.
- Mentoring Programs for At-risk Youth: At-risk youth were randomly assigned to mentoring programs or control groups to assess the impact on academic achievement and behavior.
- Dance Therapy for Parkinson’s Disease: Individuals with Parkinson’s disease were randomly assigned to dance therapy or traditional exercise to study the effect on motor function and quality of life.
- Aquaponics in Schools: Schools were randomly assigned to implement aquaponics programs to study the impact on student engagement and environmental awareness.
- Virtual Reality for Phobia Treatment: Individuals with phobias were randomly assigned to virtual reality exposure therapy or traditional therapy to compare effectiveness.
- Gardening and Mental Health: Participants were randomly assigned to engage in gardening or other leisure activities to study the impact on mental health and stress reduction.
Each of these studies exemplifies how random assignment is utilized in various fields and settings, shedding light on the multitude of ways it can be applied to glean valuable insights and knowledge.
Real-world Impact of Random Assignment

Random assignment is like a key tool in the world of learning about people's minds and behaviors. It’s super important and helps in many different areas of our everyday lives. It helps make better rules, creates new ways to help people, and is used in lots of different fields.
Health and Medicine
In health and medicine, random assignment has helped doctors and scientists make lots of discoveries. It’s a big part of tests that help create new medicines and treatments.
By putting people into different groups by chance, scientists can really see if a medicine works.
This has led to new ways to help people with all sorts of health problems, like diabetes, heart disease, and mental health issues like depression and anxiety.
Schools and education have also learned a lot from random assignment. Researchers have used it to look at different ways of teaching, what kind of classrooms are best, and how technology can help learning.
This knowledge has helped make better school rules, develop what we learn in school, and find the best ways to teach students of all ages and backgrounds.
Workplace and Organizational Behavior
Random assignment helps us understand how people act at work and what makes a workplace good or bad.
Studies have looked at different kinds of workplaces, how bosses should act, and how teams should be put together. This has helped companies make better rules and create places to work that are helpful and make people happy.
Environmental and Social Changes
Random assignment is also used to see how changes in the community and environment affect people. Studies have looked at community projects, changes to the environment, and social programs to see how they help or hurt people’s well-being.
This has led to better community projects, efforts to protect the environment, and programs to help people in society.
Technology and Human Interaction
In our world where technology is always changing, studies with random assignment help us see how tech like social media, virtual reality, and online stuff affect how we act and feel.
This has helped make better and safer technology and rules about using it so that everyone can benefit.
The effects of random assignment go far and wide, way beyond just a science lab. It helps us understand lots of different things, leads to new and improved ways to do things, and really makes a difference in the world around us.
From making healthcare and schools better to creating positive changes in communities and the environment, the real-world impact of random assignment shows just how important it is in helping us learn and make the world a better place.
So, what have we learned? Random assignment is like a super tool in learning about how people think and act. It's like a detective helping us find clues and solve mysteries in many parts of our lives.
From creating new medicines to helping kids learn better in school, and from making workplaces happier to protecting the environment, it’s got a big job!
This method isn’t just something scientists use in labs; it reaches out and touches our everyday lives. It helps make positive changes and teaches us valuable lessons.
Whether we are talking about technology, health, education, or the environment, random assignment is there, working behind the scenes, making things better and safer for all of us.
In the end, the simple act of putting people into groups by chance helps us make big discoveries and improvements. It’s like throwing a small stone into a pond and watching the ripples spread out far and wide.
Thanks to random assignment, we are always learning, growing, and finding new ways to make our world a happier and healthier place for everyone!
Related posts:
- 19+ Experimental Design Examples (Methods + Types)
- Cluster Sampling vs Stratified Sampling
- 41+ White Collar Job Examples (Salary + Path)
- 47+ Blue Collar Job Examples (Salary + Path)
- McDonaldization of Society (Definition + Examples)
Reference this article:
About The Author
Free Personality Test

Free Memory Test

Free IQ Test

PracticalPie.com is a participant in the Amazon Associates Program. As an Amazon Associate we earn from qualifying purchases.
Follow Us On:
Youtube Facebook Instagram X/Twitter
Psychology Resources
Developmental
Personality
Relationships
Psychologists
Serial Killers
Psychology Tests
Personality Quiz
Memory Test
Depression test
Type A/B Personality Test
© PracticalPsychology. All rights reserved
Privacy Policy | Terms of Use
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Sweepstakes
- Guided Meditations
- Verywell Mind Insights
- 2024 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
The Definition of Random Assignment According to Psychology
Materio / Getty Images
Random assignment refers to the use of chance procedures in psychology experiments to ensure that each participant has the same opportunity to be assigned to any given group in a study to eliminate any potential bias in the experiment at the outset. Participants are randomly assigned to different groups, such as the treatment group versus the control group. In clinical research, randomized clinical trials are known as the gold standard for meaningful results.
Simple random assignment techniques might involve tactics such as flipping a coin, drawing names out of a hat, rolling dice, or assigning random numbers to a list of participants. It is important to note that random assignment differs from random selection .
While random selection refers to how participants are randomly chosen from a target population as representatives of that population, random assignment refers to how those chosen participants are then assigned to experimental groups.
Random Assignment In Research
To determine if changes in one variable will cause changes in another variable, psychologists must perform an experiment. Random assignment is a critical part of the experimental design that helps ensure the reliability of the study outcomes.
Researchers often begin by forming a testable hypothesis predicting that one variable of interest will have some predictable impact on another variable.
The variable that the experimenters will manipulate in the experiment is known as the independent variable , while the variable that they will then measure for different outcomes is known as the dependent variable. While there are different ways to look at relationships between variables, an experiment is the best way to get a clear idea if there is a cause-and-effect relationship between two or more variables.
Once researchers have formulated a hypothesis, conducted background research, and chosen an experimental design, it is time to find participants for their experiment. How exactly do researchers decide who will be part of an experiment? As mentioned previously, this is often accomplished through something known as random selection.
Random Selection
In order to generalize the results of an experiment to a larger group, it is important to choose a sample that is representative of the qualities found in that population. For example, if the total population is 60% female and 40% male, then the sample should reflect those same percentages.
Choosing a representative sample is often accomplished by randomly picking people from the population to be participants in a study. Random selection means that everyone in the group stands an equal chance of being chosen to minimize any bias. Once a pool of participants has been selected, it is time to assign them to groups.
By randomly assigning the participants into groups, the experimenters can be fairly sure that each group will have the same characteristics before the independent variable is applied.
Participants might be randomly assigned to the control group , which does not receive the treatment in question. The control group may receive a placebo or receive the standard treatment. Participants may also be randomly assigned to the experimental group , which receives the treatment of interest. In larger studies, there can be multiple treatment groups for comparison.
There are simple methods of random assignment, like rolling the die. However, there are more complex techniques that involve random number generators to remove any human error.
There can also be random assignment to groups with pre-established rules or parameters. For example, if you want to have an equal number of men and women in each of your study groups, you might separate your sample into two groups (by sex) before randomly assigning each of those groups into the treatment group and control group.
Random assignment is essential because it increases the likelihood that the groups are the same at the outset. With all characteristics being equal between groups, other than the application of the independent variable, any differences found between group outcomes can be more confidently attributed to the effect of the intervention.
Example of Random Assignment
Imagine that a researcher is interested in learning whether or not drinking caffeinated beverages prior to an exam will improve test performance. After randomly selecting a pool of participants, each person is randomly assigned to either the control group or the experimental group.
The participants in the control group consume a placebo drink prior to the exam that does not contain any caffeine. Those in the experimental group, on the other hand, consume a caffeinated beverage before taking the test.
Participants in both groups then take the test, and the researcher compares the results to determine if the caffeinated beverage had any impact on test performance.
A Word From Verywell
Random assignment plays an important role in the psychology research process. Not only does this process help eliminate possible sources of bias, but it also makes it easier to generalize the results of a tested sample of participants to a larger population.
Random assignment helps ensure that members of each group in the experiment are the same, which means that the groups are also likely more representative of what is present in the larger population of interest. Through the use of this technique, psychology researchers are able to study complex phenomena and contribute to our understanding of the human mind and behavior.
Lin Y, Zhu M, Su Z. The pursuit of balance: An overview of covariate-adaptive randomization techniques in clinical trials . Contemp Clin Trials. 2015;45(Pt A):21-25. doi:10.1016/j.cct.2015.07.011
Sullivan L. Random assignment versus random selection . In: The SAGE Glossary of the Social and Behavioral Sciences. SAGE Publications, Inc.; 2009. doi:10.4135/9781412972024.n2108
Alferes VR. Methods of Randomization in Experimental Design . SAGE Publications, Inc.; 2012. doi:10.4135/9781452270012
Nestor PG, Schutt RK. Research Methods in Psychology: Investigating Human Behavior. (2nd Ed.). SAGE Publications, Inc.; 2015.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
- Skip to secondary menu
- Skip to main content
- Skip to primary sidebar
Statistics By Jim
Making statistics intuitive
Random Assignment in Experiments
By Jim Frost 4 Comments
Random assignment uses chance to assign subjects to the control and treatment groups in an experiment. This process helps ensure that the groups are equivalent at the beginning of the study, which makes it safer to assume the treatments caused any differences between groups that the experimenters observe at the end of the study.

Huh? That might be a big surprise! At this point, you might be wondering about all of those studies that use statistics to assess the effects of different treatments. There’s a critical separation between significance and causality:
- Statistical procedures determine whether an effect is significant.
- Experimental designs determine how confidently you can assume that a treatment causes the effect.
In this post, learn how using random assignment in experiments can help you identify causal relationships.
Correlation, Causation, and Confounding Variables
Random assignment helps you separate causation from correlation and rule out confounding variables. As a critical component of the scientific method , experiments typically set up contrasts between a control group and one or more treatment groups. The idea is to determine whether the effect, which is the difference between a treatment group and the control group, is statistically significant. If the effect is significant, group assignment correlates with different outcomes.
However, as you have no doubt heard, correlation does not necessarily imply causation. In other words, the experimental groups can have different mean outcomes, but the treatment might not be causing those differences even though the differences are statistically significant.
The difficulty in definitively stating that a treatment caused the difference is due to potential confounding variables or confounders. Confounders are alternative explanations for differences between the experimental groups. Confounding variables correlate with both the experimental groups and the outcome variable. In this situation, confounding variables can be the actual cause for the outcome differences rather than the treatments themselves. As you’ll see, if an experiment does not account for confounding variables, they can bias the results and make them untrustworthy.
Related posts : Understanding Correlation in Statistics , Causation versus Correlation , and Hill’s Criteria for Causation .
Example of Confounding in an Experiment

- Control group: Does not consume vitamin supplements
- Treatment group: Regularly consumes vitamin supplements.
Imagine we measure a specific health outcome. After the experiment is complete, we perform a 2-sample t-test to determine whether the mean outcomes for these two groups are different. Assume the test results indicate that the mean health outcome in the treatment group is significantly better than the control group.
Why can’t we assume that the vitamins improved the health outcomes? After all, only the treatment group took the vitamins.
Related post : Confounding Variables in Regression Analysis
Alternative Explanations for Differences in Outcomes
The answer to that question depends on how we assigned the subjects to the experimental groups. If we let the subjects decide which group to join based on their existing vitamin habits, it opens the door to confounding variables. It’s reasonable to assume that people who take vitamins regularly also tend to have other healthy habits. These habits are confounders because they correlate with both vitamin consumption (experimental group) and the health outcome measure.
Random assignment prevents this self sorting of participants and reduces the likelihood that the groups start with systematic differences.
In fact, studies have found that supplement users are more physically active, have healthier diets, have lower blood pressure, and so on compared to those who don’t take supplements. If subjects who already take vitamins regularly join the treatment group voluntarily, they bring these healthy habits disproportionately to the treatment group. Consequently, these habits will be much more prevalent in the treatment group than the control group.
The healthy habits are the confounding variables—the potential alternative explanations for the difference in our study’s health outcome. It’s entirely possible that these systematic differences between groups at the start of the study might cause the difference in the health outcome at the end of the study—and not the vitamin consumption itself!
If our experiment doesn’t account for these confounding variables, we can’t trust the results. While we obtained statistically significant results with the 2-sample t-test for health outcomes, we don’t know for sure whether the vitamins, the systematic difference in habits, or some combination of the two caused the improvements.
Learn why many randomized clinical experiments use a placebo to control for the Placebo Effect .
Experiments Must Account for Confounding Variables
Your experimental design must account for confounding variables to avoid their problems. Scientific studies commonly use the following methods to handle confounders:
- Use control variables to keep them constant throughout an experiment.
- Statistically control for them in an observational study.
- Use random assignment to reduce the likelihood that systematic differences exist between experimental groups when the study begins.
Let’s take a look at how random assignment works in an experimental design.
Random Assignment Can Reduce the Impact of Confounding Variables
Note that random assignment is different than random sampling. Random sampling is a process for obtaining a sample that accurately represents a population .

Random assignment uses a chance process to assign subjects to experimental groups. Using random assignment requires that the experimenters can control the group assignment for all study subjects. For our study, we must be able to assign our participants to either the control group or the supplement group. Clearly, if we don’t have the ability to assign subjects to the groups, we can’t use random assignment!
Additionally, the process must have an equal probability of assigning a subject to any of the groups. For example, in our vitamin supplement study, we can use a coin toss to assign each subject to either the control group or supplement group. For more complex experimental designs, we can use a random number generator or even draw names out of a hat.
Random Assignment Distributes Confounders Equally
The random assignment process distributes confounding properties amongst your experimental groups equally. In other words, randomness helps eliminate systematic differences between groups. For our study, flipping the coin tends to equalize the distribution of subjects with healthier habits between the control and treatment group. Consequently, these two groups should start roughly equal for all confounding variables, including healthy habits!
Random assignment is a simple, elegant solution to a complex problem. For any given study area, there can be a long list of confounding variables that you could worry about. However, using random assignment, you don’t need to know what they are, how to detect them, or even measure them. Instead, use random assignment to equalize them across your experimental groups so they’re not a problem.
Because random assignment helps ensure that the groups are comparable when the experiment begins, you can be more confident that the treatments caused the post-study differences. Random assignment helps increase the internal validity of your study.
Comparing the Vitamin Study With and Without Random Assignment
Let’s compare two scenarios involving our hypothetical vitamin study. We’ll assume that the study obtains statistically significant results in both cases.
Scenario 1: We don’t use random assignment and, unbeknownst to us, subjects with healthier habits disproportionately end up in the supplement treatment group. The experimental groups differ by both healthy habits and vitamin consumption. Consequently, we can’t determine whether it was the habits or vitamins that improved the outcomes.
Scenario 2: We use random assignment and, consequently, the treatment and control groups start with roughly equal levels of healthy habits. The intentional introduction of vitamin supplements in the treatment group is the primary difference between the groups. Consequently, we can more confidently assert that the supplements caused an improvement in health outcomes.
For both scenarios, the statistical results could be identical. However, the methodology behind the second scenario makes a stronger case for a causal relationship between vitamin supplement consumption and health outcomes.
How important is it to use the correct methodology? Well, if the relationship between vitamins and health outcomes is not causal, then consuming vitamins won’t cause your health outcomes to improve regardless of what the study indicates. Instead, it’s probably all the other healthy habits!
Learn more about Randomized Controlled Trials (RCTs) that are the gold standard for identifying causal relationships because they use random assignment.
Drawbacks of Random Assignment
Random assignment helps reduce the chances of systematic differences between the groups at the start of an experiment and, thereby, mitigates the threats of confounding variables and alternative explanations. However, the process does not always equalize all of the confounding variables. Its random nature tends to eliminate systematic differences, but it doesn’t always succeed.
Sometimes random assignment is impossible because the experimenters cannot control the treatment or independent variable. For example, if you want to determine how individuals with and without depression perform on a test, you cannot randomly assign subjects to these groups. The same difficulty occurs when you’re studying differences between genders.
In other cases, there might be ethical issues. For example, in a randomized experiment, the researchers would want to withhold treatment for the control group. However, if the treatments are vaccinations, it might be unethical to withhold the vaccinations.
Other times, random assignment might be possible, but it is very challenging. For example, with vitamin consumption, it’s generally thought that if vitamin supplements cause health improvements, it’s only after very long-term use. It’s hard to enforce random assignment with a strict regimen for usage in one group and non-usage in the other group over the long-run. Or imagine a study about smoking. The researchers would find it difficult to assign subjects to the smoking and non-smoking groups randomly!
Fortunately, if you can’t use random assignment to help reduce the problem of confounding variables, there are different methods available. The other primary approach is to perform an observational study and incorporate the confounders into the statistical model itself. For more information, read my post Observational Studies Explained .
Read About Real Experiments that Used Random Assignment
I’ve written several blog posts about studies that have used random assignment to make causal inferences. Read studies about the following:
- Flu Vaccinations
- COVID-19 Vaccinations
Sullivan L. Random assignment versus random selection . SAGE Glossary of the Social and Behavioral Sciences, SAGE Publications, Inc.; 2009.
Share this:

Reader Interactions

November 13, 2019 at 4:59 am
Hi Jim, I have a question of randomly assigning participants to one of two conditions when it is an ongoing study and you are not sure of how many participants there will be. I am using this random assignment tool for factorial experiments. http://methodologymedia.psu.edu/most/rannumgenerator It asks you for the total number of participants but at this point, I am not sure how many there will be. Thanks for any advice you can give me, Floyd

May 28, 2019 at 11:34 am
Jim, can you comment on the validity of using the following approach when we can’t use random assignments. I’m in education, we have an ACT prep course that we offer. We can’t force students to take it and we can’t keep them from taking it either. But we want to know if it’s working. Let’s say that by senior year all students who are going to take the ACT have taken it. Let’s also say that I’m only including students who have taking it twice (so I can show growth between first and second time taking it). What I’ve done to address confounders is to go back to say 8th or 9th grade (prior to anyone taking the ACT or the ACT prep course) and run an analysis showing the two groups are not significantly different to start with. Is this valid? If the ACT prep students were higher achievers in 8th or 9th grade, I could not assume my prep course is effecting greater growth, but if they were not significantly different in 8th or 9th grade, I can assume the significant difference in ACT growth (from first to second testing) is due to the prep course. Yes or no?

May 26, 2019 at 5:37 pm
Nice post! I think the key to understanding scientific research is to understand randomization. And most people don’t get it.

May 27, 2019 at 9:48 pm
Thank you, Anoop!
I think randomness in an experiment is a funny thing. The issue of confounding factors is a serious problem. You might not even know what they are! But, use random assignment and, voila, the problem usually goes away! If you can’t use random assignment, suddenly you have a whole host of issues to worry about, which I’ll be writing about in more detail in my upcoming post about observational experiments!
Comments and Questions Cancel reply
What Is Random Assignment in Psychology?
Categories Research Methods
Random assignment means that every participant has the same chance of being chosen for the experimental or control group. It involves using procedures that rely on chance to assign participants to groups. Doing this means that every participant in a study has an equal opportunity to be assigned to any group.
For example, in a psychology experiment, participants might be assigned to either a control or experimental group. Some experiments might only have one experimental group, while others may have several treatment variations.
Using random assignment means that each participant has the same chance of being assigned to any of these groups.
Table of Contents
How to Use Random Assignment
So what type of procedures might psychologists utilize for random assignment? Strategies can include:
- Flipping a coin
- Assigning random numbers
- Rolling dice
- Drawing names out of a hat
How Does Random Assignment Work?
A psychology experiment aims to determine if changes in one variable lead to changes in another variable. Researchers will first begin by coming up with a hypothesis. Once researchers have an idea of what they think they might find in a population, they will come up with an experimental design and then recruit participants for their study.
Once they have a pool of participants representative of the population they are interested in looking at, they will randomly assign the participants to their groups.
- Control group : Some participants will end up in the control group, which serves as a baseline and does not receive the independent variables.
- Experimental group : Other participants will end up in the experimental groups that receive some form of the independent variables.
By using random assignment, the researchers make it more likely that the groups are equal at the start of the experiment. Since the groups are the same on other variables, it can be assumed that any changes that occur are the result of varying the independent variables.
After a treatment has been administered, the researchers will then collect data in order to determine if the independent variable had any impact on the dependent variable.
Random Assignment vs. Random Selection
It is important to remember that random assignment is not the same thing as random selection , also known as random sampling.
Random selection instead involves how people are chosen to be in a study. Using random selection, every member of a population stands an equal chance of being chosen for a study or experiment.
So random sampling affects how participants are chosen for a study, while random assignment affects how participants are then assigned to groups.
Examples of Random Assignment
Imagine that a psychology researcher is conducting an experiment to determine if getting adequate sleep the night before an exam results in better test scores.
Forming a Hypothesis
They hypothesize that participants who get 8 hours of sleep will do better on a math exam than participants who only get 4 hours of sleep.
Obtaining Participants
The researcher starts by obtaining a pool of participants. They find 100 participants from a local university. Half of the participants are female, and half are male.
Randomly Assign Participants to Groups
The researcher then assigns random numbers to each participant and uses a random number generator to randomly assign each number to either the 4-hour or 8-hour sleep groups.
Conduct the Experiment
Those in the 8-hour sleep group agree to sleep for 8 hours that night, while those in the 4-hour group agree to wake up after only 4 hours. The following day, all of the participants meet in a classroom.
Collect and Analyze Data
Everyone takes the same math test. The test scores are then compared to see if the amount of sleep the night before had any impact on test scores.
Why Is Random Assignment Important in Psychology Research?
Random assignment is important in psychology research because it helps improve a study’s internal validity. This means that the researchers are sure that the study demonstrates a cause-and-effect relationship between an independent and dependent variable.
Random assignment improves the internal validity by minimizing the risk that there are systematic differences in the participants who are in each group.
Key Points to Remember About Random Assignment
- Random assignment in psychology involves each participant having an equal chance of being chosen for any of the groups, including the control and experimental groups.
- It helps control for potential confounding variables, reducing the likelihood of pre-existing differences between groups.
- This method enhances the internal validity of experiments, allowing researchers to draw more reliable conclusions about cause-and-effect relationships.
- Random assignment is crucial for creating comparable groups and increasing the scientific rigor of psychological studies.
| Elements of Research | ||||||||||||||||||||||||||||||||||||||||||||||
Random Assignment

77 Accesses Random assignment defines the assignment of participants of a study to their respective group strictly by chance. IntroductionStatistical inference is based on the theory of probability, and effects investigated in psychological studies are defined by measures that are treated as random variables. The inference about the probability of a given result with regard to an assumed population and the popular term “significance” are only meaningful and without bias if the measure of interest is really a random variable. To achieve the creation of a random variable in form of a measure derived from a sample of participants, these participants have to be randomly drawn. In an experimental study involving different groups of participants, these participants have to additionally be randomly assigned to one of the groups. Why Is Random Assignment Crucial for Statistical Inference?Many psychological investigations, such as clinical treatment studies or neuropsychological training... This is a preview of subscription content, log in via an institution to check access. Access this chapterInstitutional subscriptions Gigerenzer, G., Swijtink, Z., Porter, T., Daston, L., Beatty, J., & Kruger, L. (1989). The empire of chance: How probability changed science and everyday-life . Cambridge: New York. Google Scholar Download references Author informationAuthors and affiliations. Psychology Department, LMU Munich, Munich, Germany Sven Hilbert You can also search for this author in PubMed Google Scholar Corresponding authorCorrespondence to Sven Hilbert . Editor informationEditors and affiliations. Oakland University, Rochester, USA Virgil Zeigler-Hill Todd K. Shackelford Section Editor informationHumboldt University, Germany, Berlin, Germany Matthias Ziegler Rights and permissionsReprints and permissions Copyright information© 2017 Springer International Publishing AG About this entryCite this entry. Hilbert, S. (2017). Random Assignment. In: Zeigler-Hill, V., Shackelford, T. (eds) Encyclopedia of Personality and Individual Differences. Springer, Cham. https://doi.org/10.1007/978-3-319-28099-8_1343-1 Download citationDOI : https://doi.org/10.1007/978-3-319-28099-8_1343-1 Received : 29 August 2016 Accepted : 06 January 2017 Published : 25 January 2017 Publisher Name : Springer, Cham Print ISBN : 978-3-319-28099-8 Online ISBN : 978-3-319-28099-8 eBook Packages : Springer Reference Behavioral Science and Psychology Reference Module Humanities and Social Sciences Reference Module Business, Economics and Social Sciences
Policies and ethics
5.2 Experimental DesignLearning objectives.
In this section, we look at some different ways to design an experiment. The primary distinction we will make is between approaches in which each participant experiences one level of the independent variable and approaches in which each participant experiences all levels of the independent variable. The former are called between-subjects experiments and the latter are called within-subjects experiments. Between-Subjects ExperimentsIn a between-subjects experiment , each participant is tested in only one condition. For example, a researcher with a sample of 100 university students might assign half of them to write about a traumatic event and the other half write about a neutral event. Or a researcher with a sample of 60 people with severe agoraphobia (fear of open spaces) might assign 20 of them to receive each of three different treatments for that disorder. It is essential in a between-subjects experiment that the researcher assigns participants to conditions so that the different groups are, on average, highly similar to each other. Those in a trauma condition and a neutral condition, for example, should include a similar proportion of men and women, and they should have similar average intelligence quotients (IQs), similar average levels of motivation, similar average numbers of health problems, and so on. This matching is a matter of controlling these extraneous participant variables across conditions so that they do not become confounding variables. Random AssignmentThe primary way that researchers accomplish this kind of control of extraneous variables across conditions is called random assignment , which means using a random process to decide which participants are tested in which conditions. Do not confuse random assignment with random sampling. Random sampling is a method for selecting a sample from a population, and it is rarely used in psychological research. Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other fields too. In its strictest sense, random assignment should meet two criteria. One is that each participant has an equal chance of being assigned to each condition (e.g., a 50% chance of being assigned to each of two conditions). The second is that each participant is assigned to a condition independently of other participants. Thus one way to assign participants to two conditions would be to flip a coin for each one. If the coin lands heads, the participant is assigned to Condition A, and if it lands tails, the participant is assigned to Condition B. For three conditions, one could use a computer to generate a random integer from 1 to 3 for each participant. If the integer is 1, the participant is assigned to Condition A; if it is 2, the participant is assigned to Condition B; and if it is 3, the participant is assigned to Condition C. In practice, a full sequence of conditions—one for each participant expected to be in the experiment—is usually created ahead of time, and each new participant is assigned to the next condition in the sequence as he or she is tested. When the procedure is computerized, the computer program often handles the random assignment. One problem with coin flipping and other strict procedures for random assignment is that they are likely to result in unequal sample sizes in the different conditions. Unequal sample sizes are generally not a serious problem, and you should never throw away data you have already collected to achieve equal sample sizes. However, for a fixed number of participants, it is statistically most efficient to divide them into equal-sized groups. It is standard practice, therefore, to use a kind of modified random assignment that keeps the number of participants in each group as similar as possible. One approach is block randomization . In block randomization, all the conditions occur once in the sequence before any of them is repeated. Then they all occur again before any of them is repeated again. Within each of these “blocks,” the conditions occur in a random order. Again, the sequence of conditions is usually generated before any participants are tested, and each new participant is assigned to the next condition in the sequence. Table 5.2 shows such a sequence for assigning nine participants to three conditions. The Research Randomizer website ( http://www.randomizer.org ) will generate block randomization sequences for any number of participants and conditions. Again, when the procedure is computerized, the computer program often handles the block randomization.
Random assignment is not guaranteed to control all extraneous variables across conditions. The process is random, so it is always possible that just by chance, the participants in one condition might turn out to be substantially older, less tired, more motivated, or less depressed on average than the participants in another condition. However, there are some reasons that this possibility is not a major concern. One is that random assignment works better than one might expect, especially for large samples. Another is that the inferential statistics that researchers use to decide whether a difference between groups reflects a difference in the population takes the “fallibility” of random assignment into account. Yet another reason is that even if random assignment does result in a confounding variable and therefore produces misleading results, this confound is likely to be detected when the experiment is replicated. The upshot is that random assignment to conditions—although not infallible in terms of controlling extraneous variables—is always considered a strength of a research design. Matched GroupsAn alternative to simple random assignment of participants to conditions is the use of a matched-groups design . Using this design, participants in the various conditions are matched on the dependent variable or on some extraneous variable(s) prior the manipulation of the independent variable. This guarantees that these variables will not be confounded across the experimental conditions. For instance, if we want to determine whether expressive writing affects people’s health then we could start by measuring various health-related variables in our prospective research participants. We could then use that information to rank-order participants according to how healthy or unhealthy they are. Next, the two healthiest participants would be randomly assigned to complete different conditions (one would be randomly assigned to the traumatic experiences writing condition and the other to the neutral writing condition). The next two healthiest participants would then be randomly assigned to complete different conditions, and so on until the two least healthy participants. This method would ensure that participants in the traumatic experiences writing condition are matched to participants in the neutral writing condition with respect to health at the beginning of the study. If at the end of the experiment, a difference in health was detected across the two conditions, then we would know that it is due to the writing manipulation and not to pre-existing differences in health. Within-Subjects ExperimentsIn a within-subjects experiment , each participant is tested under all conditions. Consider an experiment on the effect of a defendant’s physical attractiveness on judgments of his guilt. Again, in a between-subjects experiment, one group of participants would be shown an attractive defendant and asked to judge his guilt, and another group of participants would be shown an unattractive defendant and asked to judge his guilt. In a within-subjects experiment, however, the same group of participants would judge the guilt of both an attractive and an unattractive defendant. The primary advantage of this approach is that it provides maximum control of extraneous participant variables. Participants in all conditions have the same mean IQ, same socioeconomic status, same number of siblings, and so on—because they are the very same people. Within-subjects experiments also make it possible to use statistical procedures that remove the effect of these extraneous participant variables on the dependent variable and therefore make the data less “noisy” and the effect of the independent variable easier to detect. We will look more closely at this idea later in the book . However, not all experiments can use a within-subjects design nor would it be desirable to do so. One disadvantage of within-subjects experiments is that they make it easier for participants to guess the hypothesis. For example, a participant who is asked to judge the guilt of an attractive defendant and then is asked to judge the guilt of an unattractive defendant is likely to guess that the hypothesis is that defendant attractiveness affects judgments of guilt. This knowledge could lead the participant to judge the unattractive defendant more harshly because he thinks this is what he is expected to do. Or it could make participants judge the two defendants similarly in an effort to be “fair.” Carryover Effects and CounterbalancingThe primary disadvantage of within-subjects designs is that they can result in order effects. An order effect occurs when participants’ responses in the various conditions are affected by the order of conditions to which they were exposed. One type of order effect is a carryover effect. A carryover effect is an effect of being tested in one condition on participants’ behavior in later conditions. One type of carryover effect is a practice effect , where participants perform a task better in later conditions because they have had a chance to practice it. Another type is a fatigue effect , where participants perform a task worse in later conditions because they become tired or bored. Being tested in one condition can also change how participants perceive stimuli or interpret their task in later conditions. This type of effect is called a context effect (or contrast effect) . For example, an average-looking defendant might be judged more harshly when participants have just judged an attractive defendant than when they have just judged an unattractive defendant. Within-subjects experiments also make it easier for participants to guess the hypothesis. For example, a participant who is asked to judge the guilt of an attractive defendant and then is asked to judge the guilt of an unattractive defendant is likely to guess that the hypothesis is that defendant attractiveness affects judgments of guilt. Carryover effects can be interesting in their own right. (Does the attractiveness of one person depend on the attractiveness of other people that we have seen recently?) But when they are not the focus of the research, carryover effects can be problematic. Imagine, for example, that participants judge the guilt of an attractive defendant and then judge the guilt of an unattractive defendant. If they judge the unattractive defendant more harshly, this might be because of his unattractiveness. But it could be instead that they judge him more harshly because they are becoming bored or tired. In other words, the order of the conditions is a confounding variable. The attractive condition is always the first condition and the unattractive condition the second. Thus any difference between the conditions in terms of the dependent variable could be caused by the order of the conditions and not the independent variable itself. There is a solution to the problem of order effects, however, that can be used in many situations. It is counterbalancing , which means testing different participants in different orders. The best method of counterbalancing is complete counterbalancing in which an equal number of participants complete each possible order of conditions. For example, half of the participants would be tested in the attractive defendant condition followed by the unattractive defendant condition, and others half would be tested in the unattractive condition followed by the attractive condition. With three conditions, there would be six different orders (ABC, ACB, BAC, BCA, CAB, and CBA), so some participants would be tested in each of the six orders. With four conditions, there would be 24 different orders; with five conditions there would be 120 possible orders. With counterbalancing, participants are assigned to orders randomly, using the techniques we have already discussed. Thus, random assignment plays an important role in within-subjects designs just as in between-subjects designs. Here, instead of randomly assigning to conditions, they are randomly assigned to different orders of conditions. In fact, it can safely be said that if a study does not involve random assignment in one form or another, it is not an experiment. A more efficient way of counterbalancing is through a Latin square design which randomizes through having equal rows and columns. For example, if you have four treatments, you must have four versions. Like a Sudoku puzzle, no treatment can repeat in a row or column. For four versions of four treatments, the Latin square design would look like:
You can see in the diagram above that the square has been constructed to ensure that each condition appears at each ordinal position (A appears first once, second once, third once, and fourth once) and each condition preceded and follows each other condition one time. A Latin square for an experiment with 6 conditions would by 6 x 6 in dimension, one for an experiment with 8 conditions would be 8 x 8 in dimension, and so on. So while complete counterbalancing of 6 conditions would require 720 orders, a Latin square would only require 6 orders. Finally, when the number of conditions is large experiments can use random counterbalancing in which the order of the conditions is randomly determined for each participant. Using this technique every possible order of conditions is determined and then one of these orders is randomly selected for each participant. This is not as powerful a technique as complete counterbalancing or partial counterbalancing using a Latin squares design. Use of random counterbalancing will result in more random error, but if order effects are likely to be small and the number of conditions is large, this is an option available to researchers. There are two ways to think about what counterbalancing accomplishes. One is that it controls the order of conditions so that it is no longer a confounding variable. Instead of the attractive condition always being first and the unattractive condition always being second, the attractive condition comes first for some participants and second for others. Likewise, the unattractive condition comes first for some participants and second for others. Thus any overall difference in the dependent variable between the two conditions cannot have been caused by the order of conditions. A second way to think about what counterbalancing accomplishes is that if there are carryover effects, it makes it possible to detect them. One can analyze the data separately for each order to see whether it had an effect. When 9 Is “Larger” Than 221Researcher Michael Birnbaum has argued that the lack of context provided by between-subjects designs is often a bigger problem than the context effects created by within-subjects designs. To demonstrate this problem, he asked participants to rate two numbers on how large they were on a scale of 1-to-10 where 1 was “very very small” and 10 was “very very large”. One group of participants were asked to rate the number 9 and another group was asked to rate the number 221 (Birnbaum, 1999) [1] . Participants in this between-subjects design gave the number 9 a mean rating of 5.13 and the number 221 a mean rating of 3.10. In other words, they rated 9 as larger than 221! According to Birnbaum, this difference is because participants spontaneously compared 9 with other one-digit numbers (in which case it is relatively large) and compared 221 with other three-digit numbers (in which case it is relatively small). Simultaneous Within-Subjects DesignsSo far, we have discussed an approach to within-subjects designs in which participants are tested in one condition at a time. There is another approach, however, that is often used when participants make multiple responses in each condition. Imagine, for example, that participants judge the guilt of 10 attractive defendants and 10 unattractive defendants. Instead of having people make judgments about all 10 defendants of one type followed by all 10 defendants of the other type, the researcher could present all 20 defendants in a sequence that mixed the two types. The researcher could then compute each participant’s mean rating for each type of defendant. Or imagine an experiment designed to see whether people with social anxiety disorder remember negative adjectives (e.g., “stupid,” “incompetent”) better than positive ones (e.g., “happy,” “productive”). The researcher could have participants study a single list that includes both kinds of words and then have them try to recall as many words as possible. The researcher could then count the number of each type of word that was recalled. Between-Subjects or Within-Subjects?Almost every experiment can be conducted using either a between-subjects design or a within-subjects design. This possibility means that researchers must choose between the two approaches based on their relative merits for the particular situation. Between-subjects experiments have the advantage of being conceptually simpler and requiring less testing time per participant. They also avoid carryover effects without the need for counterbalancing. Within-subjects experiments have the advantage of controlling extraneous participant variables, which generally reduces noise in the data and makes it easier to detect a relationship between the independent and dependent variables. A good rule of thumb, then, is that if it is possible to conduct a within-subjects experiment (with proper counterbalancing) in the time that is available per participant—and you have no serious concerns about carryover effects—this design is probably the best option. If a within-subjects design would be difficult or impossible to carry out, then you should consider a between-subjects design instead. For example, if you were testing participants in a doctor’s waiting room or shoppers in line at a grocery store, you might not have enough time to test each participant in all conditions and therefore would opt for a between-subjects design. Or imagine you were trying to reduce people’s level of prejudice by having them interact with someone of another race. A within-subjects design with counterbalancing would require testing some participants in the treatment condition first and then in a control condition. But if the treatment works and reduces people’s level of prejudice, then they would no longer be suitable for testing in the control condition. This difficulty is true for many designs that involve a treatment meant to produce long-term change in participants’ behavior (e.g., studies testing the effectiveness of psychotherapy). Clearly, a between-subjects design would be necessary here. Remember also that using one type of design does not preclude using the other type in a different study. There is no reason that a researcher could not use both a between-subjects design and a within-subjects design to answer the same research question. In fact, professional researchers often take exactly this type of mixed methods approach. Key Takeaways
 Share This Book
Randomization: Sample, Assignment and SequenceRandomizing key steps during experimentation for unbiased results. Andrew Kaldas Towards Data Science Aside from controlling variables , randomization is likely the most forgotten, most important, and easiest to implement concept related to experimentation. People have a hard time predicting or emulating random events. This is part of the reason that games such as poker, dice or the ancient game of throwing astragali¹ have been so popular throughout human history. These games are appealing in part because of their reliance on unfolding random occurrences. The games are not entirely random but are randomized in key ways to make gameplay unpredictable. Similarly, experimenters may find themselves running randomized experiments that are not entirely random — for better or worse. Simple precautions can ensure an experiment is effectively randomized. In scenarios where you know your participants ahead of time, such as in an email messaging experiment, you can enter your participants — by name, ID or email address — into an excel data table and assign a random number between 0 and 1 to each participant. If you’re interested in testing a new version of an email message, you can compare the new and old message variants against each other using two groups — participants with randomly generated numbers below the median and those above (or equal to) the median. By randomly sending one email, either the new or old variant, to each group above or below the median, you are able to counterbalance most confounding and covarying factors across experimental groups. This random assignment of participants to experimental (and control) groups is useful in controlling for unknown, unobservable and random variables. For example, relating back to our bartending scenario , imagine your friends come over for a second night of drinking. How do you serve them to best learn which one of four drinks reigns supreme? Intuition may be to serve four drinks to each of your friends. And for some instances, such as throwing a party, this may be appropriate. But there are costs associated with this approach. Besides being monetarily costly, order of exposure may affect response data. Some drinks are better by the second round, and who knows how your response data will look after four rounds of drinks. The kind of experimental design where stimuli are evaluated in succession by the same respondent is referred to as a sequential monadic design. These kinds of experiments or surveys generally do not require as many participants and can reduce costs when increasing the number of participants is more costly than increasing the number of stimuli each participant experiences. However, as mentioned before, this design may introduce order bias and generally increases the time requirement for each participant, which may affect the quality of response data, as in our party scenario. To address order bias resulting from participants’ exposure to previous stimuli during the course of the experiment, it’s generally a good idea to randomize sequences including questions in a survey or stimuli in experimental blocks. The order of blocks of questions or stimuli should also be randomized if possible. Sometimes there is a logical flow, as is often the case in surveys, and complete randomization would impair comprehension of the survey. When designing an experiment or survey, considerations can be made on whether certain questions, stimuli or blocks can be randomized without detracting from the user experience. By randomizing stimuli or block sequence, not only is order bias mitigated but also experimenters are able to randomly assign participants to experience a subset of stimuli in a random order. This approach is also referred to as a sequential monadic design. For our bartending example, this could mean providing houseguests with two drinks randomly — likely to yield higher quality data and may also contribute to a less rowdy party atmosphere. However, to produce a comparable amount of data related to each drink, this method of providing houseguests with two out of four drinks at random will require about twice as many guests.² A third approach would be to provide your houseguests one drink each. This is referred to as a monadic design. Here, all participants or a subset of participants are exposed to a single concept or experimental stimuli of a certain type. Notably, although each houseguest may provide data around only a single drink, multiple questions regarding that drink may be asked. Similarly, although participants may be exposed to only a single concept in a monadic survey design, surveyors may ask multiple questions regarding that concept. Further, you are able to make comparisons between responses across concepts if respondents are representative of the same target population. So your friends are coming over for another night of drinks, and you can comfortably serve them whichever amount of drinks they prefer. What’s the problem? Well, although this setup is probably about right for hosting guests generally, for the purposes of your experiment to uncover the Drink of the Gods, you’re going to have to do better. The remaining problem relates to participant sampling. Briefly, the goal of sampling is to select a representative group or sample from the target population under study. If the target population is your drinking friends — since this is the relevant reference network containing people whose opinions matter most to you, at least regarding your mystery cocktail — then your sample should be representative of your drinking friends. Experimenting in this context may entail 1) messaging all your drinking friends and inviting them over or 2) representatively sampling by randomly choosing a subset of your drinking friends to invite over. If you have too many friends to make drinks for everyone, you could break out the astragali or dice and randomize participant sampling that way — it would be a random approach. More easily, you could rely on Excel randomly generated numbers similarly to the process for randomizing assignment in an email experiment. Still, it is important not to conduct your drinking experiment with only the friends who initially or first respond to your text message — this is convenience sampling where your sample is drawn from individuals that are easiest to reach and thus inherently not random. For example, if you are randomly selected to participate in the U.S. Census but fail to respond, the Census Bureau follows up with you in order to collect the maximum number of responses from their intended sample to maintain representativeness with the target population being the population of the United States. At the expense of breaking the cardinal rule, the rules here are slightly reminiscent of those in Fight Club — everyone fights.³ Anybody included in your sample or target population of drinking friends should be able to drink if assigned to an experimental drinking condition.⁴ Conversely, any of your drinking friends must also be willing to forego drinking in the event they are randomly assigned to a baseline (sober) control condition. Otherwise, uneven participation may introduce selection bias, e.g., imagine if only your friends preferring lemon agreed to drink lemon cocktails — you could misinterpret results indicating that lemon was the highest rated based on the biased selection of participants recruited for and completing the experiment. So, equipped with knowledge around randomization, you’re prepared to conduct experiments on your email contacts and friends or at least host a very random party. [1]: Mlodinow, L. (2009). The drunkard’s walk: how randomness rules our lives . People have been interested with randomization and decision making under uncertain probabilities since before the theory of probability. For thousands of years the Ancient Greeks both made decisions and gambled by throwing astragalus bones or astragali, similar to modern dice, and largely believed the outcome to be a result of divine intervention. The Roman statesman Cicero attributed the outcome of astragli throws to luck rather than divine intervention and thus propelled the examination of randomness through his coining of the term probabilis, the forerunner to modern probability. [2]: Not quite twice as many houseguest participants are required. The control group — never exposed to any drinks — is not required to increase in size to maintain equivalent statistical power. [3]: Palahniuk, C. (2005). Fight club . The final rule of Fight Club is actually, “if this is your first night at fight club, you have to fight.” In our party example, it’s everyone’s second night, but it’s still important that participants are capable of participating in the conditions to which they are randomly assigned. [4]: Technically that’s not true. Often in medical research studies such as in epidemiology, statistical analyses can be performed based on intention-to-treat, meaning whether or not doctors intended to treat patients regardless of patients’ adherence to their treatment regimen. This approach works although decreases observable effect sizes, meaning larger participant sample sizes may be required to detect meaningful differences across conditions.  Written by Andrew KaldasI'm a researcher. I'm motivated by learning how things work, and sometimes the insights help make things work better. Text to speech 15 Random Assignment Examples Chris Drew (PhD) Dr. Chris Drew is the founder of the Helpful Professor. He holds a PhD in education and has published over 20 articles in scholarly journals. He is the former editor of the Journal of Learning Development in Higher Education. [Image Descriptor: Photo of Chris] Learn about our Editorial Process  In research, random assignment refers to the process of randomly assigning research participants into groups (conditions) in order to minimize the influence of confounding variables or extraneous factors . Ideally, through randomization, each research participant has an equal chance of ending up in either the control or treatment condition group. For example, consider the following two groups under analysis. Under a model such as self-selection or snowball sampling, there may be a chance that the reds cluster themselves into one group (The reason for this would likely be that there is a confounding variable that the researchers have not controlled for):  To maximize the chances that the reds will be evenly split between groups, we could employ a random assignment method, which might produce the following more balanced outcome:  This process is considered a gold standard for experimental research and is generally expected of major studies that explore the effects of independent variables on dependent variables . However, random assignment is not without its flaws – chief among them being the importance of a sufficiently sized sample which will allow for randomization to tend toward a mean (take, for example, the odds of 50/50 heads and tail after 100 coin flips being higher than 1/1 heads and tail after 2 coin flips). In fact, even in the above example where I randomized the colors, you can see that there are twice as many yellows in the treatment condition than the control condition, likely because of the low number of research participants. Methods for Random Assignment of ParticipantsRandomly assigning research participants into controls is relatively easy. However, there is a range of ways to go about it, and each method has its own pros and cons. For example, there are some strategies – like the matched-pair method – that can help you to control for confounds in interesting ways. Here are some of the most common methods of random assignment, with explanations of when you might want to use each one: 1. Simple Random Assignment This is the most basic form of random assignment. All participants are pooled together and then divided randomly into groups using an equivalent chance process such as flipping a coin, drawing names from a hat, or using a random number generator. This method is straightforward and ensures each participant has an equal chance of being assigned to any group (Jamison, 2019; Nestor & Schutt, 2018). 2. Block Randomization In this method, the researcher divides the participants into “blocks” or batches of a pre-determined size, which is then randomized (Alferes, 2012). This technique ensures that the researcher will have evenly sized groups by the end of the randomization process. It’s especially useful in clinical trials where balanced and similar-sized groups are vital. 3. Stratified Random Assignment In stratified random assignment, the researcher categorizes the participants based on key characteristics (such as gender, age, ethnicity) before the random allocation process begins. Each stratum is then subjected to simple random assignment. This method is beneficial when the researcher aims to ensure that the groups are balanced with regard to certain characteristics or variables (Rosenberger & Lachin, 2015). 4. Cluster Random Assignment Here, pre-existing groups or clusters, such as schools, households, or communities, are randomly assigned to different conditions of a research study. It’s ideal when individual random assignment is not feasible, or when the treatment is naturally delivered at the group or community level (Blair, Coppock & Humphreys, 2023). 5. Matched-Pair Random Assignment In this method, participants are first paired based on a particular characteristic or set of characteristics that are relevant to the research study, such as age, gender, or a specific health condition. Each pair is then split randomly into different research conditions or groups. This can help control for the influence of specific variables and increase the likelihood that the groups will be comparable, thereby increasing the validity of the results (Nestor & Schutt, 2018). Random Assignment Examples1. Pharmaceutical Efficacy Study In this type of research, consider a scenario where a pharmaceutical company wishes to test the potency of two different versions of a medication, Medication A and Medication B. The researcher recruits a group of volunteers and randomly assigns them to receive either Medication A or Medication B. This method ensures that each participant has an equal chance of being given either option, mitigating potential bias from the investigator’s side. It’s an expectation, for example, for FDA approval pre-trials (Rosenberger & Lachin, 2015). 2. Educational Techniques Study In this approach, an educator looking to evaluate a new teaching technique may randomly assign their students into two distinct classrooms. In one classroom, the new teaching technique will be implemented, while in the other, traditional methods will be utilized. The students’ performance will then be analyzed to determine if the new teaching strategy yields better results. To ensure the class cohorts are randomly assigned, we need to make sure there is no interference from parents, administrators, or others. 3. Website Usability Test In this digital-oriented example, a web designer could be researching the most effective layout for a website. Participants would be randomly assigned to use websites with a different layout and their navigation and satisfaction would be subsequently measured. This technique helps identify which design is user-friendlier based on the measured outcomes. 4. Physical Fitness Research For an investigator looking to evaluate the effectiveness of different exercise routines for weight loss, they could randomly assign participants to either a High-Intensity Interval Training (HIIT) or an endurance-based running program. By studying the participants’ weight changes across a specified time, a conclusion can be drawn on which exercise regime produces better weight loss results. 5. Environmental Psychology Study In this illustration, imagine a psychologist wanting to understand how office settings influence employees’ productivity. He could randomly assign employees to work in one of two offices: one with windows and natural light, the other windowless. The psychologist would then measure their work output to gauge if the environmental conditions impact productivity. 6. Dietary Research Test In this case, a dietician, striving to determine the efficacy of two diets on heart health, might randomly assign participants to adhere to either a Mediterranean diet or a low-fat diet. The dietician would then track cholesterol levels, blood pressure, and other heart health indicators over a determined period to discern which diet benefits heart health the most. 7. Mental Health Study In examining the IMPACT (Improving Mood-Promoting Access to Collaborative Treatment) model, a mental health researcher could randomly assign patients to receive either standard depression treatment or the IMPACT model treatment. Here, the purpose is to cross-compare recovery rates to gauge the effectiveness of the IMPACT model against the standard treatment. 8. Marketing Research A company intending to validate the effectiveness of different marketing strategies could randomly assign customers to receive either email marketing materials or social media marketing materials. Customer response and engagement rates would then be measured to evaluate which strategy is more beneficial and drives better engagement. 9. Sleep Study Research Suppose a researcher wants to investigate the effects of different levels of screen time on sleep quality. The researcher may randomly assign participants to varying amounts of nightly screen time, then compare sleep quality metrics (such as total sleep time, sleep latency, and awakenings during the night). 10. Workplace Productivity Experiment Let’s consider an HR professional who aims to evaluate the efficacy of open office and closed office layouts on employee productivity. She could randomly assign a group of employees to work in either environment and measure metrics such as work completed, attention to detail, and number of errors made to determine which office layout promotes higher productivity. 11. Child Development Study Suppose a developmental psychologist wants to investigate the effect of different learning tools on children’s development. The psychologist could randomly assign children to use either digital learning tools or traditional physical learning tools, such as books, for a fixed period. Subsequently, their development and learning progression would be tracked to determine which tool fosters more effective learning. 12. Traffic Management Research In an urban planning study, researchers could randomly assign streets to implement either traditional stop signs or roundabouts. The researchers, over a predetermined period, could then measure accident rates, traffic flow, and average travel times to identify which traffic management method is safer and more efficient. 13. Energy Consumption Study In a research project comparing the effectiveness of various energy-saving strategies, residents could be randomly assigned to implement either energy-saving light bulbs or regular bulbs in their homes. After a specific duration, their energy consumption would be compared to evaluate which measure yields better energy conservation. 14. Product Testing Research In a consumer goods case, a company looking to launch a new dishwashing detergent could randomly assign the new product or the existing best seller to a group of consumers. By analyzing their feedback on cleaning capabilities, scent, and product usage, the company can find out if the new detergent is an improvement over the existing one Nestor & Schutt, 2018. 15. Physical Therapy Research A physical therapist might be interested in comparing the effectiveness of different treatment regimens for patients with lower back pain. They could randomly assign patients to undergo either manual therapy or exercise therapy for a set duration and later evaluate pain levels and mobility. Random assignment is effective, but not infallible. Nevertheless, it does help us to achieve greater control over our experiments and minimize the chances that confounding variables are undermining the direct correlation between independent and dependent variables within a study. Over time, when a sufficient number of high-quality and well-designed studies are conducted, with sufficient sample sizes and sufficient generalizability, we can gain greater confidence in the causation between a treatment and its effects. Read Next: Types of Research Design Alferes, V. R. (2012). Methods of randomization in experimental design . Sage Publications. Blair, G., Coppock, A., & Humphreys, M. (2023). Research Design in the Social Sciences: Declaration, Diagnosis, and Redesign. New Jersey: Princeton University Press. Jamison, J. C. (2019). The entry of randomized assignment into the social sciences. Journal of Causal Inference , 7 (1), 20170025. Nestor, P. G., & Schutt, R. K. (2018). Research Methods in Psychology: Investigating Human Behavior. New York: SAGE Publications. Rosenberger, W. F., & Lachin, J. M. (2015). Randomization in Clinical Trials: Theory and Practice. London: Wiley. 
Leave a Comment Cancel ReplyYour email address will not be published. Required fields are marked * Difference between Random Selection and Random AssignmentRandom selection and random assignment are commonly confused or used interchangeably, though the terms refer to entirely different processes. Random selection refers to how sample members (study participants) are selected from the population for inclusion in the study. Random assignment is an aspect of experimental design in which study participants are assigned to the treatment or control group using a random procedure. Random selection requires the use of some form of random sampling (such as stratified random sampling , in which the population is sorted into groups from which sample members are chosen randomly). Random sampling is a probability sampling method, meaning that it relies on the laws of probability to select a sample that can be used to make inference to the population; this is the basis of statistical tests of significance .  Discover How We Assist to Edit Your Dissertation ChaptersAligning theoretical framework, gathering articles, synthesizing gaps, articulating a clear methodology and data plan, and writing about the theoretical and practical implications of your research are part of our comprehensive dissertation editing services.
Random assignment takes place following the selection of participants for the study. In a true experiment, all study participants are randomly assigned either to receive the treatment (also known as the stimulus or intervention) or to act as a control in the study (meaning they do not receive the treatment). Although random assignment is a simple procedure (it can be accomplished by the flip of a coin), it can be challenging to implement outside of controlled laboratory conditions. A study can use both, only one, or neither. Here are some examples to illustrate each situation: A researcher gets a list of all students enrolled at a particular school (the population). Using a random number generator, the researcher selects 100 students from the school to participate in the study (the random sample). All students’ names are placed in a hat and 50 are chosen to receive the intervention (the treatment group), while the remaining 50 students serve as the control group. This design uses both random selection and random assignment. A study using only random assignment could ask the principle of the school to select the students she believes are most likely to enjoy participating in the study, and the researcher could then randomly assign this sample of students to the treatment and control groups. In such a design the researcher could draw conclusions about the effect of the intervention but couldn’t make any inference about whether the effect would likely to be found in the population. A study using only random selection could randomly select students from the overall population of the school, but then assign students in one grade to the intervention and students in another grade to the control group. While any data collected from this sample could be used to make inference to the population of the school, the lack of random assignment to be in the treatment or control group would make it impossible to conclude whether the intervention had any effect. Random selection is thus essential to external validity, or the extent to which the researcher can use the results of the study to generalize to the larger population. Random assignment is central to internal validity, which allows the researcher to make causal claims about the effect of the treatment. Nonrandom assignment often leads to non-equivalent groups, meaning that any effect of the treatment might be a result of the groups being different at the outset rather than different at the end as a result of the treatment. The consequences of random selection and random assignment are clearly very different, and a strong research design will employ both whenever possible to ensure both internal and external validity .  Title: Random Assignment Definition: In statistics and research methodology, random assignment refers to the process of assigning participants or subjects to different groups or conditions in such a way that each individual has an equal chance of being placed in any of the groups. It is a critical component of experimental design and helps to ensure that the groups being compared are similar in terms of their characteristics or attributes, reducing the likelihood of bias. Importance of Random Assignment: Random assignment is crucial in research studies as it allows researchers to make causal inferences about the effects of certain variables or interventions. By distributing participants randomly, researchers can assume that any differences observed between the groups after the experiment are solely due to the independent variable being manipulated, rather than any preexisting individual differences. Process of Random Assignment: The process of random assignment typically involves using techniques such as random number generators, computer software, or even drawing lots to allocate participants randomly to the different groups. Researchers often strive to achieve balance in the groups in terms of demographic characteristics, prior knowledge, or other relevant factors to enhance the internal validity of the experiment. Benefits of Random Assignment: Random assignment provides several benefits such as reducing selection bias, distributing confounding variables equally across groups, and increasing the generalizability of research findings. It ensures that any observed differences in outcomes between groups can be confidently attributed to the treatment or intervention under investigation. Frequently asked questionsWhat’s the difference between random assignment and random selection. Random selection, or random sampling , is a way of selecting members of a population for your study’s sample. In contrast, random assignment is a way of sorting the sample into control and experimental groups. Random sampling enhances the external validity or generalizability of your results, while random assignment improves the internal validity of your study. Frequently asked questions: MethodologyAttrition refers to participants leaving a study. It always happens to some extent—for example, in randomized controlled trials for medical research. Differential attrition occurs when attrition or dropout rates differ systematically between the intervention and the control group . As a result, the characteristics of the participants who drop out differ from the characteristics of those who stay in the study. Because of this, study results may be biased . Action research is conducted in order to solve a particular issue immediately, while case studies are often conducted over a longer period of time and focus more on observing and analyzing a particular ongoing phenomenon. Action research is focused on solving a problem or informing individual and community-based knowledge in a way that impacts teaching, learning, and other related processes. It is less focused on contributing theoretical input, instead producing actionable input. Action research is particularly popular with educators as a form of systematic inquiry because it prioritizes reflection and bridges the gap between theory and practice. Educators are able to simultaneously investigate an issue as they solve it, and the method is very iterative and flexible. A cycle of inquiry is another name for action research . It is usually visualized in a spiral shape following a series of steps, such as “planning → acting → observing → reflecting.” To make quantitative observations , you need to use instruments that are capable of measuring the quantity you want to observe. For example, you might use a ruler to measure the length of an object or a thermometer to measure its temperature. Criterion validity and construct validity are both types of measurement validity . In other words, they both show you how accurately a method measures something. While construct validity is the degree to which a test or other measurement method measures what it claims to measure, criterion validity is the degree to which a test can predictively (in the future) or concurrently (in the present) measure something. Construct validity is often considered the overarching type of measurement validity . You need to have face validity , content validity , and criterion validity in order to achieve construct validity. Convergent validity and discriminant validity are both subtypes of construct validity . Together, they help you evaluate whether a test measures the concept it was designed to measure.
You need to assess both in order to demonstrate construct validity. Neither one alone is sufficient for establishing construct validity.
Content validity shows you how accurately a test or other measurement method taps into the various aspects of the specific construct you are researching. In other words, it helps you answer the question: “does the test measure all aspects of the construct I want to measure?” If it does, then the test has high content validity. The higher the content validity, the more accurate the measurement of the construct. If the test fails to include parts of the construct, or irrelevant parts are included, the validity of the instrument is threatened, which brings your results into question. Face validity and content validity are similar in that they both evaluate how suitable the content of a test is. The difference is that face validity is subjective, and assesses content at surface level. When a test has strong face validity, anyone would agree that the test’s questions appear to measure what they are intended to measure. For example, looking at a 4th grade math test consisting of problems in which students have to add and multiply, most people would agree that it has strong face validity (i.e., it looks like a math test). On the other hand, content validity evaluates how well a test represents all the aspects of a topic. Assessing content validity is more systematic and relies on expert evaluation. of each question, analyzing whether each one covers the aspects that the test was designed to cover. A 4th grade math test would have high content validity if it covered all the skills taught in that grade. Experts(in this case, math teachers), would have to evaluate the content validity by comparing the test to the learning objectives. Snowball sampling is a non-probability sampling method . Unlike probability sampling (which involves some form of random selection ), the initial individuals selected to be studied are the ones who recruit new participants. Because not every member of the target population has an equal chance of being recruited into the sample, selection in snowball sampling is non-random. Snowball sampling is a non-probability sampling method , where there is not an equal chance for every member of the population to be included in the sample . This means that you cannot use inferential statistics and make generalizations —often the goal of quantitative research . As such, a snowball sample is not representative of the target population and is usually a better fit for qualitative research . Snowball sampling relies on the use of referrals. Here, the researcher recruits one or more initial participants, who then recruit the next ones. Participants share similar characteristics and/or know each other. Because of this, not every member of the population has an equal chance of being included in the sample, giving rise to sampling bias . Snowball sampling is best used in the following cases:
The reproducibility and replicability of a study can be ensured by writing a transparent, detailed method section and using clear, unambiguous language. Reproducibility and replicability are related terms.
Stratified sampling and quota sampling both involve dividing the population into subgroups and selecting units from each subgroup. The purpose in both cases is to select a representative sample and/or to allow comparisons between subgroups. The main difference is that in stratified sampling, you draw a random sample from each subgroup ( probability sampling ). In quota sampling you select a predetermined number or proportion of units, in a non-random manner ( non-probability sampling ). Purposive and convenience sampling are both sampling methods that are typically used in qualitative data collection. A convenience sample is drawn from a source that is conveniently accessible to the researcher. Convenience sampling does not distinguish characteristics among the participants. On the other hand, purposive sampling focuses on selecting participants possessing characteristics associated with the research study. The findings of studies based on either convenience or purposive sampling can only be generalized to the (sub)population from which the sample is drawn, and not to the entire population. Random sampling or probability sampling is based on random selection. This means that each unit has an equal chance (i.e., equal probability) of being included in the sample. On the other hand, convenience sampling involves stopping people at random, which means that not everyone has an equal chance of being selected depending on the place, time, or day you are collecting your data. Convenience sampling and quota sampling are both non-probability sampling methods. They both use non-random criteria like availability, geographical proximity, or expert knowledge to recruit study participants. However, in convenience sampling, you continue to sample units or cases until you reach the required sample size. In quota sampling, you first need to divide your population of interest into subgroups (strata) and estimate their proportions (quota) in the population. Then you can start your data collection, using convenience sampling to recruit participants, until the proportions in each subgroup coincide with the estimated proportions in the population. A sampling frame is a list of every member in the entire population . It is important that the sampling frame is as complete as possible, so that your sample accurately reflects your population. Stratified and cluster sampling may look similar, but bear in mind that groups created in cluster sampling are heterogeneous , so the individual characteristics in the cluster vary. In contrast, groups created in stratified sampling are homogeneous , as units share characteristics. Relatedly, in cluster sampling you randomly select entire groups and include all units of each group in your sample. However, in stratified sampling, you select some units of all groups and include them in your sample. In this way, both methods can ensure that your sample is representative of the target population . A systematic review is secondary research because it uses existing research. You don’t collect new data yourself. The key difference between observational studies and experimental designs is that a well-done observational study does not influence the responses of participants, while experiments do have some sort of treatment condition applied to at least some participants by random assignment . An observational study is a great choice for you if your research question is based purely on observations. If there are ethical, logistical, or practical concerns that prevent you from conducting a traditional experiment , an observational study may be a good choice. In an observational study, there is no interference or manipulation of the research subjects, as well as no control or treatment groups . It’s often best to ask a variety of people to review your measurements. You can ask experts, such as other researchers, or laypeople, such as potential participants, to judge the face validity of tests. While experts have a deep understanding of research methods , the people you’re studying can provide you with valuable insights you may have missed otherwise. Face validity is important because it’s a simple first step to measuring the overall validity of a test or technique. It’s a relatively intuitive, quick, and easy way to start checking whether a new measure seems useful at first glance. Good face validity means that anyone who reviews your measure says that it seems to be measuring what it’s supposed to. With poor face validity, someone reviewing your measure may be left confused about what you’re measuring and why you’re using this method. Face validity is about whether a test appears to measure what it’s supposed to measure. This type of validity is concerned with whether a measure seems relevant and appropriate for what it’s assessing only on the surface. Statistical analyses are often applied to test validity with data from your measures. You test convergent validity and discriminant validity with correlations to see if results from your test are positively or negatively related to those of other established tests. You can also use regression analyses to assess whether your measure is actually predictive of outcomes that you expect it to predict theoretically. A regression analysis that supports your expectations strengthens your claim of construct validity . When designing or evaluating a measure, construct validity helps you ensure you’re actually measuring the construct you’re interested in. If you don’t have construct validity, you may inadvertently measure unrelated or distinct constructs and lose precision in your research. Construct validity is often considered the overarching type of measurement validity , because it covers all of the other types. You need to have face validity , content validity , and criterion validity to achieve construct validity. Construct validity is about how well a test measures the concept it was designed to evaluate. It’s one of four types of measurement validity , which includes construct validity, face validity , and criterion validity. There are two subtypes of construct validity.
Naturalistic observation is a valuable tool because of its flexibility, external validity , and suitability for topics that can’t be studied in a lab setting. The downsides of naturalistic observation include its lack of scientific control , ethical considerations , and potential for bias from observers and subjects. Naturalistic observation is a qualitative research method where you record the behaviors of your research subjects in real world settings. You avoid interfering or influencing anything in a naturalistic observation. You can think of naturalistic observation as “people watching” with a purpose. A dependent variable is what changes as a result of the independent variable manipulation in experiments . It’s what you’re interested in measuring, and it “depends” on your independent variable. In statistics, dependent variables are also called:
An independent variable is the variable you manipulate, control, or vary in an experimental study to explore its effects. It’s called “independent” because it’s not influenced by any other variables in the study. Independent variables are also called:
As a rule of thumb, questions related to thoughts, beliefs, and feelings work well in focus groups. Take your time formulating strong questions, paying special attention to phrasing. Be careful to avoid leading questions , which can bias your responses. Overall, your focus group questions should be:
A structured interview is a data collection method that relies on asking questions in a set order to collect data on a topic. They are often quantitative in nature. Structured interviews are best used when:
More flexible interview options include semi-structured interviews , unstructured interviews , and focus groups . Social desirability bias is the tendency for interview participants to give responses that will be viewed favorably by the interviewer or other participants. It occurs in all types of interviews and surveys , but is most common in semi-structured interviews , unstructured interviews , and focus groups . Social desirability bias can be mitigated by ensuring participants feel at ease and comfortable sharing their views. Make sure to pay attention to your own body language and any physical or verbal cues, such as nodding or widening your eyes. This type of bias can also occur in observations if the participants know they’re being observed. They might alter their behavior accordingly. The interviewer effect is a type of bias that emerges when a characteristic of an interviewer (race, age, gender identity, etc.) influences the responses given by the interviewee. There is a risk of an interviewer effect in all types of interviews , but it can be mitigated by writing really high-quality interview questions. A semi-structured interview is a blend of structured and unstructured types of interviews. Semi-structured interviews are best used when:
An unstructured interview is the most flexible type of interview, but it is not always the best fit for your research topic. Unstructured interviews are best used when:
The four most common types of interviews are:
Deductive reasoning is commonly used in scientific research, and it’s especially associated with quantitative research . In research, you might have come across something called the hypothetico-deductive method . It’s the scientific method of testing hypotheses to check whether your predictions are substantiated by real-world data. Deductive reasoning is a logical approach where you progress from general ideas to specific conclusions. It’s often contrasted with inductive reasoning , where you start with specific observations and form general conclusions. Deductive reasoning is also called deductive logic. There are many different types of inductive reasoning that people use formally or informally. Here are a few common types:
Inductive reasoning is a bottom-up approach, while deductive reasoning is top-down. Inductive reasoning takes you from the specific to the general, while in deductive reasoning, you make inferences by going from general premises to specific conclusions. In inductive research , you start by making observations or gathering data. Then, you take a broad scan of your data and search for patterns. Finally, you make general conclusions that you might incorporate into theories. Inductive reasoning is a method of drawing conclusions by going from the specific to the general. It’s usually contrasted with deductive reasoning, where you proceed from general information to specific conclusions. Inductive reasoning is also called inductive logic or bottom-up reasoning. A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question. A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data). Triangulation can help:
But triangulation can also pose problems:
There are four main types of triangulation :
Many academic fields use peer review , largely to determine whether a manuscript is suitable for publication. Peer review enhances the credibility of the published manuscript. However, peer review is also common in non-academic settings. The United Nations, the European Union, and many individual nations use peer review to evaluate grant applications. It is also widely used in medical and health-related fields as a teaching or quality-of-care measure. Peer assessment is often used in the classroom as a pedagogical tool. Both receiving feedback and providing it are thought to enhance the learning process, helping students think critically and collaboratively. Peer review can stop obviously problematic, falsified, or otherwise untrustworthy research from being published. It also represents an excellent opportunity to get feedback from renowned experts in your field. It acts as a first defense, helping you ensure your argument is clear and that there are no gaps, vague terms, or unanswered questions for readers who weren’t involved in the research process. Peer-reviewed articles are considered a highly credible source due to this stringent process they go through before publication. In general, the peer review process follows the following steps:
Exploratory research is often used when the issue you’re studying is new or when the data collection process is challenging for some reason. You can use exploratory research if you have a general idea or a specific question that you want to study but there is no preexisting knowledge or paradigm with which to study it. Exploratory research is a methodology approach that explores research questions that have not previously been studied in depth. It is often used when the issue you’re studying is new, or the data collection process is challenging in some way. Explanatory research is used to investigate how or why a phenomenon occurs. Therefore, this type of research is often one of the first stages in the research process , serving as a jumping-off point for future research. Exploratory research aims to explore the main aspects of an under-researched problem, while explanatory research aims to explain the causes and consequences of a well-defined problem. Explanatory research is a research method used to investigate how or why something occurs when only a small amount of information is available pertaining to that topic. It can help you increase your understanding of a given topic. Clean data are valid, accurate, complete, consistent, unique, and uniform. Dirty data include inconsistencies and errors. Dirty data can come from any part of the research process, including poor research design , inappropriate measurement materials, or flawed data entry. Data cleaning takes place between data collection and data analyses. But you can use some methods even before collecting data. For clean data, you should start by designing measures that collect valid data. Data validation at the time of data entry or collection helps you minimize the amount of data cleaning you’ll need to do. After data collection, you can use data standardization and data transformation to clean your data. You’ll also deal with any missing values, outliers, and duplicate values. Every dataset requires different techniques to clean dirty data , but you need to address these issues in a systematic way. You focus on finding and resolving data points that don’t agree or fit with the rest of your dataset. These data might be missing values, outliers, duplicate values, incorrectly formatted, or irrelevant. You’ll start with screening and diagnosing your data. Then, you’ll often standardize and accept or remove data to make your dataset consistent and valid. Data cleaning is necessary for valid and appropriate analyses. Dirty data contain inconsistencies or errors , but cleaning your data helps you minimize or resolve these. Without data cleaning, you could end up with a Type I or II error in your conclusion. These types of erroneous conclusions can be practically significant with important consequences, because they lead to misplaced investments or missed opportunities. Data cleaning involves spotting and resolving potential data inconsistencies or errors to improve your data quality. An error is any value (e.g., recorded weight) that doesn’t reflect the true value (e.g., actual weight) of something that’s being measured. In this process, you review, analyze, detect, modify, or remove “dirty” data to make your dataset “clean.” Data cleaning is also called data cleansing or data scrubbing. Research misconduct means making up or falsifying data, manipulating data analyses, or misrepresenting results in research reports. It’s a form of academic fraud. These actions are committed intentionally and can have serious consequences; research misconduct is not a simple mistake or a point of disagreement but a serious ethical failure. Anonymity means you don’t know who the participants are, while confidentiality means you know who they are but remove identifying information from your research report. Both are important ethical considerations . You can only guarantee anonymity by not collecting any personally identifying information—for example, names, phone numbers, email addresses, IP addresses, physical characteristics, photos, or videos. You can keep data confidential by using aggregate information in your research report, so that you only refer to groups of participants rather than individuals. Research ethics matter for scientific integrity, human rights and dignity, and collaboration between science and society. These principles make sure that participation in studies is voluntary, informed, and safe. Ethical considerations in research are a set of principles that guide your research designs and practices. These principles include voluntary participation, informed consent, anonymity, confidentiality, potential for harm, and results communication. Scientists and researchers must always adhere to a certain code of conduct when collecting data from others . These considerations protect the rights of research participants, enhance research validity , and maintain scientific integrity. In multistage sampling , you can use probability or non-probability sampling methods . For a probability sample, you have to conduct probability sampling at every stage. You can mix it up by using simple random sampling , systematic sampling , or stratified sampling to select units at different stages, depending on what is applicable and relevant to your study. Multistage sampling can simplify data collection when you have large, geographically spread samples, and you can obtain a probability sample without a complete sampling frame. But multistage sampling may not lead to a representative sample, and larger samples are needed for multistage samples to achieve the statistical properties of simple random samples . These are four of the most common mixed methods designs :
Triangulation in research means using multiple datasets, methods, theories and/or investigators to address a research question. It’s a research strategy that can help you enhance the validity and credibility of your findings. Triangulation is mainly used in qualitative research , but it’s also commonly applied in quantitative research . Mixed methods research always uses triangulation. In multistage sampling , or multistage cluster sampling, you draw a sample from a population using smaller and smaller groups at each stage. This method is often used to collect data from a large, geographically spread group of people in national surveys, for example. You take advantage of hierarchical groupings (e.g., from state to city to neighborhood) to create a sample that’s less expensive and time-consuming to collect data from. No, the steepness or slope of the line isn’t related to the correlation coefficient value. The correlation coefficient only tells you how closely your data fit on a line, so two datasets with the same correlation coefficient can have very different slopes. To find the slope of the line, you’ll need to perform a regression analysis . Correlation coefficients always range between -1 and 1. The sign of the coefficient tells you the direction of the relationship: a positive value means the variables change together in the same direction, while a negative value means they change together in opposite directions. The absolute value of a number is equal to the number without its sign. The absolute value of a correlation coefficient tells you the magnitude of the correlation: the greater the absolute value, the stronger the correlation. These are the assumptions your data must meet if you want to use Pearson’s r :
Quantitative research designs can be divided into two main categories:
Qualitative research designs tend to be more flexible. Common types of qualitative design include case study , ethnography , and grounded theory designs. A well-planned research design helps ensure that your methods match your research aims, that you collect high-quality data, and that you use the right kind of analysis to answer your questions, utilizing credible sources . This allows you to draw valid , trustworthy conclusions. The priorities of a research design can vary depending on the field, but you usually have to specify:
A research design is a strategy for answering your research question . It defines your overall approach and determines how you will collect and analyze data. Questionnaires can be self-administered or researcher-administered. Self-administered questionnaires can be delivered online or in paper-and-pen formats, in person or through mail. All questions are standardized so that all respondents receive the same questions with identical wording. Researcher-administered questionnaires are interviews that take place by phone, in-person, or online between researchers and respondents. You can gain deeper insights by clarifying questions for respondents or asking follow-up questions. You can organize the questions logically, with a clear progression from simple to complex, or randomly between respondents. A logical flow helps respondents process the questionnaire easier and quicker, but it may lead to bias. Randomization can minimize the bias from order effects. Closed-ended, or restricted-choice, questions offer respondents a fixed set of choices to select from. These questions are easier to answer quickly. Open-ended or long-form questions allow respondents to answer in their own words. Because there are no restrictions on their choices, respondents can answer in ways that researchers may not have otherwise considered. A questionnaire is a data collection tool or instrument, while a survey is an overarching research method that involves collecting and analyzing data from people using questionnaires. The third variable and directionality problems are two main reasons why correlation isn’t causation . The third variable problem means that a confounding variable affects both variables to make them seem causally related when they are not. The directionality problem is when two variables correlate and might actually have a causal relationship, but it’s impossible to conclude which variable causes changes in the other. Correlation describes an association between variables : when one variable changes, so does the other. A correlation is a statistical indicator of the relationship between variables. Causation means that changes in one variable brings about changes in the other (i.e., there is a cause-and-effect relationship between variables). The two variables are correlated with each other, and there’s also a causal link between them. While causation and correlation can exist simultaneously, correlation does not imply causation. In other words, correlation is simply a relationship where A relates to B—but A doesn’t necessarily cause B to happen (or vice versa). Mistaking correlation for causation is a common error and can lead to false cause fallacy . Controlled experiments establish causality, whereas correlational studies only show associations between variables.
In general, correlational research is high in external validity while experimental research is high in internal validity . A correlation is usually tested for two variables at a time, but you can test correlations between three or more variables. A correlation coefficient is a single number that describes the strength and direction of the relationship between your variables. Different types of correlation coefficients might be appropriate for your data based on their levels of measurement and distributions . The Pearson product-moment correlation coefficient (Pearson’s r ) is commonly used to assess a linear relationship between two quantitative variables. A correlational research design investigates relationships between two variables (or more) without the researcher controlling or manipulating any of them. It’s a non-experimental type of quantitative research . A correlation reflects the strength and/or direction of the association between two or more variables.
Random error is almost always present in scientific studies, even in highly controlled settings. While you can’t eradicate it completely, you can reduce random error by taking repeated measurements, using a large sample, and controlling extraneous variables . You can avoid systematic error through careful design of your sampling , data collection , and analysis procedures. For example, use triangulation to measure your variables using multiple methods; regularly calibrate instruments or procedures; use random sampling and random assignment ; and apply masking (blinding) where possible. Systematic error is generally a bigger problem in research. With random error, multiple measurements will tend to cluster around the true value. When you’re collecting data from a large sample , the errors in different directions will cancel each other out. Systematic errors are much more problematic because they can skew your data away from the true value. This can lead you to false conclusions ( Type I and II errors ) about the relationship between the variables you’re studying. Random and systematic error are two types of measurement error. Random error is a chance difference between the observed and true values of something (e.g., a researcher misreading a weighing scale records an incorrect measurement). Systematic error is a consistent or proportional difference between the observed and true values of something (e.g., a miscalibrated scale consistently records weights as higher than they actually are). On graphs, the explanatory variable is conventionally placed on the x-axis, while the response variable is placed on the y-axis.
The term “ explanatory variable ” is sometimes preferred over “ independent variable ” because, in real world contexts, independent variables are often influenced by other variables. This means they aren’t totally independent. Multiple independent variables may also be correlated with each other, so “explanatory variables” is a more appropriate term. The difference between explanatory and response variables is simple:
In a controlled experiment , all extraneous variables are held constant so that they can’t influence the results. Controlled experiments require:
Depending on your study topic, there are various other methods of controlling variables . There are 4 main types of extraneous variables :
An extraneous variable is any variable that you’re not investigating that can potentially affect the dependent variable of your research study. A confounding variable is a type of extraneous variable that not only affects the dependent variable, but is also related to the independent variable. In a factorial design, multiple independent variables are tested. If you test two variables, each level of one independent variable is combined with each level of the other independent variable to create different conditions. Within-subjects designs have many potential threats to internal validity , but they are also very statistically powerful . Advantages:
Disadvantages:
While a between-subjects design has fewer threats to internal validity , it also requires more participants for high statistical power than a within-subjects design .
Yes. Between-subjects and within-subjects designs can be combined in a single study when you have two or more independent variables (a factorial design). In a mixed factorial design, one variable is altered between subjects and another is altered within subjects. In a between-subjects design , every participant experiences only one condition, and researchers assess group differences between participants in various conditions. In a within-subjects design , each participant experiences all conditions, and researchers test the same participants repeatedly for differences between conditions. The word “between” means that you’re comparing different conditions between groups, while the word “within” means you’re comparing different conditions within the same group. Random assignment is used in experiments with a between-groups or independent measures design. In this research design, there’s usually a control group and one or more experimental groups. Random assignment helps ensure that the groups are comparable. In general, you should always use random assignment in this type of experimental design when it is ethically possible and makes sense for your study topic. To implement random assignment , assign a unique number to every member of your study’s sample . Then, you can use a random number generator or a lottery method to randomly assign each number to a control or experimental group. You can also do so manually, by flipping a coin or rolling a dice to randomly assign participants to groups. In experimental research, random assignment is a way of placing participants from your sample into different groups using randomization. With this method, every member of the sample has a known or equal chance of being placed in a control group or an experimental group. “Controlling for a variable” means measuring extraneous variables and accounting for them statistically to remove their effects on other variables. Researchers often model control variable data along with independent and dependent variable data in regression analyses and ANCOVAs . That way, you can isolate the control variable’s effects from the relationship between the variables of interest. Control variables help you establish a correlational or causal relationship between variables by enhancing internal validity . If you don’t control relevant extraneous variables , they may influence the outcomes of your study, and you may not be able to demonstrate that your results are really an effect of your independent variable . A control variable is any variable that’s held constant in a research study. It’s not a variable of interest in the study, but it’s controlled because it could influence the outcomes. Including mediators and moderators in your research helps you go beyond studying a simple relationship between two variables for a fuller picture of the real world. They are important to consider when studying complex correlational or causal relationships. Mediators are part of the causal pathway of an effect, and they tell you how or why an effect takes place. Moderators usually help you judge the external validity of your study by identifying the limitations of when the relationship between variables holds. If something is a mediating variable :
A confounder is a third variable that affects variables of interest and makes them seem related when they are not. In contrast, a mediator is the mechanism of a relationship between two variables: it explains the process by which they are related. A mediator variable explains the process through which two variables are related, while a moderator variable affects the strength and direction of that relationship. There are three key steps in systematic sampling :
Systematic sampling is a probability sampling method where researchers select members of the population at a regular interval – for example, by selecting every 15th person on a list of the population. If the population is in a random order, this can imitate the benefits of simple random sampling . Yes, you can create a stratified sample using multiple characteristics, but you must ensure that every participant in your study belongs to one and only one subgroup. In this case, you multiply the numbers of subgroups for each characteristic to get the total number of groups. For example, if you were stratifying by location with three subgroups (urban, rural, or suburban) and marital status with five subgroups (single, divorced, widowed, married, or partnered), you would have 3 x 5 = 15 subgroups. You should use stratified sampling when your sample can be divided into mutually exclusive and exhaustive subgroups that you believe will take on different mean values for the variable that you’re studying. Using stratified sampling will allow you to obtain more precise (with lower variance ) statistical estimates of whatever you are trying to measure. For example, say you want to investigate how income differs based on educational attainment, but you know that this relationship can vary based on race. Using stratified sampling, you can ensure you obtain a large enough sample from each racial group, allowing you to draw more precise conclusions. In stratified sampling , researchers divide subjects into subgroups called strata based on characteristics that they share (e.g., race, gender, educational attainment). Once divided, each subgroup is randomly sampled using another probability sampling method. Cluster sampling is more time- and cost-efficient than other probability sampling methods , particularly when it comes to large samples spread across a wide geographical area. However, it provides less statistical certainty than other methods, such as simple random sampling , because it is difficult to ensure that your clusters properly represent the population as a whole. There are three types of cluster sampling : single-stage, double-stage and multi-stage clustering. In all three types, you first divide the population into clusters, then randomly select clusters for use in your sample.
Cluster sampling is a probability sampling method in which you divide a population into clusters, such as districts or schools, and then randomly select some of these clusters as your sample. The clusters should ideally each be mini-representations of the population as a whole. If properly implemented, simple random sampling is usually the best sampling method for ensuring both internal and external validity . However, it can sometimes be impractical and expensive to implement, depending on the size of the population to be studied, If you have a list of every member of the population and the ability to reach whichever members are selected, you can use simple random sampling. The American Community Survey is an example of simple random sampling . In order to collect detailed data on the population of the US, the Census Bureau officials randomly select 3.5 million households per year and use a variety of methods to convince them to fill out the survey. Simple random sampling is a type of probability sampling in which the researcher randomly selects a subset of participants from a population . Each member of the population has an equal chance of being selected. Data is then collected from as large a percentage as possible of this random subset. Quasi-experimental design is most useful in situations where it would be unethical or impractical to run a true experiment . Quasi-experiments have lower internal validity than true experiments, but they often have higher external validity as they can use real-world interventions instead of artificial laboratory settings. A quasi-experiment is a type of research design that attempts to establish a cause-and-effect relationship. The main difference with a true experiment is that the groups are not randomly assigned. Blinding is important to reduce research bias (e.g., observer bias , demand characteristics ) and ensure a study’s internal validity . If participants know whether they are in a control or treatment group , they may adjust their behavior in ways that affect the outcome that researchers are trying to measure. If the people administering the treatment are aware of group assignment, they may treat participants differently and thus directly or indirectly influence the final results.
Blinding means hiding who is assigned to the treatment group and who is assigned to the control group in an experiment . A true experiment (a.k.a. a controlled experiment) always includes at least one control group that doesn’t receive the experimental treatment. However, some experiments use a within-subjects design to test treatments without a control group. In these designs, you usually compare one group’s outcomes before and after a treatment (instead of comparing outcomes between different groups). For strong internal validity , it’s usually best to include a control group if possible. Without a control group, it’s harder to be certain that the outcome was caused by the experimental treatment and not by other variables. An experimental group, also known as a treatment group, receives the treatment whose effect researchers wish to study, whereas a control group does not. They should be identical in all other ways. Individual Likert-type questions are generally considered ordinal data , because the items have clear rank order, but don’t have an even distribution. Overall Likert scale scores are sometimes treated as interval data. These scores are considered to have directionality and even spacing between them. The type of data determines what statistical tests you should use to analyze your data. A Likert scale is a rating scale that quantitatively assesses opinions, attitudes, or behaviors. It is made up of 4 or more questions that measure a single attitude or trait when response scores are combined. To use a Likert scale in a survey , you present participants with Likert-type questions or statements, and a continuum of items, usually with 5 or 7 possible responses, to capture their degree of agreement. In scientific research, concepts are the abstract ideas or phenomena that are being studied (e.g., educational achievement). Variables are properties or characteristics of the concept (e.g., performance at school), while indicators are ways of measuring or quantifying variables (e.g., yearly grade reports). The process of turning abstract concepts into measurable variables and indicators is called operationalization . There are various approaches to qualitative data analysis , but they all share five steps in common:
The specifics of each step depend on the focus of the analysis. Some common approaches include textual analysis , thematic analysis , and discourse analysis . There are five common approaches to qualitative research :
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance. Operationalization means turning abstract conceptual ideas into measurable observations. For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioral avoidance of crowded places, or physical anxiety symptoms in social situations. Before collecting data , it’s important to consider how you will operationalize the variables that you want to measure. When conducting research, collecting original data has significant advantages:
However, there are also some drawbacks: data collection can be time-consuming, labor-intensive and expensive. In some cases, it’s more efficient to use secondary data that has already been collected by someone else, but the data might be less reliable. Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organizations. There are several methods you can use to decrease the impact of confounding variables on your research: restriction, matching, statistical control and randomization. In restriction , you restrict your sample by only including certain subjects that have the same values of potential confounding variables. In matching , you match each of the subjects in your treatment group with a counterpart in the comparison group. The matched subjects have the same values on any potential confounding variables, and only differ in the independent variable . In statistical control , you include potential confounders as variables in your regression . In randomization , you randomly assign the treatment (or independent variable) in your study to a sufficiently large number of subjects, which allows you to control for all potential confounding variables. A confounding variable is closely related to both the independent and dependent variables in a study. An independent variable represents the supposed cause , while the dependent variable is the supposed effect . A confounding variable is a third variable that influences both the independent and dependent variables. Failing to account for confounding variables can cause you to wrongly estimate the relationship between your independent and dependent variables. To ensure the internal validity of your research, you must consider the impact of confounding variables. If you fail to account for them, you might over- or underestimate the causal relationship between your independent and dependent variables , or even find a causal relationship where none exists. Yes, but including more than one of either type requires multiple research questions . For example, if you are interested in the effect of a diet on health, you can use multiple measures of health: blood sugar, blood pressure, weight, pulse, and many more. Each of these is its own dependent variable with its own research question. You could also choose to look at the effect of exercise levels as well as diet, or even the additional effect of the two combined. Each of these is a separate independent variable . To ensure the internal validity of an experiment , you should only change one independent variable at a time. No. The value of a dependent variable depends on an independent variable, so a variable cannot be both independent and dependent at the same time. It must be either the cause or the effect, not both! You want to find out how blood sugar levels are affected by drinking diet soda and regular soda, so you conduct an experiment .
Determining cause and effect is one of the most important parts of scientific research. It’s essential to know which is the cause – the independent variable – and which is the effect – the dependent variable. In non-probability sampling , the sample is selected based on non-random criteria, and not every member of the population has a chance of being included. Common non-probability sampling methods include convenience sampling , voluntary response sampling, purposive sampling , snowball sampling, and quota sampling . Probability sampling means that every member of the target population has a known chance of being included in the sample. Probability sampling methods include simple random sampling , systematic sampling , stratified sampling , and cluster sampling . Using careful research design and sampling procedures can help you avoid sampling bias . Oversampling can be used to correct undercoverage bias . Some common types of sampling bias include self-selection bias , nonresponse bias , undercoverage bias , survivorship bias , pre-screening or advertising bias, and healthy user bias. Sampling bias is a threat to external validity – it limits the generalizability of your findings to a broader group of people. A sampling error is the difference between a population parameter and a sample statistic . A statistic refers to measures about the sample , while a parameter refers to measures about the population . Populations are used when a research question requires data from every member of the population. This is usually only feasible when the population is small and easily accessible. Samples are used to make inferences about populations . Samples are easier to collect data from because they are practical, cost-effective, convenient, and manageable. There are seven threats to external validity : selection bias , history, experimenter effect, Hawthorne effect , testing effect, aptitude-treatment and situation effect. The two types of external validity are population validity (whether you can generalize to other groups of people) and ecological validity (whether you can generalize to other situations and settings). The external validity of a study is the extent to which you can generalize your findings to different groups of people, situations, and measures. Cross-sectional studies cannot establish a cause-and-effect relationship or analyze behavior over a period of time. To investigate cause and effect, you need to do a longitudinal study or an experimental study . Cross-sectional studies are less expensive and time-consuming than many other types of study. They can provide useful insights into a population’s characteristics and identify correlations for further research. Sometimes only cross-sectional data is available for analysis; other times your research question may only require a cross-sectional study to answer it. Longitudinal studies can last anywhere from weeks to decades, although they tend to be at least a year long. The 1970 British Cohort Study , which has collected data on the lives of 17,000 Brits since their births in 1970, is one well-known example of a longitudinal study . Longitudinal studies are better to establish the correct sequence of events, identify changes over time, and provide insight into cause-and-effect relationships, but they also tend to be more expensive and time-consuming than other types of studies. Longitudinal studies and cross-sectional studies are two different types of research design . In a cross-sectional study you collect data from a population at a specific point in time; in a longitudinal study you repeatedly collect data from the same sample over an extended period of time.
There are eight threats to internal validity : history, maturation, instrumentation, testing, selection bias , regression to the mean, social interaction and attrition . Internal validity is the extent to which you can be confident that a cause-and-effect relationship established in a study cannot be explained by other factors. In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question . The research methods you use depend on the type of data you need to answer your research question .
A confounding variable , also called a confounder or confounding factor, is a third variable in a study examining a potential cause-and-effect relationship. A confounding variable is related to both the supposed cause and the supposed effect of the study. It can be difficult to separate the true effect of the independent variable from the effect of the confounding variable. In your research design , it’s important to identify potential confounding variables and plan how you will reduce their impact. Discrete and continuous variables are two types of quantitative variables :
Quantitative variables are any variables where the data represent amounts (e.g. height, weight, or age). Categorical variables are any variables where the data represent groups. This includes rankings (e.g. finishing places in a race), classifications (e.g. brands of cereal), and binary outcomes (e.g. coin flips). You need to know what type of variables you are working with to choose the right statistical test for your data and interpret your results . You can think of independent and dependent variables in terms of cause and effect: an independent variable is the variable you think is the cause , while a dependent variable is the effect . In an experiment, you manipulate the independent variable and measure the outcome in the dependent variable. For example, in an experiment about the effect of nutrients on crop growth:
Defining your variables, and deciding how you will manipulate and measure them, is an important part of experimental design . Experimental design means planning a set of procedures to investigate a relationship between variables . To design a controlled experiment, you need:
When designing the experiment, you decide:
Experimental design is essential to the internal and external validity of your experiment. I nternal validity is the degree of confidence that the causal relationship you are testing is not influenced by other factors or variables . External validity is the extent to which your results can be generalized to other contexts. The validity of your experiment depends on your experimental design . Reliability and validity are both about how well a method measures something:
If you are doing experimental research, you also have to consider the internal and external validity of your experiment. A sample is a subset of individuals from a larger population . Sampling means selecting the group that you will actually collect data from in your research. For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students. In statistics, sampling allows you to test a hypothesis about the characteristics of a population. Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings. Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail. Methodology refers to the overarching strategy and rationale of your research project . It involves studying the methods used in your field and the theories or principles behind them, in order to develop an approach that matches your objectives. Methods are the specific tools and procedures you use to collect and analyze data (for example, experiments, surveys , and statistical tests ). In shorter scientific papers, where the aim is to report the findings of a specific study, you might simply describe what you did in a methods section . In a longer or more complex research project, such as a thesis or dissertation , you will probably include a methodology section , where you explain your approach to answering the research questions and cite relevant sources to support your choice of methods. Ask our teamWant to contact us directly? No problem. We are always here for you.
 Our team helps students graduate by offering:
Scribbr specializes in editing study-related documents . We proofread:
Scribbr’s Plagiarism Checker is powered by elements of Turnitin’s Similarity Checker , namely the plagiarism detection software and the Internet Archive and Premium Scholarly Publications content databases . The add-on AI detector is powered by Scribbr’s proprietary software. The Scribbr Citation Generator is developed using the open-source Citation Style Language (CSL) project and Frank Bennett’s citeproc-js . It’s the same technology used by dozens of other popular citation tools, including Mendeley and Zotero. You can find all the citation styles and locales used in the Scribbr Citation Generator in our publicly accessible repository on Github . AP® PsychologyThe ultimate guide to 2015 ap® psychology frqs.
 AP® Psychology FRQWhen you are facing down the AP® Psychology exam, the AP® Psych FRQ can often seem much more challenging than the multiple-choice section. This is understandable because multiple choice questions allow for recognition. Even if you can’t remember something off the top of your head, you could recognize the correct answer. However, the AP® Psychology FRQ is an entirely different kind of question. Having the challenge of straight recall can create added anxiety to students, more than they may already have when confronting the AP® Psychology exam. This Ultimate Guide to the 2015 AP® Psychology FRQ will show you how to gain a full score of 7 on this FRQ to be better prepared for your future exam. Another thing that may be causing you added anxiety about the AP® Psychology FRQ is the actual writing portion. What you need to remember is that you aren’t being tested on the quality of your writing in the way that you would be on an AP® English exam. You won’t be graded on your writing quality, your grammar, or even your spelling! As long as the scorer can understand what you are trying to say (or your spelling is close enough that they can figure out what the word is), then you can still be awarded a point. What you should concentrate on is making your question correct and concise. If you only need one or two sentences to answer the question correctly, then go for it!  You do need to keep in mind that if you give just a definition of a concept on the AP® Psychology FRQ, you will not score a point. The point of the FRQ is to test your ability to apply psychological concepts to a random scenario placed in front of you. In order to score a full point, you need to be able to demonstrate an application of a concept to the scenario. Also, you should know that you won’t be penalized for putting down something incorrect. We have a tendency, as students, to become accustomed to receiving partial credit from teachers on exams for short answer questions. A scorer on the AP® Psychology exam will grade similarly. Don’t be concerned with putting down something incorrect; if it doesn’t directly contradict your correct answer, you will still receive credit. This question follows a typical AP® Psychology FRQ format by using a research study. For this question, the research design is a naturalistic study of hyperactivity in young children. When you are confronted with a research design based question on the FRQ, you will be provided with the study. Subsequently, you will need to answer questions regarding the study. This will assess your understanding of research designs. In this study, the children were at a party and researchers determined hyperactivity by the number of times the children got out of their seats. They also recorded the sugary snacks that were served at the party. Researchers found a strong positive correlation between the sugary snacks as well as the hyperactivity. Therefore, they determined that sugar causes hyperactivity. On question 1, the mean score students received was a 3.85 out of 7. How might the following explain why people may easily accept the conclusion of the study described above? Confirmation bias, availability heuristic, and misunderstanding of correlational studies. Confirmation BiasFor this point, you have to explain in some way how people will be more likely to accept a conclusion of a study if that conclusion aligns with or supports beliefs they already have. For example, an answer that would score a point would simply explain that people would pay more attention to or more easily believe the results of this study because it offers a conclusion they already believe. Availability HeuristicFor this point, you need to demonstrate how the conclusion of the study (sugar causes hyperactivity) would come to someone’s mind quicker and would lead to easier acceptance of the study’s conclusion. Misunderstanding of Correlational StudiesThis point brings up a very key idea in psychology and one that will serve you well to remember in all of psychology. Correlation is not causation. One thing could have a 100% positive correlation rate with something else, but that does not imply causation. In order to score a point, all you need to do is state that the researchers failed to understand that correlation does not prove causation. As a follow-up study, researchers are designing an experiment to test whether sugar causes hyperactivity. Please do the following for the experiment: state a possible hypothesis, operationally define the dependent variable, and describe how random assignment can be achieved. State a Possible HypothesisFor this question, you need to provide a hypothesis that demonstrates a causal relationship between sugar and hyperactivity. For example, your hypothesis could be that sugar has no effect on hyperactivity, or that sugar has a great effect on hyperactivity. Operationally Define the Dependent VariableFor this section, you need to provide an operational definition for hyperactivity. Essentially, you need to provide an example of how hyperactivity will be measured. For example, the researchers in the original study measured hyperactivity by how often the children got up from their seats. Describe how Random Assignment can be AchievedTo answer this question, you must understand how random assignment works. Essentially, you have to provide an explanation of how all the subjects have an equal probability of being placed into either of the groups or conditions. Don’t get random assignment confused with random selection! Based on the results of the follow-up experiment described in Part B, researchers conclude that sugar does not cause any change in hyperactivity. Draw a correctly labeled bar graph depicting this result. This part of question 1 is 2 points, the first for labeling the axes correctly and the other for a correctly drawn bar graph. The X (horizontal) axis must be labeled with sugar, with the Y axis (vertical) must be labeled as hyperactivity. To properly draw the bars on this graph and to earn the point, the bars on the graph must be roughly the same length. Where did Students have Difficulty?Although they were able to demonstrate knowledge of an availability heuristic, students had difficulty relating this concept to the research study. Students also had difficulty with the question about the graph, since many students incorrectly labeled the two axes. There is a high probability of receiving questions about graphs and/or research studies, and it’s vital (for the exam and the future) to understand the difference between the x and y-axis and how to properly label them. This question follows the typical AP® Psychology FRQ format. In this question, you are given a scenario and a list of concepts to which you need to relate it. This scenario is that Chandler and Alex have moved to a new city and need to find a new home to live in. After looking at houses, they finally found and bought one that met all their criteria. In each of the different parts, you are given a slightly different aspect of this question with concepts that you need to apply. On question 2, the mean score students received was a 2.64 out of 7. In Part A of this question, you need to explain how the following concepts relate to Chandler and Alex’s decision to buy a home: prefrontal cortex and algorithm. First, for prefrontal cortex, it is important to remember that your prefrontal cortex regulates executive functioning. First, you need to specify an active cognitive process (such as executive functioning) and give an example of how Chandler and Alex would use it towards their decision of buying a home. For example, you could say that Chandler and Alex used their prefrontal corticies/executive functioning to weigh the pros and cons of the houses. Next, for algorithm, you need to give a step-by-step procedure that Chandler and Alex would use in order to make their decision. For example, you could say that they created a formula in order to figure out how much money they could spend on a house. In Part B , the situation is about Chandler and Alex packing to move. At first they asked their friends to help them move. One week before the day they thought they were moving, they were told they needed to move out within 48 hours and had to hurry and quickly finish packing. You need to explain how these concepts relate to the moving process: social loafing and alarm stage of the general adaptation syndrome. First, remember that you need to apply social loafing to the moving process. For this point, you have to explain the connection between the presence of others and a decrease in effort. For example, you could say that since there were a lot of people packing, everyone slacked off and each individual assumed someone else would pack. Next, for the alarm stage of the general adaptation syndrome, you must refer to this physiological response and relate it to the moving process. For example, your answer could be that once they found out they had 48 hours to move out, their body entered the alarm stage and increased their adrenaline, allowing them to work faster. For Part C , you need to take the following concepts and explain how they relate to Chandler and Alex’s new life in the new home and neighborhood: proactive interference, habituation, and normative social influence. First, for proactive interference, your example must demonstrate how old thoughts or behaviors would create difficulty in learning or remembering new thoughts or behaviors. A simple example would be that both Alex and Chandler had difficulty memorizing their new address because they kept remembering their old one. Second, for habituation, you have to connect a decreased responsiveness to a specific recurring stimulus. For example, if Alex and Chandler lived near train tracks, they would most likely be able to hear the train whenever it passed by. However, they stopped actively hearing the train whenever it passed by because they became habituated to it. Finally, for normative social influence , you must give an example of a specific behavior that is in agreement with a group, and you must also reference the motivation to fit in or be liked. For example, if Chandler and Alex lived in a neighborhood where everyone had flags on their front lawn, Chandler and Alex would put a flag on their lawn in order to be accepted. Students mainly had difficulty with the prefrontal cortex in terms of specifying a cognitive process (such as decision-making or planning). For that point, students needed to specifically demonstrate the deliberative nature of how the prefrontal cortex is the processing center of our brain. Another point they had a difficult time with was the alarm stage of general adaptation syndrome. Many students incorrectly associated this stage with panic rather than just an increased level of physiological stress. The most important thing to keep in mind when you are given the AP® Psychology FRQ is that you cannot get away with just definitions alone! You need to demonstrate that you understand the concepts well enough to apply them to specific scenarios. With the research study question, you need to be able to demonstrate your ability to critically analyze a study. Many students who take the AP® Psychology exam struggle with the AP® Psychology FRQ . As you can see for this test, the mean score was less than half for both questions. However, the best way to overcome this is through FRQ practice. And remember, don’t ever leave a part blank! Even if you are unsure or you completely can’t remember something, try and put down whatever you can. The only way to ensure you won’t get a point is by leaving a part blank. So, that’s it for this Ultimate Guide to the 2015 AP® Psychology FRQs ! Do you need help with review for a different psychological concept? Check out some of our review articles, like our AP® Psychology Bystander Effect Review . Is there a topic that you want us to cover, but you can’t find it on the blog? Make sure to let us know! And good luck on your exam this year! Looking for AP® Psychology practice?Kickstart your AP® Psychology prep with Albert. Start your AP® exam prep today . Interested in a school license?Popular posts.  AP® Score CalculatorsSimulate how different MCQ and FRQ scores translate into AP® scores  AP® Review GuidesThe ultimate review guides for AP® subjects to help you plan and structure your prep.  Core Subject Review GuidesReview the most important topics in Physics and Algebra 1 . 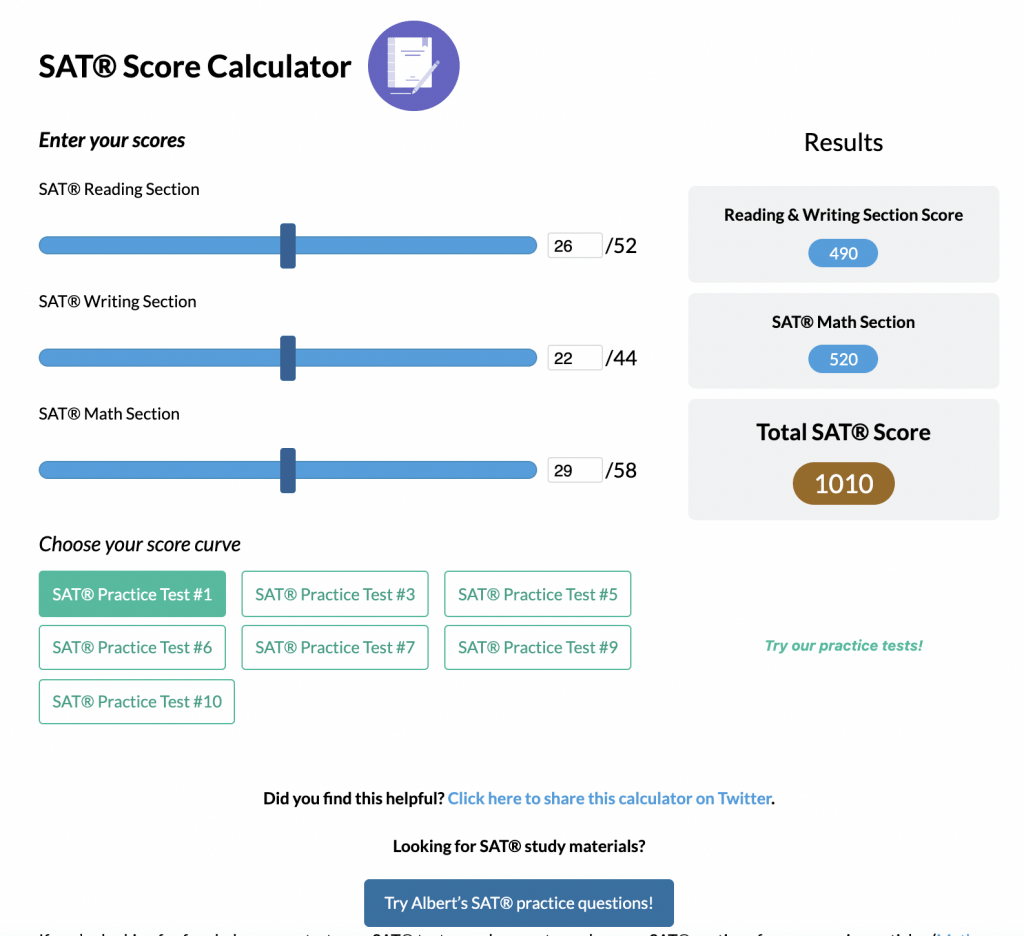 SAT® Score CalculatorSee how scores on each section impacts your overall SAT® score 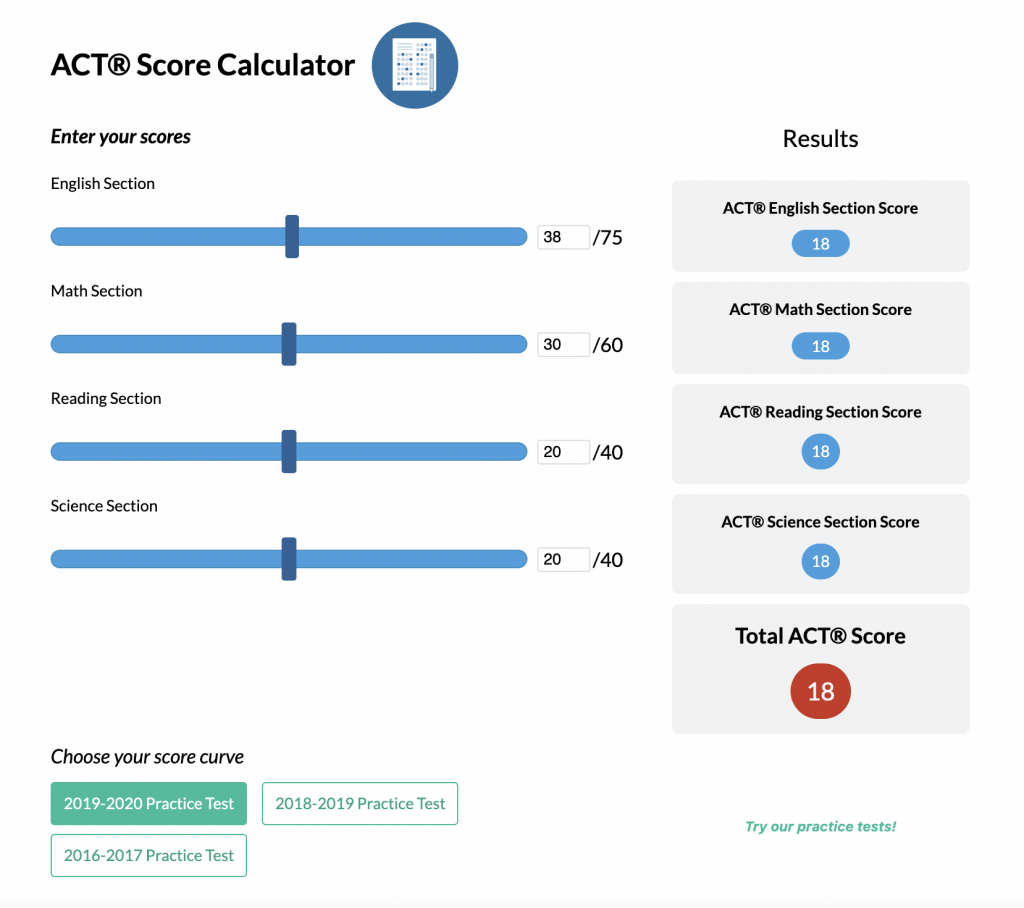 ACT® Score CalculatorSee how scores on each section impacts your overall ACT® score  Grammar Review HubComprehensive review of grammar skills  AP® PostersDownload updated posters summarizing the main topics and structure for each AP® exam. | ||||||||||||||||||||||||||||||||||||||||||||||
IMAGES
VIDEO
COMMENTS
Random sampling (also called probability sampling or random selection) is a way of selecting members of a population to be included in your study. In contrast, random assignment is a way of sorting the sample participants into control and experimental groups. While random sampling is used in many types of studies, random assignment is only used ...
Random selection (also called probability sampling or random sampling) is a way of randomly selecting members of a population to be included in your study. On the other hand, random assignment is a way of sorting the sample participants into control and treatment groups. Random selection ensures that everyone in the population has an equal ...
Random assignment, while methodologically sound, can also present ethical dilemmas. In some cases, withholding a potentially beneficial treatment from one of the groups of participants can raise serious ethical questions, especially in medical or clinical research where participants' well-being might be directly affected.
Materio / Getty Images. Random assignment refers to the use of chance procedures in psychology experiments to ensure that each participant has the same opportunity to be assigned to any given group in a study to eliminate any potential bias in the experiment at the outset. Participants are randomly assigned to different groups, such as the ...
Random assignment or random placement is an experimental technique for assigning human participants or animal subjects to different groups in an experiment (e.g., a treatment group versus a control group) using randomization, such as by a chance procedure (e.g., flipping a coin) or a random number generator. [1] This ensures that each participant or subject has an equal chance of being placed ...
Random assignment is complex in theory but can be simple in practice. If there are only two groups, as in the headache medicine example, a coin toss can be used to assign participants to the ...
If there are two conditions in an experiment, then the simplest way to implement random assignment is to flip a coin for each participant. Heads means being assigned to the treatment and tails means being assigned to the control (or vice versa). 3. Rolling a die. Rolling a single die is another way to randomly assign participants.
Correlation, Causation, and Confounding Variables. Random assignment helps you separate causation from correlation and rule out confounding variables. As a critical component of the scientific method, experiments typically set up contrasts between a control group and one or more treatment groups. The idea is to determine whether the effect, which is the difference between a treatment group and ...
Research Methods. Random assignment means that every participant has the same chance of being chosen for the experimental or control group. It involves using procedures that rely on chance to assign participants to groups. Doing this means that every participant in a study has an equal opportunity to be assigned to any group.
Random distribution can be achieved by an automatized process, like a random number generator, pre-existing lists for assigning the subjects to the groups in a certain order, or even a coin flip. Importantly, random assignment cannot ensure that the distributions of gender, age, and other potential confounds are the same across all groups.
Random assignment is a procedure used in experiments to create multiple study groups that include participants with similar characteristics so that the groups are equivalent at the beginning of the study. The procedure involves assigning individuals to an experimental treatment or program at random, or by chance (like the flip of a coin).
Introduction. Statistical inference is based on the theory of probability, and effects investigated in psycholog-ical studies are de fined by measures that are treated as random variables. The inference about the probability of a given result with regard to an assumed population and the popular term "signif-icance are only meaningful and ...
Rules + Random Number Generation. A set of rules may be applied to random assignment to ensure that treatment and control groups are balanced. For example, in a medical study, a rule could be applied that each group have an equal number of men and women. This could be implemented by applying random assignment separately for male and female ...
Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other fields too. In its strictest sense, random assignment should meet two criteria. One is that each participant has an equal chance of being assigned to each condition ...
1.1 Describe key concepts, principles, and overarching themes in psychology 2.4 Interpret, design, and conduct basic psychological research ... They must explain how and why researchers use random assignment. Teachers can use this student-response to judge the extent to which students understood the teacher-led activity. During class/outside of ...
Randomizing key steps during experimentation for unbiased results. Aside from controlling variables, randomization is likely the most forgotten, most important, and easiest to implement concept related to experimentation. People have a hard time predicting or emulating random events. This is part of the reason that games such as poker, dice or ...
Random Assignment Examples. 1. Pharmaceutical Efficacy Study. In this type of research, consider a scenario where a pharmaceutical company wishes to test the potency of two different versions of a medication, Medication A and Medication B. The researcher recruits a group of volunteers and randomly assigns them to receive either Medication A or ...
A random assignment is envy free if everyone prefers his or her assignment to the assignment of anyone else (i.e. his or her assignment stchastically domonates the assignments of others). Therorem: For any reported preferences, the PS mechanism produces an envy-free assignment with respect to the reported preferences.
General Summary. A true experiment is characterized by a high degree of experimental control, the hallmark of which is random assignment. The research techniques described in this chapter provide the tools with which a researcher can confidently answer questions in the field of behavioral research.
Random selection is thus essential to external validity, or the extent to which the researcher can use the results of the study to generalize to the larger population. Random assignment is central to internal validity, which allows the researcher to make causal claims about the effect of the treatment. Nonrandom assignment often leads to non ...
Skip to content. Mental Health Menu Toggle. Anxiety; Hyperactivity; Depression; Bulimia Nervosa; Dementia
Random selection, or random sampling, is a way of selecting members of a population for your study's sample. In contrast, random assignment is a way of sorting the sample into control and experimental groups. Random sampling enhances the external validity or generalizability of your results, while random assignment improves the internal ...
Describe how Random Assignment can be Achieved . To answer this question, you must understand how random assignment works. Essentially, you have to provide an explanation of how all the subjects have an equal probability of being placed into either of the groups or conditions. Don't get random assignment confused with random selection! Part C: