100 Most Popular Courses For September


Harvard and MIT’s $800 Million Mistake: The Triple Failure of 2U, edX, and Axim Collaborative
The future of Coursera’s only credible alternative for universities rests in the hands of 2U’s creditors.
- 1000s of Free Digital Marketing Courses
- 10 Best Data Analysis Courses for 2024: From Data to Insights
- Replacing Bad Study Habits with Effective Learning Techniques
- [2024] 1800+ Coursera Courses Still Completely Free
- 7 Best Autodesk Maya Courses for 2024: Exploring 3D Animation
600 Free Google Certifications
Most common
Popular subjects.
Communication Skills
Data Analysis
Popular courses
The Emergence of the Modern Middle East - Part I
Whole genome sequencing of bacterial genomes - tools and applications
Positive Psychiatry and Mental Health
Organize and share your learning with Class Central Lists.
View our Lists Showcase
Quantitative Research Courses and Certifications
Learn Quantitative Research, earn certificates with paid and free online courses from Harvard, MIT, The Open University, University of Toronto and other top universities around the world. Read reviews to decide if a class is right for you.
- Statistics & Probability Courses
- Data Analysis Courses
- Research Methods Courses
- Econometrics Courses
- SPSS Courses
- R Programming Courses
- Survey Design Courses
- Experimental Design Courses
- With certificate (59)
- Free course (49)
- With free certificate (1)
- University course only (41)
- Beginner (27)
- Intermediate (5)
- Advanced (2)
- < 30 mins (3)
- 30 - 60 mins (4)
- 1 - 2 hours (7)
- 2 - 5 hours (9)
- 5 - 10 hours (10)
- 10+ hours (25)
- English (75)
- Italian (1)
- Portuguese (1)
Quantitative Methods
Explore quantitative research methods in social sciences, focusing on scientific principles, research designs, measurement, sampling, and ethics. Gain skills to distinguish between solid research and flawed studies.
- Free Online Course (Audit)
Quantitative Research
Gain insights for data-driven marketing decisions through survey design, implementation, and analysis. Learn to identify opportunities, maximize response rates, and interpret results using statistical models.
- 17 hours 28 minutes
Quantitative Marketing Research
Learn how to design a quantitative market research project, and implement specific methods, interpret data and come up with marketing decisions.
- 5 weeks, 3-4 hours a week
Level I CFA® Prep Course (2023) - Quantitative Methods
Deep dive into Quant with the Bestselling CFA® prep course updated for 2023 exam | With visual learning + Quizzes
- 6 hours 49 minutes
- Paid Course
An Introduction to Online Quantitative Market Research
Learn how to effectively conceptualise, design, execute and apply quantitative online research like a PRO!
- 10 hours 34 minutes
Quantitative Analysis
Learn and review key topics in quantitative decision-making for business, including risk analysis, simulation, inventory models, and linear programming, to enhance your skills and exam performance.
- 7 hours 12 minutes
Quantitative Analysis: Skills Development & Training
Develop strategic management, decision analysis, and project planning skills through comprehensive videos on quantitative analysis techniques and practical applications.
- 2 hours 32 minutes
Learn quantitative marketing research techniques, including value estimation, conjoint analysis, and market segmentation. Gain practical skills in survey design, data interpretation, and ethical considerations for informed decision-making.
- Free Online Course
Explore regression analysis and difference-in-differences methodology using R, with a focus on the Minimum Legal Drinking Age example.
- 1 hour 30 minutes
Quantitative and Mixed Methods Research for Management
Comprehensive exploration of quantitative and mixed methods research, covering problem identification, research design, sampling, data collection, hypothesis testing, and analysis techniques using SPSS.
Quantitative Methods for Biology
Learn introductory programming and data analysis in MATLAB, with applications to biology and medicine.
- 10 weeks, 3-5 hours a week
Quantitative Social Science Methods
First course for incoming Harvard Government Department PhD students; also taken by students in other departments, and students elsewhere through the Harvard Extension School. Instructor: Gary King.
Inclusive Analytic Techniques
Learn techniques to uncover gender-based insights in policies, products, and services. Explore quantitative and qualitative data analysis methods to develop innovative, equitable solutions for diverse communities.
- 8 hours 1 minute
Market Research
Learn comprehensive market research skills, from project initiation to data analysis and presentation. Develop expertise in qualitative and quantitative methods, data visualization, and delivering actionable insights to stakeholders.
- 17 weeks, 4 hours a week
Foundations of Sensory Science
Explore the science of sensory perception, from physiological factors to psychological processes, and learn how to conduct sensory evaluations for various products using human senses.
Never Stop Learning.
Get personalized course recommendations, track subjects and courses with reminders, and more.
Department of Psychology
Quantitative methods (qcr).
Science searches for patterns in data. Quantitative methods are tools for finding and evaluating these patterns. This course introduces foundational concepts in quantitative methods, including data visualization and common statistical tests used in psychological research.
- Search Courses
.jpg)
Target Audience: Early stage postgraduate research students and early career researchers
This course is for you if you have little or no previous experience of quantitative research methods (i.e. methods involving numbers and basic statistics) but feel that there is potential to apply such methods to your research. The course covers different types of quantitative methods including calculation of summary statistics, an introduction to correlation and regression analysis, hypothesis testing and calculating p-values.
This course will be useful if:
You need to apply these methods in your own discipline
You want to assess whether there is potential to use quantitative methods
You need to interpret the output from other quantitative research
Description
This is a two-day introductory course, and does not assume any previous experience of quantitative research methods.
The aim of the course is an introduction to statistics as a whole, but will focus on several common topics of interest to many disciplines. The course does not aim to teach students how to use particular statistical packages, though there will be some examples of implementing statistical methods in R.
The focus is on understanding the topics; applications are shown by simple examples calculated by hand. Although 'by hand' calculations are not common practice in research, their purpose here is for students to gain an insight into how to obtain statistical results and to appreciate the meaning and implications of their output from statistics software.
The course includes the following topics
A description of different types of quantitative data
Strength sand weaknesses of quantitative data
Discussions on data integrity
Describing data graphically
Calculating summary statistics
Measures of correlation
Conducting hypothesis testing
Calculating and interpreting p-values
Introduction to regression analysis
- Disseminating quantitative research
Aims: The aim of the course is to provide a brief introduction to the principles of quantitative research methods.
Objectives:
By the end of the course, you will:
Be able to distinguish between different types of quantitative data
Be able to provide basic numerical summaries of data
Be able to perform hypothesis tests and report p-values
- Be able to interpret simple regressions
Process: A two-day course involving discussion and practical exercises. Course Materials:
You can self-enrol to access the course resources in Moodle by following this link: https://moodle.nottingham.ac.uk/course/view.php?id=140161
Here you will find all the course information for both the online and face to face versions of this course which complement each other, including the slides, pre-recorded tutor videos, workbook and formulae sheet.
You do not need to bring a copy of the workbook, as this is intended to be used as a reference having completed the course. You need to bring a printed copy or have access to the electronic version of the formulae sheet, as this will often be used for exercises during the course.
The R codes used in the class are also available on the course page. The R codes used in the class are also available on the course page. Solutions to exercises can also be checked after completion of the course.
If you cannot access the course page, please email [email protected] . Please note, attendances for courses will be recorded. There are no training points associated with courses run by the Researcher Academy.
Related courses
'Introduction to SPSS' is an online course designed to teach you the basis of IBM® SPSS® Statistics.
'Statistical test advisor' is an online learning tool for those who are familiar with the basics of data collection and analysis and require more information about statistical methods.
Additionally, help is available from the Methods and Data Institute (MDI): PGRs engaged in empirical research for their PhD thesis can call on the MDI for advice on their choice and use of methods and data. MDI often host drop-in sessions especially for PGRs - appointments must be made for this by emailing [email protected]
Research Integrity - stand-alone online course designed to strengthen your awareness of your own responsibilities and accountability when planning and conducting research and provides guidance on what to do should things go wrong. Course Accessibility The following table shows a summary of what is needed to participate in the course. If you feel you will experience any difficulties participating, please let us know via the ‘special requirements’ tab, providing as much information as possible. The special requirements tab can be completed when you book your place. Alternatively, you can contact us directly at [email protected] .
| Print off pre-requisite paperwork/ resources & bring them to the course (optional) | |
| Bring your own laptop/ PC to the course (optional) | |
| Access seminar room on campus | |
| Attend the course at the specified date and time | |
| Watch and listen to the course tutor(s) and/or other attendees | |
| Follow presentation slides during the course |
Booking Conditions
Latecomer policy
Researchers should plan to arrive prior to the advertised course start time. Except for exceptional reasons, there will be no admittance to a Researcher Academy or Faculty Training Programme (FTP) course 15 minutes after the advertised course start time.
Importance of booking commitment
When booking on to a Researcher Academy short course you are entering into a commitment to attend. If you find that you are no longer available to attend you MUST cancel your place (on the system if more than three days before the course) or if at short notice by emailing [email protected] . This will ensure that your place can be offered to another researcher on the waiting list. Failure to cancel a place results in other researchers missing out on places through the waiting list process.
It is unacceptable for researchers to just not attend when booked onto a course. The Researcher Academy maintains records of those who repeatedly do not attend courses they have booked. This may affect future eligibility to book onto further Researcher Academy courses and will affect considerations for Researcher Academy funded opportunities.
| Delegate Price | £0.00 |
| TSA Member Price | £0.00 |
Please fill in this enquiry form, and we will get back to you

NCRM delivers training and resources at core and advanced levels, covering quantitative, qualitative, digital, creative, visual, mixed and multimodal methods
Join our team!
NCRM is looking for a Senior Engagement Manager

Short courses
Browse our calendar of training courses and events

Featured course
30 September 2024

Our resources
NCRM hosts a huge range of online resources, including video tutorials and podcasts, plus an extensive publications catalogue.

Online tutorials
Access more than 90 free research methods tutorials

Resources for trainers
Browse our materials for teachers of research methods
Methods News

Participatory research poses challenges to postgraduate researchers

Winners of NCRM 20th Anniversary Impact Prize announced

The dance of co-production and arts in health
A Quick Guide to Quantitative Research in the Social Sciences
(12 reviews)
Christine Davies, Carmarthen, Wales
Copyright Year: 2020
Last Update: 2021
Publisher: University of Wales Trinity Saint David
Language: English
Formats Available
Conditions of use.
Learn more about reviews.
Reviewed by Jennifer Taylor, Assistant Professor, Texas A&M University-Corpus Christi on 4/18/24
This resource is a quick guide to quantitative research in the social sciences and not a comprehensive resource. It provides a VERY general overview of quantitative research but offers a good starting place for students new to research. It... read more
Comprehensiveness rating: 4 see less
This resource is a quick guide to quantitative research in the social sciences and not a comprehensive resource. It provides a VERY general overview of quantitative research but offers a good starting place for students new to research. It offers links and references to additional resources that are more comprehensive in nature.
Content Accuracy rating: 4
The content is relatively accurate. The measurement scale section is very sparse. Not all types of research designs or statistical methods are included, but it is a guide, so details are meant to be limited.
Relevance/Longevity rating: 4
The examples were interesting and appropriate. The content is up to date and will be useful for several years.
Clarity rating: 5
The text was clearly written. Tables and figures are not referenced in the text, which would have been nice.
Consistency rating: 5
The framework is consistent across chapters with terminology clearly highlighted and defined.
Modularity rating: 5
The chapters are subdivided into section that can be divided and assigned as reading in a course. Most chapters are brief and concise, unless elaboration is necessary, such as with the data analysis chapter. Again, this is a guide and not a comprehensive text, so sections are shorter and don't always include every subtopic that may be considered.
Organization/Structure/Flow rating: 5
The guide is well organized. I appreciate that the topics are presented in a logical and clear manner. The topics are provided in an order consistent with traditional research methods.
Interface rating: 5
The interface was easy to use and navigate. The images were clear and easy to read.
Grammatical Errors rating: 5
I did not notice any grammatical errors.
Cultural Relevance rating: 5
The materials are not culturally insensitive or offensive in any way.
I teach a Marketing Research course to undergraduates. I would consider using some of the chapters or topics included, especially the overview of the research designs and the analysis of data section.
Reviewed by Tiffany Kindratt, Assistant Professor, University of Texas at Arlington on 3/9/24
The text provides a brief overview of quantitative research topics that is geared towards research in the fields of education, sociology, business, and nursing. The author acknowledges that the textbook is not a comprehensive resource but offers... read more
Comprehensiveness rating: 3 see less
The text provides a brief overview of quantitative research topics that is geared towards research in the fields of education, sociology, business, and nursing. The author acknowledges that the textbook is not a comprehensive resource but offers references to other resources that can be used to deepen the knowledge. The text does not include a glossary or index. The references in the figures for each chapter are not included in the reference section. It would be helpful to include those.
Overall, the text is accurate. For example, Figure 1 on page 6 provides a clear overview of the research process. It includes general definitions of primary and secondary research. It would be helpful to include more details to explain some of the examples before they are presented. For instance, the example on page 5 was unclear how it pertains to the literature review section.
In general, the text is relevant and up-to-date. The text includes many inferences of moving from qualitative to quantitative analysis. This was surprising to me as a quantitative researcher. The author mentions that moving from a qualitative to quantitative approach should only be done when needed. As a predominantly quantitative researcher, I would not advice those interested in transitioning to using a qualitative approach that qualitative research would enhance their research—not something that should only be done if you have to.
Clarity rating: 4
The text is written in a clear manner. It would be helpful to the reader if there was a description of the tables and figures in the text before they are presented.
Consistency rating: 4
The framework for each chapter and terminology used are consistent.
Modularity rating: 4
The text is clearly divided into sections within each chapter. Overall, the chapters are a similar brief length except for the chapter on data analysis, which is much more comprehensive than others.
Organization/Structure/Flow rating: 4
The topics in the text are presented in a clear and logical order. The order of the text follows the conventional research methodology in social sciences.
I did not encounter any interface issues when reviewing this text. All links worked and there were no distortions of the images or charts that may confuse the reader.
Grammatical Errors rating: 3
There are some grammatical/typographical errors throughout. Of note, for Section 5 in the table of contents. “The” should be capitalized to start the title. In the title for Table 3, the “t” in typical should be capitalized.
Cultural Relevance rating: 4
The examples are culturally relevant. The text is geared towards learners in the UK, but examples are relevant for use in other countries (i.e., United States). I did not see any examples that may be considered culturally insensitive or offensive in any way.
I teach a course on research methods in a Bachelor of Science in Public Health program. I would consider using some of the text, particularly in the analysis chapter to supplement the current textbook in the future.
Reviewed by Finn Bell, Assistant Professor, University of Michigan, Dearborn on 1/3/24
For it being a quick guide and only 26 pages, it is very comprehensive, but it does not include an index or glossary. read more
For it being a quick guide and only 26 pages, it is very comprehensive, but it does not include an index or glossary.
Content Accuracy rating: 5
As far as I can tell, the text is accurate, error-free and unbiased.
Relevance/Longevity rating: 5
This text is up-to-date, and given the content, unlikely to become obsolete any time soon.
The text is very clear and accessible.
The text is internally consistent.
Given how short the text is, it seems unnecessary to divide it into smaller readings, nonetheless, it is clearly labelled such that an instructor could do so.
The text is well-organized and brings readers through basic quantitative methods in a logical, clear fashion.
Easy to navigate. Only one table that is split between pages, but not in a way that is confusing.
There were no noticeable grammatical errors.
The examples in this book don't give enough information to rate this effectively.
This text is truly a very quick guide at only 26 double-spaced pages. Nonetheless, Davies packs a lot of information on the basics of quantitative research methods into this text, in an engaging way with many examples of the concepts presented. This guide is more of a brief how-to that takes readers as far as how to select statistical tests. While it would be impossible to fully learn quantitative research from such a short text, of course, this resource provides a great introduction, overview, and refresher for program evaluation courses.
Reviewed by Shari Fedorowicz, Adjunct Professor, Bridgewater State University on 12/16/22
The text is indeed a quick guide for utilizing quantitative research. Appropriate and effective examples and diagrams were used throughout the text. The author clearly differentiates between use of quantitative and qualitative research providing... read more
Comprehensiveness rating: 5 see less
The text is indeed a quick guide for utilizing quantitative research. Appropriate and effective examples and diagrams were used throughout the text. The author clearly differentiates between use of quantitative and qualitative research providing the reader with the ability to distinguish two terms that frequently get confused. In addition, links and outside resources are provided to deepen the understanding as an option for the reader. The use of these links, coupled with diagrams and examples make this text comprehensive.
The content is mostly accurate. Given that it is a quick guide, the author chose a good selection of which types of research designs to include. However, some are not provided. For example, correlational or cross-correlational research is omitted and is not discussed in Section 3, but is used as a statistical example in the last section.
Examples utilized were appropriate and associated with terms adding value to the learning. The tables that included differentiation between types of statistical tests along with a parametric/nonparametric table were useful and relevant.
The purpose to the text and how to use this guide book is stated clearly and is established up front. The author is also very clear regarding the skill level of the user. Adding to the clarity are the tables with terms, definitions, and examples to help the reader unpack the concepts. The content related to the terms was succinct, direct, and clear. Many times examples or figures were used to supplement the narrative.
The text is consistent throughout from contents to references. Within each section of the text, the introductory paragraph under each section provides a clear understanding regarding what will be discussed in each section. The layout is consistent for each section and easy to follow.
The contents are visible and address each section of the text. A total of seven sections, including a reference section, is in the contents. Each section is outlined by what will be discussed in the contents. In addition, within each section, a heading is provided to direct the reader to the subtopic under each section.
The text is well-organized and segues appropriately. I would have liked to have seen an introductory section giving a narrative overview of what is in each section. This would provide the reader with the ability to get a preliminary glimpse into each upcoming sections and topics that are covered.
The book was easy to navigate and well-organized. Examples are presented in one color, links in another and last, figures and tables. The visuals supplemented the reading and placed appropriately. This provides an opportunity for the reader to unpack the reading by use of visuals and examples.
No significant grammatical errors.
The text is not offensive or culturally insensitive. Examples were inclusive of various races, ethnicities, and backgrounds.
This quick guide is a beneficial text to assist in unpacking the learning related to quantitative statistics. I would use this book to complement my instruction and lessons, or use this book as a main text with supplemental statistical problems and formulas. References to statistical programs were appropriate and were useful. The text did exactly what was stated up front in that it is a direct guide to quantitative statistics. It is well-written and to the point with content areas easy to locate by topic.
Reviewed by Sarah Capello, Assistant Professor, Radford University on 1/18/22
The text claims to provide "quick and simple advice on quantitative aspects of research in social sciences," which it does. There is no index or glossary, although vocabulary words are bolded and defined throughout the text. read more
The text claims to provide "quick and simple advice on quantitative aspects of research in social sciences," which it does. There is no index or glossary, although vocabulary words are bolded and defined throughout the text.
The content is mostly accurate. I would have preferred a few nuances to be hashed out a bit further to avoid potential reader confusion or misunderstanding of the concepts presented.
The content is current; however, some of the references cited in the text are outdated. Newer editions of those texts exist.
The text is very accessible and readable for a variety of audiences. Key terms are well-defined.
There are no content discrepancies within the text. The author even uses similarly shaped graphics for recurring purposes throughout the text (e.g., arrow call outs for further reading, rectangle call outs for examples).
The content is chunked nicely by topics and sections. If it were used for a course, it would be easy to assign different sections of the text for homework, etc. without confusing the reader if the instructor chose to present the content in a different order.
The author follows the structure of the research process. The organization of the text is easy to follow and comprehend.
All of the supplementary images (e.g., tables and figures) were beneficial to the reader and enhanced the text.
There are no significant grammatical errors.
I did not find any culturally offensive or insensitive references in the text.
This text does the difficult job of introducing the complicated concepts and processes of quantitative research in a quick and easy reference guide fairly well. I would not depend solely on this text to teach students about quantitative research, but it could be a good jumping off point for those who have no prior knowledge on this subject or those who need a gentle introduction before diving in to more advanced and complex readings of quantitative research methods.
Reviewed by J. Marlie Henry, Adjunct Faculty, University of Saint Francis on 12/9/21
Considering the length of this guide, this does a good job of addressing major areas that typically need to be addressed. There is a contents section. The guide does seem to be organized accordingly with appropriate alignment and logical flow of... read more
Considering the length of this guide, this does a good job of addressing major areas that typically need to be addressed. There is a contents section. The guide does seem to be organized accordingly with appropriate alignment and logical flow of thought. There is no glossary but, for a guide of this length, a glossary does not seem like it would enhance the guide significantly.
The content is relatively accurate. Expanding the content a bit more or explaining that the methods and designs presented are not entirely inclusive would help. As there are different schools of thought regarding what should/should not be included in terms of these designs and methods, simply bringing attention to that and explaining a bit more would help.
Relevance/Longevity rating: 3
This content needs to be updated. Most of the sources cited are seven or more years old. Even more, it would be helpful to see more currently relevant examples. Some of the source authors such as Andy Field provide very interesting and dynamic instruction in general, but they have much more current information available.
The language used is clear and appropriate. Unnecessary jargon is not used. The intent is clear- to communicate simply in a straightforward manner.
The guide seems to be internally consistent in terms of terminology and framework. There do not seem to be issues in this area. Terminology is internally consistent.
For a guide of this length, the author structured this logically into sections. This guide could be adopted in whole or by section with limited modifications. Courses with fewer than seven modules could also logically group some of the sections.
This guide does present with logical organization. The topics presented are conceptually sequenced in a manner that helps learners build logically on prior conceptualization. This also provides a simple conceptual framework for instructors to guide learners through the process.
Interface rating: 4
The visuals themselves are simple, but they are clear and understandable without distracting the learner. The purpose is clear- that of learning rather than visuals for the sake of visuals. Likewise, navigation is clear and without issues beyond a broken link (the last source noted in the references).
This guide seems to be free of grammatical errors.
It would be interesting to see more cultural integration in a guide of this nature, but the guide is not culturally insensitive or offensive in any way. The language used seems to be consistent with APA's guidelines for unbiased language.
Reviewed by Heng Yu-Ku, Professor, University of Northern Colorado on 5/13/21
The text covers all areas and ideas appropriately and provides practical tables, charts, and examples throughout the text. I would suggest the author also provides a complete research proposal at the end of Section 3 (page 10) and a comprehensive... read more
The text covers all areas and ideas appropriately and provides practical tables, charts, and examples throughout the text. I would suggest the author also provides a complete research proposal at the end of Section 3 (page 10) and a comprehensive research study as an Appendix after section 7 (page 26) to help readers comprehend information better.
For the most part, the content is accurate and unbiased. However, the author only includes four types of research designs used on the social sciences that contain quantitative elements: 1. Mixed method, 2) Case study, 3) Quasi-experiment, and 3) Action research. I wonder why the correlational research is not included as another type of quantitative research design as it has been introduced and emphasized in section 6 by the author.
I believe the content is up-to-date and that necessary updates will be relatively easy and straightforward to implement.
The text is easy to read and provides adequate context for any technical terminology used. However, the author could provide more detailed information about estimating the minimum sample size but not just refer the readers to use the online sample calculators at a different website.
The text is internally consistent in terms of terminology and framework. The author provides the right amount of information with additional information or resources for the readers.
The text includes seven sections. Therefore, it is easier for the instructor to allocate or divide the content into different weeks of instruction within the course.
Yes, the topics in the text are presented in a logical and clear fashion. The author provides clear and precise terminologies, summarizes important content in Table or Figure forms, and offers examples in each section for readers to check their understanding.
The interface of the book is consistent and clear, and all the images and charts provided in the book are appropriate. However, I did encounter some navigation problems as a couple of links are not working or requires permission to access those (pages 10 and 27).
No grammatical errors were found.
No culturally incentive or offensive in its language and the examples provided were found.
As the book title stated, this book provides “A Quick Guide to Quantitative Research in Social Science. It offers easy-to-read information and introduces the readers to the research process, such as research questions, research paradigms, research process, research designs, research methods, data collection, data analysis, and data discussion. However, some links are not working or need permissions to access them (pages 10 and 27).
Reviewed by Hsiao-Chin Kuo, Assistant Professor, Northeastern Illinois University on 4/26/21, updated 4/28/21
As a quick guide, it covers basic concepts related to quantitative research. It starts with WHY quantitative research with regard to asking research questions and considering research paradigms, then provides an overview of research design and... read more
As a quick guide, it covers basic concepts related to quantitative research. It starts with WHY quantitative research with regard to asking research questions and considering research paradigms, then provides an overview of research design and process, discusses methods, data collection and analysis, and ends with writing a research report. It also identifies its target readers/users as those begins to explore quantitative research. It would be helpful to include more examples for readers/users who are new to quantitative research.
Its content is mostly accurate and no bias given its nature as a quick guide. Yet, it is also quite simplified, such as its explanations of mixed methods, case study, quasi-experimental research, and action research. It provides resources for extended reading, yet more recent works will be helpful.
The book is relevant given its nature as a quick guide. It would be helpful to provide more recent works in its resources for extended reading, such as the section for Survey Research (p. 12). It would also be helpful to include more information to introduce common tools and software for statistical analysis.
The book is written with clear and understandable language. Important terms and concepts are presented with plain explanations and examples. Figures and tables are also presented to support its clarity. For example, Table 4 (p. 20) gives an easy-to-follow overview of different statistical tests.
The framework is very consistent with key points, further explanations, examples, and resources for extended reading. The sample studies are presented following the layout of the content, such as research questions, design and methods, and analysis. These examples help reinforce readers' understanding of these common research elements.
The book is divided into seven chapters. Each chapter clearly discusses an aspect of quantitative research. It can be easily divided into modules for a class or for a theme in a research method class. Chapters are short and provides additional resources for extended reading.
The topics in the chapters are presented in a logical and clear structure. It is easy to follow to a degree. Though, it would be also helpful to include the chapter number and title in the header next to its page number.
The text is easy to navigate. Most of the figures and tables are displayed clearly. Yet, there are several sections with empty space that is a bit confusing in the beginning. Again, it can be helpful to include the chapter number/title next to its page number.
Grammatical Errors rating: 4
No major grammatical errors were found.
There are no cultural insensitivities noted.
Given the nature and purpose of this book, as a quick guide, it provides readers a quick reference for important concepts and terms related to quantitative research. Because this book is quite short (27 pages), it can be used as an overview/preview about quantitative research. Teacher's facilitation/input and extended readings will be needed for a deeper learning and discussion about aspects of quantitative research.
Reviewed by Yang Cheng, Assistant Professor, North Carolina State University on 1/6/21
It covers the most important topics such as research progress, resources, measurement, and analysis of the data. read more
It covers the most important topics such as research progress, resources, measurement, and analysis of the data.
The book accurately describes the types of research methods such as mixed-method, quasi-experiment, and case study. It talks about the research proposal and key differences between statistical analyses as well.
The book pinpointed the significance of running a quantitative research method and its relevance to the field of social science.
The book clearly tells us the differences between types of quantitative methods and the steps of running quantitative research for students.
The book is consistent in terms of terminologies such as research methods or types of statistical analysis.
It addresses the headlines and subheadlines very well and each subheading should be necessary for readers.
The book was organized very well to illustrate the topic of quantitative methods in the field of social science.
The pictures within the book could be further developed to describe the key concepts vividly.
The textbook contains no grammatical errors.
It is not culturally offensive in any way.
Overall, this is a simple and quick guide for this important topic. It should be valuable for undergraduate students who would like to learn more about research methods.
Reviewed by Pierre Lu, Associate Professor, University of Texas Rio Grande Valley on 11/20/20
As a quick guide to quantitative research in social sciences, the text covers most ideas and areas. read more
As a quick guide to quantitative research in social sciences, the text covers most ideas and areas.
Mostly accurate content.
As a quick guide, content is highly relevant.
Succinct and clear.
Internally, the text is consistent in terms of terminology used.
The text is easily and readily divisible into smaller sections that can be used as assignments.
I like that there are examples throughout the book.
Easy to read. No interface/ navigation problems.
No grammatical errors detected.
I am not aware of the culturally insensitive description. After all, this is a methodology book.
I think the book has potential to be adopted as a foundation for quantitative research courses, or as a review in the first weeks in advanced quantitative course.
Reviewed by Sarah Fischer, Assistant Professor, Marymount University on 7/31/20
It is meant to be an overview, but it incredibly condensed and spends almost no time on key elements of statistics (such as what makes research generalizable, or what leads to research NOT being generalizable). read more
It is meant to be an overview, but it incredibly condensed and spends almost no time on key elements of statistics (such as what makes research generalizable, or what leads to research NOT being generalizable).
Content Accuracy rating: 1
Contains VERY significant errors, such as saying that one can "accept" a hypothesis. (One of the key aspect of hypothesis testing is that one either rejects or fails to reject a hypothesis, but NEVER accepts a hypothesis.)
Very relevant to those experiencing the research process for the first time. However, it is written by someone working in the natural sciences but is a text for social sciences. This does not explain the errors, but does explain why sometimes the author assumes things about the readers ("hail from more subjectivist territory") that are likely not true.
Clarity rating: 3
Some statistical terminology not explained clearly (or accurately), although the author has made attempts to do both.
Very consistently laid out.
Chapters are very short yet also point readers to outside texts for additional information. Easy to follow.
Generally logically organized.
Easy to navigate, images clear. The additional sources included need to linked to.
Minor grammatical and usage errors throughout the text.
Makes efforts to be inclusive.
The idea of this book is strong--short guides like this are needed. However, this book would likely be strengthened by a revision to reduce inaccuracies and improve the definitions and technical explanations of statistical concepts. Since the book is specifically aimed at the social sciences, it would also improve the text to have more examples that are based in the social sciences (rather than the health sciences or the arts).
Reviewed by Michelle Page, Assistant Professor, Worcester State University on 5/30/20
This text is exactly intended to be what it says: A quick guide. A basic outline of quantitative research processes, akin to cliff notes. The content provides only the essentials of a research process and contains key terms. A student or new... read more
This text is exactly intended to be what it says: A quick guide. A basic outline of quantitative research processes, akin to cliff notes. The content provides only the essentials of a research process and contains key terms. A student or new researcher would not be able to use this as a stand alone guide for quantitative pursuits without having a supplemental text that explains the steps in the process more comprehensively. The introduction does provide this caveat.
Content Accuracy rating: 3
There are no biases or errors that could be distinguished; however, it’s simplicity in content, although accurate for an outline of process, may lack a conveyance of the deeper meanings behind the specific processes explained about qualitative research.
The content is outlined in traditional format to highlight quantitative considerations for formatting research foundational pieces. The resources/references used to point the reader to literature sources can be easily updated with future editions.
The jargon in the text is simple to follow and provides adequate context for its purpose. It is simplified for its intention as a guide which is appropriate.
Each section of the text follows a consistent flow. Explanation of the research content or concept is defined and then a connection to literature is provided to expand the readers understanding of the section’s content. Terminology is consistent with the qualitative process.
As an “outline” and guide, this text can be used to quickly identify the critical parts of the quantitative process. Although each section does not provide deeper content for meaningful use as a stand alone text, it’s utility would be excellent as a reference for a course and can be used as an content guide for specific research courses.
The text’s outline and content are aligned and are in a logical flow in terms of the research considerations for quantitative research.
The only issue that the format was not able to provide was linkable articles. These would have to be cut and pasted into a browser. Functional clickable links in a text are very successful at leading the reader to the supplemental material.
No grammatical errors were noted.
This is a very good outline “guide” to help a new or student researcher to demystify the quantitative process. A successful outline of any process helps to guide work in a logical and systematic way. I think this simple guide is a great adjunct to more substantial research context.
Table of Contents
- Section 1: What will this resource do for you?
- Section 2: Why are you thinking about numbers? A discussion of the research question and paradigms.
- Section 3: An overview of the Research Process and Research Designs
- Section 4: Quantitative Research Methods
- Section 5: the data obtained from quantitative research
- Section 6: Analysis of data
- Section 7: Discussing your Results
Ancillary Material
About the book.
This resource is intended as an easy-to-use guide for anyone who needs some quick and simple advice on quantitative aspects of research in social sciences, covering subjects such as education, sociology, business, nursing. If you area qualitative researcher who needs to venture into the world of numbers, or a student instructed to undertake a quantitative research project despite a hatred for maths, then this booklet should be a real help.
The booklet was amended in 2022 to take into account previous review comments.
About the Contributors
Christine Davies , Ph.D
Contribute to this Page
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- What Is Quantitative Research? | Definition, Uses & Methods
What Is Quantitative Research? | Definition, Uses & Methods
Published on June 12, 2020 by Pritha Bhandari . Revised on June 22, 2023.
Quantitative research is the process of collecting and analyzing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalize results to wider populations.
Quantitative research is the opposite of qualitative research , which involves collecting and analyzing non-numerical data (e.g., text, video, or audio).
Quantitative research is widely used in the natural and social sciences: biology, chemistry, psychology, economics, sociology, marketing, etc.
- What is the demographic makeup of Singapore in 2020?
- How has the average temperature changed globally over the last century?
- Does environmental pollution affect the prevalence of honey bees?
- Does working from home increase productivity for people with long commutes?
Table of contents
Quantitative research methods, quantitative data analysis, advantages of quantitative research, disadvantages of quantitative research, other interesting articles, frequently asked questions about quantitative research.
You can use quantitative research methods for descriptive, correlational or experimental research.
- In descriptive research , you simply seek an overall summary of your study variables.
- In correlational research , you investigate relationships between your study variables.
- In experimental research , you systematically examine whether there is a cause-and-effect relationship between variables.
Correlational and experimental research can both be used to formally test hypotheses , or predictions, using statistics. The results may be generalized to broader populations based on the sampling method used.
To collect quantitative data, you will often need to use operational definitions that translate abstract concepts (e.g., mood) into observable and quantifiable measures (e.g., self-ratings of feelings and energy levels).
| Research method | How to use | Example |
|---|---|---|
| Control or manipulate an to measure its effect on a dependent variable. | To test whether an intervention can reduce procrastination in college students, you give equal-sized groups either a procrastination intervention or a comparable task. You compare self-ratings of procrastination behaviors between the groups after the intervention. | |
| Ask questions of a group of people in-person, over-the-phone or online. | You distribute with rating scales to first-year international college students to investigate their experiences of culture shock. | |
| (Systematic) observation | Identify a behavior or occurrence of interest and monitor it in its natural setting. | To study college classroom participation, you sit in on classes to observe them, counting and recording the prevalence of active and passive behaviors by students from different backgrounds. |
| Secondary research | Collect data that has been gathered for other purposes e.g., national surveys or historical records. | To assess whether attitudes towards climate change have changed since the 1980s, you collect relevant questionnaire data from widely available . |
Note that quantitative research is at risk for certain research biases , including information bias , omitted variable bias , sampling bias , or selection bias . Be sure that you’re aware of potential biases as you collect and analyze your data to prevent them from impacting your work too much.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

Once data is collected, you may need to process it before it can be analyzed. For example, survey and test data may need to be transformed from words to numbers. Then, you can use statistical analysis to answer your research questions .
Descriptive statistics will give you a summary of your data and include measures of averages and variability. You can also use graphs, scatter plots and frequency tables to visualize your data and check for any trends or outliers.
Using inferential statistics , you can make predictions or generalizations based on your data. You can test your hypothesis or use your sample data to estimate the population parameter .
First, you use descriptive statistics to get a summary of the data. You find the mean (average) and the mode (most frequent rating) of procrastination of the two groups, and plot the data to see if there are any outliers.
You can also assess the reliability and validity of your data collection methods to indicate how consistently and accurately your methods actually measured what you wanted them to.
Quantitative research is often used to standardize data collection and generalize findings . Strengths of this approach include:
- Replication
Repeating the study is possible because of standardized data collection protocols and tangible definitions of abstract concepts.
- Direct comparisons of results
The study can be reproduced in other cultural settings, times or with different groups of participants. Results can be compared statistically.
- Large samples
Data from large samples can be processed and analyzed using reliable and consistent procedures through quantitative data analysis.
- Hypothesis testing
Using formalized and established hypothesis testing procedures means that you have to carefully consider and report your research variables, predictions, data collection and testing methods before coming to a conclusion.
Despite the benefits of quantitative research, it is sometimes inadequate in explaining complex research topics. Its limitations include:
- Superficiality
Using precise and restrictive operational definitions may inadequately represent complex concepts. For example, the concept of mood may be represented with just a number in quantitative research, but explained with elaboration in qualitative research.
- Narrow focus
Predetermined variables and measurement procedures can mean that you ignore other relevant observations.
- Structural bias
Despite standardized procedures, structural biases can still affect quantitative research. Missing data , imprecise measurements or inappropriate sampling methods are biases that can lead to the wrong conclusions.
- Lack of context
Quantitative research often uses unnatural settings like laboratories or fails to consider historical and cultural contexts that may affect data collection and results.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Chi square goodness of fit test
- Degrees of freedom
- Null hypothesis
- Discourse analysis
- Control groups
- Mixed methods research
- Non-probability sampling
- Inclusion and exclusion criteria
Research bias
- Rosenthal effect
- Implicit bias
- Cognitive bias
- Selection bias
- Negativity bias
- Status quo bias
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organizations.
Operationalization means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioral avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalize the variables that you want to measure.
Reliability and validity are both about how well a method measures something:
- Reliability refers to the consistency of a measure (whether the results can be reproduced under the same conditions).
- Validity refers to the accuracy of a measure (whether the results really do represent what they are supposed to measure).
If you are doing experimental research, you also have to consider the internal and external validity of your experiment.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bhandari, P. (2023, June 22). What Is Quantitative Research? | Definition, Uses & Methods. Scribbr. Retrieved September 9, 2024, from https://www.scribbr.com/methodology/quantitative-research/
Is this article helpful?

Pritha Bhandari
Other students also liked, descriptive statistics | definitions, types, examples, inferential statistics | an easy introduction & examples, get unlimited documents corrected.
✔ Free APA citation check included ✔ Unlimited document corrections ✔ Specialized in correcting academic texts

Subscribe to Our Newsletter
Short Courses
We are committed to advancing social science research through education and training. Each year we offer 100+ short courses on a range of topics in the social and behavioral sciences.
Short Course Categories
More than 2,250 participants, including UNC undergraduate and graduate students, faculty and staff, attend our short courses annually. A number of courses are also open to researchers from not-for-profit organizations, government agencies, and corporations.
Many of our courses are free for the UNC students – you just need to secure your spot with a small deposit that is refundable upon attendance for the full course. These courses fill up on a first-come, first-served basis. Courses that require non-refundable registration fees will indicate as much on the individual event pages.
Short course categories include:
- Quantitative Analysis : Upcoming short courses in quantitative data analysis/statistical software
- Qualitative Research : Upcoming short courses in qualitative research methods/data analysis
- Survey Research : Upcoming short courses in survey research
- Data Science : Upcoming short courses in data science
- Professional Development : Upcoming short courses highlighting skills for professionals and academics
For a list of all current short courses, visit our events calendar: https://odum.unc.edu/events/
For a pdf of our short course listings, download here., education staff.

Victoria Hammet, Phd Assistant Director, Education and Evaluation

Paul Mihas Assistant Director of Qualitative and Mixed Methods Research
[email protected] 919-962-0513.

Jill Stevens Education Coordinator
We are always looking for better ways to serve the campus community. Is there a short course you would like to see offered? Use the form below to submit a short course suggestion.
Before submitting your suggestion, check out our list of current and past courses above. Feel free to submit a past offering or indicate that you would like to see more offerings of a current course in your submission.
Request a Short Course
- Name * First Last
- I am: * Undergraduate Student Graduate Student University Staff University Faculty University Post-Doc/Resident/Visiting Scholar Corporate employee Non-profit employee Government employee
- Under which category would your short course or topic be considered? * Qualitative (Text) Analysis Data Science and Statistical Analysis Data Collection – Quantitative and Qualitative Methodologies Professional Development Other
- Please enter the short course or topic you would like to request *
- Odum schedules short courses 6-12 months in advance. Please list dates/times your would like to see this course offered * (please be as specific as possible)
- How would this course help you?
- Do you know anyone else who might be interested in this course?
Back to top
Browser does not support script.
Advanced Quantitative Research Methods 7KNIP042
Key information, subject area:.
Nursing, Midwifery & Palliative Care
Course type:
Assessed Module
Credit level:
Credit value:, available course dates:.
From: 08 October 2024 To: 12 November 2024
Course overview
This module forms part of the MRES Clinical Research. The module contributes to your programme of study by providing a solid grounding in quantitative research methods, providing you with skills for designing, conducting and appraising your own and others’ research. This is the first module of the programme and provides a foundation for your research methods training, complemented by the Advanced Qualitative Research Methods module taken in term 2.
The module is for PGR students and MSc students only. Not available as Free Standing Module.
What will I achieve?
Participants will develop:
- Advanced understanding of key approaches in quantitative health research.
- Advanced understanding of the application and use of appropriate quantitative research methods.
- Advanced understanding of stages involved in undertaking quantitative research methods.
- Advanced understanding of stages involved in undertaking quantitative research.
- Advanced critical appraisal skills to interrogate the application of quantitative research approaches and methods.
- Advanced skills in selecting and conducting appropriate statistical tests for quantitative data.
The content of this module will include:
- Research design and data collection approaches.
- Surveys, case-control, and cohort studies.
- Clinical trials.
- Prognostic and diagnostic tests.
- Data types and distribution.
- Access and ethics.
- Hypothesis testing.
- Samples and populations.
- Approaches to analyses: comparisons, regression, correlation.
- Analysis of categorical and continuous data.
- Combining the results of independent studies.
Who will I learn with?

Associate Dean (Postgraduate Research Studies) and Senior Lecturer in Mental Health
Who is this for?
Healthcare professionals
How will I be assessed?
3000 word assignment. Critical appraisal of a quantitative research paper.
What is the teaching schedule?
08/10/2024, 15/10, 22/10, 29/10, 05/11, 12/11
Course status:
Full fee £3400
To find out more about this module, please contact Module lead Vasiliki Tzouvara.
- [email protected]
- Florence Nightingale Faculty of Nursing, Midwifery & Palliative Care

Quantitative Methodology: Measurement and Statistics, M.S.
Fall, Spring
Full-time Part-time
- September 27, 2024 (Spring 2025)
- December 3, 2024 (Fall 2025)
June 30, 2025
In-State - $12,540 Out-of-State - $26,490 More Info
This Quantitative Methodology: Measurement and Statistics, Master of Science (M.S.) program provides you with advanced training in quantitative research methods and statistical analysis. You will learn to design and conduct research studies, analyze data using sophisticated statistical techniques, and interpret and present research findings effectively. We emphasize both theoretical knowledge and practical skills, preparing you for careers in any industry. Whether pursuing further graduate studies or entering the workforce directly, you will be well-prepared to contribute to the advancement of knowledge in your chosen field.
Key Features
- Balanced Training : Gain comprehensive skills in quantitative methods suitable for various professional settings.
- Proximity to Washington, D.C. : Access diverse academic and professional opportunities in the nation's capital.
- Rigorous Core Curriculum : Master key concepts in applied measurement, statistical modeling, and evaluation methods.
- Flexibility : Choose from a range of elective courses to deepen your expertise in specific areas of interest.
- Demonstrate proficiency in applied measurement, statistical analysis, and research design.
- Apply quantitative methods to address complex research questions in diverse contexts.
- Evaluate and critique research literature and methodologies in the field of quantitative methodology.
- Communicate quantitative findings effectively to diverse audiences through written reports and presentations.
This program offers a wide range of career pathways, including:
- Research Associate
- Data Analyst
- Policy Analyst
- Evaluation Specialist
Click on admissions button below to swap url
Admission Requirements Guide to Applying
You are required to submit all required documents before submitting the application.
Program Specific Requirements
- Letters of Recommendation (3)
- Graduate Record Examination (GRE)
- Writing Sample (1)
Marieh Arnett, student, Quantitative Methodology: Measurement and Statistics
Courses in this program are carefully selected and highly customizable to give you the best possible experience. Your specific program of study will be structured to take into account your background and aspirations. Both thesis and non-thesis options are available.
QMMS Graduate Student Handbook
There is a common core of courses comprised of:
- EDMS 623 Applied Measurement: Issues and Practices (3)
- EDMS 646 General Linear Models I (3)
- EDMS 647 Causal Inference and Evaluation Methods (3)
- EDMS 651 General Linear Models II (3)
- EDMS 655 Introduction to Multilevel Modeling (3)
- EDMS 657 Exploratory Latent and Composite Variable Methods (3)
- EDMS 724 Modern Measurement Theory (3)
Additional elective coursework completes the program. A written comprehensive examination based on the first four courses of the core is required. The Graduate School allows transfer of up to six credits of appropriate prior graduate work.

Sep 17 Graduate Fair Expo Sep 17, 2024 4:00 – 6:00 pm
Cookies on our website
We use some essential cookies to make this website work.
We'd like to set additional cookies to understand how you use our site so we can improve it for everyone. Also, we'd like to serve you some cookies set by other services to show you relevant content.
Quantitative Methods and Research Design (854N1)
15 credits, Level 7 (Masters)
Autumn teaching
Contact hours and workload
We regularly review our modules to incorporate student feedback, staff expertise, as well as the latest research and teaching methodology. We’re planning to run these modules in the academic year 2024/25. However, there may be changes to these modules in response to feedback, staff availability, student demand or updates to our curriculum. We’ll make sure to let you know of any material changes to modules at the earliest opportunity.
- Introduction
- 1.1. Seminar
- 1.2. Solutions
- 2.1. Seminar
- 2.2. Solutions
- 3.1. Seminar
- 3.2. Solutions
- 4.1. Seminar
- 4.2. Solutions
- 5.1. Seminar
- 5.2. Solutions
- 6.1. Seminar
- 6.2. Solutions
- 7.1. Seminar
- 7.2. Solutions
- 8.1. Seminar
- 8.2. Solutions
- 9.1. Seminar
- 9.2. Solutions
- 10.1. R on UCL Computers
- 10.2. How to Set Working Directory
- 10.3. Operators in R
- 10.4. Order of Loading Packages
- 10.5. Installing Zelig
- 10.6. Interpreting Zelig Simulation
- 10.7. Common Problems and Solutions
- 10.8. Downloading WDI Dataset
- 11.1. Central Limit Theorem
- 11.2. Linear Regression
- 12. Datasets
- 13. R Resources
- 14. References
- Published with GitBook
Introduction to Quantitative Methods
About this course.
This course is designed to introduce you to and help you become familiar with quantitative methodologies critical to your development as a social scientist. The introductory methods course has two primary aims. First, students will be introduced to quantitative methodology that researchers and policymakers use in answering social, political and economic questions. Second, the course will equip students to use one or more of the discussed techniques in their MSc dissertation.
By the end of the course, you should be able to understand basic research methods, apply them to real world problems and evaluate their use in published research. Students will also acquire competency in performing statistical analyses using a popular statistical program (R).
The assessment for this course is a 24 hour prior disclosure exam which will be completed in the last week of the term.
*Please note that this module is only available to SPP students. Students taking this module are not permitted to take PUBLG088 Advanced Quantitative Methods.
You can also access this site with a short URL: http://bit.ly/PUBLG100
Psychological resilience and valued living in difficult times: mixed method research in cultural context
- Published: 12 September 2024
Cite this article

- Feyza Topçu ORCID: orcid.org/0000-0002-5853-2670 1 &
- Mehmet Dinç ORCID: orcid.org/0000-0001-9544-8999 1
2 Altmetric
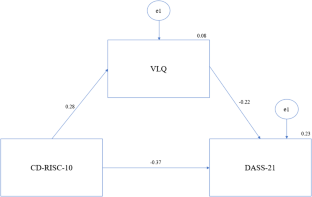
Valued living involves aligning one’s actions with one’s personal values, which can contribute to mental strength and psychological resilience. The present study aimed to examine the importance of living a valued life in maintaining mental strength, particularly during challenging times. In addition, it identifies the culturally relevant values that strengthen adults. Our study used both quantitative and qualitative methods. In the quantitative phase, 493 adults completed the following scales Valued Living Questionnaire (VLQ), Connor-Davidson Resilience Scale Short Form (CD-RISC-10), and Depression, Anxiety, and Stress Scale (DASS-21). We calculated Pearson’s product-moment correlation coefficient and used structural equation modeling (SEM) to conduct the path analysis. For the qualitative phase, we recruited 15 participants from a larger quantitative sample based on their scores obtained on administered scales and conducted in-depth interviews along with researcher’s journal and memos. Based on our quantitative findings, this study indicates that the concept of valued living serves as a mediating factor between psychological resilience and mental health outcomes. In our qualitative analysis, we identified certain values (e.g., acceptance, love, and goodwill) that serve to empower adults during challenging periods. The findings of this study are deemed to serve as a reference for the formulation and implementation of interventions intended to strengthen psychological resilience, from the viewpoints of both mental health specialists and psychological counselors.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Explore related subjects
- Artificial Intelligence
Data availability
The data sets used in the study can be provided upon request to the corresponding author.
Ağırkan, M., & Kağan, M. (2017). Üniversite Öğrencilerinin Değer Yönelimleri Ile Psikolojik Dayanıklılık Düzeyleri Arasındaki İlişki. Erzincan Üniversitesi Eğitim Fakültesi Dergisi , 19 (3), 225–245. https://doi.org/10.17556/erziefd.335063
Article Google Scholar
Ahmadi, N., Ahmadi, F., Erbil, P., & Cetrez, Ö. A. (2016). Religious meaning-making coping in Turkey: A study among cancer patients. Illness Crisis & Loss , 27 (3), 190–208.
Ahmadi, F., Erbil, P., Ahmadi, N., & Cetrez, Ö. A. (2019). Religion, culture and meaning-making coping: A study among cancer patients in Turkey. Journal of Religion and Health , 58 , 1115–1124.
Article PubMed Google Scholar
Boer, D., & Fischer, R. (2013). How and when do personal values guide our attitudes and sociality? Explaining cross-cultural variability in attitude-value linkages. Psychological Bulletin , 139 (5), 1113–1147. https://doi.org/10.1037/a0031347
Bojanowska, A., & Piotrowski, K. (2021). Two levels of personality: Temperament and values and their effects on hedonic and eudaimonic well-being. Current Psychology , 40 , 1185–1193. https://doi.org/10.1007/s12144-018-0043-0
Campbell-Sills, L., & Stein, M. B. (2007). Psychometric analysis and refinement of the Connor–Davidson Resilience Scale (CD-RISC): Validation of a 10-item measure of resilience. Journal of Traumatic Stress: Official Publication of the International Society for Traumatic Stress Studies , 20 (6), 1019–1028. https://doi.org/10.1002/jts.20271
Carvalho, S. A., Xavier, A., Gillanders, D., Pinto-Gouveia, J., & Castilho, P. (2021). Rumination and valued living in women with chronic pain: How they relate to the link between mindfulness and depressive symptoms. Current Psychology , 40 , 1411–1419. https://doi.org/10.1007/s12144-018-0052-z
Ceary, C. D., Donahue, J. J., & Shaffer, K. (2019). The strength of pursuing your values: Valued living as a path to resilience among college students. Stress and Health , 35 (4), 532–541. https://doi.org/10.1002/smi.2886
Çekici, F., Aydın-Sünbül, Z., Malkoç, A., Aslan-Gördesli, M., & Arslan, R. (2018). Değer Odaklı Yaşam Ölçeği: Türk kültürüne uyarlama, geçerlik ve güvenirlik çalışması. Electronic Turkish Studies , 13 (19), 459–471. https://doi.org/10.7827/TurkishStudies.14094
Cénat, J. M., Kouamou, L. N., Farahi, S. M. M. M., Darius, W. P., Dalexis, R. D., Charles, M., & Kogan, C. S. (2022). Perceived racial discrimination, psychosomatic symptoms, and resilience among black individuals in Canada: A moderated mediation model. Journal of Psychosomatic Research , 163 , 111053. https://doi.org/10.1016/j.jpsychores.2022.111053
Chow, K. M., Tang, W. K. F., Chan, W. H. C., Sit, W. H. J., Choi, K. C., & Chan, S. (2018). Resilience and well-being of university nursing students in Hong Kong: A cross-sectional study. BMC Medical Education , 18 (1), 1–8. https://doi.org/10.1186/s12909-018-1119-0
Connor, K. M., & Davidson, J. R. T. (2003). Development of a new resilience scale: The Connor-Davidson Resilience Scale (CD-RISC). Depression and Anxiety , 18 , 76–82. https://doi.org/10.1002/da.10113
Cooley, S. J., Quinton, M. L., Holland, M. J. G., Parry, B. J., & Cumming, J. (2019). The experiences of homeless youth when using strengths profiling to identify their character strengths. Frontiers in Psychology , 10 , 1–16. https://doi.org/10.3389/fpsyg.2019.02036
Corbin, J., & Strauss, A. (2015). Basics of qualitative research: Techniques and procedures for developing grounded theory (4th ed.). SAGE.
Google Scholar
Creswell, J. W., & Plano-Clark, V. L. (2007). Designing and conducting mixed methods research (1th ed.). SAGE.
Creswell, J. W., & Plano-Clark, V. L. (2011). Designing and conducting mixed methods research (2nd ed.). SAGE.
Creswell, J. W., & Plano-Clark, V. L. (2018). Designing and conducting mixed methods research (3rd ed.). SAGE.
Cross, S. E. (1995). Self-construals, coping, and stress in cross-cultural adaptation. Journal of Cross-cultural Psychology , 26 (6), 673–697.
Deng, J., Zhou, R., & Yan, L. (2019). The relationship between conscience and subjective well-being among junior high school students: Mediator role of social support. Advances in Psychology , 9 (7), 1230–1239. https://doi.org/10.12677/ap.2019.97151
Eldem, E. (2013). Istanbul as a cosmopolitan city. In A. Quayson, & G. Daswani (Eds.), A companion to diaspora and transnationalism (pp. 212–230). Blackwell.
Chapter Google Scholar
EVS/WVS. (2022). European Values Study and World Values Survey: Joint EVS/WVS 2017–2022 Dataset (Joint EVS/WVS). JD Systems Institute & WVSA. Dataset Version 4.0.0. https://www.worldvaluessurvey.org/WVSEVSjoint2017.jsp
Färber, F., & Rosendahl, J. (2018). The association between resilience and mental health in the somatically ill: A systematic review and meta-analysis. Deutsches Ärzteblatt International , 115 (38), 621–627. https://doi.org/10.3238/arztebl.2018.0621
Article PubMed PubMed Central Google Scholar
Farnsworth, J. K., Drescher, K. D., Evans, W., & Walser, R. D. (2017). A functional approach to understanding and treating military-related moral injury. Journal of Contextual Behavioral Science , 6 (4), 391–397. https://doi.org/10.1016/j.jcbs.2017.07.003
Fischer, A. H., & Manstead, A. S. R. (2000). The relation between gender and emotions in different cultures. In A. Fischer (Ed.), Gender and emotion: Social psychological perspectives (pp. 71–94). Cambridge University Press.
Fredrickson, B. L. (2001). The role of positive emotions in positive psychology: The broaden-and-build theory of positive emotions. American Psychologist , 56 (3), 218. https://doi.org/10.1037//0003-066x.56.3.218
Gentili, C., Rickardsson, J., Zetterqvist, V., Simons, L. E., Lekander, M., & Wicksell, R. K. (2019). Psychological flexibility as a resilience factor in individuals with chronic pain. Frontiers in Psychology , 10 , 1–11. https://doi.org/10.3389/fpsyg.2019.02016
Greene, J. C. (2007). Mixed methods in social inquiry . Jossey-Bass.
Hall, N. A., Everson, A. T., Billingsley, M. R., & Miller, M. B. (2021). Moral injury, mental health and behavioural health outcomes: A systematic review of the literature. Clinical Psychology & Psychotherapy , 29 (1), 92–110. https://doi.org/10.1002/cpp.2607
Hanel, P. H., Maio, G. R., Soares, A. K., Vione, K. C., de Holanda Coelho, G. L., Gouveia, V. V., & Manstead, A. S. (2018). Cross-cultural differences and similarities in human value instantiation. Frontiers in Psychology , 9 , 366179. https://doi.org/10.3389/fpsyg.2018.00849
Hayes, S. C. (2005). Get out of your mind and into your life: The new acceptance and commitment therapy . New Harbinger.
Hofstede, G., Hofstede, G. J., & Minkov, M. (2010). Cultures and organizations: Software of the mind (3rd ed.). Mc Graw-Hill.
Howell Smith, M. C., Babchuk, W. A., Stevens, J., Garrett, A. L., Wang, S. C., & Guetterman, T. C. (2020). Modeling the use of mixed methods–grounded theory: Developing scales for a new measurement model. Journal of Mixed Methods Research , 14 (2), 184–206. https://doi.org/10.1177/155868981987259
Kaya, F., & Odacı, H. (2021). Connor-Davidson Psikolojik Sağlamlık ölçeği kısa Formu: Türkçe’ye uyarlama, geçerlik ve güvenirlik çalışması. HAYEF: Journal of Education , 17 (2), 38–54. https://doi.org/10.5152/hayef.2021.20029
Kim, H. Y. (2013). Statistical notes for clinical researchers: Assessing normal distribution (2) using skewness and kurtosis. Restorative Dentistry & Endodontics , 38 (1), 52–54. https://doi.org/10.5395/rde.2013.38.1.52
Kuhar, M., & Zager Kocjan, G. (2022). Adverse childhood experiences and somatic symptoms in adulthood: A moderated mediation effects of disturbed self-organization and resilient coping. Psychological Trauma: Theory Research Practice and Policy , 14 (8), 1288–1298. https://doi.org/10.1037/tra0001040
Kuzulugil, Ş. (2010). A classification of Turkish cultural values . ICSS 2010 Proceedings.
Lazarus, R. S. (2000). Toward better research on stress and coping. American Psychological Association , 55 (6), 665–673. https://doi.org/10.1037/0003-066X.55.6.665
Lijadi, A. A. (2019). W hat are universally accepted human values that define ‘a good life’? Historical perspective of value theory. IIASA Working Paper . IIASA.
Lipowski, Z. J. (1988). Somatization: The concept and its clinical application. American Journal of Psychiatry , 145 (11), 1358–1368.
Lovibond, P. F., & Lovibond, S. H. (1995). The structure of negative emotional states: Comparison of the Depression Anxiety Stress Scales (DASS) with the Beck Depression and anxiety inventories. Behaviour Research and Therapy, 33 (3), 335–343.
Maercker, A., Zhang, X. C., Gao, Z., Kochetkov, Y., Lu, S., Sang, Z., & Margraf, J. (2015). Personal value orientations as mediated predictors of mental health: A three-culture study of Chinese, Russian, and German university students. International Journal of Clinical and Health Psychology , 15 (1), 8–17. https://doi.org/10.1016/j.ijchp.2014.06.001
Martin, F., & Oliver, T. (2019). Behavioral activation for children and adolescents: A systematic review of progress and promise. European Child & Adolescent Psychiatry , 28 , 427–441. https://doi.org/10.1007/s00787-018-1126-z
Masten, A. S. (2014). Ordinary magic: Resilience in development . Guilford.
Miller, J. G. (1997). Cultural conceptions of duty. In D. Munro, J. E. Schumaker, & S. C. Carr (Eds.), Motivation and culture (pp. 178–192). Routledge.
Miller, A. N., & Orsillo, S. M. (2020). Values, acceptance, and belongingess in graduate school: Perspectives from underrepresented minority students. Journal of Contextual Behavioral Science , 15 , 197–206. https://doi.org/10.1016/j.jcbs.2020.01.002
Motti-Stefanidi, F. (2018). Resilience among immigrant youth: The role of culture, development and acculturation. Developmental Review , 50 , 99–109. https://doi.org/10.1016/j.dr.2018.04.002
Ostermann, M., Huffziger, S., Kleindienst, N., Mata, J., Schmahl, C., Beierlein, C., & Lyssenko, L. (2017). Realization of personal values predicts mental health and satisfaction with life in a German population. Journal of Social and Clinical Psychology , 36 (8), 651–674. https://doi.org/10.1521/jscp.2017.36.8.651
Özcan, B., & Bulus, M. (2022). Protective factors associated with academic resilience of adolescents in individualist and collectivist cultures: Evidence from PISA 2018 large scale assessment. Current Psychology , 41 (4), 1740–1756. https://doi.org/10.1007/s12144-022-02944-z
Özgen, N. (2015). Demographic development and some cultural characteristics of Anatolian Circassians. In E. Efe, M. Ayışığı, Ö. Düzbakar, & M. Arslan (Eds.), Turkey at the Beginning of 21st Century: Past and present (pp. 394–422). St. Kliment Ohridski University Press Sofia.
Patterson, J. H., Collins, L., & Abbott, G. (2004). A study of teacher resilience in urban schools. Journal of Instructional Psychology , 31 (1), 3–11.
Peterson, C., & Seligman, M. E. (2004). Character strengths and virtues: A handbook and classification . Oxford University Press.
Plumb, J. C., Stewart, I., Dahl, J., & Lundgren, T. (2009). In search of meaning: Values in modern clinical behavior analysis. The Behavior Analyst , 32 , 85–103. https://doi.org/10.1007/BF03392177
Ran, L., Wang, W., Ai, M., Kong, Y., Chen, J., & Kuang, L. (2020). Psychological resilience, depression, anxiety, and somatization symptoms in response to COVID-19: A study of the general population in China at the peak of its epidemic. Social Science & Medicine , 262 , 113261. https://doi.org/10.1016/j.socscimed.2020.113261
Ruiz, F. J., Suárez-Falcón, J. C., Segura‐Vargas, M. A., & ve Gil‐Luciano, B. (2021). Psychometric properties of the Spanish version of the Valuing Questionnaire in Colombian clinical and nonclinical samples. Journal of Clinical Psychology , 78 (2), 233–248. https://doi.org/10.1002/jclp.23212
Sahare, P., & Kotnala, A. (2022). Effectiveness of spiritual augmented psychotherapy on resilience and conscience on juvenile delinquents. Yoga Mimamsa , 54 (2), 56–61. https://doi.org/10.4103/ym.ym_124_22
Schwartz, S. H. (2012). An overview of the Schwartz theory of basic values. Online Readings in Psychology and Culture , 2 (1), 2307–0919. https://doi.org/10.9707/2307-0919.1116
Sebre, S., Miltuze, A., & Bite, I. (2014). Resilience in relation to self-direction values and anxious/depressed symptoms across the life span. Poster session presentation at the meeting of the 16th European Conference on Developmental Pscyhology, Switzerland .
Shim, M., Johnson, B., Bradt, J., & Gasson, S. (2021). A mixed methods–grounded theory design for producing more refined theoretical models. Journal of Mixed Methods Research , 15 (1), 61–86. https://doi.org/10.1177/1558689820932311
Siegmann, P., Teismann, T., Fritsch, N., Forkmann, T., Glaesmer, H., Zhang, X. C., & Margraf, J. (2018). Resilience to suicide ideation: A cross-cultural test of the buffering hypothesis. Clinical Psychology & Psychotherapy , 25 (1), e1–e9. https://doi.org/10.1002/cpp.2118
Skevington, S. M., & The WHOQOL SRPB Group. (2020). Is culture ımportant to the relationship between quality of life and resilience? Global ımplications for preparing communities for environmental and health disasters. Frontiers in Psychology , 11 , 1492. https://doi.org/10.3389/fpsyg.2020.01492
Tajul Ariffin, A. H., Khaiyom, A., J. H., & Md Rosli, A. N. (2022). Islam, Iman, and Ihsan: The role of religiosity on quality of life and mental health of muslim undergraduate students. IIUM Medical Journal Malaysia , 21 (3), 146–154. https://doi.org/10.31436/imjm.v21i3
Tanyu, M., Spier, E., Pulizzi, S., Rooney, M., Sorenson, I., & Fernandez, J. (2020). Improving education outcomes for students who have experienced trauma and/or adversity. OECD Education Working Papers , 242 . https://doi.org/10.1787/54d45980-en
Teddlie, C., & Tashakkori, A. (2009). Foundations of mixed methods research: Integrating quantitative and qualitative approaches in the social and behavioral sciences . Sage.
Triandis, H. C. (2001). Individualism-collectivism and personality. Journal of Personality , 69 (6), 907–924. https://doi.org/10.1111/1467-6494.696169
Tunç, H., Morris, P. G., Kyranides, M. N., McArdle, A., McConachie, D., & Williams, J. (2023). The relationships between valued living and depression and anxiety: A systematic review, meta -analysis, and metaregression. Journal of Contextual Behavioral Science , 28 , 102–126. https://doi.org/10.1016/j.jcbs.2023.02.004
Ungar, M., Liebenberg, L., & Brown, M. (2005). The International resilience project. In M. Ungar (Eds.), Handbook for working with children and youth: Pathways to resilience across cultures and contexts (pp. 211–229). Sage.
Ungar, M., & Theron, L. (2020). Resilience and mental health: How multisystemic processes contribute to positive outcomes. The Lancet Psychiatry, 7 (5), 441–448. https://doi.org/10.1016/S2215-0366(19)30434-1
Ungar, M., Theron, L., Murphy, K., & Jefferies, P. (2021). Researching multisystemic resilience: A sample methodology. Frontiers in Psychology , 11 , 607994. https://doi.org/10.3389/fpsyg.2020.607994
Williams, K. E., Ciarrochi, J., & Heaven, P. C. (2015). Relationships between valued act ion and well-being across the transit ion from high school to early adulthood. The Journal of Positive Psychology , 10 (2), 127–140. https://doi.org/10.1080/17439760.2014.920404
Wilson, K. G., & Murrell, A. R. (2004). Values work in acceptance and commitment therapy: Setting a course for behavioral treatment. In S. C. Hayes, V. M. Folette, & M. Linehan (Eds.), Mindfulness and acceptance: Expanding the cognitive behavioral tradition (Vol. 151, p. 120). Guilford Press.
World Population Review (2024). Religion by country 2024 . Retrieved July 11, 2024, from https://worldpopulationreview.com/country-rankings/religion-by-country
Wright, M. O. D., Masten, A. S., & Narayan, A. J. (2013). Resilience processes in development: Four waves of research on positive adaptation in the context of adversity. In S. Goldstein, & R. B. Brooks (Eds.), Handbook of Resilience in Children (pp. 15–37). Springer.
Xie, Q., & Wong, D. F. K. (2020). Culturally sensitive conceptualization of resilience: A multidimensional model of Chinese resilience. Transcultural Psychiatry , 58 (3), 323–334. https://doi.org/10.1177/1363461520951306
Yang, Y. (2020). Daily stressor, daily resilience, and daily somatization: The role of trait aggression. Personality and Individual Differences , 165 , 110141. https://doi.org/10.1016/j.paid.2020.110141
Yaşaroğlu, C. (2013). Türkiye’deki hayat bilgisi ile singapur’daki vatandaşlık ve ahlak eğitimi derslerinin değerler eğitimi bağlamında karşılaştırılması. Journal of Turkish Studies , 8 (8), 1453–1461.
Yeh, C. J., Arora, A. K., & Wu, K. A. (2006). A new theoretical model of collectivistic coping. In P. T. P. Wong, & L. C. J. Wong (Eds.), Handbook of multicultural perspectives on stress and coping (pp. 55–72). Springer.
Yıldırım, A., Boysan, M., & Kefeli, M. C. (2018). Psychometric properties of the Turkish version of the Depression anxiety stress Scale-21 (DASS-21). British Journal of Guidance & Counselling , 46 (5), 582–595. https://doi.org/10.1080/03069885.2018.1442558
Yılmaz, G. (2019). Being immigrant in a Conflict-Ridden Society. In G. Yılmaz, İ. D. Karatepe, & T. Tören (Eds.), Integration through Exploitation: Syrians in Turkey (pp. 11–127). Rainer Hampp.
Zümbül, S. (2021). Coping: A holistic review. İnönü University Journal of the Faculty of Education , 22 (1), 109–143. https://doi.org/10.17679/inuefd.688844
Download references
Acknowledgements
We thank all participating for their effort.
This research is not supported by any side.
Author information
Authors and affiliations.
Department of Psychology, Faculty of Economic Administrative and Social Sciences, Hasan Kalyoncu University, Havalimanı Yolu Üzeri 8. Km, Şahinbey/Gaziantep, Turkey
Feyza Topçu & Mehmet Dinç
You can also search for this author in PubMed Google Scholar
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by [Feyza Topçu]. The first draft of the manuscript was written by [Feyza Topçu], [Mehmet Dinç] and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Correspondence to Feyza Topçu or Mehmet Dinç .
Ethics declarations
Ethics approval and consent to participate.
This study was performed in line with the principles of the Declaration of Helsinki. The present study was approved by the Hasan Kalyoncu University Graduate Education Institute Ethics Committee.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Consent to publish
Competing interests.
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic Supplementary Material
Below is the link to the electronic supplementary material.
Supplementary Material (DOCX 15.4 KB)
Rights and permissions.
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Topçu, F., Dinç, M. Psychological resilience and valued living in difficult times: mixed method research in cultural context. Curr Psychol (2024). https://doi.org/10.1007/s12144-024-06552-x
Download citation
Accepted : 11 August 2024
Published : 12 September 2024
DOI : https://doi.org/10.1007/s12144-024-06552-x
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Valued living
- Psychological resilience
- Mental health
- Find a journal
- Publish with us
- Track your research
Advanced Quantitative Methods in Social Sciences MRes
1 year full-time, starting in september 2025.
Develop in-depth knowledge and research skills in social science. You’ll learn advanced techniques to analyse large data sets and draw effective insights.
By combining a substantial theoretical and quantitative core with comprehensive qualitative training, this course will help you gain the essential skills to become a working social science or educational researcher.
You’ll enhance your understanding of the techniques used in the analysis and presentation of quantitative data in a social science context. This will allow you to apply key research techniques to large scale data sets in public and commercial life, and draw actionable conclusions.
A key element of your studies will be to identify and investigate your own original research question using advanced quantitative methods.
This course is designed to enable you to carry out high-quality doctoral research or pursue other professional research activities in private or public sector settings.
Why choose a Master of Research (MRes) degree?
An MRes is a master’s degree with a focus on research. The knowledge and expertise you’ll gain will prepare you for doctoral study and a range of non-academic careers that require strong research skills.
Find out more about why an MRes might be right for you .
South West Doctoral Training Partnership This MRes is recognised by the Economic & Social Research Council (ESRC) , specifically, as part of the larger South West Doctoral Training Partnership (SWDTP) . It can be taken as a course in its own right, or if you hold an SWDTP studentship you can take the 1+3 (MRes + PhD) pathway. If you wish to be considered for a 1+3 SWDTP studentship, then you must apply for your preferred PhD route and not the stand-alone MRes . You should follow our how to apply guidelines. For those holding a 1+3 SWDTP studentship, progression from the MRes to the MPhil or PhD stage is dependent on an acceptable level of achievement. Read more about other funding that you may be eligible for .
Learn from experts in their field
You’ll learn from experts in social science research. Their passion, knowledge and research shape their teaching to enhance your learning experience.
Gain important career skills
We work to provide you with the tools and support to prepare you for employment and further study.
This includes advanced quantitative research skills, and bibliographic skills; and the use of appropriate technology to undertake tasks that use these skills.
Graduate prospects
There is increasing demand for high-level quantitative skills from a wide range of private and public sector recruiters.
Many firms and government departments are now committed to data-driven decision-making, making use of the increased availability of big data.
This course will equip you with a hybrid skill set that combines quantitative, computing and analytical skills with an understanding of social science research and enquiry.
This MRes also equips you to go into further study at PhD level.
2025/26 Academic Year
Before you apply for a course, please check the website for the most recently published course detail. If you apply to the University of Bath, you will be advised of any significant changes to the advertised programme, in accordance with our Terms and Conditions.
We understand that you will want to know more about the shape of the academic year. We work hard and plan for different scenarios, to be able to welcome you to the University of Bath at the start of each semester.
- Course structure
Occasionally we make changes to our programmes in response to, for example, feedback from students, developments in research and the field of studies, and the requirements of accrediting bodies. You will be advised of any significant changes to the advertised programme, in accordance with our Terms and Conditions.
Compulsory units
Aqm 1 - experimental and quasi-experimental quantitative methods for social science , digital methods and data skills for mres, dissertation, interdisciplinary research methods in social sciences, research design and methods for aqm.
You’ll choose one optional unit.
Mathematics and programming skills for social scientists
aqm 2 - advanced modelling techniques for social sciences, optional units, advanced qualitative methods, business analytics, independent research essay.
- Learning and assessment
You’ll be taught and assessed by a variety of methods and it will vary between units. These methods are designed to promote in-depth learning and understanding of the subject.
These lists are to give you an idea of some, but not all, of the learning and assessment methods used on this course. They are not exhaustive lists and methods are subject to change.
Learning and teaching
You are expected to spend approximately 35 hours per week studying, with around 8-10 of those hours being structured classes.
This will be made up of a combination of lectures and seminars.
Assessment breakdown
You will experience a range of different forms of assessment designed to support your professional development. This will include coursework, project work, examinations, and a dissertation.
We can make reasonable adjustments to assessment procedures for students with disabilities. Read our Disability Service’s pages for information.
Recognition of professional qualifications
As well as being recognised as a higher academic qualification, a number of our degrees are also accredited by professional bodies in the United Kingdom. An accredited degree may entitle you to work in a specific profession within the UK, and abroad (where there are reciprocating arrangements with professional bodies in other countries).
The requirements to practise a profession vary from country to country. If you wish to practise your profession outside the United Kingdom, you are advised to confirm that the UK professional qualification you seek is valid in the country in which you are intending to work.
- Entry requirements
Origin of qualifications
British qualifications.
You should have a bachelor’s honours degree or international equivalent, typically a 2:1 or above.
To apply for this course you should have an undergraduate degree with substantive quantitative elements, such as economics, psychology, social policy, sociology, geography, politics, management or a Q-Step programme.
In your application you will need to provide a max. 500 word personal statement in your own words which should explain:
(a) Why you wish to undertake a Master of Research and the interests and skills you particularly hope to develop on the course.
(b) Your research interests - please be specific.
We may make an offer based on a lower grade if you can provide evidence of your suitability for the degree.
If your first language is not English but within the last 2 years, you completed your degree in the UK, you may be exempt from our English language requirements.
English language requirements
- IELTS: 6.5 overall with no less than 6.0 in all components
- The Pearson Test of English Academic (PTE Academic): 62 with no less than 59 in any element
- TOEFL IBT: 90 overall with a minimum 21 in all 4 components
You will need to get your English language qualification within 24 months prior to starting your course.
If you need to improve your English language skills before starting your studies, you may be able to take a pre-sessional course to reach the required level.
Filipino qualifications
You should have a Bachelor degree (awarded from 2022 onwards) or a Master’s degree from a prestigious institution with a final overall score of 1.75 on a 5-point scale (where 1 is the highest mark) or 3.0 out of 4.0.
Sri Lankan qualifications
You should have a four-year Bachelor degree (Special or Honours) or a Bachelor degree (Professional) with a final overall result of at least 60%.
Bangladeshi qualifications
You should have a Master's degree (following a 3 or 4 year Bachelor degree) with a final overall grade of at least 3.2 out of 4.0 (65% or B+). We may also consider a Bachelor of Architecture when studied for at least five years, or a Bachelor of Engineering when recognised by the Institution of Engineers Bangladesh (IEB) or accredited by the Board of Accreditation for Engineering and Technical Education (BAETE).
Lithuanian qualifications
You should have a Bakalauro Diplomas or Profesinis Bakalauras with an overall final result of at least 8 out of 10.
Malawian qualifications
You should have a Master's degree with a final overall result of at least 70%.
Norwegian qualifications
You should have a Bachelorgrad (Bachelor degree), Candidatus/a Magisterii, Sivilingeniør or Siviløkonom with a final overall result of at least B.
Hong Kongese qualifications
You should have a Bachelor degree (Honours) with a final overall result of Second Class (Division 1) Honours or 3.0 out of 4.0.
Icelandic qualifications
You should have a Baccalaureus or Candidatus/a with an overall final result of at least 7.25 on a 10-point scale.
Irish qualifications
You should have a Honours Bachelor degree with a final overall result of at least Second Class Honours (Grade I).
Indonesian qualifications
You should have a Bachelor degree (Sarjana I) with a final overall result of at least 3.0 out of 4.0.
Malaysian qualifications
You should have a Bachelor degree with a final overall result of at least Second Class (Division 1).
Mexican qualifications
You should have a Título de Licenciado or Título (Profesional) de [subject area] with a final overall result of least 8 out of 10.
Dutch qualifications
You should have a Bachelor degree or Doctoraal with a final overall result of at least 7 out of 10.
New Zealander qualifications
You should have a Bachelor Honours degree or Bachelor degree with a final overall result of at least B+/B or 6 on a 9-point scale.
Iranian qualifications
You should have a Bachelor's degree or Professional Doctorate with a final overall result of at least 14 out of 20 when studied at a state university and 15 out of 20 when studied at a private university.
Jamaican qualifications
You should have a Bachelor degree with a final overall result of at least Second Class (Upper).
Israeli qualifications
You should have a Bachelor degree with a final overall result of at least 80%.
Italian qualifications
You should have a Laurea, Laurea in Ingegneria / Architettura, Diploma Accademico di Primo Livello, Diploma di Mediatore Linguistico or Licenza di Academia di Belle Arti with a final result of at least 102 out of 110.
Nigerian qualifications
You should have a Bachelor degree with a final overall result of at least Second Class Honours (Upper Division).
Macedonian qualifications
You should have a Baccalaureus/Baccalaurea (Bachelor degree) with a final overall result of at least 9 out of 10.
Russian qualifications
You should have a Diplom Bakalavra (Bachelor degree) or Specialist Diploma with an overall final result of at least 4 out of 5 (khorosho/good).
Polish qualifications
You should have a Licencjat or Inżynier (Bachelor degree) with a final overall result of at least 4.5 on a 5-point scale.
Kazakhstani qualifications
You should have a Bakalavr (Bachelor degree) or Specialist Diploma with a final overall result of at least 4.3 on a 5-point scale or 3.2 on a 4-point scale.
Japanese qualifications
You should have a Bachelor degree (Gakushi) with a final overall result of at least 3.0 out of 4.0 (B).
Jordanian qualifications
You should have a Bachelor degree with a final overall result of Very Good or GPA 3.0 on a 4-point scale.
Kenyan qualifications
Portuguese qualifications.
You should have a Licenciado with a final overall result of at least 15 out of 20.
Romanian qualifications
You should have a Diplomă de Licență (Bachelor degree), Diplomă de Inginer or Diplomă de Urbanist Diplomat with a final overall result of at least 8 out of 10.
Saudi Arabian qualifications
You should have a Bachelor degree with a final overall result of at least 3.5 on a 5-point scale or 3.0 on a 4-point scale.
South African qualifications
You should have a Bachelor Honours degree, Professional Bachelor degree or Baccalaureus Technologiae (Bachelor of Technology) with a final overall result of at least Second Class (Division One) or 70%.
Cambodian qualifications
You should have a Master’s degree from a recognised degree-awarding institution with a final overall result of at least 80%.
Singaporean qualifications
You should have a strong Bachelor (Honours) degree when studied at Nanyang Technological University (NTU), National University of Singapore (NUS), Singapore Institute of Technology or Singapore University of Social Sciences with a final overall result of at least Second Class (Upper) Honours, or a strong Bachelor degree when studied at Singapore Management University (SMU) or Singapore University of Technology and Design (SUTD). Typically, we require a final overall result of at least Second Class (Upper) Honours, 60% or B, however we ask that you upload a copy of the grading scale used by your institution, along with your transcript, when you submit your application due to the range of grading scales used by different institutions.
Swedish qualifications
You should have a Kandidatexamen (Bachelor Degree) or Yrkesexamen (Professional Bachelor degree) with a final overall result of at least Grade B. Please contact us if your institution uses a different grading scale.
Slovene qualifications
You should have a Diploma o pridobljeni univerzitetni izobrazbi (University Degree), Diplomant or Univerzitetni diplomant with a final overall result of at least 8 out of 10 (prav dobro/very good).
South Korean qualifications
You should have a Bachelor degree (Haksa) with a final overall result of at least 3.0 out of 4.3 or 3.5 out of 4.5.
Albanian qualifications
You should have a Diplomë Bachelor or a Master i Shkencave with a final overall result of at least 8 out of 10. Please contact us if your institution uses a different grading scale.
Swiss qualifications
You should have a Bachelor Degree (Baccalauréat Universitaire) with a final overall result of at least 5 out of 6.
Syrian qualifications
You should have a Bachelor degree (Licence/Al-ijâza) with a final overall result of at least 70-80% depending on the institution attended.
Nepali qualifications
You should have a four-year Bachelor degree from a recognised university, or a Master's degree following a three-year or four-year Bachelor degree, with a final overall result of at least 65% or 3.25/4.0.
Belgian qualifications
You should have a Bachelier, Licencié or Licentiaat and other two cycle diplomas with a final overall score of at least 16 out of 20.
Algerian qualifications
You should have a Licence, Diplôme in any specialised professional field, Diplôme d'Ingênieur, Diplôme d'Architecte d'État or Diplôme d'Etudes Supérieures with a final overall score of at least 14 out of 20.
Brazilian qualifications
You should have a Titulo de Bacharel, Titulo de [subject area] or Licenciado/a with a final overall result of at least 7.5 out of 10.
Australian qualifications
You should have a Bachelor Honours degree with a final result of at least Second Class (Upper Division) or a Bachelor degree with a final result of Distinction or higher.
Austrian qualifications
You should have a Bachelor degree or Fachhochschuldiplom/Diplom (FH) with a final result of at least Gut.
Bolivian qualifications
You should have a Licenciado or Titulo de [subject area] with a final overall result of at least 75%.
Bulgarian qualifications
You should have a Bachelor degree with a final overall result of at least 5 out of 6.
Croatian qualifications
You should have a Baccalaureus or Baccalaurea with a final overall result of at least 4 out of 5.
Canadian qualifications
You should have a Bachelor degree (Honours) or Bachelor degree with a final overall result of at least CGPA 3.0 on a 4-point scale (B or 70%). Please contact us if your institution uses a different grading scale.
Czech qualifications
You should have a Bakalár (Bachelor degree) with a final overall score of 1.5 on a 1-4 scale or Grade B. Please contact us if your institution uses a different grading scale.
Chilean qualifications
You should have a Grado de Licenciado with a final overall result of at least 5.5 on a 7-point scale.
Colombian qualifications
You should have a Licenciado en, Titulo de, Profesional en, Maestro en or Diploma de [subject area] with a final overall result of at least 3.8.
Cypriot qualifications
You should have a Bachelor degree (Ptychio) with a final overall result of at least 6.5 out of 10.
Danish qualifications
You should have a Bachelor degree, Candidatus Philosophiae, Diplomingeniør (Engineer), Professionsbachelor (Professional Bachelor degree) or Korrespondenteksamen with a final overall result of at least 7 out of 10.
French qualifications
You should have a Grade de licence / Grade de licence professionnelle with a final overall result of at least 13 out of 20.
Kuwaiti qualifications
You should have a Bachelor degree (البكالوريوس) with a final overall result of 3.2 on a 4-point scale.
Finnish qualifications
You should have a Kandidaatti / Kandidat (University Bachelor Degree), (Professional Title) (AMK/YH) (Bachelor degree from a University of Applied Sciences), Arkkitehti / Arktitekt / Diplomi-insööri / Diplomingenör / Proviisori / Provisor with a final overall result of at least 3.5 on a 5-point scale.
Chinese qualifications
You should have a four-year Bachelor degree with a final overall score of at least 75-80% depending on the institution attended.
Egyptian qualifications
You should have a Bachelor degree from a university with a final overall result of at least 75% (Very Good) or 3.0 on a 4-point scale.
Vietnamese qualifications
You should have a Bachelor degree (Bằng Tốt Nghiệp Đại Học/Bằng Cử Nhân) of at least four years or a Master's degree (Thạc sĩ) from a recognised degree-awarding institution with a final overall result of at least 7.0 on a 10-point scale.
Estonian qualifications
You should have a Bakalaurusekraad (Bachelor degree), Diplomeeritud spetsialisti ülikoolidiplom/Kraadita Diploma (University Specialist's Diploma) or Rakenduskõrgharidusõppe Diplom (Professional Higher Education Diploma) with a final overall result of at least 4 on a 5-point scale (B).
German qualifications
You should have a Bachelor degree, Erste Staatsprüfung (Primarstufe / Sekundarstufe I), Fachhochschuldiplom / Diplom (FH) or Magister Artium with a final overall result of at least 2.5 (Gut).
Taiwanese qualifications
You should have a Bachelor degree with a final overall result of at least 75%.
Zimbabwean qualifications
You should have a Bachelor Honours degree with a final overall result of at least Upper Second Division (65%).
Turkish qualifications
You should have a Lisans Diplomasi (Bachelor degree) or Mühendis Diplomasi with a final overall score of at least GPA 2.8-3.0 on a 4-point scale, depending on the institution you have attended.
Spanish qualifications
You should have a Título Universitario Oficial de Licenciado en (subject area) (Licenciatura), Título Universitario Oficial de Graduado en (subject area) (Grado), Título de Ingeniero or Título de Arquitecto with a final overall result of at least 7 out of 10 (Notable/Very Good).
Other qualifications
We welcome applications from graduates from all countries so if you can’t see your country in the list, please contact our admissions team for advice about your specific entry requirements.
Tunisian qualifications
You should have a Licence, Maîtrise, Diplôme National d'Ingénieur, Diplôme National d'Architecture with a final overall result of at least 14 out of 20 (Bien).
Tanzanian qualifications
You should have a Bachelor degree with a final overall result of at least Upper Second (Very Good, B+ or GPA 3.5 on a 5-point scale).
Thai qualifications
You should have a Bachelor degree with a final overall result of at least CGPA 3.0.
American qualifications
You should have an Honors Bachelor degree or Bachelor degree with a final overall result of at least CGPA 3.0 on a 4-point scale.
Ugandan qualifications
You should have a Bachelor degree with a final overall result of at least Class II Upper or GPA 4.0 on a 5-point scale.
Ukrainian qualifications
You should have a Bachelor degree (awarded after 2007) or Specialist Diploma with a final result of at least 80% or 3.5 on a 4-point scale. Please contact us if your institution uses a different grading scale.
Emirati qualifications
You should have a Bachelor degree with a final overall result of at least 3 out of 4, 80% or B.
Hungarian qualifications
You should have an Alapfokozt (Bachelor degree) or Egyetemi Oklevél (University Diploma) with an overall final result of 4 out of 5.
Ghanaian qualifications
You should have a Bachelor degree with a final overall result of Upper Second Class (60% or 3.25 on a 4-point scale).
Greek qualifications
You should have a University Bachelor degree (Ptychio) or Diploma with a final overall score of at least 6.5 out of 10.
Indian qualifications
Typically, you should have a Bachelor degree with a final overall result of at least First Class. However, due to the number of different grading scales in use, we ask that you upload a copy of the grading scale used by your institution, along with your transcript, when you submit your application.
If you have graduated within the last 5 years from an Indian university where the medium of instruction is English and have achieved the required level of English in your Indian 12th Standard examinations, we may be able to assess your English. More information can be found here .
- Fees and funding
Fees and funding information for Advanced Quantitative Methods in Social Sciences MRes full-time
Your tuition fees and how you pay them will depend on whether you are a Home or Overseas student.
Tuition fees
See the most recent fees for postgraduate courses .
Tuition fee loans
If you are studying a postgraduate course, you may be able to take out a loan for your tuition fees and living costs.
Scholarships and bursaries
You could be considered for a bursary or scholarship to help you study at Bath. You do not have to pay it back.
Other payment options
You can pay your tuition fees by Direct Debit, debit card, credit card or bank transfer. You may also be eligible for a student loan to help you pay your fees.
You will need to budget at least £100 for the cost of photocopying, printing and binding. You will also need to budget for the cost of textbooks.
Some courses involve visits away from campus and you may be required to pay some or all of the costs of travel, accommodation and food and drink.
If you’re on a placement, you’re responsible for your own travel, accommodation and living costs. You should also consider the financial implications if you go on an unpaid or overseas placement.
- Application information
- Course title Advanced Quantitative Methods in Social Sciences
- Final award MRes
- Mode of study Full-time
- Course code TDUXX-MR65
- Department Department of Education
- Location University of Bath Claverton Down, Bath BA2 7AY
We recommend you apply early as we may close applications before the deadline if a course is full.
We recommend you apply early as we may close applications before the deadline if a course is full. We may consider late applications but if you need a Student Visa to study in the UK, you will need time to apply for and receive your visa to be in the UK by the start of the course.
- Application eligibility Home and Overseas students are eligible to apply
- Regulator The Office for Students (OfS)
- Course enquiries
- Related courses
- Advanced Quantitative Methods in Social Sciences MRes – 2 years part-time
- Statistics and Data Science (Health) MSc – 1 years
On this page
- Course changes for 2025/26
- Recognition of Professional Qualifications
Develop a range of technical skills that cover major experimental and quasi-experimental approaches to data analysis in the social sciences.
This unit aims to introduce you to these approaches, and provide you with:
theoretical understanding of these techniques and practical experience in using them
- the knowledge to critically appraise research findings using these techniques
an insight into how these methods can be applied in your own field of interest
Enhance your understanding of the basic qualitative methods in social sciences research.
You'll develop the conceptual and practical skills to begin to conduct, analyse, interpret, and present qualitative research.
Develop analytical skills that will allow you to:
- understand and analyse data
- develop insights that influence decision-making
You will develop your analytical thinking and problem-solving skills. You'll learn a variety of modern analytics tools and techniques that help decision-making in many business areas like finance, marketing and operations management.
Develop your ability to understand, collect and analyse complex and evolving forms of digital data.
You'll receive:
a foundational overview of the variety of digital data sources used for research across multiple social science disciplines
an introduction to range of computational, quantitative and qualitative methods that can be used to collect and analyse specific forms of digital data.
Throughout this unit, you'll also learn about ethical and research quality issues.
Identify, investigate and present your own piece of original research. You'll do this across 12 months.
During this unit, you'll receive guidance to develop the necessary research skills to produce a pilot study and a dissertation of academic and professional quality.
You'll identify an appropriate methodology and engage with relevant theory and data to answer your research question(s).
- Year 1 - Semester 1
- Year 1 - Semester 2
This is your opportunity to develop an in-depth understanding of a key research-related issue of your choice.
Receive an introduction to research practices and theories, and qualitative and quantitative research approaches.
You'll gain knowledge of:
- qualitative research approaches to a level that will allow you to understand and to interpret a range of phenomenological or textual data
- quantitative approaches to a stage that will give you a base level of statistical literacy
You'll also explore the philosophical foundations of social research.
Gain the advanced-level mathematical skills needed to overcome various types of optimisation problems.
You'll learn to use software that can solve practical optimisation problems within research.
Explore key social sciences data analysis techniques. These techniques aren’t covered in ‘AQM 1 - Experimental and Quasi-experimental Quantitative Methods in Social Science’.
- theoretical understanding of these techniques and practical experience using them
- an insight into how these methods can be applied in your own field
Develop the skills and knowledge to formulate research questions and carry out your own research projects.
You will learn about the epistemological and methodological traditions in social science research and the social science research space, with a focus on the range of quantitative methods used.
You'll then build the necessary skills to
design and organise a research project
conduct critical reviews of published research
effectively disseminate and communnicate research
IMAGES
VIDEO
COMMENTS
Overview. This five-day short course will give you a comprehensive introduction to the fundamental aspects of research methods and statistics.It's suitable for those new to quantitative research. You'll look at topics ranging from study design, data type and graphs through to choice and interpretation of statistical tests - with a particular focus on standard errors, confidence intervals and p ...
review quantitative research published in journal articles with genuine understanding of the design, methods, results and conclusions; undertake your own basic quantitative research from the design stage, data collection, all the way through to writing and interpretation of results; Cost and concessions. The standard price is £375.
Dr. Charles Lawoko gives an overview of his course on quantitative research methods, discussing what to expect in each of thirteen sections. Chapter 1: Introduction to Dr. Charles Lawoko icon angle down. Start time: 00:00:00; End time: 00:01:34; Chapter 2: Overview of the Course
Best online courses in Quantitative Research from Harvard, MIT, The Open University, University of Toronto and other top universities around the world. ... Explore quantitative research methods in social sciences, focusing on scientific principles, research designs, measurement, sampling, and ethics. Gain skills to distinguish between solid ...
View additional details. Science searches for patterns in data. Quantitative methods are tools for finding and evaluating these patterns. This course introduces foundational concepts in quantitative methods, including data visualization and common statistical tests used in psychological research. Contact Us. Phone: 609-258-2600. Fax: 609-258-1113.
Aims: The aim of the course is to provide a brief introduction to the principles of quantitative research methods. Objectives: By the end of the course, you will: Process: A two-day course involving discussion and practical exercises. You can self-enrol to access the course resources in Moodle by following this link: https://moodle.nottingham ...
NCRM delivers research methods training, produces learning resources, conducts research and supports methodological innovation ... quantitative, qualitative, digital, creative, visual, mixed and multimodal methods ... NCRM is looking for a Senior Engagement Manager to join its team. Short courses. Browse our calendar of training courses and ...
This resource is intended as an easy-to-use guide for anyone who needs some quick and simple advice on quantitative aspects of research in social sciences, covering subjects such as education, sociology, business, nursing. If you area qualitative researcher who needs to venture into the world of numbers, or a student instructed to undertake a quantitative research project despite a hatred for ...
In today's data-driven world, the addition of analytical skills is essential, and the Quantitative Methodology: Measurement and Statistics, Post-Baccalaureate Certificate (P.B.C.) program is tailored for University of Maryland doctoral students seeking specialized training in quantitative methods. It equips students with essential skills in advanced statistical analysis, addressing the growing ...
Quantitative research methods. You can use quantitative research methods for descriptive, correlational or experimental research. In descriptive research, you simply seek an overall summary of your study variables.; In correlational research, you investigate relationships between your study variables.; In experimental research, you systematically examine whether there is a cause-and-effect ...
Research skills and statistics. A range of practical courses for anyone who needs to understand research methods and statistical analyses for research purposes. There is a problem with this content. Please try again later. RADIANCE - Longitudinal Data Analysis with SEM | Short courses - UCL - University College London.
Short course categories include: Quantitative Analysis: Upcoming short courses in quantitative data analysis/statistical software. Qualitative Research: Upcoming short courses in qualitative research methods/data analysis. Survey Research: Upcoming short courses in survey research. Data Science: Upcoming short courses in data science.
The course provides students with an elementary through to a more advanced knowledge of quantitative data collection, analysis and interpretation. By the end of the module, students will have enhanced their team working, project management, verbal and written communication, advanced ICT, quantitative, creativity, independent research and ...
Advanced skills in selecting and conducting appropriate statistical tests for quantitative data. The content of this module will include: Research design and data collection approaches. Surveys, case-control, and cohort studies. Clinical trials. Prognostic and diagnostic tests. Data types and distribution. Access and ethics.
The quantitative part of this methods course introduces survey research and basic quantitative analysis using Stata. Through weekly readings, lectures, discussions, lab sessions, and mini-projects, you will learn crucial principles of research ethics in social research, how to design and conduct interviews, basic knowledge about content ...
The material covered in the Quantitative Methodology: Measurement and Statistics, Master of Science (M.S.) program is crucial in today's data-driven world, where the ability to analyze and interpret data is in demand across many industries. Ideal for individuals with a passion for research and a strong aptitude for mathematics, this program attracts students who are analytical, detail-oriented ...
Recruitment and short courses; Conferences and facilities; Networks and events; Alumni. Alumni. News and events; Sussex people; Get involved ... Home. Module list. Postgraduate modules. Current location: Quantitative Methods and Research Design. Quantitative Methods and Research Design (854N1) 15 credits, Level 7 (Masters) Autumn teaching ...
This course is designed to introduce you to and help you become familiar with quantitative methodologies critical to your development as a social scientist. The introductory methods course has two primary aims. First, students will be introduced to quantitative methodology that researchers and policymakers use in answering social, political and economic questions.
Mixed methods research methodology is a valuable approach that combines quantitative and qualitative methods to gain a deep understanding of complex research problems (Creswell & Plano-Clark, 2007). In this study, we focused on the cultural values that contribute to individuals' mental health during challenging times.
A key element of your studies will be to identify and investigate your own original research question using advanced quantitative methods. This course is designed to enable you to carry out high-quality doctoral research or pursue other professional research activities in private or public sector settings.