- Stack Overflow for Teams Where developers & technologists share private knowledge with coworkers
- Advertising & Talent Reach devs & technologists worldwide about your product, service or employer brand
- OverflowAI GenAI features for Teams
- OverflowAPI Train & fine-tune LLMs
- Labs The future of collective knowledge sharing
- About the company Visit the blog

Collectives™ on Stack Overflow
Find centralized, trusted content and collaborate around the technologies you use most.
Q&A for work
Connect and share knowledge within a single location that is structured and easy to search.
Get early access and see previews of new features.
IPv6 Address Assignments
I have just started working with IPv6, so I've done a lot of reading in the last couple of days. Unfortunately, some of my questions have not been answered in my research.
My goal is to keep track of what addresses are assigned, and to what interface they are assigned. From what I've read, there are a few ways that an interface can get an IPv6 address, which I've listed below in sub sections. I've highlighted what I've discovered so far, and posed some questions in these sections. If anyone can make any corrections to what I've learned, or have answers to the questions, please do so. If anyone knows of a place I can find more information, I don't mind researching it more myself.
Edit: I've discovered that Prefix Delegation does not actually result in address assignment. It is used by DHCP servers to get the prefixes to use from another DHCP server.
The methods for obtaining an IPv6 address are:
- StateLess Address Auto-Config (SLAAC)
Stateful DHCPv6
SLAAC is used in small networks to generate an IPv6 address for an interface. It requires (almost) no configuration and basically works as follows:
- When the interface comes online, the client will generate a link-local IPv6 address using its interface ID address and the link-local prefix ( FE80::/10 ).
- To verify this address is unique, a Neighbour Solicitation ( NS ) message is sent to the address. If there is a reply, then the address is in use and cannot be used. Auto-config is aborted and configuration should proceed manually. Question 1a: Is there really no fall back here?
Assuming no reply is received by the end of the timeout period, the address is assumed to be unique and it is assigned as the link-local address to the interface.
Now the node has connectivity to all other nodes on this link
The node either waits to receive a Router Advertisement ( RA ), or sends a Router Solicitation ( RS ) message to the multicast group for all routers. When an RS is received by a router, it will respond with an RA . The RA will contain a prefix.
- The node will generate a global unicast address with the prefix and its interface ID.
- Similar to when the link-local address was created, the node will send a message to the address to determine if it is unique. Question 2: Is this also an NS message? If there is a reply, then the address is already in use, address assignment must proceed manually. Question 1b: Again, is there any automated way to recover?
- Assuming there was no reply within the timeout, then the address is then assigned as the global IPv6 address to the interface.
Question 3: It is possible to have more than one address for the interface. In fact, at the end of the above process, a single interface will have 2 addresses - a link-local one and a global unicast one. Is it possible to get additional addresses for this interface using SLAAC? Or must another method (e.g. DHCPv6) be used?
A node may obtain a link-local address using steps 1-3 from above. I believe this is optional and that it can simply use ::/128 (unspecified) as its source address in DHCP requests until it is assigned an address.
There are two methods of obtaining an address - normal and rapid-commit. Normal is a 4 message exchange ( Solicit , Advertise , Request , Reply ), and Rapid is a 2 message exchange ( Solicit , Reply ). Rapid-commit is done when the client requests it with a Rapid-Commit option in the Solicit message. It is essentially the same as Normal, and since it doesn't make a difference for my usage, I am going to ignore it for now.
Also, it is possible that messages are proxied through relays. Messages sent to a server from a relay are RELAY_FORW messages, and messages sent from the server to the relay are RELAY_REPL messages. The actual dialog between the client and server is encapsulated in its entirety within an OPTION_RELAY_MSG option. For the following, I am dealing only with non-relay messages. If a message was relayed, then it is easy to obtian the original message and the following still holds.
Address assignment takes place as follows:
- The client sends a Solicit message to the "All DHCP Servers and Relays" multicast address. The purpose of this message it to discover the identity of a DHCP server on the local link.
- A DHCP server responds with an Advertise message to the local multicast address.
- The client sends a Request message directly to the DHCP server with options indicating that it would like to have an IP address. Question 4: In the PCAP files I've seen, it looks like this message is still sent to the multicast address ff02::1:2 . Any reason that this is not sent directly to the DHCP server from which the Advertise was received?
- The DHCP server responds with a Reply containing the IP address.
- The client should perform duplicate address detection similar to step 6 in the SLAAC method.
- The node assigns this address to the interface and can begin using it.
This is the general method by which addresses are assigned, but more specifically, there are 3 ways that this can be done:
- Non-temporary address assignment ( IA_NA )
- Temporary address assignment ( IA_TA )
- Prefix Delegation ( PD )
All three methods are accomplished by including an option in the Request which is then populated by the server and returned in the Reply . For the first two, a complete IPv6 address is returned which can then be assigned as an IP address for the interface. For the third, a prefix is returned similar to the RA in the SLAAC method. This prefix is then used with the interface identifier to create a complete global IPv6 address.
Question 5: In my pcap captures, I am seeing that the Solicit and Advertise often contain these options as well. This seems redundant in the non-rapid case since the Request and subsequent Reply must also contain the option. What is the purpose for including this option in the Solicit ? And what is the purpose of the DHCP server creating the IP address (or prefix) in the Advertise before being Request ed to do so?
Question 6: The RFCs indicate that multiple instances of the IA_NA (or IA_TA ) option can be included. I assume this means that the interface will then have multiple addresses. Does the client simply include multiple instances of the option in the Request to get multiple addresses? What happens if a DHCP server can supply some, but not all of the addresses? Does the entire Reply indicate a failure? Or are some addresses given?
Releasing Addresses
For DHCPv6, an address in use can be released with a Release message. An address assigned by the server in a Reply can be declined by the client with a Decline message instead of being used.
If a client fails to send the Release or Decline , the server will continue to hold the address for the client until it expires.
Question 7: If a client can't send the Release (or Decline ) and reboots, it will initiate a new DHCP request. Will the DHCP server give back the old address? Or will it assume this is a request for an additional IP address and assign a new one?
I am not sure how addresses created by SLAAC or DHCP PD are released, if ever. Perhaps the release of these addresses is only done internally and no external device need know of the event.
As I stated at the beginning, my goal is to keep track of all the address assignments that are currently valid. My plan was to do the following:
- Create a map indexed by address which stores the client to which it is assigned (DUID).
- Extract the Client-DUID option
- For each IA , set map[address]=Client-DUID
- Store the expiry time of the address
- For each IA , set remove map[address]
- When an address expires, it will be removed from the map
Question 8: How do I detect SLAAC generated addresses or DHCP PD addresses? Is there some field in the messages I can use to regenerate the complete IP address? I will already have the prefix, but the interface ID is unknown.
Is this sufficient to maintain a list of IP addresses assigned to clients?
- That is a long question :). – thuovila Commented Aug 5, 2013 at 7:48
- Yes, I've already got some of the answers and will update it. – Trenin Commented Aug 6, 2013 at 13:19
- It's a long post and I will finish the article later, it's a question but I learned a lot from the post. Thanks. I will study and try to answer some questions later. – dspjm Commented Aug 18, 2013 at 8:54
- Some implementation details of DAD present here: criticalindirection.com/2015/06/30/ipv6_dad_floating_ips – user31986 Commented Jul 17, 2015 at 21:24
- You may get better answers to this question in networkengineering.stackexchange.com – StockB Commented May 4, 2016 at 14:29
2 Answers 2
OK - so I've done some more research and I have most of the answers now.
First of all, a correction. Addresses are not obtained via PD with DHCP. That is how DHCP servers obtain a network prefix to use for the DHCP clients they host. There is another DHCP server which deals with handing out these prefixes. Thus, PD can be ignored as a method for obtaining IP addresses.
Question 1a/b: Is there really no fall back here?
Answer: There is no automated fallback mechanism. One can be implemented, but it would be custom.
Question 2: Is this also an NS message?
Answer: Yes
Answer: Multiple addresses can be generated with SLAAC. A client can use the Router Advertisements from multiple routers, and each router may advertise multiple prefixes. Each prefix can be used by the host to create a global unicast address.
Question 8 (modified): How do I detect SLAAC generated addresses? Is there some field in the messages I can use to regenerate the complete IP address? I will already have the prefix, but the interface ID is unknown.
Answer: The only way to detect them is to listen for NS messages. Since these messages are optional, there is no guaranteed way to detect SLAAC generated addresses.
I still don't have answers for questions 4-7, but I am not too concerned with them at the moment.
There is a third method to get an IPv6 address, manual configuration.
- Yes - I referred to that in my post as the backup method when auto configuration fails. I am not concerned with that case since my goal is to keep track of the IP address assignments. If they are made statically, then the assignment can also be recorded statically. – Trenin Commented Aug 6, 2013 at 18:09
Your Answer
Reminder: Answers generated by artificial intelligence tools are not allowed on Stack Overflow. Learn more
Sign up or log in
Post as a guest.
Required, but never shown
By clicking “Post Your Answer”, you agree to our terms of service and acknowledge you have read our privacy policy .
Not the answer you're looking for? Browse other questions tagged ipv6 dhcp or ask your own question .
- The Overflow Blog
- Masked self-attention: How LLMs learn relationships between tokens
- Deedy Das: from coding at Meta, to search at Google, to investing with Anthropic
- Featured on Meta
- User activation: Learnings and opportunities
- Preventing unauthorized automated access to the network
- Feedback Requested: How do you use the tagged questions page?
Hot Network Questions
- BTD6 Kinetic Chaos (9/26/24 Odyssey)
- How to format units inside math environment?
- How many natural operations on subsets are there?
- Find all tuples with prescribed ordering
- What is the name for this BC-BE back-to-back transistor configuration?
- Improving MILP formulation (profitability based network design)
- Why would elves care what happens to Middle Earth?
- Story where the main character is hired as a FORTH interpreter. We pull back and realise he is a computer program living in a circuit board
- What is the average result of rolling Xd6 twice and taking the higher of the two sums?
- What is an "axiomatic definition"? Every definition is an axiomatic definition?
- Estimating an upper bound of hyperbolicity constants in Gromov-hyperbolic groups
- What is "illegal, immoral or improper" use in CPOL?
- What are major reasons why Republicans support the death penalty?
- Help with unidentified character denoting temperature, 19th century thermodynamics
- Shock absorber rusted from being outside
- What book is this proof from?
- Unbounded expansion in Tex
- Are logic and mathematics the only fields in which certainty (proof) can be obtained?
- Does copying files from one drive to another also copy previously deleted data from the drive one?
- In big band horn parts, should I write double flats (sharps) or the enharmonic equivalent?
- What "Texas and federal law"s is SpaceX "in violation of"?
- God the Father punished the Son for bearing the sin of the world: how does that prove God’s righteousness?
- YA sci fi book, tower on a planet with a destructive wind
- How Do Courts Decide Which Right Prevails When Fundamental Rights Conflict?
Your IP Address is: 185.80.151.41
Tip: try using "quotes around your search phrase"
- RIPE Document Store
- Documentation
- IPv6 Info Centre
IPv6 Address Allocation and Assignment Policy
- Policy Proposal 2019-06
This document defines registry policies for the assignment and allocation of globally unique IPv6 addresses to Internet Service Providers (ISPs) and other organisations. It was developed through joint discussions among the APNIC, ARIN and RIPE communities.
1. Introduction
1.1. overview.
This document describes policies for the allocation and assignment of globally unique Internet Protocol version 6 (IPv6) address space.
[ RFC 4291 ] designates 2000::/3 to be global unicast address space that the Internet Assigned Numbers Authority (IANA) may allocate to the RIRs. In accordance with [ RFC 4291 ], IANA allocated initial ranges of global unicast IPv6 address space from the 2000::/3 address block to the RIRs. This document concerns the initial and subsequent allocations of the 2000::/3 unicast address space, for which RIRs formulate allocation and assignment policies. All bits to the left of /64 are in scope.
2. Definitions
[Note: some of these definitions will be replaced by definitions from other RIR documents in order to be more consistent.]
The following terms and their definitions are of particular importance to the understanding of the goals, environment and policies described in this document.
Responsibility for management of IPv6 address spaces is distributed globally in accordance with the hierarchical structure shown below.
2.1. Internet Registry (IR)
An Internet Registry is an organisation that is responsible for distributing IP address space to its members or customers and for registering those distributions. IRs are classified according to their primary function and territorial scope within the hierarchical structure depicted in the figure above.
2.2. Regional Internet Registry (RIR)
Regional Internet Registries are established and authorised by respective regional communities and recognised by the IANA to serve and represent large geographical regions. The primary role of RIRs is to manage and distribute public Internet address space within their respective regions.
2.3. National Internet Registry (NIR)
A National Internet Registry primarily allocates address space to its members or constituents, which are generally LIRs organised at a national level. NIRs exist mostly in the Asia Pacific region.
2.4. Local Internet Registry (LIR)
A Local Internet Registry is an IR that primarily assigns address space to the users of the network services that it provides. LIRs are generally ISPs whose customers are primarily End Users and possibly other ISPs.
2.5. Allocate
To “allocate” means to distribute address space to IRs for the purpose of subsequent distribution by them.
2.6. Assign
To “assign” means to delegate address space to an ISP or End User for specific use within the Internet infrastructure they operate. Assignments must only be made for specific purposes documented by specific organisations and are not to be sub-assigned to other parties.
Providing another entity with separate addresses (not prefixes) from a subnet used on a link operated by the assignment holder is not considered a sub-assignment. This includes for example letting visitors connect to the assignment holder's network, connecting a server or appliance to an assignment holder's network and setting up point-to-point links with 3rd parties.
2.7. Utilisation
The actual usage of addresses within each assignment may be low when compared to IPv4 assignments. In IPv6, "utilisation" is only measured in terms of the bits to the left of the efficiency measurement unit (/56). In other words, "utilisation" effectively refers to the assignment of network prefixes to End Sites and not the number of addresses assigned within individual End Site assignments.
Throughout this document, the term "utilisation" refers to the assignment of network prefixes to End Sites and not the number of addresses assigned within individual subnets within those End Sites.
2.8. HD-Ratio
The HD-Ratio is a way of measuring the efficiency of address assignment [ RFC 3194 ]. It is an adaptation of the H-Ratio originally defined in [ RFC 1715 ] and is expressed as follows:
where (in the case of this document) the objects are IPv6 site addresses assigned from an IPv6 prefix of a given size.
2.9. End Site
An End Site is defined as the location of an End User (subscriber) who has a business or legal relationship (same or associated entities) with a service provider that involves:
- that service provider assigning address space to the End User location
- that service provider providing transit service for the End User location to other sites
- that service provider carrying the End User's location traffic
- that service provider advertising an aggregate prefix route that contains the End User's location assignment
3. Goals of IPv6 address space management
IPv6 address space is a public resource that must be managed in a prudent manner with regards to the long-term interests of the Internet. Responsible address space management involves balancing a set of sometimes competing goals. The following are the goals relevant to IPv6 address policy.
3.2. Uniqueness
Every assignment and/or allocation of address space must guarantee uniqueness worldwide. This is an absolute requirement for ensuring that every public host on the Internet can be uniquely identified.
3.3. Registration
Internet address space must be registered in a registry database accessible to appropriate members of the Internet community. This is necessary to ensure the uniqueness of each Internet address and to provide reference information for Internet troubleshooting at all levels, ranging from all RIRs and IRs to End Users.
The goal of registration should be applied within the context of reasonable privacy considerations and applicable laws.
3.4. Aggregation
Wherever possible, address space should be distributed in a hierarchical manner, according to the topology of network infrastructure. This is necessary to permit the aggregation of routing information by ISPs and to limit the expansion of Internet routing tables.
This goal is particularly important in IPv6 addressing, where the size of the total address pool creates significant implications for both internal and external routing.
IPv6 address policies should seek to avoid fragmentation of address ranges.
Further, RIRs should apply practices that maximise the potential for subsequent allocations to be made contiguous with past allocations currently held. However, there can be no guarantee of contiguous allocation.
3.5. Conservation
Although IPv6 provides an extremely large pool of address space, address policies should avoid unnecessarily wasteful practices. Requests for address space should be supported by appropriate documentation and stockpiling of unused addresses should be avoided.
3.6. Fairness
All policies and practices relating to the use of public address space should apply fairly and equitably to all existing and potential members of the Internet community, regardless of their location, nationality, size, or any other factor.
3.7. Minimised overhead
It is desirable to minimise the overhead associated with obtaining address space. Overhead includes the need to go back to RIRs for additional space too frequently, the overhead associated with managing address space that grows through a number of small successive incremental expansions rather than through fewer, but larger, expansions.
3.8. Conflict of goals
The goals described above will often conflict with each other, or with the needs of individual IRs or End Users. All IRs evaluating requests for allocations and assignments must make judgments, seeking to balance the needs of the applicant with the needs of the Internet community as a whole.
In IPv6 address policy, the goal of aggregation is considered to be the most important.
4. IPv6 Policy Principles
To address the goals described in the previous section, the policies in this document discuss and follow the basic principles described below.
4.1. Address space not to be considered property
It is contrary to the goals of this document and is not in the interests of the Internet community as a whole for address space to be considered freehold property.
The policies in this document are based upon the understanding that globally unique IPv6 unicast address space is licensed for use rather than owned. Specifically, IP addresses will be allocated and assigned on a license basis, with licenses subject to renewal on a periodic basis. The granting of a license is subject to specific conditions applied at the start or renewal of the license.
RIRs will generally renew licenses automatically, provided requesting organisations are making a “good faith” effort at meeting the criteria under which they qualified for or were granted an allocation or assignment. However, in those cases where a requesting organisation is not using the address space as intended, or is showing bad faith in following through on the associated obligation, RIRs reserve the right to not renew the license. Note that when a license is renewed, the new license will be evaluated under and governed by the applicable IPv6 address policies in place at the time of renewal, which may differ from the policy in place at the time of the original allocation or assignment.
4.2. Routability not guaranteed
There is no guarantee that any address allocation or assignment will be globally routable.
However, RIRs must apply procedures that reduce the possibility of fragmented address space which may lead to a loss of routability.
4.3. Minimum allocation
The minimum allocation size for IPv6 address space is /32.
4.4. Consideration of IPv4 infrastructure
Where an existing IPv4 service provider requests IPv6 space for eventual transition of existing services to IPv6, the number of present IPv4 customers may be used to justify a larger request than would be justified if based solely on the IPv6 infrastructure.
5. Policies for Allocations and Assignments
5.1. initial allocation, 5.1.1. initial allocation criteria for lirs.
To qualify for an initial allocation of IPv6 address space, an LIR must have a plan for making sub-allocations to other organisations and/or End Site assignments within two years.
5.1.2. Initial allocation size
LIRs that meet the initial allocation criteria are eligible to receive an initial allocation of /32 up to /29 without needing to supply any additional information.
LIRs may qualify for an initial allocation greater than /29 by submitting documentation that reasonably justifies the request. If so, the allocation size will be based on the number of users, the extent of the LIR infrastructure, the hierarchical and geographical structuring of the LIR, the segmentation of infrastructure for security and the planned longevity of the allocation.
5.2. Subsequent allocation
LIRs that have received an IPv6 allocation may receive a subsequent allocation in accordance with the following policies.
5.2.1. Subsequent allocation criteria
Subsequent allocation will be provided when an LIR:
a) Satisfies the evaluation threshold of past address utilisation in terms of the number of sites in units of /56. To this end, the HD-Ratio [ RFC 3194 ] is used to determine the utilisation thresholds. or
b) Can justify new needs (which can't be satisfied within the previous allocation), according to the initial allocation size criteria as described in section 5.1.2.
5.2.2. Applied HD-Ratio
The HD-Ratio value of 0.94 is adopted as indicating an acceptable address utilisation for justifying the allocation of additional address space. Appendix A provides a table showing the number of assignments that are necessary to achieve an acceptable utilisation value for a given address block size.
5.2.3. Subsequent allocation size
When an LIR meets the subsequent allocation criteria, it is immediately eligible to obtain an additional allocation that results in a doubling of the address space allocated to it. Where possible, the allocation will be made from an adjacent address block, meaning that its existing allocation is extended by one bit to the left.
If an LIR needs more address space, it must provide documentation justifying its new requirements, as described in section 5.1.2. The allocation made will be based on the relevant documentation.
5.3. LIR-to-ISP allocation
There is no specific policy for an LIR to allocate address space to subordinate ISPs. Each LIR organisation may develop its own policy for subordinate ISPs to encourage optimum utilisation of the total address block allocated to the LIR. However, all /48 assignments to End Sites are required to be registered either by the LIR or its subordinate ISPs in such a way that the RIR/NIR can properly evaluate the HD-Ratio when a subsequent allocation becomes necessary.
5.4. Assignment
LIRs must make IPv6 assignments in accordance with the following provisions.
5.4.1. Assignment address space size
End Users are assigned an End Site assignment from their LIR or ISP. The size of the assignment is a local decision for the LIR or ISP to make, using a value of "n" x /64. Section 4.2 of ripe-690 provides guidelines about this.
5.4.2. Assignments shorter than a /48 to a single End Site
Assignments larger than a /48 (shorter prefix) or additional assignments exceeding a total of a /48 must be based on address usage or because different routing requirements exist for additional assignments.
In case of an audit or when making a request for a subsequent allocation, the LIR must be able to present documentation justifying the need for assignments shorter than a /48 to a single End-Site.
5.5. Registration
When an LIR holding an IPv6 address allocation makes IPv6 address assignments, it must register these assignments in the appropriate RIR database.
These registrations can either be made as individual assignments or by inserting an object with a status value of 'AGGREGATED-BY-LIR' where the assignment-size attribute contains the size of the individual assignments made to End Users. When more than a /48 is assigned to an organisation, it must be registered in the database as a separate object with status 'ASSIGNED'.
In case of an audit or when making a request for a subsequent allocation, the LIR must be able to present statistics showing the number of individual assignments made in all objects with a status of 'AGGREGATED-BY-LIR' in such a way the RIR is able to calculate and verify the actual HD-ratio.
5.6. Reverse lookup
When an RIR/NIR delegates IPv6 address space to an LIR, it also delegates the responsibility to manage the reverse lookup zone that corresponds to the allocated IPv6 address space. Each LIR should properly manage its reverse lookup zone. When making an address assignment, the LIR must delegate to an assignee organisation, upon request, the responsibility to manage the reverse lookup zone that corresponds to the assigned address.
5.7. Existing IPv6 address space holders
LIRs that hold one or more IPv6 allocations are able to request extension of each of these allocations up to a /29 without providing further documentation.
The RIPE NCC should allocate the new address space contiguously with the LIRs' existing allocations and avoid allocating non-contiguous space under this policy section.
6. Anycasting TLD and Tier 0/1 ENUM Nameservers
The organisations applicable under this policy are TLD managers, as recorded in the IANA's Root Zone Database and ENUM administrators, as assigned by the ITU. The organisation may receive up to four /48 prefixes per TLD and four /48 prefixes per ENUM. These prefixes must be used for the sole purpose of anycasting authoritative DNS servers for the stated TLD/ENUM, as described in BCP126/ RFC 4786 .
Assignments for authoritative TLD or ENUM Tier 0/1 DNS lookup services are subject to the policies described in the RIPE Document entitled " Contractual Requirements for Provider Independent Resource Holders in the RIPE NCC Service Region ".
Anycasting assignments are registered with a status of 'ASSIGNED ANYCAST' in the RIPE Database and must be returned to the RIPE NCC if not in use for infrastructure providing authoritative TLD or ENUM Tier 0/1 DNS lookup services any longer.
7. IPv6 Provider Independent (PI) Assignments
To qualify for IPv6 PI address space, an organisation must meet the requirements of the policies described in the RIPE NCC document entitled “ Contractual Requirements for Provider Independent Resources Holders in the RIPE NCC Service Region ”.
The RIPE NCC will assign the prefix directly to the End User organisations upon a request properly submitted to the RIPE NCC, either directly or through a sponsoring LIR.
Assignments will be made from a separate 'designated block' to facilitate filtering practices.
The PI assignment cannot be further sub-assigned to other organisations.
7.1. IPv6 Provider Independent (PI) Assignment Size
The minimum size of the assignment is a /48.
The considerations of "5.4.2. Assignments shorter than a /48 to a single End-Site" must be followed if needed.
7.2. IPv6 Provider Independent (PI) Assignments for LIRs
LIRs can qualify for an IPv6 PI assignment for parts of their own infrastructure that are not used for customer end sites. Where an LIR has an IPv6 allocation, the LIR must demonstrate the unique routing requirements for the PI assignment.
The LIR should return the IPv6 PI assignment within a period of six months if the original criteria on which the assignment was based are no longer valid.
8. Transfer of IPv6 resources
The transfer of Internet number resources is governed by the RIPE Document, " RIPE Resource Transfer Policies ".
9. References
[RFC 1715] "The H Ratio for Address Assignment Efficiency", C. Huitema. November 1994, ftp://ftp.ripe.net/rfc/rfc1715.txt
[RFC 2026] "The Internet Standards Process -- Revision 3 IETF Experimental RFC ftp://ftp.ripe.net/rfc/rfc2026.txt see Sec. 4.2.1
[RFC 2462] "IPv6 Stateless Address Autoconfiguration", S. Thomson, T. Narten, 1998, ftp://ftp.ripe.net/rfc/rfc2462.txt
[RFC 4291] "IP Version 6 Addressing Architecture", R. Hinden, S. Deering. February 2006, ftp://ftp.ripe.net/rfc/rfc4291.txt
[RFC 2928] "Initial IPv6 Sub-TLA ID Assignments", R. Hinden, S. Deering, R. Fink, T. Hain. September 2000 ftp://ftp.ripe.net/rfc/rfc2928.txt
[RFC 3194] "The H-Density Ratio for Address Assignment Efficiency An Update on the H ratio", A. Durand, C. Huitema. November 2001, ftp://ftp.ripe.net/rfc/rfc3194.txt
[RFC 4786] "Operation of Anycast Services", J. Abley, K. Lindqvist. December 2006, ftp://ftp.ripe.net/rfc/rfc4786.txt
10. Appendix A: HD-Ratio
The utilisation threshold T, expressed as a number of individual /56 prefixes to be allocated from IPv6 prefix P, can be calculated as:
Thus, the utilisation threshold for an LIR requesting subsequent allocation of IPv6 address block is specified as a function of the prefix size and target HD ratio. This utilisation refers to the use of /56s as an efficiency measurement unit, and does not refer to the utilisation of addresses within those End Sites. It is an address allocation utilisation ratio and not an address assignment utilisation ratio.
In accordance with the recommendations of [ RFC 3194 ], this document adopts an HD-Ratio of 0.94 as the utilisation threshold for IPv6 address space allocations.
The following table provides equivalent absolute and percentage address utilisation figures for IPv6 prefixes, corresponding to an HD-Ratio of 0.94.
|
|
|
|
|
| 10 | 70368744177664 | 10388121308479 | 14.76 |
| 11 | 35184372088832 | 5414630391777 | 15.39 |
| 12 | 17592186044416 | 2822283395519 | 16.04 |
| 13 | 8796093022208 | 1471066903609 | 16.72 |
| 14 | 4398046511104 | 766768439460 | 17.43 |
| 15 | 2199023255552 | 399664922315 | 18.17 |
| 16 | 1099511627776 | 208318498661 | 18.95 |
| 17 | 549755813888 | 108582451102 | 19.75 |
| 18 | 274877906944 | 56596743751 | 20.59 |
| 19 | 137438953472 | 29500083768 | 21.46 |
| 20 | 68719476736 | 15376413635 | 22.38 |
| 21 | 34359738368 | 8014692369 | 23.33 |
| 22 | 17179869184 | 4177521189 | 24.32 |
| 23 | 8589934592 | 2177461403 | 25.35 |
| 24 | 4294967296 | 1134964479 | 26.43 |
| 25 | 2147483648 | 591580804 | 27.55 |
| 26 | 1073741824 | 308351367 | 28.72 |
| 27 | 536870912 | 160722871 | 29.94 |
| 28 | 268435456 | 83774045 | 31.21 |
| 29 | 134217728 | 43665787 | 32.53 |
| 30 | 67108864 | 22760044 | 33.92 |
| 31 | 33554432 | 11863283 | 35.36 |
| 32 | 16777216 | 6183533 | 36.86 |
11. Appendix B: Background information
11.1. background.
The impetus for revising the 1999 provisional IPv6 policy started with the APNIC meeting held in Taiwan in August 2001. Follow-on discussions were held at the October 2001 RIPE and ARIN meetings. During these meetings, the participants recognised an urgent need for more detailed, complete policies. One result of the meetings was the establishment of a single mailing list to discuss a revised policy together with a desire to develop a general policy that all RIRs could use. This document does not provide details of individual discussions that lead to policies described in this document; detailed information can be found in the individual meeting minutes at the www.apnic.net, www.arin.net, and www.ripe.net web sites.
In September 2002 at the RIPE 43 Meeting in Rhodes, Greece, the RIPE community approved the policy allowing Internet experiments to receive temporary assignments. As a result, Section 6 was added to this document in January 2003.
11.2. Why a joint policy?
IPv6 addresses are a public resource that must be managed with consideration to the long-term interests of the Internet community. Although regional registries adopt allocation policies according to their own internal processes, address policies should largely be uniform across registries. Having significantly varying policies in different regions is undesirable because it can lead to situations where "registry shopping" can occur as requesting organisations request addresses from the registry that has the most favorable policy for their particular desires. This can lead to the policies in one region undermining the efforts of registries in other regions with regards to prudent stewardship of the address space. In cases where regional variations from the policy are deemed necessary, the preferred approach is to raise the issue in the other regional registries in order to develop a consensus approach that all registries can support.
11.3. The size of IPv6's address space
Compared to IPv4, IPv6 has a seemingly endless amount of address space. While superficially true, short-sighted and wasteful allocation policies could also result in the adoption of practices that lead to premature exhaustion of the address space.
It should be noted that the 128-bit address space is divided into three logical parts, with the usage of each component managed differently. The rightmost 64 bits, the Interface Identifier [RFC 4291], will often be a globally unique IEEE identifier (e.g., mac address). Although an "inefficient" way to use the Interface Identifier field from the perspective of maximizing the number of addressable nodes, the numbering scheme was explicitly chosen to simplify Stateless Address Autoconfiguration [ RFC 2462 ].
The middle bits of an address indicate the subnet ID. This field may often be inefficiently utilised, but the operational benefits of a consistent width subnet field were deemed to be outweigh the drawbacks. This is a variable length field, determined by each LIR's local assignment policy.
11.4. Acknowledgment
The initial version of this document was produced by the JPNIC IPv6 policy drafting team consisting of Akihiro Inomata, Akinori Maemura, Kosuke Ito, Kuniaki Kondo, Takashi Arano, Tomohiro Fujisaki, and Toshiyuki Yamasaki. Special thanks goes out to this team, who worked over a holiday in order to produce an initial document quickly.
An editing team was then organised by representatives from each of the three RIRs (Takashi Arano, Chair of APNIC's Policy SIG, Thomas Narten, Chair of ARIN's IPv6 WG, and David Kessens, Chair of the RIPE IPv6 Working Group).
The editing team would like to acknowledge the contributions to this document of Takashi Arano, John Crain, Steve Deering, Gert Doering, Kosuke Ito, Richard Jimmerson, David Kessens, Mirjam Kuehne, Anne Lord, Jun Murai, Paul Mylotte, Thomas Narten, Ray Plzak, Dave Pratt, Stuart Prevost, Barbara Roseman, Gerard Ross, Paul Wilson, Cathy Wittbrodt and Wilfried Woeber.
The final editing of the initial version of this document was done by Thomas Narten.
IPv6 configuration
See also: Static IPv6 routes , IPv6 routing example , IPv4/IPv6 transitioning , IPv6 extras
The default firmware provides full IPv6 support with a DHCPv6 client ( odhcp6c ), an RA & DHCPv6 Server ( odhcpd ) and a IPv6 firewall ( ip6tables ). Also, the default installation of the web interface includes the package luci-proto-ipv6 , required to configure IPv6 from the luci web interface.
Our aim is to follow RFC 7084 where possible. Please notify us if you find any standard violations.
The following requirements of RFC 7084 are currently known not to be met:
- RFC 7084 WAA-5 (SHOULD-requirement): The NTP -Server is requested and received but currently not processed or used.
General features
- Management of prefixes, addresses and routes from upstream connections and local ULA-prefixes
- Management of prefix unreachable-routes, prefix deprecation ( RFC 7084 ) and prefix classes
- Distribution of prefixes onto downstream interfaces (including size, ID and class hints)
- Source-based policy routing to correctly handle multiple uplink interfaces, ingress policy filtering ( RFC 7084 )
Upstream configuration for WAN interfaces
The following sections describe the configuration of IPv6 connections to your ISP or an upstream router. Please note that most tunneling mechanisms like 6in4, 6rd and 6to4 may not work behind a NAT -router. Multiple IPv6 addresses can be assigned with aliases .
Native IPv6 connection
- Automatic bootstrap from SLAAC, stateless DHCPv6, stateful DHCPv6, DHCPv6-PD and any combination
- Handling of preferred and valid address and prefix lifetimes
- Duplicate address (DAD) and Link- MTU detection
- DHCPv6 Extensions: Reconfigure, Information-Refresh, SOL_MAX_RT=3600
- DHCPv6 Extensions: RDNSS, DNS Search Domain, NTP , SIP, ds-lite, prefix exclusion (experimental)
For an uplink with native IPv6 -connectivity you can use the following example configuration. It will work both for uplinks supporting DHCPv6 with Prefix Delegation and those that don't support DHCPv6-PD or DHCPv6 at all (SLAAC-only).
See below for advanced configuration options of protocol dhcpv6 .
PPP-based protocols and option ipv6
PPP-based protocols - for example pppoe and pppoa - require that option ipv6 is specified in the parent config interface wan section. See WAN interface protocols . option ipv6 can take the value:
- 0 : disable IPv6 on the interface
- 1 : enable IPCP6 negotiation on the interface, but nothing else. If successful, the parent interface will be assigned a link-local address (prefix fe80::/10). All other IPv6 configuration is made in the wan6 interface which must be configured manually, as described below.
- auto : (default) enable IPv6 on the interface. Spawn a virtual interface wan_6 (note the underscore) and start DHCPv6 client odhcp6c to manage prefix assignment. Ensure the lan interface has option ip6assign 64 (or a larger prefix size) set to redistribute the received prefix downstream.
Further configuration options, if required, can be given in the config interface wan6 section.
Note: In order to successfully receive DHCPv6 advertisement unicast messages from the dhcp6s to OpenWrt dhcp6c, you will need to have firewall rule for the WAN zone (already allowed in default):
Protocol "dhcpv6"
These are available options in uci configuration of client ipv6 interface (using the “dhcpv6” protocol).
| Name | Type | Required | Default | Description |
|---|---|---|---|---|
| [try,force,none] | no | try | Behaviour for requesting addresses | |
| [auto,no,0-64] | no | auto | Behaviour for requesting prefixes (numbers denote hinted prefix length). Use 'no' if you only want a single address for the itself without a subnet for routing | |
| hexstring | no | Override client identifier in requests (Option 1). The odhcp6c default is concatenated with the MAC address - see | ||
| ipv6 addr | no | Override the interface identifier for adresses received via RA (Router Advertisement) | ||
| list of ip addresses | no | Supplement -assigned server(s), or use only these if peerdns is 0 | ||
| boolean | no | Use -provided server(s) | ||
| boolean | no | Ignore default lifetime for RDNSS records | ||
| boolean | no | Whether to create an default route via the received gateway | ||
| list of numbers | no | Specifies a list of additional options to request | ||
| boolean | no | If set to , do not request any options except those specified in | ||
| string | no | Space-separated list of additional options to send to the server. Syntax: where is either an integer code or a symbolic name such as . | ||
| boolean | no | Don't allow configuration via SLAAC (RAs) only (implied by reqprefix != no) | ||
| boolean | no | Require presence of Prefix in received message | ||
| boolean | no | Don't send a RELEASE when the interface is brought down | ||
| ipv6 prefix | no | Use an (additional) user-provided prefix for distribution to clients | ||
| boolean | no | On a 3GPP Mobile link, accept a /64 prefix via SLAAC and extend it on one downstream interface - see | ||
| logical interface | no | Logical interface template for auto-configuration of DS-Lite (0 means disable DS-Lite autoconfiguration; every other value will autoconfigure DS-Lite when the AFTR-Name option is received) | ||
| string | no | Firewall zone of the logical DS-Lite interface | ||
| string | no | Logical interface template for auto-configuration of either map-e/map-t/lw6o4 autoconfiguration (0 means disable map-e/map-t/lw406 autoconfiguration; every other value will autoconfigure map-e/map-t/lw4o6 when the corresponding Softwire46 options are received) | ||
| string | no | Firewall zone of the logical map-e/map-t/lw6o4 interface | ||
| string | no | Logical interface template for the 464xlat interface (0 means disable 464xlat autoconfiguration; every other value will try to autoconfigure 464xlat) | ||
| string | no | Firewall zone of the logical 464xlat interface | ||
| string | no | Firewall zone to which the interface will be added | ||
| boolean | no | Whether to enable source based routing | ||
| string | no | Vendor class to be included in the messages (Option 16) | ||
| string | no | User class to be be included in the messages (Option 15) | ||
| boolean | no | Whether to enable prefix delegation in case of DS-Lite/map/464xlat | ||
| integer | no | The maximum solicit timeout | ||
| boolean | no | Fake default route when no route info via RA is received | ||
| integer | no | Minimum time in seconds between accepting RA updates | ||
| boolean | no | Don't send Client option (Option 39). The unset default uses the system hostname e.g. | ||
| boolean | no | Don't send Accept Reconfigure option | ||
| boolean | no | Ignore Server Unicast option | ||
| integer | no | Set packet kernel priority | ||
| boolean | no | Increase logging verbosity |
Note: To automatically configure ds-lite from dhcpv6, you need to create an interface with option auto 0 and put its name as the 'iface_dslite' parameter. In addition, you also need to add its name to a suitable firewall zone in /etc/config/firewall.
Static IPv6 connection
Static configuration of the IPv6 uplink is supported as well. The following example demonstrates this.
For advanced configuration options see below for the usable options in a IPv6 “static” protocol:
Protocol "static", IPv6
| Name | Type | Required | Default | Description |
|---|---|---|---|---|
| ipv6 address | yes, if no is set | Assign given address to this interface (CIDR notation) | ||
| ipv6 suffix | no | ::1 | Allowed values: 'eui64', 'random', fixed value like '::1:2'. It is advised to use just '::' as this is a ' When prefix (like 'a:b:c:d::') is received from a delegating server, use the suffix (like '::1') to form the address ('a:b:c:d::1') for this interface. Useful with several routers in . The option was introduced by to netifd in Jan 2015. | |
| ipv6 address | no | Assign given default gateway to this interface | ||
| prefix length | no | Delegate a prefix of given length to this interface (see Downstream configuration below) | ||
| prefix hint (hex) | no | Hint the subprefix-ID that should be delegated as hexadecimal number (see Downstream configuration below) | ||
| ipv6 prefix | no | prefix routed here for use on other interfaces (Barrier Breaker and later only) | ||
| list of strings | no | Define the prefix-classes this interface will accept | ||
| boolean | no | Set preferred lifetime of addresses to zero | ||
| list of ip addresses | no | server(s) | ||
| integer | no | |||
| list of domain names | no | Search list for host-name lookup, relevant only for the router | ||
| integer | no | Specifies the default route metric to use |
Downstream configuration for LAN interfaces
- Server support for Router Advertisement, DHCPv6 (stateless and stateful) and DHCPv6-PD
- Automatic detection of announced prefixes, delegated prefixes, default routes and MTU
- Change detection for prefixes and routes triggering resending of RAs and DHCPv6-Reconfigure
- Detection of client hostnames and export as augmented hosts-file
- Support for RA & DHCPv6-relaying and NDP-proxying to e.g. support uplinks without prefix delegation
OpenWrt provides a flexible local prefix delegation mechanism.
It can be tuned for each downstream-interface individually with 3 parameters which are all optional:
- ip6assign : Prefix size used for assigned prefix to the interface (e.g. 64 will assign /64-prefixes)
- ip6hint : Subprefix ID to be used if available (e.g. 1234 with an ip6assign of 64 will assign prefixes of the form ...:1234::/64 or given LAN ports, LAN & LAN2, and a prefix delegation of /56, use ip6hint of 00 and 80 which would give prefixes of LAN ...:xx00::/64 and LAN2 ...:xx80::/64)
- ip6class : Filter for prefix classes to accept on this interface (e.g. wan6 - only assign prefix from the respective interface, local - only assign the ULA-prefix)
ip6assign and / or ip6hint settings might be ignored if the desired subprefix cannot be assigned. In this case, the system will first try to assign a prefix with the same length but different subprefix-ID. If this fails as well, the prefix length is reduced until the assignment can be satisfied. If ip6hint is not set, an arbitrary ID will be chosen. Setting the ip6assign parameter to a value < 64 will allow the DHCPv6-server to hand out all but the first /64 via DHCPv6-Prefix Delegation to downstream routers on the interface. If ip6hint is not suitable for the given ip6assign , it will be rounded down to the nearest possible value.
If ip6class is not set, then all prefix classes are accepted on this interface. Specify one or multiple interface names such as wan6 to accept only prefix from the respective interface, or specify local accept only the ULA-prefix when using IPv6 NAT or NPT. This can be used to select upstream interfaces from which subprefixes are assigned. For prefixes received from dynamic-configuration methods like DHCPv6, it is possible that the prefix-class is not equal to the source-interface but e.g. augmented with an ISP -provided numeric prefix class-value.
The results of that configuration would be:
- The lan interface will be assigned the prefixes 2001:db80:0:10::/60 and fd00:db80:0:10::/60.
- The DHCPv6-server can offer both prefixes except 2001:db80:0:10::/64 and fd00:db80:0:10::/64 to downstream routers on lan via DHCPv6-PD.
- The guest interface will only get assinged the prefix 2001:db80:0:abcd::/64 due to the class filter.
For multiple interfaces, the prefixes are assigned based on firstly the assignment length (smallest first) then on weight and finally alphabetical order of interface names. e.g. if wlan0 and eth1 have ip6assign 61 and eth2 has ip6assign 62, the prefixes are assigned to eth1 then wlan0 (alphabetic) and then eth2 (longest prefix). Note that if there are not enough prefixes, the last interfaces get no prefix - which would happen to eth2 if the overall prefix length was 60 in this example.
Router Advertisement & DHCPv6
OpenWrt features a versatile RA & DHCPv6 server and relay. Per default, SLAAC and both stateless and stateful DHCPv6 are enabled on an interface. If there are any prefixes of size /64 or shorter present then addresses will be handed out from each prefix. If all addresses on an interface have prefixes shorter than /64, then DHCPv6 Prefix Delegation is enabled for downstream routers. If a default route is present, the router advertises itself as default router on the interface.
The system is also able to detect when there is no prefix available from an upstream interface and can switch into relaying mode automatically to extend the upstream interface configuration onto its downstream interfaces. This is useful for putting the target router behind another IPv6 router which doesn't offer prefixes via DHCPv6-PD.
SLAAC and DHCPv6
Example configuration section for SLAAC + DHCPv6 server mode. This is suitable also for a typical 6in4 tunnel configuration, where you specify the fixed LAN prefix in the tunnel interface config. Make sure to disable NDP-Proxy by removing the ndp option if any.
Example configuration section for SLAAC alone. Make sure to deactivate RA flags, otherwise clients expect the presence of a DHCPv6 and consequently may fail to activate the network connection. Note that disabling DHCPv6 makes some clients (e.g. Android devices) prefer IPv4 over IPv6 .
Example configuration section for relaying
Routing Management
OpenWrt uses a source-address and source-interface based policy-routing system. This is required to correctly handle different uplink interfaces. Each delegated prefix is added with an unreachable route to avoid IPv6 -routing loops.
To determine the current status of routes you can consult the information provided by ifstatus .
Example (ifstatus wan6):
Interpretation:
- On the interface 2 routes are provided: 2001:db80::/48 and a default-route via the router fe80::800:27ff:fe00:0.
- These routes can only be used by locally generated traffic and traffic with a suitable source-address, that is either one of the local addresses or an address out of the delegated prefix.
IPv6 ULA prefix can serve the following purposes:
- Predictable static IPv6 suffix allocation with DHCPv6.
- Predictable site-to-site connectivity with dynamic or missing GUA prefix.
- IPv6 routing for LAN clients behind NAT66 with missing GUA prefix.
If IPv6 GUA is not available, a workaround is generally required to make applications prefer IPv6 over IPv4 .
- Last modified: 2024/09/18 12:44
- by aleks-mariusz

IPv6 prefix assignment BCOP published as RIPE-690

RIPE-690 outlines best current operational practices for the assignment of IPv6 prefixes (i.e. a block of IPv6 addresses) for end-users, as making wrong choices when designing an IPv6 network will eventually have negative implications for deployment and require further effort such as renumbering when the network is already in operation. In particular, assigning IPv6 prefixes longer than /56 to residential customers is strongly discouraged, with /48 recommended for business customers. This will allow plenty of space for future expansion and sub-netting without the need for renumbering, whilst persistent prefixes (i.e. static) should be highly preferred for simplicity, stability and cost reasons.
The target audience of RIPE-690 is technical staff working in ISPs and other network operators who currently provide or intend to provide IPv6 services to residential or business end-users. Up until now, there have been no clear recommendations on how to assign IPv6 prefixes to customers, and a variety of different and sometimes problematic solutions have been implemented.
By bringing together subject matter experts with practical deployment experience, it’s been possible to identify common practices and problems, and provide recommended solutions to some of the more commonly encountered issues.
The authors of the document were Jan Žorž, Sander Steffann, Primož Dražumerič, Mark Townsley, Andrew Alston, Gert Doering, Jordi Palet, Jen Linkova, Luis Balbinot, Kevin Meynell and Lee Howard. Other contributors were Nathalie Kunneke-Trenaman, Mikael Abrahamsson, Jason Fesler, Martin Levy, Ian Dickinson, Philip Homburg, Ivan Pepelnjak, Matthias Kluth, Ondřej Caletka, Nick Hilliard, Paul Hoffman, Tim Chown, Nurul Islam, Yannis Nikolopoulos and Marco Hogewoning.
The document was submitted to the RIPE BCOP Task Force and then to the RIPE IPv6 Working Group , as part of the Internet community feedback and consensus building process. Thanks should go the Chairs of those groups who ensured the recommendations do conform with actual best operational practice, along with the RIPE NCC staff who facilitated the publishing process.
So now there are some agreed stable recommendations for IPv6 prefix assignment for end-users, we’d ask all network operators to read and consider the document when deploying IPv6 to your customers.
And as always, please visit Deploy360’s Start Here page to find resources on how to get started with IPv6.
Disclaimer: Viewpoints expressed in this post are those of the author and may or may not reflect official Internet Society positions.
Recent Posts
- Looking Beyond the Global Digital Compact
- Texas’ Mandatory Age Verification Law Will Weaken Privacy and Security on the Internet
- US Government Networks Get a Security Boost: White House Roadmap Tackles Routing Vulnerabilities
- Beginning a New Role as President and CEO
- Amplifying Impact: Empowering the Next Generation of Computer Networkers
Related Posts
Dns privacy frequently asked questions (faq).
We previously posted about how the DNS does not inherently employ any mechanisms to provide confidentiality for DNS transactions,...
Introduction to DNS Privacy
Almost every time we use an Internet application, it starts with a DNS (Domain Name System) transaction to map...
IPv6 Security for IPv4 Engineers
It is often argued that IPv4 practices should be forgotten when deploying IPv6, as after all IPv6 is a...
IPv6 prefix lengths
By Geoff Huston on 25 Apr 2024
Category: Tech matters
Tags: IPv6 , measurement

Co-authored by Nathan Ward.
The topic of address plans for IPv6 has had a rich and varied history. From the very early concepts of ‘it’s just like IPv4, only with a 128-bit address field’, through the models of ‘Aggregation Identifiers’ and the hierarchy of ‘Top-Level,’ ‘Next-Level’ and ‘Site-Level’ defined in RFC 2373 from July 1998 and then the simplified adoption of a /48 Site-Level prefix in RFC 3177 from September 2001 to the address plan of RFC 6177 from March 2011, which avoids, as far as possible, the use of fixed boundaries in the address plan.
What we have today is a single ‘boundary’ in the IPv6 address plan, where the low order 64 bits are locally assigned as an interface identifier, and the high order 64 bits are in essence a network identifier, where the boundary between what constitutes locally-defined site networks and globally visible networks is left to each network operator.
The concept behind this 64-bit interface identifier was the idea that all hosts would maintain a constant 64-bit interface identifier irrespective of where and when the host was attached to a public network. In theory, a site could maintain local connectivity based only on these 64-bit values, regardless of the site’s external connectivity. This was supposed to aid in sites improving their resiliency through having an option for multiple external connections and allowing disconnected sites to still operate.
As subsequently pointed out in RFC 4941 , this represented a significant vulnerability to user privacy, allowing an external observer to correlate multiple appearances of the same mobile host on multiple access networks over time. This RFC recommended that IPv6 hosts use a random IPv6 interface identifier, and regularly change its value. The effective result is that almost all IPv6 hosts (some 96.15% of IPv6 hosts as seen in APNIC Labs’ IPv6 measurement program) use these random interface identifiers in place of a static 64-bit interface identifier for public communications.
The question is, why do we persist with this 64 / 64-bit boundary in the IPv6 address architecture between the network and the host identifier? Why did we not just go all the way and emulate IPv4’s address architecture and allow the network operator to select their own address length for the network?
I have no rational answer to this question. I’m left with the observation that IPv6 is not, in fact, a ‘128-bit address protocol’ in the same way as IPv4 is a ’32-bit address protocol’. It’s a ’64-bit plus a few extra interface identifier bits’ address protocol.
The concept of a ‘site prefix’ has persisted in IPv6, but instead of being a 48-bit value, it’s a variable length value, which is the length determined by each individual network operator, or their IPv6 technology provider.
This leads to the question: What lengths are commonly used by network operators to assign site prefixes to each customer?
Unless you are located within the network and can observe the length of the IPv6 address prefix that your provider has assigned to you, this is not an easy question to answer. But suppose we can assemble a collection of IPv6 addresses used in the public Internet. In that case, we can examine the address to make a reasonable estimate of the site prefix length being used.
For each IPv6 address:
- If bits 48 to 63 are all zero then assume a /48 site prefix, and the site is using subnet 0.
- If any bits between 48 and 55 are one, and bits 56 through 63 are all zero, we assume a /56 prefix.
- If any bits between 48 and 59 are one, and bits 60 through 63 all being zero, we assume a /60 prefix.
- If we see any bits between 48 and 64, we assume a /64 prefix.
- For prefix lengths 48, 56, and 60, if bit 64 is 1, we assume the address is from a second subnet within the ISP-assigned prefix.
This estimate was first conducted by Nathan Ward using a small data set of 936 IPv6 host addresses. The results of that analysis can be found at GitHub. He estimated that 0.01% of these IPv6 addresses used a /48 prefix length, 21% used a /56, 22% used a /60 and 55% of these addresses used a /64 prefix length.
The obvious question is — do these values hold when using a significantly larger collection of IPv6 source addresses?
The APNIC Labs ad-based IPv6 measurement platform, collects some 7M to 8M unique IPv6 source addresses per day. These are typically the IPv6 addresses of end-user systems that received an ad impression (although there is a small level of exceptions when a VPN is in use, or when obscuring technology, such as Apple Private Data Relay service, is being used).
IPv6 subnet use
We’ve applied this subnet classification algorithm to these IPv6 host addresses on a day-by-day basis since the start of 2022. The result is shown in Figure 1.
The results from this exercise show that the current breakdown of subnet prefix sizes in the APNIC Labs data set is consistent with the results from the smaller data set used by Nathan Ward. The /64 subnet is the most common subnet size, used in 57% of cases in recent data. The /60 and /56 subnets are seen in 21% and 20% of cases respectively. Finally, the /48 subnet is seen in 2% of cases.
Over the past 28 months, there have been some changes in this distribution, where the relative use of /64 prefixes has dropped from 72% to 57%, while the relative incidence of /56 subnets has risen by 10% during this period. There was a small relative increase in /60 subnets of 5% while the relative use of /48 subnets has remained constant.

This data indicates that few ISPs assign end sites a /48 prefix. A possible explanation of this distribution of subnet sizes is that the use of a /64 prefix is prevalent in mobile services, where individual devices are assigned a /64 prefix by the mobile service provider, while the use of a /60 and /56 appears to have become the default setting in broadband deployments in this data.
It may well be the case that /48 prefixes are used more commonly in enterprise contexts, and the penetration of IPv6 into enterprise environments has been far slower than the deployment in mass market public IP services in mobile and broadband.
Internal subnet structure?
Prefix lengths of 63 bits or smaller allow a site to operate an internal subnet structure. The question is: How often are multiple subnets used by end sites?
Again, this is not an easy question to answer by direct measurement, as this internal structure is only visible to an observer located within the end site. However, there is a way to make a rough estimate, and that is by looking for the relative incidence of subnet ‘1’ in visible host addresses. This assumes that most site administrators will number site-local subnets using sequential numbering of 0, 1, 2 and so on. The presence of subnet 1 in an address, as per the decision algorithm described above, may be an indicator of the use of multiple subnets within a site.
The relative occurrence of subnet 1 in each of the /48, /56 and /60 site prefixes are shown in Figure 2.

This data indicates that multiple subnets may be common in /48 prefixes (~45%), but less so for /56 (10%) and /60 prefixes (20%). This data is consistent with the supposition that /48 prefixes are more commonly used in enterprise scenarios, where multiple subnets are more likely to be used.
Measurement by /48s
It can be argued that the outcome shown in Figure 1, namely that /64s are the most common, is influenced by the observation that there are many more /64 prefixes than /48 prefixes. We can attempt to compensate for this by using a uniform /48 division in the IPv6 address plan. For each observed source IPv6 address, we use the classification algorithm to derive a likely subnet size, but we then use the encompassing /48 address prefix and assign this subnet size to the /48 subnet. When we get multiple subnets of different sizes in the same /48, we’ll use the longer subnet (if we observe both a /48 and a /60 in a common /48 prefix then we’ll use the /60 value). The result of this analysis is shown in Figure 3.
Comparing this result to that shown in Figure 1 we see that the most common subnet size, when looking at the IPv6 space as a set of /48 prefixes, is a /56. While there is a large set of IPv6 source addresses that map to a /64 subnet, they all come from a smaller set of common /48 prefixes.

RIR allocations
It’s not clear that a /48 ‘parent’ prefix is the most appropriate one to use here. Alternatively, we could make an assumption that each network uses a uniform subnet address plan, and furthermore assume that each IPv6 address allocation from a Regional Internet Registry (RIR) corresponds to an individual network.

This perspective of subnet use is similar to Figure 3, where the use of /64 and /56 subnets is the most prevalent, while /60 and /48 subnets are far less common.
This exercise is based on the assumption that where subnetting is being used within an end site, the initial subnet, subnet 0, is the most likely to be used.
This is not necessarily the case. For example, Starlink assigns each end user a /56 . The default subnet identifier, seen in 15,309 cases out of 16,711 in one recent day from this data set, uses subnet number 16 (hex 10) as the default on-site network, causing this algorithm to incorrectly assume that a /60 is being used for Starlink address assignments.
It appears that, at best, this approach offers an approximate view of IPv6 address assignment and subnet behaviours in the IPv6 network.
The role of subnets in a network architecture
Why use subnets at all? The standard response is that ‘subnets make networks more efficient’ by localizing traffic. A subnet encompasses an internally self-connected region of a network. Traffic between the attached nodes within a subnet can be handled by the routers within that subnet. Subnets can simplify the network routing architecture, in that routers within a distinct subnet need only maintain routes for the hosts that are located within the subnet, and a ‘default’ router pointing to the network beyond the subnet can be used for all other hosts.
Suppose all the hosts in a subnet are addressed from a common address prefix. In that case, the external network that hosts the subnet need only maintain a single route to this common address prefix, delegating the details of individual host reachability to the routers within the subnet (Figure 5). All of this is explained in detail in RFC 950 .

The entire concept of nested hierarchies of subnets is an intrinsic part of the IPv4 architecture, particularly so when the address architecture was migrated from the old Class A, B and C network/host fixed boundaries to a classless address architecture where every subnet was essentially defined by a common address prefix and a prefix length.
It’s an interesting question to ask to what extent this address architecture is an intrinsic part of today’s network designs. In the IPv4 environment, the depleted IPv4 address pools have meant that for many networks at the edge, the conventional subnet boundaries have been replaced by network address translation boundaries.
In the world of IPv6, subnets still have relevance, but their importance is more aligned with IPv6 neighbor discovery. Here, belonging to the same multicast realm determines the idea of ‘locality’. In a networking world where the capabilities of Layer-2 switching environments have all but supplanted the former role of direct physical connectivity, the answer to the simple question of ‘are we connected to each other?’ is sometimes deceptively complex.
As an abstraction to assist in scaling the networks, subnets still have a role to play, but as the pendulum of packet networking technology swings back from routing to switching, it’s increasingly challenging to understand exactly what this role is!
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.
Fabulous piece thank you
This is a great perspective on how IPv6 is being implemented, even if not exact, it still represents how implementation has been impacted by the artificial /64 boundary.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name and email in this browser for the next time I comment.
Yes, add me to your mailing list
Notify me of follow-up comments via email. You can also subscribe without commenting.
- Skip to primary navigation
- Skip to main content
- Skip to primary sidebar
- Skip to custom navigation
- Infoblox Threat Intel
- Infoblox Partner
- Partner Portal

Why Infoblox
Market Leadership

Networking Products Core network services including DNS, DHCP and IPAM (DDI)
Security Products Foundational security for anywhere protection
Infoblox Universal DDI ™ Product Suite Unify SaaS management of DNS, DHCP, and IPAM across hybrid, multi-cloud infrastructures
Infoblox Universal Asset Insights ™ Automate network discovery and analysis of assets across hybrid and multi-cloud environments
NIOS DDI Unify DNS, DHCP and IPAM for complex, on-premise networking
Automation Products Tools to streamline modern networking and security
Networking Ecosystem Automate workflows and create data-driven insights with networking integrations
Infoblox Threat Defense ™ Quickly deploy hybrid DNS-layer security everywhere
Advanced DNS Protection Protect enterprise DNS infrastructure to ensure maximum uptime
Security Ecosystem Automate SecOps response and efficiency with advanced integrations
Initiative Solutions for key challenges
Technology Key tools and integrations
Industry Vertical market solutions
Job Function Solutions overview by role
Multi-Cloud Networking Transform hybrid, multi-cloud management of critical network services such as DNS and IPAM
On-Premises + Cloud-Managed Networking Uniting enterprise grade and cloud native core networking services for the hybrid enterprise
Hybrid Workplace Speed your transition to a secure, multi-cloud organization to support your hybrid workforce
Cybersecurity Frameworks Satisfy requirements for leading security best practices
IT Compliance Simplify management of regulatory compliance requirements

Technology Optimization
Accelerate Office 365 performance Ensure fast, reliable user experiences
Secure IoT Protect devices across IoT environments
Deploy IPv6 Set your network foundation up for success
Optimize SD-WAN Use cloud-managed DNS, DHCP and IPAM for better ROI
Support Encrypted DNS Offer DoT/DoH services while maintaining security and performance
Key Integrations
Networking Ecosystem Improve efficiency and agility across hybrid and multi-cloud networks
Security Ecosystem Boost threat detection and simplify security operations
Ecosystem Portal One centralized location to easily find all certified integrations
Healthcare Simplify, control and secure vital healthcare services
Higher Education Improve network performance while reducing costs
Public Sector Scale and secure distributed networking for all
- Public Health & Human Services
- State & Local
Service Providers Deliver modern core network services and security
- Mobile Providers
- Cable and Broadband
- Managed Service Providers
- Subscriber Services
NetOps Unify DNS, DHCP and IPAM and simplify complex networking
DevOps Use automation and advanced integrations to streamline operations
SecOps Leverage automation and multi-source intelligence to stop threats faster
CIO/CISO Optimize your workforce productivity with a SaaS-enabled enterprise

Support Overview
Customer Support Portal
Technical Account Manager
Customer Success
Infoblox Community
Professional Services
Education Services
Cloud Services
Infoblox Portal
Cloud Services Status
Developer Portal
Analyst Reports
Customer Case Studies
Deployment Guides
Evaluations
Live Events & Webinars
Infographics
Solution Notes
On-demand Webinars
Whitepapers

About Infoblox
Diversity & Inclusion
Environmental, Social, and Governance Policy
About Infoblox Partners
Technology Ecosystem
- Network Ecosystem
- Security Ecosystem
Infoblox for Microsoft
Infoblox for AWS
News and Events
Company Blog
In the News
Press Releases
Home / IPv6 CoE / IPv6 Prefix Allocation Methods – Part Two
IPv6 Prefix Allocation Methods – Part Two
August 5, 2020
Introduction
In part one , we started our discussion of IPv6 prefix allocation methods with the simple reason of why you need them in the first place: a properly sized IPv6 allocation provides a vast amount of IPv6 space and you need to have one or more methods for logically and sensibly dividing and assigning that space based on the types of networks you are addressing. I also listed the four most common methods of IPv6 prefix allocation: next available , sparse , best fit , and random. Part one concluded with a detailed look at the next available allocation technique. If you haven’t read part one and are unfamiliar with IPv6 address planning, I encourage you to read it before reading this post.
In part two, we’ll discuss the remaining IPv6 prefix allocation methods along with how and when to use them. As with our example in part one, the idea is that you’ve been allocated a sufficiently large block of IPv6 addresses to meet your IPv6 addressing needs for decades .
Since we covered the next available prefix allocation method of assigning prefixes (i.e., subnets) of IPv6 address space in detail last time, this time we’ll focus on the three allocation methods that remain. They are:
Sparse Allocation
The simplest description for sparse allocation of IPv6 is the assignment of prefixes with lots of additional unused prefixes (and thus address space) in between them. The basic benefit of this method is not simply leaving space in reserve—after all, it likely wouldn’t be that hard to find available extra IPv6 address space from within the overall IPv6 allocation. What sparse allocation provides is address space in reserve that is more likely to be contiguous .
Fellow routing nerds may recognize immediately that such contiguous space adjacent to the original allocation and reserved for the original allocation’s recipient, is better for enabling route summarization and reducing the size of routing tables (i.e., preventing large prefix disaggregation ). That is precisely why sparse allocation is preferred for service providers that need to allocate large blocks of address space to their customers. And of course, organizations such as the Regional Internet Registries and IANA which are tasked with allocating all IPv6 (and IPv4) addressing to those service providers (and more frequently than before, directly to enterprises) benefit from using sparse allocation mode to guarantee contiguous space held in reserve for any and all allocations.
For example, if an enterprise is allocated a /32 of address space from ARIN (the RIR for North America), it is very likely that such a /32 was allocated from a larger allocation held in reserve for that enterprise. Keep in mind that the enterprise developed enough of an address plan to recognize that they needed a /32 of IPv6 address space. They requested a /32 from ARIN and provided the necessary justification. ARIN approved the request and assigned them a /32. However, perhaps unbeknownst to the enterprise, ARIN reserved, say, a /29 containing 8 /32s, one of which was publicly assigned to the enterprise. If that enterprise needed more IPv6 address space at some point in the future—and as long as that need didn’t exceed the remaining 7 /32s—additional contiguous /32s up to the entire /29 could then be assigned to the enterprise.
Otherwise, the enterprise could certainly be assigned additional IPv6 space from another part of the RIR’s overall IPv6 allocation, but it would not be contiguous. It’s also possible that without contiguous space held in reserve for the enterprise, the RIR could require the return of the original allocation for the new larger one (hello, painful and costly renumbering of the entire network!). Most organizations are used to dealing with disaggregated and non-contiguous IPv4 prefixes, but it creates complexity in managing the address plan. Such complexity typically results in operational errors and more difficult fault isolation.
The above example applies equally well to service providers and their customers. Sparse allocation provides similar benefits. Keep in mind that service provider allocations are almost always Provider Assigned (PA), meaning that the allocation or any part of it is only permitted to be routed through that service provider’s network. (Compare this with the Provider Independent (PI) space RIRs assign, which are allowed to be routed through any provider.)
Here’s a visual example of sparse allocation to hopefully make the concept a bit clearer. Imagine that an organization starts with a /32 of IPv6 address space—in this example the reserved documentation prefix of 2001:db8::/32. The organization could be a Regional Internet Registry like ARIN (where the /32 would come from their much larger pool of a /12). Each entity being assigned prefixes from the /32 by ARIN would be some smaller organization requesting address space from ARIN.
Or the primary /32 allocation could belong to a service provider that has been allocated the /32 from an RIR. In that case, the entities receiving subsequent smaller assignments from the service provider would be their customers.
Another possibility is that the primary /32 allocation could belong to an enterprise. In that case, the entities might represent internal assignments to corporate network locations or regions.
In any of the above cases, the sparse allocation method would be to assign the first available /36 (e.g., 2001:db8::/36) to the entity while reserving some contiguous amount of address space. In our visual example, the equivalent of 3 additional /36s have been held in reserve for each of the first and second entities.
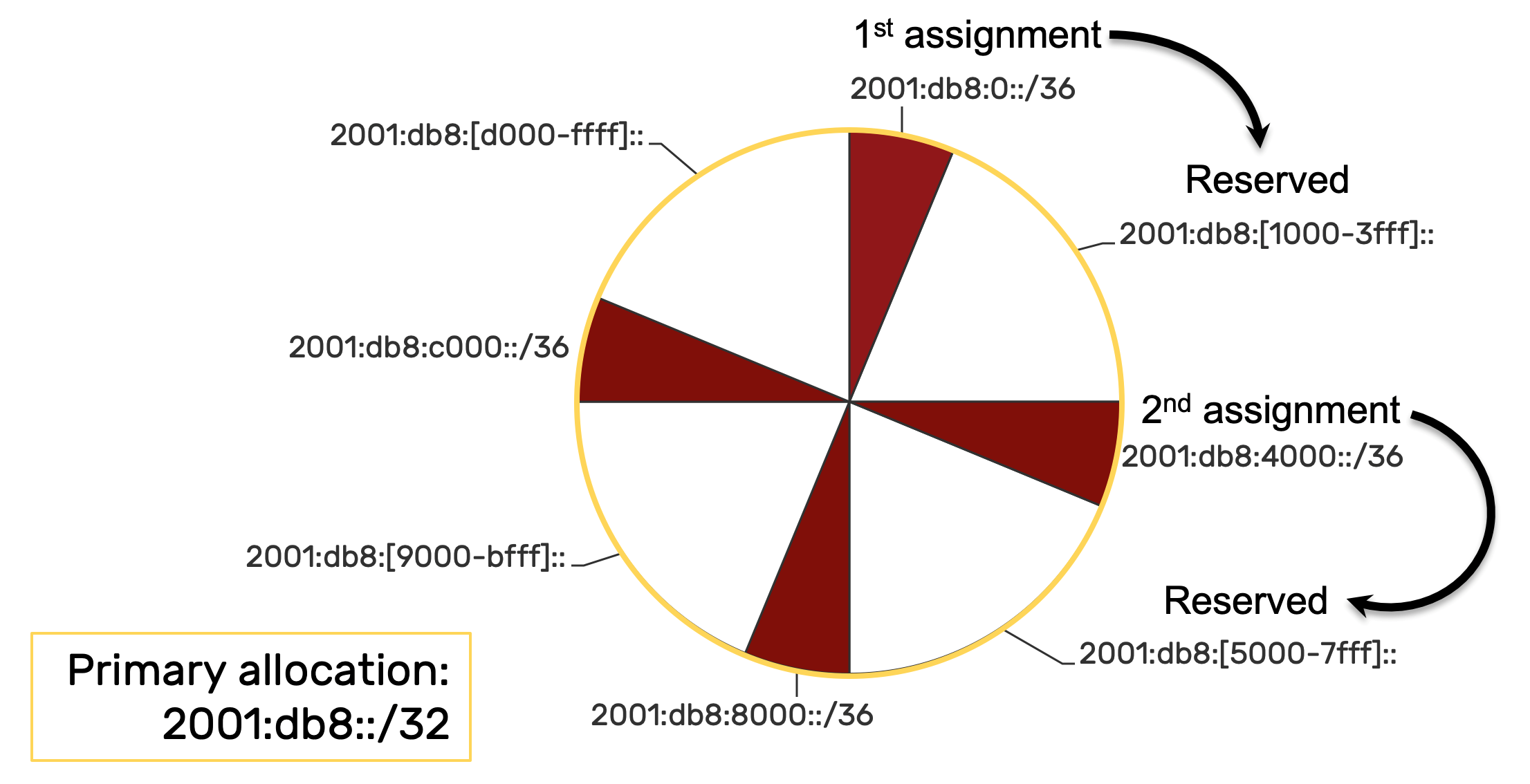
Let’s look at each step of the sparse allocation method in this example. The initial assignment to entity 1 is 2001:db8::/36. Keep in mind that because of zero compression rules for IPv6 addresses, the prefixes for the /32 and the /36 might end up looking exactly the same, but for the CIDR notation at the end of the prefix indicating the prefix length (e.g., 2001:db8::/32 and 2001:db8::/36).
You may notice that in the example graphics, I break this rule in a couple of ways. For instance, in the above graphic, to assist in highlighting the relevant nibble for the /36, I included one zero. In the graphics below, I included four zeroes in the first prefix example in the table column to help maintain a consistent prefix width for visual purposes. Technically, both these examples should be zero compressed to the minimum length (e.g., 2001:db8::/36).
If you read part one of this blog, you may want to briefly recall how the next available allocation method works for comparison purposes. If we were using it, the next entity would get the next available /36, or 2001:db8:1000::/36.
As it happens, the underlying binary arithmetic and resulting bit manipulation for each method provides another perspective on how they compare. Since for either method we’re currently only looking at /36-sized prefixes assigned from a /32, we can restrict our bit manipulation to the most significant nibble in the 3rd hextet.
With the next available method of assignment, the next prefix would be defined by incrementing the least significant (rightmost) bits in that particular nibble. For example:
0 0 0 0 = 2001:db8::/36 (or with the relevant zero included 2001:db8:0::/36)
0 0 0 1 = 2001:db8:1000::/36
0 0 1 0 = 2001:db8:2000::/36
0 0 1 1 = 2001:db8:3000::/36
By comparison, sparse allocation increments the most significant (leftmost) bits in the nibble. Note that if this is done strictly, by incrementing one bit at a time, you’ll observe that it results in a sequence that skips the intervening prefixes in a way that isn’t necessarily intuitive. For example:
0 0 0 0 = 2001:db8::/36 (or with the relevant zero included 2001:db8:0::/36)
1 0 0 0 = 2001:db8:8000::/36
0 1 0 0 = 2001:db8:4000::/36
1 1 0 0 = 2001:db8:c000::/36
We can then reorder the assignments according to their natural decimal order to better align with our entity list order:
So how many entities can I assign /36s to? Well you may observe that once half (or eight) of the available /36s are consumed the sparse method is no longer possible for consistent assignment of remaining prefixes to the remaining entities. In this example, we’ll limit the number of entities to four, which results in each entity having 3 additional contiguous /36s in reserve.
Remember: the contiguous characteristic is definitional for sparse allocation! For example, by continuing to contiguously assign the remaining /36s to the respective entities, we get the following:
When all the IPv6 address space available in the primary allocation is assigned and the entire /32 consumed, each entity will have 4 contiguous /36s. As the above example suggests, these 4 /36s could each be summarized as a single /34. For example:
Entity 1 summary: 2001:db8:0000::/34
Entity 2 summary: 2001:db8:8000::/34
Entity 3 summary: 2001:db8:4000::/34
Entity 4 summary: 2001:db8:c000::/34
This summarization results in no more than 4 entries in the upstream router. By comparison, using any other method could result in as many as 16 routes. That should help demonstrate why sparse allocation is the method of choice for service providers and Regional Internet Registries (RIRs).
It may be obvious to you at this point that in our nibble-aligned example of a /32 divided into 16 /36s, any divisor that permits the assignment of an equal number of contiguous prefixes to each entity could be used.
2 entities = 8 /36s
4 entities = 4 /36s
8 entities = 2 /36s
Of course, we’re not limited to /32s and /36s. The sparse allocation method works just as well for other primary allocation sizes and could include groups of prefixes that don’t conform to nibble-aligned assignment as well.
Though sparse allocation is ideal for service providers, larger enterprises may find it useful as well. For example, an enterprise with locations in many regions supported by larger networks could benefit from using sparse assignments for each region. Future growth of those regions and networks could be accommodated with additional contiguous prefixes helping keep the routing table size to a minimum and simplifying configurations, operations, and troubleshooting.
The two remaining IPv6 allocation methods are best fit and random .
You’re likely intimately familiar with the best fit allocation method from IPv4, where it gets used frequently to conserve IP space—in particular, host addresses. In the best fit method, a prefix that provides the minimum number of smaller prefixes and/or host addresses (in the case of IPv4) is assigned from a larger primary allocation. In the process, as much as possible of the remaining primary allocation is preserved.
In this example, different entities are requesting the number of IPv6 address prefixes they have determined they need. To tailor the example to an enterprise, these entities could be functions or departments (e.g., data center, manufacturing, IT, etc.) responsible for their own networks and in need of address space.
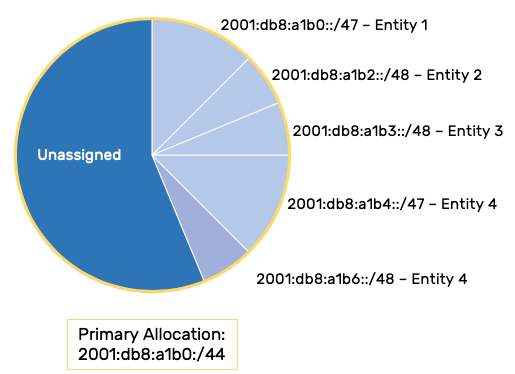
Entity one determines it needs more than one /48 but not more than two. The assignment that would “best fit” that request is a /47 (although it might be odd that a site may outgrow a single /48 and need two). Entity two needs not more than one /48 and receives a /48. Entity three also needs not more than one /48 and receives a /48.
Entity four determines it needs the equivalent of three /48s. Binary dictates that the prefix size has to be some integer power of two, so the assignment that would best fit entity three’s requirement would be one /47 and one /48.
All of this is perfectly reasonable in terms of meeting the basic requirement of a) having enough address space and b) assigning it according to current needs. But veteran network folk can spot the complications immediately.
For one thing our routing table will have the following entries:
2001:db8:a1b0::/47 – Entity 1
2001:db8:a1b2::/48 – Entity 2
2001:db8:a1b3::/48 – Entity 3
2001:db8:a1b4::/47 – Entity 4
2001:db8:a1b6::/48 – Entity 4
Of course these can always be summarized as the primary allocation prefix of 2001:db8:a1b0::/44 but within the immediate routing domain, we have to operationally deal with different prefix sizes, some entities having one prefix in the routing table with others having multiple entries.
By comparison, choosing the entity with the largest /48 requirement and assigning all the entities that size prefix allows us to meet the prefix/address space needs of each entity while reducing both the size and complexity of the routing table:
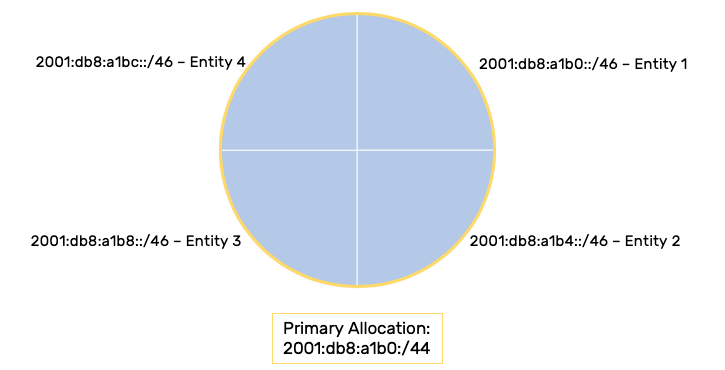
2001:db8:a1b0::/46 – Entity 1
2001:db8:a1b4::/46 – Entity 2
2001:db8:a1b8::/46 – Entity 3
2001:db8:a1bc::/46 – Entity 4
You’ll notice also that this allows us to use the next available allocation method.
This is typically the point where anxiety about “wasting” address space ramps up. “Entities 2 and 3 only need a /48! Why am I giving them 4 times that amount?!” The answer is that the practically inexhaustible supply of IPv6 results in the ability to make addressing and address plan choices that favor operational ease and efficiency over mere conservation for its own sake (a trade-off simply not available to us in IPv4 given its limited/exhausted supply): e.g., fewer routing table entries and greater ease of identification of network assignments—especially where allocations strictly conform to nibble boundaries (unlike our example immediately above).
The final address allocation method we’ll discuss (if ever-so-briefly) is random . With random allocation, it’s typical to assign every entity the same size prefix but those prefix assignments are randomly selected. For example, a /48 provides 65,536 /64s. These /64 prefixes could be randomly generated and assigned:
2001:db8:a1b0:c290::/64 – Entity 1
2001:db8:a1b0:f0aa::/64 – Entity 2
2001:db8:a1b0:223b::/64 – Entity 3
2001:db8:a1b0:101e::/64 – Entity 4
This method would really only be useful or practical in a limited number of cases—specifically, where the allocation and provisioning process is highly automated and there is some additional benefit to random assignments (for reasons of security for instance, given an automated provisioning environment where the prefixes could be periodically reassigned with new random values). For example, a data center with different clusters that need unique IPv6 address space that will be routed to that cluster dynamically (e.g., Kubernetes).
If the last statement sounds (even vaguely) recognizable, it’s because a qualified example of this method is used all of the time—with “/128 prefixes”; i.e., individual IPv6 addresses! Privacy or temporary addresses are automatically provisioned via SLAAC and there is a presumed security benefit in preserving the anonymity of the IPv6 host (rather than having it be identifiable and traceable by the inclusion of its hardware address as part of the standard, non-random EUI-64 address assignment).
You’ve probably inferred at this point that when first designing (and with early iterations of) your IPv6 address plan, it’s unlikely that you’ll find much benefit to using either the best fit or random allocation methods. The best fit method is probably unavoidable at a much later date—hopefully much, much later—especially if you’ve designed your address plan based on a large enough initial allocation to provide abundant enough prefixes for consistent next available and sparse assignments.
Finally, it should also be pointed out that a good IPAM solution makes any of these IPv6 allocation methods easier to effectively manage. Fortunately, I can recommend a reputable DDI vendor that offers a high-performance solution in this area. 😉
- Tips & Tricks
Tom Coffeen
Co-founder of hexabuild.io.
Tom Coffeen is a network engineer, architect, and author with over twenty years of internetwork design, deployment, administration, and management experience. Tom co-founded HexaBuild, an IT consultancy specializing in the advancement of cloud, IoT, and security deployment best practices through IPv6 adoption. Prior to co-founding HexaBuild, Tom was an IPv6 Evangelist and a Distinguished Architect at Infoblox. Before that Tom was the VP of network architecture at the global CDN Limelight Networks where he led their deployment of IPv6. He is also the author of O’Reilly Media’s IPv6 Address Planning.
You might also be interested in

Understanding DHCPv6 Lease Times
By Scott Hogg

The IPv6 Prefix Information Option or Fun with the L Flag
By Ed Horley

IPv6 Prefix Allocation Methods - Part One (of Two)
By Tom Coffeen

Infoblox Advanced DNS Protection Rules - Viewing the Tip of an Iceberg

The Odd History of Provisioning an IPv6 Address on a Host

IPv6 Projects and “The Human Element”
By Steve Rogers
> Configuring IPv6 prefix assignment |
|
Configuring IPv6 prefix assignment
About ipv6 prefix assignment.
Use the following methods to configure IPv6 prefix assignment:
Configure a static IPv6 prefix binding in an address pool —If you bind a DUID and an IAID to an IPv6 prefix, the DUID and IAID in a request must match those in the binding before the DHCPv6 server can assign the IPv6 prefix to the DHCPv6 client. If you only bind a DUID to an IPv6 prefix, the DUID in the request must match the DUID in the binding before the DHCPv6 server can assign the IPv6 prefix to the DHCPv6 client.
Apply a prefix pool to an address pool —The DHCPv6 server dynamically assigns an IPv6 prefix from the prefix pool in the address pool to a DHCPv6 client.
Restrictions and guidelines
When you configure IPv6 prefix assignment, follow these restrictions and guidelines:
An IPv6 prefix can be bound to only one DHCPv6 client. You cannot modify bindings that have been created. To change the binding for a DHCPv6 client, you must delete the existing binding first.
One address pool can have only one prefix pool applied. You cannot modify prefix pools that have been applied. To change the prefix pool for an address pool, you must remove the prefix pool application first.
You can apply a prefix pool that has not been created to an address pool. The setting takes effect after the prefix pool is created.
Enter system view.
system-view
(Optional.) Specify the IPv6 prefixes excluded from dynamic assignment.
ipv6 dhcp server forbidden-prefix start-prefix/prefix-len [ end-prefix/prefix-len ]
By default, no IPv6 prefixes in the prefix pool are excluded from dynamic assignment.
If the excluded IPv6 prefix is in a static binding, the prefix still can be assigned to the client.
Create a prefix pool.
ipv6 dhcp prefix-pool prefix-pool-number prefix { prefix-number | prefix/prefix-len } assign-len assign-len
This step is required for dynamic prefix assignment.
If you specify an IPv6 prefix by its ID, make sure the IPv6 prefix is in effect. Otherwise, the configuration does not take effect.
Enter DHCP address pool view.
ipv6 dhcp pool pool-name
Specify an IPv6 subnet for dynamic assignment.
network { prefix/prefix-length | prefix prefix-number [ sub-prefix/sub-prefix-length ] } [ preferred-lifetime preferred-lifetime valid-lifetime valid-lifetime ]
By default, no IPv6 subnet is specified for dynamic assignment.
The IPv6 subnets cannot be the same in different address pools.
Configure the prefix assignment. Choose the options to configure as needed:
Configure a static prefix binding:
static-bind prefix prefix/prefix-len duid duid [ iaid iaid ] [ preferred-lifetime preferred-lifetime valid-lifetime valid-lifetime ]
By default, no static prefix binding is configured.
To add multiple static IPv6 prefix bindings, repeat this step.
Apply the prefix pool to the address pool:
prefix-pool prefix-pool-number [ preferred-lifetime preferred-lifetime valid-lifetime valid-lifetime ]
By default, static or dynamic prefix assignment is not configured for an address pool.
|
|
|
DHCPv6 server tasks at a glance |
| Configuring IPv6 address assignment |
© Copyright 2015, 2017 Hewlett Packard Enterprise Development LP
Internet Protocol Version 6 Address Space
| IPv6 Prefix | Allocation | Reference | Notes |
|---|---|---|---|
| ::/8 | Reserved by IETF | [ ][ ] | This range has been partially allocated. See [ ] for details. ::/96, formerly defined as the "IPv4-compatible IPv6 address" prefix, was deprecated by [ ]. |
| 100::/8 | Reserved by IETF | [ ][ ] | This range has been partially allocated. See [ ] for details. |
| 200::/7 | Reserved by IETF | [ ] | Deprecated as of December 2004 [ ]. Formerly an OSI NSAP-mapped prefix set [ ]. |
| 400::/6 | Reserved by IETF | [ ][ ] | |
| 800::/5 | Reserved by IETF | [ ][ ] | |
| 1000::/4 | Reserved by IETF | [ ][ ] | |
| 2000::/3 | Global Unicast | [ ][ ] | The IPv6 Unicast space encompasses the entire IPv6 address range with the exception of ff00::/8, per [ ]. IANA unicast address assignments are currently limited to the IPv6 unicast address range of 2000::/3. IANA assignments from this block are registered in [ ]. |
| 4000::/3 | Reserved by IETF | [ ][ ] | This range has been partially allocated. See [ ] for details. 5f00::/8 (with 3ffe::/16, as noted at [ ]) was used for the 6bone, but returned [ ]. |
| 6000::/3 | Reserved by IETF | [ ][ ] | |
| 8000::/3 | Reserved by IETF | [ ][ ] | |
| a000::/3 | Reserved by IETF | [ ][ ] | |
| c000::/3 | Reserved by IETF | [ ][ ] | |
| e000::/4 | Reserved by IETF | [ ][ ] | |
| f000::/5 | Reserved by IETF | [ ][ ] | |
| f800::/6 | Reserved by IETF | [ ][ ] | |
| fc00::/7 | Unique Local Unicast | [ ] | See [ ] for details. |
| fe00::/9 | Reserved by IETF | [ ][ ] | |
| fe80::/10 | Link-Scoped Unicast | [ ][ ] | See [ ] for details. |
| fec0::/10 | Reserved by IETF | [ ] | Deprecated by [ ] in September 2004. Formerly a Site-Local scoped address prefix. |
| ff00::/8 | Multicast | [ ][ ] | See [ ] for details. |
Oracle Cloud Infrastructure Documentation
- IPv6 Addresses
This topic describes support for IPv6 addressing in your VCN.
- IPv6 addressing is supported for all commercial and government regions.
- During VCN creation, you choose whether the VCN is enabled for IPv6, or you can enable IPv6 on existing IPv4-only VCNs. You also choose whether each subnet in an IPv6-enabled VCN is enabled for IPv6.
- IPv6-enabled VCNs can use a /56 IPv6 global unicast address (GUA) prefix allocated by Oracle, specify a /64 or larger Unique Local Address (ULA) prefix, or import a /48 or larger BYOIPv6 prefix.
- An Oracle-assigned /56 prefix can be globally routable to the VCN for internet communication, depending on whether the subnet using a /64 portion of the prefix is public or private. A ULA prefix is not globally routable for internet communication.
- All IPv6 enabled subnets are /64. You can either permit or prohibit internet communication to a subnet by specifying the "public/private" subnet-level flag.
- If you use BYOIP , you can import a /48 or larger IPv6 GUA prefix and must assign a /64 prefix or larger to a VCN.
- You choose whether a given VNIC in an IPv6-enabled subnet has IPv6 addresses (up to 32 maximum per VNIC).
- Only these Networking gateways support IPv6 traffic: dynamic routing gateway (DRG) , local peering gateway (LPG) , and internet gateway .
Both inbound- and outbound-initiated IPv6 connections are supported between your VCN and the internet, and between your VCN and your on-premises network. Communication between resources within your VCN or between VCNs is also supported.
- IPv6 traffic between resources within a region (intra- and inter-VCN) is supported. See other important details in Routing for IPv6 Traffic and Internet Communication .
- Both FastConnect and Site-to-Site VPN support IPv6 traffic between your VCN and on-premises network. You must configure FastConnect or Site-to-Site VPN for IPv6.
- Overview of IPv6 Addresses
Oracle VCNs support IPv4-only addressing and dual-stack IPv4 and IPv6 addressing. Every VCN always has at least one private IPv4 CIDR, and you can enable IPv6 during VCN creation. You can also add an IPv6 prefix to an IPv4-only VCN while enabling IPv6. When IPv6 is enabled for a VCN, while creating a subnet of that VCN you can enable it to also have IPv4 addresses only, both IPv4 and IPv6 addresses, or IPv6 addresses only (sometimes called single-stack IPv6). Therefore a VCN can have a mix of IPv4-only subnets, IPv6-only subnets, and subnets that have both IPv4 and IPv6.
When you create a compute instance, you can add one or more IPv6 addresses to the VNIC. These IP addresses can be assigned from multiple IPv6 prefixes if they are assigned to the subnet. You can remove an IPv6 address from a VNIC at any time.
IPv6 Prefixes Assigned to an IPv6-Enabled VCN
An IPv6-enabled VCN is dual-stack, meaning it has both an IPv4 CIDR and an IPv6 prefix assigned. A VCN can have up to five IPv4 CIDRs and up to five IPv6 prefixes. An IPv6-enabled VCN can use an Oracle-allocated /56 Global Unicast Address (GUA), let you import and assign a BYOIPv6 prefix, or specify a Unique Local Address (ULA) prefix. Oracle can allocate a GUA IPv6 prefix, also referred to here as a globally routable IPv6 prefix. You can also use Bring Your Own IP (BYOIP) to use a /48 prefix. Both ULA and BYOIPv6 prefixes must be at minimum /64 in size when assigned to a VCN. The following table summarizes the options.
| IPv4 or IPv6 | Use and Size | Who Assigns the Address Block | Allowed Values |
|---|---|---|---|
| Private IPv4 CIDR | Private communication /16 to /30 | You | Typically RFC 1918 range |
| Globally routable IPv6 prefix | Internet or Private Communication /56 | Oracle | Oracle allocates the IPv6 prefix. |
| BYOIP IPv6 prefix | Internet or Private Communication /64 (minimum) | You | IPv6 GUA are always in the range of 2000::/3. |
| IPv6 ULA | Private Communication /64 (minimum) | You | This address type can be in the fc00::/7 ULA range or 2000:/3 GUA range. We recommend you assign ULA prefixes from the fd00 half of the range. |
IPv6 ULA addresses allocated to VCNs are only used for internal communications even if the addresses are in the GUA range. OCI will not advertise the prefixes to the internet, nor route traffic between these internal prefixes and the internet.
Unique Local Addresses are globally unique addresses that permit communication between nodes on different links within the same site or between sites. They are administratively segmented and are not for routing on the Internet. RFC 4193 provides more information about ULAs.
Internet Communication
When you enable IPv6 in your VCN, you can choose which types of IPv6 addresses are assigned: Oracle-allocated, BYOIPv6, or ULA. You can then enable IPv6 in subnets (see Task 2: Create a regional IPv6-enabled public subnet ) and assign IPv6 addresses to an individual instance's VNICs or load balancers if they were launched in an IPv6-enabled subnet with an IPv6 prefix. You can also determine whether internet communication with IPv6-enabled resources is permitted or prohibited by specifying the subnet is public or private. If an IPv6-enabled resource is assigned a GUA address and is hosted in a public subnet, communication to and from the internet is permitted. If an IPv6-enabled resource is hosted in a private subnet, communication to and from the internet is prohibited even if the resource has a GUA address assigned.
Assignment of IPv6 Addresses to a VNIC
To enable IPv6 for a given VNIC, just assign an IPv6 to the VNIC . Multiple IP addresses can be assigned from multiple IPv6 prefixes if they are assigned to the subnet. As with IPv4, when assigning an IPv6 address, you can specify the particular address you want to use, or let Oracle choose one for you.
A VNIC can have an IPv6 address assigned at compute instance creation, or you can add one after you create the instance.
A VNIC can use IPv6-only addressing, provided that the OS image you choose for the compute instance supports IPv6-only addressing and the subnet is configured to only use IPv6 addressing.
You can move an IPv6 address from one VNIC to another in the same subnet .
Format of IPv6 Addresses
IPv6 addresses have 128 bits.
An IPv6 prefix block for a VCN must be /56 in size. The left 56 bits identify the VCN portion of the address. For example:
2001:0db8:0123:7800 ::/56 (or fd00::/56 for ULA addresses)
An IPv6 prefix block for a subnet must be /64 in size. The right 16 bits in a subnet's prefix identify the subnet portion of the address. In the following example, the 7811 is the unique portion for the subnet:
2001:0db8:0123: 7811 ::/64
In the following ULA example, the 11 is the unique portion for the subnet:
fd00:0:0: 11 ::/64
The right-most 64 bits of an IPv6 address identify the unique portion specific to the particular IPv6 address. For example:
2001:0db8:0123:7811: abcd:ef01:2345:6789
When you assign an IPv6 to a VNIC, you can specify which specific IPv6 address to use (those 64 bits).
In this example, Oracle assigns this prefix: 2001:0db8:0123: 7811 ::/56.
The following diagram illustrates the VCN and includes two subnets: public subnet 1111 and private subnet 1112.
Access to the internet is always determined at the subnet level, not at the VNIC level.
VNIC 1 in Subnet 1111 has a primary private IPv4 address (10.0.1.4) with an optional IPv6 address assigned. VNIC 1 has a secondary private IPv4 address (10.0.1.5), also with an optional public IP address assigned.
Since Subnet 1111 has internet access enabled it can only have an internet-routable IPv6 address, which is 2001:0db8:0123:7811:abcd:ef01:2345:0006.
Subnet 1112 is private, which means the VNICs don't have IPv4 or IPv6 access from the internet. The instance using VNIC 2 can still initiate contact with other hosts on the internet and get responses, but won't get uninitiated requests.
- Routing for IPv6 Traffic
Here are other important details about routing of IPv6 traffic:
Currently IPv6 traffic is supported only through these gateways:
- Dynamic routing gateway (DRG) : For access to your on-premises network or other networks outside the region (using remote peering ). Both Oracle Cloud Infrastructure FastConnect and Site-to-Site VPN support IPv6 traffic. For more details about IPv6 configuration, see the upcoming sections.
- Internet gateway : For access to the internet.
- Local peering gateway : For connecting two VCNs in the same region so that their resources can communicate using private IP addresses without routing the traffic over the internet or through your on-premises network.
- IPv6 traffic between resources within a region (within and between VCNs) is supported. VCNs are dual-stack, meaning they always support IPv4 and can optionally also support IPv6. A VCN's route tables support both IPv4 and IPv6 rules in the same table. IPv4 and IPv6 rules must be discretely specified. Rules to route traffic that match a certain IPv6 prefix to the VCN's attached DRG, internet gateway, local peering gateway, or an IPv6 address (next hop) are supported.
VCN Route Tables and IPv6
The VCN's route tables support both IPv4 rules and IPv6 rules that use a DRG, local peering gateway, or internet gateway as the target. For example, the route table for a given subnet could have these rules:
- Rule to route traffic that matches a certain IPv4 CIDR to the VCN's attached DRG
- Rule to route traffic that matches a certain IPv4 CIDR to the VCN's service gateway
- Rule to route traffic that matches a certain IPv4 CIDR to the VCN's NAT gateway
- Rule to route traffic that matches a certain IPv6 prefix to the VCN's attached DRG
- Rule to route traffic that matches a certain IPv6 prefix to the VCN's attached internet gateway
- Security Rules for IPv6 Traffic
Like route tables, the VCN's network security groups and security lists support both IPv4 and IPv6 security rules . For example, a network security group or security list could have these security rules:
- Rule to allow SSH traffic from the on-premises network's IPv4 CIDR
- Rule to allow ping traffic from the on-premises network's IPv4 CIDR
- Rule to allow SSH traffic from the on-premises network's IPv6 prefix
- Rule to allow ping traffic from the on-premises network's IPv6 prefix
The default security list in an IPv6-enabled VCN includes default IPv4 rules and the following default IPv6 rules:
Stateful ingress: Allow IPv6 TCP traffic on destination port 22 (SSH) from source ::/0 and any source port. This rule makes it easy for you to create a VCN with a public subnet and internet gateway, create a Linux instance, add an internet-access-enabled IPv6, and then immediately connect with SSH to that instance without needing to write any security rules yourself.
The default security list does not include a rule to allow Remote Desktop Protocol (RDP) access. If you're using Windows images , add a stateful ingress rule for TCP traffic on destination port 3389 from source ::/0 and any source port.
See To enable RDP access for more information.
- Stateful ingress: Allow ICMPv6 traffic type 2 code 0 (Packet Too Big) from source ::/0 and any source port. This rule enables your instances to receive Path MTU Discovery fragmentation messages.
- Stateful egress: Choosing to allow all IPv6 traffic lets instances initiate IPv6 traffic of any kind to any destination. Notice that instances with an internet-access-enabled IPv6 can talk to any internet IPv6 address if the VCN has a configured internet gateway. And because stateful security rules use connection tracking, the response traffic is automatically allowed regardless of any ingress rules. For more information, see Stateful Versus Stateless Rules .
- FastConnect and IPv6
If you use FastConnect , you can configure it so that on-premises hosts with IPv6 addresses can communicate with an IPv6-enabled VCN. In general, you must ensure that the FastConnect virtual circuit has IPv6 BGP addresses, and update the VCN's routing and security rules for IPv6 traffic.
About the IPv6 BGP Addresses
A FastConnect virtual circuit always requires IPv4 BGP addresses, but IPv6 BGP addresses are optional and only required for IPv6 traffic. Depending on how you're using FastConnect, you might be asked to provide the virtual circuit's BGP addresses yourself (both IPv4 and IPv6).
The addresses consist of a pair: one for your end of the BGP session, and another for the Oracle end of the BGP session.
When you specify a BGP address pair, you must include a subnet mask that contains both of the addresses. Specifically for IPv6, the allowed subnet masks are:
For example, you could specify 2001:db8::6/64 for the address at your end of the BGP session, and 2001:db8::7/64 for the Oracle end.
Process to Enable IPv6
In general, here's how to enable IPv6 for a FastConnect virtual circuit:
- Virtual circuit BGP: Ensure the FastConnect virtual circuit has IPv6 BGP addresses. If you're responsible for providing the BGP IP addresses, when you set up a new virtual circuit or edit an existing one, there's a place for the two IPv4 BGP addresses. There's a separate checkbox for Enable IPv6 Address Assignment and a place to provide the two IPv6 addresses. If you're editing an existing virtual circuit to add support for IPv6, it goes down while being re-provisioned to use the new BGP information.
- VCN route tables: For each IPv6-enabled subnet in the VCN, update its route table to include rules that route the IPv6 traffic from the VCN to the IPv6 subnets in your on-premises network. For example, the Destination CIDR Block for a route rule would be an IPv6 subnet in your on-premises network, and the Target would be the dynamic routing gateway (DRG) attached to the IPv6-enabled VCN.
- VCN security rules: For each IPv6-enabled subnet in the VCN, update its security lists or relevant network security groups to allow IPv6 traffic between the VCN and your on-premises network. See Security Rules for IPv6 Traffic .
If you do not yet have a FastConnect connection, see these topics to get started:
- FastConnect Overview
- FastConnect Requirements
- Site-to-Site VPN and IPv6
If you use Site-to-Site VPN , you can configure it so that on-premises hosts with IPv6 addresses can communicate with an IPv6-enabled VCN. Here's how to enable IPv6 for the connection:
- IPSec connection static routes: Configure the IPSec connection with the IPv6 static routes of your on-premises network.
- VCN route tables: For each IPv6-enabled subnet in the VCN, update its route table to include rules that route the IPv6 traffic from the VCN to the IPv6 subnets in your on-premises network. For example, the Destination CIDR Block for a route rule would be an IPv6 static route for your on-premises network, and the Target would be the dynamic routing gateway (DRG) attached to the IPv6-enabled VCN.
- VCN security rules: For each IPv6-enabled subnet in the VCN, update its security lists or relevant network security groups to allow the wanted IPv6 traffic between the VCN and your on-premises network. See Security Rules for IPv6 Traffic .
If you have an existing Site-to-Site VPN IPSec connection that uses static routing, you can update the list of static routes to include ones for IPv6. Changing the list of static routes causes Site-to-Site VPN to go down while being re-provisioned. See Changing the Static Routes .
If you do not yet have Site-to-Site VPN, see these topics to get started:
- Site-to-Site VPN Overview
- Setting Up Site-to-Site VPN
- Working with Site-to-Site VPN
DHCPv6 auto-configuration of IP addresses is supported. You do not need to statically configure any IPv6 address.
The VCN's Internet Resolver supports IPv6, which means resources in your VCN can resolve IPv6 addresses of hosts outside the VCN. Assignment of a hostname to an IPv6 address is not supported.
- Load Balancers
When you create a load balancer , you can choose to have an IPv4-only or IPv4 and IPv6 dual-stack configuration. When you choose the dual-stack option, the Load Balancer service assigns both an IPv4 and an IPv6 address to the load balancer. The load balancer receives client traffic sent to the assigned IPv6 address. The load balancer uses only IPv4 addresses to communicate with backend servers. IPv6 communication between the load balancer and the backend servers is not supported.
IPv6 address assignment occurs only at load balancer creation. You cannot assign an IPv6 address to an existing load balancer.
- Comparison of IPv4 and IPv6 for Your VCN
The following table summarizes the differences between IPv4 and IPv6 addressing in a VCN.
| Characteristic | IPv4 | IPv6 |
|---|---|---|
| Addressing type supported | IPv4 addressing is always required, regardless of whether IPv6 is enabled. This can be a private IPv4 CIDR if necessary. | IPv6 addressing is optional per VCN, optional per subnet in an IPv6-enabled VCN, and optional per VNIC in an IPv6-enabled subnet. An IPv6-only subnet or VNIC is allowed. |
| Supported traffic types | IPv4 traffic is supported for all gateways. IPv4 traffic between instances within the VCN is supported (east/west traffic). | IPv6 traffic is supported only with these gateways: internet gateway, local peering gateway, and DRG. Both inbound- and outbound-initiated IPv6 connections are supported between your VCN and the internet, and between your VCN and your on-premises network. IPv6 traffic between resources within a region (within or between VCNs) is fully supported (east/west traffic). Also see . |
| VCN size | /16 to /30 | Oracle GUA: /56 only BYOIPv6: /64 or larger ULA: /64 or larger |
| Subnet size | /16 to /30, with 3 addresses reserved in each subnet by Oracle (first 2 and last 1). | /64 only, with 8 addresses in the subnet reserved by Oracle (first 4 and last 4). |
| Private and public IP address space | Private: A VCN's private IPv4 CIDR can be from an RFC 1918 range or a publicly routable range (treated as private). You specify the range, unless you use the Console's VCN creation wizard, which always uses 10.0.0.0/16. Public: The VCN does not have a dedicated public IPv4 address space. Oracle chooses any public addresses in your VCN. | Unlike with IPv4, your VCN can receive an allocated /56 GUA prefix from Oracle or import and assign a BYOIP prefix. Either of these can be internet routable if assigned to resources in public subnets. You also have an option to assign ULA addresses, which are not internet routable, regardless of whether the subnet is public or private. |
| IP address assignment | Private: Each VNIC gets a private IPv4 address. You can choose the address or let Oracle choose it. Public: You determine whether the private IPv4 address has a public IP address associated with it (assuming the VNIC is in a public subnet). Oracle chooses the public IP address. From an API standpoint: the object is separate from the object. You can remove the public IP address from the private IPv4 address at any time. | You may assign IPv6 addresses from distinct prefixes to a VNIC if they are assigned to the subnet. You can choose the IPv6 address or let Oracle choose it. From an API standpoint: IP addresses are included in the object and the distinction between public and private is controlled using the public/private subnet flag. |
| Internet access | You control whether a subnet is public or private. You add or remove a public IP address from a private IPv4 address on a VNIC (assuming the VNIC is in a public subnet). | You control whether a subnet is public or private. You do not add or remove a public IP address to or from the VNIC as you do with IPv4. Instead you enable or disable the internet access for all IPv6-enabled resources in the subnet using the public/private subnet flag. |
| Primary and secondary labels | Each VNIC automatically has a primary private IP address, and you can assign up to 32 secondary private IPs per VNIC. | You choose to add an IPv6 address to a VNIC, with no or label. You can assign up to 32 IPv6 addresses per VNIC. |
| Hostnames | You can assign hostnames to IPv4 addresses. | You cannot assign hostnames to IPv6 addresses. |
| Route rule limits | See . | IPv4 and IPv6 route rules can reside together in the same route table. IPv6 route rules can target only an internet gateway, local peering gateway, or DRG. Limit on number of IPv6 route rules in a route table: 50. |
| Security rule limits | See . | IPv4 and IPv6 security rules can reside together in same network security group or security list. IPv6 security rules can use only IPv6 prefix ranges for source or destination, and not a service prefix label used for a service gateway. Limit on number of IPv6 security rules in a security list: 50 ingress and 50 egress. Limit on number of IPv6 security rules in a network security group: 16 total. |
| Reserved public IP addresses | Supported. | Not supported. |
| Regional or AD-specific | Primary private IPv4 addresses are -specific. Secondary private IPv4 addresses are AD-specific unless assigned to a VNIC in a regional subnet. Public IP addresses can be AD-specific or regional depending on the type (ephemeral or reserved). See . | IPv6 addresses are regional. |
- Setting Up an IPv6-Enabled VCN with Internet Access
Use the following process to set up an IPv6-enabled VCN with internet access so you can easily create an instance and connect to it by using its globally routable IPv6 address.
- Open the navigation menu, click Networking , and then click Virtual cloud networks .
- Under List Scope , select a compartment that you have permission to work in.The page updates to display only the resources in that compartment. If you're not sure which compartment to use, contact an administrator. For more information, see Access Control .
Click Create Virtual Cloud Network .
Enter the following:
- Name: A descriptive name for the VCN. It doesn't have to be unique, and it cannot be changed later in the Console (but you can change it with the API). Avoid entering confidential information.
- Create in Compartment: Leave as is.
- CIDR Block: A single, contiguous IPv4 CIDR block for the VCN. For example: 172.16.0.0/16. You cannot change this value later. See Allowed VCN Size and Address Ranges . For reference, here's a CIDR calculator .
- Enable IPv6 Address Assignment: Oracle can allocate an IPv6 prefix for you, you can select a BYOIPv6 prefix you have already imported, or you can specify a ULA prefix. You cannot later disable IPv6 for the VCN but you can change the IPv6 prefix or prefixes on the VCN as long as there is always at least one IPv6 prefix. If you accept an Oracle-allocated IPv6 prefix, you receive a /56. For BYOIPv6 or ULA, specify any prefix size of /64 or larger. All IPv6-enabled subnets are /64 in size.
- Use DNS Hostnames in this VCN (supported for IPv4 only): This option is required to assign DNS hostnames to hosts in the VCN, and required if you plan to use the VCN's default DNS feature (called the Internet and VCN Resolver ). If you select this option you can specify a DNS Label for the VCN, or you can allow the Console to generate one for you. The dialog box automatically displays the corresponding DNS Domain Name for the VCN ( <VCN_DNS_label> .oraclevcn.com ). For more information, see DNS in Your Virtual Cloud Network .
- Tags: Leave as is. You can add tags later. For more information, see Resource Tags .
The VCN is then created and displayed on the Virtual Cloud Networks page in the compartment you chose.
- While still viewing the VCN, click Create Subnet .
- Name: A descriptive name for the subnet (for example, Regional Public Subnet). It doesn't have to be unique, and you can change it later. Avoid entering confidential information.
- Regional or Availability Domain-specific subnet: Oracle recommends creating only regional subnets , which means that the subnet can contain resources in any of the region's availability domains. If you instead choose Availability Domain-Specific , you must also specify an availability domain. This choice means that any instances or other resources later created in this subnet must also be in that availability domain.
- CIDR Block: A single, contiguous IPv4 CIDR block for the subnet (for example, 172.16.0.0/24). The address block must be within the VCN's IPv4 CIDR block and not overlap any other subnets. You cannot change this value later. See Allowed VCN Size and Address Ranges . For reference, here's a CIDR calculator .
- If you have an Oracle-allocated prefix assigned to the VCN, select the checkbox and enter two hexadecimal characters (00-FF).
- If you assigned a BYOIPv6 or ULA prefix in the VCN, select it and specify hex characters to assign a /64 to the subnet.
- Route Table: Select the default route table.
- Private or public subnet : Select Public Subnet , which means instances in the subnet can optionally have public IPv4 addresses. Internet communication using IPv6 is allowed when GUA IPv6 addresses are assigned to resources hosted in a public subnet. For more information, see Access to the Internet .
- Use DNS Hostnames in this Subnet (supported for IPv4 only): This option is available only if a DNS label was provided for the VCN when it was created. The option is required for assignment of DNS hostnames to hosts in the subnet, and also when you plan to use the VCN's default DNS feature (called the Internet and VCN Resolver ). If you select the checkbox, you can specify a DNS label for the subnet, or let the Console generate one for you. The dialog box automatically displays the corresponding DNS domain name for the subnet as an FQDN. For more information, see DNS in Your Virtual Cloud Network .
- DHCP Options: Select the default set of DHCP options.
- Security Lists: Select the default security list.
- Tags: Leave as is. You can add tags later if you want. For more information, see Resource Tags .
Click Create Subnet .
The subnet is then created and displayed on the Subnets page.
- Under Resources , click Internet Gateways .
Click Create Internet Gateway .
- Name: A descriptive name for the internet gateway. It doesn't have to be unique, and it cannot be changed later in the Console (but you can change it with the API). Avoid entering confidential information.
Your internet gateway is created and displayed on the Internet Gateways page. The internet gateway is already enabled, but you must add route rules that allow IPv4 and IPv6 traffic.
The default route table starts out with no rules. Here you add rules that route all IPv4 and IPv6 traffic destined for addresses outside the VCN to the internet gateway. The existence of these rules also enables inbound connections to come from the internet to the subnet, through the internet gateway. You use security rules to control the types of traffic that are allowed in and out of the instances in the subnet (see the next task).
No route rule is required to route traffic within the VCN.
- Under Resources , click Route Tables .
- Click the default route table to view its details.
- Click Add Route Rules .
- Target Type: Internet Gateway
- Destination CIDR block: 0.0.0.0/0 (which means that all IPv4 non-intra-VCN traffic that is not already covered by other rules in the route table goes to the target specified in this rule).
- Compartment: The compartment where the internet gateway is located.
- Target: The internet gateway you created.
- Description: An optional description of the rule.
- Click + Additional Route Rule .
- Destination CIDR block: ::/0 (for the IPv6 traffic).
The default route table now has two rules for the internet gateway, one for IPv4 traffic and one for IPv6 traffic. Because the subnet was set up to use the default route table, the resources in the subnet can now use the internet gateway. The next step is to specify the types of traffic you want to allow in and out of the instances you later create in the subnet.
Earlier you set up the subnet to use the VCN's default security list . This list already includes basic rules that allow essential IPv4 and IPv6 traffic. In this task, you add any additional security rules that allow the types of connections that the instances in the VCN need.
For example: in a public subnet with an internet gateway, the instances you create might need to receive inbound HTTPS connections from the internet (if they are web servers). Here's how to add another rule to the default security list to enable that traffic:
- Under Resources , click Security Lists.
- Click the default security list to view its details. By default, you land on the Ingress Rules page.
- Click Add Ingress Rule .
To enable inbound connections for HTTPS (TCP port 443), enter the following:
- Stateless : Unselected (this is a stateful rule )
- Source Type: CIDR
- Source CIDR: 0.0.0.0/0 (or ::/0 if you want to enable IPv6 traffic with this rule)
- IP Protocol: TCP
- Source Port Range: All
- Destination Port Range : 443
Security List Rule for Windows Instances
If you're going to create Windows instances, you need to add a security rule to enable Remote Desktop Protocol (RDP) access. Specifically, you need a stateful ingress rule for TCP traffic on destination port 3389 from source 0.0.0.0/0 (and a separate rule with ::/0 for IPv6 traffic) and any source port. For more information, see Security Rules .
For a production VCN, you typically set up one or more custom security lists for each subnet. If you like, you can edit the subnet to use different security lists . If you choose not to use the default security list, do so only after carefully assessing which of its default rules you want to duplicate in your custom security list. For example: the default ICMP rules in the default security list are important for receiving connectivity messages for IPv4.
Your next step is to create an instance in the subnet. When you create the instance, you choose the availability domain , which VCN and subnet to use, and several other characteristics.
Each instance automatically gets a private IPv4 address. When you create an instance in a public subnet , you choose whether the instance gets a public IPv4 address. A public IPv4 address is NOT required for globally routable IPv6 traffic. But if you want to connect to the instance from an IPv4 host, you must give the instance a public IP address, or else you can't access them through the internet gateway. The default (for a public subnet) is for the instance to get a public IP address.
If the instance's VNIC is associated with a VCN and subnet that support IPv6 addressing, you have the choice of creating a compute instance with IPv6 addresses assigned at instance launch or assigning IPv6 addresses at a later date.
For more information and instructions, see Launching an Instance .
- While viewing the instance you created in the previous step, click Attached VNICs .
- Click the name of the primary VNIC from the list of attached VNICs.
- Under Resources , click IPv6 Addresses .
- Click Assign IPv6 Address .
- Automatically assign IPv6 addresses from prefix: Choose this option to let the console select an available IPv6 address from an IPv6 prefix assigned to this subnet. A subnet can have more than one IPv6 prefix, and the prefixes can be one of three types: ULA, BYOIP, or Oracle-allocated.
- Manually assign IPv6 addresses from prefix: Choose this option to select a specific address from an IPv6 prefix assigned to this subnet. Example: 0000:0000:1a1a:1a2b. This option is only available for IPv6-enabled subnets.
- Unassign if already assigned to another VNIC: (Only available if you select Manually assign IPv6 addresses from prefix: ) Leave this checkbox as is (cleared). Only use this option to force reassignment of an IPv6 address that is already assigned to another VNIC in the subnet.
If you click + Another subnet prefix you can assign additional IPv6 addresses to the instance VNIC. You can assign one and only one IPv6 address to the VNIC from each IPv6 prefix (there can be several IPv6 prefixes assigned to a subnet). If this VNIC is being attached to an existing instance after its launch, keep in mind that your instance OS needs specific configuration to use IPv6 addressing.
- Click Assign .
The IPv6 is created and then displayed on the IPv6 Addresses page for the VNIC.
You must configure the instance's OS to use the IPv6. For more information, see Configuring an Instance OS to use IPv6 .
Assign the IPv6 address dynamically when using Oracle Linux 8. Enabling IPv6 during the compute create is not supported, so you might not see the IPv6 address immediately after the instance is launched. After the compute instance is up, you can wait for the next DHCPv6 cycle to get the IPv6 address, or you can use the DHCPv6 client service to manually cycle DHCP and update with the newly added IPv6 address. To use the DHCPv6 client, enter:
- Managing IPv6s in the Console
This section includes basic tasks for working with IPv6-related resources.
See the instructions in Task 1: Create the IPv6-enabled VCN .
Summary: Creating an IPv6-enabled subnet is similar to creating an IPv4 subnet. The difference is that you must select which VCN IPv6 prefix you want to assign a /64 from and specify characters accordingly. If selecting an Oracle-allocated prefix, you can provide 8 bits for the subnet's portion of the IPv6 prefix. See Overview of IPv6 Addresses .
For general instructions, see Task 2: Create a regional IPv6-enabled public subnet . If you want a private subnet, select the radio button for Private Subnet when creating the subnet.
The process for adding an IPv6 address to a VNIC is similar to adding a secondary private IPv4 address . You can specify the particular IPv6 address to use or let Oracle choose it from the subnet. For more information, see Overview of IPv6 Addresses . After assigning the IPv6 to the VNIC, you must configure the OS to use the IPv6 .
- Assign the IPv6. For general instructions, see Task 7: Add an IPv6 address to the instance .
- Configure the OS to use the IPv6 address. For more information, see Configuring an Instance OS to use IPv6 .
The process is similar to moving a secondary private IPv4 address from one VNIC to another (let's call them the original VNIC and the new VNIC ). You assign the IPv6 to the new VNIC, specify the IPv6 address, and select Unassign if already assigned to another VNIC . Oracle automatically unassigns it from original VNIC and assigns it to the new VNIC.
- Confirm you're viewing the compartment that contains the instance you're interested in.
- Open the navigation menu and click Compute . Under Compute , click Instances .
- Click the instance to view its details.
Under Resources , click Attached VNICs .
The primary VNIC and any secondary VNICs attached to the instance are displayed.
- Click the VNIC you're interested in.
- Click Assign Private IP Address .
- IPv6 Address: The IPv6 address that you want to move.
- Unassign if already assigned to another VNIC: Select this checkbox to move the IPv6 address from the currently assigned VNIC.
- Tags: If you have permissions to create a resource, then you also have permissions to apply free-form tags to that resource. To apply a defined tag, you must have permissions to use the tag namespace. For more information about tagging, see Resource Tags . If you're not sure whether to apply tags, skip this option or ask an administrator. You can apply tags later.
The IP address is moved from the original VNIC to the new VNIC.

- Confirm when prompted.
The IPv6 address is returned to the pool of available addresses in the subnet.
- Using the API
For information about using the API and signing requests, see REST API documentation and Security Credentials . For information about SDKs, see SDKs and the CLI .
For IPv6 addressing, there's an Ipv6 object with the following operations:
- Configuring an Instance OS to use IPv6
After assigning an IPv6 address to the VNIC through the Console, the associated instance OS need to learn the assigned address. DHCPv6 will automatically take care of this, but that will require you to wait for the next refresh cycle. You can require the instance's operating system to immediately refresh its IPv6 address.
Oracle Linux Configuration
Oracle Linux 8 uses the following command to refresh an IPv6 address on an instance:
See the Setting Up Networking documentation for Oracle Linux 8 for more details.
If you haven't yet, ensure that the VCN's route table and security rules are configured for the wanted IPv6 traffic. See Routing for IPv6 Traffic and Security Rules for IPv6 Traffic .
Windows Configuration
You can use the following at the Windows command line or the Network Connections UI to ask the instance to refresh the IPv6 address:
If you use PowerShell, you must run it as an administrator. The configuration persists through a reboot of the instance. Apply it as soon as possible after the instance is created.
- Settings Profile and security information
IPv6 Information
On this page.
Scroll for more
What is IPv6?
Internet Protocol version 6 (IPv6) is the latest IP revision, developed as a successor to IPv4. IPv6 provides a much larger address pool so that many more devices can be connected to the Internet. It also improves addressing and routing of network traffic. Because the free pool of IPv4 addresses has been depleted, customers will want to request IPv6 address space for new networks, and eventually transition their networks from IPv4 to IPv6.
For a more complete understanding of IPv6, the video below provides a walkthrough of many of the finer details of IPv6.
Why Do You Need IPv6?
Now that IPv4 is depleted, there are extra costs associated with staying IPv4-only, which will likely increase over time. On the other hand, it is easy to get IPv6 from ARIN, there are generally no additional costs for ISPs, and fees were recently reduced for end users.
Don’t forget that we also have a reserve IPv4 block that is dedicated for IPv6 transition support, which you can read more about in ARIN’s Number Resource Policy Manual (Section 4.10) . You can receive one /24 every six months to support your IPv6 transition effort.
Preparing for IPv6
Before you implement IPv6, it’s a good idea to make sure your equipment, software, and staff are ready. Think about how many network addresses you’ll need, and how you’ll set up your network.
To learn more about how to determine how much IPv6 address space you need, visit Your First IPv6 Request .
Get advice from those who have already adopted IPv6, and ask questions! You can read case studies from organizations that have already adopted IPv6 including ISPs, hosting providers, enterprise businesses, universities, and governments.
How Do I Get IPv6?
It’s easy! Follow these steps:
- Research and plan (see above).
- Decide how much space you’ll need to request. Your First IPv6 Request will help.
- Submit your request through ARIN Online.
What Do I Do Next?
- Implement IPv6 on your network’s hardware and applications, using our IPv6 Case Studies for implementation advice and shared experiences from other organizations who have already implemented IPv6.
For More Information
For more information, see:
- Guide to Internet Number Resources
- Your First IPv6 Request
- IPv6 Case Studies
- IP Address Blocks from which ARIN Issues Resources
- IPv6 Wiki Archive
- IPv6 Consulting and Training Services
- IPv6 Hosting and DNS Providers
How ARIN uses IPv6
- How ARIN Adopted IPv6
- Video Part 1 | Part 2
How is IPv6 Different than IPv4?
IPv6 differs from IPv4 in many ways, including address size, format, notation, and possible combinations.
An IPv6 address consists of 128 bits (as opposed to the 32-bit size of IPv4 addresses) and is expressed in hexadecimal notation. The IPv6 anatomy graphic below represents just one possible configuration of an IPv6 address, although there are many different possibilities.

Determining the Netmask and Gateway of an IPv6 Address
As with IPv4, in IPv6 there is no way to definitively calculate the netmask and gateway using only a given address. Both are established when a person sets up a network, and you would need to contact your network administrator to determine what they are. However, when given an address and a prefix, one can compute the starting and ending addresses of a subnet, just like in IPv4.
To conform to typical conventions about IPv6 addressing of network interfaces, most networks use a /64 prefix. This prefix length accommodates stateless address autoconfiguration (SLAAC). Note that the length of a given IPv6 network prefix cannot be shorter than the registered IPv6 allocation or assignment.
There is no strong convention as to where to number the gateway; although choosing the smallest number in the network is common.
- The History of IPv6 @ ARIN
- IP Addresses & ASNs
- Getting Started With ARIN
- Quick Guide to Requesting Resources
- Preparing Applications for IPv6
- CIDR Chart: IP Address Block Size Equivalents in Classful Addressing, IPv4, and IPv6
Registration Services Help Desk 7:00 AM to 7:00 PM ET Phone: +1.703.227.0660 Fax: +1.703.997.8844
Tips for Calling the Help Desk
Introduction to IPv6
In this lesson, I’ll give you an introduction to IPv6 and you will learn the differences between IPv4 and IPv6. Let’s start with a nice picture:

This picture is old already but it shows you the reason why we need IPv6…we are running out of IPv4 addresses!
So what happened to IPv4? What went wrong? We have 32 bits which gives us 4,294,467,295 IP addresses. Remember our Class A, B, and C ranges? When the Internet started, you would get a Class A, B, or C network. Class C gives you a block of 256 IP addresses, class B is 65.535 IP addresses, and a class A even 16,777,216 IP addresses. Large companies like Apple, Microsoft, IBM, and such got one or more Class A networks. Did they really need > 16 million IP addresses? Many IP addresses were just wasted.
We started using VLSM (Variable Length Subnet Mask), so we could use any subnet mask we like and create smaller subnets, we no longer had to use the class A, B, or C networks. We also started using NAT and PAT so we can have many private IP addresses behind a single public IP address.
Nevertheless, the Internet has grown in a way nobody expected 20 years ago. Despite all our cool tricks like VLSM and NAT/PAT we really need more IP addresses, and that’s why we need IPv6.
What happened to IPv5? Good question…IP version 5 was used for an experimental project called “Internet Stream Protocol”. It’s defined in an RFC if you are interested.
IPv6 has 128-bit addresses and has a much larger address space than 32-bit IPv4 which offered us a bit more than 4 billion addresses. Keep in mind every additional bit doubles the number of IP addresses…so we go from 4 billion to 8 billion, 16,32,64, etc. Keep doubling until you reach 128 bits. With 128 bits, this is the largest value you can create:
- 340,282,366,920,938,463,463,374,607,431,768,211,456
Can we even pronounce this? Let’s try this:
- 340- undecillion
- 282- decillion
- 366- nonillion
- 920- octillion
- 938- septillion
- 463- sextillion
- 463- quintillion
- 374- quadrillion
- 607- trillion
- 431- billion
- 768- million
- 211- thousand
That’s mind-boggling… This gives us enough IP addresses for networks on Earth, the moon, mars, and the rest of the universe. To put this in perspective, let’s put the entire IPv6 and IPv4 address space next to each other:
- IPv6: 340282366920938463463374607431768211456
- IPv4: 4294467295
Some other nice numbers: the entire IPv6 address space is 4294467295 times the size of the complete IPv4 address space. Or, if you like percentages, the entire IPv4 address space is only 0.000000000000000000000000001.26% of the entire IPv6 address space.
The main reason to start using IPv6 is that we need more addresses, but it also offers some new features:
- No Broadcast traffic : that’s right, we don’t use broadcasts anymore. We use multicast instead. This means some protocols like ARP are replaced with other solutions.
- Stateless Autoconfiguration : this is like a “mini DHCP server.” Routers running IPv6 are able to advertise the IPv6 prefix and gateway address to hosts so that they can automatically configure themselves and get access outside of their own network.
- Address Renumbering : renumbering static IPv4 addresses on your network is a pain. If you use stateless autoconfiguration for IPv6, you can easily swap the current prefix with another one.
- Mobility : IPv6 has built-in support for mobile devices. Hosts will be able to move from one network to another and keep their current IPv6 address.
- No NAT / PAT : we have so many IPv6 addresses that we don’t need NAT or PAT anymore. Every device in your network can have a public IPv6 address.
- IPsec : IPv6 has native support for IPsec, you don’t have to use it, but it’s built-in the protocol.
- Improved header : the IPv6 header is simpler and doesn’t require checksums. It also has a flow label that is used to quickly see whether certain packets belong to the same flow.
- Migration Tools : IPv4 and IPv6 are incompatible, so we need migration tools. We can use multiple tunneling techniques to transport IPv6 over IPv4 networks (or the other way around). Running IPv4 and IPv6 simultaneously is called “dual stack.”
What does an IPv6 address look like? We use a different format than IPv4:
X:X:X:X:X:X:X:X where X is a 16-bit hexadecimal field
We don’t use decimal numbers like for IPv4. We are using hexadecimal now. Here’s an example of an actual IPv6 address:
2041:1234:140F:1122:AB91:564F:875B:131B
Now imagine you have to call one of your users or colleagues and ask him or her to ping this IPv6 address when you are trying to troubleshoot something…sounds like fun, right?
To make things a bit more convenient, it’s possible to shorten IPv6 addresses , which I discuss in this lesson . Running a local DNS server is also a good idea. Remembering hostnames is easier than these IPv6 addresses.
That’s all I have for now. I hope this introduction has given you an idea of why we need IPv6, what the address looks like, and some of the new features. The next lessons cover everything, including addressing, routing protocols, tunneling, and more.
That’s all for now! You should now have an idea of how IPv6 works. In future lessons, I will show you how to configure routing for IPv6 and some other things. If you have any questions, just leave a comment.
Tags: EUI-64
Forum Replies
Probably little mistake on last picture. On picture above is mac adress starting with CC0A and on the last picture is IPv6 address with CE0A. Anyway, thanks for great lesson.
In reality the router does one more thing when creating the IPv6 address using EUI-64. The MAC address is chopped in two pieces but it will also “flip” the 7th bit. When it’s a 0 it will make it a 1 and the other way around. Here’s an example for the MAC address I used in this tutorial:
CC0A.180E.0000
Each hexadecimal character represents 4 binary bits:
C = 1100 C = 1100 0 = 0000 A = 1010
Let’s put “CC” in binary behind each other:
EUI-64 will flip the 7th bit of this address so it will become:
Let’s calculate that back to hexadecim
If you want an example for EUI-64, I created a lesson that explains it in detail:
https://networklessons.com/ipv6/ipv6-eui-64-explained
Hello, Nice job at the introduction, I never new what anything past a trillion was called =). I’m sure i’ll have questions as I read through the following IPv6 lessons though.
Thanks again,

If you have any questions, just let me know…
25 more replies! Ask a question or join the discussion by visiting our Community Forum
IMAGES
VIDEO
COMMENTS
Before going into details about the size of IPv6 prefix assignments, the choice for the WAN link needs to be understood. There are three options for addresses on the link between the operator network and the "end-user" CPE WAN port. Note that CE is also commonly used for the CPE (RFC 7084). 4.1.1. /64 prefix from a dedicated pool of IPv6 ...
This web page lists the allocation of IPv6 unicast address space by IANA and RIRs. It includes the prefix, date, WHOIS, status and note of each assignment, as well as references to other registries and RFCs.
Learn how to calculate the prefix of an IPv6 address using prefix length, hexadecimal characters and binary bits. See examples of IPv6 addresses with different prefix lengths and how to write them in short form.
Learn how to create IPv6 prefixes and subnets from IANA, RIRs, ISPs and customers. See how to use 16 bits to create 65.536 subnets with an example of a global unicast prefix.
Temporary address assignment (IA_TA) Prefix Delegation (PD) All three methods are accomplished by including an option in the Request which is then populated by the server and returned in the Reply. For the first two, a complete IPv6 address is returned which can then be assigned as an IP address for the interface.
to the operational practices for the assignment of IPv6 prefixes for end-customers. •Making wrong choices when designing your IPv6 network will sooner or later have negative implications on your deployment and require further effort such as renumbering when the network is already in operation. The temptation
5.4. Assignment. LIRs must make IPv6 assignments in accordance with the following provisions. 5.4.1. Assignment address space size. End Users are assigned an End Site assignment from their LIR or ISP. The size of the assignment is a local decision for the LIR or ISP to make, using a value of "n" x /64. Section 4.2 of ripe-690 provides ...
Learn how to configure IPv6 on OpenWrt devices, including native, PPP-based and tunneled connections. See options for DHCPv6, prefix handling, firewall, DNS and more.
RIPE-690 outlines best current operational practices for the assignment of IPv6 prefixes (i.e. a block of IPv6 addresses) for end-users, as making wrong choices when designing an IPv6 network will eventually have negative implications for deployment and require further effort such as renumbering when the network is already in operation.
Learn how IPv6 addresses are assigned by network operators and how the prefix lengths vary across different ISPs. See the results of a study based on 7M to 8M IPv6 source addresses per day from APNIC Labs.
5. End-customer IPv6 prefix assignment: Persistent vs non-persistent 5.1. Why non-persistent assignments may be perceived as "easier" than static ones 5.2. Why non-persistent assignments are considered harmful. 5.3. Why persistent prefix assignments are recommended 6. Acknowledgements BCOP IPv6 Prefix Assignment for end-customers - 5
The simplest description for sparse allocation of IPv6 is the assignment of prefixes with lots of additional unused prefixes (and thus address space) in between them. The basic benefit of this method is not simply leaving space in reserve—after all, it likely wouldn't be that hard to find available extra IPv6 address space from within the ...
Learn how to integrate IPv6 into a network that already has IPv4 address space and how to handle multiple IP address ranges. This guide covers IPv6 addressing format, types, management, assignment, and transition technologies.
Create a prefix pool. ipv6 dhcp prefix-pool prefix-pool-number prefix { prefix-number | prefix/prefix-len } assign-len assign-len. This step is required for dynamic prefix assignment. If you specify an IPv6 prefix by its ID, make sure the IPv6 prefix is in effect. Otherwise, the configuration does not take effect. Enter DHCP address pool view.
The upper 64 bits of an IPv6 prefix usually consists of a /48 global routing prefix (or site prefix) and the remaining 16 bits are used for more specific prefixes (the subnet). This is explained in detail in the following lesson: IPv6 address assignment. The IPv6 general (or generic) prefix feature lets you renumber a global prefix on your ...
Learn how to implement IPv6 addressing and basic connectivity in Cisco IOS XE 17 software. Find feature information, prerequisites, restrictions, and configuration examples for IPv6 features such as Cisco Express Forwarding, DNS, and neighbor discovery.
This web page lists the IPv6 address formats, prefixes, and allocations by IANA. It does not contain any information about the query fec0::c0:a8:1:1, which is a reserved prefix for site-local unicast addresses.
use of the :: makes many IPv6 addresses very small. Network Prefix The IPv6 prefix is part of the address that represents the left-most bits that have a fixed value and represent the network identifier. The IPv6 prefix is represented using the IPv6-prefix or prefix-length format just like an IPv4
8.7.1 Duplicate Address Detection. Whenever an IPv6 host obtains a unicast address - a link-local address, an address created via SLAAC, an address received via DHCPv6 or a manually configured address - it goes through a duplicate-address detection (DAD) process. The host sends one or more Neighbor Solicitation messages (that is, like an ARP query), as in 8.6 Neighbor Discovery, asking if ...
Enable IPv6 Address Assignment: Oracle can allocate an IPv6 prefix for you, you can select a BYOIPv6 prefix you have already imported, or you can specify a ULA prefix. You cannot later disable IPv6 for the VCN but you can change the IPv6 prefix or prefixes on the VCN as long as there is always at least one IPv6 prefix.
Learn about different types of IPv6 addresses, such as global unicast, unique local, link-local and multicast. Find out how to create and use link-local addresses with FE80::/10 prefix and what they look like.
Learn about IPv6, the latest IP revision with a much larger address pool than IPv4. An IPv6 address consists of 128 bits and is expressed in hexadecimal notation.
IPv6 Address Assignment Example; IPv6 EUI-64 explained; IPv6 Summarization Example; IPv6 General Prefix; IPv6 Solicited Node Multicast Address; IPv6 Neighbor Discovery Protocol; IPv6 Stateless Autoconfiguration; Troubleshooting IPv6 Stateless Autoconfiguration; IPv6 Router Advertisement Preference;