Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base

Hypothesis Testing | A Step-by-Step Guide with Easy Examples
Published on November 8, 2019 by Rebecca Bevans . Revised on June 22, 2023.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics . It is most often used by scientists to test specific predictions, called hypotheses, that arise from theories.
There are 5 main steps in hypothesis testing:
- State your research hypothesis as a null hypothesis and alternate hypothesis (H o ) and (H a or H 1 ).
- Collect data in a way designed to test the hypothesis.
- Perform an appropriate statistical test .
- Decide whether to reject or fail to reject your null hypothesis.
- Present the findings in your results and discussion section.
Though the specific details might vary, the procedure you will use when testing a hypothesis will always follow some version of these steps.
Table of contents
Step 1: state your null and alternate hypothesis, step 2: collect data, step 3: perform a statistical test, step 4: decide whether to reject or fail to reject your null hypothesis, step 5: present your findings, other interesting articles, frequently asked questions about hypothesis testing.
After developing your initial research hypothesis (the prediction that you want to investigate), it is important to restate it as a null (H o ) and alternate (H a ) hypothesis so that you can test it mathematically.
The alternate hypothesis is usually your initial hypothesis that predicts a relationship between variables. The null hypothesis is a prediction of no relationship between the variables you are interested in.
- H 0 : Men are, on average, not taller than women. H a : Men are, on average, taller than women.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
For a statistical test to be valid , it is important to perform sampling and collect data in a way that is designed to test your hypothesis. If your data are not representative, then you cannot make statistical inferences about the population you are interested in.
There are a variety of statistical tests available, but they are all based on the comparison of within-group variance (how spread out the data is within a category) versus between-group variance (how different the categories are from one another).
If the between-group variance is large enough that there is little or no overlap between groups, then your statistical test will reflect that by showing a low p -value . This means it is unlikely that the differences between these groups came about by chance.
Alternatively, if there is high within-group variance and low between-group variance, then your statistical test will reflect that with a high p -value. This means it is likely that any difference you measure between groups is due to chance.
Your choice of statistical test will be based on the type of variables and the level of measurement of your collected data .
- an estimate of the difference in average height between the two groups.
- a p -value showing how likely you are to see this difference if the null hypothesis of no difference is true.
Based on the outcome of your statistical test, you will have to decide whether to reject or fail to reject your null hypothesis.
In most cases you will use the p -value generated by your statistical test to guide your decision. And in most cases, your predetermined level of significance for rejecting the null hypothesis will be 0.05 – that is, when there is a less than 5% chance that you would see these results if the null hypothesis were true.
In some cases, researchers choose a more conservative level of significance, such as 0.01 (1%). This minimizes the risk of incorrectly rejecting the null hypothesis ( Type I error ).
Prevent plagiarism. Run a free check.
The results of hypothesis testing will be presented in the results and discussion sections of your research paper , dissertation or thesis .
In the results section you should give a brief summary of the data and a summary of the results of your statistical test (for example, the estimated difference between group means and associated p -value). In the discussion , you can discuss whether your initial hypothesis was supported by your results or not.
In the formal language of hypothesis testing, we talk about rejecting or failing to reject the null hypothesis. You will probably be asked to do this in your statistics assignments.
However, when presenting research results in academic papers we rarely talk this way. Instead, we go back to our alternate hypothesis (in this case, the hypothesis that men are on average taller than women) and state whether the result of our test did or did not support the alternate hypothesis.
If your null hypothesis was rejected, this result is interpreted as “supported the alternate hypothesis.”
These are superficial differences; you can see that they mean the same thing.
You might notice that we don’t say that we reject or fail to reject the alternate hypothesis . This is because hypothesis testing is not designed to prove or disprove anything. It is only designed to test whether a pattern we measure could have arisen spuriously, or by chance.
If we reject the null hypothesis based on our research (i.e., we find that it is unlikely that the pattern arose by chance), then we can say our test lends support to our hypothesis . But if the pattern does not pass our decision rule, meaning that it could have arisen by chance, then we say the test is inconsistent with our hypothesis .
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Descriptive statistics
- Measures of central tendency
- Correlation coefficient
Methodology
- Cluster sampling
- Stratified sampling
- Types of interviews
- Cohort study
- Thematic analysis
Research bias
- Implicit bias
- Cognitive bias
- Survivorship bias
- Availability heuristic
- Nonresponse bias
- Regression to the mean
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 22). Hypothesis Testing | A Step-by-Step Guide with Easy Examples. Scribbr. Retrieved August 24, 2024, from https://www.scribbr.com/statistics/hypothesis-testing/
Is this article helpful?

Rebecca Bevans
Other students also liked, choosing the right statistical test | types & examples, understanding p values | definition and examples, what is your plagiarism score.
- Skip to secondary menu
- Skip to main content
- Skip to primary sidebar
Statistics By Jim
Making statistics intuitive
Statistical Hypothesis Testing Overview
By Jim Frost 59 Comments
In this blog post, I explain why you need to use statistical hypothesis testing and help you navigate the essential terminology. Hypothesis testing is a crucial procedure to perform when you want to make inferences about a population using a random sample. These inferences include estimating population properties such as the mean, differences between means, proportions, and the relationships between variables.
This post provides an overview of statistical hypothesis testing. If you need to perform hypothesis tests, consider getting my book, Hypothesis Testing: An Intuitive Guide .
Why You Should Perform Statistical Hypothesis Testing

Hypothesis testing is a form of inferential statistics that allows us to draw conclusions about an entire population based on a representative sample. You gain tremendous benefits by working with a sample. In most cases, it is simply impossible to observe the entire population to understand its properties. The only alternative is to collect a random sample and then use statistics to analyze it.
While samples are much more practical and less expensive to work with, there are trade-offs. When you estimate the properties of a population from a sample, the sample statistics are unlikely to equal the actual population value exactly. For instance, your sample mean is unlikely to equal the population mean. The difference between the sample statistic and the population value is the sample error.
Differences that researchers observe in samples might be due to sampling error rather than representing a true effect at the population level. If sampling error causes the observed difference, the next time someone performs the same experiment the results might be different. Hypothesis testing incorporates estimates of the sampling error to help you make the correct decision. Learn more about Sampling Error .
For example, if you are studying the proportion of defects produced by two manufacturing methods, any difference you observe between the two sample proportions might be sample error rather than a true difference. If the difference does not exist at the population level, you won’t obtain the benefits that you expect based on the sample statistics. That can be a costly mistake!
Let’s cover some basic hypothesis testing terms that you need to know.
Background information : Difference between Descriptive and Inferential Statistics and Populations, Parameters, and Samples in Inferential Statistics
Hypothesis Testing
Hypothesis testing is a statistical analysis that uses sample data to assess two mutually exclusive theories about the properties of a population. Statisticians call these theories the null hypothesis and the alternative hypothesis. A hypothesis test assesses your sample statistic and factors in an estimate of the sample error to determine which hypothesis the data support.
When you can reject the null hypothesis, the results are statistically significant, and your data support the theory that an effect exists at the population level.
The effect is the difference between the population value and the null hypothesis value. The effect is also known as population effect or the difference. For example, the mean difference between the health outcome for a treatment group and a control group is the effect.
Typically, you do not know the size of the actual effect. However, you can use a hypothesis test to help you determine whether an effect exists and to estimate its size. Hypothesis tests convert your sample effect into a test statistic, which it evaluates for statistical significance. Learn more about Test Statistics .
An effect can be statistically significant, but that doesn’t necessarily indicate that it is important in a real-world, practical sense. For more information, read my post about Statistical vs. Practical Significance .
Null Hypothesis
The null hypothesis is one of two mutually exclusive theories about the properties of the population in hypothesis testing. Typically, the null hypothesis states that there is no effect (i.e., the effect size equals zero). The null is often signified by H 0 .
In all hypothesis testing, the researchers are testing an effect of some sort. The effect can be the effectiveness of a new vaccination, the durability of a new product, the proportion of defect in a manufacturing process, and so on. There is some benefit or difference that the researchers hope to identify.
However, it’s possible that there is no effect or no difference between the experimental groups. In statistics, we call this lack of an effect the null hypothesis. Therefore, if you can reject the null, you can favor the alternative hypothesis, which states that the effect exists (doesn’t equal zero) at the population level.
You can think of the null as the default theory that requires sufficiently strong evidence against in order to reject it.
For example, in a 2-sample t-test, the null often states that the difference between the two means equals zero.
When you can reject the null hypothesis, your results are statistically significant. Learn more about Statistical Significance: Definition & Meaning .
Related post : Understanding the Null Hypothesis in More Detail
Alternative Hypothesis
The alternative hypothesis is the other theory about the properties of the population in hypothesis testing. Typically, the alternative hypothesis states that a population parameter does not equal the null hypothesis value. In other words, there is a non-zero effect. If your sample contains sufficient evidence, you can reject the null and favor the alternative hypothesis. The alternative is often identified with H 1 or H A .
For example, in a 2-sample t-test, the alternative often states that the difference between the two means does not equal zero.
You can specify either a one- or two-tailed alternative hypothesis:
If you perform a two-tailed hypothesis test, the alternative states that the population parameter does not equal the null value. For example, when the alternative hypothesis is H A : μ ≠ 0, the test can detect differences both greater than and less than the null value.
A one-tailed alternative has more power to detect an effect but it can test for a difference in only one direction. For example, H A : μ > 0 can only test for differences that are greater than zero.
Related posts : Understanding T-tests and One-Tailed and Two-Tailed Hypothesis Tests Explained

P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is correct. In simpler terms, p-values tell you how strongly your sample data contradict the null. Lower p-values represent stronger evidence against the null. You use P-values in conjunction with the significance level to determine whether your data favor the null or alternative hypothesis.
Related post : Interpreting P-values Correctly
Significance Level (Alpha)

For instance, a significance level of 0.05 signifies a 5% risk of deciding that an effect exists when it does not exist.
Use p-values and significance levels together to help you determine which hypothesis the data support. If the p-value is less than your significance level, you can reject the null and conclude that the effect is statistically significant. In other words, the evidence in your sample is strong enough to be able to reject the null hypothesis at the population level.
Related posts : Graphical Approach to Significance Levels and P-values and Conceptual Approach to Understanding Significance Levels
Types of Errors in Hypothesis Testing
Statistical hypothesis tests are not 100% accurate because they use a random sample to draw conclusions about entire populations. There are two types of errors related to drawing an incorrect conclusion.
- False positives: You reject a null that is true. Statisticians call this a Type I error . The Type I error rate equals your significance level or alpha (α).
- False negatives: You fail to reject a null that is false. Statisticians call this a Type II error. Generally, you do not know the Type II error rate. However, it is a larger risk when you have a small sample size , noisy data, or a small effect size. The type II error rate is also known as beta (β).
Statistical power is the probability that a hypothesis test correctly infers that a sample effect exists in the population. In other words, the test correctly rejects a false null hypothesis. Consequently, power is inversely related to a Type II error. Power = 1 – β. Learn more about Power in Statistics .
Related posts : Types of Errors in Hypothesis Testing and Estimating a Good Sample Size for Your Study Using Power Analysis
Which Type of Hypothesis Test is Right for You?
There are many different types of procedures you can use. The correct choice depends on your research goals and the data you collect. Do you need to understand the mean or the differences between means? Or, perhaps you need to assess proportions. You can even use hypothesis testing to determine whether the relationships between variables are statistically significant.
To choose the proper statistical procedure, you’ll need to assess your study objectives and collect the correct type of data . This background research is necessary before you begin a study.
Related Post : Hypothesis Tests for Continuous, Binary, and Count Data
Statistical tests are crucial when you want to use sample data to make conclusions about a population because these tests account for sample error. Using significance levels and p-values to determine when to reject the null hypothesis improves the probability that you will draw the correct conclusion.
To see an alternative approach to these traditional hypothesis testing methods, learn about bootstrapping in statistics !
If you want to see examples of hypothesis testing in action, I recommend the following posts that I have written:
- How Effective Are Flu Shots? This example shows how you can use statistics to test proportions.
- Fatality Rates in Star Trek . This example shows how to use hypothesis testing with categorical data.
- Busting Myths About the Battle of the Sexes . A fun example based on a Mythbusters episode that assess continuous data using several different tests.
- Are Yawns Contagious? Another fun example inspired by a Mythbusters episode.
Share this:

Reader Interactions

January 14, 2024 at 8:43 am
Hello professor Jim, how are you doing! Pls. What are the properties of a population and their examples? Thanks for your time and understanding.

January 14, 2024 at 12:57 pm
Please read my post about Populations vs. Samples for more information and examples.
Also, please note there is a search bar in the upper-right margin of my website. Use that to search for topics.

July 5, 2023 at 7:05 am
Hello, I have a question as I read your post. You say in p-values section
“P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is correct. In simpler terms, p-values tell you how strongly your sample data contradict the null. Lower p-values represent stronger evidence against the null.”
But according to your definition of effect, the null states that an effect does not exist, correct? So what I assume you want to say is that “P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is **incorrect**.”
July 6, 2023 at 5:18 am
Hi Shrinivas,
The correct definition of p-value is that it is a probability that exists in the context of a true null hypothesis. So, the quotation is correct in stating “if the null hypothesis is correct.”
Essentially, the p-value tells you the likelihood of your observed results (or more extreme) if the null hypothesis is true. It gives you an idea of whether your results are surprising or unusual if there is no effect.
Hence, with sufficiently low p-values, you reject the null hypothesis because it’s telling you that your sample results were unlikely to have occurred if there was no effect in the population.
I hope that helps make it more clear. If not, let me know I’ll attempt to clarify!

May 8, 2023 at 12:47 am
Thanks a lot Ny best regards
May 7, 2023 at 11:15 pm
Hi Jim Can you tell me something about size effect? Thanks
May 8, 2023 at 12:29 am
Here’s a post that I’ve written about Effect Sizes that will hopefully tell you what you need to know. Please read that. Then, if you have any more specific questions about effect sizes, please post them there. Thanks!

January 7, 2023 at 4:19 pm
Hi Jim, I have only read two pages so far but I am really amazed because in few paragraphs you made me clearly understand the concepts of months of courses I received in biostatistics! Thanks so much for this work you have done it helps a lot!
January 10, 2023 at 3:25 pm
Thanks so much!

June 17, 2021 at 1:45 pm
Can you help in the following question: Rocinante36 is priced at ₹7 lakh and has been designed to deliver a mileage of 22 km/litre and a top speed of 140 km/hr. Formulate the null and alternative hypotheses for mileage and top speed to check whether the new models are performing as per the desired design specifications.

April 19, 2021 at 1:51 pm
Its indeed great to read your work statistics.
I have a doubt regarding the one sample t-test. So as per your book on hypothesis testing with reference to page no 45, you have mentioned the difference between “the sample mean and the hypothesised mean is statistically significant”. So as per my understanding it should be quoted like “the difference between the population mean and the hypothesised mean is statistically significant”. The catch here is the hypothesised mean represents the sample mean.
Please help me understand this.
Regards Rajat
April 19, 2021 at 3:46 pm
Thanks for buying my book. I’m so glad it’s been helpful!
The test is performed on the sample but the results apply to the population. Hence, if the difference between the sample mean (observed in your study) and the hypothesized mean is statistically significant, that suggests that population does not equal the hypothesized mean.
For one sample tests, the hypothesized mean is not the sample mean. It is a mean that you want to use for the test value. It usually represents a value that is important to your research. In other words, it’s a value that you pick for some theoretical/practical reasons. You pick it because you want to determine whether the population mean is different from that particular value.
I hope that helps!

November 5, 2020 at 6:24 am
Jim, you are such a magnificent statistician/economist/econometrician/data scientist etc whatever profession. Your work inspires and simplifies the lives of so many researchers around the world. I truly admire you and your work. I will buy a copy of each book you have on statistics or econometrics. Keep doing the good work. Remain ever blessed
November 6, 2020 at 9:47 pm
Hi Renatus,
Thanks so much for you very kind comments. You made my day!! I’m so glad that my website has been helpful. And, thanks so much for supporting my books! 🙂

November 2, 2020 at 9:32 pm
Hi Jim, I hope you are aware of 2019 American Statistical Association’s official statement on Statistical Significance: https://www.tandfonline.com/doi/full/10.1080/00031305.2019.1583913 In case you do not bother reading the full article, may I quote you the core message here: “We conclude, based on our review of the articles in this special issue and the broader literature, that it is time to stop using the term “statistically significant” entirely. Nor should variants such as “significantly different,” “p < 0.05,” and “nonsignificant” survive, whether expressed in words, by asterisks in a table, or in some other way."
With best wishes,
November 3, 2020 at 2:09 am
I’m definitely aware of the debate surrounding how to use p-values most effectively. However, I need to correct you on one point. The link you provide is NOT a statement by the American Statistical Association. It is an editorial by several authors.
There is considerable debate over this issue. There are problems with p-values. However, as the authors state themselves, much of the problem is over people’s mindsets about how to use p-values and their incorrect interpretations about what statistical significance does and does not mean.
If you were to read my website more thoroughly, you’d be aware that I share many of their concerns and I address them in multiple posts. One of the authors’ key points is the need to be thoughtful and conduct thoughtful research and analysis. I emphasize this aspect in multiple posts on this topic. I’ll ask you to read the following three because they all address some of the authors’ concerns and suggestions. But you might run across others to read as well.
Five Tips for Using P-values to Avoid Being Misled How to Interpret P-values Correctly P-values and the Reproducibility of Experimental Results

September 24, 2020 at 11:52 pm
HI Jim, i just want you to know that you made explanation for Statistics so simple! I should say lesser and fewer words that reduce the complexity. All the best! 🙂
September 25, 2020 at 1:03 am
Thanks, Rene! Your kind words mean a lot to me! I’m so glad it has been helpful!

September 23, 2020 at 2:21 am
Honestly, I never understood stats during my entire M.Ed course and was another nightmare for me. But how easily you have explained each concept, I have understood stats way beyond my imagination. Thank you so much for helping ignorant research scholars like us. Looking forward to get hardcopy of your book. Kindly tell is it available through flipkart?
September 24, 2020 at 11:14 pm
I’m so happy to hear that my website has been helpful!
I checked on flipkart and it appears like my books are not available there. I’m never exactly sure where they’re available due to the vagaries of different distribution channels. They are available on Amazon in India.
Introduction to Statistics: An Intuitive Guide (Amazon IN) Hypothesis Testing: An Intuitive Guide (Amazon IN)

July 26, 2020 at 11:57 am
Dear Jim I am a teacher from India . I don’t have any background in statistics, and still I should tell that in a single read I can follow your explanations . I take my entire biostatistics class for botany graduates with your explanations. Thanks a lot. May I know how I can avail your books in India
July 28, 2020 at 12:31 am
Right now my books are only available as ebooks from my website. However, soon I’ll have some exciting news about other ways to obtain it. Stay tuned! I’ll announce it on my email list. If you’re not already on it, you can sign up using the form that is in the right margin of my website.

June 22, 2020 at 2:02 pm
Also can you please let me if this book covers topics like EDA and principal component analysis?
June 22, 2020 at 2:07 pm
This book doesn’t cover principal components analysis. Although, I wouldn’t really classify that as a hypothesis test. In the future, I might write a multivariate analysis book that would cover this and others. But, that’s well down the road.
My Introduction to Statistics covers EDA. That’s the largely graphical look at your data that you often do prior to hypothesis testing. The Introduction book perfectly leads right into the Hypothesis Testing book.
June 22, 2020 at 1:45 pm
Thanks for the detailed explanation. It does clear my doubts. I saw that your book related to hypothesis testing has the topics that I am studying currently. I am looking forward to purchasing it.
Regards, Take Care
June 19, 2020 at 1:03 pm
For this particular article I did not understand a couple of statements and it would great if you could help: 1)”If sample error causes the observed difference, the next time someone performs the same experiment the results might be different.” 2)”If the difference does not exist at the population level, you won’t obtain the benefits that you expect based on the sample statistics.”
I discovered your articles by chance and now I keep coming back to read & understand statistical concepts. These articles are very informative & easy to digest. Thanks for the simplifying things.
June 20, 2020 at 9:53 pm
I’m so happy to hear that you’ve found my website to be helpful!
To answer your questions, keep in mind that a central tenant of inferential statistics is that the random sample that a study drew was only one of an infinite number of possible it could’ve drawn. Each random sample produces different results. Most results will cluster around the population value assuming they used good methodology. However, random sampling error always exists and makes it so that population estimates from a sample almost never exactly equal the correct population value.
So, imagine that we’re studying a medication and comparing the treatment and control groups. Suppose that the medicine is truly not effect and that the population difference between the treatment and control group is zero (i.e., no difference.) Despite the true difference being zero, most sample estimates will show some degree of either a positive or negative effect thanks to random sampling error. So, just because a study has an observed difference does not mean that a difference exists at the population level. So, on to your questions:
1. If the observed difference is just random error, then it makes sense that if you collected another random sample, the difference could change. It could change from negative to positive, positive to negative, more extreme, less extreme, etc. However, if the difference exists at the population level, most random samples drawn from the population will reflect that difference. If the medicine has an effect, most random samples will reflect that fact and not bounce around on both sides of zero as much.
2. This is closely related to the previous answer. If there is no difference at the population level, but say you approve the medicine because of the observed effects in a sample. Even though your random sample showed an effect (which was really random error), that effect doesn’t exist. So, when you start using it on a larger scale, people won’t benefit from the medicine. That’s why it’s important to separate out what is easily explained by random error versus what is not easily explained by it.
I think reading my post about how hypothesis tests work will help clarify this process. Also, in about 24 hours (as I write this), I’ll be releasing my new ebook about Hypothesis Testing!

May 29, 2020 at 5:23 am
Hi Jim, I really enjoy your blog. Can you please link me on your blog where you discuss about Subgroup analysis and how it is done? I need to use non parametric and parametric statistical methods for my work and also do subgroup analysis in order to identify potential groups of patients that may benefit more from using a treatment than other groups.
May 29, 2020 at 2:12 pm
Hi, I don’t have a specific article about subgroup analysis. However, subgroup analysis is just the dividing up of a larger sample into subgroups and then analyzing those subgroups separately. You can use the various analyses I write about on the subgroups.
Alternatively, you can include the subgroups in regression analysis as an indicator variable and include that variable as a main effect and an interaction effect to see how the relationships vary by subgroup without needing to subdivide your data. I write about that approach in my article about comparing regression lines . This approach is my preferred approach when possible.

April 19, 2020 at 7:58 am
sir is confidence interval is a part of estimation?

April 17, 2020 at 3:36 pm
Sir can u plz briefly explain alternatives of hypothesis testing? I m unable to find the answer
April 18, 2020 at 1:22 am
Assuming you want to draw conclusions about populations by using samples (i.e., inferential statistics ), you can use confidence intervals and bootstrap methods as alternatives to the traditional hypothesis testing methods.

March 9, 2020 at 10:01 pm
Hi JIm, could you please help with activities that can best teach concepts of hypothesis testing through simulation, Also, do you have any question set that would enhance students intuition why learning hypothesis testing as a topic in introductory statistics. Thanks.

March 5, 2020 at 3:48 pm
Hi Jim, I’m studying multiple hypothesis testing & was wondering if you had any material that would be relevant. I’m more trying to understand how testing multiple samples simultaneously affects your results & more on the Bonferroni Correction
March 5, 2020 at 4:05 pm
I write about multiple comparisons (aka post hoc tests) in the ANOVA context . I don’t talk about Bonferroni Corrections specifically but I cover related types of corrections. I’m not sure if that exactly addresses what you want to know but is probably the closest I have already written. I hope it helps!

January 14, 2020 at 9:03 pm
Thank you! Have a great day/evening.
January 13, 2020 at 7:10 pm
Any help would be greatly appreciated. What is the difference between The Hypothesis Test and The Statistical Test of Hypothesis?
January 14, 2020 at 11:02 am
They sound like the same thing to me. Unless this is specialized terminology for a particular field or the author was intending something specific, I’d guess they’re one and the same.

April 1, 2019 at 10:00 am
so these are the only two forms of Hypothesis used in statistical testing?
April 1, 2019 at 10:02 am
Are you referring to the null and alternative hypothesis? If so, yes, that’s those are the standard hypotheses in a statistical hypothesis test.
April 1, 2019 at 9:57 am
year very insightful post, thanks for the write up

October 27, 2018 at 11:09 pm
hi there, am upcoming statistician, out of all blogs that i have read, i have found this one more useful as long as my problem is concerned. thanks so much
October 27, 2018 at 11:14 pm
Hi Stano, you’re very welcome! Thanks for your kind words. They mean a lot! I’m happy to hear that my posts were able to help you. I’m sure you will be a fantastic statistician. Best of luck with your studies!

October 26, 2018 at 11:39 am
Dear Jim, thank you very much for your explanations! I have a question. Can I use t-test to compare two samples in case each of them have right bias?
October 26, 2018 at 12:00 pm
Hi Tetyana,
You’re very welcome!
The term “right bias” is not a standard term. Do you by chance mean right skewed distributions? In other words, if you plot the distribution for each group on a histogram they have longer right tails? These are not the symmetrical bell-shape curves of the normal distribution.
If that’s the case, yes you can as long as you exceed a specific sample size within each group. I include a table that contains these sample size requirements in my post about nonparametric vs parametric analyses .
Bias in statistics refers to cases where an estimate of a value is systematically higher or lower than the true value. If this is the case, you might be able to use t-tests, but you’d need to be sure to understand the nature of the bias so you would understand what the results are really indicating.
I hope this helps!

April 2, 2018 at 7:28 am
Simple and upto the point 👍 Thank you so much.
April 2, 2018 at 11:11 am
Hi Kalpana, thanks! And I’m glad it was helpful!

March 26, 2018 at 8:41 am
Am I correct if I say: Alpha – Probability of wrongly rejection of null hypothesis P-value – Probability of wrongly acceptance of null hypothesis
March 28, 2018 at 3:14 pm
You’re correct about alpha. Alpha is the probability of rejecting the null hypothesis when the null is true.
Unfortunately, your definition of the p-value is a bit off. The p-value has a fairly convoluted definition. It is the probability of obtaining the effect observed in a sample, or more extreme, if the null hypothesis is true. The p-value does NOT indicate the probability that either the null or alternative is true or false. Although, those are very common misinterpretations. To learn more, read my post about how to interpret p-values correctly .

March 2, 2018 at 6:10 pm
I recently started reading your blog and it is very helpful to understand each concept of statistical tests in easy way with some good examples. Also, I recommend to other people go through all these blogs which you posted. Specially for those people who have not statistical background and they are facing to many problems while studying statistical analysis.
Thank you for your such good blogs.
March 3, 2018 at 10:12 pm
Hi Amit, I’m so glad that my blog posts have been helpful for you! It means a lot to me that you took the time to write such a nice comment! Also, thanks for recommending by blog to others! I try really hard to write posts about statistics that are easy to understand.

January 17, 2018 at 7:03 am
I recently started reading your blog and I find it very interesting. I am learning statistics by my own, and I generally do many google search to understand the concepts. So this blog is quite helpful for me, as it have most of the content which I am looking for.
January 17, 2018 at 3:56 pm
Hi Shashank, thank you! And, I’m very glad to hear that my blog is helpful!

January 2, 2018 at 2:28 pm
thank u very much sir.
January 2, 2018 at 2:36 pm
You’re very welcome, Hiral!

November 21, 2017 at 12:43 pm
Thank u so much sir….your posts always helps me to be a #statistician
November 21, 2017 at 2:40 pm
Hi Sachin, you’re very welcome! I’m happy that you find my posts to be helpful!

November 19, 2017 at 8:22 pm
great post as usual, but it would be nice to see an example.
November 19, 2017 at 8:27 pm
Thank you! At the end of this post, I have links to four other posts that show examples of hypothesis tests in action. You’ll find what you’re looking for in those posts!
Comments and Questions Cancel reply
Tutorial Playlist
Statistics tutorial, everything you need to know about the probability density function in statistics, the best guide to understand central limit theorem, an in-depth guide to measures of central tendency : mean, median and mode, the ultimate guide to understand conditional probability.
A Comprehensive Look at Percentile in Statistics
The Best Guide to Understand Bayes Theorem
Everything you need to know about the normal distribution, an in-depth explanation of cumulative distribution function, a complete guide to chi-square test, what is hypothesis testing in statistics types and examples, understanding the fundamentals of arithmetic and geometric progression, the definitive guide to understand spearman’s rank correlation, mean squared error: overview, examples, concepts and more, all you need to know about the empirical rule in statistics, the complete guide to skewness and kurtosis, a holistic look at bernoulli distribution.
All You Need to Know About Bias in Statistics
A Complete Guide to Get a Grasp of Time Series Analysis
The Key Differences Between Z-Test Vs. T-Test
The Complete Guide to Understand Pearson's Correlation
A complete guide on the types of statistical studies, everything you need to know about poisson distribution, your best guide to understand correlation vs. regression, the most comprehensive guide for beginners on what is correlation, hypothesis testing in statistics - types | examples.
Lesson 10 of 24 By Avijeet Biswal

Table of Contents
In today’s data-driven world, decisions are based on data all the time. Hypothesis plays a crucial role in that process, whether it may be making business decisions, in the health sector, academia, or in quality improvement. Without hypothesis & hypothesis tests, you risk drawing the wrong conclusions and making bad decisions. In this tutorial, you will look at Hypothesis Testing in Statistics.
The Ultimate Ticket to Top Data Science Job Roles
What Is Hypothesis Testing in Statistics?
Hypothesis Testing is a type of statistical analysis in which you put your assumptions about a population parameter to the test. It is used to estimate the relationship between 2 statistical variables.
Let's discuss few examples of statistical hypothesis from real-life -
- A teacher assumes that 60% of his college's students come from lower-middle-class families.
- A doctor believes that 3D (Diet, Dose, and Discipline) is 90% effective for diabetic patients.
Now that you know about hypothesis testing, look at the two types of hypothesis testing in statistics.
Hypothesis Testing Formula
Z = ( x̅ – μ0 ) / (σ /√n)
- Here, x̅ is the sample mean,
- μ0 is the population mean,
- σ is the standard deviation,
- n is the sample size.
How Hypothesis Testing Works?
An analyst performs hypothesis testing on a statistical sample to present evidence of the plausibility of the null hypothesis. Measurements and analyses are conducted on a random sample of the population to test a theory. Analysts use a random population sample to test two hypotheses: the null and alternative hypotheses.
The null hypothesis is typically an equality hypothesis between population parameters; for example, a null hypothesis may claim that the population means return equals zero. The alternate hypothesis is essentially the inverse of the null hypothesis (e.g., the population means the return is not equal to zero). As a result, they are mutually exclusive, and only one can be correct. One of the two possibilities, however, will always be correct.
Your Dream Career is Just Around The Corner!
Null Hypothesis and Alternative Hypothesis
The Null Hypothesis is the assumption that the event will not occur. A null hypothesis has no bearing on the study's outcome unless it is rejected.
H0 is the symbol for it, and it is pronounced H-naught.
The Alternate Hypothesis is the logical opposite of the null hypothesis. The acceptance of the alternative hypothesis follows the rejection of the null hypothesis. H1 is the symbol for it.
Let's understand this with an example.
A sanitizer manufacturer claims that its product kills 95 percent of germs on average.
To put this company's claim to the test, create a null and alternate hypothesis.
H0 (Null Hypothesis): Average = 95%.
Alternative Hypothesis (H1): The average is less than 95%.
Another straightforward example to understand this concept is determining whether or not a coin is fair and balanced. The null hypothesis states that the probability of a show of heads is equal to the likelihood of a show of tails. In contrast, the alternate theory states that the probability of a show of heads and tails would be very different.
Become a Data Scientist with Hands-on Training!
Hypothesis Testing Calculation With Examples
Let's consider a hypothesis test for the average height of women in the United States. Suppose our null hypothesis is that the average height is 5'4". We gather a sample of 100 women and determine that their average height is 5'5". The standard deviation of population is 2.
To calculate the z-score, we would use the following formula:
z = ( x̅ – μ0 ) / (σ /√n)
z = (5'5" - 5'4") / (2" / √100)
z = 0.5 / (0.045)
We will reject the null hypothesis as the z-score of 11.11 is very large and conclude that there is evidence to suggest that the average height of women in the US is greater than 5'4".
Steps in Hypothesis Testing
Hypothesis testing is a statistical method to determine if there is enough evidence in a sample of data to infer that a certain condition is true for the entire population. Here’s a breakdown of the typical steps involved in hypothesis testing:
Formulate Hypotheses
- Null Hypothesis (H0): This hypothesis states that there is no effect or difference, and it is the hypothesis you attempt to reject with your test.
- Alternative Hypothesis (H1 or Ha): This hypothesis is what you might believe to be true or hope to prove true. It is usually considered the opposite of the null hypothesis.
Choose the Significance Level (α)
The significance level, often denoted by alpha (α), is the probability of rejecting the null hypothesis when it is true. Common choices for α are 0.05 (5%), 0.01 (1%), and 0.10 (10%).
Select the Appropriate Test
Choose a statistical test based on the type of data and the hypothesis. Common tests include t-tests, chi-square tests, ANOVA, and regression analysis. The selection depends on data type, distribution, sample size, and whether the hypothesis is one-tailed or two-tailed.
Collect Data
Gather the data that will be analyzed in the test. This data should be representative of the population to infer conclusions accurately.
Calculate the Test Statistic
Based on the collected data and the chosen test, calculate a test statistic that reflects how much the observed data deviates from the null hypothesis.
Determine the p-value
The p-value is the probability of observing test results at least as extreme as the results observed, assuming the null hypothesis is correct. It helps determine the strength of the evidence against the null hypothesis.
Make a Decision
Compare the p-value to the chosen significance level:
- If the p-value ≤ α: Reject the null hypothesis, suggesting sufficient evidence in the data supports the alternative hypothesis.
- If the p-value > α: Do not reject the null hypothesis, suggesting insufficient evidence to support the alternative hypothesis.
Report the Results
Present the findings from the hypothesis test, including the test statistic, p-value, and the conclusion about the hypotheses.
Perform Post-hoc Analysis (if necessary)
Depending on the results and the study design, further analysis may be needed to explore the data more deeply or to address multiple comparisons if several hypotheses were tested simultaneously.
Types of Hypothesis Testing
To determine whether a discovery or relationship is statistically significant, hypothesis testing uses a z-test. It usually checks to see if two means are the same (the null hypothesis). Only when the population standard deviation is known and the sample size is 30 data points or more, can a z-test be applied.
A statistical test called a t-test is employed to compare the means of two groups. To determine whether two groups differ or if a procedure or treatment affects the population of interest, it is frequently used in hypothesis testing.
Chi-Square
You utilize a Chi-square test for hypothesis testing concerning whether your data is as predicted. To determine if the expected and observed results are well-fitted, the Chi-square test analyzes the differences between categorical variables from a random sample. The test's fundamental premise is that the observed values in your data should be compared to the predicted values that would be present if the null hypothesis were true.
Hypothesis Testing and Confidence Intervals
Both confidence intervals and hypothesis tests are inferential techniques that depend on approximating the sample distribution. Data from a sample is used to estimate a population parameter using confidence intervals. Data from a sample is used in hypothesis testing to examine a given hypothesis. We must have a postulated parameter to conduct hypothesis testing.
Bootstrap distributions and randomization distributions are created using comparable simulation techniques. The observed sample statistic is the focal point of a bootstrap distribution, whereas the null hypothesis value is the focal point of a randomization distribution.
A variety of feasible population parameter estimates are included in confidence ranges. In this lesson, we created just two-tailed confidence intervals. There is a direct connection between these two-tail confidence intervals and these two-tail hypothesis tests. The results of a two-tailed hypothesis test and two-tailed confidence intervals typically provide the same results. In other words, a hypothesis test at the 0.05 level will virtually always fail to reject the null hypothesis if the 95% confidence interval contains the predicted value. A hypothesis test at the 0.05 level will nearly certainly reject the null hypothesis if the 95% confidence interval does not include the hypothesized parameter.
Become a Data Scientist through hands-on learning with hackathons, masterclasses, webinars, and Ask-Me-Anything! Start learning now!
Simple and Composite Hypothesis Testing
Depending on the population distribution, you can classify the statistical hypothesis into two types.
Simple Hypothesis: A simple hypothesis specifies an exact value for the parameter.
Composite Hypothesis: A composite hypothesis specifies a range of values.
A company is claiming that their average sales for this quarter are 1000 units. This is an example of a simple hypothesis.
Suppose the company claims that the sales are in the range of 900 to 1000 units. Then this is a case of a composite hypothesis.
One-Tailed and Two-Tailed Hypothesis Testing
The One-Tailed test, also called a directional test, considers a critical region of data that would result in the null hypothesis being rejected if the test sample falls into it, inevitably meaning the acceptance of the alternate hypothesis.
In a one-tailed test, the critical distribution area is one-sided, meaning the test sample is either greater or lesser than a specific value.
In two tails, the test sample is checked to be greater or less than a range of values in a Two-Tailed test, implying that the critical distribution area is two-sided.
If the sample falls within this range, the alternate hypothesis will be accepted, and the null hypothesis will be rejected.
Become a Data Scientist With Real-World Experience
Right Tailed Hypothesis Testing
If the larger than (>) sign appears in your hypothesis statement, you are using a right-tailed test, also known as an upper test. Or, to put it another way, the disparity is to the right. For instance, you can contrast the battery life before and after a change in production. Your hypothesis statements can be the following if you want to know if the battery life is longer than the original (let's say 90 hours):
- The null hypothesis is (H0 <= 90) or less change.
- A possibility is that battery life has risen (H1) > 90.
The crucial point in this situation is that the alternate hypothesis (H1), not the null hypothesis, decides whether you get a right-tailed test.
Left Tailed Hypothesis Testing
Alternative hypotheses that assert the true value of a parameter is lower than the null hypothesis are tested with a left-tailed test; they are indicated by the asterisk "<".
Suppose H0: mean = 50 and H1: mean not equal to 50
According to the H1, the mean can be greater than or less than 50. This is an example of a Two-tailed test.
In a similar manner, if H0: mean >=50, then H1: mean <50
Here the mean is less than 50. It is called a One-tailed test.
Type 1 and Type 2 Error
A hypothesis test can result in two types of errors.
Type 1 Error: A Type-I error occurs when sample results reject the null hypothesis despite being true.
Type 2 Error: A Type-II error occurs when the null hypothesis is not rejected when it is false, unlike a Type-I error.
Suppose a teacher evaluates the examination paper to decide whether a student passes or fails.
H0: Student has passed
H1: Student has failed
Type I error will be the teacher failing the student [rejects H0] although the student scored the passing marks [H0 was true].
Type II error will be the case where the teacher passes the student [do not reject H0] although the student did not score the passing marks [H1 is true].
Our Data Scientist Master's Program covers core topics such as R, Python, Machine Learning, Tableau, Hadoop, and Spark. Get started on your journey today!
Limitations of Hypothesis Testing
Hypothesis testing has some limitations that researchers should be aware of:
- It cannot prove or establish the truth: Hypothesis testing provides evidence to support or reject a hypothesis, but it cannot confirm the absolute truth of the research question.
- Results are sample-specific: Hypothesis testing is based on analyzing a sample from a population, and the conclusions drawn are specific to that particular sample.
- Possible errors: During hypothesis testing, there is a chance of committing type I error (rejecting a true null hypothesis) or type II error (failing to reject a false null hypothesis).
- Assumptions and requirements: Different tests have specific assumptions and requirements that must be met to accurately interpret results.
Learn All The Tricks Of The BI Trade
After reading this tutorial, you would have a much better understanding of hypothesis testing, one of the most important concepts in the field of Data Science . The majority of hypotheses are based on speculation about observed behavior, natural phenomena, or established theories.
If you are interested in statistics of data science and skills needed for such a career, you ought to explore the Post Graduate Program in Data Science.
If you have any questions regarding this ‘Hypothesis Testing In Statistics’ tutorial, do share them in the comment section. Our subject matter expert will respond to your queries. Happy learning!
1. What is hypothesis testing in statistics with example?
Hypothesis testing is a statistical method used to determine if there is enough evidence in a sample data to draw conclusions about a population. It involves formulating two competing hypotheses, the null hypothesis (H0) and the alternative hypothesis (Ha), and then collecting data to assess the evidence. An example: testing if a new drug improves patient recovery (Ha) compared to the standard treatment (H0) based on collected patient data.
2. What is H0 and H1 in statistics?
In statistics, H0 and H1 represent the null and alternative hypotheses. The null hypothesis, H0, is the default assumption that no effect or difference exists between groups or conditions. The alternative hypothesis, H1, is the competing claim suggesting an effect or a difference. Statistical tests determine whether to reject the null hypothesis in favor of the alternative hypothesis based on the data.
3. What is a simple hypothesis with an example?
A simple hypothesis is a specific statement predicting a single relationship between two variables. It posits a direct and uncomplicated outcome. For example, a simple hypothesis might state, "Increased sunlight exposure increases the growth rate of sunflowers." Here, the hypothesis suggests a direct relationship between the amount of sunlight (independent variable) and the growth rate of sunflowers (dependent variable), with no additional variables considered.
4. What are the 3 major types of hypothesis?
The three major types of hypotheses are:
- Null Hypothesis (H0): Represents the default assumption, stating that there is no significant effect or relationship in the data.
- Alternative Hypothesis (Ha): Contradicts the null hypothesis and proposes a specific effect or relationship that researchers want to investigate.
- Nondirectional Hypothesis: An alternative hypothesis that doesn't specify the direction of the effect, leaving it open for both positive and negative possibilities.
Find our PL-300 Microsoft Power BI Certification Training Online Classroom training classes in top cities:
| Name | Date | Place | |
|---|---|---|---|
| 7 Sep -22 Sep 2024, Weekend batch | Your City | ||
| 21 Sep -6 Oct 2024, Weekend batch | Your City | ||
| 12 Oct -27 Oct 2024, Weekend batch | Your City |
About the Author
Avijeet is a Senior Research Analyst at Simplilearn. Passionate about Data Analytics, Machine Learning, and Deep Learning, Avijeet is also interested in politics, cricket, and football.
Recommended Resources
Free eBook: Top Programming Languages For A Data Scientist
Normality Test in Minitab: Minitab with Statistics
Machine Learning Career Guide: A Playbook to Becoming a Machine Learning Engineer
- PMP, PMI, PMBOK, CAPM, PgMP, PfMP, ACP, PBA, RMP, SP, and OPM3 are registered marks of the Project Management Institute, Inc.
LEARN STATISTICS EASILY
Learn Data Analysis Now!
A Comprehensive Guide to Hypotheses Tests in Statistics
You will learn the essentials of hypothesis tests, from fundamental concepts to practical applications in statistics.
- Null and alternative hypotheses guide hypothesis tests.
- Significance level and p-value aid decision-making.
- Parametric tests assume specific probability distributions.
- Non-parametric tests offer flexible assumptions.
- Confidence intervals provide estimate precision.
Introduction to Hypotheses Tests
Hypothesis testing is a statistical tool used to make decisions based on data.
It involves making assumptions about a population parameter and testing its validity using a population sample.
Hypothesis tests help us draw conclusions and make informed decisions in various fields like business, research, and science.
Null and Alternative Hypotheses
The null hypothesis (H0) is an initial claim about a population parameter, typically representing no effect or no difference.
The alternative hypothesis (H1) opposes the null hypothesis, suggesting an effect or difference.
Hypothesis tests aim to determine if there is evidence for the null hypothesis rejection in favor of the alternative hypothesis.
Significance Levels and P-values
The significance level (α), often set at 0.05 or 5%, serves as a threshold for determining if we should reject the null hypothesis.
A p-value, calculated during hypothesis testing, represents the probability of observing the test statistic if the null hypothesis is true.
Suppose the p-value is less than the significance level. We reject the null hypothesis, in that case, indicating that the alternative hypothesis is more likely.
Parametric and Non-Parametric Tests
Parametric tests assume the data follows a specific probability distribution, usually the normal distribution. Examples include the Student’s t-test.
Non-parametric tests do not require such assumptions and are helpful when dealing with data that do not meet the assumptions of parametric tests. Examples include the Mann-Whitney U test.

🎓 Master Data Analysis and Skyrocket Your Career
Find Out the Secrets in Our Ultimate Guide! 💼
Commonly Used Hypotheses Tests
Independent samples t-test: This analysis compares the means of two independent groups.
Paired samples t-test: Compares the means of two related groups (e.g., before and after treatment).
Chi-squared test: Determines if there is a significant association, in a contingency table, between two categorical variables.
Analysis of Variance (ANOVA): Compares the means of three or more independent groups to determine whether significant differences exist.
Pearson’s Correlation Coefficient (Pearson’s r): Quantifies the strength and direction of a linear association between two continuous variables.
Simple Linear Regression: Evaluate whether a significant linear relationship exists between a predictor variable (X) and a continuous outcome variable (y).
Logistic Regression: Determines the relationship between one or more predictor variables (continuous or categorical) and a binary outcome variable (e.g., success or failure).
Levene’s Test: Tests the equality of variances between two or more groups, often used as an assumption checks for ANOVA.
Shapiro-Wilk Test: Assesses the null hypothesis that a data sample is drawn from a population with a normal distribution.
| Hypothesis Test | Description | Application |
|---|---|---|
| Compares means of two independent groups | Comparing scores of two groups of students | |
| Compares means of two related groups (e.g., before and after treatment) | Comparing weight loss before and after a diet program | |
| Determines significant associations between two categorical variables in a contingency table | Analyzing the relationship between education and income | |
| Compares means of three or more independent groups | Evaluating the impact of different teaching methods on test scores | |
| Measures the strength and direction of a linear relationship between two continuous variables | Studying the correlation between height and weight | |
| Determines a significant linear relationship between a predictor variable and an outcome variable | Predicting sales based on advertising budget | |
| Determines the relationship between predictor variables and a binary outcome variable | Predicting the probability of loan default based on credit score | |
| Tests the equality of variances between two or more groups | Checking the assumption of equal variances for ANOVA | |
| Tests if a data sample is from a normally distributed population | Assessing normality assumption for parametric tests |
Interpreting the Results of Hypotheses Tests
To interpret the hypothesis test results, compare the p-value to the chosen significance level.
If the p-value falls below the significance level, reject the null hypothesis and infer that a notable effect or difference exists.
Otherwise, fail to reject the null hypothesis, meaning there is insufficient evidence to support the alternative hypothesis.
Other Relevant Information
In addition to understanding the basics of hypothesis tests, it’s crucial to consider other relevant information when interpreting the results.
For example, factors such as effect size, statistical power, and confidence intervals can provide valuable insights and help you make more informed decisions.
Effect size
The effect size represents a quantitative measurement of the strength or magnitude of the observed relationship or effect between variables. It aids in evaluating the practical significance of the results. A statistically significant outcome may not necessarily imply practical relevance. At the same time, a substantial effect size can suggest meaningful findings, even when statistical significance appears marginal.
Statistical power
The power of a test represents the likelihood of accurately rejecting the null hypothesis when it is incorrect. In other words, it’s the likelihood that the test will detect an effect when it exists. Factors affecting the power of a test include the sample size, effect size, and significance level. Enhanced power reduces the likelihood of making an error of Type II — failing to reject the null hypothesis when it ought to be rejected.
Confidence intervals
A confidence interval represents a range where the true population parameter is expected to be found with a specified confidence level (e.g., 95%). Confidence intervals provide additional context to hypothesis testing, helping to assess the estimate’s precision and offering a better understanding of the uncertainty surrounding the results.
By considering these additional aspects when interpreting the results of hypothesis tests, you can gain a more comprehensive understanding of the data and make more informed conclusions.
Hypothesis testing is an indispensable statistical tool for drawing meaningful inferences and making informed data-based decisions.
By comprehending the essential concepts such as null and alternative hypotheses, significance levels, p-values, and the distinction between parametric and non-parametric tests, you can proficiently apply hypothesis testing to a wide range of real-world situations.
Additionally, understanding the importance of effect sizes, statistical power, and confidence intervals will enhance your ability to interpret the results and make better decisions.
With many applications across various fields, including medicine, psychology, business, and environmental sciences, hypothesis testing is a versatile and valuable method for research and data analysis.
A comprehensive grasp of hypothesis testing techniques will enable professionals and researchers to strengthen their decision-making processes, optimize strategies, and deepen their understanding of the relationships between variables, leading to more impactful results and discoveries.
Refine your data analysis skills and present meaningful insights with confidence using our latest digital book!
Access FREE samples now and master advanced techniques in data analysis, including optimal sample size determination and effective communication of results.
Don’t miss the chance to immerse yourself in Applied Statistics: Data Analysis and unlock your full potential in data-driven decision making.
Click the link to start exploring!

Can Standard Deviations Be Negative?
Connect with us on our social networks.
DAILY POSTS ON INSTAGRAM!
Hypothesis Tests
Similar posts.

What is the Difference Between ANOVA and T-Test?
Learn the key differences between t-tests and ANOVA, when to use each, and avoid common errors. Explore more relevant articles on our blog.

Parametric vs. Nonparametric Tests: Choosing the Right Tool for Your Data
Explore the essence of Parametric vs. Nonparametric Tests to select the ideal statistical tool for your data analysis, enhancing accuracy.

Kruskal-Wallis Test: Mastering Non-Parametric Analysis for Multiple Groups
Unlock the potential of the Kruskal-Wallis Test for analyzing non-parametric data across multiple groups with precision and clarity.

Generalized Linear Model (GLM) Distribution and Link Function Selection Guide
Master the Generalized Linear Model Distribution and Link Function selection for enhanced statistical modeling and analysis.

Mastering One-Way ANOVA: A Comprehensive Guide for Beginners
Master One Way ANOVA with this guide, covering assumptions, effect sizes, post hoc tests, common mistakes, and best practices.

Standard Deviation Rules Misconceptions
Standard deviation rules are often misunderstood, leading to incorrect data analysis. Learn the truth about these rules and how to use them correctly with this guide.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Hypothesis Testing
Hypothesis testing is a tool for making statistical inferences about the population data. It is an analysis tool that tests assumptions and determines how likely something is within a given standard of accuracy. Hypothesis testing provides a way to verify whether the results of an experiment are valid.
A null hypothesis and an alternative hypothesis are set up before performing the hypothesis testing. This helps to arrive at a conclusion regarding the sample obtained from the population. In this article, we will learn more about hypothesis testing, its types, steps to perform the testing, and associated examples.
| 1. | |
| 2. | |
| 3. | |
| 4. | |
| 5. | |
| 6. | |
| 7. | |
| 8. |
What is Hypothesis Testing in Statistics?
Hypothesis testing uses sample data from the population to draw useful conclusions regarding the population probability distribution . It tests an assumption made about the data using different types of hypothesis testing methodologies. The hypothesis testing results in either rejecting or not rejecting the null hypothesis.
Hypothesis Testing Definition
Hypothesis testing can be defined as a statistical tool that is used to identify if the results of an experiment are meaningful or not. It involves setting up a null hypothesis and an alternative hypothesis. These two hypotheses will always be mutually exclusive. This means that if the null hypothesis is true then the alternative hypothesis is false and vice versa. An example of hypothesis testing is setting up a test to check if a new medicine works on a disease in a more efficient manner.
Null Hypothesis
The null hypothesis is a concise mathematical statement that is used to indicate that there is no difference between two possibilities. In other words, there is no difference between certain characteristics of data. This hypothesis assumes that the outcomes of an experiment are based on chance alone. It is denoted as \(H_{0}\). Hypothesis testing is used to conclude if the null hypothesis can be rejected or not. Suppose an experiment is conducted to check if girls are shorter than boys at the age of 5. The null hypothesis will say that they are the same height.
Alternative Hypothesis
The alternative hypothesis is an alternative to the null hypothesis. It is used to show that the observations of an experiment are due to some real effect. It indicates that there is a statistical significance between two possible outcomes and can be denoted as \(H_{1}\) or \(H_{a}\). For the above-mentioned example, the alternative hypothesis would be that girls are shorter than boys at the age of 5.
Hypothesis Testing P Value
In hypothesis testing, the p value is used to indicate whether the results obtained after conducting a test are statistically significant or not. It also indicates the probability of making an error in rejecting or not rejecting the null hypothesis.This value is always a number between 0 and 1. The p value is compared to an alpha level, \(\alpha\) or significance level. The alpha level can be defined as the acceptable risk of incorrectly rejecting the null hypothesis. The alpha level is usually chosen between 1% to 5%.
Hypothesis Testing Critical region
All sets of values that lead to rejecting the null hypothesis lie in the critical region. Furthermore, the value that separates the critical region from the non-critical region is known as the critical value.
Hypothesis Testing Formula
Depending upon the type of data available and the size, different types of hypothesis testing are used to determine whether the null hypothesis can be rejected or not. The hypothesis testing formula for some important test statistics are given below:
- z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\). \(\overline{x}\) is the sample mean, \(\mu\) is the population mean, \(\sigma\) is the population standard deviation and n is the size of the sample.
- t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\). s is the sample standard deviation.
- \(\chi ^{2} = \sum \frac{(O_{i}-E_{i})^{2}}{E_{i}}\). \(O_{i}\) is the observed value and \(E_{i}\) is the expected value.
We will learn more about these test statistics in the upcoming section.
Types of Hypothesis Testing
Selecting the correct test for performing hypothesis testing can be confusing. These tests are used to determine a test statistic on the basis of which the null hypothesis can either be rejected or not rejected. Some of the important tests used for hypothesis testing are given below.
Hypothesis Testing Z Test
A z test is a way of hypothesis testing that is used for a large sample size (n ≥ 30). It is used to determine whether there is a difference between the population mean and the sample mean when the population standard deviation is known. It can also be used to compare the mean of two samples. It is used to compute the z test statistic. The formulas are given as follows:
- One sample: z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\).
- Two samples: z = \(\frac{(\overline{x_{1}}-\overline{x_{2}})-(\mu_{1}-\mu_{2})}{\sqrt{\frac{\sigma_{1}^{2}}{n_{1}}+\frac{\sigma_{2}^{2}}{n_{2}}}}\).
Hypothesis Testing t Test
The t test is another method of hypothesis testing that is used for a small sample size (n < 30). It is also used to compare the sample mean and population mean. However, the population standard deviation is not known. Instead, the sample standard deviation is known. The mean of two samples can also be compared using the t test.
- One sample: t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\).
- Two samples: t = \(\frac{(\overline{x_{1}}-\overline{x_{2}})-(\mu_{1}-\mu_{2})}{\sqrt{\frac{s_{1}^{2}}{n_{1}}+\frac{s_{2}^{2}}{n_{2}}}}\).
Hypothesis Testing Chi Square
The Chi square test is a hypothesis testing method that is used to check whether the variables in a population are independent or not. It is used when the test statistic is chi-squared distributed.
One Tailed Hypothesis Testing
One tailed hypothesis testing is done when the rejection region is only in one direction. It can also be known as directional hypothesis testing because the effects can be tested in one direction only. This type of testing is further classified into the right tailed test and left tailed test.
Right Tailed Hypothesis Testing
The right tail test is also known as the upper tail test. This test is used to check whether the population parameter is greater than some value. The null and alternative hypotheses for this test are given as follows:
\(H_{0}\): The population parameter is ≤ some value
\(H_{1}\): The population parameter is > some value.
If the test statistic has a greater value than the critical value then the null hypothesis is rejected

Left Tailed Hypothesis Testing
The left tail test is also known as the lower tail test. It is used to check whether the population parameter is less than some value. The hypotheses for this hypothesis testing can be written as follows:
\(H_{0}\): The population parameter is ≥ some value
\(H_{1}\): The population parameter is < some value.
The null hypothesis is rejected if the test statistic has a value lesser than the critical value.

Two Tailed Hypothesis Testing
In this hypothesis testing method, the critical region lies on both sides of the sampling distribution. It is also known as a non - directional hypothesis testing method. The two-tailed test is used when it needs to be determined if the population parameter is assumed to be different than some value. The hypotheses can be set up as follows:
\(H_{0}\): the population parameter = some value
\(H_{1}\): the population parameter ≠ some value
The null hypothesis is rejected if the test statistic has a value that is not equal to the critical value.

Hypothesis Testing Steps
Hypothesis testing can be easily performed in five simple steps. The most important step is to correctly set up the hypotheses and identify the right method for hypothesis testing. The basic steps to perform hypothesis testing are as follows:
- Step 1: Set up the null hypothesis by correctly identifying whether it is the left-tailed, right-tailed, or two-tailed hypothesis testing.
- Step 2: Set up the alternative hypothesis.
- Step 3: Choose the correct significance level, \(\alpha\), and find the critical value.
- Step 4: Calculate the correct test statistic (z, t or \(\chi\)) and p-value.
- Step 5: Compare the test statistic with the critical value or compare the p-value with \(\alpha\) to arrive at a conclusion. In other words, decide if the null hypothesis is to be rejected or not.
Hypothesis Testing Example
The best way to solve a problem on hypothesis testing is by applying the 5 steps mentioned in the previous section. Suppose a researcher claims that the mean average weight of men is greater than 100kgs with a standard deviation of 15kgs. 30 men are chosen with an average weight of 112.5 Kgs. Using hypothesis testing, check if there is enough evidence to support the researcher's claim. The confidence interval is given as 95%.
Step 1: This is an example of a right-tailed test. Set up the null hypothesis as \(H_{0}\): \(\mu\) = 100.
Step 2: The alternative hypothesis is given by \(H_{1}\): \(\mu\) > 100.
Step 3: As this is a one-tailed test, \(\alpha\) = 100% - 95% = 5%. This can be used to determine the critical value.
1 - \(\alpha\) = 1 - 0.05 = 0.95
0.95 gives the required area under the curve. Now using a normal distribution table, the area 0.95 is at z = 1.645. A similar process can be followed for a t-test. The only additional requirement is to calculate the degrees of freedom given by n - 1.
Step 4: Calculate the z test statistic. This is because the sample size is 30. Furthermore, the sample and population means are known along with the standard deviation.
z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\).
\(\mu\) = 100, \(\overline{x}\) = 112.5, n = 30, \(\sigma\) = 15
z = \(\frac{112.5-100}{\frac{15}{\sqrt{30}}}\) = 4.56
Step 5: Conclusion. As 4.56 > 1.645 thus, the null hypothesis can be rejected.
Hypothesis Testing and Confidence Intervals
Confidence intervals form an important part of hypothesis testing. This is because the alpha level can be determined from a given confidence interval. Suppose a confidence interval is given as 95%. Subtract the confidence interval from 100%. This gives 100 - 95 = 5% or 0.05. This is the alpha value of a one-tailed hypothesis testing. To obtain the alpha value for a two-tailed hypothesis testing, divide this value by 2. This gives 0.05 / 2 = 0.025.
Related Articles:
- Probability and Statistics
- Data Handling
Important Notes on Hypothesis Testing
- Hypothesis testing is a technique that is used to verify whether the results of an experiment are statistically significant.
- It involves the setting up of a null hypothesis and an alternate hypothesis.
- There are three types of tests that can be conducted under hypothesis testing - z test, t test, and chi square test.
- Hypothesis testing can be classified as right tail, left tail, and two tail tests.
Examples on Hypothesis Testing
- Example 1: The average weight of a dumbbell in a gym is 90lbs. However, a physical trainer believes that the average weight might be higher. A random sample of 5 dumbbells with an average weight of 110lbs and a standard deviation of 18lbs. Using hypothesis testing check if the physical trainer's claim can be supported for a 95% confidence level. Solution: As the sample size is lesser than 30, the t-test is used. \(H_{0}\): \(\mu\) = 90, \(H_{1}\): \(\mu\) > 90 \(\overline{x}\) = 110, \(\mu\) = 90, n = 5, s = 18. \(\alpha\) = 0.05 Using the t-distribution table, the critical value is 2.132 t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\) t = 2.484 As 2.484 > 2.132, the null hypothesis is rejected. Answer: The average weight of the dumbbells may be greater than 90lbs
- Example 2: The average score on a test is 80 with a standard deviation of 10. With a new teaching curriculum introduced it is believed that this score will change. On random testing, the score of 38 students, the mean was found to be 88. With a 0.05 significance level, is there any evidence to support this claim? Solution: This is an example of two-tail hypothesis testing. The z test will be used. \(H_{0}\): \(\mu\) = 80, \(H_{1}\): \(\mu\) ≠ 80 \(\overline{x}\) = 88, \(\mu\) = 80, n = 36, \(\sigma\) = 10. \(\alpha\) = 0.05 / 2 = 0.025 The critical value using the normal distribution table is 1.96 z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\) z = \(\frac{88-80}{\frac{10}{\sqrt{36}}}\) = 4.8 As 4.8 > 1.96, the null hypothesis is rejected. Answer: There is a difference in the scores after the new curriculum was introduced.
- Example 3: The average score of a class is 90. However, a teacher believes that the average score might be lower. The scores of 6 students were randomly measured. The mean was 82 with a standard deviation of 18. With a 0.05 significance level use hypothesis testing to check if this claim is true. Solution: The t test will be used. \(H_{0}\): \(\mu\) = 90, \(H_{1}\): \(\mu\) < 90 \(\overline{x}\) = 110, \(\mu\) = 90, n = 6, s = 18 The critical value from the t table is -2.015 t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\) t = \(\frac{82-90}{\frac{18}{\sqrt{6}}}\) t = -1.088 As -1.088 > -2.015, we fail to reject the null hypothesis. Answer: There is not enough evidence to support the claim.
go to slide go to slide go to slide

Book a Free Trial Class
FAQs on Hypothesis Testing
What is hypothesis testing.
Hypothesis testing in statistics is a tool that is used to make inferences about the population data. It is also used to check if the results of an experiment are valid.
What is the z Test in Hypothesis Testing?
The z test in hypothesis testing is used to find the z test statistic for normally distributed data . The z test is used when the standard deviation of the population is known and the sample size is greater than or equal to 30.
What is the t Test in Hypothesis Testing?
The t test in hypothesis testing is used when the data follows a student t distribution . It is used when the sample size is less than 30 and standard deviation of the population is not known.
What is the formula for z test in Hypothesis Testing?
The formula for a one sample z test in hypothesis testing is z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\) and for two samples is z = \(\frac{(\overline{x_{1}}-\overline{x_{2}})-(\mu_{1}-\mu_{2})}{\sqrt{\frac{\sigma_{1}^{2}}{n_{1}}+\frac{\sigma_{2}^{2}}{n_{2}}}}\).
What is the p Value in Hypothesis Testing?
The p value helps to determine if the test results are statistically significant or not. In hypothesis testing, the null hypothesis can either be rejected or not rejected based on the comparison between the p value and the alpha level.
What is One Tail Hypothesis Testing?
When the rejection region is only on one side of the distribution curve then it is known as one tail hypothesis testing. The right tail test and the left tail test are two types of directional hypothesis testing.
What is the Alpha Level in Two Tail Hypothesis Testing?
To get the alpha level in a two tail hypothesis testing divide \(\alpha\) by 2. This is done as there are two rejection regions in the curve.
Hypothesis Testing
About hypothesis testing.
Watch the video for a brief overview of hypothesis testing:

Can’t see the video? Click here to watch it on YouTube.
Contents (Click to skip to the section):
What is a Hypothesis?
What is hypothesis testing.
- Hypothesis Testing Examples (One Sample Z Test).
- Hypothesis Test on a Mean (TI 83).
Bayesian Hypothesis Testing.
- More Hypothesis Testing Articles
- Hypothesis Tests in One Picture
- Critical Values
What is the Null Hypothesis?
Need help with a homework problem? Check out our tutoring page!

A hypothesis is an educated guess about something in the world around you. It should be testable, either by experiment or observation. For example:
- A new medicine you think might work.
- A way of teaching you think might be better.
- A possible location of new species.
- A fairer way to administer standardized tests.
It can really be anything at all as long as you can put it to the test.
What is a Hypothesis Statement?
If you are going to propose a hypothesis, it’s customary to write a statement. Your statement will look like this: “If I…(do this to an independent variable )….then (this will happen to the dependent variable ).” For example:
- If I (decrease the amount of water given to herbs) then (the herbs will increase in size).
- If I (give patients counseling in addition to medication) then (their overall depression scale will decrease).
- If I (give exams at noon instead of 7) then (student test scores will improve).
- If I (look in this certain location) then (I am more likely to find new species).
A good hypothesis statement should:
- Include an “if” and “then” statement (according to the University of California).
- Include both the independent and dependent variables.
- Be testable by experiment, survey or other scientifically sound technique.
- Be based on information in prior research (either yours or someone else’s).
- Have design criteria (for engineering or programming projects).
Hypothesis testing can be one of the most confusing aspects for students, mostly because before you can even perform a test, you have to know what your null hypothesis is. Often, those tricky word problems that you are faced with can be difficult to decipher. But it’s easier than you think; all you need to do is:
- Figure out your null hypothesis,
- State your null hypothesis,
- Choose what kind of test you need to perform,
- Either support or reject the null hypothesis .
If you trace back the history of science, the null hypothesis is always the accepted fact. Simple examples of null hypotheses that are generally accepted as being true are:
- DNA is shaped like a double helix.
- There are 8 planets in the solar system (excluding Pluto).
- Taking Vioxx can increase your risk of heart problems (a drug now taken off the market).
How do I State the Null Hypothesis?
You won’t be required to actually perform a real experiment or survey in elementary statistics (or even disprove a fact like “Pluto is a planet”!), so you’ll be given word problems from real-life situations. You’ll need to figure out what your hypothesis is from the problem. This can be a little trickier than just figuring out what the accepted fact is. With word problems, you are looking to find a fact that is nullifiable (i.e. something you can reject).
Hypothesis Testing Examples #1: Basic Example
A researcher thinks that if knee surgery patients go to physical therapy twice a week (instead of 3 times), their recovery period will be longer. Average recovery times for knee surgery patients is 8.2 weeks.
The hypothesis statement in this question is that the researcher believes the average recovery time is more than 8.2 weeks. It can be written in mathematical terms as: H 1 : μ > 8.2
Next, you’ll need to state the null hypothesis . That’s what will happen if the researcher is wrong . In the above example, if the researcher is wrong then the recovery time is less than or equal to 8.2 weeks. In math, that’s: H 0 μ ≤ 8.2
Rejecting the null hypothesis
Ten or so years ago, we believed that there were 9 planets in the solar system. Pluto was demoted as a planet in 2006. The null hypothesis of “Pluto is a planet” was replaced by “Pluto is not a planet.” Of course, rejecting the null hypothesis isn’t always that easy— the hard part is usually figuring out what your null hypothesis is in the first place.
Hypothesis Testing Examples (One Sample Z Test)
The one sample z test isn’t used very often (because we rarely know the actual population standard deviation ). However, it’s a good idea to understand how it works as it’s one of the simplest tests you can perform in hypothesis testing. In English class you got to learn the basics (like grammar and spelling) before you could write a story; think of one sample z tests as the foundation for understanding more complex hypothesis testing. This page contains two hypothesis testing examples for one sample z-tests .
One Sample Hypothesis Testing Example: One Tailed Z Test
Watch the video for an example:

A principal at a certain school claims that the students in his school are above average intelligence. A random sample of thirty students IQ scores have a mean score of 112.5. Is there sufficient evidence to support the principal’s claim? The mean population IQ is 100 with a standard deviation of 15.
Step 1: State the Null hypothesis . The accepted fact is that the population mean is 100, so: H 0 : μ = 100.
Step 2: State the Alternate Hypothesis . The claim is that the students have above average IQ scores, so: H 1 : μ > 100. The fact that we are looking for scores “greater than” a certain point means that this is a one-tailed test.

Step 4: State the alpha level . If you aren’t given an alpha level , use 5% (0.05).
Step 5: Find the rejection region area (given by your alpha level above) from the z-table . An area of .05 is equal to a z-score of 1.645.

Step 6: If Step 6 is greater than Step 5, reject the null hypothesis. If it’s less than Step 5, you cannot reject the null hypothesis. In this case, it is more (4.56 > 1.645), so you can reject the null.
One Sample Hypothesis Testing Examples: #3
Watch the video for an example of a two-tailed z-test:
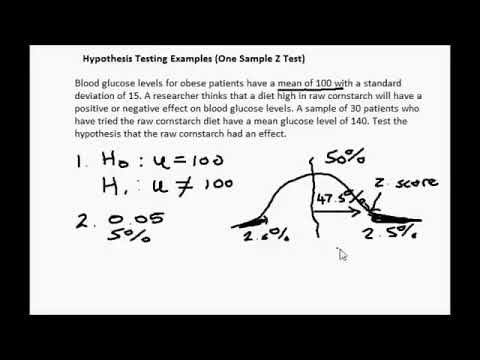
Blood glucose levels for obese patients have a mean of 100 with a standard deviation of 15. A researcher thinks that a diet high in raw cornstarch will have a positive or negative effect on blood glucose levels. A sample of 30 patients who have tried the raw cornstarch diet have a mean glucose level of 140. Test the hypothesis that the raw cornstarch had an effect.
- State the null hypothesis : H 0 :μ=100
- State the alternate hypothesis : H 1 :≠100
- State your alpha level. We’ll use 0.05 for this example. As this is a two-tailed test, split the alpha into two. 0.05/2=0.025
- Find the z-score associated with your alpha level . You’re looking for the area in one tail only . A z-score for 0.75(1-0.025=0.975) is 1.96. As this is a two-tailed test, you would also be considering the left tail (z = 1.96)
- If Step 5 is less than -1.96 or greater than 1.96 (Step 3), reject the null hypothesis . In this case, it is greater, so you can reject the null.
*This process is made much easier if you use a TI-83 or Excel to calculate the z-score (the “critical value”). See:
- Critical z value TI 83
- Z Score in Excel
Hypothesis Testing Examples: Mean (Using TI 83)
You can use the TI 83 calculator for hypothesis testing, but the calculator won’t figure out the null and alternate hypotheses; that’s up to you to read the question and input it into the calculator.
Example problem : A sample of 200 people has a mean age of 21 with a population standard deviation (σ) of 5. Test the hypothesis that the population mean is 18.9 at α = 0.05.
Step 1: State the null hypothesis. In this case, the null hypothesis is that the population mean is 18.9, so we write: H 0 : μ = 18.9
Step 2: State the alternative hypothesis. We want to know if our sample, which has a mean of 21 instead of 18.9, really is different from the population, therefore our alternate hypothesis: H 1 : μ ≠ 18.9
Step 3: Press Stat then press the right arrow twice to select TESTS.
Step 4: Press 1 to select 1:Z-Test… . Press ENTER.
Step 5: Use the right arrow to select Stats .
Step 6: Enter the data from the problem: μ 0 : 18.9 σ: 5 x : 21 n: 200 μ: ≠μ 0
Step 7: Arrow down to Calculate and press ENTER. The calculator shows the p-value: p = 2.87 × 10 -9
This is smaller than our alpha value of .05. That means we should reject the null hypothesis .
Bayesian Hypothesis Testing: What is it?

Bayesian hypothesis testing helps to answer the question: Can the results from a test or survey be repeated? Why do we care if a test can be repeated? Let’s say twenty people in the same village came down with leukemia. A group of researchers find that cell-phone towers are to blame. However, a second study found that cell-phone towers had nothing to do with the cancer cluster in the village. In fact, they found that the cancers were completely random. If that sounds impossible, it actually can happen! Clusters of cancer can happen simply by chance . There could be many reasons why the first study was faulty. One of the main reasons could be that they just didn’t take into account that sometimes things happen randomly and we just don’t know why.
It’s good science to let people know if your study results are solid, or if they could have happened by chance. The usual way of doing this is to test your results with a p-value . A p value is a number that you get by running a hypothesis test on your data. A P value of 0.05 (5%) or less is usually enough to claim that your results are repeatable. However, there’s another way to test the validity of your results: Bayesian Hypothesis testing. This type of testing gives you another way to test the strength of your results.
Traditional testing (the type you probably came across in elementary stats or AP stats) is called Non-Bayesian. It is how often an outcome happens over repeated runs of the experiment. It’s an objective view of whether an experiment is repeatable. Bayesian hypothesis testing is a subjective view of the same thing. It takes into account how much faith you have in your results. In other words, would you wager money on the outcome of your experiment?
Differences Between Traditional and Bayesian Hypothesis Testing.
Traditional testing (Non Bayesian) requires you to repeat sampling over and over, while Bayesian testing does not. The main different between the two is in the first step of testing: stating a probability model. In Bayesian testing you add prior knowledge to this step. It also requires use of a posterior probability , which is the conditional probability given to a random event after all the evidence is considered.
Arguments for Bayesian Testing.
Many researchers think that it is a better alternative to traditional testing, because it:
- Includes prior knowledge about the data.
- Takes into account personal beliefs about the results.
Arguments against.
- Including prior data or knowledge isn’t justifiable.
- It is difficult to calculate compared to non-Bayesian testing.
Back to top
Hypothesis Testing Articles
- What is Ad Hoc Testing?
- Composite Hypothesis Test
- What is a Rejection Region?
- What is a Two Tailed Test?
- How to Decide if a Hypothesis Test is a One Tailed Test or a Two Tailed Test.
- How to Decide if a Hypothesis is a Left Tailed Test or a Right-Tailed Test.
- How to State the Null Hypothesis in Statistics.
- How to Find a Critical Value .
- How to Support or Reject a Null Hypothesis.
Specific Tests:
- Brunner Munzel Test (Generalized Wilcoxon Test).
- Chi Square Test for Normality.
- Cochran-Mantel-Haenszel Test.
- Granger Causality Test .
- Hotelling’s T-Squared.
- KPSS Test .
- What is a Likelihood-Ratio Test?
- Log rank test .
- MANCOVA Assumptions.
- MANCOVA Sample Size.
- Marascuilo Procedure
- Rao’s Spacing Test
- Rayleigh test of uniformity.
- Sequential Probability Ratio Test.
- How to Run a Sign Test.
- T Test: one sample.
- T-Test: Two sample .
- Welch’s ANOVA .
- Welch’s Test for Unequal Variances .
- Z-Test: one sample .
- Z Test: Two Proportion.
- Wald Test .
Related Articles:
- What is an Acceptance Region?
- How to Calculate Chebyshev’s Theorem.
- Contrast Analysis
- Decision Rule.
- Degrees of Freedom .
- Directional Test
- False Discovery Rate
- How to calculate the Least Significant Difference.
- Levels in Statistics.
- How to Calculate Margin of Error.
- Mean Difference (Difference in Means)
- The Multiple Testing Problem .
- What is the Neyman-Pearson Lemma?
- What is an Omnibus Test?
- One Sample Median Test .
- How to Find a Sample Size (General Instructions).
- Sig 2(Tailed) meaning in results
- What is a Standardized Test Statistic?
- How to Find Standard Error
- Standardized values: Example.
- How to Calculate a T-Score.
- T-Score Vs. a Z.Score.
- Testing a Single Mean.
- Unequal Sample Sizes.
- Uniformly Most Powerful Tests.
- How to Calculate a Z-Score.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Indian J Crit Care Med
- v.23(Suppl 3); 2019 Sep
An Introduction to Statistics: Understanding Hypothesis Testing and Statistical Errors
Priya ranganathan.
1 Department of Anesthesiology, Critical Care and Pain, Tata Memorial Hospital, Mumbai, Maharashtra, India
2 Department of Surgical Oncology, Tata Memorial Centre, Mumbai, Maharashtra, India
The second article in this series on biostatistics covers the concepts of sample, population, research hypotheses and statistical errors.
How to cite this article
Ranganathan P, Pramesh CS. An Introduction to Statistics: Understanding Hypothesis Testing and Statistical Errors. Indian J Crit Care Med 2019;23(Suppl 3):S230–S231.
Two papers quoted in this issue of the Indian Journal of Critical Care Medicine report. The results of studies aim to prove that a new intervention is better than (superior to) an existing treatment. In the ABLE study, the investigators wanted to show that transfusion of fresh red blood cells would be superior to standard-issue red cells in reducing 90-day mortality in ICU patients. 1 The PROPPR study was designed to prove that transfusion of a lower ratio of plasma and platelets to red cells would be superior to a higher ratio in decreasing 24-hour and 30-day mortality in critically ill patients. 2 These studies are known as superiority studies (as opposed to noninferiority or equivalence studies which will be discussed in a subsequent article).
SAMPLE VERSUS POPULATION
A sample represents a group of participants selected from the entire population. Since studies cannot be carried out on entire populations, researchers choose samples, which are representative of the population. This is similar to walking into a grocery store and examining a few grains of rice or wheat before purchasing an entire bag; we assume that the few grains that we select (the sample) are representative of the entire sack of grains (the population).
The results of the study are then extrapolated to generate inferences about the population. We do this using a process known as hypothesis testing. This means that the results of the study may not always be identical to the results we would expect to find in the population; i.e., there is the possibility that the study results may be erroneous.
HYPOTHESIS TESTING
A clinical trial begins with an assumption or belief, and then proceeds to either prove or disprove this assumption. In statistical terms, this belief or assumption is known as a hypothesis. Counterintuitively, what the researcher believes in (or is trying to prove) is called the “alternate” hypothesis, and the opposite is called the “null” hypothesis; every study has a null hypothesis and an alternate hypothesis. For superiority studies, the alternate hypothesis states that one treatment (usually the new or experimental treatment) is superior to the other; the null hypothesis states that there is no difference between the treatments (the treatments are equal). For example, in the ABLE study, we start by stating the null hypothesis—there is no difference in mortality between groups receiving fresh RBCs and standard-issue RBCs. We then state the alternate hypothesis—There is a difference between groups receiving fresh RBCs and standard-issue RBCs. It is important to note that we have stated that the groups are different, without specifying which group will be better than the other. This is known as a two-tailed hypothesis and it allows us to test for superiority on either side (using a two-sided test). This is because, when we start a study, we are not 100% certain that the new treatment can only be better than the standard treatment—it could be worse, and if it is so, the study should pick it up as well. One tailed hypothesis and one-sided statistical testing is done for non-inferiority studies, which will be discussed in a subsequent paper in this series.
STATISTICAL ERRORS
There are two possibilities to consider when interpreting the results of a superiority study. The first possibility is that there is truly no difference between the treatments but the study finds that they are different. This is called a Type-1 error or false-positive error or alpha error. This means falsely rejecting the null hypothesis.
The second possibility is that there is a difference between the treatments and the study does not pick up this difference. This is called a Type 2 error or false-negative error or beta error. This means falsely accepting the null hypothesis.
The power of the study is the ability to detect a difference between groups and is the converse of the beta error; i.e., power = 1-beta error. Alpha and beta errors are finalized when the protocol is written and form the basis for sample size calculation for the study. In an ideal world, we would not like any error in the results of our study; however, we would need to do the study in the entire population (infinite sample size) to be able to get a 0% alpha and beta error. These two errors enable us to do studies with realistic sample sizes, with the compromise that there is a small possibility that the results may not always reflect the truth. The basis for this will be discussed in a subsequent paper in this series dealing with sample size calculation.
Conventionally, type 1 or alpha error is set at 5%. This means, that at the end of the study, if there is a difference between groups, we want to be 95% certain that this is a true difference and allow only a 5% probability that this difference has occurred by chance (false positive). Type 2 or beta error is usually set between 10% and 20%; therefore, the power of the study is 90% or 80%. This means that if there is a difference between groups, we want to be 80% (or 90%) certain that the study will detect that difference. For example, in the ABLE study, sample size was calculated with a type 1 error of 5% (two-sided) and power of 90% (type 2 error of 10%) (1).
Table 1 gives a summary of the two types of statistical errors with an example
Statistical errors
| (a) Types of statistical errors | |||
| : Null hypothesis is | |||
| True | False | ||
| Null hypothesis is actually | True | Correct results! | Falsely rejecting null hypothesis - Type I error |
| False | Falsely accepting null hypothesis - Type II error | Correct results! | |
| (b) Possible statistical errors in the ABLE trial | |||
| There is difference in mortality between groups receiving fresh RBCs and standard-issue RBCs | There difference in mortality between groups receiving fresh RBCs and standard-issue RBCs | ||
| Truth | There is difference in mortality between groups receiving fresh RBCs and standard-issue RBCs | Correct results! | Falsely rejecting null hypothesis - Type I error |
| There difference in mortality between groups receiving fresh RBCs and standard-issue RBCs | Falsely accepting null hypothesis - Type II error | Correct results! | |
In the next article in this series, we will look at the meaning and interpretation of ‘ p ’ value and confidence intervals for hypothesis testing.
Source of support: Nil
Conflict of interest: None

User Preferences
Content preview.
Arcu felis bibendum ut tristique et egestas quis:
- Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris
- Duis aute irure dolor in reprehenderit in voluptate
- Excepteur sint occaecat cupidatat non proident
Keyboard Shortcuts
6a.2 - steps for hypothesis tests, the logic of hypothesis testing section .
A hypothesis, in statistics, is a statement about a population parameter, where this statement typically is represented by some specific numerical value. In testing a hypothesis, we use a method where we gather data in an effort to gather evidence about the hypothesis.
How do we decide whether to reject the null hypothesis?
- If the sample data are consistent with the null hypothesis, then we do not reject it.
- If the sample data are inconsistent with the null hypothesis, but consistent with the alternative, then we reject the null hypothesis and conclude that the alternative hypothesis is true.
Six Steps for Hypothesis Tests Section
In hypothesis testing, there are certain steps one must follow. Below these are summarized into six such steps to conducting a test of a hypothesis.
- Set up the hypotheses and check conditions : Each hypothesis test includes two hypotheses about the population. One is the null hypothesis, notated as \(H_0 \), which is a statement of a particular parameter value. This hypothesis is assumed to be true until there is evidence to suggest otherwise. The second hypothesis is called the alternative, or research hypothesis, notated as \(H_a \). The alternative hypothesis is a statement of a range of alternative values in which the parameter may fall. One must also check that any conditions (assumptions) needed to run the test have been satisfied e.g. normality of data, independence, and number of success and failure outcomes.
- Decide on the significance level, \(\alpha \): This value is used as a probability cutoff for making decisions about the null hypothesis. This alpha value represents the probability we are willing to place on our test for making an incorrect decision in regards to rejecting the null hypothesis. The most common \(\alpha \) value is 0.05 or 5%. Other popular choices are 0.01 (1%) and 0.1 (10%).
- Calculate the test statistic: Gather sample data and calculate a test statistic where the sample statistic is compared to the parameter value. The test statistic is calculated under the assumption the null hypothesis is true and incorporates a measure of standard error and assumptions (conditions) related to the sampling distribution.
- Calculate probability value (p-value), or find the rejection region: A p-value is found by using the test statistic to calculate the probability of the sample data producing such a test statistic or one more extreme. The rejection region is found by using alpha to find a critical value; the rejection region is the area that is more extreme than the critical value. We discuss the p-value and rejection region in more detail in the next section.
- Make a decision about the null hypothesis: In this step, we decide to either reject the null hypothesis or decide to fail to reject the null hypothesis. Notice we do not make a decision where we will accept the null hypothesis.
- State an overall conclusion : Once we have found the p-value or rejection region, and made a statistical decision about the null hypothesis (i.e. we will reject the null or fail to reject the null), we then want to summarize our results into an overall conclusion for our test.
We will follow these six steps for the remainder of this Lesson. In the future Lessons, the steps will be followed but may not be explained explicitly.
Step 1 is a very important step to set up correctly. If your hypotheses are incorrect, your conclusion will be incorrect. In this next section, we practice with Step 1 for the one sample situations.
- Search Search Please fill out this field.
What Is Hypothesis Testing?
- How It Works
4 Step Process
The bottom line.
- Fundamental Analysis
Hypothesis Testing: 4 Steps and Example
:max_bytes(150000):strip_icc():format(webp)/ChristinaMajaski-5c9433ea46e0fb0001d880b1.jpeg "hypothesis in basic statistics")
Hypothesis testing, sometimes called significance testing, is an act in statistics whereby an analyst tests an assumption regarding a population parameter. The methodology employed by the analyst depends on the nature of the data used and the reason for the analysis.
Hypothesis testing is used to assess the plausibility of a hypothesis by using sample data. Such data may come from a larger population or a data-generating process. The word "population" will be used for both of these cases in the following descriptions.
Key Takeaways
- Hypothesis testing is used to assess the plausibility of a hypothesis by using sample data.
- The test provides evidence concerning the plausibility of the hypothesis, given the data.
- Statistical analysts test a hypothesis by measuring and examining a random sample of the population being analyzed.
- The four steps of hypothesis testing include stating the hypotheses, formulating an analysis plan, analyzing the sample data, and analyzing the result.
How Hypothesis Testing Works
In hypothesis testing, an analyst tests a statistical sample, intending to provide evidence on the plausibility of the null hypothesis. Statistical analysts measure and examine a random sample of the population being analyzed. All analysts use a random population sample to test two different hypotheses: the null hypothesis and the alternative hypothesis.
The null hypothesis is usually a hypothesis of equality between population parameters; e.g., a null hypothesis may state that the population mean return is equal to zero. The alternative hypothesis is effectively the opposite of a null hypothesis. Thus, they are mutually exclusive , and only one can be true. However, one of the two hypotheses will always be true.
The null hypothesis is a statement about a population parameter, such as the population mean, that is assumed to be true.
- State the hypotheses.
- Formulate an analysis plan, which outlines how the data will be evaluated.
- Carry out the plan and analyze the sample data.
- Analyze the results and either reject the null hypothesis, or state that the null hypothesis is plausible, given the data.
Example of Hypothesis Testing
If an individual wants to test that a penny has exactly a 50% chance of landing on heads, the null hypothesis would be that 50% is correct, and the alternative hypothesis would be that 50% is not correct. Mathematically, the null hypothesis is represented as Ho: P = 0.5. The alternative hypothesis is shown as "Ha" and is identical to the null hypothesis, except with the equal sign struck-through, meaning that it does not equal 50%.
A random sample of 100 coin flips is taken, and the null hypothesis is tested. If it is found that the 100 coin flips were distributed as 40 heads and 60 tails, the analyst would assume that a penny does not have a 50% chance of landing on heads and would reject the null hypothesis and accept the alternative hypothesis.
If there were 48 heads and 52 tails, then it is plausible that the coin could be fair and still produce such a result. In cases such as this where the null hypothesis is "accepted," the analyst states that the difference between the expected results (50 heads and 50 tails) and the observed results (48 heads and 52 tails) is "explainable by chance alone."
When Did Hypothesis Testing Begin?
Some statisticians attribute the first hypothesis tests to satirical writer John Arbuthnot in 1710, who studied male and female births in England after observing that in nearly every year, male births exceeded female births by a slight proportion. Arbuthnot calculated that the probability of this happening by chance was small, and therefore it was due to “divine providence.”
What are the Benefits of Hypothesis Testing?
Hypothesis testing helps assess the accuracy of new ideas or theories by testing them against data. This allows researchers to determine whether the evidence supports their hypothesis, helping to avoid false claims and conclusions. Hypothesis testing also provides a framework for decision-making based on data rather than personal opinions or biases. By relying on statistical analysis, hypothesis testing helps to reduce the effects of chance and confounding variables, providing a robust framework for making informed conclusions.
What are the Limitations of Hypothesis Testing?
Hypothesis testing relies exclusively on data and doesn’t provide a comprehensive understanding of the subject being studied. Additionally, the accuracy of the results depends on the quality of the available data and the statistical methods used. Inaccurate data or inappropriate hypothesis formulation may lead to incorrect conclusions or failed tests. Hypothesis testing can also lead to errors, such as analysts either accepting or rejecting a null hypothesis when they shouldn’t have. These errors may result in false conclusions or missed opportunities to identify significant patterns or relationships in the data.
Hypothesis testing refers to a statistical process that helps researchers determine the reliability of a study. By using a well-formulated hypothesis and set of statistical tests, individuals or businesses can make inferences about the population that they are studying and draw conclusions based on the data presented. All hypothesis testing methods have the same four-step process, which includes stating the hypotheses, formulating an analysis plan, analyzing the sample data, and analyzing the result.
Sage. " Introduction to Hypothesis Testing ," Page 4.
Elder Research. " Who Invented the Null Hypothesis? "
Formplus. " Hypothesis Testing: Definition, Uses, Limitations and Examples ."
:max_bytes(150000):strip_icc():format(webp)/null_hypothesis-finalE-56a4132b022f49f0a3d469c6882ddd99.jpg "hypothesis in basic statistics")
- Terms of Service
- Editorial Policy
- Privacy Policy
- Data Science
- Data Analysis
- Data Visualization
- Machine Learning
- Deep Learning
- Computer Vision
- Artificial Intelligence
- AI ML DS Interview Series
- AI ML DS Projects series
- Data Engineering
- Web Scrapping
Understanding Hypothesis Testing
Hypothesis testing involves formulating assumptions about population parameters based on sample statistics and rigorously evaluating these assumptions against empirical evidence. This article sheds light on the significance of hypothesis testing and the critical steps involved in the process.
What is Hypothesis Testing?
A hypothesis is an assumption or idea, specifically a statistical claim about an unknown population parameter. For example, a judge assumes a person is innocent and verifies this by reviewing evidence and hearing testimony before reaching a verdict.
Hypothesis testing is a statistical method that is used to make a statistical decision using experimental data. Hypothesis testing is basically an assumption that we make about a population parameter. It evaluates two mutually exclusive statements about a population to determine which statement is best supported by the sample data.
To test the validity of the claim or assumption about the population parameter:
- A sample is drawn from the population and analyzed.
- The results of the analysis are used to decide whether the claim is true or not.
Example: You say an average height in the class is 30 or a boy is taller than a girl. All of these is an assumption that we are assuming, and we need some statistical way to prove these. We need some mathematical conclusion whatever we are assuming is true.
Defining Hypotheses
- Null hypothesis (H 0 ): In statistics, the null hypothesis is a general statement or default position that there is no relationship between two measured cases or no relationship among groups. In other words, it is a basic assumption or made based on the problem knowledge. Example : A company’s mean production is 50 units/per da H 0 : [Tex]\mu [/Tex] = 50.
- Alternative hypothesis (H 1 ): The alternative hypothesis is the hypothesis used in hypothesis testing that is contrary to the null hypothesis. Example: A company’s production is not equal to 50 units/per day i.e. H 1 : [Tex]\mu [/Tex] [Tex]\ne [/Tex] 50.
Key Terms of Hypothesis Testing
- Level of significance : It refers to the degree of significance in which we accept or reject the null hypothesis. 100% accuracy is not possible for accepting a hypothesis, so we, therefore, select a level of significance that is usually 5%. This is normally denoted with [Tex]\alpha[/Tex] and generally, it is 0.05 or 5%, which means your output should be 95% confident to give a similar kind of result in each sample.
- P-value: The P value , or calculated probability, is the probability of finding the observed/extreme results when the null hypothesis(H0) of a study-given problem is true. If your P-value is less than the chosen significance level then you reject the null hypothesis i.e. accept that your sample claims to support the alternative hypothesis.
- Test Statistic: The test statistic is a numerical value calculated from sample data during a hypothesis test, used to determine whether to reject the null hypothesis. It is compared to a critical value or p-value to make decisions about the statistical significance of the observed results.
- Critical value : The critical value in statistics is a threshold or cutoff point used to determine whether to reject the null hypothesis in a hypothesis test.
- Degrees of freedom: Degrees of freedom are associated with the variability or freedom one has in estimating a parameter. The degrees of freedom are related to the sample size and determine the shape.
Why do we use Hypothesis Testing?
Hypothesis testing is an important procedure in statistics. Hypothesis testing evaluates two mutually exclusive population statements to determine which statement is most supported by sample data. When we say that the findings are statistically significant, thanks to hypothesis testing.
One-Tailed and Two-Tailed Test
One tailed test focuses on one direction, either greater than or less than a specified value. We use a one-tailed test when there is a clear directional expectation based on prior knowledge or theory. The critical region is located on only one side of the distribution curve. If the sample falls into this critical region, the null hypothesis is rejected in favor of the alternative hypothesis.
One-Tailed Test
There are two types of one-tailed test:
- Left-Tailed (Left-Sided) Test: The alternative hypothesis asserts that the true parameter value is less than the null hypothesis. Example: H 0 : [Tex]\mu \geq 50 [/Tex] and H 1 : [Tex]\mu < 50 [/Tex]
- Right-Tailed (Right-Sided) Test : The alternative hypothesis asserts that the true parameter value is greater than the null hypothesis. Example: H 0 : [Tex]\mu \leq50 [/Tex] and H 1 : [Tex]\mu > 50 [/Tex]
Two-Tailed Test
A two-tailed test considers both directions, greater than and less than a specified value.We use a two-tailed test when there is no specific directional expectation, and want to detect any significant difference.
Example: H 0 : [Tex]\mu = [/Tex] 50 and H 1 : [Tex]\mu \neq 50 [/Tex]
To delve deeper into differences into both types of test: Refer to link
What are Type 1 and Type 2 errors in Hypothesis Testing?
In hypothesis testing, Type I and Type II errors are two possible errors that researchers can make when drawing conclusions about a population based on a sample of data. These errors are associated with the decisions made regarding the null hypothesis and the alternative hypothesis.
- Type I error: When we reject the null hypothesis, although that hypothesis was true. Type I error is denoted by alpha( [Tex]\alpha [/Tex] ).
- Type II errors : When we accept the null hypothesis, but it is false. Type II errors are denoted by beta( [Tex]\beta [/Tex] ).
Null Hypothesis is True | Null Hypothesis is False | |
|---|---|---|
Null Hypothesis is True (Accept) | Correct Decision | Type II Error (False Negative) |
Alternative Hypothesis is True (Reject) | Type I Error (False Positive) | Correct Decision |
How does Hypothesis Testing work?
Step 1: define null and alternative hypothesis.
State the null hypothesis ( [Tex]H_0 [/Tex] ), representing no effect, and the alternative hypothesis ( [Tex]H_1 [/Tex] ), suggesting an effect or difference.
We first identify the problem about which we want to make an assumption keeping in mind that our assumption should be contradictory to one another, assuming Normally distributed data.
Step 2 – Choose significance level
Select a significance level ( [Tex]\alpha [/Tex] ), typically 0.05, to determine the threshold for rejecting the null hypothesis. It provides validity to our hypothesis test, ensuring that we have sufficient data to back up our claims. Usually, we determine our significance level beforehand of the test. The p-value is the criterion used to calculate our significance value.
Step 3 – Collect and Analyze data.
Gather relevant data through observation or experimentation. Analyze the data using appropriate statistical methods to obtain a test statistic.
Step 4-Calculate Test Statistic
The data for the tests are evaluated in this step we look for various scores based on the characteristics of data. The choice of the test statistic depends on the type of hypothesis test being conducted.
There are various hypothesis tests, each appropriate for various goal to calculate our test. This could be a Z-test , Chi-square , T-test , and so on.
- Z-test : If population means and standard deviations are known. Z-statistic is commonly used.
- t-test : If population standard deviations are unknown. and sample size is small than t-test statistic is more appropriate.
- Chi-square test : Chi-square test is used for categorical data or for testing independence in contingency tables
- F-test : F-test is often used in analysis of variance (ANOVA) to compare variances or test the equality of means across multiple groups.
We have a smaller dataset, So, T-test is more appropriate to test our hypothesis.
T-statistic is a measure of the difference between the means of two groups relative to the variability within each group. It is calculated as the difference between the sample means divided by the standard error of the difference. It is also known as the t-value or t-score.
Step 5 – Comparing Test Statistic:
In this stage, we decide where we should accept the null hypothesis or reject the null hypothesis. There are two ways to decide where we should accept or reject the null hypothesis.
Method A: Using Crtical values
Comparing the test statistic and tabulated critical value we have,
- If Test Statistic>Critical Value: Reject the null hypothesis.
- If Test Statistic≤Critical Value: Fail to reject the null hypothesis.
Note: Critical values are predetermined threshold values that are used to make a decision in hypothesis testing. To determine critical values for hypothesis testing, we typically refer to a statistical distribution table , such as the normal distribution or t-distribution tables based on.
Method B: Using P-values
We can also come to an conclusion using the p-value,
- If the p-value is less than or equal to the significance level i.e. ( [Tex]p\leq\alpha [/Tex] ), you reject the null hypothesis. This indicates that the observed results are unlikely to have occurred by chance alone, providing evidence in favor of the alternative hypothesis.
- If the p-value is greater than the significance level i.e. ( [Tex]p\geq \alpha[/Tex] ), you fail to reject the null hypothesis. This suggests that the observed results are consistent with what would be expected under the null hypothesis.
Note : The p-value is the probability of obtaining a test statistic as extreme as, or more extreme than, the one observed in the sample, assuming the null hypothesis is true. To determine p-value for hypothesis testing, we typically refer to a statistical distribution table , such as the normal distribution or t-distribution tables based on.
Step 7- Interpret the Results
At last, we can conclude our experiment using method A or B.
Calculating test statistic
To validate our hypothesis about a population parameter we use statistical functions . We use the z-score, p-value, and level of significance(alpha) to make evidence for our hypothesis for normally distributed data .
1. Z-statistics:
When population means and standard deviations are known.
[Tex]z = \frac{\bar{x} – \mu}{\frac{\sigma}{\sqrt{n}}}[/Tex]
- [Tex]\bar{x} [/Tex] is the sample mean,
- μ represents the population mean,
- σ is the standard deviation
- and n is the size of the sample.
2. T-Statistics
T test is used when n<30,
t-statistic calculation is given by:
[Tex]t=\frac{x̄-μ}{s/\sqrt{n}} [/Tex]
- t = t-score,
- x̄ = sample mean
- μ = population mean,
- s = standard deviation of the sample,
- n = sample size
3. Chi-Square Test
Chi-Square Test for Independence categorical Data (Non-normally distributed) using:
[Tex]\chi^2 = \sum \frac{(O_{ij} – E_{ij})^2}{E_{ij}}[/Tex]
- [Tex]O_{ij}[/Tex] is the observed frequency in cell [Tex]{ij} [/Tex]
- i,j are the rows and columns index respectively.
- [Tex]E_{ij}[/Tex] is the expected frequency in cell [Tex]{ij}[/Tex] , calculated as : [Tex]\frac{{\text{{Row total}} \times \text{{Column total}}}}{{\text{{Total observations}}}}[/Tex]
Real life Examples of Hypothesis Testing
Let’s examine hypothesis testing using two real life situations,
Case A: D oes a New Drug Affect Blood Pressure?
Imagine a pharmaceutical company has developed a new drug that they believe can effectively lower blood pressure in patients with hypertension. Before bringing the drug to market, they need to conduct a study to assess its impact on blood pressure.
- Before Treatment: 120, 122, 118, 130, 125, 128, 115, 121, 123, 119
- After Treatment: 115, 120, 112, 128, 122, 125, 110, 117, 119, 114
Step 1 : Define the Hypothesis
- Null Hypothesis : (H 0 )The new drug has no effect on blood pressure.
- Alternate Hypothesis : (H 1 )The new drug has an effect on blood pressure.
Step 2: Define the Significance level
Let’s consider the Significance level at 0.05, indicating rejection of the null hypothesis.
If the evidence suggests less than a 5% chance of observing the results due to random variation.
Step 3 : Compute the test statistic
Using paired T-test analyze the data to obtain a test statistic and a p-value.
The test statistic (e.g., T-statistic) is calculated based on the differences between blood pressure measurements before and after treatment.
t = m/(s/√n)
- m = mean of the difference i.e X after, X before
- s = standard deviation of the difference (d) i.e d i = X after, i − X before,
- n = sample size,
then, m= -3.9, s= 1.8 and n= 10
we, calculate the , T-statistic = -9 based on the formula for paired t test
Step 4: Find the p-value
The calculated t-statistic is -9 and degrees of freedom df = 9, you can find the p-value using statistical software or a t-distribution table.
thus, p-value = 8.538051223166285e-06
Step 5: Result
- If the p-value is less than or equal to 0.05, the researchers reject the null hypothesis.
- If the p-value is greater than 0.05, they fail to reject the null hypothesis.
Conclusion: Since the p-value (8.538051223166285e-06) is less than the significance level (0.05), the researchers reject the null hypothesis. There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different.
Python Implementation of Case A
Let’s create hypothesis testing with python, where we are testing whether a new drug affects blood pressure. For this example, we will use a paired T-test. We’ll use the scipy.stats library for the T-test.
Scipy is a mathematical library in Python that is mostly used for mathematical equations and computations.
We will implement our first real life problem via python,
import numpy as np from scipy import stats # Data before_treatment = np . array ([ 120 , 122 , 118 , 130 , 125 , 128 , 115 , 121 , 123 , 119 ]) after_treatment = np . array ([ 115 , 120 , 112 , 128 , 122 , 125 , 110 , 117 , 119 , 114 ]) # Step 1: Null and Alternate Hypotheses # Null Hypothesis: The new drug has no effect on blood pressure. # Alternate Hypothesis: The new drug has an effect on blood pressure. null_hypothesis = "The new drug has no effect on blood pressure." alternate_hypothesis = "The new drug has an effect on blood pressure." # Step 2: Significance Level alpha = 0.05 # Step 3: Paired T-test t_statistic , p_value = stats . ttest_rel ( after_treatment , before_treatment ) # Step 4: Calculate T-statistic manually m = np . mean ( after_treatment - before_treatment ) s = np . std ( after_treatment - before_treatment , ddof = 1 ) # using ddof=1 for sample standard deviation n = len ( before_treatment ) t_statistic_manual = m / ( s / np . sqrt ( n )) # Step 5: Decision if p_value <= alpha : decision = "Reject" else : decision = "Fail to reject" # Conclusion if decision == "Reject" : conclusion = "There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different." else : conclusion = "There is insufficient evidence to claim a significant difference in average blood pressure before and after treatment with the new drug." # Display results print ( "T-statistic (from scipy):" , t_statistic ) print ( "P-value (from scipy):" , p_value ) print ( "T-statistic (calculated manually):" , t_statistic_manual ) print ( f "Decision: { decision } the null hypothesis at alpha= { alpha } ." ) print ( "Conclusion:" , conclusion )
T-statistic (from scipy): -9.0 P-value (from scipy): 8.538051223166285e-06 T-statistic (calculated manually): -9.0 Decision: Reject the null hypothesis at alpha=0.05. Conclusion: There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different.
In the above example, given the T-statistic of approximately -9 and an extremely small p-value, the results indicate a strong case to reject the null hypothesis at a significance level of 0.05.
- The results suggest that the new drug, treatment, or intervention has a significant effect on lowering blood pressure.
- The negative T-statistic indicates that the mean blood pressure after treatment is significantly lower than the assumed population mean before treatment.
Case B : Cholesterol level in a population
Data: A sample of 25 individuals is taken, and their cholesterol levels are measured.
Cholesterol Levels (mg/dL): 205, 198, 210, 190, 215, 205, 200, 192, 198, 205, 198, 202, 208, 200, 205, 198, 205, 210, 192, 205, 198, 205, 210, 192, 205.
Populations Mean = 200
Population Standard Deviation (σ): 5 mg/dL(given for this problem)
Step 1: Define the Hypothesis
- Null Hypothesis (H 0 ): The average cholesterol level in a population is 200 mg/dL.
- Alternate Hypothesis (H 1 ): The average cholesterol level in a population is different from 200 mg/dL.
As the direction of deviation is not given , we assume a two-tailed test, and based on a normal distribution table, the critical values for a significance level of 0.05 (two-tailed) can be calculated through the z-table and are approximately -1.96 and 1.96.
The test statistic is calculated by using the z formula Z = [Tex](203.8 – 200) / (5 \div \sqrt{25}) [/Tex] and we get accordingly , Z =2.039999999999992.
Step 4: Result
Since the absolute value of the test statistic (2.04) is greater than the critical value (1.96), we reject the null hypothesis. And conclude that, there is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL
Python Implementation of Case B
import scipy.stats as stats import math import numpy as np # Given data sample_data = np . array ( [ 205 , 198 , 210 , 190 , 215 , 205 , 200 , 192 , 198 , 205 , 198 , 202 , 208 , 200 , 205 , 198 , 205 , 210 , 192 , 205 , 198 , 205 , 210 , 192 , 205 ]) population_std_dev = 5 population_mean = 200 sample_size = len ( sample_data ) # Step 1: Define the Hypotheses # Null Hypothesis (H0): The average cholesterol level in a population is 200 mg/dL. # Alternate Hypothesis (H1): The average cholesterol level in a population is different from 200 mg/dL. # Step 2: Define the Significance Level alpha = 0.05 # Two-tailed test # Critical values for a significance level of 0.05 (two-tailed) critical_value_left = stats . norm . ppf ( alpha / 2 ) critical_value_right = - critical_value_left # Step 3: Compute the test statistic sample_mean = sample_data . mean () z_score = ( sample_mean - population_mean ) / \ ( population_std_dev / math . sqrt ( sample_size )) # Step 4: Result # Check if the absolute value of the test statistic is greater than the critical values if abs ( z_score ) > max ( abs ( critical_value_left ), abs ( critical_value_right )): print ( "Reject the null hypothesis." ) print ( "There is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL." ) else : print ( "Fail to reject the null hypothesis." ) print ( "There is not enough evidence to conclude that the average cholesterol level in the population is different from 200 mg/dL." )
Reject the null hypothesis. There is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL.
Limitations of Hypothesis Testing
- Although a useful technique, hypothesis testing does not offer a comprehensive grasp of the topic being studied. Without fully reflecting the intricacy or whole context of the phenomena, it concentrates on certain hypotheses and statistical significance.
- The accuracy of hypothesis testing results is contingent on the quality of available data and the appropriateness of statistical methods used. Inaccurate data or poorly formulated hypotheses can lead to incorrect conclusions.
- Relying solely on hypothesis testing may cause analysts to overlook significant patterns or relationships in the data that are not captured by the specific hypotheses being tested. This limitation underscores the importance of complimenting hypothesis testing with other analytical approaches.
Hypothesis testing stands as a cornerstone in statistical analysis, enabling data scientists to navigate uncertainties and draw credible inferences from sample data. By systematically defining null and alternative hypotheses, choosing significance levels, and leveraging statistical tests, researchers can assess the validity of their assumptions. The article also elucidates the critical distinction between Type I and Type II errors, providing a comprehensive understanding of the nuanced decision-making process inherent in hypothesis testing. The real-life example of testing a new drug’s effect on blood pressure using a paired T-test showcases the practical application of these principles, underscoring the importance of statistical rigor in data-driven decision-making.
Frequently Asked Questions (FAQs)
1. what are the 3 types of hypothesis test.
There are three types of hypothesis tests: right-tailed, left-tailed, and two-tailed. Right-tailed tests assess if a parameter is greater, left-tailed if lesser. Two-tailed tests check for non-directional differences, greater or lesser.
2.What are the 4 components of hypothesis testing?
Null Hypothesis ( [Tex]H_o [/Tex] ): No effect or difference exists. Alternative Hypothesis ( [Tex]H_1 [/Tex] ): An effect or difference exists. Significance Level ( [Tex]\alpha [/Tex] ): Risk of rejecting null hypothesis when it’s true (Type I error). Test Statistic: Numerical value representing observed evidence against null hypothesis.
3.What is hypothesis testing in ML?
Statistical method to evaluate the performance and validity of machine learning models. Tests specific hypotheses about model behavior, like whether features influence predictions or if a model generalizes well to unseen data.
4.What is the difference between Pytest and hypothesis in Python?
Pytest purposes general testing framework for Python code while Hypothesis is a Property-based testing framework for Python, focusing on generating test cases based on specified properties of the code.
Please Login to comment...
Similar reads.
- data-science
- How to Get a Free SSL Certificate
- Best SSL Certificates Provider in India
- Elon Musk's xAI releases Grok-2 AI assistant
- What is OpenAI SearchGPT? How it works and How to Get it?
- Content Improvement League 2024: From Good To A Great Article
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
IMAGES
COMMENTS
Table of contents. Step 1: State your null and alternate hypothesis. Step 2: Collect data. Step 3: Perform a statistical test. Step 4: Decide whether to reject or fail to reject your null hypothesis. Step 5: Present your findings. Other interesting articles. Frequently asked questions about hypothesis testing.
In hypothesis testing, the goal is to see if there is sufficient statistical evidence to reject a presumed null hypothesis in favor of a conjectured alternative hypothesis.The null hypothesis is usually denoted \(H_0\) while the alternative hypothesis is usually denoted \(H_1\). An hypothesis test is a statistical decision; the conclusion will either be to reject the null hypothesis in favor ...
5 Steps of Significance Testing. Hypothesis testing involves five key steps, each critical to validating a research hypothesis using statistical methods: Formulate the Hypotheses: Write your research hypotheses as a null hypothesis (H 0) and an alternative hypothesis (H A ). Data Collection: Gather data specifically aimed at testing the ...
A hypothesis test consists of five steps: 1. State the hypotheses. State the null and alternative hypotheses. These two hypotheses need to be mutually exclusive, so if one is true then the other must be false. 2. Determine a significance level to use for the hypothesis. Decide on a significance level.
Test Statistic: z = ¯ x − μo σ / √n since it is calculated as part of the testing of the hypothesis. Definition 7.1.4. p - value: probability that the test statistic will take on more extreme values than the observed test statistic, given that the null hypothesis is true.
Components of a Formal Hypothesis Test. The null hypothesis is a statement about the value of a population parameter, such as the population mean (µ) or the population proportion (p).It contains the condition of equality and is denoted as H 0 (H-naught).. H 0: µ = 157 or H0 : p = 0.37. The alternative hypothesis is the claim to be tested, the opposite of the null hypothesis.
Hypothesis testing is a crucial procedure to perform when you want to make inferences about a population using a random sample. These inferences include estimating population properties such as the mean, differences between means, proportions, and the relationships between variables. This post provides an overview of statistical hypothesis testing.
S.3 Hypothesis Testing. In reviewing hypothesis tests, we start first with the general idea. Then, we keep returning to the basic procedures of hypothesis testing, each time adding a little more detail. The general idea of hypothesis testing involves: Making an initial assumption. Collecting evidence (data).
What is hypothesis testing in statistics with example? Hypothesis testing is a statistical method used to determine if there is enough evidence in a sample data to draw conclusions about a population. It involves formulating two competing hypotheses, the null hypothesis (H0) and the alternative hypothesis (Ha), and then collecting data to ...
Basic approach to hypothesis testing. State a model describing the relationship between the explanatory variables and the outcome variable (s) in the population and the nature of the variability. State all of your assumptions. Specify the null and alternative hypotheses in terms of the parameters of the model.
Step 7: Based on Steps 5 and 6, draw a conclusion about H 0. If F calculated is larger than F α, then you are in the rejection region and you can reject the null hypothesis with ( 1 − α) level of confidence. Note that modern statistical software condenses Steps 6 and 7 by providing a p -value. The p -value here is the probability of getting ...
Introduction to Hypotheses Tests. Hypothesis testing is a statistical tool used to make decisions based on data. It involves making assumptions about a population parameter and testing its validity using a population sample. Hypothesis tests help us draw conclusions and make informed decisions in various fields like business, research, and science.
A statistical hypothesis test may return a value called p or the p-value. This is a quantity that we can use to interpret or quantify the result of the test and either reject or fail to reject the null hypothesis. This is done by comparing the p-value to a threshold value chosen beforehand called the significance level.
The basic steps to perform hypothesis testing are as follows: Step 1: Set up the null hypothesis by correctly identifying whether it is the left-tailed, right-tailed, or two-tailed hypothesis testing. ... Hypothesis testing in statistics is a tool that is used to make inferences about the population data. It is also used to check if the results ...
Hypothesis testing in statistics is a way for you to test the results of a survey or experiment to see if you have meaningful results. You're basically testing whether your results are valid by figuring out the odds that your results have happened by chance. ... Hypothesis Testing Examples #1: Basic Example. A researcher thinks that if knee ...
HYPOTHESIS TESTING. A clinical trial begins with an assumption or belief, and then proceeds to either prove or disprove this assumption. In statistical terms, this belief or assumption is known as a hypothesis. Counterintuitively, what the researcher believes in (or is trying to prove) is called the "alternate" hypothesis, and the opposite ...
Practice this lesson yourself on KhanAcademy.org right now: https://www.khanacademy.org/math/probability/probability-and-combinatorics-topic/decisions-with-p...
Step 7: Based on steps 5 and 6, draw a conclusion about H0. If the F\calculated F \calculated from the data is larger than the Fα F α, then you are in the rejection region and you can reject the null hypothesis with (1 − α) ( 1 − α) level of confidence. Note that modern statistical software condenses steps 6 and 7 by providing a p p -value.
Get the full course at: http://www.MathTutorDVD.comThe student will learn the big picture of what a hypothesis test is in statistics. We will discuss terms ...
Below these are summarized into six such steps to conducting a test of a hypothesis. Set up the hypotheses and check conditions: Each hypothesis test includes two hypotheses about the population. One is the null hypothesis, notated as H 0, which is a statement of a particular parameter value. This hypothesis is assumed to be true until there is ...
Hypothesis testing is an act in statistics whereby an analyst tests an assumption regarding a population parameter. The methodology employed by the analyst depends on the nature of the data used ...
Null hypothesis (H 0): In statistics, the null hypothesis is a general statement or default position that there is no relationship between two measured cases or no relationship among groups. In other words, it is a basic assumption or made based on the problem knowledge.
For simple tasks such as descriptive statistics, you can use the built-in statistics modules or other core Python functions. But there's a suite of Python libraries for basic to advanced statistical analysis—from descriptive statistics to hypothesis testing and more. In this guide, we'll go over popular Python libraries for statistics.
Bayesian statistics constitute one of the not-so-conventional subareas within statistics, based on a particular vision of the concept of probabilities. This post introduces and unveils what bayesian statistics is and its differences from frequentist statistics, through a gentle and predominantly non-technical narrative that will awaken your curiosity about this fascinating topic. Introduction ...
Most programs were either really basic and tailored to high level executives. Others were detailed and built on top of prerequisite knowledge I did not possess. I spent time scouring the Internet for resources to better understand concepts like hypothesis testing and confidence intervals.
This page titled 1.1: Basic Definitions and Concepts is shared under a CC BY-NC-SA 3.0 license and was authored, remixed, and/or curated by Anonymous via source content that was edited to the style and standards of the LibreTexts platform. Statistics is a study of data: describing properties of data (descriptive statistics) and drawing ...
DEPARTMENT OF ENERGY (DOE) . OFFICE OF SCIENCE (SC) . BIOLOGICAL AND ENVIRONMENTAL RESEARCH (BER). BIOIMAGING RESEARCH AND APPROACHES FOR THE BIOECONOMY & THE ENVIRONMENT. FUNDING OPPORTUNITY ANNOUNCEMENT (FOA) NUMBER: . DE-FOA-0003231 . FOA TYPE: INITIAL. FOA Issue Date: December 7, 2023 Submission Deadline for Pre-Applications: January 9, 2024 at 5:00 PM Eastern Time