EViews User Forum
Skip to content
- Board index Technical Support Estimation

hypothesis testing
Moderators: EViews Gareth , EViews Moderator
Post by Eoghan » Thu Apr 27, 2017 12:29 am
Re: hypothesis testing
Post by EViews Gareth » Thu Apr 27, 2017 12:44 am
Return to “Estimation”
- Technical Support
- Installation and Registration
- License Manager
- Data Manipulation
- Estimation
- Programming
- Tips, Tricks and Suggestions
- General Information and Tips and Tricks
- Suggestions and Requests
- Bug Reports
- Any Other Business
- Program Repository
- EViews Add-ins
- Add-in Support
- Add-in Writing area
- Models
- Econometric Discussions
- Econometric Discussions
Who is online
Users browsing this forum: No registered users and 26 guests
- Board index
- All times are UTC
- [email protected]
- Connecting and sharing with us
- Entrepreneurship
- Growth of firm
- Sales Management
- Retail Management
- Import – Export
- International Business
- Project Management
- Production Management
- Quality Management
- Logistics Management
- Supply Chain Management
- Human Resource Management
- Organizational Culture
- Information System Management
- Corporate Finance
- Stock Market
- Office Management
- Theory of the Firm
- Management Science
- Microeconomics
- Research Process
- Experimental Research
- Research Philosophy
- Management Research
- Writing a thesis
- Writing a paper
- Literature Review
- Action Research
- Qualitative Content Analysis
- Observation
- Phenomenology
- Statistics and Econometrics
- Questionnaire Survey
- Quantitative Content Analysis
- Meta Analysis
Interval Estimation and Hypothesis Testing by using EViews
1. interval estimation.
For the regression model y = β 1 +β 2 x + e, and under assumptions SR1-SR6, the important result that we use in this chapter is given in equation (3.3) of POE.
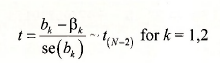
Using this result we can show that the interval b k ± t c se(b k ) has probability 1-a of containing the true but unknown parameter p*, where the “critical value” t c from a /-distribution such that P(t>t c ) = P(t < -t c ) = a/2
To construct interval estimates we will use EViews’ stored regression results. We will also make use of EViews built in statistical functions. For each distribution (see Function reference in EViews Help) four statistical functions are provided. The two we will make use of are the cumulative distribution (CDF) and the quantile (Inverse CDF) functions.
The for the /-distribution the CDF is given by the function @ctdist(x,v). This function returns the probability that a /-random variable with v degrees of freedom falls to the left of x. That is,
The quantile function @qtdist(p,v) computes the critical value of a /-random variable with v degrees of freedom such that probability p falls to the left of it. For example, if we specify tc=@qtdist(.975,38), then
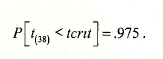
To construct the interval estimates we require the least squares estimates bk and their standard errors se(bk). After each regression model is estimated the coefficients and standard errors are saved in the arrays @coefs and @stderrs. However they are saved only until the next regression is run, at which time they are replaced. If you have named the regression results, as we have (FOOD_EQ) then the coefficients are saved as well, with the names food_eq.@coefs and food_eq.@stderrs, respectively.
1.1. Constructing the interval estimate
Since we have estimated only one regression we can use the simple form for the saved results. Thus @coefs(2) = b2 and @stderrs(2) = se(b2). To generate the 95% confidence interval [b 2 – t c se{b 2 ), b 2 + t c se(b 2 )\ enter the following commands in the EViews command window, pressing the <Enter> key after each:
scalar tc = @qtdist(.975,38)
scalar b2 = @coefs(2)
scalar seb2 = @stderrs(2)
scalar b2_lb = b2 – tc*seb2
scalar b2_ub = b2 + tc*seb2
These scalar values show up in the workfile with the symbol #. For example, the value of the lower bound of the interval estimate is

1.2. Using a coefficient vector
While the above approach works perfectly fine, it may be nicer for report writing to store the interval estimates in an array and construct a table. On the main EViews Menu select Objects/New Object

We will create a Matrix-Vector-Coef named INT EST
It will be a coefficient vector that has 2 rows and 1 column
Click OK, and the empty array appears. Instead of all that pointing and clicking, you can simply enter on the command line
coef(2) int_est
Now, enter the commands
int_est(1) = @coefs(2) – @qtdist(.975,38)*@stderrs(2)
int_est(2) = @coefs(2) + @qtdist(.975,38)*@stderrs(2)
Here we have used the EViews saved results directly rather than create scalars for each elements. The vector we created is
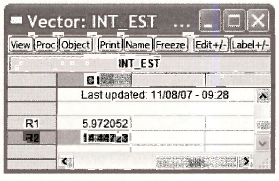
Click on Freeze and then Name. We chose the name B2 INTERVAL ESTIMATE and it looks like this:
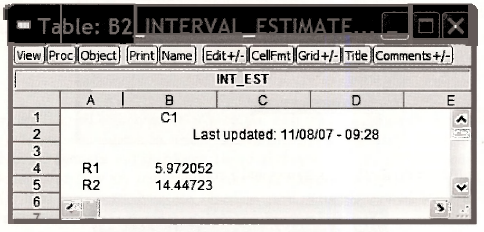
The advantage of this approach is that the contents can be highlighted, copied (Ctrl+C) and pasted (Ctrl+V) into a document. The resulting table can be edited as you like

2. RIGHT-TAIL TESTS
2.1. test of significance.
To test the null hypothesis that (3 2 = 0 against the alternative that it is positive (> 0), as described in Chapter 3.4.1a of POE, requires us to find the critical value, construct the /-statistic, and determine the /7-value.
- If we choose the a = .05 level of significance, then the critical value is the 95 th percentile of the /(3g) distribution.
- The /- statistic is the ratio of the estimate bi over its standard error, se(b 2 ).
- The /7-value is the area to the right of the calculated /-statistic (since it is a right-tail test). This value is one minus the cumulative probability to the left of the /-statistic.
The simplest set of commands is (do not type the comments in italic font)
scalar tc95 = @qtdist(.95,38) t-critical right tail
scalar tstat = b2/seb2 t-statistic
scalar pval = 1 – @ctdist(tstat,38) right-tail p-value
Alternatively, use the vector approach outlined in the previous section

Use the results of this vector to construct a table, such as

2.2. Test of an economic hypothesis
To test the null hypothesis that β 2 < 5 against tl alternative β 2 > 5 the same steps are executed, except for the construction of the t-statistic.

3. LEFT-TAIL TESTS
3.1. test of significance.
To test the null hypothesis that β 2 > 0 against the alternative that it is negative (< 0) requires us to find the critical value, construct the t-statistic, and determine the p-value.
- If we choose the a = .05 level of significance, then the critical value is the 5 th percentile of the t(38) distribution.
- The t- statistic is the ratio of the estimate b 2 over its standard error, se(b 2 ).
- The p-value is the area to the left of the calculated /-statistic (since it is a left-tail test). This value is given by the cumulative probability to the left of the t-statistic.

Alternatively

Note that we fail to reject the null hypothesis in this case, as expected.
3.2. Test of an economic hypothesis
To test the null hypothesis that β 2 >12 against the alternative that β 2 < 12, we use the same steps as above, except for the construction of the t-statistic.

The t-statistic value -.85 does not fall in the rejection region, and the p-value is about .20, thus we fail to reject this null hypothesis.
4. TWO-TAIL TESTS
4.1. test of significance.
The two tail test of the null hypothesis that β 2 = 0 against the alternative that β 2 # 0 we require the same test elements
- If we choose the a = .05 level of significance, then the right-tail critical value is the 97.5- percentile of the f ( 38) distribution and the left tail critical value is the 2.5-percentile.
- The t- statistic is the ratio of the estimate bi over its standard error, se(£>->).
- The p-value is the area to the left of minus the absolute value of the calculated t-statistic plus the area to the right of the absolute value of the calculated test statistic (since it is a two-tail test). This value is given by the cumulative probability to the left of the – |t-statistic| and l – the cumulative probability to the right of |t-statistic|.
The two tail p-value is
The test is carried out by EViews each time a regression model is estimated. If we examine FOOD_EQ, in the column labeled t-statistic is the ratio of the Coefficient to Std. Error. The column labeled Prob. contains the two-tail p-value for the test of significance. Note that the very small p-value is rounded to zero (to 4 places). For practical purposes this is enough since levels of significance below .001 are hardly ever used.

To use the coefficient vector approach

The result is as follows. Here we have copied the results from EViews at the highest precision to show that the p-value works out to be the same as reported above.

4.2. Test of an economic hypothesis
To test the null hypothesis that β 2 = 12.5 against the alternative β 2 # 12.5 the steps are the same as those above, except for the construction of the t-statistic.

Which yields
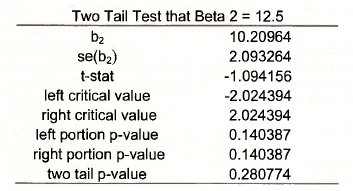
Source: Griffiths William E., Hill R. Carter, Lim Mark Andrew (2008), Using EViews for Principles of Econometrics , John Wiley & Sons; 3rd Edition.
20 Sep 2021
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Username or email address *
Password *
Log in Remember me
Lost your password?

- Customers Testimonial
- Become a Distributor
- TI Calculators
- Data Loggers
- Innovator, Rover & Navigator
- Upgrade to TI-Nspire™ CX technology
- TI Calculators Support
- Technical Support Services
- Consulting Services
- Training Services
- Professional Development
- Upcoming Webinars
- Training & Workshop
- Register Your Product
- Get in Touch ! +911146142446

Descriptive Statistics and Eviews

EViews has a lot to offer when it comes to data analysis, which includes descriptive statistics, impressive graphs, tests, and procedures as it understands the importance of statistical analysis s an important task to examine series and groups.
The fact that EViews is the most easy-to-use Statistical software, it understands all our needs to view different displays of our series, provides general statistics and statistics for time series, modify a series labels all with a just a set of clicks.
Taking an example, we have used GDP data of India from 1960 to 2019 measured in trillion dollars. The magical menus in Eviews for any series is the View and the Proc menu. The main data analysis can be done once you click on the View menu where all actions are divided into four blocks.

The first section views the data series in spreadsheet and Graph which is fully customizable in the Options tab.
The second section provides descriptive statistics and tests as well as one way tabulation of your series.

Descriptive statistics and tests-
This section of the View menu has various options allowing to get a deep statistical analysis of the data.
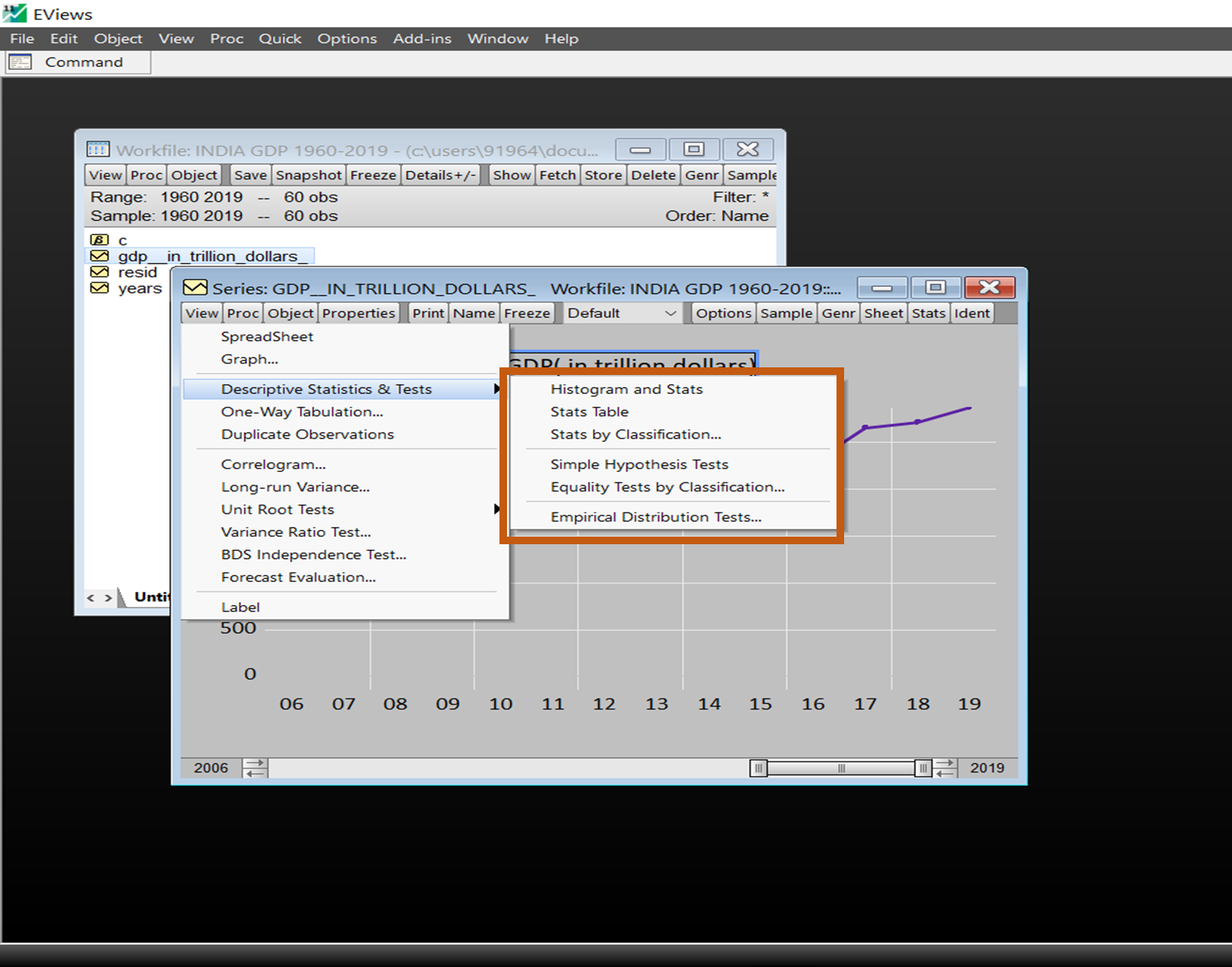
For Histogram & Stats Table –
Simply clicking on View/ Descriptive statistics and tests/ Histogram and stats
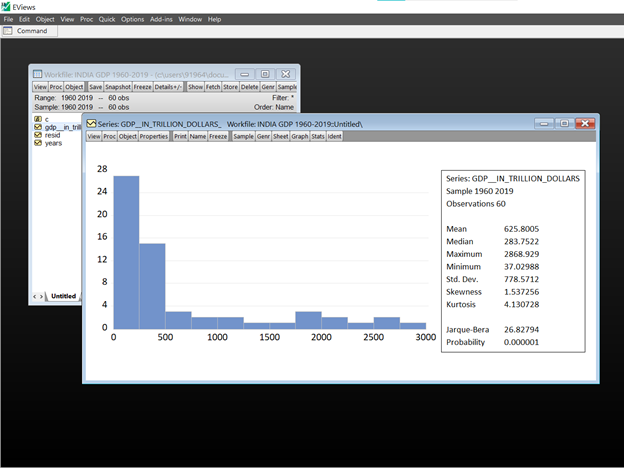
The results show the name of the series, the sample and the number of observations at top of the statistics panel. EViews summarizes the main statistics for the series measuring central tendencies, Maximum and minimum values, standard deviation, skewness- the measure of asymmetry in data, kurtosis- The presence of fat tails, the Jarque-bera statistic and its associated p-value.
For Tabulation Analysis – View/ Descriptive statistics and tests/ One way Tabulation.
In this View EViews provides the counts, percentage counts and cumulative counts for each observation value.
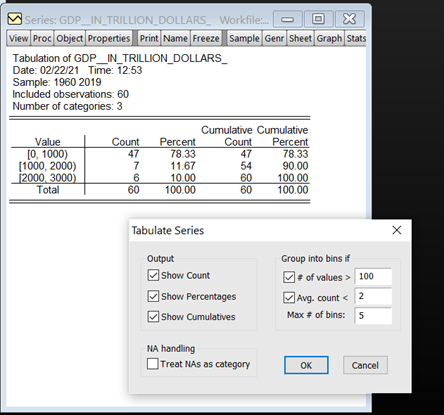
Apart from descriptive statistics, EViews allows to carry out a number of formal hypothesis tests on a series namely
- Simple hypothesis tests – Tests for Mean, median and variance of the series.
- Equality Tests by Classification – Tests equality of means, medians and variance across subsamples of a series.
- Empirical Distribution Tests – Tests whether the data distribution of the series is drawn from a number of well-known distributions.
Simple hypothesis tests
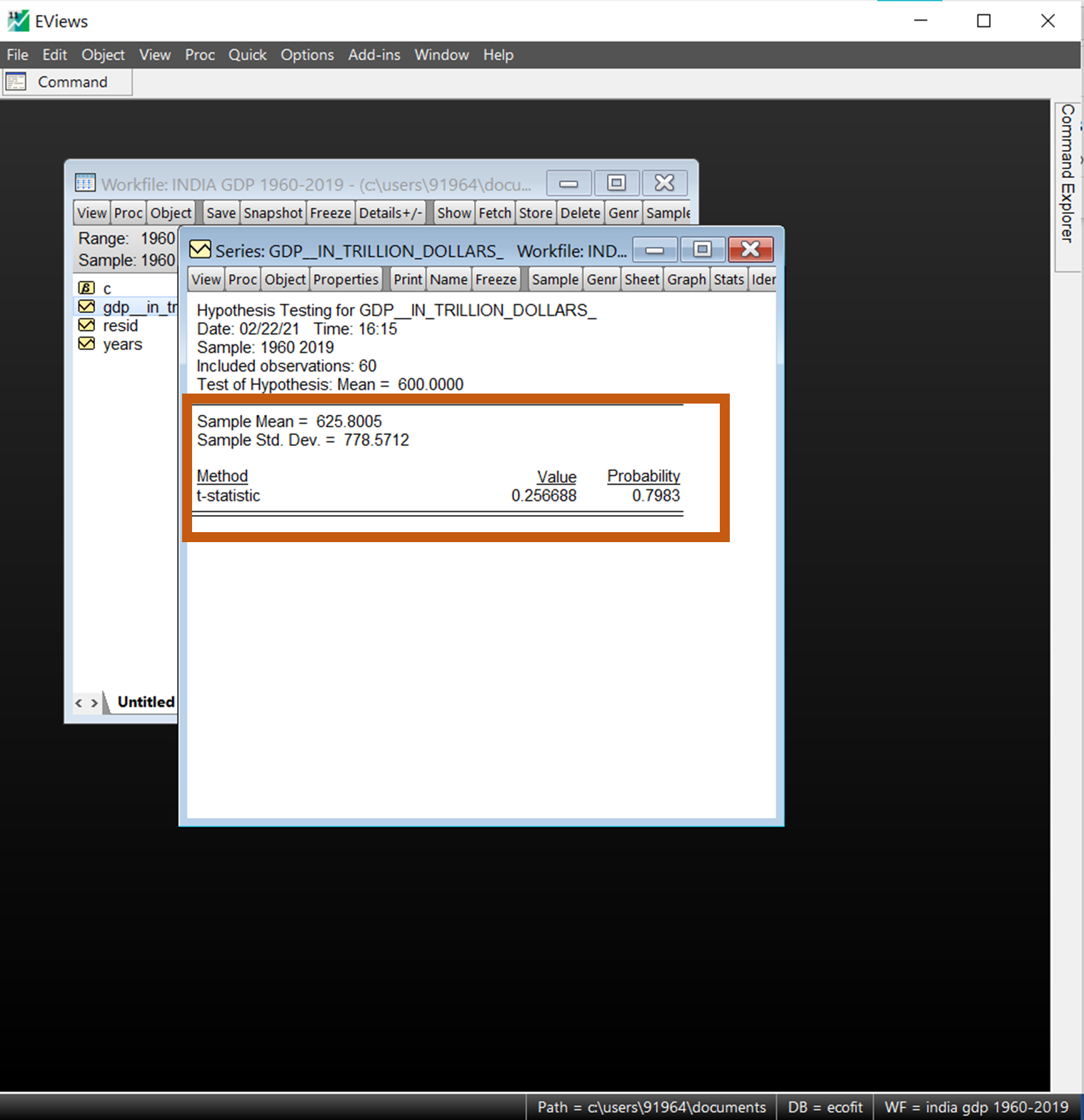
One of the most common tests of series is to compare whether its mean is equal to a specific value. The GDP in our example can be tested for a mean of 600 trillion dollars if it is statistically significant.
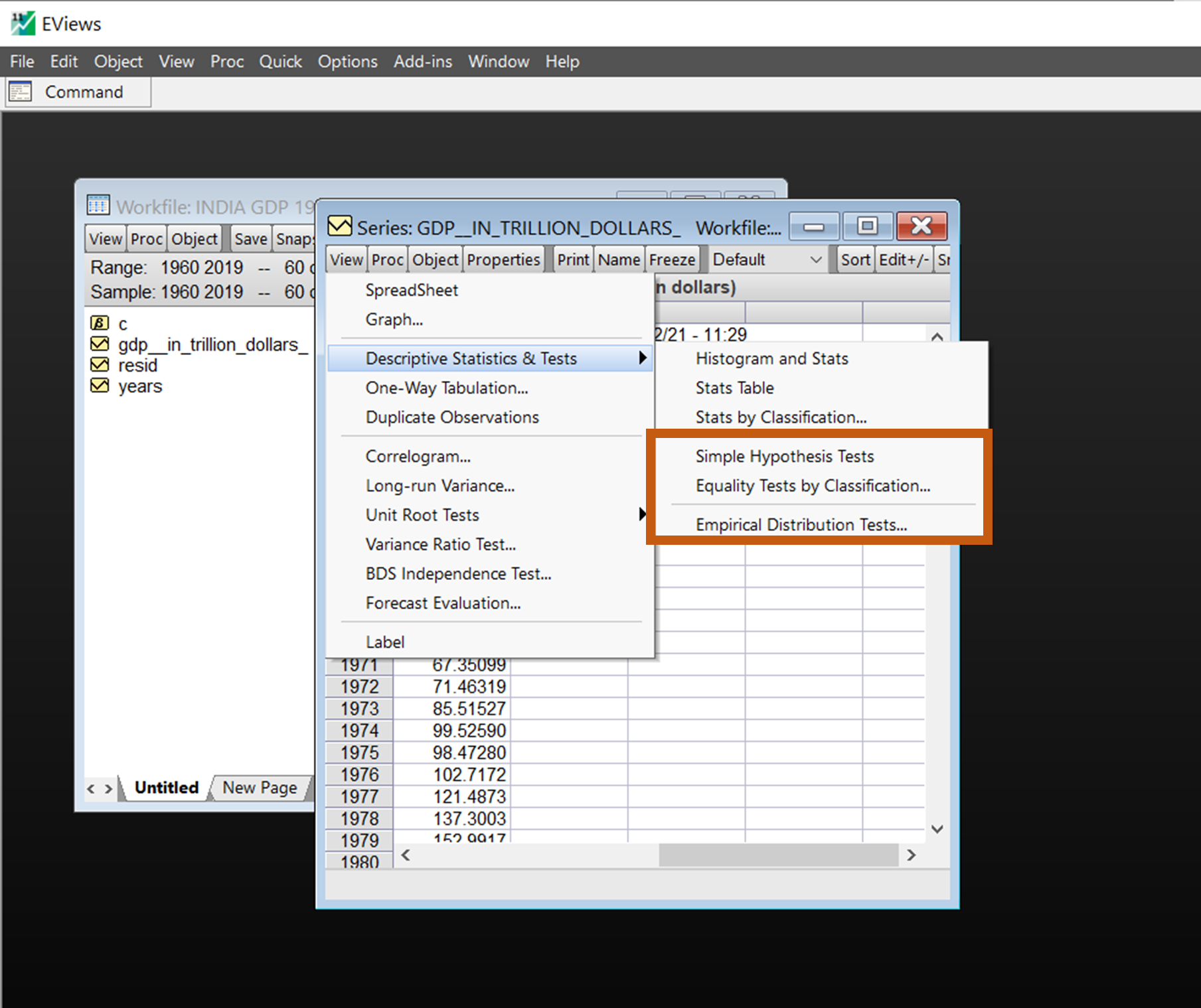
- Open GDP series
- Click View/Descriptive statistics and tests/Simple Hypothesis Tests
- In the Series Distribution Tests dialog box, the test values can be added for Mean, Variance, and median.
- For Instance, we test the mean of ‘600 trillion dollars’ for the whole observations.
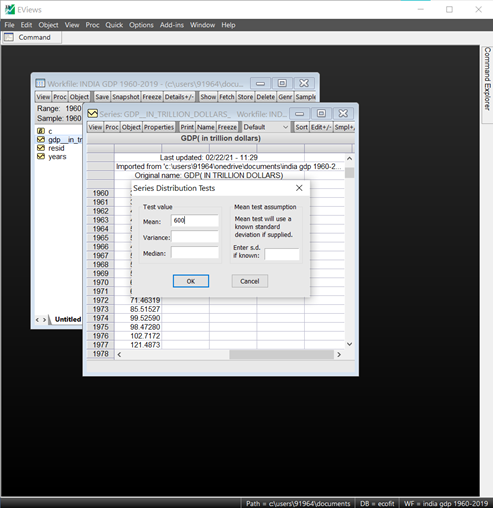
The results of the same appear and clearly the p-value is significant, and the null-hypothesis cannot be rejected.
Equality Tests by Classification
This view allows you to test equality of the means, medians and variances across sub samples of a single series.
For example, you can test whether mean income is the same for males and females, or whether the variance of education is related to race. The tests assume that the subsamples are independent.
Letting EViews know which series is to be classified
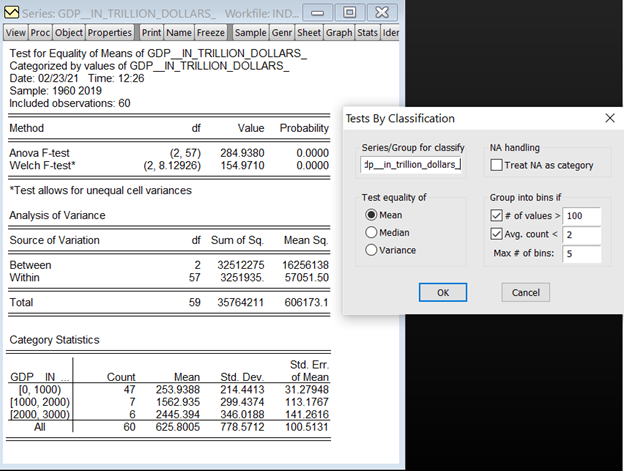
Empirical Distribution Tests
EViews provides built-in Kolmogorov-Smirnov, Lilliefors, Cramer-von Mises, Anderson-Darling, and Watson empirical distribution tests. These tests are based on the comparison between the empirical distribution and the specified theoretical distribution function.
You can test whether your series is normally distributed, or whether it comes from, among others, an exponential, extreme value, logistic, chi-square, Weibull, or gamma distribution. You may provide parameters for the distribution, or EViews will estimate the parameters for you.
To carry out the test, simply double click on the series and select View/Descriptive Statistics & Tests/Empirical Distribution Tests… from the series window.
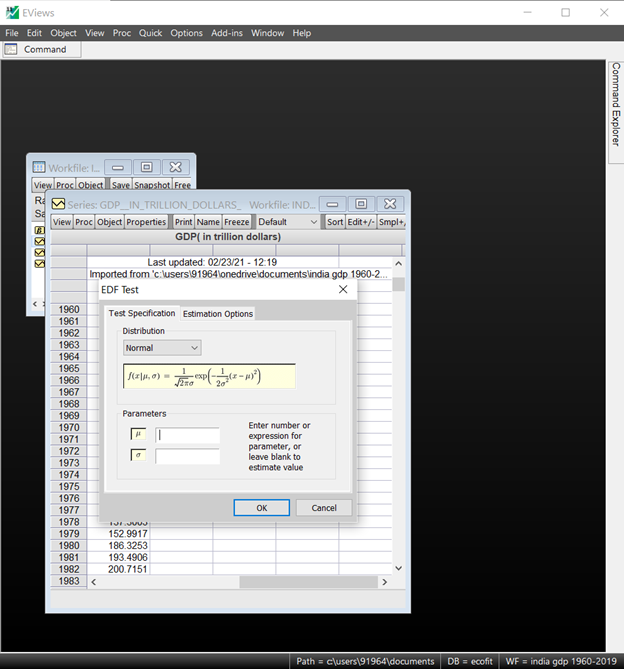
The output of the test is shown in the screenshot and both the mean and variance is estimated. The value reports the asymptotic test statistics while the second column, “Adj. Value”, reports test statistics that have a finite sample correction or adjusted for parameter uncertainty (in case the parameters are estimated). The third column reports p -value for the adjusted statistics.
All of the reported EViews p -values will account for the fact that parameters in the distribution have been estimated.
The second part of the output table displays the parameter values used to compute the theoretical distribution function. Any parameters that are specified to estimate are estimated by maximum likelihood (for the normal distribution, the ML estimate of the standard deviation is subsequently degree of freedom corrected if the mean is not specified a priori ). For parameters that do not have a closed form analytic solution, the likelihood function is maximized using analytic first and second derivatives. These estimated parameters are reported with a standard error and p -value based on the asymptotic normal distribution.
Related Posts

New EViews Patch Now Available
EViews 12 Patch Installer
[ Important Note: To determine if your installed EViews is out-of-date, you can compare the “build […]

EViews 12 System requirements
What is EViews 12 ? EViews 12 offers academic researchers, corporations, government agencies, and students access to […]

How to Install TI-Nspire™ CX Premium Teacher Software on your Mac®.
[TI-Inspire™ Premium teacher software installation guide] Download Nspire™ CX Premium Teacher Software for Mac
1.When your download is finished, double-click the […]

Law of Sines and Cosines – Resources for Teachers and Students
[International Mathematics]
The law of sines and cosines are also known as Sine and Cosine rules and these are used […]

Latest Econometric Features in EViews 12
By Numerical
EViews being the #1 best software for Econometric, leaves no feature behind in enhancing your analysis. EViews 12 has […]
How to Download Latest Operating System in TI Nspire CX II
How to Download latest Operating System (OS) 5.2 in your TI Nspire CX II and TI Nspire CX II […]
What’s New in EViews 12?
EViews 12 features a wide range of exciting changes and improvements. What follows is a list of a few […]

How to Disable Press-to-Test Mode Using Student’s Software
Numerical Analytics > [How to Disable Press-to-Test Mode Using Student’s Software]
This blog is guide on “How to Disable Press-to-Test […]

Getting Started With NVivo
NVivo, the best in class for qualitative research is few steps away to be working on your system. As […]

Correlation VS Causation
In economics, variables show various patterns and relationships which can be analyzed through statistics and econometrics. The variables are […]

WhatsApp us
- [email protected]
- "Econometrics || Economic Research || Data Analytics"
+254 786 524680

How to Interpret the Results of a Unit Root Test in Eviews
To interpret the results of a unit root test in EViews, you should consider the test statistic, p-value, and critical values. If the test statistic is less than the critical value, you may reject the null hypothesis of a unit root and conclude that the series is stationary.
The p-value indicates the probability of obtaining a test statistic as extreme as the one observed, assuming the null hypothesis is true. If the p-value is less than the significance level, typically 0.05, you may reject the null hypothesis. EViews provides a variety of unit root testing tools, including the Augmented Dickey-Fuller (ADF) test, HEGY test, Canova and Hansen test, and Variance Ratio tests.
You can run a unit root test by specifying the series and the test type in EViews, such as the ADF test, Phillips-Perron test, or other relevant tests. It’s important to ensure that the series is stationary before performing further analysis, such as time series modeling or forecasting.
You can refer to EViews tutorials and resources available on platforms like YouTube and EViews forums for step-by-step guidance on conducting unit root tests and checking for stationarity in EViews
Data Analytics Services
- Python Data Analysis
- SPSS Data Analysis
- Stata Data Analysis
- EVIEWS Data Analysis
- R Data aAnalysis
Need Our Services?
Econometrics & statistics modelling services.
- Linear Regression
- Probit & Logit Models
- ARIMA Models
- Vector Autoregressive
- Panel Data Models
- Propensity Score Matching
- Principal Component Analysis
- Spatial Econometrics
- Survival Analysis
Stuck with Your Research or Data Analysis Project? L et Our Experts Help You :
Whatsapp us:.

We Make Sense out of your Data
- ""Let Us Help you with Data Analytics & Research""
- Company Overview
- About the CEO
PRIVACY & TOS
- Privacy Policy
- Terms & Conditions

Parameter Estimation and Hypothesis Testing in Linear Models
- © 1999
- Latest edition
- Karl-Rudolf Koch 0
Institute of Theoretical Geodesy of the University of Bonn, Bonn, Germany
You can also search for this author in PubMed Google Scholar
- Based on a course on "Least Squares Adjustment and Statistics"
- The book is self-contained
- Includes supplementary material: sn.pub/extras
583 Citations
3 Altmetric
This is a preview of subscription content, log in via an institution to check access.
Access this book
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
- Durable hardcover edition
Tax calculation will be finalised at checkout
Other ways to access
Licence this eBook for your library
Institutional subscriptions
About this book
Similar content being viewed by others.

Statistical Inference

- Probability distribution
- Probability theory
- analysis of variance
- confidence regions
- hypothesis testing
- linear models
- parameter estimation
Table of contents (5 chapters)
Front matter, introduction.
Karl-Rudolf Koch
Vector and Matrix Algebra
Probability theory, parameter estimation in linear models, hypothesis testing, interval estimation and test for outliers, back matter, authors and affiliations, bibliographic information.
Book Title : Parameter Estimation and Hypothesis Testing in Linear Models
Authors : Karl-Rudolf Koch
DOI : https://doi.org/10.1007/978-3-662-03976-2
Publisher : Springer Berlin, Heidelberg
eBook Packages : Springer Book Archive
Copyright Information : Springer-Verlag Berlin Heidelberg 1999
Hardcover ISBN : 978-3-540-65257-1 Published: 01 April 1999
Softcover ISBN : 978-3-642-08461-4 Published: 07 December 2010
eBook ISBN : 978-3-662-03976-2 Published: 09 March 2013
Edition Number : 2
Number of Pages : XX, 334
Additional Information : Original German edition published by Dümmlers, Bonn
Topics : Probability Theory and Stochastic Processes , Geophysics/Geodesy , Mathematical and Computational Engineering , Statistics for Engineering, Physics, Computer Science, Chemistry and Earth Sciences
- Publish with us
Policies and ethics
- Find a journal
- Track your research
- EViews Help
COMMENTS
EViews will report the results of the Wald test: The low probability values indicate that the null hypothesis that C(4)=2 is strongly rejected. ... The statistic labeled "Obs*R-squared" is the LM test statistic for the null hypothesis of no serial correlation. The (effectively) zero probability value strongly indicates the presence of ...
This video will show you how to do simple hypothesis testing and Equality Test by Classification in eViews.Music By: Bensound
This video covers how to view descriptive statistics (mean, median, standard deviation etc) for singular series and groups. Also covered are a few simple hyp...
1 1. EViews: INTRODUCTION This tutorial will introduce you to a statistical and econometric software package called EViews. The most current professional version is EViews 10 and all output in this tutorial was created using EViews 10. However there is an EViews Student Version Lite that is free for university students, with a license that expires after one year.
Hypothesis testing. Postby monica88 » Wed Jul 10, 2013 9:57 am. I have done OLS estimation with panel data (in a panel workfile) and would like to do some hypothesis testing (I am using EViews 7). A) I need the t-ratio for the hypothesis that the difference between two coefficients is zero (against the hypothesis that the two coefficients differ).
This video is about conducting the multiple regression via eViews. Not only this, hypothesis testing with the help of Wald Test is also conducted which was n...
hypothesis testing. Post by Eoghan » Thu Apr 27, 2017 1:29 am . Hi, I'm trying to test that four variables = 0 against at least one not equaling 0 ... hypothesis testing. Post by EViews Gareth » Thu Apr 27, 2017 1:44 am . From an equation, View->Coefficient Restrictions->Wald Test.
$\begingroup$ I think I don't see some hypothesis testing in your result. There are some tests like the Dickey Fuller or KPSS test but you didn't give the results here. You probably have to state some where in EViews that you want to conduct such a test. Take a look at this youtube video.
Here we have copied the results from EViews at the highest precision to show that the p-value works out to be the same as reported above. 4.2. Test of an economic hypothesis. To test the null hypothesis that β 2 = 12.5 against the alternative β 2 # 12.5 the steps are the same as those above, except for the construction of the t-statistic ...
Apart from descriptive statistics, EViews allows to carry out a number of formal hypothesis tests on a series namely. Simple hypothesis tests - Tests for Mean, median and variance of the series.; Equality Tests by Classification- Tests equality of means, medians and variance across subsamples of a series.; Empirical Distribution Tests- Tests whether the data distribution of the series is ...
A practical guide to selecting and applying the most appropriate model for analysis of cross section data using EViews. This book is a reflection of the vast experience and knowledge of the author. It is a useful reference for students and practitioners dealing with cross sectional data analysis ... The strength of the book lies in its wealth of material and well structured guidelines ...
3) Set a level of significance. 4) Evaluate a test statistic for the hypothesis. 5) Estimate the p-value for the test statistic. The null hypothesis is a statement about a value for the parameter, for which data will be collected to assess. For the parameter of interest μ, the null value is represented μ 0.
To interpret the results of a unit root test in EViews, you should consider the test statistic, p-value, and critical values. If the test statistic is less than the critical value, you may reject the null hypothesis of a unit root and conclude that the series is stationary. The p-value indicates the probability of obtaining a test statistic as ...
The estimate is a realization of the estimator. Example: Estimating the mean. Consider the basic task of estimating the mean of \ (f_1\) from a sample \ (s= (s_1,\ldots ,s_N)\) assumed to be a realization of N independent identically distributed random variables. Typically, statistical inference uses the sample mean.
In this chapter, we discuss methods for estimating parameters and testing hypothe-ses about these parameters. They are interpreted from a frequentist's point of view. Here we discuss only the properties of these methods. This part of parameter esti-mation and hypotheses testing is objective.
Be aware of what containers or utensils come into contact with raw meat and keep clean utensils separate from dirty ones. Refrigerate meat until ready to cook. If you use a cooler, make sure to ...
This second English edition is there fore a translation of the third German edition of Parameter Estimation and Hypothesis Testing in Linear Models, published in 1997. It differs from the first English edition by the addition of a new chapter on robust estimation of parameters and the deletion of the section on discriminant analysis, which ...
The following links provide quick access to summaries of the help command reference material. Using these links is the quickest way of finding all of the relevant EViews commands and functions associated with a general topic such as equations, strings, or statistical distributions.