- History & Society
- Science & Tech
- Biographies
- Animals & Nature
- Geography & Travel
- Arts & Culture
- Games & Quizzes
- On This Day
- One Good Fact
- New Articles
- Lifestyles & Social Issues
- Philosophy & Religion
- Politics, Law & Government
- World History
- Health & Medicine
- Browse Biographies
- Birds, Reptiles & Other Vertebrates
- Bugs, Mollusks & Other Invertebrates
- Environment
- Fossils & Geologic Time
- Entertainment & Pop Culture
- Sports & Recreation
- Visual Arts
- Demystified
- Image Galleries
- Infographics
- Top Questions
- Britannica Kids
- Saving Earth
- Space Next 50
- Student Center
- Introduction

Data collection

data analysis
Our editors will review what you’ve submitted and determine whether to revise the article.
- Academia - Data Analysis
- U.S. Department of Health and Human Services - Office of Research Integrity - Data Analysis
- Chemistry LibreTexts - Data Analysis
- IBM - What is Exploratory Data Analysis?
- Table Of Contents

data analysis , the process of systematically collecting, cleaning, transforming, describing, modeling, and interpreting data , generally employing statistical techniques. Data analysis is an important part of both scientific research and business, where demand has grown in recent years for data-driven decision making . Data analysis techniques are used to gain useful insights from datasets, which can then be used to make operational decisions or guide future research . With the rise of “Big Data,” the storage of vast quantities of data in large databases and data warehouses, there is increasing need to apply data analysis techniques to generate insights about volumes of data too large to be manipulated by instruments of low information-processing capacity.
Datasets are collections of information. Generally, data and datasets are themselves collected to help answer questions, make decisions, or otherwise inform reasoning. The rise of information technology has led to the generation of vast amounts of data of many kinds, such as text, pictures, videos, personal information, account data, and metadata, the last of which provide information about other data. It is common for apps and websites to collect data about how their products are used or about the people using their platforms. Consequently, there is vastly more data being collected today than at any other time in human history. A single business may track billions of interactions with millions of consumers at hundreds of locations with thousands of employees and any number of products. Analyzing that volume of data is generally only possible using specialized computational and statistical techniques.
The desire for businesses to make the best use of their data has led to the development of the field of business intelligence , which covers a variety of tools and techniques that allow businesses to perform data analysis on the information they collect.
For data to be analyzed, it must first be collected and stored. Raw data must be processed into a format that can be used for analysis and be cleaned so that errors and inconsistencies are minimized. Data can be stored in many ways, but one of the most useful is in a database . A database is a collection of interrelated data organized so that certain records (collections of data related to a single entity) can be retrieved on the basis of various criteria . The most familiar kind of database is the relational database , which stores data in tables with rows that represent records (tuples) and columns that represent fields (attributes). A query is a command that retrieves a subset of the information in the database according to certain criteria. A query may retrieve only records that meet certain criteria, or it may join fields from records across multiple tables by use of a common field.
Frequently, data from many sources is collected into large archives of data called data warehouses. The process of moving data from its original sources (such as databases) to a centralized location (generally a data warehouse) is called ETL (which stands for extract , transform , and load ).
- The extraction step occurs when you identify and copy or export the desired data from its source, such as by running a database query to retrieve the desired records.
- The transformation step is the process of cleaning the data so that they fit the analytical need for the data and the schema of the data warehouse. This may involve changing formats for certain fields, removing duplicate records, or renaming fields, among other processes.
- Finally, the clean data are loaded into the data warehouse, where they may join vast amounts of historical data and data from other sources.
After data are effectively collected and cleaned, they can be analyzed with a variety of techniques. Analysis often begins with descriptive and exploratory data analysis. Descriptive data analysis uses statistics to organize and summarize data, making it easier to understand the broad qualities of the dataset. Exploratory data analysis looks for insights into the data that may arise from descriptions of distribution, central tendency, or variability for a single data field. Further relationships between data may become apparent by examining two fields together. Visualizations may be employed during analysis, such as histograms (graphs in which the length of a bar indicates a quantity) or stem-and-leaf plots (which divide data into buckets, or “stems,” with individual data points serving as “leaves” on the stem).
Data analysis frequently goes beyond descriptive analysis to predictive analysis, making predictions about the future using predictive modeling techniques. Predictive modeling uses machine learning , regression analysis methods (which mathematically calculate the relationship between an independent variable and a dependent variable), and classification techniques to identify trends and relationships among variables. Predictive analysis may involve data mining , which is the process of discovering interesting or useful patterns in large volumes of information. Data mining often involves cluster analysis , which tries to find natural groupings within data, and anomaly detection , which detects instances in data that are unusual and stand out from other patterns. It may also look for rules within datasets, strong relationships among variables in the data.
Data Analysis
- Introduction to Data Analysis
- Quantitative Analysis Tools
- Qualitative Analysis Tools
- Mixed Methods Analysis
- Geospatial Analysis
- Further Reading

What is Data Analysis?
According to the federal government, data analysis is "the process of systematically applying statistical and/or logical techniques to describe and illustrate, condense and recap, and evaluate data" ( Responsible Conduct in Data Management ). Important components of data analysis include searching for patterns, remaining unbiased in drawing inference from data, practicing responsible data management , and maintaining "honest and accurate analysis" ( Responsible Conduct in Data Management ).
In order to understand data analysis further, it can be helpful to take a step back and understand the question "What is data?". Many of us associate data with spreadsheets of numbers and values, however, data can encompass much more than that. According to the federal government, data is "The recorded factual material commonly accepted in the scientific community as necessary to validate research findings" ( OMB Circular 110 ). This broad definition can include information in many formats.
Some examples of types of data are as follows:
- Photographs
- Hand-written notes from field observation
- Machine learning training data sets
- Ethnographic interview transcripts
- Sheet music
- Scripts for plays and musicals
- Observations from laboratory experiments ( CMU Data 101 )
Thus, data analysis includes the processing and manipulation of these data sources in order to gain additional insight from data, answer a research question, or confirm a research hypothesis.
Data analysis falls within the larger research data lifecycle, as seen below.
( University of Virginia )
Why Analyze Data?
Through data analysis, a researcher can gain additional insight from data and draw conclusions to address the research question or hypothesis. Use of data analysis tools helps researchers understand and interpret data.
What are the Types of Data Analysis?
Data analysis can be quantitative, qualitative, or mixed methods.
Quantitative research typically involves numbers and "close-ended questions and responses" ( Creswell & Creswell, 2018 , p. 3). Quantitative research tests variables against objective theories, usually measured and collected on instruments and analyzed using statistical procedures ( Creswell & Creswell, 2018 , p. 4). Quantitative analysis usually uses deductive reasoning.
Qualitative research typically involves words and "open-ended questions and responses" ( Creswell & Creswell, 2018 , p. 3). According to Creswell & Creswell, "qualitative research is an approach for exploring and understanding the meaning individuals or groups ascribe to a social or human problem" ( 2018 , p. 4). Thus, qualitative analysis usually invokes inductive reasoning.
Mixed methods research uses methods from both quantitative and qualitative research approaches. Mixed methods research works under the "core assumption... that the integration of qualitative and quantitative data yields additional insight beyond the information provided by either the quantitative or qualitative data alone" ( Creswell & Creswell, 2018 , p. 4).
- Next: Planning >>
- Last Updated: Jun 25, 2024 10:23 AM
- URL: https://guides.library.georgetown.edu/data-analysis
- Privacy Policy
Home » Data Analysis – Process, Methods and Types
Data Analysis – Process, Methods and Types
Table of Contents

Data Analysis
Definition:
Data analysis refers to the process of inspecting, cleaning, transforming, and modeling data with the goal of discovering useful information, drawing conclusions, and supporting decision-making. It involves applying various statistical and computational techniques to interpret and derive insights from large datasets. The ultimate aim of data analysis is to convert raw data into actionable insights that can inform business decisions, scientific research, and other endeavors.
Data Analysis Process
The following are step-by-step guides to the data analysis process:
Define the Problem
The first step in data analysis is to clearly define the problem or question that needs to be answered. This involves identifying the purpose of the analysis, the data required, and the intended outcome.
Collect the Data
The next step is to collect the relevant data from various sources. This may involve collecting data from surveys, databases, or other sources. It is important to ensure that the data collected is accurate, complete, and relevant to the problem being analyzed.
Clean and Organize the Data
Once the data has been collected, it needs to be cleaned and organized. This involves removing any errors or inconsistencies in the data, filling in missing values, and ensuring that the data is in a format that can be easily analyzed.
Analyze the Data
The next step is to analyze the data using various statistical and analytical techniques. This may involve identifying patterns in the data, conducting statistical tests, or using machine learning algorithms to identify trends and insights.
Interpret the Results
After analyzing the data, the next step is to interpret the results. This involves drawing conclusions based on the analysis and identifying any significant findings or trends.
Communicate the Findings
Once the results have been interpreted, they need to be communicated to stakeholders. This may involve creating reports, visualizations, or presentations to effectively communicate the findings and recommendations.
Take Action
The final step in the data analysis process is to take action based on the findings. This may involve implementing new policies or procedures, making strategic decisions, or taking other actions based on the insights gained from the analysis.
Types of Data Analysis
Types of Data Analysis are as follows:
Descriptive Analysis
This type of analysis involves summarizing and describing the main characteristics of a dataset, such as the mean, median, mode, standard deviation, and range.
Inferential Analysis
This type of analysis involves making inferences about a population based on a sample. Inferential analysis can help determine whether a certain relationship or pattern observed in a sample is likely to be present in the entire population.
Diagnostic Analysis
This type of analysis involves identifying and diagnosing problems or issues within a dataset. Diagnostic analysis can help identify outliers, errors, missing data, or other anomalies in the dataset.
Predictive Analysis
This type of analysis involves using statistical models and algorithms to predict future outcomes or trends based on historical data. Predictive analysis can help businesses and organizations make informed decisions about the future.
Prescriptive Analysis
This type of analysis involves recommending a course of action based on the results of previous analyses. Prescriptive analysis can help organizations make data-driven decisions about how to optimize their operations, products, or services.
Exploratory Analysis
This type of analysis involves exploring the relationships and patterns within a dataset to identify new insights and trends. Exploratory analysis is often used in the early stages of research or data analysis to generate hypotheses and identify areas for further investigation.
Data Analysis Methods
Data Analysis Methods are as follows:
Statistical Analysis
This method involves the use of mathematical models and statistical tools to analyze and interpret data. It includes measures of central tendency, correlation analysis, regression analysis, hypothesis testing, and more.
Machine Learning
This method involves the use of algorithms to identify patterns and relationships in data. It includes supervised and unsupervised learning, classification, clustering, and predictive modeling.
Data Mining
This method involves using statistical and machine learning techniques to extract information and insights from large and complex datasets.
Text Analysis
This method involves using natural language processing (NLP) techniques to analyze and interpret text data. It includes sentiment analysis, topic modeling, and entity recognition.
Network Analysis
This method involves analyzing the relationships and connections between entities in a network, such as social networks or computer networks. It includes social network analysis and graph theory.
Time Series Analysis
This method involves analyzing data collected over time to identify patterns and trends. It includes forecasting, decomposition, and smoothing techniques.
Spatial Analysis
This method involves analyzing geographic data to identify spatial patterns and relationships. It includes spatial statistics, spatial regression, and geospatial data visualization.
Data Visualization
This method involves using graphs, charts, and other visual representations to help communicate the findings of the analysis. It includes scatter plots, bar charts, heat maps, and interactive dashboards.
Qualitative Analysis
This method involves analyzing non-numeric data such as interviews, observations, and open-ended survey responses. It includes thematic analysis, content analysis, and grounded theory.
Multi-criteria Decision Analysis
This method involves analyzing multiple criteria and objectives to support decision-making. It includes techniques such as the analytical hierarchy process, TOPSIS, and ELECTRE.
Data Analysis Tools
There are various data analysis tools available that can help with different aspects of data analysis. Below is a list of some commonly used data analysis tools:
- Microsoft Excel: A widely used spreadsheet program that allows for data organization, analysis, and visualization.
- SQL : A programming language used to manage and manipulate relational databases.
- R : An open-source programming language and software environment for statistical computing and graphics.
- Python : A general-purpose programming language that is widely used in data analysis and machine learning.
- Tableau : A data visualization software that allows for interactive and dynamic visualizations of data.
- SAS : A statistical analysis software used for data management, analysis, and reporting.
- SPSS : A statistical analysis software used for data analysis, reporting, and modeling.
- Matlab : A numerical computing software that is widely used in scientific research and engineering.
- RapidMiner : A data science platform that offers a wide range of data analysis and machine learning tools.
Applications of Data Analysis
Data analysis has numerous applications across various fields. Below are some examples of how data analysis is used in different fields:
- Business : Data analysis is used to gain insights into customer behavior, market trends, and financial performance. This includes customer segmentation, sales forecasting, and market research.
- Healthcare : Data analysis is used to identify patterns and trends in patient data, improve patient outcomes, and optimize healthcare operations. This includes clinical decision support, disease surveillance, and healthcare cost analysis.
- Education : Data analysis is used to measure student performance, evaluate teaching effectiveness, and improve educational programs. This includes assessment analytics, learning analytics, and program evaluation.
- Finance : Data analysis is used to monitor and evaluate financial performance, identify risks, and make investment decisions. This includes risk management, portfolio optimization, and fraud detection.
- Government : Data analysis is used to inform policy-making, improve public services, and enhance public safety. This includes crime analysis, disaster response planning, and social welfare program evaluation.
- Sports : Data analysis is used to gain insights into athlete performance, improve team strategy, and enhance fan engagement. This includes player evaluation, scouting analysis, and game strategy optimization.
- Marketing : Data analysis is used to measure the effectiveness of marketing campaigns, understand customer behavior, and develop targeted marketing strategies. This includes customer segmentation, marketing attribution analysis, and social media analytics.
- Environmental science : Data analysis is used to monitor and evaluate environmental conditions, assess the impact of human activities on the environment, and develop environmental policies. This includes climate modeling, ecological forecasting, and pollution monitoring.
When to Use Data Analysis
Data analysis is useful when you need to extract meaningful insights and information from large and complex datasets. It is a crucial step in the decision-making process, as it helps you understand the underlying patterns and relationships within the data, and identify potential areas for improvement or opportunities for growth.
Here are some specific scenarios where data analysis can be particularly helpful:
- Problem-solving : When you encounter a problem or challenge, data analysis can help you identify the root cause and develop effective solutions.
- Optimization : Data analysis can help you optimize processes, products, or services to increase efficiency, reduce costs, and improve overall performance.
- Prediction: Data analysis can help you make predictions about future trends or outcomes, which can inform strategic planning and decision-making.
- Performance evaluation : Data analysis can help you evaluate the performance of a process, product, or service to identify areas for improvement and potential opportunities for growth.
- Risk assessment : Data analysis can help you assess and mitigate risks, whether it is financial, operational, or related to safety.
- Market research : Data analysis can help you understand customer behavior and preferences, identify market trends, and develop effective marketing strategies.
- Quality control: Data analysis can help you ensure product quality and customer satisfaction by identifying and addressing quality issues.
Purpose of Data Analysis
The primary purposes of data analysis can be summarized as follows:
- To gain insights: Data analysis allows you to identify patterns and trends in data, which can provide valuable insights into the underlying factors that influence a particular phenomenon or process.
- To inform decision-making: Data analysis can help you make informed decisions based on the information that is available. By analyzing data, you can identify potential risks, opportunities, and solutions to problems.
- To improve performance: Data analysis can help you optimize processes, products, or services by identifying areas for improvement and potential opportunities for growth.
- To measure progress: Data analysis can help you measure progress towards a specific goal or objective, allowing you to track performance over time and adjust your strategies accordingly.
- To identify new opportunities: Data analysis can help you identify new opportunities for growth and innovation by identifying patterns and trends that may not have been visible before.
Examples of Data Analysis
Some Examples of Data Analysis are as follows:
- Social Media Monitoring: Companies use data analysis to monitor social media activity in real-time to understand their brand reputation, identify potential customer issues, and track competitors. By analyzing social media data, businesses can make informed decisions on product development, marketing strategies, and customer service.
- Financial Trading: Financial traders use data analysis to make real-time decisions about buying and selling stocks, bonds, and other financial instruments. By analyzing real-time market data, traders can identify trends and patterns that help them make informed investment decisions.
- Traffic Monitoring : Cities use data analysis to monitor traffic patterns and make real-time decisions about traffic management. By analyzing data from traffic cameras, sensors, and other sources, cities can identify congestion hotspots and make changes to improve traffic flow.
- Healthcare Monitoring: Healthcare providers use data analysis to monitor patient health in real-time. By analyzing data from wearable devices, electronic health records, and other sources, healthcare providers can identify potential health issues and provide timely interventions.
- Online Advertising: Online advertisers use data analysis to make real-time decisions about advertising campaigns. By analyzing data on user behavior and ad performance, advertisers can make adjustments to their campaigns to improve their effectiveness.
- Sports Analysis : Sports teams use data analysis to make real-time decisions about strategy and player performance. By analyzing data on player movement, ball position, and other variables, coaches can make informed decisions about substitutions, game strategy, and training regimens.
- Energy Management : Energy companies use data analysis to monitor energy consumption in real-time. By analyzing data on energy usage patterns, companies can identify opportunities to reduce energy consumption and improve efficiency.
Characteristics of Data Analysis
Characteristics of Data Analysis are as follows:
- Objective : Data analysis should be objective and based on empirical evidence, rather than subjective assumptions or opinions.
- Systematic : Data analysis should follow a systematic approach, using established methods and procedures for collecting, cleaning, and analyzing data.
- Accurate : Data analysis should produce accurate results, free from errors and bias. Data should be validated and verified to ensure its quality.
- Relevant : Data analysis should be relevant to the research question or problem being addressed. It should focus on the data that is most useful for answering the research question or solving the problem.
- Comprehensive : Data analysis should be comprehensive and consider all relevant factors that may affect the research question or problem.
- Timely : Data analysis should be conducted in a timely manner, so that the results are available when they are needed.
- Reproducible : Data analysis should be reproducible, meaning that other researchers should be able to replicate the analysis using the same data and methods.
- Communicable : Data analysis should be communicated clearly and effectively to stakeholders and other interested parties. The results should be presented in a way that is understandable and useful for decision-making.
Advantages of Data Analysis
Advantages of Data Analysis are as follows:
- Better decision-making: Data analysis helps in making informed decisions based on facts and evidence, rather than intuition or guesswork.
- Improved efficiency: Data analysis can identify inefficiencies and bottlenecks in business processes, allowing organizations to optimize their operations and reduce costs.
- Increased accuracy: Data analysis helps to reduce errors and bias, providing more accurate and reliable information.
- Better customer service: Data analysis can help organizations understand their customers better, allowing them to provide better customer service and improve customer satisfaction.
- Competitive advantage: Data analysis can provide organizations with insights into their competitors, allowing them to identify areas where they can gain a competitive advantage.
- Identification of trends and patterns : Data analysis can identify trends and patterns in data that may not be immediately apparent, helping organizations to make predictions and plan for the future.
- Improved risk management : Data analysis can help organizations identify potential risks and take proactive steps to mitigate them.
- Innovation: Data analysis can inspire innovation and new ideas by revealing new opportunities or previously unknown correlations in data.
Limitations of Data Analysis
- Data quality: The quality of data can impact the accuracy and reliability of analysis results. If data is incomplete, inconsistent, or outdated, the analysis may not provide meaningful insights.
- Limited scope: Data analysis is limited by the scope of the data available. If data is incomplete or does not capture all relevant factors, the analysis may not provide a complete picture.
- Human error : Data analysis is often conducted by humans, and errors can occur in data collection, cleaning, and analysis.
- Cost : Data analysis can be expensive, requiring specialized tools, software, and expertise.
- Time-consuming : Data analysis can be time-consuming, especially when working with large datasets or conducting complex analyses.
- Overreliance on data: Data analysis should be complemented with human intuition and expertise. Overreliance on data can lead to a lack of creativity and innovation.
- Privacy concerns: Data analysis can raise privacy concerns if personal or sensitive information is used without proper consent or security measures.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Conceptual Framework – Types, Methodology and...

Context of the Study – Writing Guide and Examples

Cluster Analysis – Types, Methods and Examples

Informed Consent in Research – Types, Templates...

Research Methodology – Types, Examples and...

Research Problem – Examples, Types and Guide

What is Data Analysis? (Types, Methods, and Tools)

- Couchbase Product Marketing December 17, 2023
Data analysis is the process of cleaning, transforming, and interpreting data to uncover insights, patterns, and trends. It plays a crucial role in decision making, problem solving, and driving innovation across various domains.
In addition to further exploring the role data analysis plays this blog post will discuss common data analysis techniques, delve into the distinction between quantitative and qualitative data, explore popular data analysis tools, and discuss the steps involved in the data analysis process.
By the end, you should have a deeper understanding of data analysis and its applications, empowering you to harness the power of data to make informed decisions and gain actionable insights.
Why is Data Analysis Important?
Data analysis is important across various domains and industries. It helps with:
- Decision Making : Data analysis provides valuable insights that support informed decision making, enabling organizations to make data-driven choices for better outcomes.
- Problem Solving : Data analysis helps identify and solve problems by uncovering root causes, detecting anomalies, and optimizing processes for increased efficiency.
- Performance Evaluation : Data analysis allows organizations to evaluate performance, track progress, and measure success by analyzing key performance indicators (KPIs) and other relevant metrics.
- Gathering Insights : Data analysis uncovers valuable insights that drive innovation, enabling businesses to develop new products, services, and strategies aligned with customer needs and market demand.
- Risk Management : Data analysis helps mitigate risks by identifying risk factors and enabling proactive measures to minimize potential negative impacts.
By leveraging data analysis, organizations can gain a competitive advantage, improve operational efficiency, and make smarter decisions that positively impact the bottom line.
Quantitative vs. Qualitative Data
In data analysis, you’ll commonly encounter two types of data: quantitative and qualitative. Understanding the differences between these two types of data is essential for selecting appropriate analysis methods and drawing meaningful insights. Here’s an overview of quantitative and qualitative data:
Quantitative Data
Quantitative data is numerical and represents quantities or measurements. It’s typically collected through surveys, experiments, and direct measurements. This type of data is characterized by its ability to be counted, measured, and subjected to mathematical calculations. Examples of quantitative data include age, height, sales figures, test scores, and the number of website users.
Quantitative data has the following characteristics:
- Numerical : Quantitative data is expressed in numerical values that can be analyzed and manipulated mathematically.
- Objective : Quantitative data is objective and can be measured and verified independently of individual interpretations.
- Statistical Analysis : Quantitative data lends itself well to statistical analysis. It allows for applying various statistical techniques, such as descriptive statistics, correlation analysis, regression analysis, and hypothesis testing.
- Generalizability : Quantitative data often aims to generalize findings to a larger population. It allows for making predictions, estimating probabilities, and drawing statistical inferences.
Qualitative Data
Qualitative data, on the other hand, is non-numerical and is collected through interviews, observations, and open-ended survey questions. It focuses on capturing rich, descriptive, and subjective information to gain insights into people’s opinions, attitudes, experiences, and behaviors. Examples of qualitative data include interview transcripts, field notes, survey responses, and customer feedback.
Qualitative data has the following characteristics:
- Descriptive : Qualitative data provides detailed descriptions, narratives, or interpretations of phenomena, often capturing context, emotions, and nuances.
- Subjective : Qualitative data is subjective and influenced by the individuals’ perspectives, experiences, and interpretations.
- Interpretive Analysis : Qualitative data requires interpretive techniques, such as thematic analysis, content analysis, and discourse analysis, to uncover themes, patterns, and underlying meanings.
- Contextual Understanding : Qualitative data emphasizes understanding the social, cultural, and contextual factors that shape individuals’ experiences and behaviors.
- Rich Insights : Qualitative data enables researchers to gain in-depth insights into complex phenomena and explore research questions in greater depth.
In summary, quantitative data represents numerical quantities and lends itself well to statistical analysis, while qualitative data provides rich, descriptive insights into subjective experiences and requires interpretive analysis techniques. Understanding the differences between quantitative and qualitative data is crucial for selecting appropriate analysis methods and drawing meaningful conclusions in research and data analysis.
Types of Data Analysis
Different types of data analysis techniques serve different purposes. In this section, we’ll explore four types of data analysis: descriptive, diagnostic, predictive, and prescriptive, and go over how you can use them.
Descriptive Analysis
Descriptive analysis involves summarizing and describing the main characteristics of a dataset. It focuses on gaining a comprehensive understanding of the data through measures such as central tendency (mean, median, mode), dispersion (variance, standard deviation), and graphical representations (histograms, bar charts). For example, in a retail business, descriptive analysis may involve analyzing sales data to identify average monthly sales, popular products, or sales distribution across different regions.
Diagnostic Analysis
Diagnostic analysis aims to understand the causes or factors influencing specific outcomes or events. It involves investigating relationships between variables and identifying patterns or anomalies in the data. Diagnostic analysis often uses regression analysis, correlation analysis, and hypothesis testing to uncover the underlying reasons behind observed phenomena. For example, in healthcare, diagnostic analysis could help determine factors contributing to patient readmissions and identify potential improvements in the care process.
Predictive Analysis
Predictive analysis focuses on making predictions or forecasts about future outcomes based on historical data. It utilizes statistical models, machine learning algorithms, and time series analysis to identify patterns and trends in the data. By applying predictive analysis, businesses can anticipate customer behavior, market trends, or demand for products and services. For example, an e-commerce company might use predictive analysis to forecast customer churn and take proactive measures to retain customers.
Prescriptive Analysis
Prescriptive analysis takes predictive analysis a step further by providing recommendations or optimal solutions based on the predicted outcomes. It combines historical and real-time data with optimization techniques, simulation models, and decision-making algorithms to suggest the best course of action. Prescriptive analysis helps organizations make data-driven decisions and optimize their strategies. For example, a logistics company can use prescriptive analysis to determine the most efficient delivery routes, considering factors like traffic conditions, fuel costs, and customer preferences.
In summary, data analysis plays a vital role in extracting insights and enabling informed decision making. Descriptive analysis helps understand the data, diagnostic analysis uncovers the underlying causes, predictive analysis forecasts future outcomes, and prescriptive analysis provides recommendations for optimal actions. These different data analysis techniques are valuable tools for businesses and organizations across various industries.
Data Analysis Methods
In addition to the data analysis types discussed earlier, you can use various methods to analyze data effectively. These methods provide a structured approach to extract insights, detect patterns, and derive meaningful conclusions from the available data. Here are some commonly used data analysis methods:
Statistical Analysis
Statistical analysis involves applying statistical techniques to data to uncover patterns, relationships, and trends. It includes methods such as hypothesis testing, regression analysis, analysis of variance (ANOVA), and chi-square tests. Statistical analysis helps organizations understand the significance of relationships between variables and make inferences about the population based on sample data. For example, a market research company could conduct a survey to analyze the relationship between customer satisfaction and product price. They can use regression analysis to determine whether there is a significant correlation between these variables.
Data Mining
Data mining refers to the process of discovering patterns and relationships in large datasets using techniques such as clustering, classification, association analysis, and anomaly detection. It involves exploring data to identify hidden patterns and gain valuable insights. For example, a telecommunications company could analyze customer call records to identify calling patterns and segment customers into groups based on their calling behavior.
Text Mining
Text mining involves analyzing unstructured data , such as customer reviews, social media posts, or emails, to extract valuable information and insights. It utilizes techniques like natural language processing (NLP), sentiment analysis, and topic modeling to analyze and understand textual data. For example, consider how a hotel chain might analyze customer reviews from various online platforms to identify common themes and sentiment patterns to improve customer satisfaction.
Time Series Analysis
Time series analysis focuses on analyzing data collected over time to identify trends, seasonality, and patterns. It involves techniques such as forecasting, decomposition, and autocorrelation analysis to make predictions and understand the underlying patterns in the data.
For example, an energy company could analyze historical electricity consumption data to forecast future demand and optimize energy generation and distribution.
Data Visualization
Data visualization is the graphical representation of data to communicate patterns, trends, and insights visually. It uses charts, graphs, maps, and other visual elements to present data in a visually appealing and easily understandable format. For example, a sales team might use a line chart to visualize monthly sales trends and identify seasonal patterns in their sales data.
These are just a few examples of the data analysis methods you can use. Your choice should depend on the nature of the data, the research question or problem, and the desired outcome.
How to Analyze Data
Analyzing data involves following a systematic approach to extract insights and derive meaningful conclusions. Here are some steps to guide you through the process of analyzing data effectively:
Define the Objective : Clearly define the purpose and objective of your data analysis. Identify the specific question or problem you want to address through analysis.
Prepare and Explore the Data : Gather the relevant data and ensure its quality. Clean and preprocess the data by handling missing values, duplicates, and formatting issues. Explore the data using descriptive statistics and visualizations to identify patterns, outliers, and relationships.
Apply Analysis Techniques : Choose the appropriate analysis techniques based on your data and research question. Apply statistical methods, machine learning algorithms, and other analytical tools to derive insights and answer your research question.
Interpret the Results : Analyze the output of your analysis and interpret the findings in the context of your objective. Identify significant patterns, trends, and relationships in the data. Consider the implications and practical relevance of the results.
Communicate and Take Action : Communicate your findings effectively to stakeholders or intended audiences. Present the results clearly and concisely, using visualizations and reports. Use the insights from the analysis to inform decision making.
Remember, data analysis is an iterative process, and you may need to revisit and refine your analysis as you progress. These steps provide a general framework to guide you through the data analysis process and help you derive meaningful insights from your data.
Data Analysis Tools
Data analysis tools are software applications and platforms designed to facilitate the process of analyzing and interpreting data . These tools provide a range of functionalities to handle data manipulation, visualization, statistical analysis, and machine learning. Here are some commonly used data analysis tools:
Spreadsheet Software
Tools like Microsoft Excel, Google Sheets, and Apple Numbers are used for basic data analysis tasks. They offer features for data entry, manipulation, basic statistical functions, and simple visualizations.
Business Intelligence (BI) Platforms
BI platforms like Microsoft Power BI, Tableau, and Looker integrate data from multiple sources, providing comprehensive views of business performance through interactive dashboards, reports, and ad hoc queries.
Programming Languages and Libraries
Programming languages like R and Python, along with their associated libraries (e.g., NumPy, SciPy, scikit-learn), offer extensive capabilities for data analysis. They provide flexibility, customizability, and access to a wide range of statistical and machine-learning algorithms.
Cloud-Based Analytics Platforms
Cloud-based platforms like Google Cloud Platform (BigQuery, Data Studio), Microsoft Azure (Azure Analytics, Power BI), and Amazon Web Services (AWS Analytics, QuickSight) provide scalable and collaborative environments for data storage, processing, and analysis. They have a wide range of analytical capabilities for handling large datasets.
Data Mining and Machine Learning Tools
Tools like RapidMiner, KNIME, and Weka automate the process of data preprocessing, feature selection, model training, and evaluation. They’re designed to extract insights and build predictive models from complex datasets.
Text Analytics Tools
Text analytics tools, such as Natural Language Processing (NLP) libraries in Python (NLTK, spaCy) or platforms like RapidMiner Text Mining Extension, enable the analysis of unstructured text data . They help extract information, sentiment, and themes from sources like customer reviews or social media.
Choosing the right data analysis tool depends on analysis complexity, dataset size, required functionalities, and user expertise. You might need to use a combination of tools to leverage their combined strengths and address specific analysis needs.
By understanding the power of data analysis, you can leverage it to make informed decisions, identify opportunities for improvement, and drive innovation within your organization. Whether you’re working with quantitative data for statistical analysis or qualitative data for in-depth insights, it’s important to select the right analysis techniques and tools for your objectives.
To continue learning about data analysis, review the following resources:
- What is Big Data Analytics?
- Operational Analytics
- JSON Analytics + Real-Time Insights
- Database vs. Data Warehouse: Differences, Use Cases, Examples
- Couchbase Capella Columnar Product Blog
- Posted in: Analytics , Application Design , Best Practices and Tutorials
- Tagged in: data analytics , data visualization , time series
Posted by Couchbase Product Marketing
Leave a reply cancel reply.
You must be logged in to post a comment.
Check your inbox or spam folder to confirm your subscription.
Advancing Big Data Best Practices
- Why the Enterprise Big Data Framework Alliance?
- What We Offer
- Enterprise Big Data Framework
Learn about indivual memberships.

Learn about enterprise memberships.

Learn about Educator Memberships

- Memberships
Certifications
Enterprise Big Data Professional (EBDP®)
Enterprise Big Data Analyst (EBDA®)
Enterprise Big Data Scientist (EBDS®)
Enterprise Big Data Engineer (EBDE®)
Enterprise Big Data Architect (EBDAR®)
Certificates
Data Literacy Fundamentals
Data Governance Fundamentals
Data Management Fundamentals
Data Security & Privacy Fundamentals
Training & Exams
Certification Overview
Enterprise Big Data Professional
Enterprise Big Data Analyst
Enterprise Big Data Scientist
Enterprise Big Data Engineer
Enterprise Big Data Architect
Ambassador Program
Learn about the EBDFA Ambassador Program
Academic Partners
Learn about the terms and benefits of the EBDFA Academic Partner Program
Training Partners
Learn how to become an Accredited Training Organization
Corporate Partners
Join the Corporate Partner Program and connect with the EBDFA community.
Partnerships
Become an Ambassador
- Become an Academic Partner New
- Become a Corporate Partner
Become a Training Partner
- Find a Training Partner
- Blog & Big Data News
- Big Data Events & Webinars
Big Data Days 2024
Big Data Knowledge Base
Big Data Talks Podcast
- Free Downloads & Store
What is Data Analysis? An Introductory Guide
The data analysis process, key data analysis skills, start your journey into data analysis with the official enterpise big data analyst certification, data analysis examples in the enterprise, frequently asked questions (faqs).

Data analysis is the process of inspecting, cleaning, transforming, and modeling data to derive meaningful insights and make informed decisions. It involves examining raw data to identify patterns, trends, and relationships that can be used to understand various aspects of a business, organization, or phenomenon. This process often employs statistical methods, machine learning algorithms, and data visualization techniques to extract valuable information from data sets.
At its core, data analysis aims to answer questions, solve problems, and support decision-making processes. It helps uncover hidden patterns or correlations within data that may not be immediately apparent, leading to actionable insights that can drive business strategies and improve performance. Whether it’s analyzing sales figures to identify market trends, evaluating customer feedback to enhance products or services, or studying medical data to improve patient outcomes, data analysis plays a crucial role in numerous domains.
Effective data analysis requires not only technical skills but also domain knowledge and critical thinking. Analysts must understand the context in which the data is generated, choose appropriate analytical tools and methods, and interpret results accurately to draw meaningful conclusions. Moreover, data analysis is an iterative process that may involve refining hypotheses, collecting additional data, and revisiting analytical techniques to ensure the validity and reliability of findings.
Why spend time to learn data analysis?
Learning about data analysis is beneficial for your career because it equips you with the skills to make data-driven decisions, which are highly valued in today’s data-centric business environment. Employers increasingly seek professionals who can gather, analyze, and interpret data to drive innovation, optimize processes, and achieve strategic objectives.
The data analysis process is a systematic approach to extracting valuable insights and making informed decisions from raw data. It begins with defining the problem or question at hand, followed by collecting and cleaning the relevant data. Exploratory data analysis (EDA) helps in understanding the data’s characteristics and uncovering patterns, while data modeling and analysis apply statistical or machine learning techniques to derive meaningful conclusions. In most organizations, data analysis is structured in a number of steps:
- Define the Problem or Question: The first step is to clearly define the problem or question you want to address through data analysis. This could involve understanding business objectives, identifying research questions, or defining hypotheses to be tested.
- Data Collection: Once the problem is defined, gather relevant data from various sources. This could include structured data from databases, spreadsheets, or surveys, as well as unstructured data like text documents or social media posts.
- Data Cleaning and Preprocessing: Clean and preprocess the data to ensure its quality and reliability. This step involves handling missing values, removing duplicates, standardizing formats, and transforming data if needed (e.g., scaling numerical data, encoding categorical variables).
- Exploratory Data Analysis (EDA): Explore the data through descriptive statistics, visualizations (e.g., histograms, scatter plots, heatmaps), and data profiling techniques. EDA helps in understanding the distribution of variables, detecting outliers, and identifying patterns or trends.
- Data Modeling and Analysis: Apply appropriate statistical or machine learning models to analyze the data and answer the research questions or address the problem. This step may involve hypothesis testing, regression analysis, clustering, classification, or other analytical techniques depending on the nature of the data and objectives.
- Interpretation of Results: Interpret the findings from the data analysis in the context of the problem or question. Determine the significance of results, draw conclusions, and communicate insights effectively.
- Decision Making and Action: Use the insights gained from data analysis to make informed decisions, develop strategies, or take actions that drive positive outcomes. Monitor the impact of these decisions and iterate the analysis process as needed.
- Communication and Reporting: Present the findings and insights derived from data analysis in a clear and understandable manner to stakeholders, using visualizations, dashboards, reports, or presentations. Effective communication ensures that the analysis results are actionable and contribute to informed decision-making.
These steps form a cyclical process, where feedback from decision-making may lead to revisiting earlier stages, refining the analysis, and continuously improving outcomes.
Key data analysis skills encompass a blend of technical expertise, critical thinking, and domain knowledge. Some of the essential skills for effective data analysis include:
Statistical Knowledge: Understanding statistical concepts and methods such as hypothesis testing, regression analysis, probability distributions, and statistical inference is fundamental for data analysis.
Data Manipulation and Cleaning: Proficiency in tools like Python, R, SQL, or Excel for data manipulation, cleaning, and transformation tasks, including handling missing values, removing duplicates, and standardizing data formats.
Data Visualization: Creating clear and insightful visualizations using tools like Matplotlib, Seaborn, Tableau, or Power BI to communicate trends, patterns, and relationships within data to non-technical stakeholders.
Machine Learning: Familiarity with machine learning algorithms such as decision trees, random forests, logistic regression, clustering, and neural networks for predictive modeling, classification, clustering, and anomaly detection tasks.
Programming Skills: Competence in programming languages such as Python, R, or SQL for data analysis, scripting, automation, and building data pipelines, along with version control using Git.
Critical Thinking: Ability to think critically, ask relevant questions, formulate hypotheses, and design robust analytical approaches to solve complex problems and extract actionable insights from data.
Domain Knowledge: Understanding the context and domain-specific nuances of the data being analyzed, whether it’s finance, healthcare, marketing, or any other industry, is crucial for meaningful interpretation and decision-making.
Data Ethics and Privacy: Awareness of data ethics principles , privacy regulations (e.g., GDPR, CCPA), and best practices for handling sensitive data responsibly and ensuring data security and confidentiality.
Communication and Storytelling: Effectively communicating analysis results through clear reports, presentations, and data-driven storytelling to convey insights, recommendations, and implications to diverse audiences, including non-technical stakeholders.
These skills are crucial in data analysis because they empower analysts to effectively extract, interpret, and communicate insights from complex datasets across various domains. Statistical knowledge forms the foundation for making data-driven decisions and drawing reliable conclusions. Proficiency in data manipulation and cleaning ensures data accuracy and consistency, essential for meaningful analysis. Here

The Enterprise Big Data Analyst certification is aimed at Data Analyst and provides in-depth theory and practical guidance to deduce value out of Big Data sets. The curriculum segments between different kinds of Big Data problems and its corresponding solutions. This course will teach participants how to autonomously find valuable insights in large data sets in order to realize business benefits.
Data analysis plays an important role in driving informed decision-making and strategic planning within enterprises across various industries. By harnessing the power of data, organizations can gain valuable insights into market trends, customer behaviors, operational efficiency, and performance metrics. Data analysis enables businesses to identify opportunities for growth, optimize processes, mitigate risks, and enhance overall competitiveness in the market. Examples of data analysis in the enterprise span a wide range of applications, including sales and marketing optimization, customer segmentation, financial forecasting, supply chain management, fraud detection, and healthcare analytics.
- Sales and Marketing Optimization: Enterprises use data analysis to analyze sales trends, customer preferences, and marketing campaign effectiveness. By leveraging techniques like customer segmentation and predictive modeling, businesses can tailor marketing strategies, optimize pricing strategies, and identify cross-selling or upselling opportunities.
- Customer Segmentation: Data analysis helps enterprises segment customers based on demographics, purchasing behavior, and preferences. This segmentation allows for targeted marketing efforts, personalized customer experiences, and improved customer retention and loyalty.
- Financial Forecasting: Data analysis is used in financial forecasting to analyze historical data, identify trends, and predict future financial performance. This helps businesses make informed decisions regarding budgeting, investment strategies, and risk management.
- Supply Chain Management: Enterprises use data analysis to optimize supply chain operations, improve inventory management, reduce lead times, and enhance overall efficiency. Analyzing supply chain data helps identify bottlenecks, forecast demand, and streamline logistics processes.
- Fraud Detection: Data analysis is employed to detect and prevent fraud in financial transactions, insurance claims, and online activities. By analyzing patterns and anomalies in data, enterprises can identify suspicious activities, mitigate risks, and protect against fraudulent behavior.
- Healthcare Analytics: In the healthcare sector, data analysis is used for patient care optimization, disease prediction, treatment effectiveness evaluation, and resource allocation. Analyzing healthcare data helps improve patient outcomes, reduce healthcare costs, and support evidence-based decision-making.
These examples illustrate how data analysis is a vital tool for enterprises to gain actionable insights, improve decision-making processes, and achieve strategic objectives across diverse areas of business operations.
Below are some of the most frequently asked questions about data analysis and their answers:
What role does domain knowledge play in data analysis?
Domain knowledge is crucial as it provides context, understanding of data nuances, insights into relevant variables and metrics, and helps in interpreting results accurately within specific industries or domains.
How do you ensure the quality and accuracy of data for analysis?
Ensuring data quality and accuracy involves data validation, cleaning techniques like handling missing values and outliers, standardizing data formats, performing data integrity checks, and validating results through cross-validation or data audits.
What tools and techniques are commonly used in data analysis?
Commonly used tools and techniques in data analysis include programming languages like Python and R, statistical methods such as regression analysis and hypothesis testing, machine learning algorithms for predictive modeling, data visualization tools like Tableau and Matplotlib, and database querying languages like SQL.
What are the steps involved in the data analysis process?
The data analysis process typically includes defining the problem, collecting data, cleaning and preprocessing the data, conducting exploratory data analysis, applying statistical or machine learning models for analysis, interpreting results, making decisions based on insights, and communicating findings to stakeholders.
What is data analysis, and why is it important?
Data analysis involves examining, cleaning, transforming, and modeling data to derive meaningful insights and make informed decisions. It is crucial because it helps organizations uncover trends, patterns, and relationships within data, leading to improved decision-making, enhanced business strategies, and competitive advantage.

Big Data Framework
Official account of the Enterprise Big Data Framework Alliance.
Stay in the loop
Subscribe to our free newsletter.
Related articles.

Exploratory Data Analysis

Data Analysis vs. Data Literacy

Understanding Data Quality: Ensuring Accuracy, Reliability, and Consistency
The framework.
Framework Overview
Download the Guides
About the Big Data Framework
PARTNERSHIPS
Academic Partner Program
Corporate Partnerships
CERTIFICATIONS
Big data events.
Events and Webinars
CERTIFICATES
Data Privacy Fundamentals
BIG DATA RESOURCES
Big Data News & Updates
Downloads and Resources
CONNECT WITH US
Endenicher Allee 12 53115, DE Bonn Germany
SOCIAL MEDIA
© Copyright 2021 | Enterprise Big Data Framework© | All Rights Reserved | Privacy Policy | Terms of Use | Contact
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case AskWhy Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Data Analysis: Definition, Types and Examples

Nowadays, data is collected at various stages of processes and transactions, which has the potential to improve the way we work significantly. However, to fully realize the value of data analysis, this data must be analyzed to gain valuable insights into improving products and services.
Data analysis consists aspect of making informed decisions in various industries. With the advancement of technology, it has become a dynamic and exciting field But what is it in simple words?
What is Data Analysis?
Data analysis is the science of examining data to conclude the information to make decisions or expand knowledge on various subjects. It consists of subjecting data to operations. This process happens to obtain precise conclusions to help us achieve our goals, such as operations that cannot be previously defined since data collection may reveal specific difficulties.
“A lot of this [data analysis] will help humans work smarter and faster because we have data on everything that happens.” –Daniel Burrus, business consultant and speaker on business and innovation issues.
Why is data analytics important?
Data analytics help businesses understand the target market faster, increase sales, reduce costs, increase revenue, and allow for better problem-solving. Data analysis is important for several reasons, as it plays a critical role in various aspects of modern businesses and organizations. Here are some key reasons why data analysis important is crucial:
Informed decision-making
Data analytics helps businesses make more informed and data-driven decisions. By analyzing data, organizations can gain insights into customer behavior, market trends, and operational performance, enabling them to make better choices that are supported by evidence rather than relying on intuition alone.
Identifying opportunities and challenges
Data analytics allows businesses to identify new opportunities for growth, product development, or market expansion. It also helps identify potential challenges and risks, allowing organizations to address them proactively.
Improving efficiency and productivity
Organizations can identify inefficiencies and bottlenecks by analyzing processes and performance data, leading to process optimization and improved productivity. This, in turn, can result in cost savings and better resource allocation.
Customer understanding and personalization
Data analytics enables businesses to understand their customers better, including their preferences, buying behaviors, and pain points. With this understanding, organizations can offer personalized products and services, enhancing customer satisfaction and loyalty.
Competitive advantage
Organizations that leverage data analytics effectively gain a competitive edge in today’s data-driven world. By analyzing data, businesses can identify unique insights and trends that better understand the market and their competitors, helping them stay ahead of the competition.
Performance tracking and evaluation
Data analytics allows organizations to track and measure their performance against key performance indicators (KPIs) and goals. This helps in evaluating the success of various strategies and initiatives, enabling continuous improvement.
Predictive analytics
Data analytics can be used for predictive modeling, helping organizations forecast future trends and outcomes. This is valuable for financial planning, demand forecasting, risk management, and proactive decision-making.
Data-driven innovation
Data analytics can fuel innovation by providing insights that lead to the development of new products, services, or business models. Innovations based on data analysis can lead to groundbreaking advancements and disruption in various industries.
Fraud detection and security
Data analytics can be used to detect anomalies and patterns indicative of fraudulent activities. It plays a crucial role in enhancing security and protecting businesses from financial losses and reputational risk .
Regulatory compliance
In many industries, regulations, and laws are mandatory. Data analytics can help organizations ensure that they meet these compliance requirements by tracking and auditing relevant data.
Types of data analysis
There are several types of data analysis, each with a specific purpose and method. Let’s talk about some significant types:

Descriptive Analysis
Descriptive analysis is used to summarize and describe the main features of a dataset. It involves calculating measures of central tendency and dispersion to describe the data. The descriptive analysis provides a comprehensive overview of the data and insights into its properties and structure.
LEARN ABOUT: Descriptive Analysis
Inferential Analysis
The inferential analysis is used statistical analysis plan and testing to make inferences about the population parameters, such as the mean or proportion. This unit of analysis involves using models and hypothesis testing to make predictions and draw conclusions about the population.
LEARN ABOUT: Statistical Analysis Methods
Predictive Analysis
Predictive analysis is used to predict future events or outcomes based on historical data and other relevant information. It involves using statistical models and machine learning algorithms to identify patterns in the data and make predictions about future outcomes.
Prescriptive Analysis
Prescriptive analysis is a decision-making analysis that uses mathematical modeling, optimization algorithms, and other data-driven techniques to identify the action for a given problem or situation. It combines mathematical models, data, and business constraints to find the best move or decision.
Text Analysis
Text analysis is a process of extracting meaningful information from unstructured text data. It involves a variety of techniques, including natural language processing (NLP), text mining, sentiment analysis, and topic modeling, to uncover insights and patterns in text data.
Diagnostic Analysis
The diagnostic analysis seeks to identify the root causes of specific events or outcomes. It is often used in troubleshooting problems or investigating anomalies in data.
LEARN ABOUT: Data Analytics Projects
Uses of data analysis
It is used in many industries regardless of the branch. It gives us the basis for making decisions or confirming a hypothesis.
A researcher or data analyst mainly performs data analysis to predict consumer behavior and help companies place their products and services in the market accordingly. For instance, sales data analysis can help you identify the product range not-so-popular in a specific demographic group. It can give you insights into tweaking your current marketing campaign to better connect with the target audience and address their needs.
Human Resources
Organizations can use data analysis tools to offer a great experience to their employees and ensure an excellent work environment. They can also utilize the data to find out the best resources whose skill set matches the organizational goals.
Universities and academic institutions can perform the analysis to measure student performance and gather insights on how certain behaviors can further improve education.
Techniques for data analysis
It is essential to analyze raw data to understand it. We must resort to various data analysis techniques that depend on the type of information collected, so it is crucial to define the method before implementing it.
- Qualitative data: Researchers collect qualitative data from the underlying emotions, body language, and expressions. Its foundation is the data interpretation of verbal responses. The most common ways of obtaining this information are through open-ended interviews, focus groups, and observation groups, where researchers generally analyze patterns in observations throughout the data collection phase.
- Quantitative data: Quantitative data presents itself in numerical form. It focuses on tangible results.
Data analysis focuses on reaching a conclusion based solely on the researcher’s current knowledge. How you collect your data should relate to how you plan to analyze and use it. You also need to collect accurate and trustworthy information.
Many data collection techniques exist, but experts’ most commonly used method is online surveys. It offers significant benefits, such as reducing time and money compared to traditional data collection methods .
Data analysis and data analytics are two interconnected but distinct processes in data science. Data analysis involves examining raw data using various techniques to uncover patterns, correlations, and insights. It’s about understanding historical data to make informed conclusions. On the other hand, data analytics goes a step further by utilizing those insights to predict future trends, prescribe actions, and guide decision-making.
At QuestionPro, we have an accurate tool that will help you professionally make better decisions.
Data Analysis Methods
The term data analysis technique has often been used interchangeably by professional researchers. Frequently people also throw out the previous analysis type. We’re hoping for this to be an important distinction between how and when data analyses are done.
However, there are many different techniques that allow for data analysis. Here are some of the main common methods used for data analysis:
Descriptive Statistics
Descriptive statistics involves summarizing and describing the main features of a dataset, such as mean, median, mode, standard deviation, range, and percentiles. It provides a basic understanding of the data’s distribution and characteristics.
Inferential Statistics
Inferential statistics are used to make inferences and draw conclusions about a larger population based on a sample of data. It includes techniques like hypothesis testing, confidence intervals, and regression analysis.
Data Visualization
Data visualization is the graphical representation of data to help analysts and stakeholders understand patterns, trends, and insights. Common visualization techniques include bar charts, line graphs, scatter plots, heat maps, and pie charts.
Exploratory Data Analysis (EDA)
EDA involves analyzing and visualizing data to discover patterns, relationships, and potential outliers. It helps in gaining insights into the data before formal statistical testing.
Predictive Modeling
Predictive modeling uses algorithms and statistical techniques to build models that can make predictions about future outcomes based on historical data. Machine learning algorithms, such as decision trees, logistic regression, and neural networks, are commonly used for predictive modeling.
Time Series Analysis
Time series analysis is used to analyze data collected over time, such as stock prices, temperature readings, or sales data. It involves identifying trends and seasonality and forecasting future values.
Cluster Analysis
Cluster analysis is used to group similar data points together based on certain features or characteristics. It helps in identifying patterns and segmenting data into meaningful clusters.
Factor Analysis and Principal Component Analysis (PCA)
These techniques are used to reduce the dimensionality of data and identify underlying factors or components that explain the variance in the data.
Text Mining and Natural Language Processing (NLP)
Text mining and NLP techniques are used to analyze and extract information from unstructured text data, such as social media posts, customer reviews, or survey responses.
Qualitative Data Analysis
Qualitative data analysis involves interpreting non-numeric data, such as text, images, audio, or video. Techniques like content analysis, thematic analysis, and grounded theory are used to analyze qualitative data.
Quantitative Data Analysis
Quantitative analysis focuses on analyzing numerical data to discover relationships, trends, and patterns. This analysis often involves statistical methods.
Data Mining
Data mining involves discovering patterns, relationships, or insights from large datasets using various algorithms and techniques.
Regression Analysis
Regression analysis is used to model the relationship between a dependent variable and one or more independent variables. It helps understand how changes in one variable impact the other(s).
Step-by-step guide data analysis
With these five steps in your data analysis process, you will make better decisions for your business because data that has been well collected and analyzed support your choices.
LEARN ABOUT: Data Mining Techniques

Step 1: Define your questions
Start by selecting the right questions. Questions should be measurable, clear, and concise. Design your questions to qualify or disqualify possible solutions to your specific problem.
Step 2: Establish measurement priorities
This step divides into two sub-steps:
- Decide what to measure: Analyze what kind of data you need.
- Decide how to measure it: Thinking about how to measure your data is just as important, especially before the data collection phase, because your measurement process supports or discredits your thematic analysis later on.
Step 3: Collect data
With the question clearly defined and your measurement priorities established, now it’s time to collect your data. As you manage and organize your data, remember to keep these essential points in mind:
- Before collecting new data, determine what information you could gather from existing databases or sources.
- Determine a storage and file naming system to help all team members collaborate in advance. This process saves time and prevents team members from collecting the same information twice.
- If you need to collect data through surveys, observation, or interviews, develop a questionnaire in advance to ensure consistency and save time.
- Keep the collected data organized with a log of collection dates, and add any source notes as you go along.
Step 4: Analyze the data
Once you’ve collected the correct data to answer your Step 1 question, it’s time to conduct a deeper statistical analysis . Find relationships, identify trends, and sort and filter your data according to variables. You will find the exact data you need as you analyze the data.
Step 5: Interpret the results
After analyzing the data and possibly conducting further research, it is finally time to interpret the results. Ask yourself these key questions:
- Does the data answer your original question? How?
- Does the data help you defend any objections? How?
- Are there any limitations to the conclusions, any angles you haven’t considered?
If the interpretation of data holds up under these questions and considerations, you have reached a productive conclusion. The only remaining step is to use the process results to decide how you will act.
Join us as we look into the most frequently used question types and how to analyze your findings effectively.
Make the right decisions by analyzing data the right way!
Data analysis advantages
Many industries use data to draw conclusions and decide on actions to implement. It is worth mentioning that science also uses to test or discard existing theories or models.
There’s more than one advantage to data analysis done right. Here are some examples:

- Make faster and more informed business decisions backed by facts.
- Identify performance issues that require action.
- Gain a deeper understanding of customer requirements, which creates better business relationships.
- Increase awareness of risks to implement preventive measures.
- Visualize different dimensions of the data.
- Gain competitive advantage.
- A better understanding of the financial performance of the business.
- Identify ways to reduce costs and thus increase profits.
These questions are examples of different types of data analysis. You can include them in your post-event surveys aimed at your customers:
- Questions start with: Why? How?
Example of qualitative data research analysis: Panels where a discussion is held, and consumers are interviewed about what they like or dislike about the place.
- Data is collected by asking questions like: How many? Who? How often? Where?
Example of quantitative research analysis: Surveys focused on measuring sales, trends, reports, or perceptions.
Data analysis with QuestionPro
Data analysis is crucial in aiding organizations and individuals in making informed decisions by comprehensively understanding the data. If you’re in need of various data analysis techniques solutions, consider using QuestionPro. Our software allows you to collect data easily, create real-time reports, and analyze data. Practical business intelligence relies on the synergy between analytics and reporting , where analytics uncovers valuable insights, and reporting communicates these findings to stakeholders.
LEARN ABOUT: Average Order Value
Start a free trial or schedule a demo to see the full potential of our powerful tool. We’re here to help you every step of the way!
LEARN MORE FREE TRIAL
MORE LIKE THIS

Jotform vs SurveyMonkey: Which Is Best in 2024
Aug 15, 2024

360 Degree Feedback Spider Chart is Back!
Aug 14, 2024

Jotform vs Wufoo: Comparison of Features and Prices
Aug 13, 2024

Product or Service: Which is More Important? — Tuesday CX Thoughts
Other categories.
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Tuesday CX Thoughts (TCXT)
- Uncategorized
- What’s Coming Up
- Workforce Intelligence
What is Data Analysis? Research, Types & Example
What is Data Analysis?
Data analysis is defined as a process of cleaning, transforming, and modeling data to discover useful information for business decision-making. The purpose of Data Analysis is to extract useful information from data and taking the decision based upon the data analysis.
A simple example of Data analysis is whenever we take any decision in our day-to-day life is by thinking about what happened last time or what will happen by choosing that particular decision. This is nothing but analyzing our past or future and making decisions based on it. For that, we gather memories of our past or dreams of our future. So that is nothing but data analysis. Now same thing analyst does for business purposes, is called Data Analysis.
In this Data Science Tutorial, you will learn:
Why Data Analysis?
To grow your business even to grow in your life, sometimes all you need to do is Analysis!
If your business is not growing, then you have to look back and acknowledge your mistakes and make a plan again without repeating those mistakes. And even if your business is growing, then you have to look forward to making the business to grow more. All you need to do is analyze your business data and business processes.
Data Analysis Tools

Data analysis tools make it easier for users to process and manipulate data, analyze the relationships and correlations between data sets, and it also helps to identify patterns and trends for interpretation. Here is a complete list of tools used for data analysis in research.
Types of Data Analysis: Techniques and Methods
There are several types of Data Analysis techniques that exist based on business and technology. However, the major Data Analysis methods are:
Text Analysis
Statistical analysis, diagnostic analysis, predictive analysis, prescriptive analysis.
Text Analysis is also referred to as Data Mining. It is one of the methods of data analysis to discover a pattern in large data sets using databases or data mining tools . It used to transform raw data into business information. Business Intelligence tools are present in the market which is used to take strategic business decisions. Overall it offers a way to extract and examine data and deriving patterns and finally interpretation of the data.
Statistical Analysis shows “What happen?” by using past data in the form of dashboards. Statistical Analysis includes collection, Analysis, interpretation, presentation, and modeling of data. It analyses a set of data or a sample of data. There are two categories of this type of Analysis – Descriptive Analysis and Inferential Analysis.
Descriptive Analysis
analyses complete data or a sample of summarized numerical data. It shows mean and deviation for continuous data whereas percentage and frequency for categorical data.
Inferential Analysis
analyses sample from complete data. In this type of Analysis, you can find different conclusions from the same data by selecting different samples.
Diagnostic Analysis shows “Why did it happen?” by finding the cause from the insight found in Statistical Analysis. This Analysis is useful to identify behavior patterns of data. If a new problem arrives in your business process, then you can look into this Analysis to find similar patterns of that problem. And it may have chances to use similar prescriptions for the new problems.
Predictive Analysis shows “what is likely to happen” by using previous data. The simplest data analysis example is like if last year I bought two dresses based on my savings and if this year my salary is increasing double then I can buy four dresses. But of course it’s not easy like this because you have to think about other circumstances like chances of prices of clothes is increased this year or maybe instead of dresses you want to buy a new bike, or you need to buy a house!
So here, this Analysis makes predictions about future outcomes based on current or past data. Forecasting is just an estimate. Its accuracy is based on how much detailed information you have and how much you dig in it.
Prescriptive Analysis combines the insight from all previous Analysis to determine which action to take in a current problem or decision. Most data-driven companies are utilizing Prescriptive Analysis because predictive and descriptive Analysis are not enough to improve data performance. Based on current situations and problems, they analyze the data and make decisions.
Data Analysis Process
The Data Analysis Process is nothing but gathering information by using a proper application or tool which allows you to explore the data and find a pattern in it. Based on that information and data, you can make decisions, or you can get ultimate conclusions.
Data Analysis consists of the following phases:
Data Requirement Gathering
Data collection, data cleaning, data analysis, data interpretation, data visualization.
First of all, you have to think about why do you want to do this data analysis? All you need to find out the purpose or aim of doing the Analysis of data. You have to decide which type of data analysis you wanted to do! In this phase, you have to decide what to analyze and how to measure it, you have to understand why you are investigating and what measures you have to use to do this Analysis.
After requirement gathering, you will get a clear idea about what things you have to measure and what should be your findings. Now it’s time to collect your data based on requirements. Once you collect your data, remember that the collected data must be processed or organized for Analysis. As you collected data from various sources, you must have to keep a log with a collection date and source of the data.
Now whatever data is collected may not be useful or irrelevant to your aim of Analysis, hence it should be cleaned. The data which is collected may contain duplicate records, white spaces or errors. The data should be cleaned and error free. This phase must be done before Analysis because based on data cleaning, your output of Analysis will be closer to your expected outcome.
Once the data is collected, cleaned, and processed, it is ready for Analysis. As you manipulate data, you may find you have the exact information you need, or you might need to collect more data. During this phase, you can use data analysis tools and software which will help you to understand, interpret, and derive conclusions based on the requirements.
After analyzing your data, it’s finally time to interpret your results. You can choose the way to express or communicate your data analysis either you can use simply in words or maybe a table or chart. Then use the results of your data analysis process to decide your best course of action.
Data visualization is very common in your day to day life; they often appear in the form of charts and graphs. In other words, data shown graphically so that it will be easier for the human brain to understand and process it. Data visualization often used to discover unknown facts and trends. By observing relationships and comparing datasets, you can find a way to find out meaningful information.
- Data analysis means a process of cleaning, transforming and modeling data to discover useful information for business decision-making
- Types of Data Analysis are Text, Statistical, Diagnostic, Predictive, Prescriptive Analysis
- Data Analysis consists of Data Requirement Gathering, Data Collection, Data Cleaning, Data Analysis, Data Interpretation, Data Visualization
- 40+ Best Data Science Courses Online with Certification in 2024
- SAS Tutorial for Beginners: What is & Programming Example
- What is Data Science? Introduction, Basic Concepts & Process
- Top 50 Data Science Interview Questions and Answers (PDF)
- 60+ Data Engineer Interview Questions and Answers in 2024
- Difference Between Data Science and Machine Learning
- 17 BEST Data Science Books (2024 Update)
- Data Science Tutorial for Beginners: Learn Basics in 3 Days
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
The Beginner's Guide to Statistical Analysis | 5 Steps & Examples
Statistical analysis means investigating trends, patterns, and relationships using quantitative data . It is an important research tool used by scientists, governments, businesses, and other organizations.
To draw valid conclusions, statistical analysis requires careful planning from the very start of the research process . You need to specify your hypotheses and make decisions about your research design, sample size, and sampling procedure.
After collecting data from your sample, you can organize and summarize the data using descriptive statistics . Then, you can use inferential statistics to formally test hypotheses and make estimates about the population. Finally, you can interpret and generalize your findings.
This article is a practical introduction to statistical analysis for students and researchers. We’ll walk you through the steps using two research examples. The first investigates a potential cause-and-effect relationship, while the second investigates a potential correlation between variables.
Table of contents
Step 1: write your hypotheses and plan your research design, step 2: collect data from a sample, step 3: summarize your data with descriptive statistics, step 4: test hypotheses or make estimates with inferential statistics, step 5: interpret your results, other interesting articles.
To collect valid data for statistical analysis, you first need to specify your hypotheses and plan out your research design.
Writing statistical hypotheses
The goal of research is often to investigate a relationship between variables within a population . You start with a prediction, and use statistical analysis to test that prediction.
A statistical hypothesis is a formal way of writing a prediction about a population. Every research prediction is rephrased into null and alternative hypotheses that can be tested using sample data.
While the null hypothesis always predicts no effect or no relationship between variables, the alternative hypothesis states your research prediction of an effect or relationship.
- Null hypothesis: A 5-minute meditation exercise will have no effect on math test scores in teenagers.
- Alternative hypothesis: A 5-minute meditation exercise will improve math test scores in teenagers.
- Null hypothesis: Parental income and GPA have no relationship with each other in college students.
- Alternative hypothesis: Parental income and GPA are positively correlated in college students.
Planning your research design
A research design is your overall strategy for data collection and analysis. It determines the statistical tests you can use to test your hypothesis later on.
First, decide whether your research will use a descriptive, correlational, or experimental design. Experiments directly influence variables, whereas descriptive and correlational studies only measure variables.
- In an experimental design , you can assess a cause-and-effect relationship (e.g., the effect of meditation on test scores) using statistical tests of comparison or regression.
- In a correlational design , you can explore relationships between variables (e.g., parental income and GPA) without any assumption of causality using correlation coefficients and significance tests.
- In a descriptive design , you can study the characteristics of a population or phenomenon (e.g., the prevalence of anxiety in U.S. college students) using statistical tests to draw inferences from sample data.
Your research design also concerns whether you’ll compare participants at the group level or individual level, or both.
- In a between-subjects design , you compare the group-level outcomes of participants who have been exposed to different treatments (e.g., those who performed a meditation exercise vs those who didn’t).
- In a within-subjects design , you compare repeated measures from participants who have participated in all treatments of a study (e.g., scores from before and after performing a meditation exercise).
- In a mixed (factorial) design , one variable is altered between subjects and another is altered within subjects (e.g., pretest and posttest scores from participants who either did or didn’t do a meditation exercise).
- Experimental
- Correlational
First, you’ll take baseline test scores from participants. Then, your participants will undergo a 5-minute meditation exercise. Finally, you’ll record participants’ scores from a second math test.
In this experiment, the independent variable is the 5-minute meditation exercise, and the dependent variable is the math test score from before and after the intervention. Example: Correlational research design In a correlational study, you test whether there is a relationship between parental income and GPA in graduating college students. To collect your data, you will ask participants to fill in a survey and self-report their parents’ incomes and their own GPA.
Measuring variables
When planning a research design, you should operationalize your variables and decide exactly how you will measure them.
For statistical analysis, it’s important to consider the level of measurement of your variables, which tells you what kind of data they contain:
- Categorical data represents groupings. These may be nominal (e.g., gender) or ordinal (e.g. level of language ability).
- Quantitative data represents amounts. These may be on an interval scale (e.g. test score) or a ratio scale (e.g. age).
Many variables can be measured at different levels of precision. For example, age data can be quantitative (8 years old) or categorical (young). If a variable is coded numerically (e.g., level of agreement from 1–5), it doesn’t automatically mean that it’s quantitative instead of categorical.
Identifying the measurement level is important for choosing appropriate statistics and hypothesis tests. For example, you can calculate a mean score with quantitative data, but not with categorical data.
In a research study, along with measures of your variables of interest, you’ll often collect data on relevant participant characteristics.
| Variable | Type of data |
|---|---|
| Age | Quantitative (ratio) |
| Gender | Categorical (nominal) |
| Race or ethnicity | Categorical (nominal) |
| Baseline test scores | Quantitative (interval) |
| Final test scores | Quantitative (interval) |
| Parental income | Quantitative (ratio) |
|---|---|
| GPA | Quantitative (interval) |
Here's why students love Scribbr's proofreading services
Discover proofreading & editing

In most cases, it’s too difficult or expensive to collect data from every member of the population you’re interested in studying. Instead, you’ll collect data from a sample.
Statistical analysis allows you to apply your findings beyond your own sample as long as you use appropriate sampling procedures . You should aim for a sample that is representative of the population.
Sampling for statistical analysis
There are two main approaches to selecting a sample.
- Probability sampling: every member of the population has a chance of being selected for the study through random selection.
- Non-probability sampling: some members of the population are more likely than others to be selected for the study because of criteria such as convenience or voluntary self-selection.
In theory, for highly generalizable findings, you should use a probability sampling method. Random selection reduces several types of research bias , like sampling bias , and ensures that data from your sample is actually typical of the population. Parametric tests can be used to make strong statistical inferences when data are collected using probability sampling.
But in practice, it’s rarely possible to gather the ideal sample. While non-probability samples are more likely to at risk for biases like self-selection bias , they are much easier to recruit and collect data from. Non-parametric tests are more appropriate for non-probability samples, but they result in weaker inferences about the population.
If you want to use parametric tests for non-probability samples, you have to make the case that:
- your sample is representative of the population you’re generalizing your findings to.
- your sample lacks systematic bias.
Keep in mind that external validity means that you can only generalize your conclusions to others who share the characteristics of your sample. For instance, results from Western, Educated, Industrialized, Rich and Democratic samples (e.g., college students in the US) aren’t automatically applicable to all non-WEIRD populations.
If you apply parametric tests to data from non-probability samples, be sure to elaborate on the limitations of how far your results can be generalized in your discussion section .
Create an appropriate sampling procedure
Based on the resources available for your research, decide on how you’ll recruit participants.
- Will you have resources to advertise your study widely, including outside of your university setting?
- Will you have the means to recruit a diverse sample that represents a broad population?
- Do you have time to contact and follow up with members of hard-to-reach groups?
Your participants are self-selected by their schools. Although you’re using a non-probability sample, you aim for a diverse and representative sample. Example: Sampling (correlational study) Your main population of interest is male college students in the US. Using social media advertising, you recruit senior-year male college students from a smaller subpopulation: seven universities in the Boston area.
Calculate sufficient sample size
Before recruiting participants, decide on your sample size either by looking at other studies in your field or using statistics. A sample that’s too small may be unrepresentative of the sample, while a sample that’s too large will be more costly than necessary.
There are many sample size calculators online. Different formulas are used depending on whether you have subgroups or how rigorous your study should be (e.g., in clinical research). As a rule of thumb, a minimum of 30 units or more per subgroup is necessary.
To use these calculators, you have to understand and input these key components:
- Significance level (alpha): the risk of rejecting a true null hypothesis that you are willing to take, usually set at 5%.
- Statistical power : the probability of your study detecting an effect of a certain size if there is one, usually 80% or higher.
- Expected effect size : a standardized indication of how large the expected result of your study will be, usually based on other similar studies.
- Population standard deviation: an estimate of the population parameter based on a previous study or a pilot study of your own.
Once you’ve collected all of your data, you can inspect them and calculate descriptive statistics that summarize them.
Inspect your data
There are various ways to inspect your data, including the following:
- Organizing data from each variable in frequency distribution tables .
- Displaying data from a key variable in a bar chart to view the distribution of responses.
- Visualizing the relationship between two variables using a scatter plot .
By visualizing your data in tables and graphs, you can assess whether your data follow a skewed or normal distribution and whether there are any outliers or missing data.
A normal distribution means that your data are symmetrically distributed around a center where most values lie, with the values tapering off at the tail ends.

In contrast, a skewed distribution is asymmetric and has more values on one end than the other. The shape of the distribution is important to keep in mind because only some descriptive statistics should be used with skewed distributions.
Extreme outliers can also produce misleading statistics, so you may need a systematic approach to dealing with these values.
Calculate measures of central tendency
Measures of central tendency describe where most of the values in a data set lie. Three main measures of central tendency are often reported:
- Mode : the most popular response or value in the data set.
- Median : the value in the exact middle of the data set when ordered from low to high.
- Mean : the sum of all values divided by the number of values.
However, depending on the shape of the distribution and level of measurement, only one or two of these measures may be appropriate. For example, many demographic characteristics can only be described using the mode or proportions, while a variable like reaction time may not have a mode at all.
Calculate measures of variability
Measures of variability tell you how spread out the values in a data set are. Four main measures of variability are often reported:
- Range : the highest value minus the lowest value of the data set.
- Interquartile range : the range of the middle half of the data set.
- Standard deviation : the average distance between each value in your data set and the mean.
- Variance : the square of the standard deviation.
Once again, the shape of the distribution and level of measurement should guide your choice of variability statistics. The interquartile range is the best measure for skewed distributions, while standard deviation and variance provide the best information for normal distributions.
Using your table, you should check whether the units of the descriptive statistics are comparable for pretest and posttest scores. For example, are the variance levels similar across the groups? Are there any extreme values? If there are, you may need to identify and remove extreme outliers in your data set or transform your data before performing a statistical test.
| Pretest scores | Posttest scores | |
|---|---|---|
| Mean | 68.44 | 75.25 |
| Standard deviation | 9.43 | 9.88 |
| Variance | 88.96 | 97.96 |
| Range | 36.25 | 45.12 |
| 30 | ||
From this table, we can see that the mean score increased after the meditation exercise, and the variances of the two scores are comparable. Next, we can perform a statistical test to find out if this improvement in test scores is statistically significant in the population. Example: Descriptive statistics (correlational study) After collecting data from 653 students, you tabulate descriptive statistics for annual parental income and GPA.
It’s important to check whether you have a broad range of data points. If you don’t, your data may be skewed towards some groups more than others (e.g., high academic achievers), and only limited inferences can be made about a relationship.
| Parental income (USD) | GPA | |
|---|---|---|
| Mean | 62,100 | 3.12 |
| Standard deviation | 15,000 | 0.45 |
| Variance | 225,000,000 | 0.16 |
| Range | 8,000–378,000 | 2.64–4.00 |
| 653 | ||
A number that describes a sample is called a statistic , while a number describing a population is called a parameter . Using inferential statistics , you can make conclusions about population parameters based on sample statistics.
Researchers often use two main methods (simultaneously) to make inferences in statistics.
- Estimation: calculating population parameters based on sample statistics.
- Hypothesis testing: a formal process for testing research predictions about the population using samples.
You can make two types of estimates of population parameters from sample statistics:
- A point estimate : a value that represents your best guess of the exact parameter.
- An interval estimate : a range of values that represent your best guess of where the parameter lies.
If your aim is to infer and report population characteristics from sample data, it’s best to use both point and interval estimates in your paper.
You can consider a sample statistic a point estimate for the population parameter when you have a representative sample (e.g., in a wide public opinion poll, the proportion of a sample that supports the current government is taken as the population proportion of government supporters).
There’s always error involved in estimation, so you should also provide a confidence interval as an interval estimate to show the variability around a point estimate.
A confidence interval uses the standard error and the z score from the standard normal distribution to convey where you’d generally expect to find the population parameter most of the time.
Hypothesis testing
Using data from a sample, you can test hypotheses about relationships between variables in the population. Hypothesis testing starts with the assumption that the null hypothesis is true in the population, and you use statistical tests to assess whether the null hypothesis can be rejected or not.
Statistical tests determine where your sample data would lie on an expected distribution of sample data if the null hypothesis were true. These tests give two main outputs:
- A test statistic tells you how much your data differs from the null hypothesis of the test.
- A p value tells you the likelihood of obtaining your results if the null hypothesis is actually true in the population.
Statistical tests come in three main varieties:
- Comparison tests assess group differences in outcomes.
- Regression tests assess cause-and-effect relationships between variables.
- Correlation tests assess relationships between variables without assuming causation.
Your choice of statistical test depends on your research questions, research design, sampling method, and data characteristics.
Parametric tests
Parametric tests make powerful inferences about the population based on sample data. But to use them, some assumptions must be met, and only some types of variables can be used. If your data violate these assumptions, you can perform appropriate data transformations or use alternative non-parametric tests instead.
A regression models the extent to which changes in a predictor variable results in changes in outcome variable(s).
- A simple linear regression includes one predictor variable and one outcome variable.
- A multiple linear regression includes two or more predictor variables and one outcome variable.
Comparison tests usually compare the means of groups. These may be the means of different groups within a sample (e.g., a treatment and control group), the means of one sample group taken at different times (e.g., pretest and posttest scores), or a sample mean and a population mean.
- A t test is for exactly 1 or 2 groups when the sample is small (30 or less).
- A z test is for exactly 1 or 2 groups when the sample is large.
- An ANOVA is for 3 or more groups.
The z and t tests have subtypes based on the number and types of samples and the hypotheses:
- If you have only one sample that you want to compare to a population mean, use a one-sample test .
- If you have paired measurements (within-subjects design), use a dependent (paired) samples test .
- If you have completely separate measurements from two unmatched groups (between-subjects design), use an independent (unpaired) samples test .
- If you expect a difference between groups in a specific direction, use a one-tailed test .
- If you don’t have any expectations for the direction of a difference between groups, use a two-tailed test .
The only parametric correlation test is Pearson’s r . The correlation coefficient ( r ) tells you the strength of a linear relationship between two quantitative variables.
However, to test whether the correlation in the sample is strong enough to be important in the population, you also need to perform a significance test of the correlation coefficient, usually a t test, to obtain a p value. This test uses your sample size to calculate how much the correlation coefficient differs from zero in the population.
You use a dependent-samples, one-tailed t test to assess whether the meditation exercise significantly improved math test scores. The test gives you:
- a t value (test statistic) of 3.00
- a p value of 0.0028
Although Pearson’s r is a test statistic, it doesn’t tell you anything about how significant the correlation is in the population. You also need to test whether this sample correlation coefficient is large enough to demonstrate a correlation in the population.
A t test can also determine how significantly a correlation coefficient differs from zero based on sample size. Since you expect a positive correlation between parental income and GPA, you use a one-sample, one-tailed t test. The t test gives you:
- a t value of 3.08
- a p value of 0.001
Prevent plagiarism. Run a free check.
The final step of statistical analysis is interpreting your results.
Statistical significance
In hypothesis testing, statistical significance is the main criterion for forming conclusions. You compare your p value to a set significance level (usually 0.05) to decide whether your results are statistically significant or non-significant.
Statistically significant results are considered unlikely to have arisen solely due to chance. There is only a very low chance of such a result occurring if the null hypothesis is true in the population.
This means that you believe the meditation intervention, rather than random factors, directly caused the increase in test scores. Example: Interpret your results (correlational study) You compare your p value of 0.001 to your significance threshold of 0.05. With a p value under this threshold, you can reject the null hypothesis. This indicates a statistically significant correlation between parental income and GPA in male college students.
Note that correlation doesn’t always mean causation, because there are often many underlying factors contributing to a complex variable like GPA. Even if one variable is related to another, this may be because of a third variable influencing both of them, or indirect links between the two variables.
Effect size
A statistically significant result doesn’t necessarily mean that there are important real life applications or clinical outcomes for a finding.
In contrast, the effect size indicates the practical significance of your results. It’s important to report effect sizes along with your inferential statistics for a complete picture of your results. You should also report interval estimates of effect sizes if you’re writing an APA style paper .
With a Cohen’s d of 0.72, there’s medium to high practical significance to your finding that the meditation exercise improved test scores. Example: Effect size (correlational study) To determine the effect size of the correlation coefficient, you compare your Pearson’s r value to Cohen’s effect size criteria.
Decision errors
Type I and Type II errors are mistakes made in research conclusions. A Type I error means rejecting the null hypothesis when it’s actually true, while a Type II error means failing to reject the null hypothesis when it’s false.
You can aim to minimize the risk of these errors by selecting an optimal significance level and ensuring high power . However, there’s a trade-off between the two errors, so a fine balance is necessary.
Frequentist versus Bayesian statistics
Traditionally, frequentist statistics emphasizes null hypothesis significance testing and always starts with the assumption of a true null hypothesis.
However, Bayesian statistics has grown in popularity as an alternative approach in the last few decades. In this approach, you use previous research to continually update your hypotheses based on your expectations and observations.
Bayes factor compares the relative strength of evidence for the null versus the alternative hypothesis rather than making a conclusion about rejecting the null hypothesis or not.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Student’s t -distribution
- Normal distribution
- Null and Alternative Hypotheses
- Chi square tests
- Confidence interval
Methodology
- Cluster sampling
- Stratified sampling
- Data cleansing
- Reproducibility vs Replicability
- Peer review
- Likert scale
Research bias
- Implicit bias
- Framing effect
- Cognitive bias
- Placebo effect
- Hawthorne effect
- Hostile attribution bias
- Affect heuristic
Is this article helpful?
Other students also liked.
- Descriptive Statistics | Definitions, Types, Examples
- Inferential Statistics | An Easy Introduction & Examples
- Choosing the Right Statistical Test | Types & Examples
More interesting articles
- Akaike Information Criterion | When & How to Use It (Example)
- An Easy Introduction to Statistical Significance (With Examples)
- An Introduction to t Tests | Definitions, Formula and Examples
- ANOVA in R | A Complete Step-by-Step Guide with Examples
- Central Limit Theorem | Formula, Definition & Examples
- Central Tendency | Understanding the Mean, Median & Mode
- Chi-Square (Χ²) Distributions | Definition & Examples
- Chi-Square (Χ²) Table | Examples & Downloadable Table
- Chi-Square (Χ²) Tests | Types, Formula & Examples
- Chi-Square Goodness of Fit Test | Formula, Guide & Examples
- Chi-Square Test of Independence | Formula, Guide & Examples
- Coefficient of Determination (R²) | Calculation & Interpretation
- Correlation Coefficient | Types, Formulas & Examples
- Frequency Distribution | Tables, Types & Examples
- How to Calculate Standard Deviation (Guide) | Calculator & Examples
- How to Calculate Variance | Calculator, Analysis & Examples
- How to Find Degrees of Freedom | Definition & Formula
- How to Find Interquartile Range (IQR) | Calculator & Examples
- How to Find Outliers | 4 Ways with Examples & Explanation
- How to Find the Geometric Mean | Calculator & Formula
- How to Find the Mean | Definition, Examples & Calculator
- How to Find the Median | Definition, Examples & Calculator
- How to Find the Mode | Definition, Examples & Calculator
- How to Find the Range of a Data Set | Calculator & Formula
- Hypothesis Testing | A Step-by-Step Guide with Easy Examples
- Interval Data and How to Analyze It | Definitions & Examples
- Levels of Measurement | Nominal, Ordinal, Interval and Ratio
- Linear Regression in R | A Step-by-Step Guide & Examples
- Missing Data | Types, Explanation, & Imputation
- Multiple Linear Regression | A Quick Guide (Examples)
- Nominal Data | Definition, Examples, Data Collection & Analysis
- Normal Distribution | Examples, Formulas, & Uses
- Null and Alternative Hypotheses | Definitions & Examples
- One-way ANOVA | When and How to Use It (With Examples)
- Ordinal Data | Definition, Examples, Data Collection & Analysis
- Parameter vs Statistic | Definitions, Differences & Examples
- Pearson Correlation Coefficient (r) | Guide & Examples
- Poisson Distributions | Definition, Formula & Examples
- Probability Distribution | Formula, Types, & Examples
- Quartiles & Quantiles | Calculation, Definition & Interpretation
- Ratio Scales | Definition, Examples, & Data Analysis
- Simple Linear Regression | An Easy Introduction & Examples
- Skewness | Definition, Examples & Formula
- Statistical Power and Why It Matters | A Simple Introduction
- Student's t Table (Free Download) | Guide & Examples
- T-distribution: What it is and how to use it
- Test statistics | Definition, Interpretation, and Examples
- The Standard Normal Distribution | Calculator, Examples & Uses
- Two-Way ANOVA | Examples & When To Use It
- Type I & Type II Errors | Differences, Examples, Visualizations
- Understanding Confidence Intervals | Easy Examples & Formulas
- Understanding P values | Definition and Examples
- Variability | Calculating Range, IQR, Variance, Standard Deviation
- What is Effect Size and Why Does It Matter? (Examples)
- What Is Kurtosis? | Definition, Examples & Formula
- What Is Standard Error? | How to Calculate (Guide with Examples)
What is your plagiarism score?
8 Types of Data Analysis
The different types of data analysis include descriptive, diagnostic, exploratory, inferential, predictive, causal, mechanistic and prescriptive. Here’s what you need to know about each one.
Data analysis is an aspect of data science and data analytics that is all about analyzing data for different kinds of purposes. The data analysis process involves inspecting, cleaning, transforming and modeling data to draw useful insights from it.
Types of Data Analysis
- Descriptive analysis
- Diagnostic analysis
- Exploratory analysis
- Inferential analysis
- Predictive analysis
- Causal analysis
- Mechanistic analysis
- Prescriptive analysis
With its multiple facets, methodologies and techniques, data analysis is used in a variety of fields, including energy, healthcare and marketing, among others. As businesses thrive under the influence of technological advancements in data analytics, data analysis plays a huge role in decision-making , providing a better, faster and more effective system that minimizes risks and reduces human biases .
That said, there are different kinds of data analysis with different goals. We’ll examine each one below.
Two Camps of Data Analysis
Data analysis can be divided into two camps, according to the book R for Data Science :
- Hypothesis Generation: This involves looking deeply at the data and combining your domain knowledge to generate hypotheses about why the data behaves the way it does.
- Hypothesis Confirmation: This involves using a precise mathematical model to generate falsifiable predictions with statistical sophistication to confirm your prior hypotheses.
More on Data Analysis: Data Analyst vs. Data Scientist: Similarities and Differences Explained
Data analysis can be separated and organized into types, arranged in an increasing order of complexity.
1. Descriptive Analysis
The goal of descriptive analysis is to describe or summarize a set of data . Here’s what you need to know:
- Descriptive analysis is the very first analysis performed in the data analysis process.
- It generates simple summaries of samples and measurements.
- It involves common, descriptive statistics like measures of central tendency, variability, frequency and position.
Descriptive Analysis Example
Take the Covid-19 statistics page on Google, for example. The line graph is a pure summary of the cases/deaths, a presentation and description of the population of a particular country infected by the virus.
Descriptive analysis is the first step in analysis where you summarize and describe the data you have using descriptive statistics, and the result is a simple presentation of your data.
2. Diagnostic Analysis
Diagnostic analysis seeks to answer the question “Why did this happen?” by taking a more in-depth look at data to uncover subtle patterns. Here’s what you need to know:
- Diagnostic analysis typically comes after descriptive analysis, taking initial findings and investigating why certain patterns in data happen.
- Diagnostic analysis may involve analyzing other related data sources, including past data, to reveal more insights into current data trends.
- Diagnostic analysis is ideal for further exploring patterns in data to explain anomalies .
Diagnostic Analysis Example
A footwear store wants to review its website traffic levels over the previous 12 months. Upon compiling and assessing the data, the company’s marketing team finds that June experienced above-average levels of traffic while July and August witnessed slightly lower levels of traffic.
To find out why this difference occurred, the marketing team takes a deeper look. Team members break down the data to focus on specific categories of footwear. In the month of June, they discovered that pages featuring sandals and other beach-related footwear received a high number of views while these numbers dropped in July and August.
Marketers may also review other factors like seasonal changes and company sales events to see if other variables could have contributed to this trend.
3. Exploratory Analysis (EDA)
Exploratory analysis involves examining or exploring data and finding relationships between variables that were previously unknown. Here’s what you need to know:
- EDA helps you discover relationships between measures in your data, which are not evidence for the existence of the correlation, as denoted by the phrase, “ Correlation doesn’t imply causation .”
- It’s useful for discovering new connections and forming hypotheses. It drives design planning and data collection .
Exploratory Analysis Example
Climate change is an increasingly important topic as the global temperature has gradually risen over the years. One example of an exploratory data analysis on climate change involves taking the rise in temperature over the years from 1950 to 2020 and the increase of human activities and industrialization to find relationships from the data. For example, you may increase the number of factories, cars on the road and airplane flights to see how that correlates with the rise in temperature.
Exploratory analysis explores data to find relationships between measures without identifying the cause. It’s most useful when formulating hypotheses.
4. Inferential Analysis
Inferential analysis involves using a small sample of data to infer information about a larger population of data.
The goal of statistical modeling itself is all about using a small amount of information to extrapolate and generalize information to a larger group. Here’s what you need to know:
- Inferential analysis involves using estimated data that is representative of a population and gives a measure of uncertainty or standard deviation to your estimation.
- The accuracy of inference depends heavily on your sampling scheme. If the sample isn’t representative of the population, the generalization will be inaccurate. This is known as the central limit theorem .
Inferential Analysis Example
A psychological study on the benefits of sleep might have a total of 500 people involved. When they followed up with the candidates, the candidates reported to have better overall attention spans and well-being with seven to nine hours of sleep, while those with less sleep and more sleep than the given range suffered from reduced attention spans and energy. This study drawn from 500 people was just a tiny portion of the 7 billion people in the world, and is thus an inference of the larger population.
Inferential analysis extrapolates and generalizes the information of the larger group with a smaller sample to generate analysis and predictions.
5. Predictive Analysis
Predictive analysis involves using historical or current data to find patterns and make predictions about the future. Here’s what you need to know:
- The accuracy of the predictions depends on the input variables.
- Accuracy also depends on the types of models. A linear model might work well in some cases, and in other cases it might not.
- Using a variable to predict another one doesn’t denote a causal relationship.
Predictive Analysis Example
The 2020 United States election is a popular topic and many prediction models are built to predict the winning candidate. FiveThirtyEight did this to forecast the 2016 and 2020 elections. Prediction analysis for an election would require input variables such as historical polling data, trends and current polling data in order to return a good prediction. Something as large as an election wouldn’t just be using a linear model, but a complex model with certain tunings to best serve its purpose.
6. Causal Analysis
Causal analysis looks at the cause and effect of relationships between variables and is focused on finding the cause of a correlation. This way, researchers can examine how a change in one variable affects another. Here’s what you need to know:
- To find the cause, you have to question whether the observed correlations driving your conclusion are valid. Just looking at the surface data won’t help you discover the hidden mechanisms underlying the correlations.
- Causal analysis is applied in randomized studies focused on identifying causation.
- Causal analysis is the gold standard in data analysis and scientific studies where the cause of a phenomenon is to be extracted and singled out, like separating wheat from chaff.
- Good data is hard to find and requires expensive research and studies. These studies are analyzed in aggregate (multiple groups), and the observed relationships are just average effects (mean) of the whole population. This means the results might not apply to everyone.
Causal Analysis Example
Say you want to test out whether a new drug improves human strength and focus. To do that, you perform randomized control trials for the drug to test its effect. You compare the sample of candidates for your new drug against the candidates receiving a mock control drug through a few tests focused on strength and overall focus and attention. This will allow you to observe how the drug affects the outcome.
7. Mechanistic Analysis
Mechanistic analysis is used to understand exact changes in variables that lead to other changes in other variables . In some ways, it is a predictive analysis, but it’s modified to tackle studies that require high precision and meticulous methodologies for physical or engineering science. Here’s what you need to know:
- It’s applied in physical or engineering sciences, situations that require high precision and little room for error, only noise in data is measurement error.
- It’s designed to understand a biological or behavioral process, the pathophysiology of a disease or the mechanism of action of an intervention.
Mechanistic Analysis Example
Say an experiment is done to simulate safe and effective nuclear fusion to power the world. A mechanistic analysis of the study would entail a precise balance of controlling and manipulating variables with highly accurate measures of both variables and the desired outcomes. It’s this intricate and meticulous modus operandi toward these big topics that allows for scientific breakthroughs and advancement of society.
8. Prescriptive Analysis
Prescriptive analysis compiles insights from other previous data analyses and determines actions that teams or companies can take to prepare for predicted trends. Here’s what you need to know:
- Prescriptive analysis may come right after predictive analysis, but it may involve combining many different data analyses.
- Companies need advanced technology and plenty of resources to conduct prescriptive analysis. Artificial intelligence systems that process data and adjust automated tasks are an example of the technology required to perform prescriptive analysis.
Prescriptive Analysis Example
Prescriptive analysis is pervasive in everyday life, driving the curated content users consume on social media. On platforms like TikTok and Instagram, algorithms can apply prescriptive analysis to review past content a user has engaged with and the kinds of behaviors they exhibited with specific posts. Based on these factors, an algorithm seeks out similar content that is likely to elicit the same response and recommends it on a user’s personal feed.
More on Data Explaining the Empirical Rule for Normal Distribution
When to Use the Different Types of Data Analysis
- Descriptive analysis summarizes the data at hand and presents your data in a comprehensible way.
- Diagnostic analysis takes a more detailed look at data to reveal why certain patterns occur, making it a good method for explaining anomalies.
- Exploratory data analysis helps you discover correlations and relationships between variables in your data.
- Inferential analysis is for generalizing the larger population with a smaller sample size of data.
- Predictive analysis helps you make predictions about the future with data.
- Causal analysis emphasizes finding the cause of a correlation between variables.
- Mechanistic analysis is for measuring the exact changes in variables that lead to other changes in other variables.
- Prescriptive analysis combines insights from different data analyses to develop a course of action teams and companies can take to capitalize on predicted outcomes.
A few important tips to remember about data analysis include:
- Correlation doesn’t imply causation.
- EDA helps discover new connections and form hypotheses.
- Accuracy of inference depends on the sampling scheme.
- A good prediction depends on the right input variables.
- A simple linear model with enough data usually does the trick.
- Using a variable to predict another doesn’t denote causal relationships.
- Good data is hard to find, and to produce it requires expensive research.
- Results from studies are done in aggregate and are average effects and might not apply to everyone.
Frequently Asked Questions
What is an example of data analysis.
A marketing team reviews a company’s web traffic over the past 12 months. To understand why sales rise and fall during certain months, the team breaks down the data to look at shoe type, seasonal patterns and sales events. Based on this in-depth analysis, the team can determine variables that influenced web traffic and make adjustments as needed.
How do you know which data analysis method to use?
Selecting a data analysis method depends on the goals of the analysis and the complexity of the task, among other factors. It’s best to assess the circumstances and consider the pros and cons of each type of data analysis before moving forward with a particular method.
Recent Data Science Articles

| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|






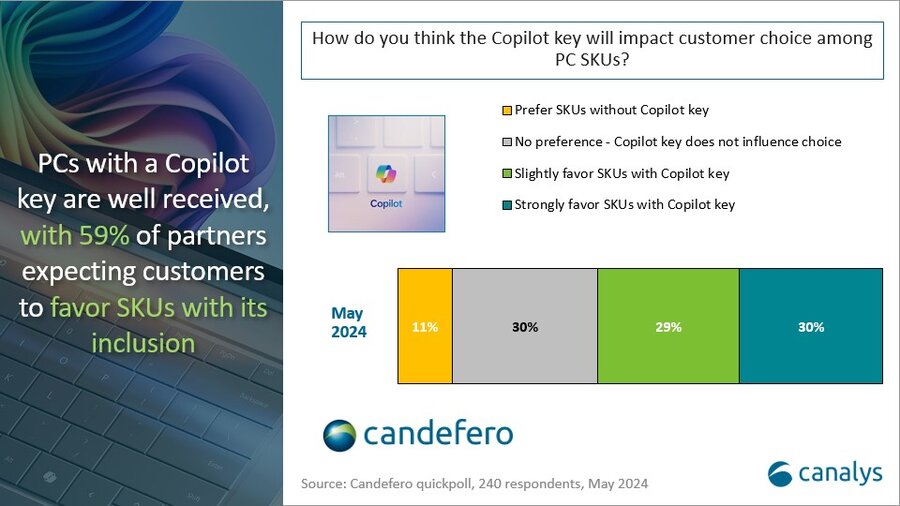




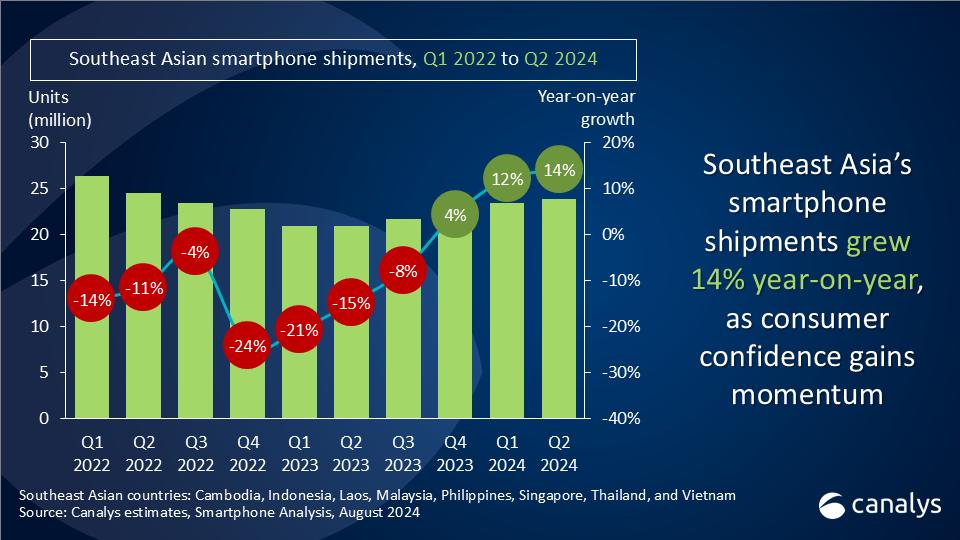


IMAGES
COMMENTS
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense. Three essential things occur during the data ...
data analysis, the process of systematically collecting, cleaning, transforming, describing, modeling, and interpreting data, generally employing statistical techniques. Data analysis is an important part of both scientific research and business, where demand has grown in recent years for data-driven decision making.
What Is Data Analysis? (With Examples) Data analysis is the practice of working with data to glean useful information, which can then be used to make informed decisions. "It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts," Sherlock Holme's proclaims ...
Data analysis is a comprehensive method of inspecting, cleansing, transforming, and modeling data to discover useful information, draw conclusions, and support decision-making. It is a multifaceted process involving various techniques and methodologies to interpret data from various sources in different formats, both structured and unstructured.
Data analysis can be quantitative, qualitative, or mixed methods. Quantitative research typically involves numbers and "close-ended questions and responses" (Creswell & Creswell, 2018, p. 3).Quantitative research tests variables against objective theories, usually measured and collected on instruments and analyzed using statistical procedures (Creswell & Creswell, 2018, p. 4).
Definition: Data analysis refers to the process of inspecting, cleaning, transforming, and modeling data with the goal of discovering useful information, drawing conclusions, and supporting decision-making. It involves applying various statistical and computational techniques to interpret and derive insights from large datasets.
Data analysis is the process of inspecting, cleansing, transforming, and modeling data with the goal of discovering useful information, informing conclusions, and supporting decision-making. [1] Data analysis has multiple facets and approaches, encompassing diverse techniques under a variety of names, and is used in different business, science, and social science domains. [2]
December 17, 2023. Data analysis is the process of cleaning, transforming, and interpreting data to uncover insights, patterns, and trends. It plays a crucial role in decision making, problem solving, and driving innovation across various domains. In addition to further exploring the role data analysis plays this blog post will discuss common ...
Data analysis is the practice of working with data to glean useful information, which can then be used to make informed decisions. ... This idea lies at the root of data analysis. When we can extract meaning from data, it empowers us to make better decisions. ... Learners are advised to conduct additional research to ensure that courses and ...
Analyse the data. By manipulating the data using various data analysis techniques and tools, you can find trends, correlations, outliers, and variations that tell a story. During this stage, you might use data mining to discover patterns within databases or data visualisation software to help transform data into an easy-to-understand graphical ...
An Introductory Guide. Data analysis is the process of inspecting, cleaning, transforming, and modeling data to derive meaningful insights and make informed decisions. It involves examining raw data to identify patterns, trends, and relationships that can be used to understand various aspects of a business, organization, or phenomenon.
This article is a practical guide to conducting data analysis in general literature reviews. The general literature review is a synthesis and analysis of published research on a relevant clinical issue, and is a common format for academic theses at the bachelor's and master's levels in nursing, physiotherapy, occupational therapy, public health and other related fields.
Prescriptive analysis is a decision-making analysis that uses mathematical modeling, optimization algorithms, and other data-driven techniques to identify the action for a given problem or situation. It combines mathematical models, data, and business constraints to find the best move or decision.
Data Analysis Tools. Data analysis tools make it easier for users to process and manipulate data, analyze the relationships and correlations between data sets, and it also helps to identify patterns and trends for interpretation. Here is a complete list of tools used for data analysis in research. Types of Data Analysis: Techniques and Methods
Data analysis in research is the process of uncovering insights from data sets. Data analysts can use their knowledge of statistical techniques, research theories and methods, and research practices to analyze data. They take data and uncover what it's trying to tell us, whether that's through charts, graphs, or other visual representations.
Statistical analysis means investigating trends, patterns, and relationships using quantitative data. It is an important research tool used by scientists, governments, businesses, and other organizations. To draw valid conclusions, statistical analysis requires careful planning from the very start of the research process. You need to specify ...
Exploratory analysis. Inferential analysis. Predictive analysis. Causal analysis. Mechanistic analysis. Prescriptive analysis. With its multiple facets, methodologies and techniques, data analysis is used in a variety of fields, including energy, healthcare and marketing, among others. As businesses thrive under the influence of technological ...
Data analysis in research is the systematic process of investigating facts and figures to make conclusions about a specific question or topic; there are two major types of data analysis methods in ...
Research is a scientific field which helps to generate new knowledge and solve the existing problem. So, data analysis is the crucial part of research which makes the result of the study more ...
Data Analysis is the process of systematically applying statistical and/or logical techniques to describe and illustrate, condense and recap, and evaluate data. According to Shamoo and Resnik (2003) various analytic procedures "provide a way of drawing inductive inferences from data and distinguishing the signal (the phenomenon of interest) from the noise (statistical fluctuations) present ...
Data analysis is the most crucial part of any research. Data analysis summarizes collected data. It involves the interpretation of data gathered through the use of analytical and logical reasoning to determine patterns, relationships or trends.
Qualitative data analysis is. concerned with transforming raw data by searching, evaluating, recogni sing, cod ing, mapping, exploring and describing patterns, trends, themes an d categories in ...
A Simplified Definition. Statistical analysis uses quantitative data to investigate patterns, relationships, and patterns to understand real-life and simulated phenomena. The approach is a key analytical tool in various fields, including academia, business, government, and science in general. This statistical analysis in research definition ...
Subjective data analysis plays a crucial role in qualitative research by providing rich, in-depth insights into participants' experiences. Understanding subjective data means interpreting the thoughts, feelings, and perspectives shared by individuals through methods like interviews, focus groups, or open-ended surveys.
It involves data discovery, drill-down, and correlations to identify the root causes of past outcomes. Predictive Analytics: This type of analytics uses historical data to forecast future events. Techniques such as regression analysis, time series analysis, and machine learning are employed to predict future trends and behaviors.
Research is shedding light on different chromosomal make-ups and what advantages they may bring to sport.
About PC Analysis. Canalys' PC Analysis service provides quarterly updated shipment data to help with accurate market sizing, competitive analysis and identifying growth opportunities in the market. Canalys PC shipment data is granular, guided by a strict methodology, and broken down by market, vendor and channel, with additional splits, such ...
Analysis. The FDIC is proud to be a pre-eminent source of U.S. banking industry research, including quarterly banking profiles, working papers, and state banking performance data. Browse our extensive research tools and reports. More FDIC Analysis
The increasing market of ultra-processed traditional Indian recipes with poor nutritional profile needs more scrutiny and research. Saliency analysis identified the preferred UPFs among the Indian population with breads, chips and sugar-sweetened beverages being the most preferred UPFs and frozen non-vegetarian snacks being the least preferred.
Brand deals are the main source of revenue at about 70%, according to survey data. Only about 4% of global creators are deemed professionals, meaning they pull in more than $100,000 a year. Goldman Sachs Research expects their share of the creator universe to stay steady even as the overall ecosystem expands.