- Skip to secondary menu
- Skip to main content
- Skip to primary sidebar
Statistics By Jim
Making statistics intuitive

Null Hypothesis: Definition, Rejecting & Examples
By Jim Frost 6 Comments
What is a Null Hypothesis?
The null hypothesis in statistics states that there is no difference between groups or no relationship between variables. It is one of two mutually exclusive hypotheses about a population in a hypothesis test.

- Null Hypothesis H 0 : No effect exists in the population.
- Alternative Hypothesis H A : The effect exists in the population.
In every study or experiment, researchers assess an effect or relationship. This effect can be the effectiveness of a new drug, building material, or other intervention that has benefits. There is a benefit or connection that the researchers hope to identify. Unfortunately, no effect may exist. In statistics, we call this lack of an effect the null hypothesis. Researchers assume that this notion of no effect is correct until they have enough evidence to suggest otherwise, similar to how a trial presumes innocence.
In this context, the analysts don’t necessarily believe the null hypothesis is correct. In fact, they typically want to reject it because that leads to more exciting finds about an effect or relationship. The new vaccine works!
You can think of it as the default theory that requires sufficiently strong evidence to reject. Like a prosecutor, researchers must collect sufficient evidence to overturn the presumption of no effect. Investigators must work hard to set up a study and a data collection system to obtain evidence that can reject the null hypothesis.
Related post : What is an Effect in Statistics?
Null Hypothesis Examples
Null hypotheses start as research questions that the investigator rephrases as a statement indicating there is no effect or relationship.
| Does the vaccine prevent infections? | The vaccine does not affect the infection rate. |
| Does the new additive increase product strength? | The additive does not affect mean product strength. |
| Does the exercise intervention increase bone mineral density? | The intervention does not affect bone mineral density. |
| As screen time increases, does test performance decrease? | There is no relationship between screen time and test performance. |
After reading these examples, you might think they’re a bit boring and pointless. However, the key is to remember that the null hypothesis defines the condition that the researchers need to discredit before suggesting an effect exists.
Let’s see how you reject the null hypothesis and get to those more exciting findings!
When to Reject the Null Hypothesis
So, you want to reject the null hypothesis, but how and when can you do that? To start, you’ll need to perform a statistical test on your data. The following is an overview of performing a study that uses a hypothesis test.
The first step is to devise a research question and the appropriate null hypothesis. After that, the investigators need to formulate an experimental design and data collection procedures that will allow them to gather data that can answer the research question. Then they collect the data. For more information about designing a scientific study that uses statistics, read my post 5 Steps for Conducting Studies with Statistics .
After data collection is complete, statistics and hypothesis testing enter the picture. Hypothesis testing takes your sample data and evaluates how consistent they are with the null hypothesis. The p-value is a crucial part of the statistical results because it quantifies how strongly the sample data contradict the null hypothesis.
When the sample data provide sufficient evidence, you can reject the null hypothesis. In a hypothesis test, this process involves comparing the p-value to your significance level .
Rejecting the Null Hypothesis
Reject the null hypothesis when the p-value is less than or equal to your significance level. Your sample data favor the alternative hypothesis, which suggests that the effect exists in the population. For a mnemonic device, remember—when the p-value is low, the null must go!
When you can reject the null hypothesis, your results are statistically significant. Learn more about Statistical Significance: Definition & Meaning .
Failing to Reject the Null Hypothesis
Conversely, when the p-value is greater than your significance level, you fail to reject the null hypothesis. The sample data provides insufficient data to conclude that the effect exists in the population. When the p-value is high, the null must fly!
Note that failing to reject the null is not the same as proving it. For more information about the difference, read my post about Failing to Reject the Null .
That’s a very general look at the process. But I hope you can see how the path to more exciting findings depends on being able to rule out the less exciting null hypothesis that states there’s nothing to see here!
Let’s move on to learning how to write the null hypothesis for different types of effects, relationships, and tests.
Related posts : How Hypothesis Tests Work and Interpreting P-values
How to Write a Null Hypothesis
The null hypothesis varies by the type of statistic and hypothesis test. Remember that inferential statistics use samples to draw conclusions about populations. Consequently, when you write a null hypothesis, it must make a claim about the relevant population parameter . Further, that claim usually indicates that the effect does not exist in the population. Below are typical examples of writing a null hypothesis for various parameters and hypothesis tests.
Related posts : Descriptive vs. Inferential Statistics and Populations, Parameters, and Samples in Inferential Statistics
Group Means
T-tests and ANOVA assess the differences between group means. For these tests, the null hypothesis states that there is no difference between group means in the population. In other words, the experimental conditions that define the groups do not affect the mean outcome. Mu (µ) is the population parameter for the mean, and you’ll need to include it in the statement for this type of study.
For example, an experiment compares the mean bone density changes for a new osteoporosis medication. The control group does not receive the medicine, while the treatment group does. The null states that the mean bone density changes for the control and treatment groups are equal.
- Null Hypothesis H 0 : Group means are equal in the population: µ 1 = µ 2 , or µ 1 – µ 2 = 0
- Alternative Hypothesis H A : Group means are not equal in the population: µ 1 ≠ µ 2 , or µ 1 – µ 2 ≠ 0.
Group Proportions
Proportions tests assess the differences between group proportions. For these tests, the null hypothesis states that there is no difference between group proportions. Again, the experimental conditions did not affect the proportion of events in the groups. P is the population proportion parameter that you’ll need to include.
For example, a vaccine experiment compares the infection rate in the treatment group to the control group. The treatment group receives the vaccine, while the control group does not. The null states that the infection rates for the control and treatment groups are equal.
- Null Hypothesis H 0 : Group proportions are equal in the population: p 1 = p 2 .
- Alternative Hypothesis H A : Group proportions are not equal in the population: p 1 ≠ p 2 .
Correlation and Regression Coefficients
Some studies assess the relationship between two continuous variables rather than differences between groups.
In these studies, analysts often use either correlation or regression analysis . For these tests, the null states that there is no relationship between the variables. Specifically, it says that the correlation or regression coefficient is zero. As one variable increases, there is no tendency for the other variable to increase or decrease. Rho (ρ) is the population correlation parameter and beta (β) is the regression coefficient parameter.
For example, a study assesses the relationship between screen time and test performance. The null states that there is no correlation between this pair of variables. As screen time increases, test performance does not tend to increase or decrease.
- Null Hypothesis H 0 : The correlation in the population is zero: ρ = 0.
- Alternative Hypothesis H A : The correlation in the population is not zero: ρ ≠ 0.
For all these cases, the analysts define the hypotheses before the study. After collecting the data, they perform a hypothesis test to determine whether they can reject the null hypothesis.
The preceding examples are all for two-tailed hypothesis tests. To learn about one-tailed tests and how to write a null hypothesis for them, read my post One-Tailed vs. Two-Tailed Tests .
Related post : Understanding Correlation
Neyman, J; Pearson, E. S. (January 1, 1933). On the Problem of the most Efficient Tests of Statistical Hypotheses . Philosophical Transactions of the Royal Society A . 231 (694–706): 289–337.
Share this:

Reader Interactions

January 11, 2024 at 2:57 pm
Thanks for the reply.
January 10, 2024 at 1:23 pm
Hi Jim, In your comment you state that equivalence test null and alternate hypotheses are reversed. For hypothesis tests of data fits to a probability distribution, the null hypothesis is that the probability distribution fits the data. Is this correct?

January 10, 2024 at 2:15 pm
Those two separate things, equivalence testing and normality tests. But, yes, you’re correct for both.
Hypotheses are switched for equivalence testing. You need to “work” (i.e., collect a large sample of good quality data) to be able to reject the null that the groups are different to be able to conclude they’re the same.
With typical hypothesis tests, if you have low quality data and a low sample size, you’ll fail to reject the null that they’re the same, concluding they’re equivalent. But that’s more a statement about the low quality and small sample size than anything to do with the groups being equal.
So, equivalence testing make you work to obtain a finding that the groups are the same (at least within some amount you define as a trivial difference).
For normality testing, and other distribution tests, the null states that the data follow the distribution (normal or whatever). If you reject the null, you have sufficient evidence to conclude that your sample data don’t follow the probability distribution. That’s a rare case where you hope to fail to reject the null. And it suffers from the problem I describe above where you might fail to reject the null simply because you have a small sample size. In that case, you’d conclude the data follow the probability distribution but it’s more that you don’t have enough data for the test to register the deviation. In this scenario, if you had a larger sample size, you’d reject the null and conclude it doesn’t follow that distribution.
I don’t know of any equivalence testing type approach for distribution fit tests where you’d need to work to show the data follow a distribution, although I haven’t looked for one either!

February 20, 2022 at 9:26 pm
Is a null hypothesis regularly (always) stated in the negative? “there is no” or “does not”
February 23, 2022 at 9:21 pm
Typically, the null hypothesis includes an equal sign. The null hypothesis states that the population parameter equals a particular value. That value is usually one that represents no effect. In the case of a one-sided hypothesis test, the null still contains an equal sign but it’s “greater than or equal to” or “less than or equal to.” If you wanted to translate the null hypothesis from its native mathematical expression, you could use the expression “there is no effect.” But the mathematical form more specifically states what it’s testing.
It’s the alternative hypothesis that typically contains does not equal.
There are some exceptions. For example, in an equivalence test where the researchers want to show that two things are equal, the null hypothesis states that they’re not equal.
In short, the null hypothesis states the condition that the researchers hope to reject. They need to work hard to set up an experiment and data collection that’ll gather enough evidence to be able to reject the null condition.

February 15, 2022 at 9:32 am
Dear sir I always read your notes on Research methods.. Kindly tell is there any available Book on all these..wonderfull Urgent
Comments and Questions Cancel reply
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 13: Inferential Statistics
Understanding Null Hypothesis Testing
Learning Objectives
- Explain the purpose of null hypothesis testing, including the role of sampling error.
- Describe the basic logic of null hypothesis testing.
- Describe the role of relationship strength and sample size in determining statistical significance and make reasonable judgments about statistical significance based on these two factors.
The Purpose of Null Hypothesis Testing
As we have seen, psychological research typically involves measuring one or more variables for a sample and computing descriptive statistics for that sample. In general, however, the researcher’s goal is not to draw conclusions about that sample but to draw conclusions about the population that the sample was selected from. Thus researchers must use sample statistics to draw conclusions about the corresponding values in the population. These corresponding values in the population are called parameters . Imagine, for example, that a researcher measures the number of depressive symptoms exhibited by each of 50 clinically depressed adults and computes the mean number of symptoms. The researcher probably wants to use this sample statistic (the mean number of symptoms for the sample) to draw conclusions about the corresponding population parameter (the mean number of symptoms for clinically depressed adults).
Unfortunately, sample statistics are not perfect estimates of their corresponding population parameters. This is because there is a certain amount of random variability in any statistic from sample to sample. The mean number of depressive symptoms might be 8.73 in one sample of clinically depressed adults, 6.45 in a second sample, and 9.44 in a third—even though these samples are selected randomly from the same population. Similarly, the correlation (Pearson’s r ) between two variables might be +.24 in one sample, −.04 in a second sample, and +.15 in a third—again, even though these samples are selected randomly from the same population. This random variability in a statistic from sample to sample is called sampling error . (Note that the term error here refers to random variability and does not imply that anyone has made a mistake. No one “commits a sampling error.”)
One implication of this is that when there is a statistical relationship in a sample, it is not always clear that there is a statistical relationship in the population. A small difference between two group means in a sample might indicate that there is a small difference between the two group means in the population. But it could also be that there is no difference between the means in the population and that the difference in the sample is just a matter of sampling error. Similarly, a Pearson’s r value of −.29 in a sample might mean that there is a negative relationship in the population. But it could also be that there is no relationship in the population and that the relationship in the sample is just a matter of sampling error.
In fact, any statistical relationship in a sample can be interpreted in two ways:
- There is a relationship in the population, and the relationship in the sample reflects this.
- There is no relationship in the population, and the relationship in the sample reflects only sampling error.
The purpose of null hypothesis testing is simply to help researchers decide between these two interpretations.
The Logic of Null Hypothesis Testing
Null hypothesis testing is a formal approach to deciding between two interpretations of a statistical relationship in a sample. One interpretation is called the null hypothesis (often symbolized H 0 and read as “H-naught”). This is the idea that there is no relationship in the population and that the relationship in the sample reflects only sampling error. Informally, the null hypothesis is that the sample relationship “occurred by chance.” The other interpretation is called the alternative hypothesis (often symbolized as H 1 ). This is the idea that there is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
Again, every statistical relationship in a sample can be interpreted in either of these two ways: It might have occurred by chance, or it might reflect a relationship in the population. So researchers need a way to decide between them. Although there are many specific null hypothesis testing techniques, they are all based on the same general logic. The steps are as follows:
- Assume for the moment that the null hypothesis is true. There is no relationship between the variables in the population.
- Determine how likely the sample relationship would be if the null hypothesis were true.
- If the sample relationship would be extremely unlikely, then reject the null hypothesis in favour of the alternative hypothesis. If it would not be extremely unlikely, then retain the null hypothesis .
Following this logic, we can begin to understand why Mehl and his colleagues concluded that there is no difference in talkativeness between women and men in the population. In essence, they asked the following question: “If there were no difference in the population, how likely is it that we would find a small difference of d = 0.06 in our sample?” Their answer to this question was that this sample relationship would be fairly likely if the null hypothesis were true. Therefore, they retained the null hypothesis—concluding that there is no evidence of a sex difference in the population. We can also see why Kanner and his colleagues concluded that there is a correlation between hassles and symptoms in the population. They asked, “If the null hypothesis were true, how likely is it that we would find a strong correlation of +.60 in our sample?” Their answer to this question was that this sample relationship would be fairly unlikely if the null hypothesis were true. Therefore, they rejected the null hypothesis in favour of the alternative hypothesis—concluding that there is a positive correlation between these variables in the population.
A crucial step in null hypothesis testing is finding the likelihood of the sample result if the null hypothesis were true. This probability is called the p value . A low p value means that the sample result would be unlikely if the null hypothesis were true and leads to the rejection of the null hypothesis. A high p value means that the sample result would be likely if the null hypothesis were true and leads to the retention of the null hypothesis. But how low must the p value be before the sample result is considered unlikely enough to reject the null hypothesis? In null hypothesis testing, this criterion is called α (alpha) and is almost always set to .05. If there is less than a 5% chance of a result as extreme as the sample result if the null hypothesis were true, then the null hypothesis is rejected. When this happens, the result is said to be statistically significant . If there is greater than a 5% chance of a result as extreme as the sample result when the null hypothesis is true, then the null hypothesis is retained. This does not necessarily mean that the researcher accepts the null hypothesis as true—only that there is not currently enough evidence to conclude that it is true. Researchers often use the expression “fail to reject the null hypothesis” rather than “retain the null hypothesis,” but they never use the expression “accept the null hypothesis.”
The Misunderstood p Value
The p value is one of the most misunderstood quantities in psychological research (Cohen, 1994) [1] . Even professional researchers misinterpret it, and it is not unusual for such misinterpretations to appear in statistics textbooks!
The most common misinterpretation is that the p value is the probability that the null hypothesis is true—that the sample result occurred by chance. For example, a misguided researcher might say that because the p value is .02, there is only a 2% chance that the result is due to chance and a 98% chance that it reflects a real relationship in the population. But this is incorrect . The p value is really the probability of a result at least as extreme as the sample result if the null hypothesis were true. So a p value of .02 means that if the null hypothesis were true, a sample result this extreme would occur only 2% of the time.
You can avoid this misunderstanding by remembering that the p value is not the probability that any particular hypothesis is true or false. Instead, it is the probability of obtaining the sample result if the null hypothesis were true.
Role of Sample Size and Relationship Strength
Recall that null hypothesis testing involves answering the question, “If the null hypothesis were true, what is the probability of a sample result as extreme as this one?” In other words, “What is the p value?” It can be helpful to see that the answer to this question depends on just two considerations: the strength of the relationship and the size of the sample. Specifically, the stronger the sample relationship and the larger the sample, the less likely the result would be if the null hypothesis were true. That is, the lower the p value. This should make sense. Imagine a study in which a sample of 500 women is compared with a sample of 500 men in terms of some psychological characteristic, and Cohen’s d is a strong 0.50. If there were really no sex difference in the population, then a result this strong based on such a large sample should seem highly unlikely. Now imagine a similar study in which a sample of three women is compared with a sample of three men, and Cohen’s d is a weak 0.10. If there were no sex difference in the population, then a relationship this weak based on such a small sample should seem likely. And this is precisely why the null hypothesis would be rejected in the first example and retained in the second.
Of course, sometimes the result can be weak and the sample large, or the result can be strong and the sample small. In these cases, the two considerations trade off against each other so that a weak result can be statistically significant if the sample is large enough and a strong relationship can be statistically significant even if the sample is small. Table 13.1 shows roughly how relationship strength and sample size combine to determine whether a sample result is statistically significant. The columns of the table represent the three levels of relationship strength: weak, medium, and strong. The rows represent four sample sizes that can be considered small, medium, large, and extra large in the context of psychological research. Thus each cell in the table represents a combination of relationship strength and sample size. If a cell contains the word Yes , then this combination would be statistically significant for both Cohen’s d and Pearson’s r . If it contains the word No , then it would not be statistically significant for either. There is one cell where the decision for d and r would be different and another where it might be different depending on some additional considerations, which are discussed in Section 13.2 “Some Basic Null Hypothesis Tests”
| Sample Size | Weak relationship | Medium-strength relationship | Strong relationship |
|---|---|---|---|
| Small ( = 20) | No | No | = Maybe = Yes |
| Medium ( = 50) | No | Yes | Yes |
| Large ( = 100) | = Yes = No | Yes | Yes |
| Extra large ( = 500) | Yes | Yes | Yes |
Although Table 13.1 provides only a rough guideline, it shows very clearly that weak relationships based on medium or small samples are never statistically significant and that strong relationships based on medium or larger samples are always statistically significant. If you keep this lesson in mind, you will often know whether a result is statistically significant based on the descriptive statistics alone. It is extremely useful to be able to develop this kind of intuitive judgment. One reason is that it allows you to develop expectations about how your formal null hypothesis tests are going to come out, which in turn allows you to detect problems in your analyses. For example, if your sample relationship is strong and your sample is medium, then you would expect to reject the null hypothesis. If for some reason your formal null hypothesis test indicates otherwise, then you need to double-check your computations and interpretations. A second reason is that the ability to make this kind of intuitive judgment is an indication that you understand the basic logic of this approach in addition to being able to do the computations.
Statistical Significance Versus Practical Significance
Table 13.1 illustrates another extremely important point. A statistically significant result is not necessarily a strong one. Even a very weak result can be statistically significant if it is based on a large enough sample. This is closely related to Janet Shibley Hyde’s argument about sex differences (Hyde, 2007) [2] . The differences between women and men in mathematical problem solving and leadership ability are statistically significant. But the word significant can cause people to interpret these differences as strong and important—perhaps even important enough to influence the college courses they take or even who they vote for. As we have seen, however, these statistically significant differences are actually quite weak—perhaps even “trivial.”
This is why it is important to distinguish between the statistical significance of a result and the practical significance of that result. Practical significance refers to the importance or usefulness of the result in some real-world context. Many sex differences are statistically significant—and may even be interesting for purely scientific reasons—but they are not practically significant. In clinical practice, this same concept is often referred to as “clinical significance.” For example, a study on a new treatment for social phobia might show that it produces a statistically significant positive effect. Yet this effect still might not be strong enough to justify the time, effort, and other costs of putting it into practice—especially if easier and cheaper treatments that work almost as well already exist. Although statistically significant, this result would be said to lack practical or clinical significance.
Key Takeaways
- Null hypothesis testing is a formal approach to deciding whether a statistical relationship in a sample reflects a real relationship in the population or is just due to chance.
- The logic of null hypothesis testing involves assuming that the null hypothesis is true, finding how likely the sample result would be if this assumption were correct, and then making a decision. If the sample result would be unlikely if the null hypothesis were true, then it is rejected in favour of the alternative hypothesis. If it would not be unlikely, then the null hypothesis is retained.
- The probability of obtaining the sample result if the null hypothesis were true (the p value) is based on two considerations: relationship strength and sample size. Reasonable judgments about whether a sample relationship is statistically significant can often be made by quickly considering these two factors.
- Statistical significance is not the same as relationship strength or importance. Even weak relationships can be statistically significant if the sample size is large enough. It is important to consider relationship strength and the practical significance of a result in addition to its statistical significance.
- Discussion: Imagine a study showing that people who eat more broccoli tend to be happier. Explain for someone who knows nothing about statistics why the researchers would conduct a null hypothesis test.
- The correlation between two variables is r = −.78 based on a sample size of 137.
- The mean score on a psychological characteristic for women is 25 ( SD = 5) and the mean score for men is 24 ( SD = 5). There were 12 women and 10 men in this study.
- In a memory experiment, the mean number of items recalled by the 40 participants in Condition A was 0.50 standard deviations greater than the mean number recalled by the 40 participants in Condition B.
- In another memory experiment, the mean scores for participants in Condition A and Condition B came out exactly the same!
- A student finds a correlation of r = .04 between the number of units the students in his research methods class are taking and the students’ level of stress.
Long Descriptions
“Null Hypothesis” long description: A comic depicting a man and a woman talking in the foreground. In the background is a child working at a desk. The man says to the woman, “I can’t believe schools are still teaching kids about the null hypothesis. I remember reading a big study that conclusively disproved it years ago.” [Return to “Null Hypothesis”]
“Conditional Risk” long description: A comic depicting two hikers beside a tree during a thunderstorm. A bolt of lightning goes “crack” in the dark sky as thunder booms. One of the hikers says, “Whoa! We should get inside!” The other hiker says, “It’s okay! Lightning only kills about 45 Americans a year, so the chances of dying are only one in 7,000,000. Let’s go on!” The comic’s caption says, “The annual death rate among people who know that statistic is one in six.” [Return to “Conditional Risk”]
Media Attributions
- Null Hypothesis by XKCD CC BY-NC (Attribution NonCommercial)
- Conditional Risk by XKCD CC BY-NC (Attribution NonCommercial)
- Cohen, J. (1994). The world is round: p < .05. American Psychologist, 49 , 997–1003. ↵
- Hyde, J. S. (2007). New directions in the study of gender similarities and differences. Current Directions in Psychological Science, 16 , 259–263. ↵
Values in a population that correspond to variables measured in a study.
The random variability in a statistic from sample to sample.
A formal approach to deciding between two interpretations of a statistical relationship in a sample.
The idea that there is no relationship in the population and that the relationship in the sample reflects only sampling error.
The idea that there is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
When the relationship found in the sample would be extremely unlikely, the idea that the relationship occurred “by chance” is rejected.
When the relationship found in the sample is likely to have occurred by chance, the null hypothesis is not rejected.
The probability that, if the null hypothesis were true, the result found in the sample would occur.
How low the p value must be before the sample result is considered unlikely in null hypothesis testing.
When there is less than a 5% chance of a result as extreme as the sample result occurring and the null hypothesis is rejected.
Research Methods in Psychology - 2nd Canadian Edition Copyright © 2015 by Paul C. Price, Rajiv Jhangiani, & I-Chant A. Chiang is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
13.1 Understanding Null Hypothesis Testing
Learning objectives.
- Explain the purpose of null hypothesis testing, including the role of sampling error.
- Describe the basic logic of null hypothesis testing.
- Describe the role of relationship strength and sample size in determining statistical significance and make reasonable judgments about statistical significance based on these two factors.
The Purpose of Null Hypothesis Testing
As we have seen, psychological research typically involves measuring one or more variables in a sample and computing descriptive statistics for that sample. In general, however, the researcher’s goal is not to draw conclusions about that sample but to draw conclusions about the population that the sample was selected from. Thus researchers must use sample statistics to draw conclusions about the corresponding values in the population. These corresponding values in the population are called parameters . Imagine, for example, that a researcher measures the number of depressive symptoms exhibited by each of 50 adults with clinical depression and computes the mean number of symptoms. The researcher probably wants to use this sample statistic (the mean number of symptoms for the sample) to draw conclusions about the corresponding population parameter (the mean number of symptoms for adults with clinical depression).
Unfortunately, sample statistics are not perfect estimates of their corresponding population parameters. This is because there is a certain amount of random variability in any statistic from sample to sample. The mean number of depressive symptoms might be 8.73 in one sample of adults with clinical depression, 6.45 in a second sample, and 9.44 in a third—even though these samples are selected randomly from the same population. Similarly, the correlation (Pearson’s r ) between two variables might be +.24 in one sample, −.04 in a second sample, and +.15 in a third—again, even though these samples are selected randomly from the same population. This random variability in a statistic from sample to sample is called sampling error . (Note that the term error here refers to random variability and does not imply that anyone has made a mistake. No one “commits a sampling error.”)
One implication of this is that when there is a statistical relationship in a sample, it is not always clear that there is a statistical relationship in the population. A small difference between two group means in a sample might indicate that there is a small difference between the two group means in the population. But it could also be that there is no difference between the means in the population and that the difference in the sample is just a matter of sampling error. Similarly, a Pearson’s r value of −.29 in a sample might mean that there is a negative relationship in the population. But it could also be that there is no relationship in the population and that the relationship in the sample is just a matter of sampling error.
In fact, any statistical relationship in a sample can be interpreted in two ways:
- There is a relationship in the population, and the relationship in the sample reflects this.
- There is no relationship in the population, and the relationship in the sample reflects only sampling error.
The purpose of null hypothesis testing is simply to help researchers decide between these two interpretations.
The Logic of Null Hypothesis Testing
Null hypothesis testing is a formal approach to deciding between two interpretations of a statistical relationship in a sample. One interpretation is called the null hypothesis (often symbolized H 0 and read as “H-naught”). This is the idea that there is no relationship in the population and that the relationship in the sample reflects only sampling error. Informally, the null hypothesis is that the sample relationship “occurred by chance.” The other interpretation is called the alternative hypothesis (often symbolized as H 1 ). This is the idea that there is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
Again, every statistical relationship in a sample can be interpreted in either of these two ways: It might have occurred by chance, or it might reflect a relationship in the population. So researchers need a way to decide between them. Although there are many specific null hypothesis testing techniques, they are all based on the same general logic. The steps are as follows:
- Assume for the moment that the null hypothesis is true. There is no relationship between the variables in the population.
- Determine how likely the sample relationship would be if the null hypothesis were true.
- If the sample relationship would be extremely unlikely, then reject the null hypothesis in favor of the alternative hypothesis. If it would not be extremely unlikely, then retain the null hypothesis .
Following this logic, we can begin to understand why Mehl and his colleagues concluded that there is no difference in talkativeness between women and men in the population. In essence, they asked the following question: “If there were no difference in the population, how likely is it that we would find a small difference of d = 0.06 in our sample?” Their answer to this question was that this sample relationship would be fairly likely if the null hypothesis were true. Therefore, they retained the null hypothesis—concluding that there is no evidence of a sex difference in the population. We can also see why Kanner and his colleagues concluded that there is a correlation between hassles and symptoms in the population. They asked, “If the null hypothesis were true, how likely is it that we would find a strong correlation of +.60 in our sample?” Their answer to this question was that this sample relationship would be fairly unlikely if the null hypothesis were true. Therefore, they rejected the null hypothesis in favor of the alternative hypothesis—concluding that there is a positive correlation between these variables in the population.
A crucial step in null hypothesis testing is finding the likelihood of the sample result if the null hypothesis were true. This probability is called the p value . A low p value means that the sample result would be unlikely if the null hypothesis were true and leads to the rejection of the null hypothesis. A p value that is not low means that the sample result would be likely if the null hypothesis were true and leads to the retention of the null hypothesis. But how low must the p value be before the sample result is considered unlikely enough to reject the null hypothesis? In null hypothesis testing, this criterion is called α (alpha) and is almost always set to .05. If there is a 5% chance or less of a result as extreme as the sample result if the null hypothesis were true, then the null hypothesis is rejected. When this happens, the result is said to be statistically significant . If there is greater than a 5% chance of a result as extreme as the sample result when the null hypothesis is true, then the null hypothesis is retained. This does not necessarily mean that the researcher accepts the null hypothesis as true—only that there is not currently enough evidence to reject it. Researchers often use the expression “fail to reject the null hypothesis” rather than “retain the null hypothesis,” but they never use the expression “accept the null hypothesis.”
The Misunderstood p Value
The p value is one of the most misunderstood quantities in psychological research (Cohen, 1994) [1] . Even professional researchers misinterpret it, and it is not unusual for such misinterpretations to appear in statistics textbooks!
The most common misinterpretation is that the p value is the probability that the null hypothesis is true—that the sample result occurred by chance. For example, a misguided researcher might say that because the p value is .02, there is only a 2% chance that the result is due to chance and a 98% chance that it reflects a real relationship in the population. But this is incorrect . The p value is really the probability of a result at least as extreme as the sample result if the null hypothesis were true. So a p value of .02 means that if the null hypothesis were true, a sample result this extreme would occur only 2% of the time.
You can avoid this misunderstanding by remembering that the p value is not the probability that any particular hypothesis is true or false. Instead, it is the probability of obtaining the sample result if the null hypothesis were true.

“Null Hypothesis” retrieved from http://imgs.xkcd.com/comics/null_hypothesis.png (CC-BY-NC 2.5)
Role of Sample Size and Relationship Strength
Recall that null hypothesis testing involves answering the question, “If the null hypothesis were true, what is the probability of a sample result as extreme as this one?” In other words, “What is the p value?” It can be helpful to see that the answer to this question depends on just two considerations: the strength of the relationship and the size of the sample. Specifically, the stronger the sample relationship and the larger the sample, the less likely the result would be if the null hypothesis were true. That is, the lower the p value. This should make sense. Imagine a study in which a sample of 500 women is compared with a sample of 500 men in terms of some psychological characteristic, and Cohen’s d is a strong 0.50. If there were really no sex difference in the population, then a result this strong based on such a large sample should seem highly unlikely. Now imagine a similar study in which a sample of three women is compared with a sample of three men, and Cohen’s d is a weak 0.10. If there were no sex difference in the population, then a relationship this weak based on such a small sample should seem likely. And this is precisely why the null hypothesis would be rejected in the first example and retained in the second.
Of course, sometimes the result can be weak and the sample large, or the result can be strong and the sample small. In these cases, the two considerations trade off against each other so that a weak result can be statistically significant if the sample is large enough and a strong relationship can be statistically significant even if the sample is small. Table 13.1 shows roughly how relationship strength and sample size combine to determine whether a sample result is statistically significant. The columns of the table represent the three levels of relationship strength: weak, medium, and strong. The rows represent four sample sizes that can be considered small, medium, large, and extra large in the context of psychological research. Thus each cell in the table represents a combination of relationship strength and sample size. If a cell contains the word Yes , then this combination would be statistically significant for both Cohen’s d and Pearson’s r . If it contains the word No , then it would not be statistically significant for either. There is one cell where the decision for d and r would be different and another where it might be different depending on some additional considerations, which are discussed in Section 13.2 “Some Basic Null Hypothesis Tests”
| Sample Size | Weak | Medium | Strong |
| Small ( = 20) | No | No | = Maybe = Yes |
| Medium ( = 50) | No | Yes | Yes |
| Large ( = 100) | = Yes = No | Yes | Yes |
| Extra large ( = 500) | Yes | Yes | Yes |
Although Table 13.1 provides only a rough guideline, it shows very clearly that weak relationships based on medium or small samples are never statistically significant and that strong relationships based on medium or larger samples are always statistically significant. If you keep this lesson in mind, you will often know whether a result is statistically significant based on the descriptive statistics alone. It is extremely useful to be able to develop this kind of intuitive judgment. One reason is that it allows you to develop expectations about how your formal null hypothesis tests are going to come out, which in turn allows you to detect problems in your analyses. For example, if your sample relationship is strong and your sample is medium, then you would expect to reject the null hypothesis. If for some reason your formal null hypothesis test indicates otherwise, then you need to double-check your computations and interpretations. A second reason is that the ability to make this kind of intuitive judgment is an indication that you understand the basic logic of this approach in addition to being able to do the computations.
Statistical Significance Versus Practical Significance
Table 13.1 illustrates another extremely important point. A statistically significant result is not necessarily a strong one. Even a very weak result can be statistically significant if it is based on a large enough sample. This is closely related to Janet Shibley Hyde’s argument about sex differences (Hyde, 2007) [2] . The differences between women and men in mathematical problem solving and leadership ability are statistically significant. But the word significant can cause people to interpret these differences as strong and important—perhaps even important enough to influence the college courses they take or even who they vote for. As we have seen, however, these statistically significant differences are actually quite weak—perhaps even “trivial.”
This is why it is important to distinguish between the statistical significance of a result and the practical significance of that result. Practical significance refers to the importance or usefulness of the result in some real-world context. Many sex differences are statistically significant—and may even be interesting for purely scientific reasons—but they are not practically significant. In clinical practice, this same concept is often referred to as “clinical significance.” For example, a study on a new treatment for social phobia might show that it produces a statistically significant positive effect. Yet this effect still might not be strong enough to justify the time, effort, and other costs of putting it into practice—especially if easier and cheaper treatments that work almost as well already exist. Although statistically significant, this result would be said to lack practical or clinical significance.

“Conditional Risk” retrieved from http://imgs.xkcd.com/comics/conditional_risk.png (CC-BY-NC 2.5)
Key Takeaways
- Null hypothesis testing is a formal approach to deciding whether a statistical relationship in a sample reflects a real relationship in the population or is just due to chance.
- The logic of null hypothesis testing involves assuming that the null hypothesis is true, finding how likely the sample result would be if this assumption were correct, and then making a decision. If the sample result would be unlikely if the null hypothesis were true, then it is rejected in favor of the alternative hypothesis. If it would not be unlikely, then the null hypothesis is retained.
- The probability of obtaining the sample result if the null hypothesis were true (the p value) is based on two considerations: relationship strength and sample size. Reasonable judgments about whether a sample relationship is statistically significant can often be made by quickly considering these two factors.
- Statistical significance is not the same as relationship strength or importance. Even weak relationships can be statistically significant if the sample size is large enough. It is important to consider relationship strength and the practical significance of a result in addition to its statistical significance.
- Discussion: Imagine a study showing that people who eat more broccoli tend to be happier. Explain for someone who knows nothing about statistics why the researchers would conduct a null hypothesis test.
- The correlation between two variables is r = −.78 based on a sample size of 137.
- The mean score on a psychological characteristic for women is 25 ( SD = 5) and the mean score for men is 24 ( SD = 5). There were 12 women and 10 men in this study.
- In a memory experiment, the mean number of items recalled by the 40 participants in Condition A was 0.50 standard deviations greater than the mean number recalled by the 40 participants in Condition B.
- In another memory experiment, the mean scores for participants in Condition A and Condition B came out exactly the same!
- A student finds a correlation of r = .04 between the number of units the students in his research methods class are taking and the students’ level of stress.
- Cohen, J. (1994). The world is round: p < .05. American Psychologist, 49 , 997–1003. ↵
- Hyde, J. S. (2007). New directions in the study of gender similarities and differences. Current Directions in Psychological Science, 16 , 259–263. ↵

Share This Book
- Increase Font Size
Have a thesis expert improve your writing
Check your thesis for plagiarism in 10 minutes, generate your apa citations for free.
- Knowledge Base
- Null and Alternative Hypotheses | Definitions & Examples
Null and Alternative Hypotheses | Definitions & Examples
Published on 5 October 2022 by Shaun Turney . Revised on 6 December 2022.
The null and alternative hypotheses are two competing claims that researchers weigh evidence for and against using a statistical test :
- Null hypothesis (H 0 ): There’s no effect in the population .
- Alternative hypothesis (H A ): There’s an effect in the population.
The effect is usually the effect of the independent variable on the dependent variable .
Table of contents
Answering your research question with hypotheses, what is a null hypothesis, what is an alternative hypothesis, differences between null and alternative hypotheses, how to write null and alternative hypotheses, frequently asked questions about null and alternative hypotheses.
The null and alternative hypotheses offer competing answers to your research question . When the research question asks “Does the independent variable affect the dependent variable?”, the null hypothesis (H 0 ) answers “No, there’s no effect in the population.” On the other hand, the alternative hypothesis (H A ) answers “Yes, there is an effect in the population.”
The null and alternative are always claims about the population. That’s because the goal of hypothesis testing is to make inferences about a population based on a sample . Often, we infer whether there’s an effect in the population by looking at differences between groups or relationships between variables in the sample.
You can use a statistical test to decide whether the evidence favors the null or alternative hypothesis. Each type of statistical test comes with a specific way of phrasing the null and alternative hypothesis. However, the hypotheses can also be phrased in a general way that applies to any test.
The null hypothesis is the claim that there’s no effect in the population.
If the sample provides enough evidence against the claim that there’s no effect in the population ( p ≤ α), then we can reject the null hypothesis . Otherwise, we fail to reject the null hypothesis.
Although “fail to reject” may sound awkward, it’s the only wording that statisticians accept. Be careful not to say you “prove” or “accept” the null hypothesis.
Null hypotheses often include phrases such as “no effect”, “no difference”, or “no relationship”. When written in mathematical terms, they always include an equality (usually =, but sometimes ≥ or ≤).
Examples of null hypotheses
The table below gives examples of research questions and null hypotheses. There’s always more than one way to answer a research question, but these null hypotheses can help you get started.
| ( ) | ||
| Does tooth flossing affect the number of cavities? | Tooth flossing has on the number of cavities. | test: The mean number of cavities per person does not differ between the flossing group (µ ) and the non-flossing group (µ ) in the population; µ = µ . |
| Does the amount of text highlighted in the textbook affect exam scores? | The amount of text highlighted in the textbook has on exam scores. | : There is no relationship between the amount of text highlighted and exam scores in the population; β = 0. |
| Does daily meditation decrease the incidence of depression? | Daily meditation the incidence of depression.* | test: The proportion of people with depression in the daily-meditation group ( ) is greater than or equal to the no-meditation group ( ) in the population; ≥ . |
*Note that some researchers prefer to always write the null hypothesis in terms of “no effect” and “=”. It would be fine to say that daily meditation has no effect on the incidence of depression and p 1 = p 2 .
The alternative hypothesis (H A ) is the other answer to your research question . It claims that there’s an effect in the population.
Often, your alternative hypothesis is the same as your research hypothesis. In other words, it’s the claim that you expect or hope will be true.
The alternative hypothesis is the complement to the null hypothesis. Null and alternative hypotheses are exhaustive, meaning that together they cover every possible outcome. They are also mutually exclusive, meaning that only one can be true at a time.
Alternative hypotheses often include phrases such as “an effect”, “a difference”, or “a relationship”. When alternative hypotheses are written in mathematical terms, they always include an inequality (usually ≠, but sometimes > or <). As with null hypotheses, there are many acceptable ways to phrase an alternative hypothesis.
Examples of alternative hypotheses
The table below gives examples of research questions and alternative hypotheses to help you get started with formulating your own.
| Does tooth flossing affect the number of cavities? | Tooth flossing has an on the number of cavities. | test: The mean number of cavities per person differs between the flossing group (µ ) and the non-flossing group (µ ) in the population; µ ≠ µ . |
| Does the amount of text highlighted in a textbook affect exam scores? | The amount of text highlighted in the textbook has an on exam scores. | : There is a relationship between the amount of text highlighted and exam scores in the population; β ≠ 0. |
| Does daily meditation decrease the incidence of depression? | Daily meditation the incidence of depression. | test: The proportion of people with depression in the daily-meditation group ( ) is less than the no-meditation group ( ) in the population; < . |
Null and alternative hypotheses are similar in some ways:
- They’re both answers to the research question
- They both make claims about the population
- They’re both evaluated by statistical tests.
However, there are important differences between the two types of hypotheses, summarized in the following table.
| A claim that there is in the population. | A claim that there is in the population. | |
|
| ||
| Equality symbol (=, ≥, or ≤) | Inequality symbol (≠, <, or >) | |
| Rejected | Supported | |
| Failed to reject | Not supported |
To help you write your hypotheses, you can use the template sentences below. If you know which statistical test you’re going to use, you can use the test-specific template sentences. Otherwise, you can use the general template sentences.
The only thing you need to know to use these general template sentences are your dependent and independent variables. To write your research question, null hypothesis, and alternative hypothesis, fill in the following sentences with your variables:
Does independent variable affect dependent variable ?
- Null hypothesis (H 0 ): Independent variable does not affect dependent variable .
- Alternative hypothesis (H A ): Independent variable affects dependent variable .
Test-specific
Once you know the statistical test you’ll be using, you can write your hypotheses in a more precise and mathematical way specific to the test you chose. The table below provides template sentences for common statistical tests.
| ( ) | ||
| test
with two groups | The mean dependent variable does not differ between group 1 (µ ) and group 2 (µ ) in the population; µ = µ . | The mean dependent variable differs between group 1 (µ ) and group 2 (µ ) in the population; µ ≠ µ . |
| with three groups | The mean dependent variable does not differ between group 1 (µ ), group 2 (µ ), and group 3 (µ ) in the population; µ = µ = µ . | The mean dependent variable of group 1 (µ ), group 2 (µ ), and group 3 (µ ) are not all equal in the population. |
| There is no correlation between independent variable and dependent variable in the population; ρ = 0. | There is a correlation between independent variable and dependent variable in the population; ρ ≠ 0. | |
| There is no relationship between independent variable and dependent variable in the population; β = 0. | There is a relationship between independent variable and dependent variable in the population; β ≠ 0. | |
| Two-proportions test | The dependent variable expressed as a proportion does not differ between group 1 ( ) and group 2 ( ) in the population; = . | The dependent variable expressed as a proportion differs between group 1 ( ) and group 2 ( ) in the population; ≠ . |
Note: The template sentences above assume that you’re performing one-tailed tests . One-tailed tests are appropriate for most studies.
The null hypothesis is often abbreviated as H 0 . When the null hypothesis is written using mathematical symbols, it always includes an equality symbol (usually =, but sometimes ≥ or ≤).
The alternative hypothesis is often abbreviated as H a or H 1 . When the alternative hypothesis is written using mathematical symbols, it always includes an inequality symbol (usually ≠, but sometimes < or >).
A research hypothesis is your proposed answer to your research question. The research hypothesis usually includes an explanation (‘ x affects y because …’).
A statistical hypothesis, on the other hand, is a mathematical statement about a population parameter. Statistical hypotheses always come in pairs: the null and alternative hypotheses. In a well-designed study , the statistical hypotheses correspond logically to the research hypothesis.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Turney, S. (2022, December 06). Null and Alternative Hypotheses | Definitions & Examples. Scribbr. Retrieved 10 June 2024, from https://www.scribbr.co.uk/stats/null-and-alternative-hypothesis/
Is this article helpful?

Shaun Turney
Other students also liked, levels of measurement: nominal, ordinal, interval, ratio, the standard normal distribution | calculator, examples & uses, types of variables in research | definitions & examples.
Ohio State nav bar
The Ohio State University
- BuckeyeLink
- Find People
- Search Ohio State
Research Questions & Hypotheses
Generally, in quantitative studies, reviewers expect hypotheses rather than research questions. However, both research questions and hypotheses serve different purposes and can be beneficial when used together.
Research Questions
Clarify the research’s aim (farrugia et al., 2010).
- Research often begins with an interest in a topic, but a deep understanding of the subject is crucial to formulate an appropriate research question.
- Descriptive: “What factors most influence the academic achievement of senior high school students?”
- Comparative: “What is the performance difference between teaching methods A and B?”
- Relationship-based: “What is the relationship between self-efficacy and academic achievement?”
- Increasing knowledge about a subject can be achieved through systematic literature reviews, in-depth interviews with patients (and proxies), focus groups, and consultations with field experts.
- Some funding bodies, like the Canadian Institute for Health Research, recommend conducting a systematic review or a pilot study before seeking grants for full trials.
- The presence of multiple research questions in a study can complicate the design, statistical analysis, and feasibility.
- It’s advisable to focus on a single primary research question for the study.
- The primary question, clearly stated at the end of a grant proposal’s introduction, usually specifies the study population, intervention, and other relevant factors.
- The FINER criteria underscore aspects that can enhance the chances of a successful research project, including specifying the population of interest, aligning with scientific and public interest, clinical relevance, and contribution to the field, while complying with ethical and national research standards.
| Feasible | ||
| Interesting | ||
| Novel | ||
| Ethical | ||
| Relevant |
- The P ICOT approach is crucial in developing the study’s framework and protocol, influencing inclusion and exclusion criteria and identifying patient groups for inclusion.
| Population (patients) | ||
| Intervention (for intervention studies only) | ||
| Comparison group | ||
| Outcome of interest | ||
| Time |
- Defining the specific population, intervention, comparator, and outcome helps in selecting the right outcome measurement tool.
- The more precise the population definition and stricter the inclusion and exclusion criteria, the more significant the impact on the interpretation, applicability, and generalizability of the research findings.
- A restricted study population enhances internal validity but may limit the study’s external validity and generalizability to clinical practice.
- A broadly defined study population may better reflect clinical practice but could increase bias and reduce internal validity.
- An inadequately formulated research question can negatively impact study design, potentially leading to ineffective outcomes and affecting publication prospects.
Checklist: Good research questions for social science projects (Panke, 2018)
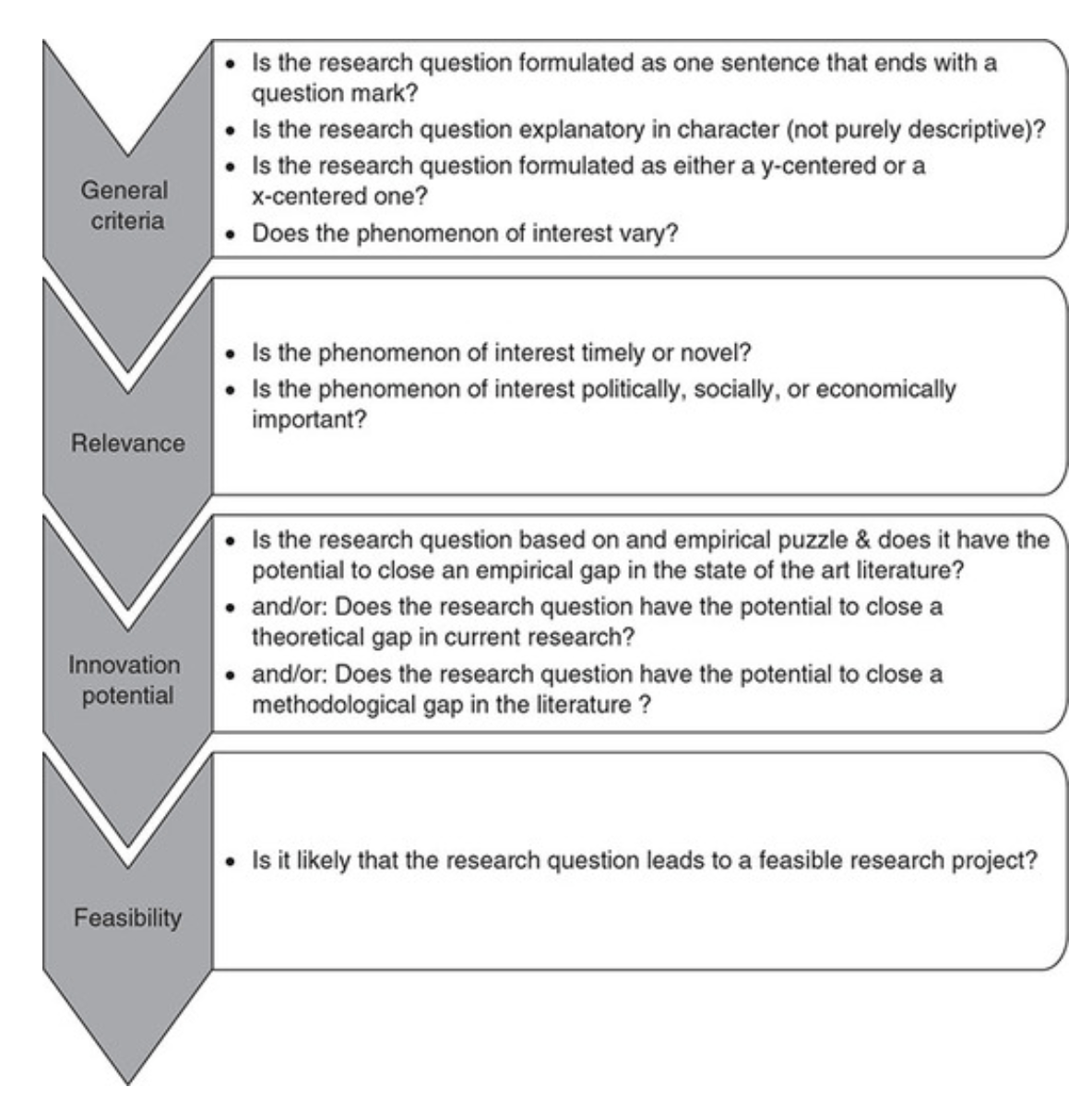
Research Hypotheses
Present the researcher’s predictions based on specific statements.
- These statements define the research problem or issue and indicate the direction of the researcher’s predictions.
- Formulating the research question and hypothesis from existing data (e.g., a database) can lead to multiple statistical comparisons and potentially spurious findings due to chance.
- The research or clinical hypothesis, derived from the research question, shapes the study’s key elements: sampling strategy, intervention, comparison, and outcome variables.
- Hypotheses can express a single outcome or multiple outcomes.
- After statistical testing, the null hypothesis is either rejected or not rejected based on whether the study’s findings are statistically significant.
- Hypothesis testing helps determine if observed findings are due to true differences and not chance.
- Hypotheses can be 1-sided (specific direction of difference) or 2-sided (presence of a difference without specifying direction).
- 2-sided hypotheses are generally preferred unless there’s a strong justification for a 1-sided hypothesis.
- A solid research hypothesis, informed by a good research question, influences the research design and paves the way for defining clear research objectives.
Types of Research Hypothesis
- In a Y-centered research design, the focus is on the dependent variable (DV) which is specified in the research question. Theories are then used to identify independent variables (IV) and explain their causal relationship with the DV.
- Example: “An increase in teacher-led instructional time (IV) is likely to improve student reading comprehension scores (DV), because extensive guided practice under expert supervision enhances learning retention and skill mastery.”
- Hypothesis Explanation: The dependent variable (student reading comprehension scores) is the focus, and the hypothesis explores how changes in the independent variable (teacher-led instructional time) affect it.
- In X-centered research designs, the independent variable is specified in the research question. Theories are used to determine potential dependent variables and the causal mechanisms at play.
- Example: “Implementing technology-based learning tools (IV) is likely to enhance student engagement in the classroom (DV), because interactive and multimedia content increases student interest and participation.”
- Hypothesis Explanation: The independent variable (technology-based learning tools) is the focus, with the hypothesis exploring its impact on a potential dependent variable (student engagement).
- Probabilistic hypotheses suggest that changes in the independent variable are likely to lead to changes in the dependent variable in a predictable manner, but not with absolute certainty.
- Example: “The more teachers engage in professional development programs (IV), the more their teaching effectiveness (DV) is likely to improve, because continuous training updates pedagogical skills and knowledge.”
- Hypothesis Explanation: This hypothesis implies a probable relationship between the extent of professional development (IV) and teaching effectiveness (DV).
- Deterministic hypotheses state that a specific change in the independent variable will lead to a specific change in the dependent variable, implying a more direct and certain relationship.
- Example: “If the school curriculum changes from traditional lecture-based methods to project-based learning (IV), then student collaboration skills (DV) are expected to improve because project-based learning inherently requires teamwork and peer interaction.”
- Hypothesis Explanation: This hypothesis presumes a direct and definite outcome (improvement in collaboration skills) resulting from a specific change in the teaching method.
- Example : “Students who identify as visual learners will score higher on tests that are presented in a visually rich format compared to tests presented in a text-only format.”
- Explanation : This hypothesis aims to describe the potential difference in test scores between visual learners taking visually rich tests and text-only tests, without implying a direct cause-and-effect relationship.
- Example : “Teaching method A will improve student performance more than method B.”
- Explanation : This hypothesis compares the effectiveness of two different teaching methods, suggesting that one will lead to better student performance than the other. It implies a direct comparison but does not necessarily establish a causal mechanism.
- Example : “Students with higher self-efficacy will show higher levels of academic achievement.”
- Explanation : This hypothesis predicts a relationship between the variable of self-efficacy and academic achievement. Unlike a causal hypothesis, it does not necessarily suggest that one variable causes changes in the other, but rather that they are related in some way.
Tips for developing research questions and hypotheses for research studies
- Perform a systematic literature review (if one has not been done) to increase knowledge and familiarity with the topic and to assist with research development.
- Learn about current trends and technological advances on the topic.
- Seek careful input from experts, mentors, colleagues, and collaborators to refine your research question as this will aid in developing the research question and guide the research study.
- Use the FINER criteria in the development of the research question.
- Ensure that the research question follows PICOT format.
- Develop a research hypothesis from the research question.
- Ensure that the research question and objectives are answerable, feasible, and clinically relevant.
If your research hypotheses are derived from your research questions, particularly when multiple hypotheses address a single question, it’s recommended to use both research questions and hypotheses. However, if this isn’t the case, using hypotheses over research questions is advised. It’s important to note these are general guidelines, not strict rules. If you opt not to use hypotheses, consult with your supervisor for the best approach.
Farrugia, P., Petrisor, B. A., Farrokhyar, F., & Bhandari, M. (2010). Practical tips for surgical research: Research questions, hypotheses and objectives. Canadian journal of surgery. Journal canadien de chirurgie , 53 (4), 278–281.
Hulley, S. B., Cummings, S. R., Browner, W. S., Grady, D., & Newman, T. B. (2007). Designing clinical research. Philadelphia.
Panke, D. (2018). Research design & method selection: Making good choices in the social sciences. Research Design & Method Selection , 1-368.

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
5.8: Descriptive Research
- Last updated
- Save as PDF
- Page ID 59848
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
Learning Objectives
- Differentiate between descriptive, experimental, and correlational research
- Explain the strengths and weaknesses of case studies, naturalistic observation, and surveys
There are many research methods available to psychologists in their efforts to understand, describe, and explain behavior and the cognitive and biological processes that underlie it. Some methods rely on observational techniques. Other approaches involve interactions between the researcher and the individuals who are being studied—ranging from a series of simple questions to extensive, in-depth interviews—to well-controlled experiments.
The three main categories of psychological research are descriptive, correlational, and experimental research. Research studies that do not test specific relationships between variables are called descriptive, or qualitative, studies . These studies are used to describe general or specific behaviors and attributes that are observed and measured. In the early stages of research it might be difficult to form a hypothesis, especially when there is not any existing literature in the area. In these situations designing an experiment would be premature, as the question of interest is not yet clearly defined as a hypothesis. Often a researcher will begin with a non-experimental approach, such as a descriptive study, to gather more information about the topic before designing an experiment or correlational study to address a specific hypothesis. Descriptive research is distinct from correlational research , in which psychologists formally test whether a relationship exists between two or more variables. Experimental research goes a step further beyond descriptive and correlational research and randomly assigns people to different conditions, using hypothesis testing to make inferences about how these conditions affect behavior. It aims to determine if one variable directly impacts and causes another. Correlational and experimental research both typically use hypothesis testing, whereas descriptive research does not.
Each of these research methods has unique strengths and weaknesses, and each method may only be appropriate for certain types of research questions. For example, studies that rely primarily on observation produce incredible amounts of information, but the ability to apply this information to the larger population is somewhat limited because of small sample sizes. Survey research, on the other hand, allows researchers to easily collect data from relatively large samples. While this allows for results to be generalized to the larger population more easily, the information that can be collected on any given survey is somewhat limited and subject to problems associated with any type of self-reported data. Some researchers conduct archival research by using existing records. While this can be a fairly inexpensive way to collect data that can provide insight into a number of research questions, researchers using this approach have no control on how or what kind of data was collected.
Correlational research can find a relationship between two variables, but the only way a researcher can claim that the relationship between the variables is cause and effect is to perform an experiment. In experimental research, which will be discussed later in the text, there is a tremendous amount of control over variables of interest. While this is a powerful approach, experiments are often conducted in very artificial settings. This calls into question the validity of experimental findings with regard to how they would apply in real-world settings. In addition, many of the questions that psychologists would like to answer cannot be pursued through experimental research because of ethical concerns.
The three main types of descriptive studies are case studies, naturalistic observation, and surveys.
Query \(\PageIndex{1}\)
Query \(\PageIndex{2}\)
Query \(\PageIndex{3}\)
Query \(\PageIndex{4}\)
Case Studies
In 2011, the New York Times published a feature story on Krista and Tatiana Hogan, Canadian twin girls. These particular twins are unique because Krista and Tatiana are conjoined twins, connected at the head. There is evidence that the two girls are connected in a part of the brain called the thalamus, which is a major sensory relay center. Most incoming sensory information is sent through the thalamus before reaching higher regions of the cerebral cortex for processing.
Link to Learning
To learn more about Krista and Tatiana, watch this video about their lives as conjoined twins.
The implications of this potential connection mean that it might be possible for one twin to experience the sensations of the other twin. For instance, if Krista is watching a particularly funny television program, Tatiana might smile or laugh even if she is not watching the program. This particular possibility has piqued the interest of many neuroscientists who seek to understand how the brain uses sensory information.
These twins represent an enormous resource in the study of the brain, and since their condition is very rare, it is likely that as long as their family agrees, scientists will follow these girls very closely throughout their lives to gain as much information as possible (Dominus, 2011).
In observational research, scientists are conducting a clinical or case study when they focus on one person or just a few individuals. Indeed, some scientists spend their entire careers studying just 10–20 individuals. Why would they do this? Obviously, when they focus their attention on a very small number of people, they can gain a tremendous amount of insight into those cases. The richness of information that is collected in clinical or case studies is unmatched by any other single research method. This allows the researcher to have a very deep understanding of the individuals and the particular phenomenon being studied.
If clinical or case studies provide so much information, why are they not more frequent among researchers? As it turns out, the major benefit of this particular approach is also a weakness. As mentioned earlier, this approach is often used when studying individuals who are interesting to researchers because they have a rare characteristic. Therefore, the individuals who serve as the focus of case studies are not like most other people. If scientists ultimately want to explain all behavior, focusing attention on such a special group of people can make it difficult to generalize any observations to the larger population as a whole. Generalizing refers to the ability to apply the findings of a particular research project to larger segments of society. Again, case studies provide enormous amounts of information, but since the cases are so specific, the potential to apply what’s learned to the average person may be very limited.
Query \(\PageIndex{5}\)
Query \(\PageIndex{6}\)
Naturalistic Observation
If you want to understand how behavior occurs, one of the best ways to gain information is to simply observe the behavior in its natural context. However, people might change their behavior in unexpected ways if they know they are being observed. How do researchers obtain accurate information when people tend to hide their natural behavior? As an example, imagine that your professor asks everyone in your class to raise their hand if they always wash their hands after using the restroom. Chances are that almost everyone in the classroom will raise their hand, but do you think hand washing after every trip to the restroom is really that universal?
This is very similar to the phenomenon mentioned earlier in this module: many individuals do not feel comfortable answering a question honestly. But if we are committed to finding out the facts about hand washing, we have other options available to us.
Suppose we send a classmate into the restroom to actually watch whether everyone washes their hands after using the restroom. Will our observer blend into the restroom environment by wearing a white lab coat, sitting with a clipboard, and staring at the sinks? We want our researcher to be inconspicuous—perhaps standing at one of the sinks pretending to put in contact lenses while secretly recording the relevant information. This type of observational study is called naturalistic observation : observing behavior in its natural setting. To better understand peer exclusion, Suzanne Fanger collaborated with colleagues at the University of Texas to observe the behavior of preschool children on a playground. How did the observers remain inconspicuous over the duration of the study? They equipped a few of the children with wireless microphones (which the children quickly forgot about) and observed while taking notes from a distance. Also, the children in that particular preschool (a “laboratory preschool”) were accustomed to having observers on the playground (Fanger, Frankel, & Hazen, 2012).

It is critical that the observer be as unobtrusive and as inconspicuous as possible: when people know they are being watched, they are less likely to behave naturally. If you have any doubt about this, ask yourself how your driving behavior might differ in two situations: In the first situation, you are driving down a deserted highway during the middle of the day; in the second situation, you are being followed by a police car down the same deserted highway (Figure 1).
It should be pointed out that naturalistic observation is not limited to research involving humans. Indeed, some of the best-known examples of naturalistic observation involve researchers going into the field to observe various kinds of animals in their own environments. As with human studies, the researchers maintain their distance and avoid interfering with the animal subjects so as not to influence their natural behaviors. Scientists have used this technique to study social hierarchies and interactions among animals ranging from ground squirrels to gorillas. The information provided by these studies is invaluable in understanding how those animals organize socially and communicate with one another. The anthropologist Jane Goodall, for example, spent nearly five decades observing the behavior of chimpanzees in Africa (Figure 2). As an illustration of the types of concerns that a researcher might encounter in naturalistic observation, some scientists criticized Goodall for giving the chimps names instead of referring to them by numbers—using names was thought to undermine the emotional detachment required for the objectivity of the study (McKie, 2010).

The greatest benefit of naturalistic observation is the validity, or accuracy, of information collected unobtrusively in a natural setting. Having individuals behave as they normally would in a given situation means that we have a higher degree of ecological validity, or realism, than we might achieve with other research approaches. Therefore, our ability to generalize the findings of the research to real-world situations is enhanced. If done correctly, we need not worry about people or animals modifying their behavior simply because they are being observed. Sometimes, people may assume that reality programs give us a glimpse into authentic human behavior. However, the principle of inconspicuous observation is violated as reality stars are followed by camera crews and are interviewed on camera for personal confessionals. Given that environment, we must doubt how natural and realistic their behaviors are.
The major downside of naturalistic observation is that they are often difficult to set up and control. In our restroom study, what if you stood in the restroom all day prepared to record people’s hand washing behavior and no one came in? Or, what if you have been closely observing a troop of gorillas for weeks only to find that they migrated to a new place while you were sleeping in your tent? The benefit of realistic data comes at a cost. As a researcher you have no control of when (or if) you have behavior to observe. In addition, this type of observational research often requires significant investments of time, money, and a good dose of luck.
Sometimes studies involve structured observation. In these cases, people are observed while engaging in set, specific tasks. An excellent example of structured observation comes from Strange Situation by Mary Ainsworth (you will read more about this in the module on lifespan development). The Strange Situation is a procedure used to evaluate attachment styles that exist between an infant and caregiver. In this scenario, caregivers bring their infants into a room filled with toys. The Strange Situation involves a number of phases, including a stranger coming into the room, the caregiver leaving the room, and the caregiver’s return to the room. The infant’s behavior is closely monitored at each phase, but it is the behavior of the infant upon being reunited with the caregiver that is most telling in terms of characterizing the infant’s attachment style with the caregiver.
Another potential problem in observational research is observer bias . Generally, people who act as observers are closely involved in the research project and may unconsciously skew their observations to fit their research goals or expectations. To protect against this type of bias, researchers should have clear criteria established for the types of behaviors recorded and how those behaviors should be classified. In addition, researchers often compare observations of the same event by multiple observers, in order to test inter-rater reliability : a measure of reliability that assesses the consistency of observations by different observers.
Query \(\PageIndex{7}\)
Query \(\PageIndex{8}\)
Often, psychologists develop surveys as a means of gathering data. Surveys are lists of questions to be answered by research participants, and can be delivered as paper-and-pencil questionnaires, administered electronically, or conducted verbally (Figure 3). Generally, the survey itself can be completed in a short time, and the ease of administering a survey makes it easy to collect data from a large number of people.
Surveys allow researchers to gather data from larger samples than may be afforded by other research methods . A sample is a subset of individuals selected from a population , which is the overall group of individuals that the researchers are interested in. Researchers study the sample and seek to generalize their findings to the population.

There is both strength and weakness of the survey in comparison to case studies. By using surveys, we can collect information from a larger sample of people. A larger sample is better able to reflect the actual diversity of the population, thus allowing better generalizability. Therefore, if our sample is sufficiently large and diverse, we can assume that the data we collect from the survey can be generalized to the larger population with more certainty than the information collected through a case study. However, given the greater number of people involved, we are not able to collect the same depth of information on each person that would be collected in a case study.
Another potential weakness of surveys is something we touched on earlier in this module: people don’t always give accurate responses. They may lie, misremember, or answer questions in a way that they think makes them look good. For example, people may report drinking less alcohol than is actually the case.
Any number of research questions can be answered through the use of surveys. One real-world example is the research conducted by Jenkins, Ruppel, Kizer, Yehl, and Griffin (2012) about the backlash against the US Arab-American community following the terrorist attacks of September 11, 2001. Jenkins and colleagues wanted to determine to what extent these negative attitudes toward Arab-Americans still existed nearly a decade after the attacks occurred. In one study, 140 research participants filled out a survey with 10 questions, including questions asking directly about the participant’s overt prejudicial attitudes toward people of various ethnicities. The survey also asked indirect questions about how likely the participant would be to interact with a person of a given ethnicity in a variety of settings (such as, “How likely do you think it is that you would introduce yourself to a person of Arab-American descent?”). The results of the research suggested that participants were unwilling to report prejudicial attitudes toward any ethnic group. However, there were significant differences between their pattern of responses to questions about social interaction with Arab-Americans compared to other ethnic groups: they indicated less willingness for social interaction with Arab-Americans compared to the other ethnic groups. This suggested that the participants harbored subtle forms of prejudice against Arab-Americans, despite their assertions that this was not the case (Jenkins et al., 2012).
Query \(\PageIndex{9}\)
Query \(\PageIndex{10}\)
Query \(\PageIndex{11}\)
Query \(\PageIndex{12}\)
Query \(\PageIndex{13}\)
Think It Over
A friend of yours is working part-time in a local pet store. Your friend has become increasingly interested in how dogs normally communicate and interact with each other, and is thinking of visiting a local veterinary clinic to see how dogs interact in the waiting room. After reading this section, do you think this is the best way to better understand such interactions? Do you have any suggestions that might result in more valid data?
clinical or case study: observational research study focusing on one or a few people
correlational research: tests whether a relationship exists between two or more variables
descriptive research: research studies that do not test specific relationships between variables; they are used to describe general or specific behaviors and attributes that are observed and measured
experimental research: tests a hypothesis to determine cause and effect relationships
generalize inferring that the results for a sample apply to the larger population
inter-rater reliability: measure of agreement among observers on how they record and classify a particular event
naturalistic observation: observation of behavior in its natural setting
observer bias: when observations may be skewed to align with observer expectations
population: overall group of individuals that the researchers are interested in
sample: subset of individuals selected from the larger population
survey: list of questions to be answered by research participants—given as paper-and-pencil questionnaires, administered electronically, or conducted verbally—allowing researchers to collect data from a large number of people
Licenses and Attributions
CC licensed content, Original
- Modification and adaptation. Provided by : Lumen Learning. License : CC BY-SA: Attribution-ShareAlike
- Approaches to Research. Authored by : OpenStax College. Located at : http://cnx.org/contents/[email protected]:iMyFZJzg@5/Approaches-to-Research . License : CC BY: Attribution . License Terms : Download for free at http://cnx.org/contents/[email protected]
- Descriptive Research. Provided by : Boundless. Located at : https://www.boundless.com/psychology/textbooks/boundless-psychology-textbook/researching-psychology-2/types-of-research-studies-27/descriptive-research-124-12659/ . License : CC BY-SA: Attribution-ShareAlike

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
2.1.3: The Research Hypothesis and the Null Hypothesis
- Last updated
- Save as PDF
- Page ID 44856

- Michelle Oja
- Taft College
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
Hypotheses are predictions of expected findings.
The Research Hypothesis
A research hypothesis is a mathematical way of stating a research question. A research hypothesis names the groups (we'll start with a sample and a population), what was measured, and which we think will have a higher mean. The last one gives the research hypothesis a direction. In other words, a research hypothesis should include:
- The name of the groups being compared. This is sometimes considered the IV.
- What was measured. This is the DV.
- Which group are we predicting will have the higher mean.
There are two types of research hypotheses related to sample means and population means: Directional Research Hypotheses and Non-Directional Research Hypotheses
Directional Research Hypothesis
If we expect our obtained sample mean to be above or below the other group's mean (the population mean, for example), we have a directional hypothesis. There are two options:
- Symbol: \( \displaystyle \bar{X} > \mu \)
- (The mean of the sample is greater than than the mean of the population.)
- Symbol: \( \displaystyle \bar{X} < \mu \)
- (The mean of the sample is less than than mean of the population.)
Example \(\PageIndex{1}\)
A study by Blackwell, Trzesniewski, and Dweck (2007) measured growth mindset and how long the junior high student participants spent on their math homework. What’s a directional hypothesis for how scoring higher on growth mindset (compared to the population of junior high students) would be related to how long students spent on their homework? Write this out in words and symbols.
Answer in Words: Students who scored high on growth mindset would spend more time on their homework than the population of junior high students.
Answer in Symbols: \( \displaystyle \bar{X} > \mu \)
Non-Directional Research Hypothesis
A non-directional hypothesis states that the means will be different, but does not specify which will be higher. In reality, there is rarely a situation in which we actually don't want one group to be higher than the other, so we will focus on directional research hypotheses. There is only one option for a non-directional research hypothesis: "The sample mean differs from the population mean." These types of research hypotheses don’t give a direction, the hypothesis doesn’t say which will be higher or lower.
A non-directional research hypothesis in symbols should look like this: \( \displaystyle \bar{X} \neq \mu \) (The mean of the sample is not equal to the mean of the population).
Exercise \(\PageIndex{1}\)
What’s a non-directional hypothesis for how scoring higher on growth mindset higher on growth mindset (compared to the population of junior high students) would be related to how long students spent on their homework (Blackwell, Trzesniewski, & Dweck, 2007)? Write this out in words and symbols.
Answer in Words: Students who scored high on growth mindset would spend a different amount of time on their homework than the population of junior high students.
Answer in Symbols: \( \displaystyle \bar{X} \neq \mu \)
See how a non-directional research hypothesis doesn't really make sense? The big issue is not if the two groups differ, but if one group seems to improve what was measured (if having a growth mindset leads to more time spent on math homework). This textbook will only use directional research hypotheses because researchers almost always have a predicted direction (meaning that we almost always know which group we think will score higher).
The Null Hypothesis
The hypothesis that an apparent effect is due to chance is called the null hypothesis, written \(H_0\) (“H-naught”). We usually test this through comparing an experimental group to a comparison (control) group. This null hypothesis can be written as:
\[\mathrm{H}_{0}: \bar{X} = \mu \nonumber \]
For most of this textbook, the null hypothesis is that the means of the two groups are similar. Much later, the null hypothesis will be that there is no relationship between the two groups. Either way, remember that a null hypothesis is always saying that nothing is different.
This is where descriptive statistics diverge from inferential statistics. We know what the value of \(\overline{\mathrm{X}}\) is – it’s not a mystery or a question, it is what we observed from the sample. What we are using inferential statistics to do is infer whether this sample's descriptive statistics probably represents the population's descriptive statistics. This is the null hypothesis, that the two groups are similar.
Keep in mind that the null hypothesis is typically the opposite of the research hypothesis. A research hypothesis for the ESP example is that those in my sample who say that they have ESP would get more correct answers than the population would get correct, while the null hypothesis is that the average number correct for the two groups will be similar.
In general, the null hypothesis is the idea that nothing is going on: there is no effect of our treatment, no relation between our variables, and no difference in our sample mean from what we expected about the population mean. This is always our baseline starting assumption, and it is what we seek to reject. If we are trying to treat depression, we want to find a difference in average symptoms between our treatment and control groups. If we are trying to predict job performance, we want to find a relation between conscientiousness and evaluation scores. However, until we have evidence against it, we must use the null hypothesis as our starting point.
In sum, the null hypothesis is always : There is no difference between the groups’ means OR There is no relationship between the variables .
In the next chapter, the null hypothesis is that there’s no difference between the sample mean and population mean. In other words:
- There is no mean difference between the sample and population.
- The mean of the sample is the same as the mean of a specific population.
- \(\mathrm{H}_{0}: \bar{X} = \mu \nonumber \)
- We expect our sample’s mean to be same as the population mean.
Exercise \(\PageIndex{2}\)
A study by Blackwell, Trzesniewski, and Dweck (2007) measured growth mindset and how long the junior high student participants spent on their math homework. What’s the null hypothesis for scoring higher on growth mindset (compared to the population of junior high students) and how long students spent on their homework? Write this out in words and symbols.
Answer in Words: Students who scored high on growth mindset would spend a similar amount of time on their homework as the population of junior high students.
Answer in Symbols: \( \bar{X} = \mu \)
Research Hypothesis In Psychology: Types, & Examples
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
A research hypothesis, in its plural form “hypotheses,” is a specific, testable prediction about the anticipated results of a study, established at its outset. It is a key component of the scientific method .
Hypotheses connect theory to data and guide the research process towards expanding scientific understanding
Some key points about hypotheses:
- A hypothesis expresses an expected pattern or relationship. It connects the variables under investigation.
- It is stated in clear, precise terms before any data collection or analysis occurs. This makes the hypothesis testable.
- A hypothesis must be falsifiable. It should be possible, even if unlikely in practice, to collect data that disconfirms rather than supports the hypothesis.
- Hypotheses guide research. Scientists design studies to explicitly evaluate hypotheses about how nature works.
- For a hypothesis to be valid, it must be testable against empirical evidence. The evidence can then confirm or disprove the testable predictions.
- Hypotheses are informed by background knowledge and observation, but go beyond what is already known to propose an explanation of how or why something occurs.
Predictions typically arise from a thorough knowledge of the research literature, curiosity about real-world problems or implications, and integrating this to advance theory. They build on existing literature while providing new insight.
Types of Research Hypotheses
Alternative hypothesis.
The research hypothesis is often called the alternative or experimental hypothesis in experimental research.
It typically suggests a potential relationship between two key variables: the independent variable, which the researcher manipulates, and the dependent variable, which is measured based on those changes.
The alternative hypothesis states a relationship exists between the two variables being studied (one variable affects the other).
A hypothesis is a testable statement or prediction about the relationship between two or more variables. It is a key component of the scientific method. Some key points about hypotheses:
- Important hypotheses lead to predictions that can be tested empirically. The evidence can then confirm or disprove the testable predictions.
In summary, a hypothesis is a precise, testable statement of what researchers expect to happen in a study and why. Hypotheses connect theory to data and guide the research process towards expanding scientific understanding.
An experimental hypothesis predicts what change(s) will occur in the dependent variable when the independent variable is manipulated.
It states that the results are not due to chance and are significant in supporting the theory being investigated.
The alternative hypothesis can be directional, indicating a specific direction of the effect, or non-directional, suggesting a difference without specifying its nature. It’s what researchers aim to support or demonstrate through their study.
Null Hypothesis
The null hypothesis states no relationship exists between the two variables being studied (one variable does not affect the other). There will be no changes in the dependent variable due to manipulating the independent variable.
It states results are due to chance and are not significant in supporting the idea being investigated.
The null hypothesis, positing no effect or relationship, is a foundational contrast to the research hypothesis in scientific inquiry. It establishes a baseline for statistical testing, promoting objectivity by initiating research from a neutral stance.
Many statistical methods are tailored to test the null hypothesis, determining the likelihood of observed results if no true effect exists.
This dual-hypothesis approach provides clarity, ensuring that research intentions are explicit, and fosters consistency across scientific studies, enhancing the standardization and interpretability of research outcomes.
Nondirectional Hypothesis
A non-directional hypothesis, also known as a two-tailed hypothesis, predicts that there is a difference or relationship between two variables but does not specify the direction of this relationship.
It merely indicates that a change or effect will occur without predicting which group will have higher or lower values.
For example, “There is a difference in performance between Group A and Group B” is a non-directional hypothesis.
Directional Hypothesis
A directional (one-tailed) hypothesis predicts the nature of the effect of the independent variable on the dependent variable. It predicts in which direction the change will take place. (i.e., greater, smaller, less, more)
It specifies whether one variable is greater, lesser, or different from another, rather than just indicating that there’s a difference without specifying its nature.
For example, “Exercise increases weight loss” is a directional hypothesis.

Falsifiability
The Falsification Principle, proposed by Karl Popper , is a way of demarcating science from non-science. It suggests that for a theory or hypothesis to be considered scientific, it must be testable and irrefutable.
Falsifiability emphasizes that scientific claims shouldn’t just be confirmable but should also have the potential to be proven wrong.
It means that there should exist some potential evidence or experiment that could prove the proposition false.
However many confirming instances exist for a theory, it only takes one counter observation to falsify it. For example, the hypothesis that “all swans are white,” can be falsified by observing a black swan.
For Popper, science should attempt to disprove a theory rather than attempt to continually provide evidence to support a research hypothesis.
Can a Hypothesis be Proven?
Hypotheses make probabilistic predictions. They state the expected outcome if a particular relationship exists. However, a study result supporting a hypothesis does not definitively prove it is true.
All studies have limitations. There may be unknown confounding factors or issues that limit the certainty of conclusions. Additional studies may yield different results.
In science, hypotheses can realistically only be supported with some degree of confidence, not proven. The process of science is to incrementally accumulate evidence for and against hypothesized relationships in an ongoing pursuit of better models and explanations that best fit the empirical data. But hypotheses remain open to revision and rejection if that is where the evidence leads.
- Disproving a hypothesis is definitive. Solid disconfirmatory evidence will falsify a hypothesis and require altering or discarding it based on the evidence.
- However, confirming evidence is always open to revision. Other explanations may account for the same results, and additional or contradictory evidence may emerge over time.
We can never 100% prove the alternative hypothesis. Instead, we see if we can disprove, or reject the null hypothesis.
If we reject the null hypothesis, this doesn’t mean that our alternative hypothesis is correct but does support the alternative/experimental hypothesis.
Upon analysis of the results, an alternative hypothesis can be rejected or supported, but it can never be proven to be correct. We must avoid any reference to results proving a theory as this implies 100% certainty, and there is always a chance that evidence may exist which could refute a theory.
How to Write a Hypothesis
- Identify variables . The researcher manipulates the independent variable and the dependent variable is the measured outcome.
- Operationalized the variables being investigated . Operationalization of a hypothesis refers to the process of making the variables physically measurable or testable, e.g. if you are about to study aggression, you might count the number of punches given by participants.
- Decide on a direction for your prediction . If there is evidence in the literature to support a specific effect of the independent variable on the dependent variable, write a directional (one-tailed) hypothesis. If there are limited or ambiguous findings in the literature regarding the effect of the independent variable on the dependent variable, write a non-directional (two-tailed) hypothesis.
- Make it Testable : Ensure your hypothesis can be tested through experimentation or observation. It should be possible to prove it false (principle of falsifiability).
- Clear & concise language . A strong hypothesis is concise (typically one to two sentences long), and formulated using clear and straightforward language, ensuring it’s easily understood and testable.
Consider a hypothesis many teachers might subscribe to: students work better on Monday morning than on Friday afternoon (IV=Day, DV= Standard of work).
Now, if we decide to study this by giving the same group of students a lesson on a Monday morning and a Friday afternoon and then measuring their immediate recall of the material covered in each session, we would end up with the following:
- The alternative hypothesis states that students will recall significantly more information on a Monday morning than on a Friday afternoon.
- The null hypothesis states that there will be no significant difference in the amount recalled on a Monday morning compared to a Friday afternoon. Any difference will be due to chance or confounding factors.
More Examples
- Memory : Participants exposed to classical music during study sessions will recall more items from a list than those who studied in silence.
- Social Psychology : Individuals who frequently engage in social media use will report higher levels of perceived social isolation compared to those who use it infrequently.
- Developmental Psychology : Children who engage in regular imaginative play have better problem-solving skills than those who don’t.
- Clinical Psychology : Cognitive-behavioral therapy will be more effective in reducing symptoms of anxiety over a 6-month period compared to traditional talk therapy.
- Cognitive Psychology : Individuals who multitask between various electronic devices will have shorter attention spans on focused tasks than those who single-task.
- Health Psychology : Patients who practice mindfulness meditation will experience lower levels of chronic pain compared to those who don’t meditate.
- Organizational Psychology : Employees in open-plan offices will report higher levels of stress than those in private offices.
- Behavioral Psychology : Rats rewarded with food after pressing a lever will press it more frequently than rats who receive no reward.
Related Articles

Research Methodology
Qualitative Data Coding

What Is a Focus Group?

Cross-Cultural Research Methodology In Psychology

What Is Internal Validity In Research?

Research Methodology , Statistics
What Is Face Validity In Research? Importance & How To Measure

Criterion Validity: Definition & Examples
9.1 Null and Alternative Hypotheses
The actual test begins by considering two hypotheses . They are called the null hypothesis and the alternative hypothesis . These hypotheses contain opposing viewpoints.
H 0 , the — null hypothesis: a statement of no difference between sample means or proportions or no difference between a sample mean or proportion and a population mean or proportion. In other words, the difference equals 0.
H a —, the alternative hypothesis: a claim about the population that is contradictory to H 0 and what we conclude when we reject H 0 .
Since the null and alternative hypotheses are contradictory, you must examine evidence to decide if you have enough evidence to reject the null hypothesis or not. The evidence is in the form of sample data.
After you have determined which hypothesis the sample supports, you make a decision. There are two options for a decision. They are reject H 0 if the sample information favors the alternative hypothesis or do not reject H 0 or decline to reject H 0 if the sample information is insufficient to reject the null hypothesis.
Mathematical Symbols Used in H 0 and H a :
| equal (=) | not equal (≠) greater than (>) less than (<) |
| greater than or equal to (≥) | less than (<) |
| less than or equal to (≤) | more than (>) |
H 0 always has a symbol with an equal in it. H a never has a symbol with an equal in it. The choice of symbol depends on the wording of the hypothesis test. However, be aware that many researchers use = in the null hypothesis, even with > or < as the symbol in the alternative hypothesis. This practice is acceptable because we only make the decision to reject or not reject the null hypothesis.
Example 9.1
H 0 : No more than 30 percent of the registered voters in Santa Clara County voted in the primary election. p ≤ 30 H a : More than 30 percent of the registered voters in Santa Clara County voted in the primary election. p > 30
A medical trial is conducted to test whether or not a new medicine reduces cholesterol by 25 percent. State the null and alternative hypotheses.
Example 9.2
We want to test whether the mean GPA of students in American colleges is different from 2.0 (out of 4.0). The null and alternative hypotheses are the following: H 0 : μ = 2.0 H a : μ ≠ 2.0
We want to test whether the mean height of eighth graders is 66 inches. State the null and alternative hypotheses. Fill in the correct symbol (=, ≠, ≥, <, ≤, >) for the null and alternative hypotheses.
- H 0 : μ __ 66
- H a : μ __ 66
Example 9.3
We want to test if college students take fewer than five years to graduate from college, on the average. The null and alternative hypotheses are the following: H 0 : μ ≥ 5 H a : μ < 5
We want to test if it takes fewer than 45 minutes to teach a lesson plan. State the null and alternative hypotheses. Fill in the correct symbol ( =, ≠, ≥, <, ≤, >) for the null and alternative hypotheses.
- H 0 : μ __ 45
- H a : μ __ 45
Example 9.4
An article on school standards stated that about half of all students in France, Germany, and Israel take advanced placement exams and a third of the students pass. The same article stated that 6.6 percent of U.S. students take advanced placement exams and 4.4 percent pass. Test if the percentage of U.S. students who take advanced placement exams is more than 6.6 percent. State the null and alternative hypotheses. H 0 : p ≤ 0.066 H a : p > 0.066
On a state driver’s test, about 40 percent pass the test on the first try. We want to test if more than 40 percent pass on the first try. Fill in the correct symbol (=, ≠, ≥, <, ≤, >) for the null and alternative hypotheses.
- H 0 : p __ 0.40
- H a : p __ 0.40
Collaborative Exercise
Bring to class a newspaper, some news magazines, and some internet articles. In groups, find articles from which your group can write null and alternative hypotheses. Discuss your hypotheses with the rest of the class.
As an Amazon Associate we earn from qualifying purchases.
This book may not be used in the training of large language models or otherwise be ingested into large language models or generative AI offerings without OpenStax's permission.
Want to cite, share, or modify this book? This book uses the Creative Commons Attribution License and you must attribute Texas Education Agency (TEA). The original material is available at: https://www.texasgateway.org/book/tea-statistics . Changes were made to the original material, including updates to art, structure, and other content updates.
Access for free at https://openstax.org/books/statistics/pages/1-introduction
- Authors: Barbara Illowsky, Susan Dean
- Publisher/website: OpenStax
- Book title: Statistics
- Publication date: Mar 27, 2020
- Location: Houston, Texas
- Book URL: https://openstax.org/books/statistics/pages/1-introduction
- Section URL: https://openstax.org/books/statistics/pages/9-1-null-and-alternative-hypotheses
© Jan 23, 2024 Texas Education Agency (TEA). The OpenStax name, OpenStax logo, OpenStax book covers, OpenStax CNX name, and OpenStax CNX logo are not subject to the Creative Commons license and may not be reproduced without the prior and express written consent of Rice University.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Hypothesis Testing | A Step-by-Step Guide with Easy Examples
Published on November 8, 2019 by Rebecca Bevans . Revised on June 22, 2023.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics . It is most often used by scientists to test specific predictions, called hypotheses, that arise from theories.
There are 5 main steps in hypothesis testing:
- State your research hypothesis as a null hypothesis and alternate hypothesis (H o ) and (H a or H 1 ).
- Collect data in a way designed to test the hypothesis.
- Perform an appropriate statistical test .
- Decide whether to reject or fail to reject your null hypothesis.
- Present the findings in your results and discussion section.
Though the specific details might vary, the procedure you will use when testing a hypothesis will always follow some version of these steps.
Table of contents
Step 1: state your null and alternate hypothesis, step 2: collect data, step 3: perform a statistical test, step 4: decide whether to reject or fail to reject your null hypothesis, step 5: present your findings, other interesting articles, frequently asked questions about hypothesis testing.
After developing your initial research hypothesis (the prediction that you want to investigate), it is important to restate it as a null (H o ) and alternate (H a ) hypothesis so that you can test it mathematically.
The alternate hypothesis is usually your initial hypothesis that predicts a relationship between variables. The null hypothesis is a prediction of no relationship between the variables you are interested in.
- H 0 : Men are, on average, not taller than women. H a : Men are, on average, taller than women.
Prevent plagiarism. Run a free check.
For a statistical test to be valid , it is important to perform sampling and collect data in a way that is designed to test your hypothesis. If your data are not representative, then you cannot make statistical inferences about the population you are interested in.
There are a variety of statistical tests available, but they are all based on the comparison of within-group variance (how spread out the data is within a category) versus between-group variance (how different the categories are from one another).
If the between-group variance is large enough that there is little or no overlap between groups, then your statistical test will reflect that by showing a low p -value . This means it is unlikely that the differences between these groups came about by chance.
Alternatively, if there is high within-group variance and low between-group variance, then your statistical test will reflect that with a high p -value. This means it is likely that any difference you measure between groups is due to chance.
Your choice of statistical test will be based on the type of variables and the level of measurement of your collected data .
- an estimate of the difference in average height between the two groups.
- a p -value showing how likely you are to see this difference if the null hypothesis of no difference is true.
Based on the outcome of your statistical test, you will have to decide whether to reject or fail to reject your null hypothesis.
In most cases you will use the p -value generated by your statistical test to guide your decision. And in most cases, your predetermined level of significance for rejecting the null hypothesis will be 0.05 – that is, when there is a less than 5% chance that you would see these results if the null hypothesis were true.
In some cases, researchers choose a more conservative level of significance, such as 0.01 (1%). This minimizes the risk of incorrectly rejecting the null hypothesis ( Type I error ).
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
The results of hypothesis testing will be presented in the results and discussion sections of your research paper , dissertation or thesis .
In the results section you should give a brief summary of the data and a summary of the results of your statistical test (for example, the estimated difference between group means and associated p -value). In the discussion , you can discuss whether your initial hypothesis was supported by your results or not.
In the formal language of hypothesis testing, we talk about rejecting or failing to reject the null hypothesis. You will probably be asked to do this in your statistics assignments.
However, when presenting research results in academic papers we rarely talk this way. Instead, we go back to our alternate hypothesis (in this case, the hypothesis that men are on average taller than women) and state whether the result of our test did or did not support the alternate hypothesis.
If your null hypothesis was rejected, this result is interpreted as “supported the alternate hypothesis.”
These are superficial differences; you can see that they mean the same thing.
You might notice that we don’t say that we reject or fail to reject the alternate hypothesis . This is because hypothesis testing is not designed to prove or disprove anything. It is only designed to test whether a pattern we measure could have arisen spuriously, or by chance.
If we reject the null hypothesis based on our research (i.e., we find that it is unlikely that the pattern arose by chance), then we can say our test lends support to our hypothesis . But if the pattern does not pass our decision rule, meaning that it could have arisen by chance, then we say the test is inconsistent with our hypothesis .
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Descriptive statistics
- Measures of central tendency
- Correlation coefficient
Methodology
- Cluster sampling
- Stratified sampling
- Types of interviews
- Cohort study
- Thematic analysis
Research bias
- Implicit bias
- Cognitive bias
- Survivorship bias
- Availability heuristic
- Nonresponse bias
- Regression to the mean
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 22). Hypothesis Testing | A Step-by-Step Guide with Easy Examples. Scribbr. Retrieved June 10, 2024, from https://www.scribbr.com/statistics/hypothesis-testing/
Is this article helpful?

Rebecca Bevans
Other students also liked, choosing the right statistical test | types & examples, understanding p values | definition and examples, what is your plagiarism score.

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Inferential Statistics
Learning Objectives
- Explain the purpose of null hypothesis testing, including the role of sampling error.
- Describe the basic logic of null hypothesis testing.
- Describe the role of relationship strength and sample size in determining statistical significance and make reasonable judgments about statistical significance based on these two factors.
The Purpose of Null Hypothesis Testing
As we have seen, psychological research typically involves measuring one or more variables in a sample and computing descriptive summary data (e.g., means, correlation coefficients) for those variables. These descriptive data for the sample are called statistics . In general, however, the researcher’s goal is not to draw conclusions about that sample but to draw conclusions about the population that the sample was selected from. Thus researchers must use sample statistics to draw conclusions about the corresponding values in the population. These corresponding values in the population are called parameters . Imagine, for example, that a researcher measures the number of depressive symptoms exhibited by each of 50 adults with clinical depression and computes the mean number of symptoms. The researcher probably wants to use this sample statistic (the mean number of symptoms for the sample) to draw conclusions about the corresponding population parameter (the mean number of symptoms for adults with clinical depression).
Unfortunately, sample statistics are not perfect estimates of their corresponding population parameters. This is because there is a certain amount of random variability in any statistic from sample to sample. The mean number of depressive symptoms might be 8.73 in one sample of adults with clinical depression, 6.45 in a second sample, and 9.44 in a third—even though these samples are selected randomly from the same population. Similarly, the correlation (Pearson’s r ) between two variables might be +.24 in one sample, −.04 in a second sample, and +.15 in a third—again, even though these samples are selected randomly from the same population. This random variability in a statistic from sample to sample is called sampling error . (Note that the term error here refers to random variability and does not imply that anyone has made a mistake. No one “commits a sampling error.”)
One implication of this is that when there is a statistical relationship in a sample, it is not always clear that there is a statistical relationship in the population. A small difference between two group means in a sample might indicate that there is a small difference between the two group means in the population. But it could also be that there is no difference between the means in the population and that the difference in the sample is just a matter of sampling error. Similarly, a Pearson’s r value of −.29 in a sample might mean that there is a negative relationship in the population. But it could also be that there is no relationship in the population and that the relationship in the sample is just a matter of sampling error.
In fact, any statistical relationship in a sample can be interpreted in two ways:
- There is a relationship in the population, and the relationship in the sample reflects this.
- There is no relationship in the population, and the relationship in the sample reflects only sampling error.
The purpose of null hypothesis testing is simply to help researchers decide between these two interpretations.
The Logic of Null Hypothesis Testing
Null hypothesis testing (often called null hypothesis significance testing or NHST) is a formal approach to deciding between two interpretations of a statistical relationship in a sample. One interpretation is called the null hypothesis (often symbolized H 0 and read as “H-zero”). This is the idea that there is no relationship in the population and that the relationship in the sample reflects only sampling error. Informally, the null hypothesis is that the sample relationship “occurred by chance.” The other interpretation is called the alternative hypothesis (often symbolized as H 1 ). This is the idea that there is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
Again, every statistical relationship in a sample can be interpreted in either of these two ways: It might have occurred by chance, or it might reflect a relationship in the population. So researchers need a way to decide between them. Although there are many specific null hypothesis testing techniques, they are all based on the same general logic. The steps are as follows:
- Assume for the moment that the null hypothesis is true. There is no relationship between the variables in the population.
- Determine how likely the sample relationship would be if the null hypothesis were true.
- If the sample relationship would be extremely unlikely, then reject the null hypothesis in favor of the alternative hypothesis. If it would not be extremely unlikely, then retain the null hypothesis .
Following this logic, we can begin to understand why Mehl and his colleagues concluded that there is no difference in talkativeness between women and men in the population. In essence, they asked the following question: “If there were no difference in the population, how likely is it that we would find a small difference of d = 0.06 in our sample?” Their answer to this question was that this sample relationship would be fairly likely if the null hypothesis were true. Therefore, they retained the null hypothesis—concluding that there is no evidence of a sex difference in the population. We can also see why Kanner and his colleagues concluded that there is a correlation between hassles and symptoms in the population. They asked, “If the null hypothesis were true, how likely is it that we would find a strong correlation of +.60 in our sample?” Their answer to this question was that this sample relationship would be fairly unlikely if the null hypothesis were true. Therefore, they rejected the null hypothesis in favor of the alternative hypothesis—concluding that there is a positive correlation between these variables in the population.
A crucial step in null hypothesis testing is finding the probability of the sample result or a more extreme result if the null hypothesis were true (Lakens, 2017). [1] This probability is called the p value . A low p value means that the sample or more extreme result would be unlikely if the null hypothesis were true and leads to the rejection of the null hypothesis. A p value that is not low means that the sample or more extreme result would be likely if the null hypothesis were true and leads to the retention of the null hypothesis. But how low must the p value criterion be before the sample result is considered unlikely enough to reject the null hypothesis? In null hypothesis testing, this criterion is called α (alpha) and is almost always set to .05. If there is a 5% chance or less of a result at least as extreme as the sample result if the null hypothesis were true, then the null hypothesis is rejected. When this happens, the result is said to be statistically significant . If there is greater than a 5% chance of a result as extreme as the sample result when the null hypothesis is true, then the null hypothesis is retained. This does not necessarily mean that the researcher accepts the null hypothesis as true—only that there is not currently enough evidence to reject it. Researchers often use the expression “fail to reject the null hypothesis” rather than “retain the null hypothesis,” but they never use the expression “accept the null hypothesis.”
The Misunderstood p Value
The p value is one of the most misunderstood quantities in psychological research (Cohen, 1994) [2] . Even professional researchers misinterpret it, and it is not unusual for such misinterpretations to appear in statistics textbooks!
The most common misinterpretation is that the p value is the probability that the null hypothesis is true—that the sample result occurred by chance. For example, a misguided researcher might say that because the p value is .02, there is only a 2% chance that the result is due to chance and a 98% chance that it reflects a real relationship in the population. But this is incorrect . The p value is really the probability of a result at least as extreme as the sample result if the null hypothesis were true. So a p value of .02 means that if the null hypothesis were true, a sample result this extreme would occur only 2% of the time.
You can avoid this misunderstanding by remembering that the p value is not the probability that any particular hypothesis is true or false. Instead, it is the probability of obtaining the sample result if the null hypothesis were true.

Role of Sample Size and Relationship Strength
Recall that null hypothesis testing involves answering the question, “If the null hypothesis were true, what is the probability of a sample result as extreme as this one?” In other words, “What is the p value?” It can be helpful to see that the answer to this question depends on just two considerations: the strength of the relationship and the size of the sample. Specifically, the stronger the sample relationship and the larger the sample, the less likely the result would be if the null hypothesis were true. That is, the lower the p value. This should make sense. Imagine a study in which a sample of 500 women is compared with a sample of 500 men in terms of some psychological characteristic, and Cohen’s d is a strong 0.50. If there were really no sex difference in the population, then a result this strong based on such a large sample should seem highly unlikely. Now imagine a similar study in which a sample of three women is compared with a sample of three men, and Cohen’s d is a weak 0.10. If there were no sex difference in the population, then a relationship this weak based on such a small sample should seem likely. And this is precisely why the null hypothesis would be rejected in the first example and retained in the second.
Of course, sometimes the result can be weak and the sample large, or the result can be strong and the sample small. In these cases, the two considerations trade off against each other so that a weak result can be statistically significant if the sample is large enough and a strong relationship can be statistically significant even if the sample is small. Table 13.1 shows roughly how relationship strength and sample size combine to determine whether a sample result is statistically significant. The columns of the table represent the three levels of relationship strength: weak, medium, and strong. The rows represent four sample sizes that can be considered small, medium, large, and extra large in the context of psychological research. Thus each cell in the table represents a combination of relationship strength and sample size. If a cell contains the word Yes , then this combination would be statistically significant for both Cohen’s d and Pearson’s r . If it contains the word No , then it would not be statistically significant for either. There is one cell where the decision for d and r would be different and another where it might be different depending on some additional considerations, which are discussed in Section 13.2 “Some Basic Null Hypothesis Tests”
| Sample Size | Weak | Medium | Strong |
| Small ( = 20) | No | No | = Maybe = Yes |
| Medium ( = 50) | No | Yes | Yes |
| Large ( = 100) | = Yes = No | Yes | Yes |
| Extra large ( = 500) | Yes | Yes | Yes |
Although Table 13.1 provides only a rough guideline, it shows very clearly that weak relationships based on medium or small samples are never statistically significant and that strong relationships based on medium or larger samples are always statistically significant. If you keep this lesson in mind, you will often know whether a result is statistically significant based on the descriptive statistics alone. It is extremely useful to be able to develop this kind of intuitive judgment. One reason is that it allows you to develop expectations about how your formal null hypothesis tests are going to come out, which in turn allows you to detect problems in your analyses. For example, if your sample relationship is strong and your sample is medium, then you would expect to reject the null hypothesis. If for some reason your formal null hypothesis test indicates otherwise, then you need to double-check your computations and interpretations. A second reason is that the ability to make this kind of intuitive judgment is an indication that you understand the basic logic of this approach in addition to being able to do the computations.
Statistical Significance Versus Practical Significance
Table 13.1 illustrates another extremely important point. A statistically significant result is not necessarily a strong one. Even a very weak result can be statistically significant if it is based on a large enough sample. This is closely related to Janet Shibley Hyde’s argument about sex differences (Hyde, 2007) [3] . The differences between women and men in mathematical problem solving and leadership ability are statistically significant. But the word significant can cause people to interpret these differences as strong and important—perhaps even important enough to influence the college courses they take or even who they vote for. As we have seen, however, these statistically significant differences are actually quite weak—perhaps even “trivial.”
This is why it is important to distinguish between the statistical significance of a result and the practical significance of that result. Practical significance refers to the importance or usefulness of the result in some real-world context. Many sex differences are statistically significant—and may even be interesting for purely scientific reasons—but they are not practically significant. In clinical practice, this same concept is often referred to as “clinical significance.” For example, a study on a new treatment for social phobia might show that it produces a statistically significant positive effect. Yet this effect still might not be strong enough to justify the time, effort, and other costs of putting it into practice—especially if easier and cheaper treatments that work almost as well already exist. Although statistically significant, this result would be said to lack practical or clinical significance.

Image Description
“Null Hypothesis” long description: A comic depicting a man and a woman talking in the foreground. In the background is a child working at a desk. The man says to the woman, “I can’t believe schools are still teaching kids about the null hypothesis. I remember reading a big study that conclusively disproved it years ago.” [Return to “Null Hypothesis”]
“Conditional Risk” long description: A comic depicting two hikers beside a tree during a thunderstorm. A bolt of lightning goes “crack” in the dark sky as thunder booms. One of the hikers says, “Whoa! We should get inside!” The other hiker says, “It’s okay! Lightning only kills about 45 Americans a year, so the chances of dying are only one in 7,000,000. Let’s go on!” The comic’s caption says, “The annual death rate among people who know that statistic is one in six.” [Return to “Conditional Risk”]
Media Attributions
- Null Hypothesis by XKCD CC BY-NC (Attribution NonCommercial)
- Conditional Risk by XKCD CC BY-NC (Attribution NonCommercial)
- Lakens, D. (2017, December 25). About p -values: Understanding common misconceptions. [Blog post] Retrieved from https://correlaid.org/en/blog/understand-p-values/ ↵
- Cohen, J. (1994). The world is round: p < .05. American Psychologist, 49 , 997–1003. ↵
- Hyde, J. S. (2007). New directions in the study of gender similarities and differences. Current Directions in Psychological Science, 16 , 259–263. ↵
Descriptive data that involves measuring one or more variables in a sample and computing descriptive summary data (e.g., means, correlation coefficients) for those variables.
Corresponding values in the population.
The random variability in a statistic from sample to sample.
A formal approach to deciding between two interpretations of a statistical relationship in a sample.
The idea that there is no relationship in the population and that the relationship in the sample reflects only sampling error (often symbolized H0 and read as “H-zero”).
An alternative to the null hypothesis (often symbolized as H1), this hypothesis proposes that there is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
A decision made by researchers using null hypothesis testing which occurs when the sample relationship would be extremely unlikely.
A decision made by researchers in null hypothesis testing which occurs when the sample relationship would not be extremely unlikely.
The probability of obtaining the sample result or a more extreme result if the null hypothesis were true.
The criterion that shows how low a p-value should be before the sample result is considered unlikely enough to reject the null hypothesis (Usually set to .05).
An effect that is unlikely due to random chance and therefore likely represents a real effect in the population.
Refers to the importance or usefulness of the result in some real-world context.
Research Methods in Psychology Copyright © 2019 by Rajiv S. Jhangiani, I-Chant A. Chiang, Carrie Cuttler, & Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Null Hypothesis Examples
ThoughtCo / Hilary Allison
- Scientific Method
- Chemical Laws
- Periodic Table
- Projects & Experiments
- Biochemistry
- Physical Chemistry
- Medical Chemistry
- Chemistry In Everyday Life
- Famous Chemists
- Activities for Kids
- Abbreviations & Acronyms
- Weather & Climate
- Ph.D., Biomedical Sciences, University of Tennessee at Knoxville
- B.A., Physics and Mathematics, Hastings College
In statistical analysis, the null hypothesis assumes there is no meaningful relationship between two variables. Testing the null hypothesis can tell you whether your results are due to the effect of manipulating a dependent variable or due to chance. It's often used in conjunction with an alternative hypothesis, which assumes there is, in fact, a relationship between two variables.
The null hypothesis is among the easiest hypothesis to test using statistical analysis, making it perhaps the most valuable hypothesis for the scientific method. By evaluating a null hypothesis in addition to another hypothesis, researchers can support their conclusions with a higher level of confidence. Below are examples of how you might formulate a null hypothesis to fit certain questions.
What Is the Null Hypothesis?
The null hypothesis states there is no relationship between the measured phenomenon (the dependent variable ) and the independent variable , which is the variable an experimenter typically controls or changes. You do not need to believe that the null hypothesis is true to test it. On the contrary, you will likely suspect there is a relationship between a set of variables. One way to prove that this is the case is to reject the null hypothesis. Rejecting a hypothesis does not mean an experiment was "bad" or that it didn't produce results. In fact, it is often one of the first steps toward further inquiry.
To distinguish it from other hypotheses , the null hypothesis is written as H 0 (which is read as “H-nought,” "H-null," or "H-zero"). A significance test is used to determine the likelihood that the results supporting the null hypothesis are not due to chance. A confidence level of 95% or 99% is common. Keep in mind, even if the confidence level is high, there is still a small chance the null hypothesis is not true, perhaps because the experimenter did not account for a critical factor or because of chance. This is one reason why it's important to repeat experiments.
Examples of the Null Hypothesis
To write a null hypothesis, first start by asking a question. Rephrase that question in a form that assumes no relationship between the variables. In other words, assume a treatment has no effect. Write your hypothesis in a way that reflects this.
| Are teens better at math than adults? | Age has no effect on mathematical ability. |
| Does taking aspirin every day reduce the chance of having a heart attack? | Taking aspirin daily does not affect heart attack risk. |
| Do teens use cell phones to access the internet more than adults? | Age has no effect on how cell phones are used for internet access. |
| Do cats care about the color of their food? | Cats express no food preference based on color. |
| Does chewing willow bark relieve pain? | There is no difference in pain relief after chewing willow bark versus taking a placebo. |
Other Types of Hypotheses
In addition to the null hypothesis, the alternative hypothesis is also a staple in traditional significance tests . It's essentially the opposite of the null hypothesis because it assumes the claim in question is true. For the first item in the table above, for example, an alternative hypothesis might be "Age does have an effect on mathematical ability."
Key Takeaways
- In hypothesis testing, the null hypothesis assumes no relationship between two variables, providing a baseline for statistical analysis.
- Rejecting the null hypothesis suggests there is evidence of a relationship between variables.
- By formulating a null hypothesis, researchers can systematically test assumptions and draw more reliable conclusions from their experiments.
- Difference Between Independent and Dependent Variables
- Examples of Independent and Dependent Variables
- What Is a Hypothesis? (Science)
- What 'Fail to Reject' Means in a Hypothesis Test
- Definition of a Hypothesis
- Null Hypothesis Definition and Examples
- Scientific Method Vocabulary Terms
- Null Hypothesis and Alternative Hypothesis
- Hypothesis Test for the Difference of Two Population Proportions
- How to Conduct a Hypothesis Test
- What Is a P-Value?
- What Are the Elements of a Good Hypothesis?
- Hypothesis Test Example
- What Is the Difference Between Alpha and P-Values?
- Understanding Path Analysis
- An Example of a Hypothesis Test

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Korean Med Sci
- v.36(50); 2021 Dec 27
Formulating Hypotheses for Different Study Designs
Durga prasanna misra.
1 Department of Clinical Immunology and Rheumatology, Sanjay Gandhi Postgraduate Institute of Medical Sciences, Lucknow, India.
Armen Yuri Gasparyan
2 Departments of Rheumatology and Research and Development, Dudley Group NHS Foundation Trust (Teaching Trust of the University of Birmingham, UK), Russells Hall Hospital, Dudley, UK.
Olena Zimba
3 Department of Internal Medicine #2, Danylo Halytsky Lviv National Medical University, Lviv, Ukraine.
Marlen Yessirkepov
4 Department of Biology and Biochemistry, South Kazakhstan Medical Academy, Shymkent, Kazakhstan.
Vikas Agarwal
George d. kitas.
5 Centre for Epidemiology versus Arthritis, University of Manchester, Manchester, UK.
Generating a testable working hypothesis is the first step towards conducting original research. Such research may prove or disprove the proposed hypothesis. Case reports, case series, online surveys and other observational studies, clinical trials, and narrative reviews help to generate hypotheses. Observational and interventional studies help to test hypotheses. A good hypothesis is usually based on previous evidence-based reports. Hypotheses without evidence-based justification and a priori ideas are not received favourably by the scientific community. Original research to test a hypothesis should be carefully planned to ensure appropriate methodology and adequate statistical power. While hypotheses can challenge conventional thinking and may be controversial, they should not be destructive. A hypothesis should be tested by ethically sound experiments with meaningful ethical and clinical implications. The coronavirus disease 2019 pandemic has brought into sharp focus numerous hypotheses, some of which were proven (e.g. effectiveness of corticosteroids in those with hypoxia) while others were disproven (e.g. ineffectiveness of hydroxychloroquine and ivermectin).
Graphical Abstract

DEFINING WORKING AND STANDALONE SCIENTIFIC HYPOTHESES
Science is the systematized description of natural truths and facts. Routine observations of existing life phenomena lead to the creative thinking and generation of ideas about mechanisms of such phenomena and related human interventions. Such ideas presented in a structured format can be viewed as hypotheses. After generating a hypothesis, it is necessary to test it to prove its validity. Thus, hypothesis can be defined as a proposed mechanism of a naturally occurring event or a proposed outcome of an intervention. 1 , 2
Hypothesis testing requires choosing the most appropriate methodology and adequately powering statistically the study to be able to “prove” or “disprove” it within predetermined and widely accepted levels of certainty. This entails sample size calculation that often takes into account previously published observations and pilot studies. 2 , 3 In the era of digitization, hypothesis generation and testing may benefit from the availability of numerous platforms for data dissemination, social networking, and expert validation. Related expert evaluations may reveal strengths and limitations of proposed ideas at early stages of post-publication promotion, preventing the implementation of unsupported controversial points. 4
Thus, hypothesis generation is an important initial step in the research workflow, reflecting accumulating evidence and experts' stance. In this article, we overview the genesis and importance of scientific hypotheses and their relevance in the era of the coronavirus disease 2019 (COVID-19) pandemic.
DO WE NEED HYPOTHESES FOR ALL STUDY DESIGNS?
Broadly, research can be categorized as primary or secondary. In the context of medicine, primary research may include real-life observations of disease presentations and outcomes. Single case descriptions, which often lead to new ideas and hypotheses, serve as important starting points or justifications for case series and cohort studies. The importance of case descriptions is particularly evident in the context of the COVID-19 pandemic when unique, educational case reports have heralded a new era in clinical medicine. 5
Case series serve similar purpose to single case reports, but are based on a slightly larger quantum of information. Observational studies, including online surveys, describe the existing phenomena at a larger scale, often involving various control groups. Observational studies include variable-scale epidemiological investigations at different time points. Interventional studies detail the results of therapeutic interventions.
Secondary research is based on already published literature and does not directly involve human or animal subjects. Review articles are generated by secondary research. These could be systematic reviews which follow methods akin to primary research but with the unit of study being published papers rather than humans or animals. Systematic reviews have a rigid structure with a mandatory search strategy encompassing multiple databases, systematic screening of search results against pre-defined inclusion and exclusion criteria, critical appraisal of study quality and an optional component of collating results across studies quantitatively to derive summary estimates (meta-analysis). 6 Narrative reviews, on the other hand, have a more flexible structure. Systematic literature searches to minimise bias in selection of articles are highly recommended but not mandatory. 7 Narrative reviews are influenced by the authors' viewpoint who may preferentially analyse selected sets of articles. 8
In relation to primary research, case studies and case series are generally not driven by a working hypothesis. Rather, they serve as a basis to generate a hypothesis. Observational or interventional studies should have a hypothesis for choosing research design and sample size. The results of observational and interventional studies further lead to the generation of new hypotheses, testing of which forms the basis of future studies. Review articles, on the other hand, may not be hypothesis-driven, but form fertile ground to generate future hypotheses for evaluation. Fig. 1 summarizes which type of studies are hypothesis-driven and which lead on to hypothesis generation.

STANDARDS OF WORKING AND SCIENTIFIC HYPOTHESES
A review of the published literature did not enable the identification of clearly defined standards for working and scientific hypotheses. It is essential to distinguish influential versus not influential hypotheses, evidence-based hypotheses versus a priori statements and ideas, ethical versus unethical, or potentially harmful ideas. The following points are proposed for consideration while generating working and scientific hypotheses. 1 , 2 Table 1 summarizes these points.
| Points to be considered while evaluating the validity of hypotheses |
|---|
| Backed by evidence-based data |
| Testable by relevant study designs |
| Supported by preliminary (pilot) studies |
| Testable by ethical studies |
| Maintaining a balance between scientific temper and controversy |
Evidence-based data
A scientific hypothesis should have a sound basis on previously published literature as well as the scientist's observations. Randomly generated (a priori) hypotheses are unlikely to be proven. A thorough literature search should form the basis of a hypothesis based on published evidence. 7
Unless a scientific hypothesis can be tested, it can neither be proven nor be disproven. Therefore, a scientific hypothesis should be amenable to testing with the available technologies and the present understanding of science.
Supported by pilot studies
If a hypothesis is based purely on a novel observation by the scientist in question, it should be grounded on some preliminary studies to support it. For example, if a drug that targets a specific cell population is hypothesized to be useful in a particular disease setting, then there must be some preliminary evidence that the specific cell population plays a role in driving that disease process.
Testable by ethical studies
The hypothesis should be testable by experiments that are ethically acceptable. 9 For example, a hypothesis that parachutes reduce mortality from falls from an airplane cannot be tested using a randomized controlled trial. 10 This is because it is obvious that all those jumping from a flying plane without a parachute would likely die. Similarly, the hypothesis that smoking tobacco causes lung cancer cannot be tested by a clinical trial that makes people take up smoking (since there is considerable evidence for the health hazards associated with smoking). Instead, long-term observational studies comparing outcomes in those who smoke and those who do not, as was performed in the landmark epidemiological case control study by Doll and Hill, 11 are more ethical and practical.
Balance between scientific temper and controversy
Novel findings, including novel hypotheses, particularly those that challenge established norms, are bound to face resistance for their wider acceptance. Such resistance is inevitable until the time such findings are proven with appropriate scientific rigor. However, hypotheses that generate controversy are generally unwelcome. For example, at the time the pandemic of human immunodeficiency virus (HIV) and AIDS was taking foot, there were numerous deniers that refused to believe that HIV caused AIDS. 12 , 13 Similarly, at a time when climate change is causing catastrophic changes to weather patterns worldwide, denial that climate change is occurring and consequent attempts to block climate change are certainly unwelcome. 14 The denialism and misinformation during the COVID-19 pandemic, including unfortunate examples of vaccine hesitancy, are more recent examples of controversial hypotheses not backed by science. 15 , 16 An example of a controversial hypothesis that was a revolutionary scientific breakthrough was the hypothesis put forth by Warren and Marshall that Helicobacter pylori causes peptic ulcers. Initially, the hypothesis that a microorganism could cause gastritis and gastric ulcers faced immense resistance. When the scientists that proposed the hypothesis themselves ingested H. pylori to induce gastritis in themselves, only then could they convince the wider world about their hypothesis. Such was the impact of the hypothesis was that Barry Marshall and Robin Warren were awarded the Nobel Prize in Physiology or Medicine in 2005 for this discovery. 17 , 18
DISTINGUISHING THE MOST INFLUENTIAL HYPOTHESES
Influential hypotheses are those that have stood the test of time. An archetype of an influential hypothesis is that proposed by Edward Jenner in the eighteenth century that cowpox infection protects against smallpox. While this observation had been reported for nearly a century before this time, it had not been suitably tested and publicised until Jenner conducted his experiments on a young boy by demonstrating protection against smallpox after inoculation with cowpox. 19 These experiments were the basis for widespread smallpox immunization strategies worldwide in the 20th century which resulted in the elimination of smallpox as a human disease today. 20
Other influential hypotheses are those which have been read and cited widely. An example of this is the hygiene hypothesis proposing an inverse relationship between infections in early life and allergies or autoimmunity in adulthood. An analysis reported that this hypothesis had been cited more than 3,000 times on Scopus. 1
LESSONS LEARNED FROM HYPOTHESES AMIDST THE COVID-19 PANDEMIC
The COVID-19 pandemic devastated the world like no other in recent memory. During this period, various hypotheses emerged, understandably so considering the public health emergency situation with innumerable deaths and suffering for humanity. Within weeks of the first reports of COVID-19, aberrant immune system activation was identified as a key driver of organ dysfunction and mortality in this disease. 21 Consequently, numerous drugs that suppress the immune system or abrogate the activation of the immune system were hypothesized to have a role in COVID-19. 22 One of the earliest drugs hypothesized to have a benefit was hydroxychloroquine. Hydroxychloroquine was proposed to interfere with Toll-like receptor activation and consequently ameliorate the aberrant immune system activation leading to pathology in COVID-19. 22 The drug was also hypothesized to have a prophylactic role in preventing infection or disease severity in COVID-19. It was also touted as a wonder drug for the disease by many prominent international figures. However, later studies which were well-designed randomized controlled trials failed to demonstrate any benefit of hydroxychloroquine in COVID-19. 23 , 24 , 25 , 26 Subsequently, azithromycin 27 , 28 and ivermectin 29 were hypothesized as potential therapies for COVID-19, but were not supported by evidence from randomized controlled trials. The role of vitamin D in preventing disease severity was also proposed, but has not been proven definitively until now. 30 , 31 On the other hand, randomized controlled trials identified the evidence supporting dexamethasone 32 and interleukin-6 pathway blockade with tocilizumab as effective therapies for COVID-19 in specific situations such as at the onset of hypoxia. 33 , 34 Clues towards the apparent effectiveness of various drugs against severe acute respiratory syndrome coronavirus 2 in vitro but their ineffectiveness in vivo have recently been identified. Many of these drugs are weak, lipophilic bases and some others induce phospholipidosis which results in apparent in vitro effectiveness due to non-specific off-target effects that are not replicated inside living systems. 35 , 36
Another hypothesis proposed was the association of the routine policy of vaccination with Bacillus Calmette-Guerin (BCG) with lower deaths due to COVID-19. This hypothesis emerged in the middle of 2020 when COVID-19 was still taking foot in many parts of the world. 37 , 38 Subsequently, many countries which had lower deaths at that time point went on to have higher numbers of mortality, comparable to other areas of the world. Furthermore, the hypothesis that BCG vaccination reduced COVID-19 mortality was a classic example of ecological fallacy. Associations between population level events (ecological studies; in this case, BCG vaccination and COVID-19 mortality) cannot be directly extrapolated to the individual level. Furthermore, such associations cannot per se be attributed as causal in nature, and can only serve to generate hypotheses that need to be tested at the individual level. 39
IS TRADITIONAL PEER REVIEW EFFICIENT FOR EVALUATION OF WORKING AND SCIENTIFIC HYPOTHESES?
Traditionally, publication after peer review has been considered the gold standard before any new idea finds acceptability amongst the scientific community. Getting a work (including a working or scientific hypothesis) reviewed by experts in the field before experiments are conducted to prove or disprove it helps to refine the idea further as well as improve the experiments planned to test the hypothesis. 40 A route towards this has been the emergence of journals dedicated to publishing hypotheses such as the Central Asian Journal of Medical Hypotheses and Ethics. 41 Another means of publishing hypotheses is through registered research protocols detailing the background, hypothesis, and methodology of a particular study. If such protocols are published after peer review, then the journal commits to publishing the completed study irrespective of whether the study hypothesis is proven or disproven. 42 In the post-pandemic world, online research methods such as online surveys powered via social media channels such as Twitter and Instagram might serve as critical tools to generate as well as to preliminarily test the appropriateness of hypotheses for further evaluation. 43 , 44
Some radical hypotheses might be difficult to publish after traditional peer review. These hypotheses might only be acceptable by the scientific community after they are tested in research studies. Preprints might be a way to disseminate such controversial and ground-breaking hypotheses. 45 However, scientists might prefer to keep their hypotheses confidential for the fear of plagiarism of ideas, avoiding online posting and publishing until they have tested the hypotheses.
SUGGESTIONS ON GENERATING AND PUBLISHING HYPOTHESES
Publication of hypotheses is important, however, a balance is required between scientific temper and controversy. Journal editors and reviewers might keep in mind these specific points, summarized in Table 2 and detailed hereafter, while judging the merit of hypotheses for publication. Keeping in mind the ethical principle of primum non nocere, a hypothesis should be published only if it is testable in a manner that is ethically appropriate. 46 Such hypotheses should be grounded in reality and lend themselves to further testing to either prove or disprove them. It must be considered that subsequent experiments to prove or disprove a hypothesis have an equal chance of failing or succeeding, akin to tossing a coin. A pre-conceived belief that a hypothesis is unlikely to be proven correct should not form the basis of rejection of such a hypothesis for publication. In this context, hypotheses generated after a thorough literature search to identify knowledge gaps or based on concrete clinical observations on a considerable number of patients (as opposed to random observations on a few patients) are more likely to be acceptable for publication by peer-reviewed journals. Also, hypotheses should be considered for publication or rejection based on their implications for science at large rather than whether the subsequent experiments to test them end up with results in favour of or against the original hypothesis.
| Points to be considered before a hypothesis is acceptable for publication |
|---|
| Experiments required to test hypotheses should be ethically acceptable as per the World Medical Association declaration on ethics and related statements |
| Pilot studies support hypotheses |
| Single clinical observations and expert opinion surveys may support hypotheses |
| Testing hypotheses requires robust methodology and statistical power |
| Hypotheses that challenge established views and concepts require proper evidence-based justification |
Hypotheses form an important part of the scientific literature. The COVID-19 pandemic has reiterated the importance and relevance of hypotheses for dealing with public health emergencies and highlighted the need for evidence-based and ethical hypotheses. A good hypothesis is testable in a relevant study design, backed by preliminary evidence, and has positive ethical and clinical implications. General medical journals might consider publishing hypotheses as a specific article type to enable more rapid advancement of science.
Disclosure: The authors have no potential conflicts of interest to disclose.
Author Contributions:
- Data curation: Gasparyan AY, Misra DP, Zimba O, Yessirkepov M, Agarwal V, Kitas GD.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Understanding Null Hypothesis Testing
Rajiv S. Jhangiani; I-Chant A. Chiang; Carrie Cuttler; and Dana C. Leighton
Learning Objectives
- Explain the purpose of null hypothesis testing, including the role of sampling error.
- Describe the basic logic of null hypothesis testing.
- Describe the role of relationship strength and sample size in determining statistical significance and make reasonable judgments about statistical significance based on these two factors.
The Purpose of Null Hypothesis Testing
As we have seen, psychological research typically involves measuring one or more variables in a sample and computing descriptive summary data (e.g., means, correlation coefficients) for those variables. These descriptive data for the sample are called statistics . In general, however, the researcher’s goal is not to draw conclusions about that sample but to draw conclusions about the population that the sample was selected from. Thus researchers must use sample statistics to draw conclusions about the corresponding values in the population. These corresponding values in the population are called parameters . Imagine, for example, that a researcher measures the number of depressive symptoms exhibited by each of 50 adults with clinical depression and computes the mean number of symptoms. The researcher probably wants to use this sample statistic (the mean number of symptoms for the sample) to draw conclusions about the corresponding population parameter (the mean number of symptoms for adults with clinical depression).
Unfortunately, sample statistics are not perfect estimates of their corresponding population parameters. This is because there is a certain amount of random variability in any statistic from sample to sample. The mean number of depressive symptoms might be 8.73 in one sample of adults with clinical depression, 6.45 in a second sample, and 9.44 in a third—even though these samples are selected randomly from the same population. Similarly, the correlation (Pearson’s r ) between two variables might be +.24 in one sample, −.04 in a second sample, and +.15 in a third—again, even though these samples are selected randomly from the same population. This random variability in a statistic from sample to sample is called sampling error . (Note that the term error here refers to random variability and does not imply that anyone has made a mistake. No one “commits a sampling error.”)
One implication of this is that when there is a statistical relationship in a sample, it is not always clear that there is a statistical relationship in the population. A small difference between two group means in a sample might indicate that there is a small difference between the two group means in the population. But it could also be that there is no difference between the means in the population and that the difference in the sample is just a matter of sampling error. Similarly, a Pearson’s r value of −.29 in a sample might mean that there is a negative relationship in the population. But it could also be that there is no relationship in the population and that the relationship in the sample is just a matter of sampling error.
In fact, any statistical relationship in a sample can be interpreted in two ways:
- There is a relationship in the population, and the relationship in the sample reflects this.
- There is no relationship in the population, and the relationship in the sample reflects only sampling error.
The purpose of null hypothesis testing is simply to help researchers decide between these two interpretations.
The Logic of Null Hypothesis Testing
Null hypothesis testing (often called null hypothesis significance testing or NHST) is a formal approach to deciding between two interpretations of a statistical relationship in a sample. One interpretation is called the null hypothesis (often symbolized H 0 and read as “H-zero”). This is the idea that there is no relationship in the population and that the relationship in the sample reflects only sampling error. Informally, the null hypothesis is that the sample relationship “occurred by chance.” The other interpretation is called the alternative hypothesis (often symbolized as H 1 ). This is the idea that there is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
Again, every statistical relationship in a sample can be interpreted in either of these two ways: It might have occurred by chance, or it might reflect a relationship in the population. So researchers need a way to decide between them. Although there are many specific null hypothesis testing techniques, they are all based on the same general logic. The steps are as follows:
- Assume for the moment that the null hypothesis is true. There is no relationship between the variables in the population.
- Determine how likely the sample relationship would be if the null hypothesis were true.
- If the sample relationship would be extremely unlikely, then reject the null hypothesis in favor of the alternative hypothesis. If it would not be extremely unlikely, then retain the null hypothesis .
Following this logic, we can begin to understand why Mehl and his colleagues concluded that there is no difference in talkativeness between women and men in the population. In essence, they asked the following question: “If there were no difference in the population, how likely is it that we would find a small difference of d = 0.06 in our sample?” Their answer to this question was that this sample relationship would be fairly likely if the null hypothesis were true. Therefore, they retained the null hypothesis—concluding that there is no evidence of a sex difference in the population. We can also see why Kanner and his colleagues concluded that there is a correlation between hassles and symptoms in the population. They asked, “If the null hypothesis were true, how likely is it that we would find a strong correlation of +.60 in our sample?” Their answer to this question was that this sample relationship would be fairly unlikely if the null hypothesis were true. Therefore, they rejected the null hypothesis in favor of the alternative hypothesis—concluding that there is a positive correlation between these variables in the population.
A crucial step in null hypothesis testing is finding the probability of the sample result or a more extreme result if the null hypothesis were true (Lakens, 2017). [1] This probability is called the p value . A low p value means that the sample or more extreme result would be unlikely if the null hypothesis were true and leads to the rejection of the null hypothesis. A p value that is not low means that the sample or more extreme result would be likely if the null hypothesis were true and leads to the retention of the null hypothesis. But how low must the p value criterion be before the sample result is considered unlikely enough to reject the null hypothesis? In null hypothesis testing, this criterion is called α (alpha) and is almost always set to .05. If there is a 5% chance or less of a result at least as extreme as the sample result if the null hypothesis were true, then the null hypothesis is rejected. When this happens, the result is said to be statistically significant . If there is greater than a 5% chance of a result as extreme as the sample result when the null hypothesis is true, then the null hypothesis is retained. This does not necessarily mean that the researcher accepts the null hypothesis as true—only that there is not currently enough evidence to reject it. Researchers often use the expression “fail to reject the null hypothesis” rather than “retain the null hypothesis,” but they never use the expression “accept the null hypothesis.”
The Misunderstood p Value
The p value is one of the most misunderstood quantities in psychological research (Cohen, 1994) [2] . Even professional researchers misinterpret it, and it is not unusual for such misinterpretations to appear in statistics textbooks!
The most common misinterpretation is that the p value is the probability that the null hypothesis is true—that the sample result occurred by chance. For example, a misguided researcher might say that because the p value is .02, there is only a 2% chance that the result is due to chance and a 98% chance that it reflects a real relationship in the population. But this is incorrect . The p value is really the probability of a result at least as extreme as the sample result if the null hypothesis were true. So a p value of .02 means that if the null hypothesis were true, a sample result this extreme would occur only 2% of the time.
You can avoid this misunderstanding by remembering that the p value is not the probability that any particular hypothesis is true or false. Instead, it is the probability of obtaining the sample result if the null hypothesis were true.

Role of Sample Size and Relationship Strength
Recall that null hypothesis testing involves answering the question, “If the null hypothesis were true, what is the probability of a sample result as extreme as this one?” In other words, “What is the p value?” It can be helpful to see that the answer to this question depends on just two considerations: the strength of the relationship and the size of the sample. Specifically, the stronger the sample relationship and the larger the sample, the less likely the result would be if the null hypothesis were true. That is, the lower the p value. This should make sense. Imagine a study in which a sample of 500 women is compared with a sample of 500 men in terms of some psychological characteristic, and Cohen’s d is a strong 0.50. If there were really no sex difference in the population, then a result this strong based on such a large sample should seem highly unlikely. Now imagine a similar study in which a sample of three women is compared with a sample of three men, and Cohen’s d is a weak 0.10. If there were no sex difference in the population, then a relationship this weak based on such a small sample should seem likely. And this is precisely why the null hypothesis would be rejected in the first example and retained in the second.
Of course, sometimes the result can be weak and the sample large, or the result can be strong and the sample small. In these cases, the two considerations trade off against each other so that a weak result can be statistically significant if the sample is large enough and a strong relationship can be statistically significant even if the sample is small. Table 13.1 shows roughly how relationship strength and sample size combine to determine whether a sample result is statistically significant. The columns of the table represent the three levels of relationship strength: weak, medium, and strong. The rows represent four sample sizes that can be considered small, medium, large, and extra large in the context of psychological research. Thus each cell in the table represents a combination of relationship strength and sample size. If a cell contains the word Yes , then this combination would be statistically significant for both Cohen’s d and Pearson’s r . If it contains the word No , then it would not be statistically significant for either. There is one cell where the decision for d and r would be different and another where it might be different depending on some additional considerations, which are discussed in Section 13.2 “Some Basic Null Hypothesis Tests”
| Sample Size | Weak | Medium | Strong |
| Small ( = 20) | No | No | = Maybe = Yes |
| Medium ( = 50) | No | Yes | Yes |
| Large ( = 100) | = Yes = No | Yes | Yes |
| Extra large ( = 500) | Yes | Yes | Yes |
Although Table 13.1 provides only a rough guideline, it shows very clearly that weak relationships based on medium or small samples are never statistically significant and that strong relationships based on medium or larger samples are always statistically significant. If you keep this lesson in mind, you will often know whether a result is statistically significant based on the descriptive statistics alone. It is extremely useful to be able to develop this kind of intuitive judgment. One reason is that it allows you to develop expectations about how your formal null hypothesis tests are going to come out, which in turn allows you to detect problems in your analyses. For example, if your sample relationship is strong and your sample is medium, then you would expect to reject the null hypothesis. If for some reason your formal null hypothesis test indicates otherwise, then you need to double-check your computations and interpretations. A second reason is that the ability to make this kind of intuitive judgment is an indication that you understand the basic logic of this approach in addition to being able to do the computations.
Statistical Significance Versus Practical Significance
Table 13.1 illustrates another extremely important point. A statistically significant result is not necessarily a strong one. Even a very weak result can be statistically significant if it is based on a large enough sample. This is closely related to Janet Shibley Hyde’s argument about sex differences (Hyde, 2007) [3] . The differences between women and men in mathematical problem solving and leadership ability are statistically significant. But the word significant can cause people to interpret these differences as strong and important—perhaps even important enough to influence the college courses they take or even who they vote for. As we have seen, however, these statistically significant differences are actually quite weak—perhaps even “trivial.”
This is why it is important to distinguish between the statistical significance of a result and the practical significance of that result. Practical significance refers to the importance or usefulness of the result in some real-world context. Many sex differences are statistically significant—and may even be interesting for purely scientific reasons—but they are not practically significant. In clinical practice, this same concept is often referred to as “clinical significance.” For example, a study on a new treatment for social phobia might show that it produces a statistically significant positive effect. Yet this effect still might not be strong enough to justify the time, effort, and other costs of putting it into practice—especially if easier and cheaper treatments that work almost as well already exist. Although statistically significant, this result would be said to lack practical or clinical significance.

Image Description
“Null Hypothesis” long description: A comic depicting a man and a woman talking in the foreground. In the background is a child working at a desk. The man says to the woman, “I can’t believe schools are still teaching kids about the null hypothesis. I remember reading a big study that conclusively disproved it years ago.” [Return to “Null Hypothesis”]
“Conditional Risk” long description: A comic depicting two hikers beside a tree during a thunderstorm. A bolt of lightning goes “crack” in the dark sky as thunder booms. One of the hikers says, “Whoa! We should get inside!” The other hiker says, “It’s okay! Lightning only kills about 45 Americans a year, so the chances of dying are only one in 7,000,000. Let’s go on!” The comic’s caption says, “The annual death rate among people who know that statistic is one in six.” [Return to “Conditional Risk”]
Media Attributions
- Null Hypothesis by XKCD CC BY-NC (Attribution NonCommercial)
- Conditional Risk by XKCD CC BY-NC (Attribution NonCommercial)
- Lakens, D. (2017, December 25). About p -values: Understanding common misconceptions. [Blog post] Retrieved from https://correlaid.org/en/blog/understand-p-values/ ↵
- Cohen, J. (1994). The world is round: p < .05. American Psychologist, 49 , 997–1003. ↵
- Hyde, J. S. (2007). New directions in the study of gender similarities and differences. Current Directions in Psychological Science, 16 , 259–263. ↵
Descriptive data that involves measuring one or more variables in a sample and computing descriptive summary data (e.g., means, correlation coefficients) for those variables.
Corresponding values in the population.
The random variability in a statistic from sample to sample.
A formal approach to deciding between two interpretations of a statistical relationship in a sample.
The idea that there is no relationship in the population and that the relationship in the sample reflects only sampling error (often symbolized H0 and read as “H-zero”).
An alternative to the null hypothesis (often symbolized as H1), this hypothesis proposes that there is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
A decision made by researchers using null hypothesis testing which occurs when the sample relationship would be extremely unlikely.
A decision made by researchers in null hypothesis testing which occurs when the sample relationship would not be extremely unlikely.
The probability of obtaining the sample result or a more extreme result if the null hypothesis were true.
The criterion that shows how low a p-value should be before the sample result is considered unlikely enough to reject the null hypothesis (Usually set to .05).
An effect that is unlikely due to random chance and therefore likely represents a real effect in the population.
Refers to the importance or usefulness of the result in some real-world context.
Understanding Null Hypothesis Testing Copyright © by Rajiv S. Jhangiani; I-Chant A. Chiang; Carrie Cuttler; and Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
What is a scientific hypothesis?
It's the initial building block in the scientific method.

Hypothesis basics
What makes a hypothesis testable.
- Types of hypotheses
- Hypothesis versus theory
Additional resources
Bibliography.
A scientific hypothesis is a tentative, testable explanation for a phenomenon in the natural world. It's the initial building block in the scientific method . Many describe it as an "educated guess" based on prior knowledge and observation. While this is true, a hypothesis is more informed than a guess. While an "educated guess" suggests a random prediction based on a person's expertise, developing a hypothesis requires active observation and background research.
The basic idea of a hypothesis is that there is no predetermined outcome. For a solution to be termed a scientific hypothesis, it has to be an idea that can be supported or refuted through carefully crafted experimentation or observation. This concept, called falsifiability and testability, was advanced in the mid-20th century by Austrian-British philosopher Karl Popper in his famous book "The Logic of Scientific Discovery" (Routledge, 1959).
A key function of a hypothesis is to derive predictions about the results of future experiments and then perform those experiments to see whether they support the predictions.
A hypothesis is usually written in the form of an if-then statement, which gives a possibility (if) and explains what may happen because of the possibility (then). The statement could also include "may," according to California State University, Bakersfield .
Here are some examples of hypothesis statements:
- If garlic repels fleas, then a dog that is given garlic every day will not get fleas.
- If sugar causes cavities, then people who eat a lot of candy may be more prone to cavities.
- If ultraviolet light can damage the eyes, then maybe this light can cause blindness.
A useful hypothesis should be testable and falsifiable. That means that it should be possible to prove it wrong. A theory that can't be proved wrong is nonscientific, according to Karl Popper's 1963 book " Conjectures and Refutations ."
An example of an untestable statement is, "Dogs are better than cats." That's because the definition of "better" is vague and subjective. However, an untestable statement can be reworded to make it testable. For example, the previous statement could be changed to this: "Owning a dog is associated with higher levels of physical fitness than owning a cat." With this statement, the researcher can take measures of physical fitness from dog and cat owners and compare the two.
Types of scientific hypotheses

In an experiment, researchers generally state their hypotheses in two ways. The null hypothesis predicts that there will be no relationship between the variables tested, or no difference between the experimental groups. The alternative hypothesis predicts the opposite: that there will be a difference between the experimental groups. This is usually the hypothesis scientists are most interested in, according to the University of Miami .
For example, a null hypothesis might state, "There will be no difference in the rate of muscle growth between people who take a protein supplement and people who don't." The alternative hypothesis would state, "There will be a difference in the rate of muscle growth between people who take a protein supplement and people who don't."
If the results of the experiment show a relationship between the variables, then the null hypothesis has been rejected in favor of the alternative hypothesis, according to the book " Research Methods in Psychology " (BCcampus, 2015).
There are other ways to describe an alternative hypothesis. The alternative hypothesis above does not specify a direction of the effect, only that there will be a difference between the two groups. That type of prediction is called a two-tailed hypothesis. If a hypothesis specifies a certain direction — for example, that people who take a protein supplement will gain more muscle than people who don't — it is called a one-tailed hypothesis, according to William M. K. Trochim , a professor of Policy Analysis and Management at Cornell University.
Sometimes, errors take place during an experiment. These errors can happen in one of two ways. A type I error is when the null hypothesis is rejected when it is true. This is also known as a false positive. A type II error occurs when the null hypothesis is not rejected when it is false. This is also known as a false negative, according to the University of California, Berkeley .
A hypothesis can be rejected or modified, but it can never be proved correct 100% of the time. For example, a scientist can form a hypothesis stating that if a certain type of tomato has a gene for red pigment, that type of tomato will be red. During research, the scientist then finds that each tomato of this type is red. Though the findings confirm the hypothesis, there may be a tomato of that type somewhere in the world that isn't red. Thus, the hypothesis is true, but it may not be true 100% of the time.
Scientific theory vs. scientific hypothesis
The best hypotheses are simple. They deal with a relatively narrow set of phenomena. But theories are broader; they generally combine multiple hypotheses into a general explanation for a wide range of phenomena, according to the University of California, Berkeley . For example, a hypothesis might state, "If animals adapt to suit their environments, then birds that live on islands with lots of seeds to eat will have differently shaped beaks than birds that live on islands with lots of insects to eat." After testing many hypotheses like these, Charles Darwin formulated an overarching theory: the theory of evolution by natural selection.
"Theories are the ways that we make sense of what we observe in the natural world," Tanner said. "Theories are structures of ideas that explain and interpret facts."
- Read more about writing a hypothesis, from the American Medical Writers Association.
- Find out why a hypothesis isn't always necessary in science, from The American Biology Teacher.
- Learn about null and alternative hypotheses, from Prof. Essa on YouTube .
Encyclopedia Britannica. Scientific Hypothesis. Jan. 13, 2022. https://www.britannica.com/science/scientific-hypothesis
Karl Popper, "The Logic of Scientific Discovery," Routledge, 1959.
California State University, Bakersfield, "Formatting a testable hypothesis." https://www.csub.edu/~ddodenhoff/Bio100/Bio100sp04/formattingahypothesis.htm
Karl Popper, "Conjectures and Refutations," Routledge, 1963.
Price, P., Jhangiani, R., & Chiang, I., "Research Methods of Psychology — 2nd Canadian Edition," BCcampus, 2015.
University of Miami, "The Scientific Method" http://www.bio.miami.edu/dana/161/evolution/161app1_scimethod.pdf
William M.K. Trochim, "Research Methods Knowledge Base," https://conjointly.com/kb/hypotheses-explained/
University of California, Berkeley, "Multiple Hypothesis Testing and False Discovery Rate" https://www.stat.berkeley.edu/~hhuang/STAT141/Lecture-FDR.pdf
University of California, Berkeley, "Science at multiple levels" https://undsci.berkeley.edu/article/0_0_0/howscienceworks_19
Sign up for the Live Science daily newsletter now
Get the world’s most fascinating discoveries delivered straight to your inbox.
'The difference between alarming and catastrophic': Cascadia megafault has 1 especially deadly section, new map reveals
Arctic 'zombie fires' rising from the dead could unleash vicious cycle of warming
Epidurals may lower risk of complications after birth, study hints
Most Popular
- 2 100-foot 'walking tree' in New Zealand looks like an Ent from Lord of the Rings — and is the lone survivor of a lost forest
- 3 Save $400 on Unistellar's new smart binoculars during their early bird Kickstarter
- 4 10 'breathtaking' photos of our galaxy from the 2024 Milky Way Photographer of the Year contest
- 5 James Webb telescope finds carbon at the dawn of the universe, challenging our understanding of when life could have emerged
- 2 Neanderthals and humans interbred 47,000 years ago for nearly 7,000 years, research suggests
- 3 What is the 3-body problem, and is it really unsolvable?
- 4 Razor-thin silk 'dampens noise by 75%' — could be game-changer for sound-proofing homes and offices
- 5 Shigir Idol: World's oldest wood sculpture has mysterious carved faces and once stood 17 feet tall
Chapter 13: Inferential Statistics
13.1 understanding null hypothesis testing, learning objectives.
- Explain the purpose of null hypothesis testing, including the role of sampling error.
- Describe the basic logic of null hypothesis testing.
- Describe the role of relationship strength and sample size in determining statistical significance and make reasonable judgments about statistical significance based on these two factors.
The Purpose of Null Hypothesis Testing
As we have seen, psychological research typically involves measuring one or more variables for a sample and computing descriptive statistics for that sample. In general, however, the researcher’s goal is not to draw conclusions about that sample but to draw conclusions about the population that the sample was selected from. Thus researchers must use sample statistics to draw conclusions about the corresponding values in the population. These corresponding values in the population are called parameters . Imagine, for example, that a researcher measures the number of depressive symptoms exhibited by each of 50 clinically depressed adults and computes the mean number of symptoms. The researcher probably wants to use this sample statistic (the mean number of symptoms for the sample) to draw conclusions about the corresponding population parameter (the mean number of symptoms for clinically depressed adults).
Unfortunately, sample statistics are not perfect estimates of their corresponding population parameters. This is because there is a certain amount of random variability in any statistic from sample to sample. The mean number of depressive symptoms might be 8.73 in one sample of clinically depressed adults, 6.45 in a second sample, and 9.44 in a third—even though these samples are selected randomly from the same population. Similarly, the correlation (Pearson’s r ) between two variables might be +.24 in one sample, −.04 in a second sample, and +.15 in a third—again, even though these samples are selected randomly from the same population. This random variability in a statistic from sample to sample is called sampling error . (Note that the term error here refers to random variability and does not imply that anyone has made a mistake. No one “commits a sampling error.”)
One implication of this is that when there is a statistical relationship in a sample, it is not always clear that there is a statistical relationship in the population. A small difference between two group means in a sample might indicate that there is a small difference between the two group means in the population. But it could also be that there is no difference between the means in the population and that the difference in the sample is just a matter of sampling error. Similarly, a Pearson’s r value of −.29 in a sample might mean that there is a negative relationship in the population. But it could also be that there is no relationship in the population and that the relationship in the sample is just a matter of sampling error.
In fact, any statistical relationship in a sample can be interpreted in two ways:
- There is a relationship in the population, and the relationship in the sample reflects this.
- There is no relationship in the population, and the relationship in the sample reflects only sampling error.
The purpose of null hypothesis testing is simply to help researchers decide between these two interpretations.
The Logic of Null Hypothesis Testing
Null hypothesis testing is a formal approach to deciding between two interpretations of a statistical relationship in a sample. One interpretation is called the null hypothesis (often symbolized H 0 and read as “H-naught”). This is the idea that there is no relationship in the population and that the relationship in the sample reflects only sampling error. Informally, the null hypothesis is that the sample relationship “occurred by chance.” The other interpretation is called the alternative hypothesis (often symbolized as H 1 ). This is the idea that there is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
Again, every statistical relationship in a sample can be interpreted in either of these two ways: It might have occurred by chance, or it might reflect a relationship in the population. So researchers need a way to decide between them. Although there are many specific null hypothesis testing techniques, they are all based on the same general logic. The steps are as follows:
- Assume for the moment that the null hypothesis is true. There is no relationship between the variables in the population.
- Determine how likely the sample relationship would be if the null hypothesis were true.
- If the sample relationship would be extremely unlikely, then reject the null hypothesis in favor of the alternative hypothesis. If it would not be extremely unlikely, then retain the null hypothesis .
Following this logic, we can begin to understand why Mehl and his colleagues concluded that there is no difference in talkativeness between women and men in the population. In essence, they asked the following question: “If there were no difference in the population, how likely is it that we would find a small difference of d = 0.06 in our sample?” Their answer to this question was that this sample relationship would be fairly likely if the null hypothesis were true. Therefore, they retained the null hypothesis—concluding that there is no evidence of a sex difference in the population. We can also see why Kanner and his colleagues concluded that there is a correlation between hassles and symptoms in the population. They asked, “If the null hypothesis were true, how likely is it that we would find a strong correlation of +.60 in our sample?” Their answer to this question was that this sample relationship would be fairly unlikely if the null hypothesis were true. Therefore, they rejected the null hypothesis in favor of the alternative hypothesis—concluding that there is a positive correlation between these variables in the population.
A crucial step in null hypothesis testing is finding the likelihood of the sample result if the null hypothesis were true. This probability is called the p value . A low p value means that the sample result would be unlikely if the null hypothesis were true and leads to the rejection of the null hypothesis. A high p value means that the sample result would be likely if the null hypothesis were true and leads to the retention of the null hypothesis. But how low must the p value be before the sample result is considered unlikely enough to reject the null hypothesis? In null hypothesis testing, this criterion is called α (alpha) and is almost always set to .05. If there is less than a 5% chance of a result as extreme as the sample result if the null hypothesis were true, then the null hypothesis is rejected. When this happens, the result is said to be statistically significant . If there is greater than a 5% chance of a result as extreme as the sample result when the null hypothesis is true, then the null hypothesis is retained. This does not necessarily mean that the researcher accepts the null hypothesis as true—only that there is not currently enough evidence to conclude that it is true. Researchers often use the expression “fail to reject the null hypothesis” rather than “retain the null hypothesis,” but they never use the expression “accept the null hypothesis.”
The Misunderstood p Value
The p value is one of the most misunderstood quantities in psychological research (Cohen, 1994). Even professional researchers misinterpret it, and it is not unusual for such misinterpretations to appear in statistics textbooks!
The most common misinterpretation is that the p value is the probability that the null hypothesis is true—that the sample result occurred by chance. For example, a misguided researcher might say that because the p value is .02, there is only a 2% chance that the result is due to chance and a 98% chance that it reflects a real relationship in the population. But this is incorrect . The p value is really the probability of a result at least as extreme as the sample result if the null hypothesis were true. So a p value of .02 means that if the null hypothesis were true, a sample result this extreme would occur only 2% of the time.
You can avoid this misunderstanding by remembering that the p value is not the probability that any particular hypothesis is true or false. Instead, it is the probability of obtaining the sample result if the null hypothesis were true.
Role of Sample Size and Relationship Strength
Recall that null hypothesis testing involves answering the question, “If the null hypothesis were true, what is the probability of a sample result as extreme as this one?” In other words, “What is the p value?” It can be helpful to see that the answer to this question depends on just two considerations: the strength of the relationship and the size of the sample. Specifically, the stronger the sample relationship and the larger the sample, the less likely the result would be if the null hypothesis were true. That is, the lower the p value. This should make sense. Imagine a study in which a sample of 500 women is compared with a sample of 500 men in terms of some psychological characteristic, and Cohen’s d is a strong 0.50. If there were really no sex difference in the population, then a result this strong based on such a large sample should seem highly unlikely. Now imagine a similar study in which a sample of three women is compared with a sample of three men, and Cohen’s d is a weak 0.10. If there were no sex difference in the population, then a relationship this weak based on such a small sample should seem likely. And this is precisely why the null hypothesis would be rejected in the first example and retained in the second.
Of course, sometimes the result can be weak and the sample large, or the result can be strong and the sample small. In these cases, the two considerations trade off against each other so that a weak result can be statistically significant if the sample is large enough and a strong relationship can be statistically significant even if the sample is small. Table 13.1 “How Relationship Strength and Sample Size Combine to Determine Whether a Result Is Statistically Significant” shows roughly how relationship strength and sample size combine to determine whether a sample result is statistically significant. The columns of the table represent the three levels of relationship strength: weak, medium, and strong. The rows represent four sample sizes that can be considered small, medium, large, and extra large in the context of psychological research. Thus each cell in the table represents a combination of relationship strength and sample size. If a cell contains the word Yes , then this combination would be statistically significant for both Cohen’s d and Pearson’s r . If it contains the word No , then it would not be statistically significant for either. There is one cell where the decision for d and r would be different and another where it might be different depending on some additional considerations, which are discussed in Section 13.2 “Some Basic Null Hypothesis Tests”
Table 13.1 How Relationship Strength and Sample Size Combine to Determine Whether a Result Is Statistically Significant
| Relationship strength | |||
|---|---|---|---|
| Sample Size | Weak | Medium | Strong |
| Small ( = 20) | No | No | = Maybe = Yes |
| Medium ( = 50) | No | Yes | Yes |
| Large ( = 100) | = Yes = No | Yes | Yes |
| Extra large ( = 500) | Yes | Yes | Yes |
Although Table 13.1 “How Relationship Strength and Sample Size Combine to Determine Whether a Result Is Statistically Significant” provides only a rough guideline, it shows very clearly that weak relationships based on medium or small samples are never statistically significant and that strong relationships based on medium or larger samples are always statistically significant. If you keep this in mind, you will often know whether a result is statistically significant based on the descriptive statistics alone. It is extremely useful to be able to develop this kind of intuitive judgment. One reason is that it allows you to develop expectations about how your formal null hypothesis tests are going to come out, which in turn allows you to detect problems in your analyses. For example, if your sample relationship is strong and your sample is medium, then you would expect to reject the null hypothesis. If for some reason your formal null hypothesis test indicates otherwise, then you need to double-check your computations and interpretations. A second reason is that the ability to make this kind of intuitive judgment is an indication that you understand the basic logic of this approach in addition to being able to do the computations.
Statistical Significance Versus Practical Significance
Table 13.1 “How Relationship Strength and Sample Size Combine to Determine Whether a Result Is Statistically Significant” illustrates another extremely important point. A statistically significant result is not necessarily a strong one. Even a very weak result can be statistically significant if it is based on a large enough sample. This is closely related to Janet Shibley Hyde’s argument about sex differences (Hyde, 2007). The differences between women and men in mathematical problem solving and leadership ability are statistically significant. But the word significant can cause people to interpret these differences as strong and important—perhaps even important enough to influence the college courses they take or even who they vote for. As we have seen, however, these statistically significant differences are actually quite weak—perhaps even “trivial.”
This is why it is important to distinguish between the statistical significance of a result and the practical significance of that result. Practical significance refers to the importance or usefulness of the result in some real-world context. Many sex differences are statistically significant—and may even be interesting for purely scientific reasons—but they are not practically significant. In clinical practice, this same concept is often referred to as “clinical significance.” For example, a study on a new treatment for social phobia might show that it produces a statistically significant positive effect. Yet this effect still might not be strong enough to justify the time, effort, and other costs of putting it into practice—especially if easier and cheaper treatments that work almost as well already exist. Although statistically significant, this result would be said to lack practical or clinical significance.
Key Takeaways
- Null hypothesis testing is a formal approach to deciding whether a statistical relationship in a sample reflects a real relationship in the population or is just due to chance.
- The logic of null hypothesis testing involves assuming that the null hypothesis is true, finding how likely the sample result would be if this assumption were correct, and then making a decision. If the sample result would be unlikely if the null hypothesis were true, then it is rejected in favor of the alternative hypothesis. If it would not be unlikely, then the null hypothesis is retained.
- The probability of obtaining the sample result if the null hypothesis were true (the p value) is based on two considerations: relationship strength and sample size. Reasonable judgments about whether a sample relationship is statistically significant can often be made by quickly considering these two factors.
- Statistical significance is not the same as relationship strength or importance. Even weak relationships can be statistically significant if the sample size is large enough. It is important to consider relationship strength and the practical significance of a result in addition to its statistical significance.
- Discussion: Imagine a study showing that people who eat more broccoli tend to be happier. Explain for someone who knows nothing about statistics why the researchers would conduct a null hypothesis test.
Practice: Use Table 13.1 “How Relationship Strength and Sample Size Combine to Determine Whether a Result Is Statistically Significant” to decide whether each of the following results is statistically significant.
- The correlation between two variables is r = −.78 based on a sample size of 137.
- The mean score on a psychological characteristic for women is 25 ( SD = 5) and the mean score for men is 24 ( SD = 5). There were 12 women and 10 men in this study.
- In a memory experiment, the mean number of items recalled by the 40 participants in Condition A was 0.50 standard deviations greater than the mean number recalled by the 40 participants in Condition B.
- In another memory experiment, the mean scores for participants in Condition A and Condition B came out exactly the same!
- A student finds a correlation of r = .04 between the number of units the students in his research methods class are taking and the students’ level of stress.
Cohen, J. (1994). The world is round: p < .05. American Psychologist, 49 , 997–1003.
Hyde, J. S. (2007). New directions in the study of gender similarities and differences. Current Directions in Psychological Science , 16 , 259–263.
- Research Methods in Psychology. Provided by : University of Minnesota Libraries Publishing. Located at : http://open.lib.umn.edu/psychologyresearchmethods/ . License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike

Privacy Policy
COMMENTS
The null and alternative hypotheses offer competing answers to your research question. When the research question asks "Does the independent variable affect the dependent variable?": The null hypothesis ( H0) answers "No, there's no effect in the population.". The alternative hypothesis ( Ha) answers "Yes, there is an effect in the ...
The null hypothesis in statistics states that there is no difference between groups or no relationship between variables. It is one of two mutually exclusive hypotheses about a population in a hypothesis test. When your sample contains sufficient evidence, you can reject the null and conclude that the effect is statistically significant.
Hypothesis-generating: Descriptive research questions: Evaluation research questions: ... state a negative relationship between two variables (null hypothesis),4,11,15 4) replace the working hypothesis if rejected ... Hypothesis 3. There will be no significant differences in the well-being of the mother and child among the three groups in terms ...
This null hypothesis can be written as: H0: X¯ = μ H 0: X ¯ = μ. For most of this textbook, the null hypothesis is that the means of the two groups are similar. Much later, the null hypothesis will be that there is no relationship between the two groups. Either way, remember that a null hypothesis is always saying that nothing is different.
A crucial step in null hypothesis testing is finding the likelihood of the sample result if the null hypothesis were true. This probability is called the p value. A low p value means that the sample result would be unlikely if the null hypothesis were true and leads to the rejection of the null hypothesis. A high p value means that the sample ...
A crucial step in null hypothesis testing is finding the likelihood of the sample result if the null hypothesis were true. This probability is called the p value. A low p value means that the sample result would be unlikely if the null hypothesis were true and leads to the rejection of the null hypothesis. A p value that is not low means that ...
The null and alternative hypotheses offer competing answers to your research question. When the research question asks "Does the independent variable affect the dependent variable?", the null hypothesis (H 0) answers "No, there's no effect in the population.". On the other hand, the alternative hypothesis (H A) answers "Yes, there ...
Descriptive Hypothesis A descriptive hypothesis is a statement that suggests a potential answer to a research question, focusing on describing the characteristics, behaviors, or properties of a particular group, situation, or phenomenon. It does not imply a causal relationship but rather aims to identify and describe specific attributes or ...
descriptive research: research studies that do not test specific relationships between variables; they are used to describe general or specific behaviors and attributes that are observed and measured. experimental research: tests a hypothesis to determine cause and effect relationships.
This null hypothesis can be written as: H0: X¯ = μ H 0: X ¯ = μ. For most of this textbook, the null hypothesis is that the means of the two groups are similar. Much later, the null hypothesis will be that there is no relationship between the two groups. Either way, remember that a null hypothesis is always saying that nothing is different.
A research hypothesis, in its plural form "hypotheses," is a specific, testable prediction about the anticipated results of a study, established at its outset. It is a key component of the scientific method. Hypotheses connect theory to data and guide the research process towards expanding scientific understanding.
6. Write a null hypothesis. If your research involves statistical hypothesis testing, you will also have to write a null hypothesis. The null hypothesis is the default position that there is no association between the variables. The null hypothesis is written as H 0, while the alternative hypothesis is H 1 or H a.
Alternatively, a script for a quantitative null hypothesis might be as follows: There is no significant difference between _____ (the control and experimental groups on the independent variable) on _____ (dependent variable). Guidelines for writing good quantitative research questions and hypotheses include the following.
The actual test begins by considering two hypotheses.They are called the null hypothesis and the alternative hypothesis.These hypotheses contain opposing viewpoints. H 0, the —null hypothesis: a statement of no difference between sample means or proportions or no difference between a sample mean or proportion and a population mean or proportion. In other words, the difference equals 0.
If your null hypothesis was rejected, this result is interpreted as "supported the alternate hypothesis." Stating results in a research paper We found a difference in average height between men and women of 14.3cm, with a p-value of 0.002, consistent with our hypothesis that there is a difference in height between men and women.
The Logic of Null Hypothesis Testing. Null hypothesis testing (often called null hypothesis significance testing or NHST) is a formal approach to deciding between two interpretations of a statistical relationship in a sample. One interpretation is called the null hypothesis (often symbolized H0 and read as "H-zero").
In scientific research, the null hypothesis (often denoted H 0) is the claim that the effect being studied does not exist. The null hypothesis can also be described as the hypothesis in which no relationship exists between two sets of data or variables being analyzed. If the null hypothesis is true, any experimentally observed effect is due to ...
To distinguish it from other hypotheses, the null hypothesis is written as H 0 (which is read as "H-nought," "H-null," or "H-zero"). A significance test is used to determine the likelihood that the results supporting the null hypothesis are not due to chance. A confidence level of 95% or 99% is common. Keep in mind, even if the confidence level is high, there is still a small chance the ...
Descriptive cross-sectional studies are one dimensional and they are done to find prevalence of the disease. They do not attempt to establish association between two parameters in a given disease or condition. ... the research hypothesis should be tested as null hypothesis. Null hypothesis means that there is no difference in outcome between ...
There are seven different types of research hypotheses. Simple Hypothesis. A simple hypothesis predicts the relationship between a single dependent variable and a single independent variable. Complex Hypothesis. A complex hypothesis predicts the relationship between two or more independent and dependent variables. Directional Hypothesis.
Formulating Hypotheses for Different Study Designs. Generating a testable working hypothesis is the first step towards conducting original research. Such research may prove or disprove the proposed hypothesis. Case reports, case series, online surveys and other observational studies, clinical trials, and narrative reviews help to generate ...
Yes, both qualitative and quantitative studies need hypothesis, a research question you answer. Generally speaking, hypotheses are used in quantitative, deductive, experimental-type studies. In ...
Research studies that do not test specific relationships between variables are called descriptive studies. These studies are used to describe general or specific behaviors and attributes that are observed and measured. In the early stages of research, it might be difficult to form a hypothesis, especially when there is not any existing ...
An alternative hypothesis (H1 or Ha) in a statistical inference experiment directly contradicts the null hypothesis and states that there is a relationship between two variables. While the null hypothesis presumes no change or status quo, an alternative hypothesis or the claim shows that a non-random cause influences the observations.
The Logic of Null Hypothesis Testing. Null hypothesis testing (often called null hypothesis significance testing or NHST) is a formal approach to deciding between two interpretations of a statistical relationship in a sample. One interpretation is called the null hypothesis (often symbolized H0 and read as "H-zero").
A scientific hypothesis is a tentative, testable explanation for a phenomenon in the natural world. It's the initial building block in the scientific method. Many describe it as an "educated guess ...
A crucial step in null hypothesis testing is finding the likelihood of the sample result if the null hypothesis were true. This probability is called the p value. A low p value means that the sample result would be unlikely if the null hypothesis were true and leads to the rejection of the null hypothesis. A high p value means that the sample ...